
基于移动感知数据的用户画像系统
2019-12-19 06:36於志文
郑州大学学报(理学版) 2019年4期
徐 恩, 於志文, 杜 贺, 郭 斌
(西北工业大学 计算机学院普适与智能计算研究所 陕西 西安 710129)
0 引言
用户画像[1]是基于一系列数据的模型.用户具有人口统计信息以及隐含特征,如爱好和人格特征.基于用户画像,我们可以标记一个或一类用户并获得他们的信息结构.此外,用户画像可以更准确地了解此人,并实现精准营销和个性化服务.例如,用户画像可以用于推荐[2-3].根据用户的年龄和性别,360公司为不同年龄段和性别的用户创建个性化的应用推荐.不同年龄的人对应用程序有不同的偏好.文献[4]指出不同性别的用户使用手机的习惯也会有差异.因此,了解用户的年龄和性别有助于为不同用户提供适当的服务.文献[5]提出的大五人格是一个识别人格的研究框架,其中包含5个因素来描述人的人格特征.文献[6]证明大五人格与手机使用有关联.在本文中,我们提出了基于多维感知数据的用户画像模型.从年龄、性别和人格特征方面描述用户.我们使用随机森林回归算法来估计用户年龄,使用随机森林分类来检测他们性别,并且利用支持向量回归(support vector regression,SVR)算法识别人格特征.我们构建用户画像的方法经过验证是有效的.
1 相关工作
我们的工作主要涉及两个方面:用户识别和用户大五人格预测.文献[7]利用加速度传感器、GPS数据,识别用户五种移动类型.文献[8]利用用户的移动轨迹和无线终端的电子信号识别用户.文献[9]从用户安装的程序列表刻画用户的基本属性.本文不仅关注用户的外在特征,也分析用户的内在属性[10].现已有大量的研究旨在挖掘用户的大五人格.例如文献[6]根据采集的SMS、通话记录、应用程序登录情况和蓝牙记录分析用户的人格. 文献[11]基于用户的Facebook点赞情况分析其人格特征.文献[12]分析不同人格特征的人对手机功能的关注点.文献[13]基于微博信息分析用户的情绪.文献[14]基于用户文本评论分析用户的情感倾向.以往基于智能手机的研究多从短信和通话情况出发收集数据,而在采集短信和通话信息时,可能会侵犯到用户的隐私.因此本文采集非敏感数据,且在用户本地处理不用上传至服务器,分析用户使用习惯,对用户的大五人格进行识别.
2 系统概述
我们首先利用内置的传感器和事件监听器收集用户的数据.接下来,根据人们使用手机不同场景提取不同的特征,并使用相应的模型实现用户画像构建.
数据采集:系统通过手机中的传感器和事件监听器收集数据.系统中传感器的采样率设置为SENSOR_DELAY_GAME采样率.如果状态改变,则记录其余信息.
特征提取:我们提取用户画像构建的使用特征、偏好特征和活动特征.具体来说,在年龄估计部分,我们在解锁屏幕场景中收集加速度计、磁力计和光线传感器数据.对于解锁屏幕,我们分析了拿起手机阶段的仰角和倾角,以及滑动屏幕阶段的触摸特征.在性别检测中,我们通过加速度计、磁力计和陀螺仪感知数据计算解锁屏幕场景中仰角和倾斜角度.在人格特征识别中,我们获取不同的时间窗口下应用程序使用情况、电池、耳机、手机模式、网络和屏幕状态等特征.
构建用户画像:本工作中的用户画像包括年龄估计、性别检测和人格特征识别.对于年龄估计和人格特征识别,利用Pearson相关系数挖掘使用习惯和用户属性之间的关系.我们应用随机森林回归方法进行年龄估计,使用随机森林分类方法进行性别检测,并采用SVR进行人格特征鉴定.
3 年龄和性别
年龄和性别是关于人的两个最基本的人口统计学属性.了解用户的年龄和性别有助于提供个性化的服务.
3.1 数据预处理
对于加速度计和磁力计,它们是三轴传感器.有时,智能手机的变化可能会反映在传感器的一个或两个方向上.因此,我们将三轴感应数据转换为单轴,以更好地了解传感器值的变化,所用公式为
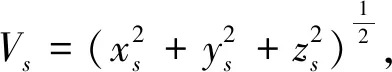
(1)
同时,我们使用加速度计和磁力计来计算方位值且利用滑动窗口来获得关键点.
3.2 年龄预测中的特征提取
一般来说,解锁屏幕的过程可以分为两个步骤:拿起手机和滑动屏幕.
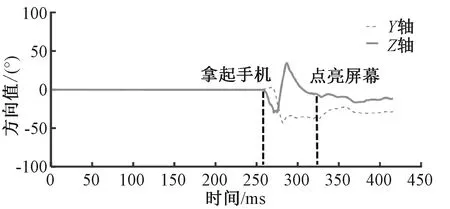
图1 解锁屏幕动作过程中的方向改变Fig.1 Change of direction during unlocking screen action
从图1中可以看到,一开始手机的仰角和倾斜角度始终是水平的,这意味着手机稳定放置;那么当用户拿起电话时就会有一个明确的转折点,而且仰角显示出明显的下降,并且在曲线上升之后,转为稳定之前还有另一个转折点,第二个转折点表示开始滑屏.
