
公交网络下的一种费用限制最小时态路径查询索引∗
2019-12-11 04:27:24梁瑞仕
软件学报 2019年11期
马 慧 , 汤 庸 , 梁瑞仕
1(电子科技大学 中山学院 计算机学院,广东 中山 528400)
2(华南师范大学 计算机学院,广东 广州 510631)
公共交通网络下的路径查询是地图服务的一个重要应用.私人交通网络下的路径查询通常用路径长度、行驶时间、费用等某方面的因素来衡量一条路径的长度;而公交网络查询需要考虑交通工具换乘的问题,因此需要考虑路径上的相邻边之间的时间顺序.此外,费用也是公交网络路径查询所要考虑的重要因素.例如,从广州直飞到洛杉矶虽然耗时短但价格昂贵,用户更想找到一条便宜的、可中途换乘的、旅途时间稍长的路线.本文研究这样的问题:一个旅行者计划乘坐公共交通工具出行,他的预算有限,他想知道在不超过预算的前提下:(1)他计划在t时刻或之后出发,最早什么时候能到达?(2)他计划在t′时刻或之前到达,最晚需要什么时候出发?(3)他可以在t时刻或之后出发,希望在t′时刻或之前到达,想找一条旅途时间最短的路径.上述3 种查询分别称为带费用限制的最早到达路径查询、最晚出发路径查询和最短耗时路经查询.3 种查询的共同点是在费用限制的前提下查找最快的路径,因此下文统称为带费用限制的最小时态路径查询.
与本文工作最相关的是文献[1].Biswas 等人提出了在时间信息图下求解带费用限制的最短路径问题.他们假设图中的每条边附有出发时刻、到达时刻、长度和费用值,求解不超过费用上限的、路径上相邻的边满足时间顺序的、长度最短的路径.文献[1]提出的两种查询算法的时间复杂度分别是O(|E|⋅log|E|+|E|⋅Δmax⋅Lopt)和O(|E|⋅P⋅(tβ-tα)),其中,|E|表示图的边数,Δmax表示顶点的最大度数,Lopt表示最短路径的长度,P表示费用上限,tα和tβ分别表示查询时间区间的下界和上界.第1 种算法的时间复杂度依赖于图的规模,不适合大规模图的实时查询;第2 种算法的时间复杂度依赖于路径长度、费用上限、查询时间区间等数值,当数值较大时,显然查询速度变慢.此外,文献[1]的实验中采用通过一条边的时间作为边的长度,查找不超过费用限制的最短路径返回旅途中乘坐交通工具所花的总时间,而等待交通工具的时间并未计入,这在路径规划中是不合理的.Yang 等人用分段函数表示通过一条边的费用依赖于出发时刻变化[2],在这种连续时间模型上,提出了一种给定查询时间区间的最小费用路径查询方法Tow-Step;在文献[3]中,Yang 等人还进一步假设通过每条边的时间也依赖于出发时刻变化,提出了Tow-Step 的改进算法.Tow-Step 算法允许路径在某个顶点上等待至恰当的时刻才继续前行,以达到路径费用最小.这种模型更适用在私人交通网络,因为公共交通运行有固定的时间表,不能在某个地方等待任意的时间.此外,Two-Step 算法也是基于原图上做查询,时间复杂度是O(k⋅|V|⋅log|V|+|E|⋅k2⋅logk),其中,|V|表示顶点数,|E|表示边数,k表示边上时间分区的段数.同样地,该算法复杂度过高,不适用于大规模图的实时查询.Li 等人认为公交网络中容易受堵车等不确定因素影响,所以用随机网络刻画道路网络:每条边的通行时间是基于一组随机时间点的随机变量[4],并针对此模型提出一种拉格朗日松弛算法求解.何胜学等人提出了一种考虑公交线路票价变化、并以总行程时间最短与换乘次数最少相结合的计算模型与寻路算法[5];魏金丽等人就公交车“限时免费换乘”的模型,寻找限定时间最短时间与超时条件最低费用的路径[6].上述方法都是在原图上做查询,不适用于大图的实时查询.
另外,有更多工作研究非时间信息图上的带费用限制的最短路径查询.这些研究假设图中的每条边带有长度和费用两个值,求解不超过费用上限的长度最短的路径.由于这种查询需要枚举从起点到终点的所有路径,因此是一个NP 难的问题[7].CSP-CH[8]借鉴路网中求最短路径的高效算法Contraction Hierarchy[9]的思路建立索引.尽管查询得到加速,但是在预处理阶段添加的边太多,导致索引太大.Lozano 等人提出了一种在大规模图上求解的方法[10].Ma 提出一种快速的基于A*标签的算法求解受资源限制路径的问题[11].此外,为了快速求解,学者提出了求近似解的方法[12-14].Tsaggouris 等人提出的方法保证近似解的路径长度在最优解的路径长度的α倍范围内[12],其中,α是一个大于1 的预定义参数.Wang 等人在文献[13]的基础上提出了更高效的α-dijk 算法求解近似解,并借鉴了路网下查找最短路径的高效索引Hub Labelling[15]的思想设计了索引COLA[14],极大地提高了查询速度,可应用在真实的大规模路网的实时查询.
此外,关于时间信息图上的最小路径查询已经有了很多的研究工作.Cooke 等人最早提出最早到达路径、最晚出发路径和最短耗时路径这3 种查询[16].随着大规模图的出现,有学者提出事先在图上建索引的方法加速查询.Geisberger 提出的CHT[17]算法与上文提到的CSP-CH 类似,也是采用Contraction Hierarchy[9]的思路建立索引.文献[18-20]对原图的边预先排序,可以在线性时间复杂度内得到查询结果.Wang 等人提出的TTL[21]和Daniel 等人提出的Public Transit Labelling[22]采用Hub Labelling 的思想,预先计算出图中部分最短路径信息,然后通过对部分路径集合的线性扫描得到结果.文献[23,24]对时间信息图下求解最短路径的前沿工作做了深入的研究.上述方法只关注路径的时间信息,没有考虑上费用的限制.
综上所述,带费用限制的最短路径查询和时间信息图下最小时态路径查询这两个问题已经有索引方法提供高效的查询,但是目前,关于带费用限制的最小时态路径查询的研究均是在原图上做搜索,在大规模图上查询效率低下,因此需要仿照图查询的传统做法,预先对图建立索引,再设计相应的查询算法利用索引查询结果.
