
一种潜在特征同步学习和偏好引导的推荐方法∗
2019-12-11 04:27杨征路
软件学报 2019年11期
李 琳 , 朱 阁 , 解 庆 , 苏 畅 , 杨征路
1(武汉理工大学 计算机科学与技术学院,湖北 武汉 430070)
2(南开大学 计算机与控制工程学院,天津 300071)
1992 年,Goldberg 等人提出了协同过滤的方法,构建和实现了个性化的邮件推荐系统[1].1994 年,Resnick 等人在文献中阐述了GroupLens 研究组研究的推荐系统[2].迄今为止,推荐系统已经在各大领域得到了广泛的应用和推广,包括Netflix 的视频推荐系统、Amazon 的商品推荐系统、淘宝网、京东商城等知名的中国电子商务平台以及具有推荐功能的音乐等休闲娱乐平台[3].
通过用户历史评分来推荐商品的协同过滤方法是主流的推荐方法之一,其他还有基于内容的推荐、基于知识的推荐以及混合推荐方法等.为了进一步提高推荐质量,研究者们不断挖掘和分析能够反映用户特性或者用户偏好的信息,例如用户的性别、用户的评论、用户的关系等.相对于历史评分数据,评论文本是用户能够更具体表达自己喜好的一种方式.研究者通过总结用户评论文本中的重要观点[4],或者是挖掘具有相同观点的用户来提高推荐质量[5],还有将评论文本的语义分析和观点挖掘融入到推荐方法中[6].用户对商品的评论文本隐含了一定量的用户信息,因此可以与传统基于用户评分的推荐方法结合,进一步提高推荐质量.
图1 中,用户对电脑产品的评分和评论数据来自于某电子商务平台.相对于评分数据(图1 中的“star5”),评论文本表达了用户对商品不同方面的关注和偏好.用户1 从价格、外观、材质这3 个方面对某电脑产品进行了评论,总体比较满意,给了5 分的评价.用户2 从价格、硬件配置和系统软件这3 个方面对进行了评论,给了4 分的评价.评论文本可以反映用户的“打分偏好”(图1 中价格、外观、材质、硬件配置和系统软件5 个方面的评价),从一定程度上解释了用户评分的依据和原因.因此,从图1 中的例子可以观察到,评分数据是用户对商品的整体评价,评论文本中蕴含着影响用户评分的偏好或者说是潜在因子.体现用户打分偏好的潜在因子表明评论数据和评论文本具有关联,因此可以将从评论文本主题发现模型学习得到的潜在主题作为个人打分偏好,融合到基于评分数据的隐因子矩阵分解模型中,从而提高面向用户的推荐质量.
目前比较流行的是基于矩阵分解的协同过滤方法[7-11].这类方法在推荐准确率上表现出色.同时,有关融合评论文本的推荐方法也在不同方面上做了进一步的优化和改进,且以某个特定指标为评价方式(比如均方误差、绝对值误差、均方根误差等)最终提升了推荐质量[12-14].但是已有的方法未能充分地利用评论文本主题来预测评分矩阵中对未知商品的打分,特别是评论文本与基于矩阵分解的协同过滤方法如何在模型求解过程中深度融合,同时考虑用户偏好和商品特性.本文的研究目标是探索融合评分矩阵分解模型与评论文本主题发现模型的推荐方法,考虑评分和评论数据都具有高层潜在特征,将矩阵分解中的潜在因子与评论文本的潜在主题建立映射关系后同步学习参数.通过在用户对商品的单条评论文本上进行主题发现学习,将潜在主题特征融入评分矩阵分解模型的求解中,从而提出了基于潜在特征同步学习和偏好引导的商品推荐方法(preference guided in matrix factorization,简称PreferenceMF).该方法将评论文本的潜在主题与矩阵分解的潜在因子进行正向映射,同时又作为预测评分的引导项,并进一步将主题概率分布作为到正则约束的一部分.实验结果表明,PreferenceMF 降低了预测评分的误差,提高了推荐方法的质量.
本文的工作主要包括以下3 个方面.
(1)提出PreferenceMF 方法,以用户对商品的单条评论文本为潜在主题学习的处理单元,通过考虑主题与评分矩阵分解后的用户潜在因子和商品潜在因子的映射关系,使这些潜在特征相互关联,并依据此关联设计相应的求解算法,达到提升推荐质量的目的.