1) 拿起手机:在图2(a)中,我们可以看到儿童波动幅度最大,这意味着孩子们拿起手机会有较大的前后晃动.从图2(b)看出,老人拿起手机时,波动比小孩小.成人可以用最小的振幅拿起手机.在拿起手机阶段,我们提取了8个特征:当用户拿起手机时,手机仰角和倾角的最大值、最小值、平均值和方差.

图2 用户拿起手机时仰角的变化Fig.2 Change of elevation angle when user picks up mobile phone
2) 滑屏解锁:如图3所示,我们可以看到,所有用户在滑动屏幕上花费的时间明显不同.老人需要更长的时间来解锁.对于一些孩子来说,他们比大多数老人需要更长的时间,因为他们太小了,无法方便地使用手机.但是对于大多数孩子来说,他们的滑动时间比老年人短.
基于上述观察,滑动屏幕过程中的特征对于预测用户的年龄非常有用.这个年龄预测系统不会使用用户的敏感信息.我们总共提取了以下特征.
滑动起始区:起点区域和终点区域.我们将手机屏幕分成8*10个区域.
滑动角度:滑动轨迹与水平轴之间的角度,定义为sa.
滑动距离:滑动的长度,定义为sd.
滑动持续时间:用户开始触摸和离开屏幕的持续时间,定义为st.
滑动速度:滑动距离与滑动持续时间的比值,定义为sd/st.
3.3 性别分类中的特征提取
由文献[15]可知男性平均手掌比女性大,手指长度更长.文献[16]证明了拇指长度不同会生成不同的滑动手势.另外手掌的大小和弯曲角度不同,手机的倾仰角也会不同.这些理论激励我们探索不同性别人群使用手机的区别.