本文的贡献如下:提出了一种带费用限制最小时态路径近似查询的高效索引(approximate cost constrained time labelling,简称ACCTL).ACCTL 对图中每个顶点预先计算一些从该顶点出发的路径和到达该顶点的路径,使得任意查询可以通过检索ACCTL 中的路径生成解,避免在原图上做查询,从而提高查询效率.实验结果表明,基于ACCTL 的查询比基于Dijkstra 的变种查询算法快2 个~3 个数量级.虽然ACCTL 与COLA[14]和TTL[21]一样,都是采用Hub Labelling 的结构建立索引,但ACCTL 并不是简单地将COLA 和TTL 合并:COLA 中的路径长度是全序关系,而ACCTL 中的时间区间是偏序关系,不能像长度那样可以两两比较出大小;TTL 中任意时刻出发的最快路径只有一条,而ACCTL 中需要考虑上费用,任意时刻出发的最快路径有多条.在下文中,将会说明ACCTL 包含了许多精心设计和优化.
本文第1 节给出问题的描述和相关符号的定义.第2 节给出一种基于Dijkstra 算法的方法,这种方法是构建索引的核心算法.第3 节介绍ACCTL 的设计思路.第4 节介绍ACCTL 的查询算法.第5 节介绍ACCTL 的预处理构建索引算法.第6 节采用交通数据集测试ACCTL 的查询效率、空间大小和建立索引的时间.最后总结全文.
1 问题描述
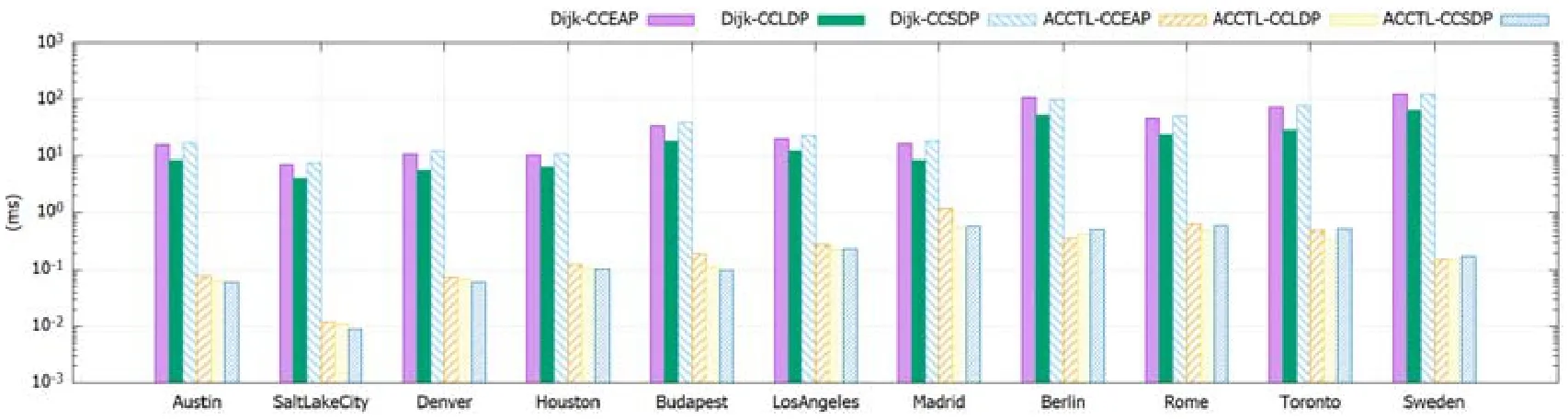
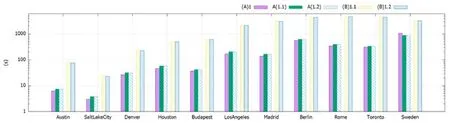
本文沿用文献[1,17,19-22]中的时间信息图来刻画公共交通网络,并给每条边添加一个费用值.设G=(V,E)是一个有向多重图,V是顶点的集合,每个顶点对应公共交通网络中的站点;E是边的集合,边e=〈u,v,td,ta,c〉表示在td时刻从顶点u出发,在ta时刻到达顶点v,所花费用是c.两点之间可以存在多条边.本文假设td,ta和c都是非负整数,这个假设是合理的,因为现实应用中不存在费用为负的开销;此外,总可以找到一个最小单位粒度来度量时间和费用.对于时刻t1和t2,用符号t1≤t2表示t1早于或等于t2,t1≥t2表示t1晚于或等于t2.定义P=〈e1,e2,…,ek〉是一条路径,若对于1≤i 本文研究的带费用限制的最早到达路径、最晚出发路径和最短耗时路径定义如下. 定义1(带费用限制的最早到达路径).给定图G,起点s,终点d,时刻t,费用上限θ,带费用限制的最早到达路径指所有在t时刻或之后从s出发,到达d,费用不超过θ的路径中,具有最早到达时刻的路径. 定义2(带费用限制的最晚出发路径).给定图G,起点s,终点d,时刻t′,费用上限θ,带费用限制的最晚出发路径指所有从s出发,在t′时刻或之前到达d,费用不超过θ的路径中,具有最晚出发时刻的路径. 定义3(带费用限制的最短耗时路径).给定图G,起点s,终点d,时刻t,t′,费用上限θ,带费用限制的最短耗时路径指所有在t时刻或之后从s出发,在t′时刻或之前到达d,费用不超过θ的路径中,具有最短耗时的路径. 约定:若查询Q存在多条路径具有最早的到达时刻(或最晚的出发时刻、或最短的耗时),则返回费用最小的路径作为解.图1 是一个带费用值的时间信息图,不同的线形表示不同的交通工具及班次.边上的数字表示[出发时刻,达时刻]和费用.假设查询从v4到v2的费用上限是30 的最早到达路径,要求出发时刻≥3,则查询应该返回路径〈e2,e3,e4〉.随着图的规模增大,两个顶点之间的路径数目暴涨.本文沿用CSP 问题的做法引入近似因子α来控制近似解与精确解的误差程度. Fig.1 A time information graph with costs图1 一个带费用值的时间信息图 定义4(带费用限制的最早到达路径查询的近似解).给定近似因子α,带费用限制的最早到达路径查询Q返回的近似解P满足:(1)c(P)≤α⋅c(Popt);(2)P的到达时刻≤Popt的到达时刻.其中,Popt是Q的精确解. 定义5(带费用限制的最晚出发路径查询的近似解).给定近似因子α,带费用限制的最晚出发路径查询Q返回的近似解P满足:(1)c(P)≤α⋅c(Popt);(2)P的出发时刻≥Popt的出发时刻.其中,Popt是Q的精确解. 定义6(带费用限制的最短耗时路径查询的近似解).给定近似因子α,带费用限制的最短耗时路径查询Q返回的近似解P满足:(1)c(P)≤α⋅c(Popt);(2)P的耗时≤Popt的耗时.其中,Popt是Q的精确解. α是一个大于等于1 的实数.当α=1 时,查询得出的解即为精确解.假设在图1 中查找从v4到v0的带费用限制的最晚出发路径,t′=10,θ=21 精确解是〈e1,e3〉.若α取1.1,近似解是〈e2,e3〉. 需要说明的是,虽然允许近似解P比它对应的查询Q的精确解Popt的费用稍大,但并不等同于任意在ACCTL 上的查询返回的P的费用总超过θ.实际上,ACCTL 的设计保证了:当θ≥α⋅c(Popt)时,ACCTL 查询返回的解P即为精确解;当θ<α⋅c(Popt),即最优路径的费用几乎达到费用上限时,可能返回精确解,也可能返回近似解.若返回的P是近似解,α限定了P的超支范围,同时,作为超支的补偿,P比Popt有更早的到达时刻或更晚的出发时刻或更短的耗时.换句话说,仅在最优解的费用几乎达到费用上限时,ACCTL 有可能返回费用稍微超支,但时间更优的近似解;其他情况下,ACCTL 返回精确解.下文将在第5.2 节的定理3 中给出证明. 