(2)提出主题偏好引导,即在矩阵分解模型中引导潜在因子矩阵的计算.用户潜在因子矩阵解释为用户在某一种潜在特征上的偏好,评论文本中又能够反映用户的个人偏好,因此,将评论中发现的个人偏好融合进潜在因子矩阵,从而能够更好地反映用户偏好.具体来说,在PreferenceMF 方法中添加基于主题偏好的引导,单条评论文文档的主题发现作为引导项,并将主题概率分布添加到正则约束中提高推荐质量.
(3)在Amazon28 组数据子集上测试了PreferenceMF 方法的推荐质量,分析了数据的稀疏问题,并与已有的方法进行了对比,采用均方误差作为评价指标,与最近相关的TopicMF 方法相比,在数据子集上均方误差最大减少了3.32%,平均减少了0.91%.
1 相关工作
1.1 基于评分数据的推荐方法
亚马逊购物网站是较早借助推荐方法进行商品销售的系统[15].在基于用户评分数据的推荐方法中,通常将用户、商品及评分关系表示成矩阵的数学形式.研究者提出了基于用户的协同过滤方法、基于商品的协同过滤方法和基于模型的推荐方法等.传统的基于用户或商品的协同过滤方法是通过计算用户之间或者商品之间的相似度之后,用最相似的若干个用户或者商品的历史评分数据来预测对未知商品的打分.相似度的计算大多采用欧氏距离、皮尔逊相关系数、余弦距离等,并且研究表明,相似度计算的改进可以提高推荐性能[7,8,16,17].
在基于模型的推荐方法中,目前比较有影响且被广泛研究的是Koren 等人提出的潜在因子分解模型(latent factor models,简称LFM)[9,18,19].传统的分解模型一般是从奇异值分解(SVD)模型开始的,需要首先将评分矩阵补全,再使用补全得到的稠密矩阵完成分解.这不仅在存储上带来了很大的限制,而且在计算复杂度上也显著地升高.2006 年Netflix 竞赛后,Simon Funk 提出了一种矩阵分解的改进算法,称为Funk-SVD,后来被Netflix 竞赛的冠军KorenY 进一步优化为LFM,能够对不完整的评分数据实现矩阵分解,从此逐步有了其他的矩阵分解模型NMF、PMF 等[3,13,20-22].
基于评分数据的推荐方法得到了广泛的研究和应用,然而也存在一定的问题.由于用户的数量和商品的数量非常庞大,用户一般不可能对所有的物品进行反馈评分,导致评分矩阵中存在很大的空缺.这种数据的稀疏性使得模型不能得到足够的训练,最终影响了推荐系统的性能.此外,新的消费者或者是新上架的商品由于没有历史评分,导致无法准确地进行相似度计算,从而引起推荐的冷启动问题.根据推荐系统的不同应用领域,研究者近年来通过挖掘商品的标签和用户的参与信息,例如用户的关系、用户的评论、用户的行为等来提高推荐系统的性能[3].本文通过挖掘评论文本的潜在主题,将其融合到基于评分的矩阵分解模型中.接下来主要介绍近年来这方面的研究现状.
1.2 加入评论文本的推荐方法
较早已有研究表明,评论文本有助于提高推荐系统的性能.Basilico 等人提出的推荐方法将回归分析应用于文本内容[10];Ganu 等人以句子为单元对评论文本分类和进行情感极性分析,并将这些信息融合到基于KNN 的协同过滤推荐方法中[11].较早的这些研究侧重于发现评论文本中用户多方面的偏好,通过标注这些重要偏好来提高评分预测的精度.他们所采用的文本处理方法是以单词为单元的词袋模型,没有考虑到文字背后的语义关联.2003 年,由Jordan 等人提出的潜在狄利克雷概率模型(latent Dirichlet allocation,简称LDA)在概率语义分析之上加入了贝叶斯框架,是目前为主最重要的语义主题挖掘模型之一[23].此外,Lee 等人在文献中提出了非负矩阵分解模型(non-negative matrix factorization,简称NMF),也可以用于文本的潜在主题分析[24].