对于绝大多数用户来说,他/她解锁手机需要拿起手机并轻扫屏幕来解锁.根据年龄预测中对解锁场景的分析,我们用同样的方法,分析不同性别用户在解锁屏幕场景中的操作.当女性拿起手机时,我们可以观察到仰角变化更剧烈.由文献[16]可知,当涉及滑动手势时,男性的完成时间更短、速度更快、加速度更大.结合年龄预测中的滑动屏幕动作,我们提取了相同的特征:滑动起始区域、滑动角度、滑动距离、滑动持续时间和滑动速度.如图4所示,我们可以看到,当滑动屏幕解锁手机时,男性比女性滑动速度快.这与文献[16]的研究结果一致.
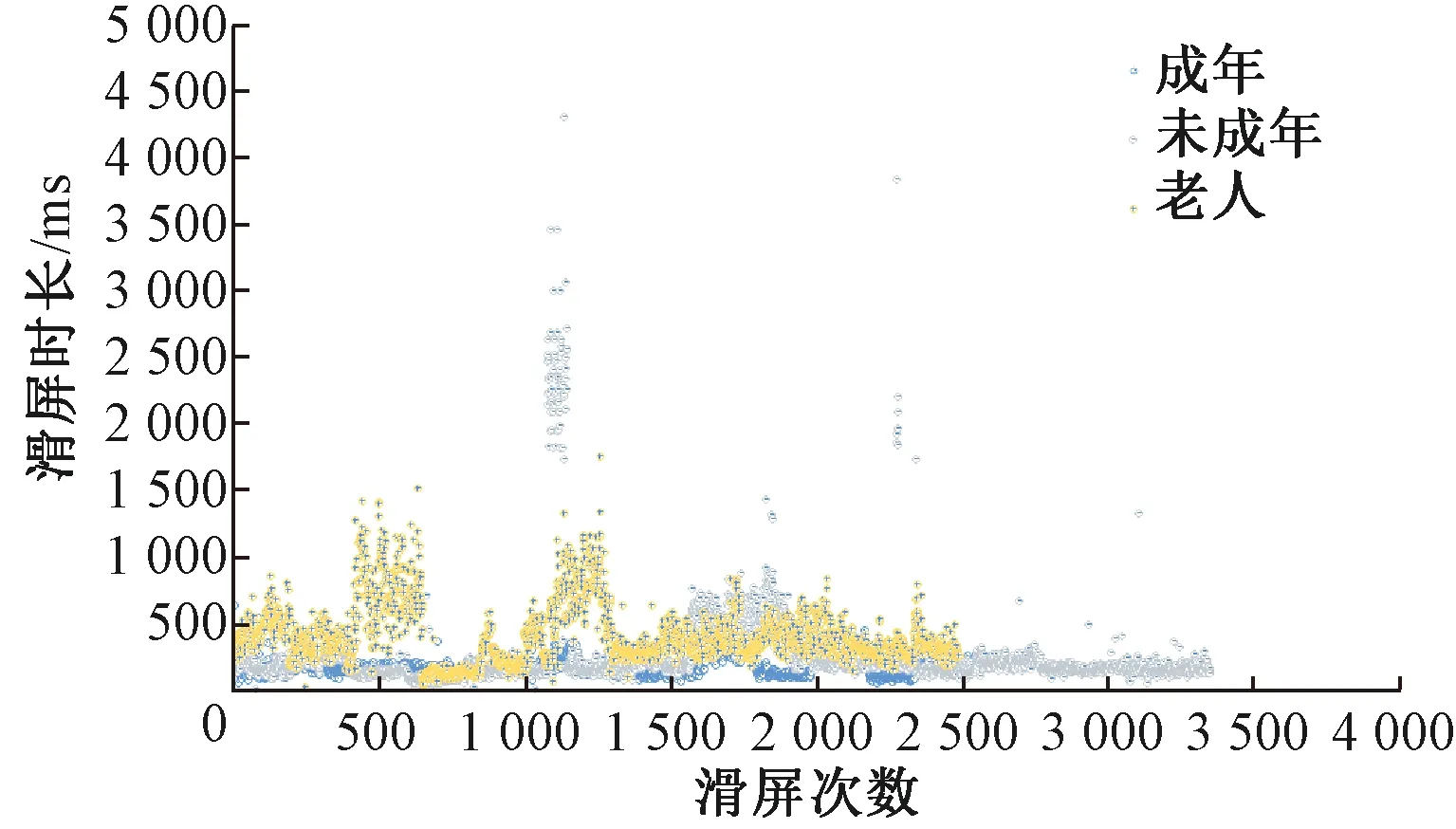
图3 解锁屏幕的滑动时间Fig.3 The time of the slide to unlock screen
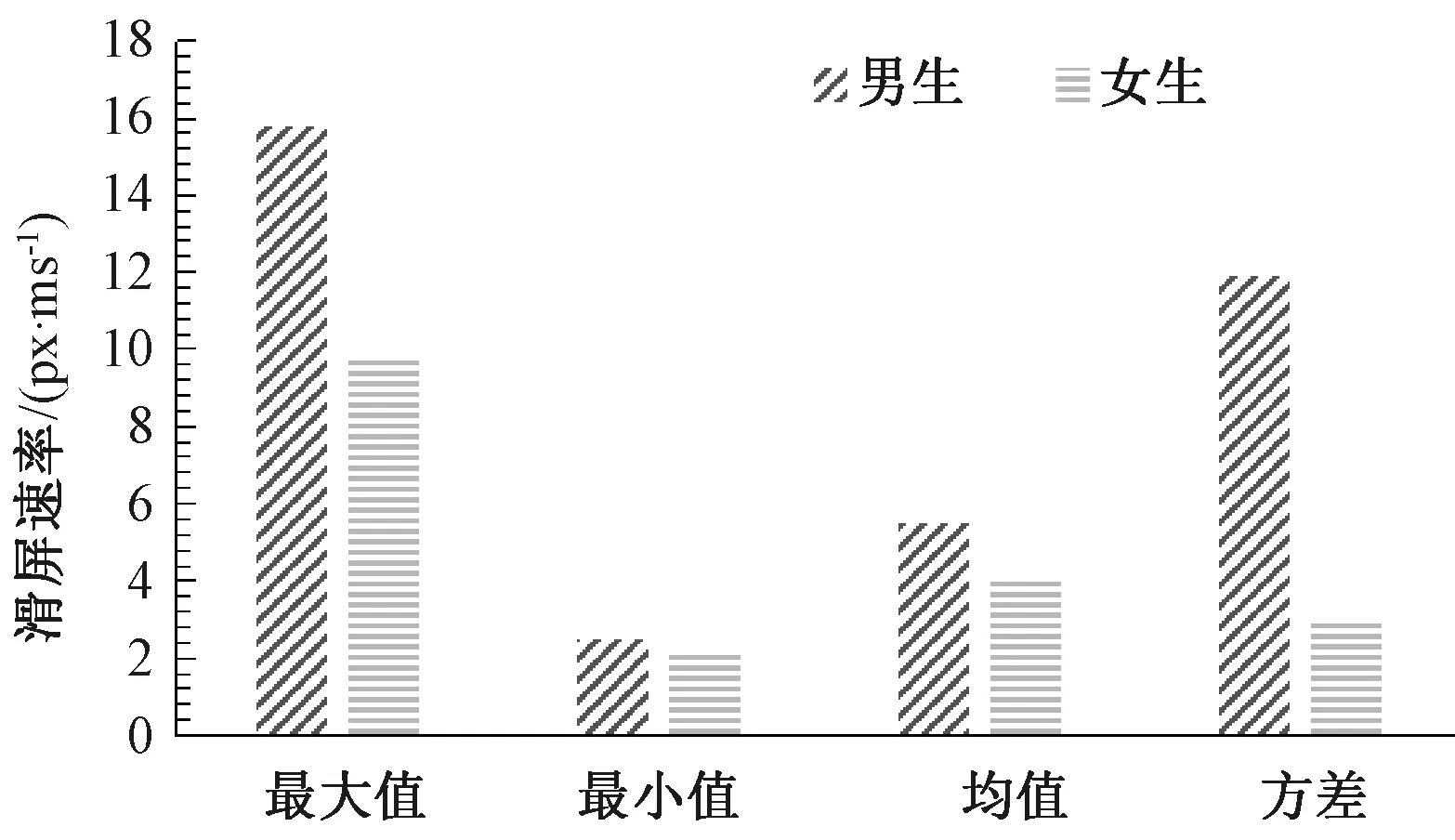
图4 解锁画面中的滑屏速率Fig.4 The speed of the slider when unlocking the screen
3.4 年龄预测和性别分类系统
3.4.1年龄阶层 在年龄预测中,我们将人们分为儿童、中青年和老年人,以分析他们使用手机时的差异.根据世界卫生组织的研究报告(https://www.who. int/healthinfo/survey/ageingdefnolder/en/),我们将年龄大于等于60岁的人视为老年人,18岁以下的人可视为儿童.在我们的工作中,将5~18岁的人视为儿童,因为该年龄的用户能够使用手机.
