
基于空间特征分区和前点约束的WKNN 室内定位方法∗
2019-12-11 04:27杨海峰张勇波黄裕梁傅惠民
软件学报 2019年11期
杨海峰 , 张勇波,2 , 黄裕梁 , 傅惠民
1(北京航空航天大学 小样本技术研究中心,北京 100191)
2(北京航空航天大学 宁波创新研究院,浙江 宁波 315800)
在移动技术蓬勃发展的今天,基于位置信息的服务在人们的日常生活中发挥的作用愈加重要,市场对于高精度室内定位与导航服务等全新需求在不断涌现[1,2].众多公司已在各方面尝试将室内定位服务拓展并进行大规模商业化运营[3,4].
截至目前,室内定位尚未形成一套统一、成熟的解决方案[5,6],但是基于不同应用场景与环境的各种室内定位方法不断被提出,其中主要包括基于微电子机械系统(micro-electro-mechanical system,简称MEMS)的行人航迹递推(pedestrian dead reckoning,简称PDR)算法[7,8]、利用无线射频识别(radio frequency identification,简称RFID)技术的室内定位方法[9,10]、基于伪卫星网的室内GPS 定位方法[11,12]以及基于WiFi 信号的室内定位方法[13-18]等.然而,上述方法都面临着各种各样的问题:由于MEMS 的误差累计,PDR 算法的定位精度会逐渐降低,以致完全失效;而RFID 定位和室内伪卫星定位则都需要铺设大量外接设备以构建导航网络,高昂的采购与部署成本限制了其在商业领域的大规模推广应用.随着移动互联网的飞速发展,WiFi 网络迅速普及,遍布现代社会各个角落,因此,基于WiFi 的室内定位技术以其部署成本低、易于推广、精度较高等优势,愈发引起研究人员的重视,逐渐成为室内定位技术的热点[19].
在基于WiFi 信号的室内定位方法中,以指纹匹配法的位置估计精度更高、对复杂环境的适应能力更强,其包含离线采样与在线匹配两个阶段.离线采样阶段是在目标区域内选取若干参考指纹点(reference point,简称RP),记录其位置、接收到各无线接入点(access point,简称AP)的媒体访问控制(media access control,简称MAC)地址以及相应的WiFi 信号强度值(received signal strength indication,简称RSSI)信息,通过对上述信息进行分析和处理,得到目标区域的指纹数据库.在线匹配阶段是用户使用设备在当前位置接收到实时的测试数据(各AP的MAC 地址和相应的RSSI 值),将其与指纹数据库进行匹配运算,再利用库中已知的RP 位置对用户当前位置进行估计[20].
由于指纹匹配法具有较大的发展优势,研究人员对其开展了大量的研究.早期的Bahl 等人开发了信号空间最接近K邻近法(K-nearest neighbors in signal space,简称KNN),该算法将筛选出的K个参考点坐标的算数平均值作为最终的位置估计[21].Lionell 等人则在KNN 算法的基础上提出了加权K邻近算法(weightedKnearest neighbors,简称WKNN),其对参考点的位置坐标计算加权平均值,以得到更优的位置估计[22].然而,无论是KNN算法还是WKNN 算法,它们的WiFi 指纹数据库都是针对一整块区域建立的,而工程实际要求处理面积较大的目标区域,此时由于AP 的覆盖范围有限,上述算法无法根据目标区域内测得的WiFi 信息建立一套全区域都适用的指纹数据库.此外,WKNN 算法估计出的位置在空间上有时还会出现跳动距离过大的情况,这是其在整个目标区域内选择K个参考点所造成的固有缺陷.
