
基于深度学习的Tor流量识别方法*
2019-12-11 02:23潘逸涵张爱新
通信技术 2019年12期
潘逸涵,张爱新
(上海交通大学 电子信息与电气工程学院,上海 200240)
0 引 言
随着网络技术的发展,网络的组成已经越来越复杂,如何从大量的网络流量中得到更有价值的信息成为了众多学者的研究目标。而网络流量的分类,尤其是针对暗网流量的识别对网络监管与维护网络安全有着重要的意义。
洋葱路由(The Onion Router,Tor)是由美国海军计算机系统安全研究实验室提出的一套路由机制。它的主要思想是在网络中随机挑选若干个洋葱路由器作为中间节点,并对洋葱包所经过的节点进行层层加密封装,中间的洋葱路由器对收到的洋葱包进行解密运算,得出下一跳的路由器地址,然后在包尾填充任意字符,使得包的大小不变,并把新的洋葱包根据所指示的地址传递给下一个洋葱路由器。由于中间的洋葱路由器只知道上一跳和下一跳的信息,不知道整条通信链路,因此在公网上实现了隐藏网络结构和通信双方地址等关键信息,同时还可以有效地防止攻击者在网上进行流量分析和窃听。鉴于Tor的匿名性,很多不法分子利用Tor进行黑客攻击或者非法交易,给互联网安全带来了巨大的威胁。因此Tor流量的识别是网络恶意行为检测中关键的技术。
1 相关研究
目前为止,国内外学者从不同角度对网络流量分类方法进行了研究,大致可以分为四大类:基于端口号匹配的分类方法、基于特征字段分析的分类方法、基于传输层行为模式的分类方法和基于流统计特征的分类方法。由于Tor网络的特殊运作机制,前两种方法无法有效应用于Tor流量的识别;后两种方法是传统的机器学习方法,目前已有学者对此进行了相应的研究。例如,Lashkari等人提出了中从不同的时间间隔角度对Tor流量进行特征提取[1],并通过采用多种不同的机器学习方法来比较分类的正确率。Cuzzocrea等人在文献[2]中提取了tcp数据流23个特征,例如数据包的平均到达时间、每秒的字节数、流的持续时间等,并通过k折交叉验证的方法来进行训练和验证。训练同样是采用各种典型的机器学习算法,并对各种算法进行了分析和比较。何高峰等人提出了基于TLS指纹和基于报文长度分布的Tor流量分类方法[3],其主要思想是由于Tor连接采用了TLS加密传输,可以先对TLS流量进行识别,随后利用Meek在TLS握手建立过程中的指纹特征,即密码套件、证书时间以及颁发机构名称和拥有者名称等特征对识别的TLS流量进行二次识别,最后利用Meek的Polling机制的动态时间特性进行最后的识别。此外,Tor流量在长度分布上会表现出几种典型长度大量出现的特征,因此也可以将报文长度分布作为特征,并利用支持向量机来进行分类。李响等人根据基于Meek的Tor流量特征,提出了Meek数据流的分片模型,再结合支持向量机技术,提出了基于SVM的Tor匿名通信识别方法[4]。
但是,上述研究方案都是采用传统机器学习方法来进行分类,而传统机器学习方法在具体应用时需要根据不同的网络选择不同的特征,同时提取合适的特征又是繁琐的过程,这在很大程度上限制了它的应用性能。
深度学习是机器学习研究中的一个新的领域,其概念最早由Hinton等人提出,它的实质是通过构建具有很多隐层的机器学习模型和海量的训练数据,来自动学习更有用的特征,从而最终提升分类或预测的准确性。1994年Lecun等人提出了第一个卷积神经网络(Convolutional Neural Network,CNN)LeNet-5[5],并在手写数字识别上取得成功。之后随着深度学习理论的完善,CNN开始快速发展。2012年,Krizhevsky等人提出的AlexNet[6]网络模型结构赢得了当年的ImageNet竞赛的冠军,之后各类CNN多次成为ImageNet竞赛的优胜算法,包括2013年的ZFNet、2014年的 VGGNet、GoogLeNet和 2015年的ResNet,使得CNN成为图像分类上的核心算法。
循环神经网络(Recurrent Neural Network,RNN)是根据“人的知识是基于过往经验和记忆”提出的,它的当前输出与前面的输出也有关。1989年,Williams和Zipser提出了循环神经网络的实时循环学习[7]。随后Werbos在1990年提出了循环神经网络的随时间反向传播[8]。1991年,Hochreiter发现了循环神经网络的长期依赖问题,为解决这一问题,大量优化理论得到引入并衍生出许多改进算法,如长短期记忆网络[9](Long Short-Term Memory,LSTM)。近年来,随着数值计算能力的提升,拥有复杂结构的RNN开始在自然语言处理问题中展现出优质。例如,Cho等人提出的RNN编码模型[10]可以用来进行机器翻译和比较不同语言的短语和词组间的语义近似程度,Zhang等人提出的高速路长短期记忆RNN[11]能够对远程语音进行识别。