3.4.2年龄预测 预测年龄是一个回归问题.我们在年龄预测中探索多种监督学习方法:构建线性回归、支持向量回归、决策树、神经网络和随机森林模型,并利用10倍交叉验证来衡量预测年龄的能力.同时使用均方根误差、决策系数和Pearson相关系数来评估预测结果.
3.4.3性别分类 我们使用随机森林、朴素贝叶斯、多层感知器和支持向量机来构建性别分类系统.为了训练每个预定义属性的分类器,我们使用10倍交叉验证策略.
3.4.4数据采集 在年龄预测实验中,我们招募了35名志愿者,其中包括12名儿童、10名老年人和13名中青年.其中男性18人,女性17人.在用户性别分类实验中,我们招募了30名大学生作为志愿者,其中男性15人,女性15人.在数据采集中,用户在使用手机时,应安装About_YOUR_Property应用程序.采集使用手机滑屏解锁过程中传感器的数据.在两个实验中分别采集了将近8 000条的数据.
3.5 特征评估
3.5.1年龄预测 在年龄预测中,我们从解锁屏幕场景提取了16个特征参数.首先,我们使用特征分布来评估特征.然后,基于Pearson相关系数评估这些特征.
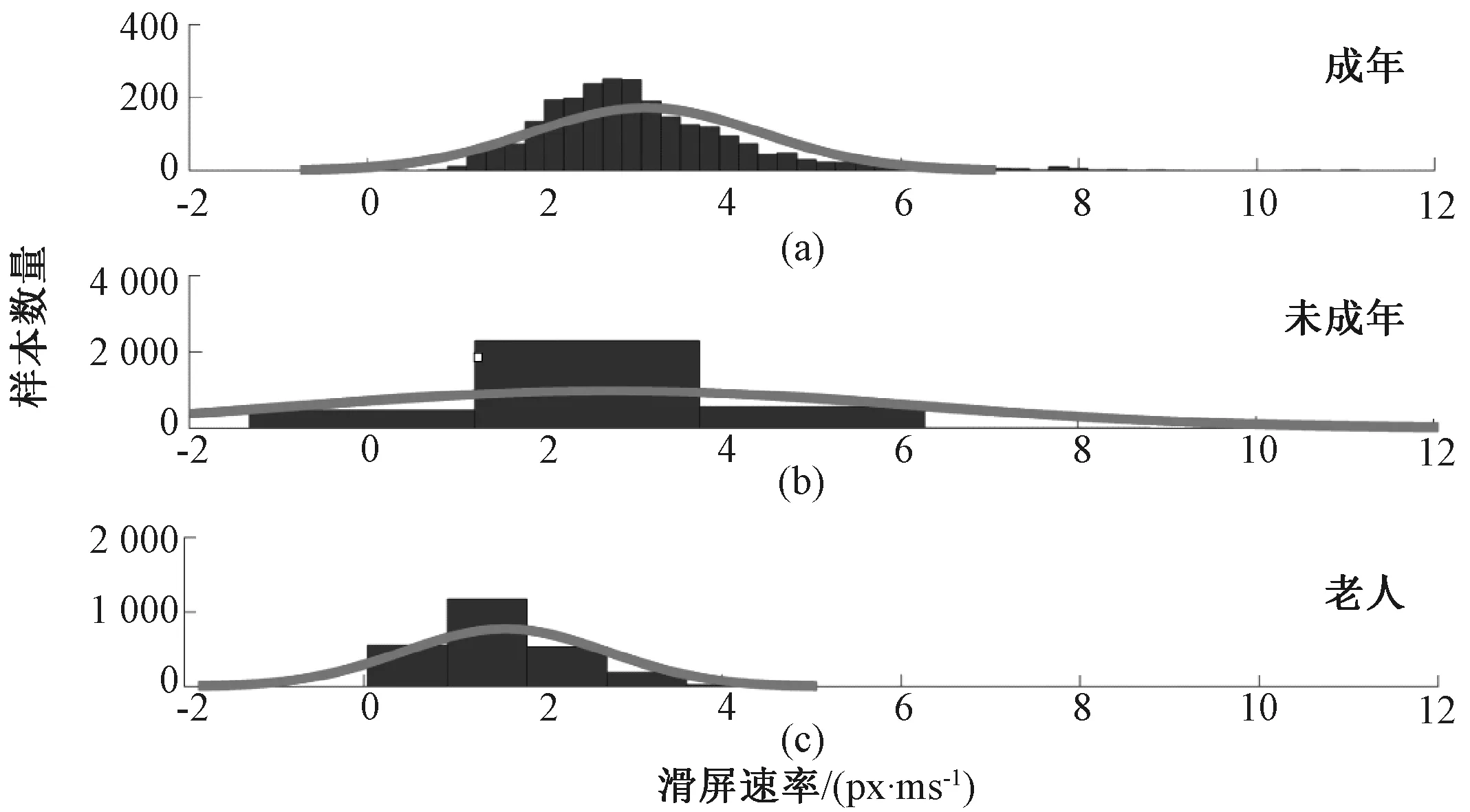
图5 年龄预测中的特征分布Fig.5 The characteristic distribution in age prediction
特征分布及相关性分析:我们将解锁屏幕过程划分为拿起手机和滑屏解锁.滑动窗口用于确定用户拿起手机滑屏的时间点.图5即为解锁屏幕时,滑屏速率分布图.从中我们可以看出,当用户滑屏解锁时,69.45%的小孩滑屏速率为1.21~3.74 px/ms;51.50%的中青年滑屏速率为1.99~3.30 px/ms;而所有老人滑屏速率为0.03~1.82 px/ms.我们使用Pearson相关系数(用r表示)来计算特征与年龄之间的相关性.拿起手机时,用户的年龄与仰角的最小值呈正相关(r=0.329,p<0.001),这意味着当老人拿起手机时,手机的仰角较大.