表1 给出了全文常用的符号及含义. Table 1 Table of notations表1 符号表 本节给出一种基于Dijkstra 算法的Dijk-CCMTP(Dijkstra-cost constrained minimal temporal path)算法,出于两点目的:首先,Dijk-CCMTP 是构建ACCTL 索引的核心算法;其次,3 种查询可以通过调用Dijk-CCMTP 的变种算法求得解,将作为实验中的对比算法.Dijk-CCMTP 与文献[1]中的算法相似,但由于本文所求解的问题和文献[1]不一样,所以两者的算法在细节上有差别.Dijk-CCMTP 按照费用值从小到大的顺序枚举不超过费用上限的路径,从中选择一条时间上最优的路径作为解;而文献[1]的算法选择长度最短的路径作为解.下文中首先给出Dijk-CCMTP 算法的细节,再讨论如何用Dijk-CCMTP 进行精确查询. 求解带费用限制的最小时态路径需要用到的一个关键概念叫做路径支配. 定义7(路径支配).设P1和P2是两条连接相同起点和终点的路径,称P1支配P2,或P2被P1支配,如果满足以下3 个条件:(1)c(P1)≤c(P2);(2)P1的出发时刻≥P2的出发时刻;(3)P1的到达时刻≤P2的到达时刻. 若P1支配P2,则表明P1在费用和时间方面均不比P2的差.若路径P不被其他路径支配,则称P是非支配路径(若两条路径的起点、终点、出发时刻、到达时刻和费用均相等,则任选一条作为非支配路径). 引理1.设P是查询Q的解,Psub是P上的一段子路.如果存在路径支配Psub,则用代替Psub所得到的路径也是Q的解. 算法1 描述了Dijk-CCMTP 算法的伪代码,求解在t时刻从s出发,费用不超过θ,到达d的最早到达时刻.算法从s开始,按路径的费用值升序,费用值相等的按到达时刻升序的顺序扩展路径.这种顺序可以在搜索的早期找到费用值小的、到达时刻早的路径,有助于利用引理1 剪枝掉被支配的路径.算法维护一个最小堆H记录当前所找到的路径.每条路径用元组表示,指路径在t时刻从s出发,在时刻到达u,费用是c*.Dijk-CCMTP 循环地从H中取出路径扩展出新路径,直到H为空. 算法1.Dijk-CCMTP 算法. 算法维护两个映射,帮助剪枝掉一些不可能生成解的路径.映射T(u)记录了当前发现的到达u的最早到达时刻.在第8 行,如果,则ρ可以被剪枝掉,这是因为:(1)说明在ρ之前存在路径ρ′出堆,ρ′的到达时刻更新了T(u)(第9 行),而由于路径按费用的升序出堆,ρ′的费用小于等于ρ的费用;(2)ρ和ρ′有相同的起点s和出发时刻t.因此,ρ′支配ρ,ρ可以被剪枝掉.另一个映射是C(e),记录最后一条边是e的路径的最小费用值.如果ρnew的费用大于等于C(e),表明已存在路径ρ′,ρ′和ρnew有相同的起点和终点,且出发时刻与到达时刻也相同,但费用小于等于ρnew的,因此ρ′支配ρnew,则ρnew可以被剪枝掉(第13 行). 除了上述两个映射以外,还利用费用值下限进行剪枝.第13 行的c⊥(w,d)表示点w到d的费用下限.可以从d出发调用一次逆向的Dijkstra 算法,扩展路径时不考虑边与边之间的时间顺序约束,计算出图中其他顶点到达d的费用下限.如果ρnew的费用(c*+c加上ρnew的终点w到达d的费用的下限已超过θ,则ρnew不可能生成解,不需要加进H. 引理2.H最多包含|E|条路径,其中,|E|表示图的边数. 证明:只需证明加进H的路径的最后一条边各不相同.因为H中的路径是按照费用值升序的顺序出堆的,因此在所有的最后一条边是e的路径中,最早被发现的路径具有最小费用,加进H;之后被发现的路径受第13 行的条件c*+c≥C(e)的约束,不会加进H.因此H的路径总数不超过|E|.□ 算法中采用费用值而不是布尔类型变量记录映射C(e),是为了优化带费用限制的最短耗时路径查询,将在第2.2 节中加以说明. 引理3.算法Dijk-CCMTP 的时间复杂度是O(|E|⋅(log|E|+Δmax)),其中,|E|表示图的边数,Δmax表示顶点的最大出度. 证明:H用二项堆实现,第6 行ρ出堆的复杂度是O(log|E|).第10 行枚举点的出边,最多循环Δmax次,因此,H中处理每条路径的时间复杂度是O(log|E|+Δmax).H最多包含|E|条路径,因此时间复杂度是O(|E|⋅(log|E|+Δmax)).□ 本节首先讨论如何调用Dijk-CCMTP 查询带费用限制的最早到达路径.考虑一个从s到d的、出发时刻≥t、费用不超过θ的查询.可以将Dijk-CCMTP 算法的第4 行的条件“出发时刻为t”改成“出发时刻≥t”.由引理1 可以证明,这个改动仍然能够保证算法的正确性. 带费用限制的最晚出发路径查询与带费用限制的最早到达路径查询是对称的.带费用限制的最晚出发路径查询从终点d出发做反向搜索扩展回起点,即扩展路径时访问顶点关联的入边.在最小堆H中,费用小的路径优先出堆;费用相等的路径出发时刻晚的优先出堆. 带费用限制的最短耗时路径查询并不能调用一次Dijk-CCMTP求解,这是因为路径的耗时与路径的出发时刻、到达时刻均有关系,因此需要枚举s的不同的出发时刻,多次调用Dijk-CCMTP 求解.留意到路径P只可能被比出发时刻不早于它的路径所支配,所以可以按出发时刻从晚到早的顺序调用Dijk-CCMTP.每次调用Dijk-CCMTP 时重用前一轮调用Dijk-CCMTP 时设置的C(e)值,即调用了Dijk-CCMTP 求解在t1时刻出发的路径以后,下一轮求在t2时刻(t2 定理1.Dijk-CCMTP 的变种算法查询带费用限制的最早到达路径和带费用限制的最晚出发路径的时间复杂度是O(|E|⋅(log|E|+Δmax)),查询带费用限制的最短耗时路径的时间复杂度是O(Δmax⋅|E|⋅(log|E|+Δmax)),其中,|E|表示图的边数,Δmax表示顶点的最大度数. 