针对上述问题,本文提出了一种基于空间特征分区和前点约束的WKNN 室内定位方法.该方法通过将面积较大的一整块区域按照其空间特征划分为多个分区,解决了指纹数据库全域覆盖的问题;又通过考虑行人前后位置之间空间约束关系,缩小了参考点的候选范围,很好地提升了位置估计的平顺性.大量真实环境下室内定位实验的结果表明,本文方法可以有效地解决大面积区域内的室内定位问题,且与传统方法相比,定位精度有较大幅度的提升.
1 基于空间特征的室内分区方法
传统的WKNN 方法在建立WiFi 指纹数据库的过程中,需要对目标区域内所有的指纹点所获得各AP 的RSSI 数据进行处理,具体处理方法是提取出全部RP 所共有的AP 对应的强度信息.这样做的前提是共有的AP存在且数量足够,从另一方面来讲,即要求有足够多的AP 其信号可以覆盖整个目标区域.然而,当目标区域的面积足够大时,限于AP 的信号覆盖能力,该条件显然无法被满足.
本文提出的基于空间特征的室内分区算法可以很好地解决上述问题,其基本做法为:首先将面积较大的目标区域依据其空间特征(如是否贯通、有无遮挡等)划分为多个面积较小的分区,然后对每个分区分别获取各自内部RP 所共有的AP 信息作为该分区的标识信息,同时建立分区指纹数据库;在在线匹配阶段,通过比对测试点获取的AP 信息与各分区的标识信息,判断该测试点所处的分区;最后,使用相应分区内的指纹数据对测试点位置进行估计.具体处理方法如下.
•步骤1:划分分区.
根据目标区域的面积大小,恰当地选取RP 的分布密度,记录各RP 的位置信息.在每个RP 处获取各AP 信息,并记录相应的RSSI 值.设目标区域内共有参考点m个,第i个RP 的位置坐标为(xi,yi),在该点可获取ni个AP信息,其中,第j个AP 的MAC 地址为MAC_i_j,对应的强度值为RSSI_i_j,则WiFi 信号的原始数据可以表示为
通过分析目标区域的空间特征,将m个RP 分配到k个不同的分区.设第i个分区内有参考点im个,则该分区内的WiFi 信号数据可以表示为
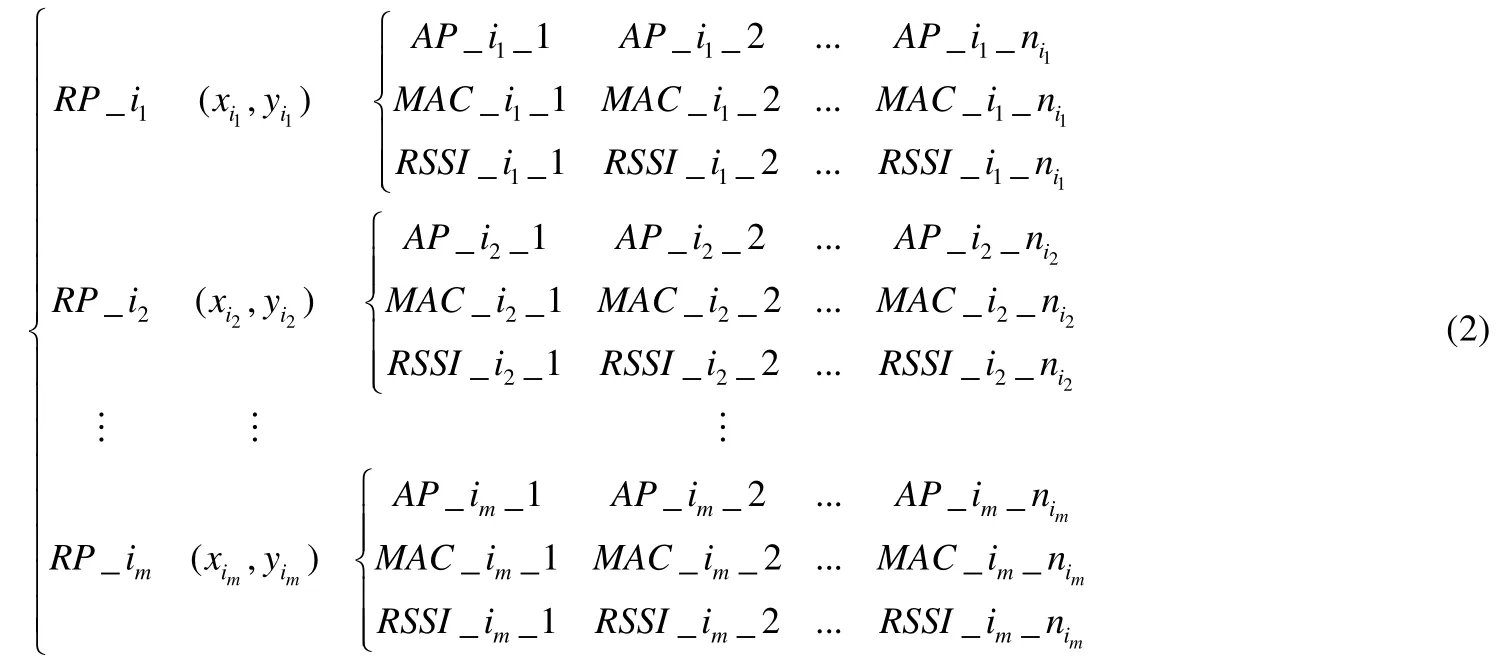
由于每个RP 处能够接受到的AP 信号数目各不相同,所以每条RP 数据的长度不可能全部相同.为了后续计算的方便,需要对分区内的WiFi 信号数据进行预处理,使其长度保持一致.具体做法是,截取分区内所有RP 所共有的AP 信息,组装成长度统一的分区指纹数据库.设i分区内im个RP 所共有的AP 数目为ni,则分区指纹数据库可以表示为
•步骤2:提取分区标识序列.
各分区的最主要区别在于其内部信号较强的AP 各不相同,因此,将每个分区内信号最强的q个AP 的MAC地址按照RSSI 由强到弱的顺序排列组装成一串特征序列,它就可以作为分区的标识序列,简捷地反映出各分区的特征.具体做法如下.
(1)对i分区指纹数据库内对应相同MAC 地址的RSSI 值进行求和运算,并按照由强到弱的顺序进行排列,得到强度和序列:

其中,

(2)若某AP 在分区内部影响较大,则分区内绝大部分RP 可以接收其RSSI,且数值较大.通过公式(4)和公式(5)的求和运算后,该AP 对应的强度和数值也较大,排序靠前.因此,可以截取公式(4)所示序列的前q个作为分区的标识信息,组成新的强度和序列.

(3)将公式(6)中RSSI 值的和依照公式(3)所示的分区指纹数据库替换为其各自对应的MAC 地址,则可得到i分区的标识序列:

•步骤3:分区判别.
由于对目标区域进行了分区处理,当测试点数据获得以后,首先需要执行对其所处分区的判别,之后才能够调取相应分区内的WiFi 指纹数据执行WKNN 算法.设在测试点获取的测试数据包含p个AP 信息,将其按信号强度从强到弱排序后,可以表示为

截取测试数据的前q个MAC 地址组成测试序列:

将公式(9)中的测试序列与公式(7)中每个分区的识别序列进行比对,记录各组数据在2q个MAC 地址中重合的个数,记作nums_amei,其中,1≤i≤k.
一般来说,选取{nums_ame}中数值最大的一个,其所对应的i即为当前测试点所处的分区编号.但是当测试点处于两分区交界线附近时,其受到两个分区的影响程度相当,便很容易出现nums_amei=nums_amej的情况.此时,算法将无从判断测试点所处的分区.更严重时,甚至会造成分区的误匹配.为了尽可能减少匹配失效和误匹配情况的发生,本文在采用识别序列进行分区判别的基础上,引入信号空间距离判定作为二级判定依据,其具体做法如下.
(1)设定启动二级判据的阈值Δnums_ame,设{nums_ame}中数值最大的两个分别为nums_amei和nums_amej,且nums_amei≥nums_amej,如果两者的差值大于Δnums_ame,则说明i分区对测试点的影响力远大于j分区,此时不需要启动二级判据;如果两者的差值小于或等于Δnums_ame,则说明两分区对测试点的影响力相当,此时就需要启动信号空间距离判据.
(2)二级判据启动后,测试点需要依照WKNN 算法,分别与i,j两个分区内的指纹数据逐一计算信号空间距离,各空间距离可以表示为