3.5.2性别分类 在这个实验中,我们将评估解锁屏幕场景下16个特征的分布情况.
特征分布:依据经验,同样我们将滑屏窗口的大小选定为0.2 s,而两个相邻的滑动窗口之间的时间间隔选定为0.1 s.如图6为解锁屏幕时手机仰角方差的变化分布直方图.从中我们可以看出,当方差在0~400范围内,男性用户有93.33%的人集中在这个区间,而女性用户只用73.33%集中在这个区间.依此可以知道女性用户滑屏解锁时手机仰角的波动更大.
3.6 年龄预测系统和性别分类系统的评估
3.6.1年龄预测 均方根误差和决策系数R是实验评估标准参数.通过利用提取的特征,我们使用随机森林回归算法来实现用户年龄预测.均方根误差值为4.445,相关系数为0.985,R2为0.971.
我们选择线性回归、支持向量回归、决策树、神经网络和随机森林5种回归模型来评估年龄识别系统.图7显示了每个分类模型的结果.随机森林的均方误差为4.445,表明实测年龄与实际年龄的偏差为4.445岁,优于其他4种模式.
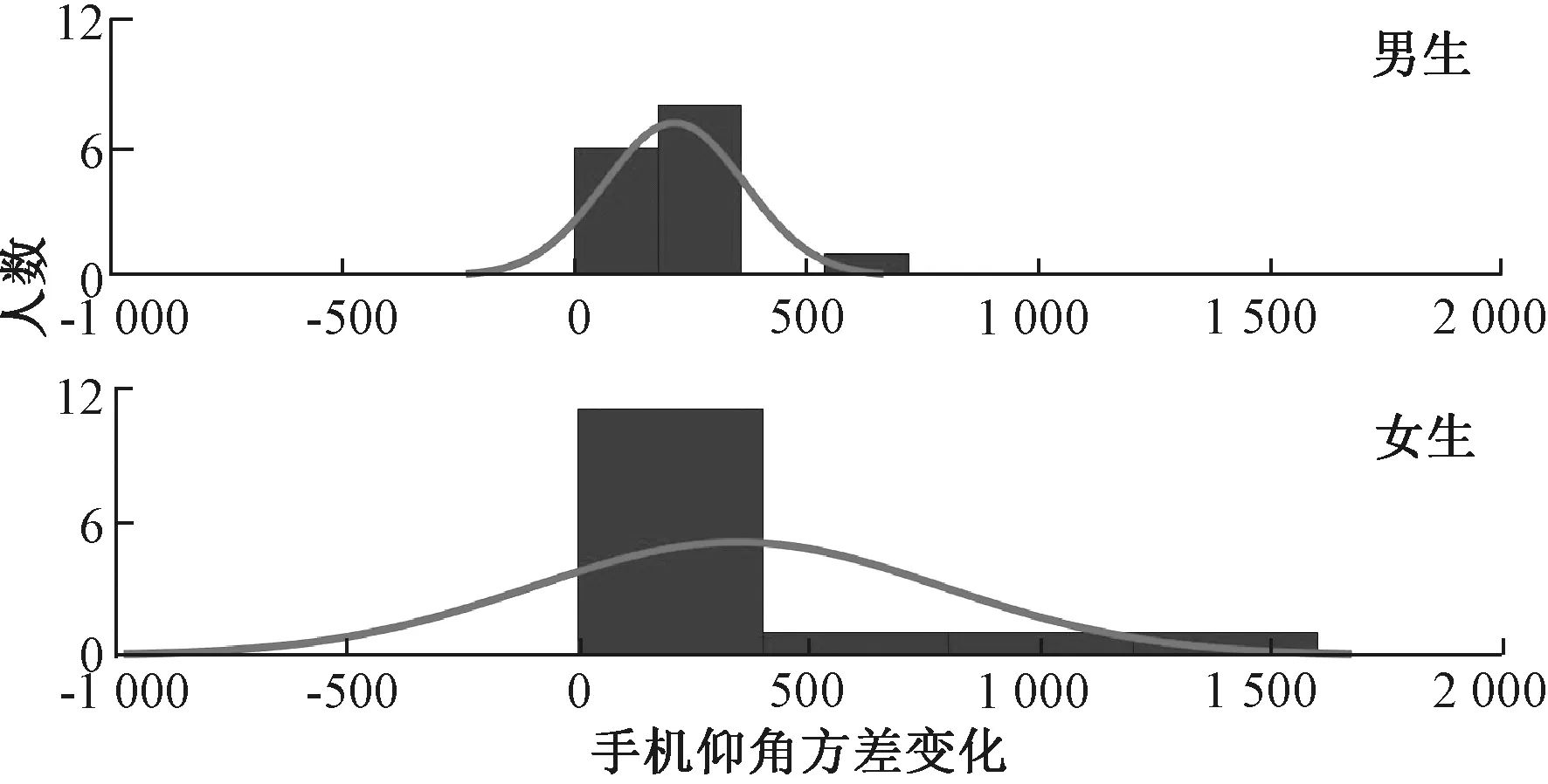
图6 性别预测中的特征分布Fig.6 The characteristic distribution in gender prediction
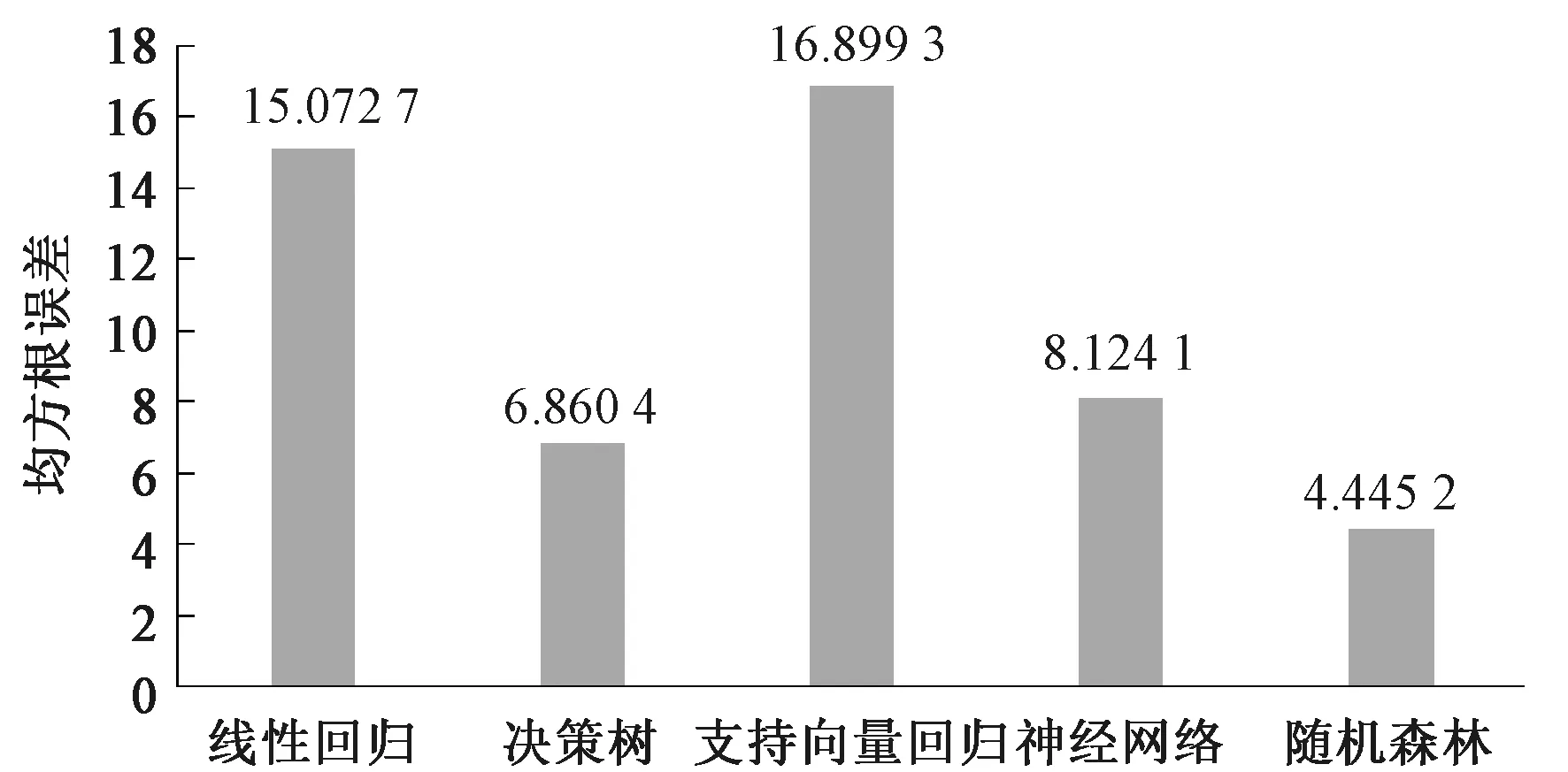
图7 不同方法的均方根误差Fig.7 The RMSE of different methods
3.6.2性别分类 最终我们将准确率和召回率作为用户性别识别系统的评价标准参数.我们分别构造了随机森林、多层感知机、支持向量机和朴素贝叶斯4种分类器对用户的性别进行预测分析.如图8所示为4种算法的表现结果,相对来说,随机森林算法构造的分类器要优于其他3种算法构建的分类器.随机森林算法构建的分类器准确率能够达到91.70%,召回率能够达到73.30%.