经文献检索发现,深度学习在网络流量识别领域也已取得较为显著的效果。如Wang和Zhou等人分别在文献[12]和文献[13]中指出可以将网络流量转化为灰度图像的形式,再利用CNN进行训练学习与分类识别。Lin等人提出可以将流量特征向量转化为特征矩阵,进而形成CNN的输入图像[14]。Yu等人将HTTP流量构建为自然语言序列,提出了一种基于双向LSTM检测异常HTTP流量的方法[15]。
综上所述,深度学习在流量识别领域已取得的成果为本文的研究打下了基础。考虑到深度学习在图像分类问题中有着更优秀的表现,而且CNN中卷积层的卷积操作能够对输入图像的局部特征进行提取,解决了人工提取特征的问题,本文提出了基于CNN的Tor流量识别方法。为了证明该方法的可行性,本文使用tor流量和常规流量进行实验,最终平均正确率为97.55%,满足了实际应用的需求。
2 基于CNN的Tor流量识别方法
本节将详细介绍本文提出的基于CNN的Tor流量识别方法,包括采用的CNN训练模型、网络流量数据的处理方式以及实验设置。
2.1 卷积神经网络CNN
卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络。它的结构通常由输入层、卷积层、池化层、全连接层和输出层组成。
2.1.1 输入层
输入层用于数据的输入,它将图像数据转化成像素矩阵,同时可以做一些预处理操作。常见的两种图像预处理方式是去均值和归一化。
2.1.2 卷积层
卷积层的主要工作是卷积核与图像做卷积运算,得到新的特征面。计算方法就是将卷积核按一定步长扫描图像,每扫描一次将其内所有对应元素做乘加运算,完整扫描后得到新的特征面。通常,卷积层可能有多个卷积核,每个卷积核需要分别做卷积运算生成新的特征面。由于卷积运算仍是一种线性运算,需要使用激励函数对卷积结果进行一个非线性映射,常用的激活函数有sigmoid、tanh和ReLU函数。
2.1.3 池化层
池化层的位置一般位于连续的卷积层中间,对输入的特征面进行压缩,一方面使特征面变小,简化网络的计算,另一方面进行特征压缩,提取主要特征。池化层一般有两种计算方式,一种是最大池化,取窗口内的最大值;另一种是平均池化,取窗口内的平均值。
2.1.4 全连接层和输出层
全连接层通常在卷积神经网络的尾部,它连接所有的特征,将输出值送给分类器;输出层负责最后目标结果的输出。
2.2 改进的CNN结构
LeNet-5是CNN中最有代表性的网络之一,最早被应用于手写数字的识别,并取得了相当好的效果。本文所采用的训练模型主要基于传统的LeNet-5结构,并在LeNet-5的基础上进行了下列改进:
(1)调整了LeNet-5的输入大小,使其适用于Tor流量的识别。
(2)由于本文的研究目的是区分Tor流量和常规流量。因此将LeNet-5模型的输出由10个神经元改为2个神经元,代表是否为Tor流量。
(3)根据网络流量数据的特点,设计了几种不同结构的卷积神经网络,如表1所示。
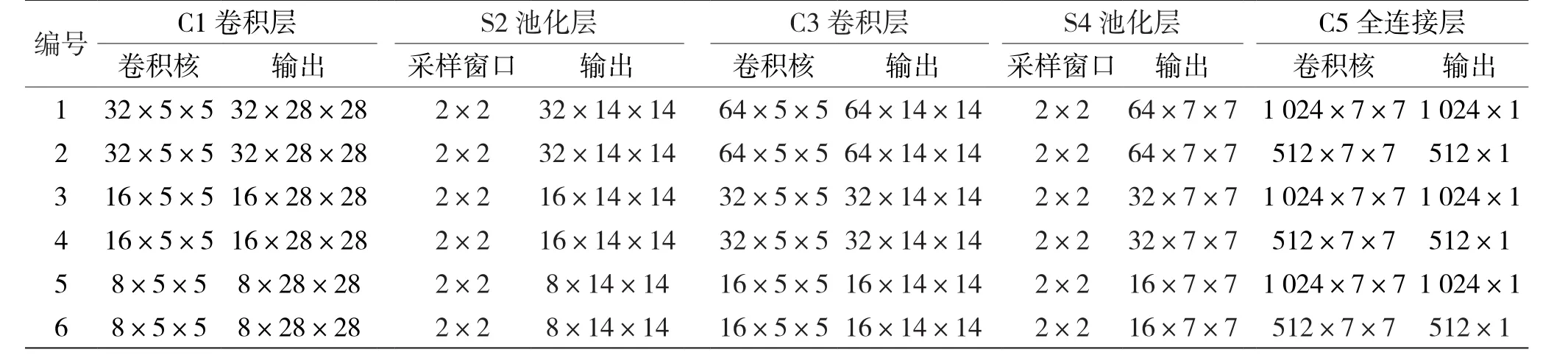
表1 不同结构的卷积神经网络
2.3 网络流量数据处理
为了使用CNN对流量数据进行训练和分类,需要对原始流量数据进行预处理,具体预处理的方法如下。
(1)对数据包进行解析,提取出数据包的五元组:源ip地址、源端口、目的ip地址、目的端口、传输层协议。具有相同五元组的数据包通过时间排序形成了一个流,而一个会话包含了双向的流,即源ip地址/端口和目的ip地址/端口是可互换的。因此可以根据五元组将原始流量数据划分为会话。
(2)为了避免ip地址和mac地址对分类产生影响,在上一步得到的每个会话中,随机生成两个新的ip地址和两个mac地址,将双方的ip地址和mac地址分别用新生成的随机地址来代替。
(3)由于不同会话之间的长度差异较大,为了便于训练和分类,需要对会话长度进行统一。本文截取了每个会话的前784 Bytes,如果不足784 Bytes,则在末尾补0至长度为784 Bytes。这样选取的主要依据是会话的前部分通常为连接数据和部分内容数据,一方面这些数据最能体现会话的内在特征,另一方面Tor建立连接的过程与普通的TCP连接具有很大的差异,因此最能够区分Tor流量和常规流量。
(4)根据会话中每一个字节对应的十进制值,将其转化为灰度为0~255的像素点,进而每个会话就转化为一幅28×28的灰度图像,如图1所示。