在上式的计算过程中,由于测试数据和两个分区指纹数据所包含的AP 信息不尽相同,因此需要截取各组数据所共有的AP 信息进行计算.
(3)由于计算信号空间距离时对两个分区指纹数据截取的维度不同,为了使空间距离具有可比性,将公式(10)中的空间距离分别除以各自对应的维度,得到归一化的信号空间距离,按距离从小到大排序后,可以表示为

其中,

(4)截取公式(11)中归一化空间距离最小的K个,记作:

对其进行平均值的求取,得到K个归一化欧式距离的均值:

如果mean_li≤mean_lj,则判定测试点处于i分区;反之,则为j分区.
综上所述,本节给出了基于空间特征的室内分区方法.方法流程图如图1 所示.它由两部分组成.
•第1 部分是将目标区域划分为不同分区,同时得到各分区的标识序列和指纹数据库
•第2 部分则给出了判断测试点处于哪一分区的两级判据:标识序列判别和欧氏距离判别.
通过分区,在大面积目标区域内执行室内定位算法的困难得以解决,为后续基于前点约束的WKNN 定位算法的实现奠定了基础.

Fig.1 Spatial characteristics partition framework图1 空间特征分区框架图
2 基于前点约束的WKNN 定位算法
通过对目标区域分区和分区判别算法,可以确定用户所在测试点的分区编号,进而可以调用对应分区内的WiFi 指纹数据库,采用WKNN 算法得到最终的用户位置估计.传统的WKNN 算法虽然较KNN 算法在定位精度上有了一定的提升,但是并没有解决其定位结果在短时间内往复跳动、平顺性不佳的问题.造成该问题的原因在于,这两种算法对K个参考点的选取并不恰当.理论上讲,两条WiFi 数据的信号空间距离越小,其在真实空间中对应位置的距离也就越近,这是WKNN 算法的理论基础.但是无论是在指纹数据库的录入过程中,还是在测试数据的获取过程中,WiFi 信号都不可避免地受到来自外界各种因素的干扰;同时,由于AP 发射的WiFi 信号本身就存在很大的波动性,因此实测得到的指纹数据与测试数据都不可能完全准确.所以在WKNN 算法的计算过程中,通过比对信号空间距离筛选出的K个参考点很有可能并不是在实际空间上距离测试点最近的K个.又由于WKNN 算法对于K个参考点的筛选范围并没有限制,所以筛选出的某一个或几个参考点与测试点实际距离较远的极端情况也有可能发生,而这无疑会对位置估计的平顺性和精度造成负面影响.
用户在室内行进过程中,在比较短的时间段内行进的距离并不会很远,因此可以认为行人的位置在空间和时间上具有连续型,即,其受到空间与时间的约束限制.本文所采用的前点约束法正是基于室内定位的这一特征,利用行人前一时刻获得的位置估计来对当前时刻的位置估计进行约束.其基本做法为:首先,通过WKNN 算法在整个分区内选出K个候选参考点;然后,以前一时刻的位置为圆心,选取恰当的R为半径做圆,以圆内作为约束条件对K个候选指纹点进行筛选,得到用以进行位置估计的最终参考点;再通过WKNN 算法计算出最终的位置估计.与传统的WKNN 算法相比,基于前点约束法的WKNN 算法缩小了参考点的候选范围,强制它们聚集到测试点实际位置的周围,在根本上杜绝了由于WiFi 信号数据不准确造成参考点距离实际位置较远情况的出现,从而增强了定位结果的平顺性,提高了位置估计的精度.基于前点约束的WKNN 算法的具体步骤如下所示.
•步骤1:计算信号空间距离.
用户使用设备在测试点获取如公式(8)所示的测试数据,简记作序列A.

设测试点通过分区判别以被确认属于i分区,则将序列A与公式(3)所示i分区指纹逐一进行信号空间距离的计算,得到一组欧式距离的集合B.

其中,

其中,nj为序列A与分区指纹RP_ij所重合的AP 个数.
•步骤2:加权得到位置估计.
截取集合B的前K个元素,组成候选参考点欧氏距离集合C.

将集合C中的每个元素替换为其所对应的RP 位置坐标,则可得到候选参考点位置集合D.