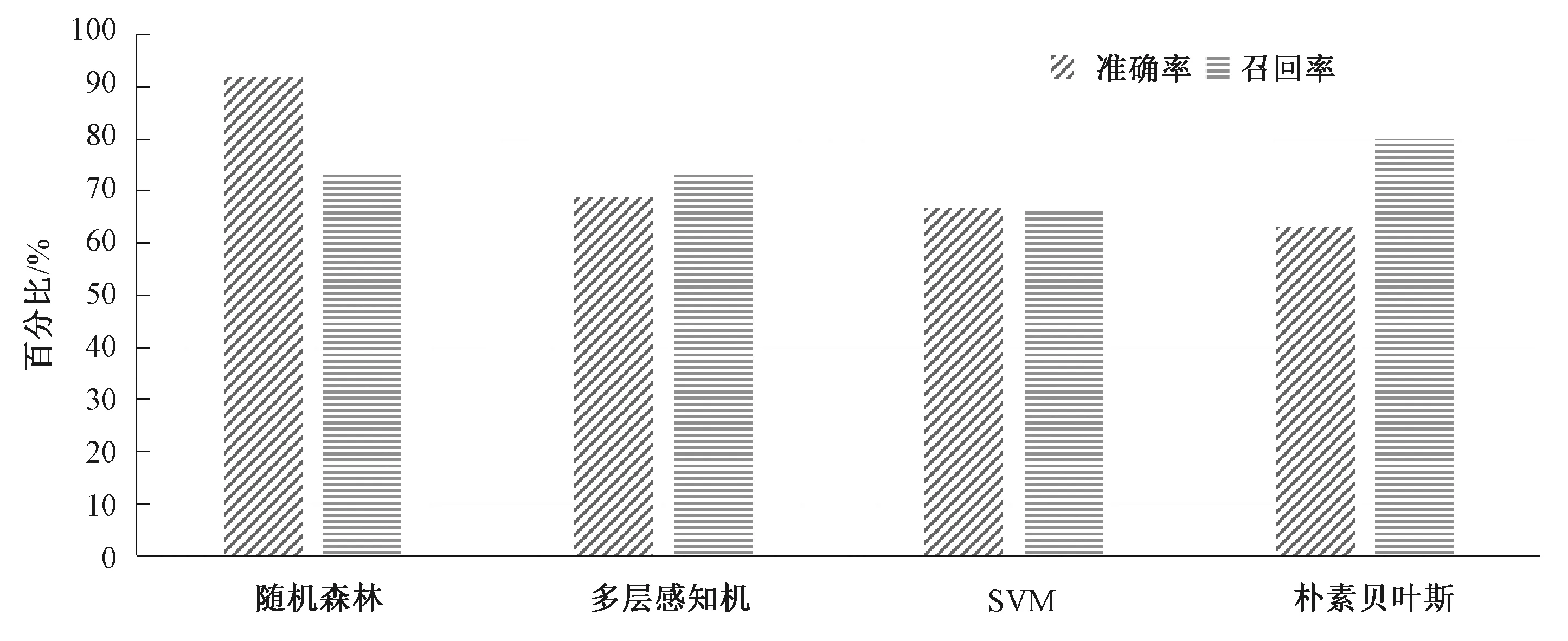
图8 4种算法结果Fig.8 The results of four algorithms
4 人格特质
完整的用户画像应该包含外在和内在属性.我们将识别用户的人格特征来描述他/她的内在属性.基于文献[16],我们开发了一款名为WhatsHabit的应用程序,用于收集应用程序的使用情况、电池、耳机、移动模式、网络和屏幕状态数据.我们收集了大约两周的应用程序使用情况.
4.1 特征提取
我们分别选择1、6、12、18、24小时为时间窗口采集数据.
应用程序使用中的特征提取:由于有些APP对应的数据比较稀疏.也就是说,有一些APP可能仅被一位用户使用过一次,所以我们按照Google Store将用户APP进行分类,并剔除一些系统自带的应用程序,最后将32位用户的所有应用分成28类.同时,我们从7个大方面展开,提取相应的特征.分别是每个类别的应用程序使用的次数、每类应用程序安装的个数以及每个类别的使用时间.
电池电量:对于电池电量,大约每五分钟完成一次扫描.因为每位用户采集了两周的数据,因此我们记录电量的消耗情况、充电次数以及在每个时间窗口内用户最常用的充电方式.
是否插入耳机:考虑到不同人格特征的用户在使用手机时会有不同的偏好,因此采集手机中耳机状态变化时间及变化情况,进而计算用户连接或不连接耳机的次数,以及耳机最常用的连接状态.
情景模式:情景模式一般包含标准模式、静音模式和振动模式.统计用户最常使用的情景模式以及在一个时间窗口内,切换情景模式的次数.
联网情况:记录了手机的联网方式,包含最常见的5类,即Wi-Fi、4G、3G、2G和没有联网.统计连接不同网络的次数,并计算其均值,并记录用户在不同时间窗口下最常使用的联网方式.