定理1 可以由引理1 和引理3 推导证明. 本节介绍索引ACCTL 的设计思想.ACCTL 的构建基于一个顶点的全序关系,全序关系用来衡量顶点在图中的重要程度.在公共交通网络中,一些交通枢纽很重要,因为相距较远的两个地方通常在交通枢纽换乘.表现在图中,一个顶点所在的带费用限制的最小时态路径越多,它就越重要,称它等级越高.本文用o(v)表示将顶点按重要程度从高到低排序后,顶点v在序列中的位置.若o(v) 设P是一条从点s到点d的路径,v⊤是P上的顶点中等级最高的点.v⊤在P中所处的位置有3 种可能:(1)v⊤=s;(2)v⊤=d;(3)v⊤≠s且v⊤≠d.设P上从s到v⊤的子路记为P+,从v⊤到d的子路记为P-.情况(1)和情况(2)可视为情况(3)的特例,即P+或P-为空.如果预先计算出一些从s到比s高级的顶点的路径(这些路径的集合记为S+)和一些从比d高级的顶点到d的路径(这些路径的集合记为S-),那么对于一个从s到d的查询,可以从S+中查找P+、从S-中查找P-,使得P+和P-能够连接成一条路径生成解.这种查找方法类似于数据库的表连接操作.如果设一张数据库表T记录任意查询Q的解,ACCTL 的作用就是把T分解成两张表T1和T2,使得T中的记录可以通过T1和T2连接操作生成.于是,ACCTL 避免在原图G上遍历,从而减少搜索量.由引理1,任何查询的解均可以由两条非支配路径生成,因此ACCTL 只需要保存一些基本路径即可. 定义8(基本路径).P是一条基本路径,如果P满足以下两个条件: (1)等级约束:P上的顶点中,起点或终点的等级最高; (2)支配约束:P是非支配路径. 假设图1 中的顶点的等级由高到低依次为v0~v5.〈e2,e3〉是一条基本路径;〈e2,e3,e4〉违反了等级约束,不是基本路径. 随着图的规模增大,图中基本路径的数目会暴涨,因此,ACCTL 需要借助近似因子α去掉部分基本路径,允许生成近似解.生成近似解的一个关键概念是路径的α-支配. 定义9(路径的α-支配).设P1和P2是两条连接相同起点和终点的路径,α是近似因子.称P1α-支配P2,或P2被P1α-支配,如果满足:(1)c(P1)≤α⋅c(P2);(2)P1的出发时刻≥P2的出发时刻;(3)P1的到达时刻≤P2的到达时刻. 定义9 与定义7 的区别在于,对路径的费用稍放宽至近似因子α倍范围内.如图1 所示,假设路径P1=〈e1,e3〉,P2=〈e2,e3〉,α取1.1,则P2α-支配P1.结合定义4~定义6 和定义9,可以得到以下引理. 引理4.设P是查询Q的精确解,P′α-支配P,则P′是Q的近似解. 表2 是ACCTL 的雏形.第2 列的每条标签〈u,td,ta,c,lptr〉表示路径在td时刻从v出发,在ta时刻到达u,费用c,lptr指向表示前缀路径的标签(表中每条标签的最后一个分量(lptr)为null 表示该标签对应的路径不存在前缀路径,为*表示前缀路径的标签不在表中),其具体含义将在定义10 中说明.例如,l0=〈v0,2,6,7,null〉表示在2 时刻从v2出发,6 时刻到达v0,费用是7.第3 列的标签表示从u到v的路径.假设查询从v4到v2的费用上限是30 的最早到达路径,要求出发时刻≥3.查询过程将标签l7,l8,…,l11和l2,l3,l4进行匹配.标签la和lb相匹配的意思是:(1)la表示的路径的终点与lb表示的路径的起点相同;(2)lb的出发时刻≥la的到达时刻;(3)la和lb的费用之和不超过费用上限.本例中,查询返回l8和l2匹配的路径,即〈e2,e3,e4〉,在3 时刻出发,14 时刻到达,费用是30. Table 2 Some canoical paths from/to v2~v4against Fig.1 with α=1.1表2 图1 的v2~v4出发/到达的部分基本路径,α=1.1 表2 的标签存在冗余,影响到索引的存储空间大小和查询效率.例如l3和l4均表示从v1到v2的路径,顶点v1只需要保存一份即可,无需在l3和l4中均保存.另外,仅具有共同端点的标签才有可能匹配上.例如查询从v4到v2的路径时,可能与l9匹配的标签只有l3和l4,因为它们的起点v1等于l9的终点.l2的起点与l9的终点不相同,因此查询时无需扫描l2.基于上述考虑,ACCTL 将表示连接相同顶点的路径的标签分成一个标签组.表3 显示了分组的标签,这也是ACCTL 的存储格式. 定义10(ACCTL 索引).给定近似因子α,图G的ACCTL 索引预先对每个顶点v计算两个标签组集合L+(v)和L-(v),满足: (3)对于任意的从顶点s到顶点d的带费用限制的最小时态路径查询Q,设Popt是Q的精确解,则在L+(s)内的某个标签组中,存在标签(下文中,对于标签中暂不需关注的项采用符号⋅表示)的对应路径P+,在L-(d)内的某个标签组中,存在标签的对应路径P-,以下3 种情况之一成立. (3.1)u=d,且P+α-支配Popt; (3.2)v=s,且P-α-支配Popt; (3.3)u=v,,且P+和P-连接起来的路径α-支配Popt. Table 3 L+(v)and L-(v)label sets of v2~v4of ACCTL against Fig.1 with α=1.1表3 图1 的ACCTL 索引中v2~v4的L+(v)和L-(v)集合,α=1.1 下文为了表述清晰,首先在第4 节介绍查询算法,然后在第5 节讨论索引的构建方法,因为索引构建方法比查询方法复杂. 查询从点s到点d的带费用限制的最小时态路径分个两阶段:首先,检索L+(s)和L-(d)得到符合查询要求的标签;然后,将标签还原回一条图G上的路径.