近年来,对评分与评论文本的融合主要关注潜在特征(潜在因子和潜在主题)的分析.Mcauley 等人提出的HFT(user)方法将用户评论集的LDA 主题分布映射到矩阵分解的用户潜在因子向量,而HFT(item)方法则将商品评论集的LDA 主题分布映射到商品潜在因子向量[12].TopicMF 方法认为,应该同时考虑反映用户偏好的主题和商品特性的主题[13],并使用了NMF 方法发现文本的主题,得到的每一条评论的主题分布是用户偏好和商品特性的综合,并将该主题分布映射到矩阵分解后的用户潜在因子向量和商品潜在因子向量.文献[14]首先利用主题模型挖掘评论文本中隐含的主题分布,然后用主题分布刻画用户偏好和商品画像,最后在逻辑回归模型上训练主题与打分的关系.文献[25]提出一种无监督的推荐方法,在评论文本中发现情感主题,主要考虑情感主题与评分的关系.Wang 等人提出将PMF(probabilistic matrix factorization)与主题分布结合,用于推荐科学文章[22].文献[26]提出用混合高斯模型取代矩阵分解模型,再与LDA 主题融合建模.黄璐等人提出将用户的主题模型和商品的主题模型与矩阵分解模型相结合,并将商品的标签信息和用户行为数据同时加以考虑,以提升推荐结果的多样性[27].Chen 等人提出矩阵分解模型结合文本信息的策略,直接通过用户评论集合和商品评论集的主题分布进行引导[28].Li 等人采用Generative Models 来学习评论文本和评分数据在方面级(aspect)的关系[29].本文提出的方法是基于矩阵分解和主题模型来同步学习潜在主题和隐因子的映射关系,并使用潜在主题正则约束进行引导预测评分.此外,在跨领域的推荐问题上,融入评论文本的方法也显著提高了推荐准确率[30,31].文献[32]直接将主题模型用于评分数据,以提高单类协同过滤推荐算法(one-class CF)的质量.
与本文研究比较相近的有HFT 方法和TopicMF 方法.这两者之间有3 点不同:一是主题模型,前者采用LDA模型,而后者使用了NMF;二是文本粒度,前者是由某个用户的所有商品评论组成,而后者是某个用户对某个商品的单条评论;三是前者将潜在主题与用户潜在因子矩阵或者商品潜在因子矩阵之一进行融合建模,而后者是与两个潜在因子矩阵同时融合建模.通过以上文献调研,我们发现,基于评分矩阵和评论文本融合建模的推荐方法可以进一步深度融合,并且以用户对商品的单条评论文本为潜在主题学习的文档单元更有利于用户偏好的分析.本文提出的PreferenceMF 推荐方法将单条评论文本的潜在主题与评分矩阵分解的用户潜在因子和商品潜在因子建立映射关系,同时,以此潜在主题作为用户偏好引入基本的矩阵分解模型中,并将主题概率分布作为正则约束,从而建立深度融合的推荐模型以及参数同步求解算法,达到减少预测评分的误差、提高推荐质量的目的.
2 PreferenceMF 商品推荐方法
本文主要研究在评分矩阵存在数据稀疏问题的情况下,如何将评论文本数据融合到基于评分矩阵的推荐模型中.本节分别从潜在特征同步学习和偏好引导两个方面入手给出PreferenceMF 推荐方法的数学模型,并讨论推荐模型的建立和参数求解算法.
2.1 PreferenceMF中的潜在特征同步学习
2.1.1 基本思想
本节先考虑PreferenceMF 中潜在特征同步学习部分.这部分将单条评论所隐藏的用户打分偏好融入到传统的隐因子模型(LFM)中.某个用户对某个商品的打分会受到用户的个人偏好与商品特性的影响,即用户的打分背后是综合了个人与商品两者的因素,在本文中统称为“打分偏好”.该打分偏好在这里可以理解为影响打分的潜在隐性特征,而用户的评论文本能够反映出这种隐性特征.换言之,就是评论文本的潜在主题反映的是用户对商品不同方面的“打分偏好”[3],如图1 所示的例子.
本文通过将用户的每一条评论文本的主题同步映射至打分矩阵的用户隐因子(个人偏好)和商品隐因子(商品特性),从而约束该用户对未打分商品的评分预测.这就是潜在特征同步学习的基本思想,也是本文提出的PreferenceMF 推荐方法重点考虑的方面之一.与本文最为相近的两个方法是来自McAuley 等人提出的HFT(hidden factors and hidden topics)方法[12]和Yang 等人提出的TopicMF 方法[13].在第1.2 节中,我们讨论了它们之间的不同点,这里直接给出PreferenceMF 中潜在特征同步学习部分.