设行人在t-1 时刻的位置估计为(xt-1,yt-1),以其为圆心、以Rt-1为半径做圆,记作圆o.以处于圆o内部作为约束条件,获取集合D的子集E,即为最终参考点位置集合.

其中,iO为使用前点约束筛选出的参考点的个数.
相应地,可以得到集合C的子集F,即为最终参考点欧氏距离集合.

基于WKNN 算法,根据公式(22)中的欧氏距离,可以计算最终参考点各自的权重:

则当前时刻,t的位置估计(xt,yt)为

对于前点约束法,有两点需要特殊说明.
(1)对初始位置进行估计时,由于其没有前一时刻的位置估计,因此需要采用标准的WKNN 方法计算;
(2)在公式(21)与公式(22)所示的最终参考点筛选过程中,仍有小概率出现筛选结果为空集的情况,此时也采用标准的WKNN 方法进行位置估计.
前点约束法的流程图如图2 所示.

Fig.2 Former location restriction framework图2 前点约束框架图
3 实验与结果分析
3.1 实验设备与环境
选择北京航空航天大学新主楼C 座9 层环形走廊作为实验场地进行定位实验,使用MI 5 手机(MEID:990********129)对参考点RP 处的WiFi 信号强度进行采集,通过空间特征分区算法获取指纹数据库后,实验员手持该设备沿走廊中线绕实验场一周,实时获取测试数据并与指纹数据库进行匹配,通过基于前点约束的WKNN 算法得到室内位置的估计结果.
3.2 实验过程
(1)设置参考点并获取原始数据
首先需要针对实验区域设置一定数量的参考点,考虑到本实验中的目标区域形状为矩形,因此采用四边形法,以1.2m 间隔进行参考点的获取,并在同一坐标系下记录各参考点的位置坐标,最终在目标区域内获得158 个指纹点,如图3 所示.

Fig.3 Map of experimental environment图3 实验环境示意图
随后,实验员手持MI 5 手机在所有参考点处对WiFi 信号进行测量,所需记录的数据包括所有接收到的AP的MAC 地址及其对应的信号强度RSSI,经编号后存储为公式(1)所示的格式.在数据获取过程中,为保证指纹数据的准确性,尽量减少WiFi 信号波动性造成的不利影响,在每个RP 处按照东西南北这4 个方向各进行10 次测量,再对40 条数据取平均值作为最终的信号强度存入原始数据库中.
(2)划分分区并提取指纹数据库
在参考点设置完毕的情况下对目标区域进行分区,由于实验环境为一条环形走廊,按照分区内部应当贯通的原则,在实验中将4 条直线型的走廊作为目标区域的4 个分区,如图4 所示.

Fig.4 Target space partition图4 目标区域分区
在分区过程中需要注意:为了避免分区后形成定位盲区(即不被任何分区所覆盖的室内空间,如图5 所示),相邻的分区应当共享边界处的指纹点,使分区之间达到无缝连接.

Fig.5 Blind zone caused by wrong partition图5 错误分区造成的定位盲区
在分区划分完成后,对各自分区内部的WiFi 信号原始数据进行共有AP 信息的截取,以建立分区指纹数据库(如公式(3)所示),进而提取出各分区的标识序列(如公式(7)所示).分区指纹数据库的建立过程与分区标识序列的提取过程分别详见第1 节的步骤1 与步骤2,此处不再赘述.
(3)在线测试并得到位置估计
建立分区指纹数据库后可进行在线测试阶段,在该阶段,实验员手持MI 5 手机沿走廊中线的规划路径匀速行走一圈,当行走至测试点时,通过操作实时获取测试数据,测试数据的存储格式如公式(8)所示.实验过程中,共获得155 个测试点,测试点间隔0.6m,如图6 所示.