下文分别介绍查找标签和还原路径的过程. 本节讨论如何用ACCTL 查询从s到d、出发时刻≥t、费用上限为θ的最早到达路径近似解,另外两种查询可作近似的处理.定义10 的条件(3)大致给出了查询过程.L+(s)和L-(d)内的标签分别记录了路径的前半部分和后半部分的信息,查询过程就是找出L+(s)和L-(d)内的相匹配的标签,生成候选路径,再从候选路径中挑选具有最早到达时刻的路径作为解. 算法2 描述了带费用限制的最早到达路径的查询算法.t⊥表示当前找到的路径的最早到达时刻,在查询过程中,利用t⊥减少不必要的标签匹配.初始时,t⊥=∞.c⊤是一个扩大α倍的上限,允许近似解的费用稍微超过θ.算法第2 行~第5 行处理定义10 中条件(3)的情况(3.1)和情况(3.2). 算法2.EAPQuery. 接下来,算法处理等级最高的点出现在路径内部的情况,对应定义10 中条件(3)的情况(3.3).指针i和j分别指示当前正在扫描L+(s)和L-(d)的第几组标签.算法对L+(s)和L-(d)内的标签组进行线性扫描.假设当前正在扫描L+(s)内的标签组和L-(d)内的标签组.如果o(ui) 当o(ui)=o(uj),即ui=uj时,内的标签有可能与内的标签匹配.留意到内的标签按出发时刻升序排列,所以可调用二分查找快速定位到中的第1 条的标签(第12 行),符合要求的标签必定都排在l+之后.在匹配l+和内的标签时,从内的第1 条标签开始按顺序遍历.记l-为当前扫描的内的标签.当l-的到达时刻≥t⊥时,对的遍历便可终止,因为内的标签按到达时刻升序排列,排在l-之后的标签不可能生成到达时刻早于t⊥的解. 假设在表3 的ACCTL 索引中查找从v4到v2、在3 时刻或之后出发的、费用不超过30 的最早到达路径.初始时t⊥=∞.首先,L+(v4)中没有终点是v2的标签组,L-(v2)中也没有起点是v4的标签组;接着,从L+(v4)的终点为v0的标签组找到第1 条出发时刻≥3 的标签l8=〈3,10,22,l5〉;接着,检查L-(v2)中以v0为起点的第1 条标签l2=〈10,14,8,null〉,于是得到一条由l8和l2拼接的候选路径,更新t⊥=14;接下来扫描L+(v4)的下一个标签组,由于中不存在出发时刻≥3 的标签,所以继续检查下一个标签组.由于L-(v2)不存在以v3为起点的标签组,所以此时L-(v2)的标签组扫描完毕,查询结束,返回l8和l2,表示结果为从3 时刻出发、在14 时刻到达、费用为30 的路径. 算法2 仅获得表示查询的解的标签,需要将标签还原成图G上的一条路径.出于对称性,下文仅讨论如何将还原.假设表示一条从顶点u到d的路径P-.设vpred表示P-上d的直接前驱顶点.由定义10,lptr表示P-上从u到vpred的那一段子路(记为Ppred).于是,可通过还原lptr获得Ppred.假设路径由k条边构成,则还原路径的复杂度是O(k). 本文为了表述清晰,用lptr指代表示路径前缀的标签.在实际编码中,lptr通过记录vpred和pos实现,其中,pos表示Ppred的标签在L-(vpred)中的标签组中的存放位置.需要说明的是,必定包含了lptr.这是因为:(1)Ppred上的顶点中,起点u的等级最高,理由是P-上u的等级最高;(2)下文将在第5.1 节中解释,ACCTL 采用Dijk-CCMTP 算法构造P-,Ppred是非支配路径;并且在第5.2 节中解释lptr会保留在ACCTL 中,不会被删除. 本节解释如何构建ACCTL 索引.ACCTL 的正确性依赖于两点:(1)对于任意查询Q,设精确解是Popt,总可以在ACCTL 找到路径P,使得Pα-支配Popt,由引理4,P是Q的近似解;(2)从ACCTL 中查找到的标签总可以还原成图G上的一条路径.因此,构建ACCTL 的难点在于:(1)如何有效地、不遗漏地计算出所有基本路径?(2)如何尽量多地去掉一些路径,但仍能保证路径被还原?对应地,ACCTL 的构建有两个步骤:一是生成基本路径;二是剪枝掉一些基本路径.下文分别在第5.1 节和第5.2 节解释这两个步骤,在第5.3 节讨论顶点的等级序o的计算. 计算基本路径的一种直观的做法是:枚举符合等级约束的路径,从中选择非支配路径,得到基本路径.初始时,设G0=G,等级最高的顶点记为v0,G0中所有从v0出发和到达v0的路径均满足等级约束.接下来,将v0从G0中删除,生成图G1.在G1中,等级最高的顶点记为v1,从v1出发和到达v1的路径均满足等级约束,….重复上述步骤,即可计算出符合等级约束的路径.算法3 描述了构建索引算法BuildIndex.第3 行~第26 行的for 循环迭代地计算从vi出发的和到达vi的基本路径,并选择部分路径生成标签加进ACCTL 中. 算法3.BuildIndex. 如何从满足等级约束的路径中有效地计算出非支配路径?假设计算从vi出发的基本路径.由于在t时刻出发的路径仅可能被在t′时刻(t′≥t)出发的路径支配,所以按vi的出发时刻降序的顺序调用Dijk-CCMTP(第6 行).第7 行~第17 行的处理与Dijk-CCMTP 类似,但做了以下改动. (1)保存在堆H中的路径ρ=〈u,ta,c,ρpred〉增加一个分量ρpred,表示ρ的前缀路径. (2)对于Gi中的每个顶点u,用一个包B(u)收集从vi到u的非支配路径.ρ从H摘除后(第11 行),仅当ρ不被B(u)中的路径支配时才将ρ加进B(u).