图1 会话流量对应的灰度图像
2.4 实验设置
为了验证本文算法的可行性,本文在表2所示的实验环境下进行实验。

表2 实验环境配置
实验样本使用了网上公开的ISCX数据集,其中包含了Tor流量和常规流量,它们由wireshark和tcpdump捕捉,总共大小为22 GB。数据集的设计者捕获了工作站和网关传出的流量,收集了一组pcap文件:一个常规流量pcap和一个Tor流量pcap文件。
对于Tor流量和常规流量,捕获的流量可以分为以下7大类:
(1)网页浏览:访问各类网页;
(2)邮件:SMPTS、POP3S以及IMAPS协议;
(3)聊天:ICQ、AIM、Skype、Facebook和Hangouts;
(4)视频播放:Vimeo和Youtube;
(5)文件传输:Skype、FTP等;
(6)网络电话:Facebook、Skype以及Hangouts语音通话、
(7)P2P:uTorrent和Bittorrent传输。
3 实验测试与结果分析
实验结果的评价指标采用准确率A、精确率P和召回率R,其中:

首先,将所设计的6种不同结构的卷积神经网络进行性能对比,即分别用它们对预处理后的ISCX数据集进行训练和测试,在测试集上的正确率如表3所示。

表3 不同CNN结构的分类准确率
根据测试结果,本文采用正确率最高的第1种卷积神经网络,其具体结构如图2所示。
为了进一步验证该方案在实际应用中的可行性,本文通过抓包分别获取了一部分Tor流量与常规流量,随后对采集到的流量进行相同的预处理操作。最后将生成的图像作为输入,输入到所设计的卷积神经网络进行识别,结果如表4所示。
为了比较卷积神经网络与传统机器学习算法之间的优劣,本文使用在流量分类领域研究最广、应用最多的支持向量机进行对比实验。实验采用了Cuzzocrea等人提出的方法,提取了tcp数据流的长度和时间等特征,然后利用支持向量机进行训练和识别。实验结果表明支持向量机的分类准确率为97.08%。

表4 实际流量的测试结果
从上述实验结果可以看出,本文提出的将网络流量预处理为灰度图,再利用卷积神经网络对Tor流量进行识别的方法在分类正确率上略优于支持向量机。并且,相比于支持向量机,深度学习省去了复杂的特征提取的过程。因此,无论是在正确率上还是在算法设计的复杂度上,本文提出的基于深度学习的Tor流量识别方法都更加优于支持向量机。
4 结 语
本文提出了一种基于深度学习的Tor流量识别方法。该方法首先对流量据集进行预处理,生成灰度图像,随后选取合适的卷积神经网络模型进行训练。为了验证方法的可行性,本文通过抓包采集了一组实际应用中的流量,并利用卷积神经网络进行识别,最终的识别正确率为97.55%,比支持向量机高了0.47%。后续研究将重点考虑Tor流量的多分类问题,即针对不同应用的Tor流量,如网页流量、视频播放、文件传输等,研究一种有效的多分类方法。
猜你喜欢
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22
舰船科学技术(2022年10期)2022-06-17
医学食疗与健康(2022年3期)2022-04-23
北京航空航天大学学报(2021年9期)2021-11-02
中华养生保健(2020年7期)2020-11-16
电子制作(2019年13期)2020-01-14
微型电脑应用(2019年8期)2019-08-22
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
北京航空航天大学学报(2017年7期)2017-11-24