Fig.6 True trajectory of positioning experiment图6 定位实验真实轨迹
对于每一条测试数据,首先通过分区判别算法确定实验员当前位置所处的分区(详见第1 节步骤3),进而调用相应分区的指纹数据库与该条数据进行匹配,最终通过基于前点约束的WKNN 算法计算得到位置估计结果(详见第2 节).
3.3 实验结果与分析
基于上述已获取的指纹数据库和测试数据,分别采用传统的WKNN 算法、融合轨迹外推信息的WKNN 算法与本文基于空间特征分区与前点约束的WKNN 算法进行对比运算.实验中,对前两种算法取K=5,对本文方法取K=10,R=2.7m.而对于前文所述两种特殊情况,K取值与传统WKNN 算法保持一致,记作KW.为保证分区判别算法的准确性,对其所需参数取q=20,Δnums_ame=0.用户在目标区域行进一圈,3 种方法位置估计的对比图如图7 所示,其各自的位置估计误差见表1.
从图7 中的对比可以看出,使用本文方法的位置估计轨迹更加平顺.与使用传统WKNN 方法的位置估计轨迹相比,往复跳动的现象得到了很好地抑制,也更加贴合图6 所示用户真实的行进轨迹.结合表1 所示两种方法位置估计误差的数值,其最小估计误差都保持在0.02m,但是WKNN 方法的最大估计误差达到了7.92m,而本文方法的最大估计误差只有2.63m.
从全程的平均误差来看,本文方法的平均估计误差保持在1m 以内,达到了0.88m,与WKNN 方法1.66m 的平均误差相比,估计精度提升了47%.融合轨迹外推信息的WKNN 方法则是在传统WKNN 方法结果的基础上,通过对前两个时刻的位置估计外推得到当前时刻位置估计的预测值,再将该预测值与WKNN 方法所得当前时刻的位置估计进行融合,从而得到最终的估计结果.该方法由于在估计过程中利用了用户的历史位置信息,因此精度与传统的WKNN 方法相比有小幅度的提升,但是与本文方法的位置估计精度相比仍有非常巨大的差距(如表1 所示),这说明本文方法对于历史位置信息的挖掘和应用更加深入和充分.此外,通过对155 个测试点分区判定结果的统计,由识别序列与信号空间距离所组成的两级分区判别算法,其准确率达到了96.4%,显示出判别算法在实际应用中的可靠性.

Fig.7 Comparation of estimated trajectories图7 位置估计对比
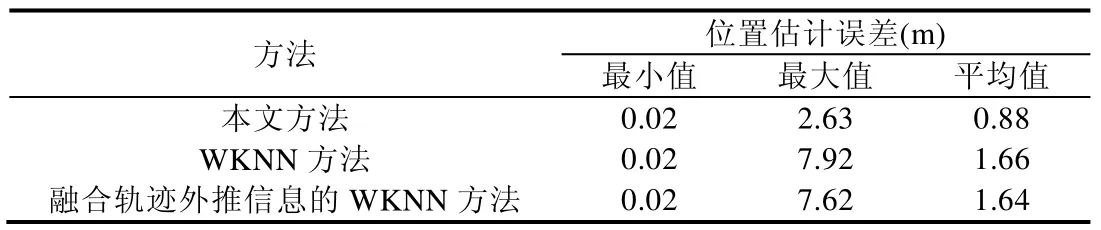
Talbe 1 Comparison of estimation errors表1 估计误差对比
图8 进一步给出了本文方法和传统WKNN 方法位置估计误差的累计概率对比图.从图中可以看出,在采用本文方法对全程155 个测试点进行位置估计时,有80%以上的估计结果精度都保持在1.5m 以内;而在同样的精度范围内,传统WKNN 方法估计结果达到标准的还不足60%.这也可以从另一个方面说明,本文方法相对于WKNN 方法的提升是全方位的.

Fig.8 Cumulative probability of location estimation errors图8 位置估计误差的累计概率
3.4 参数优化
在第3.2 节中已知,对本文方法所需要的参数取K=10,R=2.7m,KW=5.对于一个确定的目标区域,选取不同的参数值得到最终的估计结果也有所不同.为了最大限度地发挥本文方法的优势,实验中对参数进行了最优化计算.具体考虑了KW∈{4,5,6},R∈{2.5,2.6,…,3},K∈{5,6,…,15}下所有的组合方案,得到的计算结果如图9~图11所示.
在这3 种情况下,最优参数组合均为K=10,R=2.7m,而其中以KW=5 时的位置估计精度最高,因此在本实验环境下,选取其作为实验参数.需要说明的是,该参数组合仅在当前目标区域下为最优参数,当实验环境、测量工具发生变化时,需要重新运行参数优化过程以获得相应条件下的最优参数.