回顾H中的路径,按照费用升序出堆;另一方面,第10 行~第17行的while 循环计算的路径有相同的起点(s)和出发时刻(t),可推出路径按到达时刻降序的顺序加入B(u),所以只需要比较ρ和最近一条加入B(u)的路径的到达时刻,即可得出ρ是否被B(u)内的路径支配(第12 行). (3)由于终点d和费用上限θ在构建索引时未知,所以在BuildIndex 中不利用d和θ进行剪枝. 当在t时刻从vi出发的路径遍历完后,对于每个可达顶点u,它的包B(u)包含了到达u的非支配路径.第19行的MarkPrune 算法从B(u)中选择部分路径加入ACCTL,选择细节将在第5.2 节中讨论.MarkPrune 独立地选择B(u)中的路径加进ACCTL,即是说,MarkPrune 在选择B(u)中的路径时并不考虑另一个顶点v的包B(v)内的路径,其后果可能导致还原路径时出错.假设在选择B(u)中的路径时,路径ρ=〈⋅,⋅,⋅,ρpred〉被选中,生成相应的标签l加进ACCTL.为了保证标签l能正确被还原,表示路径ρpred的标签lptr必须在ACCTL 中.然而lptr可能不在ACCTL 中,因为MarkPrune 在选择B(vpred)内的路径(假设vpred是ρ上u的直接前驱顶点)时并没有考虑ρ.因此,在调用完MarkPrune 以后,需要自底向上地检查每条被保留的路径是否可被还原.加进ACCTL 的标签是否可被还原,取决于它对应的路径ρ的前缀路径ρpred是否也生成对应的标签加进ACCTL.对于每条被MarkPrune 算法标记为保留的路径ρ,如果ρpred也被标记成保留,则对ρ的检查结束;否则,将ρpred标记成保留,并追溯ρpred的前缀路径是否标记为保留,直到遇到前缀路径被标记为保留为止.假设Gi中所有顶点u的B(u)集合的路径总数为m,第20 行~第22行自底向上检查的时间复杂度是O(m).由引理2,m不超过|E|.实际上,受出发时刻和路径支配约束,m<<|E|.因此,第20 行~第22 行不会产生太大耗费. 对于每条标记为保留的路径,第23 行、第24 行生成标签l并加进相应的标签组.最后,第26 行调用反向Dijk-CCMTP 算法计算到达vi的基本路径,计算过程与第4 行~第25 行相似. 本节关注算法3 第19 行的MarkPrune 算法如何选择B(u)中的路径加进ACCTL.B(u)包含了在t时刻出发的从vi到u的路径.关键问题是:如何在B(u)中选择尽量少的路径加进ACCTL,同时能够保证对于任意的查询Q,都能在ACCTL 中找到标签生成近似解?换句话说,对于任意路径ρ∈B(u),如果表示ρ的标签没有加进ACCTL,则在ACCTL 中存在另一条标签对应路径ρ′,使得ρ′α-支配ρ.精确计算出保留的路径的最小集合是一个NP-难问题,MarkPrune 采用贪心的策略选择路径,如算法4 所示. 算法4.MarkPrune. 假设加入B(u)的路径的顺序依次是ρ0,ρ1,…,ρk-1.由于路径按费用升序生成,受路径支配的限制,ρ0,ρ1,…,ρk-1自动按到达时刻降序排列.因此,ρi仅可能α-支配比它早加入B(u)的路径ρj(j 回顾在BuildIndex 算法中,从vi出发的路径按出发时刻从晚到早的顺序生成,因此当前内的标签表示的路径的出发时刻均晚于B(u)内的路径,也可能α-支配B(u)内的某些路径.直观来说,如果在内存在某条标签对应的路径ρ′α-支配B(u)内的某条路径ρ,则可以把ρ删除.但这种判断会引起错误.假设α=1.1,B(u)中存在两条路径ρ10和ρ11,费用分别是10 和11,且有ρ11α-支配ρ10.于是保留ρ11,删除ρ10.假设中存在某条标签表示路径ρ12,费用12,且有ρ12α-支配ρ11.如果因为ρ12的存在删除ρ11,则没有路径α-支配ρ10.因此,MarkPrune 采用d(ρ)记录ρ的支配范围,即ρ能够α-支配的费用最小的路径是哪条.中,某条标签表示的路径ρ′能够删除B(u)中的某条路径ρ,仅当ρ′α-支配d(ρ). 定理2.BuildIndex 算法生成的ACCTL 索引是正确的. 证明:假设Popt是一个从顶点s到顶点d的查询Q的精确解,且Popt上任意一段子路都是非支配路径.由引理1,这样的路径Popt是存在的.设v⊤是Popt上等级最高的点,Popt上从s到v⊤的路段记为,从v⊤到d的路段记为.首先证明:在ACCTL 中能找到标签生成路径P,使得Pα-支配Popt.BuildIndex 的第6 行~第17 行枚举了所有从v⊤出发的基本路径,保证生成了;第18 行、第19 行保证ACCTL 存在路径P-,P-α-支配.对称地,ACCTL 也存在路径P+,P+α-支配在费用方面,.在时间方面,P+的到达时刻≤的到达时刻≤的出发时刻≤P-的出发时刻,所以P+与P-能够拼接成路径;同时,P+的出发时刻≥的,P-的到达时刻≤的,所以P+和P-拼接的路径α-支配Popt.最后,第20 行~第22 行保证了每条路径的前缀路径的标签都在ACCTL 中,于是能够将标签正确还原成G上的一条路径.□ 定理3.设查询Q的费用限制是θ,Popt是Q的精确解,且Popt上任意一段子路都是非支配路径.设P是用ACCTL 查询所得解. (1)若α⋅c(Popt)≤θ,则P是精确解; (2)若θ<α⋅c(Popt),则P有可能是精确解,也可能是近似解;若P是近似解,满足: (2.1)c(P)≤α⋅c(Popt); (2.2)P不早于Popt出发且不晚于Popt到达. •用反证法证明:(1)当α⋅c(Popt)≤θ时,P是精确解.因为Popt上任意一段子路都是非支配路径,所以是非支配路径,于是在ACCTL 中存在标签,使得表示的路径α-支配;同理,ACCTL 存在标签,使得表示的路径α-支配.于是,拼接的路径P满足费用限制:.