屏幕状态:考虑到由于人格特征不同,每个用户每天花在手机上的时间可能存在差异.我们统计用户开关屏的次数;并计算人格特征与使用手机时长的关系.
4.2 个性特征识别
用户人格识别可以分为两个方面:基于问卷结果的用户自我评估和基于手机使用的人格识别.
基于问卷结果的用户自我评估.用户需要填写“大五人格”问卷,其中包含60道题,每一个问题我们根据实验人员的选项给其计分,其中包括正向计分和负向计分两种.最后我们将用户在5个分量表上获得的积分视为他们各自的大五人格特征.
基于手机使用的人格识别.我们收集了大约两周的数据.然后,我们从这些数据中提取出有效特征,并将各个特征与用户关联,最终构建一个用户与使用手机习惯的特征矩阵.
我们利用实验人员使用习惯特征矩阵与大五人格矩阵构建5个回归模型,分别得到手机使用习惯与大五人格之间的回归方程.为了防止过拟合,我们采取十折交叉验证法检验系统的准确率.
4.3 实验结果
4.3.1实验设置 在实验中,招募了32名大学生,共16名男生和16名女生作为志愿者.我们采集了两周的用户手机使用信息.总共采集7类特征,最终采集了78.9 MB数据.
4.3.2功能评估 在实验中,首先评估特征对人格特征识别的有效性.我们使用Pearson相关分析来评估.模型会受到异常值的影响,通过经验去除相关性小于0.3的32名志愿者大五人格的问卷结果显示如表1.
1) 开放性:开放性较高的用户更愿意使用AC充电(r=0.337,p=0.030).高度开放性的人不经常打开文件管理(r=-0.458,p=0.004).高度开放的用户倾向于在音乐和音频应用程序上花费更多时间(r=0.404,p=0.011).同时,他们将安装较少的安全类应用程序(r=-0.377,p=0.017).

表1 大五人格统计结果Tab.1 The Result of Big Five Personality
2) 尽责性:尽责性与手机充电次数呈正相关(r=0.400,p=0.012),与用户点亮屏幕的次数呈负相关(r=-0.436,p=0.006).责任心与通信应用的数量呈负相关(r=-0.421,p=0.008)和社交应用(r=-0.376,p=0.017)也是负相关,会在旅行应用(r=0.398,p=0.012)上花更多时间.
3) 外倾性:外倾性的用户倾向少用耳机(r=-0.504,p=0.002),耳机连接时间也更短(r=-0.359,p=0.022).用户解锁屏幕的次数也与外倾性呈负相关(r=-0.384,p=0.015).外倾性用户更倾向于使用体育应用(r=0.457,p=0.004).书籍应用内向用户会更喜欢(r=-0.443,p=0.006).
4) 宜人性:宜人性用户可能会经常使用耳机(r=-0.365,p=0.020).高度友善的用户会使用更多的通信软件(r=0.319,p=0.038).宜人性得分越高的用户越喜欢使用教育软件.宜人性与游戏应用程序之间存在正相关关系(r=0.405,p=0.011).
5) 神经质:神经质与通信软件的数量呈负相关(r=-0.310,p=0.042).高神经质用户使用手机倾向振动模式(r=-0.371,p=0.018),更多的耳机连接(r=0.303,p=0.046),更多的新闻杂志应用(r=0.350,p=0.025).用户打开音乐应用的次数与神经质呈正相关(r=0.346,p=0.026).
4.3.3人格特征识别评估 同时,为了评估回归模型的拟合优度,我们使用确定系数(R2)作为评估标准,R2表示回归直线对观测值的拟合程度.
我们使用十倍交叉验证来确定与大五人格对应的5个回归方程的参数和权重.对于开放性、尽责性、外倾性、宜人性和神经质,我们使用SVR回归模型来计算均方根误差,并且该值分别为0.290、0.351、0.465、0.302、0.452.表明预测值和真实值之间的误差分别为±0.29、±0.35、±0.47、±0.30、±0.45,r分别为0.81、0.05、0.62、0.57、0.62,p≤0.05.
5 总结
在本文中,我们基于手机感知数据从年龄,性别和人格特征描述用户.年龄预测和性别分类主要利用手机中的加速度、磁力计和陀螺仪传感器.在人格特征方面,我们收集应用使用情况、电池、耳机、情景模式、网络和屏幕状态数据.然后,使用随机森林回归模型预测年龄,随机森林分类模型识别性别,并利用SVR来识别人格特征.
我们通过35、30和32个手机用户分别进行的实验来评估系统.实验结果表明,我们的方法在预测年龄方面达到了4.370的均方根误差,在性别分类方面达到了91.70%的精确度.大五人格的均方根误差分别为0.29、0.35、0.47、0.30、0.45.
猜你喜欢
钢管(2022年2期)2022-11-28
小猕猴智力画刊(2022年9期)2022-11-04
湘潮(上半月)(2021年10期)2021-12-02
奥秘(2021年1期)2021-03-15
学生天地(2020年15期)2020-08-25
电子制作(2019年10期)2019-06-17
意林(绘英语)(2018年1期)2018-04-28
小学生作文选刊·低年级版(2017年2期)2017-03-06
小学生导刊(低年级)(2016年8期)2016-09-24
汽车与新动力(2015年1期)2015-02-27