Fig.9 Average estimation error distribution when KW=4图9 KW=4 时平均估计误差分布
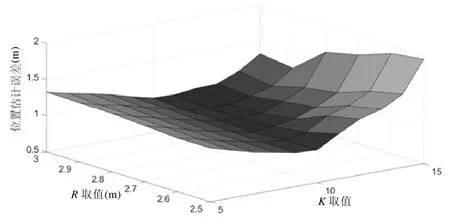
Fig.10 Average estimation error distribution when KW=5图10 KW=5 时平均估计误差分布
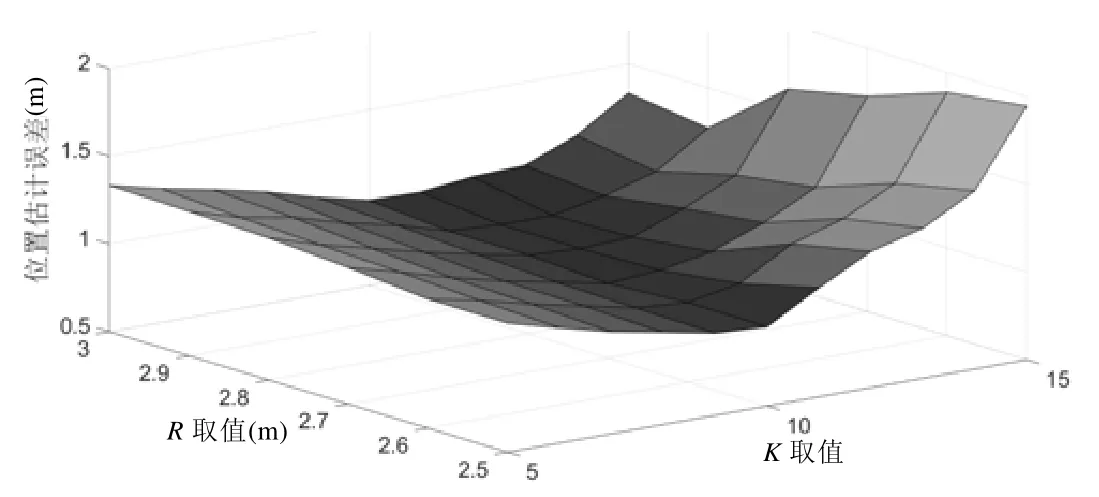
Fig.11 Average estimation error distribution when KW=6图11 KW=6 时平均估计误差分布
4 结 论
传统的WKNN 方法无法解决一套指纹数据库覆盖整个目标区域的难题,同时还存在估计结果跳动跨度较大的问题,严重影响室内定位精度.针对上述问题,本文提出了一种基于空间特征分区和前点约束法的WKNN室内定位方法.通过将面积较大的目标区域按照其空间特征划分为多个分区,同时引入识别序列和欧氏距离的组合分区判据,解决了指纹数据库无法实现全域覆盖的问题;又通过考虑行人在相邻时刻所处位置之间的空间约束关系,缩小了最终参考点的筛选范围,很好地提升了位置估计的精度.在北京航空航天大学新主楼C 座9 层环形走廊进行的室内定位实验结果表明,与传统的WKNN 方法相比,本文方法极大地提升了位置估计轨迹的平顺性,分区判别正确率达到96.4%,室内定位精度则提升了47%,达到了0.88m,进而证明了本文方法的有效性.
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
大众科学(2022年5期)2022-05-18
环球时报(2022-03-29)2022-03-29
好日子(下旬)(2020年6期)2020-08-04
上海大学学报(自然科学版)(2020年4期)2020-05-24
科学导报·科学工程与电力(2019年28期)2019-10-21
消费导刊(2019年3期)2019-01-28
计算机与数字工程(2018年4期)2018-04-26
中国新通信(2016年11期)2016-08-09