另一方面,由α-支配的定义,P的出发时刻≥的,到达时刻≤的,与Popt是最优解矛盾. •(2)当θ<α⋅c(Popt)时,如果ACCTL 中存在的标签拼接的路径P满足c(P)≤θ,则同情形(1)的证明,P是精确解;若c(P)>θ,则P是近似解,可采用定理2 的证明过程证明情形(2.1)和情形(2.2).□ 定理4.BuildIndex 算法的时间复杂度是O(|V|⋅Δmax⋅|E|⋅(log|E|+Δmax)),其中,|V|表示顶点数,|E|表示边数,Δmax表示顶点的最大度数. 与文献[14,15,21,22]相同,尽管顶点的等级序o的选取不影响查询结果的正确性,但会影响索引所包含的标签数目,进而影响查询效率.要精确计算出o,使得索引所包含的的标签数最少是一个NP-难的问题.因此,本文采用文献[14,21]的方法,对o进行启发式计算.如果顶点v在路径P上,则称v覆盖P.ACCTL 的作用好比把一张记录任意查询Q的解的数据库表T分解成两张表T1和T2,使得T中的记录可以通过T1和T2的连接操作生成.T1好比记录了所有顶点v的L+(v)内的标签,T2记录了L-(v)内的标签.为使T1和T2尽量小,应该使得T1和T2之间能连接上的记录尽量多.这等同于:v覆盖的带费用限制的最小时态路径越多,v的等级就应该越高.由于带费用限制的最小时态路径太多,不可能逐一枚举,所以本文采用这样的方法确定o:从图中随机选取一个顶点集合Vsub⊂V,分别从Vsub的每个顶点v出发扩展路径.留意到路径具有时间和费用两个属性,两个点之间有多条不会被相互支配的路径.本文采用近似的方法将路径的时间和属性量化成一个值:一条路径P的“长度”等于P的费用×β+P的耗时×(1-β),其中,β是一个[0,1)范围内的实数,在从v出发扩展路径之前随机生成.这样,从顶点v出发,采用类Dijkstra 算法搜索全图,可得出v到其他顶点的最短路径,生成一棵以v为根的Dijkstra 树.树上任一顶点u到u的子孙的路径也是最短路径,因此u在图中覆盖的最短路数目等于以u为根的子树包含的顶点数,包括u自身.u在|Vsub|棵树覆盖的最短路径的总数视为u覆盖最短路径数.算法对|Vsub|棵树分别做自底向上的扫描,统计出每个顶点覆盖的最短路径数目,从中选出覆盖最短路径数最多的点v0作为等级最高的顶点;然后,在每棵树中删除以v0为根的子树,再更新各个顶点覆盖的最短路径数,在“剩下的”路径中,选择覆盖数目最大的顶点v1作为等级次高的顶点...依此次类推.若|Vsub|棵树删除完后仍有顶点的o序未确定,则按顶点的度数从大到小排序确定. 实验采用C++语言编写测试代码,测试平台Windows 10,64 位操作系统,机器配置Intel(R)Core(TM)i7-8700K CPU,64GB 内存.实验采用文献[21]提供的数据集做测试.数据采集自GTFS[25],记录了一些地区的公共交通数据.数据集中每条边e只记录了出发时刻和到达时刻,实验给e生成一个费用值.为了模拟真实环境,一条从u到v的边的费用取值图中所有从u到v的边的耗时的平均值.实验数据的特征见表4,|V|表示顶点数,|E|表示边数,Δmax表示顶点最大度数,表示平均顶点度数.下文就ACCTL 索引的查询时间、索引大小和建立索引的时间进行分析. Table 4 Characteristics of datasets表4 数据集特征 查询沿用文献[21]提供的查询集.每个数据集的查询集内有10 万个查询.每个查询包括起点s、终点d、时刻t和t′、费用上限θ.s和d从顶点集中随机产生,t和t′从数据集的时间域随机产生.费用上限θ是在[θmin,θmax]范围内的一个随机数:θmin表示不考虑路径上相邻的边之间的时间顺序,从s到d的最小费用;θmax表示从s到d的某条随机的边出发的最短耗时路径的费用.带费用限制的最早到达路径查询使用s,d,t和θ作为查询参数;带费用限制的最晚出发路径查询使用s,d,t′和θ;带费用限制的最短耗时路径查询使用s,d,t,t′和θ. 实验将ACCTL 与文献[1]提出的一种Dijkstra 变种算法作对比.因为文献[1]解决的问题与本文的有差别(回顾文献[1]求解不超过费用上限的、路径上相邻的边满足时间顺序约束的、长度最短的路径),因此将文献[1]的Dijkstra 变种算法修改成解决本文问题的算法,也即第2 节讨论的Dijk-CCMTP 的变种算法进行3 类查询.下文中,对用基于Dijkstra 方法求解带费用限制的最早到达路径、最晚出发路径和最短耗时路径的方法标记为Dijk-CCEAP、Dijk-CCLDP 和Dijk-CCSDP;对采用ACCTL 索引查询的方法标记为ACCTL-CCEAP、ACCTLCCLDP 和ACCTL-CCSDP. 图2 显示了基于Dijkstra 变种算法和基于ACCTL 索引方法的查询时间对比.实验一共测试了11 组数据,y轴以ms 为单位,用对数的比例显示每组数据的平均查询时间.ACCTL 索引的α取1 求精确解,即调用BuildIndex时不执行第18 行~第22 行去掉部分α-支配路径的代码. Fig.2 Query times of the Dijkstra variant method and ACCTL图2 基于Dijkstra 搜索的变种算法和ACCTL 索引的查询时间 总体看来,基于ACCTL 索引的平均查询时间比基于Dijkstra 的搜索快2 个~3 个数量级.这是因为ACTTL在预先计算的路径集中查找路径生成解,避免在原图上盲目搜索.就各组数据的基于ACCTL 索引的查询时间对比,查询时间与索引大小和图的度数有关.总体来说,索引越大,查询时间就越长.图3 的各组数据的第1 根柱子显示了α=1 时的索引大小.留意到Madrid 的索引比LosAngeles 和Berlin 的都小,但查询时间长.这是因为Madrid的平均顶点度数大.顶点v的度数越大,v到达图中其他顶点(或从图中其他顶点到达v)的可能性越大,即L+(s)和L-(d)有拥有相同端点的标签组越多,所以需要匹配的标签组越多,查询时间越长.此外,最短耗时路径查询的速度比最早到达路径查询的稍慢,甚至在个别数据中最短耗时路径的查询比最早到达路径的更快(例如Berlin 的Dijk-CCEAP 与Dijk-CCSDP、SaltLakeCity 的ACCTL-CCEAP 与ACCTL-CCSDP),这是因为最短耗时路径查询受到到达时刻t′的约束,可以帮助剪枝掉部分搜索;而最早到达路径的到达时刻没有t′的约束,所以搜索量反而更大. Fig.3 Index size (MB)of group A and B,with α=1,1.1,1.2 respectively图3 A 组α取1、1.1、1.2 和B 组α取1.1、1.2 时,各个图的索引大小(MB) 本节讨论α取值以及路径的费用值浮动对索引大小的影响.实验设置两大组数据集:A 组数据集的设置如上文所述,一条从u到v的边的费用取值图中所有从u到v的边的耗时的平均值;B 组数据集的图中一条边e的费用取值为[0.7×π,1.3×π]范围内的一个随机整数,其中,π表示通过e的耗时,即令边的费用取值多样化.换句话说,A 组的图的边的费用取值单一,B 组的图的边的费用取值多样. 图3 的每组数据的前3 根柱子显示了A 组数据集下α取1,1.1 和1.2 时各个图的索引大小,以MB 为单位,分别标记为(A)1、(A)1.1、(A)1.2.当α递增时,索引变小.因为ACCTL 利用α-支配去掉部分基本路径,α放得越宽,可以被去掉的基本路径就越多.另一方面,α从1.1 递增到1.2 时,索引变小的幅度明显比α从1 递增到1.1 时的小.这是因为ACCTL 需要保证原图中(α=1 时)的每条基本路径P,在索引中都存在路径α-支配P,而不是在α=1.1 时保留的路径的基础上去掉α-支配的路径. 图3 的每组数据的后两根柱子表示B 组数据集取α=1.1 和α=1.2 的索引大小,分别标记为(B)1.1 和(B)1.2.留意到B 组的索引明显比A 组要大.因为B 组的图中边的费用取值多样,导致两点间路径的费用取值也多样,因此基本路径数也比A 组要多.在B 组数据集中,从α=1.1 递增到α=1.2 时,索引大小有40%~50%的降幅.这是因为路径费用值取值多样,使得α变大后,有更多的路径因为α-支配被去掉. 综合上述比较,索引大小与α取值和图的费用值浮动的大小有关:α越大,索引越小,但随着α的增大,索引大小降幅变慢.另一方面,当图的路径的费用值浮动越大时,α的影响也越大. 图4 显示了两大组数据建立索引的时间(单位:s).总体来说,A 组的建立索引时间小于B 组,因为A 组的基本路径数小于B 组.两组数据的α=1.1 和α=1.2 的建立索引时间差别不大,可见,建立索引的瓶颈在于生成基本路径,不在于计算α-支配路径.这与第5.1 节对BuildIndex 算法的第18 行~第22 行的讨论一致.在A 组数据内,α=1时建立索引的时间略小于α=1.1 和1.2,因为α=1 时不需要执行BuildeIndex 的第18 行~第22 行.留意到图Sweden在α=1 时的执行时间反而大于α=1.1 和1.2,这是因为α=1 时基本路径数多,对标签进行排序的时间不可忽略. Fig.4 Index construction time of group A and B,with with α=1,1.1,1.2 respectively图4 A 组α取1、1.1、1.2 和B 组α取1.1、1.2 时,各个图建立索引的时间 本文研究了公交网络下带费用限制的最小时态路径查询问题,提出了一种高效索引结构ACCTL.ACCTL通过预计算图中部分路径的信息,使得任意查询可以通过在ACCTL 中检索路径生成近似解,避免在原图上盲目搜索,从而提高查询效率.本文对ACCTL 的存储结构、建立索引方法和查询算法做了多方面的讨论和优化.实验验证了ACCTL 索引支持的查询速度比在原图上采用Dijkstra 变种算法的查询速度快2 个~3 个数量级,并分析了ACCTL 的存储空间和建立索引的时间的影响因素.

2 一种基于Dijkstra 算法的方法
2.1 核心算法Dijk-CCMTP

2.2 基于Dijk-CCMTP的查询算法
3 索引ACCTL 的框架
3.1 ACCTL的设计思想

3.2 标签去冗余

4 查询算法
4.1 查找标签

4.2 路径还原
5 ACCTL 索引的构建
5.1 计算基本路径


5.2 选择路径

5.3 点序o的计算
6 实 验

6.1 查询时间

6.2 索引的大小
6.3 建立索引的时间
7 结束语
猜你喜欢
环球人物(2022年4期)2022-02-22 22:05:06中等数学(2021年9期)2021-11-22 08:06:58小资CHIC!ELEGANCE(2021年32期)2021-09-18 06:17:14意林(2021年9期)2021-05-28 20:26:14时代英语·高一(2019年1期)2019-03-13 10:29:48山东科学(2018年6期)2018-12-20 11:08:58自动化学报(2017年2期)2017-04-04 05:14:34Coco薇(2016年8期)2016-10-09 00:02:56爆笑show(2015年4期)2015-06-24 01:55:12小学阅读指南·高年级版(2014年2期)2014-05-27 05:29:32