2.1.2 潜在特征同步学习
首先定义文档集,并引入主题模型来解决评论文本的主题发现问题.用户i对商品j的评论定义为di,j,评论集为{di,j},实例见表1.

Table 1 Examples of users’ review documents used for learning latent topics表1 用于学习潜在主题的用户评论文档集示例
根据表1,这里将每一条评论文本作为一个文档(文本粒度),对应到用户i对商品j的打分上.接下来将用户i对商品j的打分(含个人偏好和商品特性)映射到评论文档集的潜在主题(打分偏好),构建如图2 所示的参数逻辑关系.

Fig.2 Logic relation diagram of parameters in learning latent features图2 潜在特征同步学习的参数逻辑关系图
图2 中,I表示用户集合,将产生用户和潜在特征关系的矩阵和用户评论集合;J表示商品集合,将产生商品和潜在特征关系的矩阵和商品评论集合;r表示用户i对商品j的打分;p和q分别表示r在用户i上的潜在因子向量和在商品j上的潜在因子向量;θi,j就是评论集{di,j}中评论di,j的主题分布;W是评论中词的集合;Z是W的主题;ϕ表示主题词分布.从图2 中可以看到,评论文本的潜在主题(打分偏好)分布与评分矩阵的潜在因子向量p(个人偏好)和q(商品特性)可以建立映射关系,即在上文中所描述的打分偏好可以映射到用户的个人偏好与商品特性上.本文采用TopicMF[13]中推荐效果较好的映射关系,如公式(1)所示.

其中,θi,j,k表示用户i对商品j在主题k上的概率,pi,k和qj,k分别表示用户i和商品j对应于主题k的潜在因子.θi,j,k与pi,k和qj,k成正相关关系.参数κ用于控制映射关系的权重,κ越大,意味着用户倾向于最重要的主题;κ越小,用户对所有主题倾向于同等对待.此外,θi,j,k即对应于图2 中的θi,j,pi,k和qj,k对应于图2 中的p和q.建立如公式(1)所示的映射关系后,不需要同时对θi,j,pi,k和qj,k这3 个参数进行拟合求解.在PreferenceMF 方法中,若先只考虑潜在特征同步学习,则需要最小化优化的目标函数参见公式(2),其中,Θ和Φ分别是评分矩阵分解和主题发现模型中的参数集合,Z是每一个词的主题,κ是映射关系公式(1)中的参数.

在公式(2)中,
•ri,j为评分矩阵分解模型的预测打分,如公式(3)所示.

•L(τ|θ,φ,z)即为LDA 主题发现模型的似然函数,一个文档集合主题模型的似然函数参见公式(4).

公式(4)中,τ是语料中的所有文档,ω是文档中的词,Nm表示m文档中的词数目,表示从文档-主题分布θm中采样的主题zm,j,表示从主题-词分布中采样得到词θm,j,相关细节和参数求解可参见文献[23].
可以看出,本文拟最小化的目标公式(2)本质上是用主题概率分布取代了传统评分矩阵分解中的正则化项,再通过公式(1)建立评论文本的潜在主题和评分矩阵的潜在因子之间的正向映射关系,从而达到潜在特征同步学习的目标.拟合求解公式(2)中参数的基本流程参见算法1 所示.
算法1.PreferenceMF 中潜在特征同步学习的参数求解基本流程.
输入:评分评论集合.
输出:公式(2)中的参数Θ,Φ,κ,Z.
1.评分评论集合的预处理,例如评论文本分词等
2.基于用户的评分构建评分矩阵模型LFM(公式(3))
3.定义每一条评论为一篇文档,构建LDA 主题发现模型(公式(4))
4.融合步骤2、步骤3 构建模型,生成误差目标函数(公式(2))
5.Gibbs 采样方法求解潜在主题参数(公式(4))
6.拟牛顿法求解目标函数中的参数(公式(2))
7.重复步骤5、步骤6,直到达到迭代次数
2.1.3 参数的拟合求解
在公式(2)中需要优化参数Θ,Φ,τ,Z,其中,Θ={μ,bi,bj,pi,qj},Φ={θ,φ}分别是评分矩阵模型中的参数和主题发现模型中的参数,然而,因为p和q与θ具有映射关系的约束,因此不能独立进行拟合求解,通过采用两步迭代方法进行求解,如公式(5)和公式(6)所示.
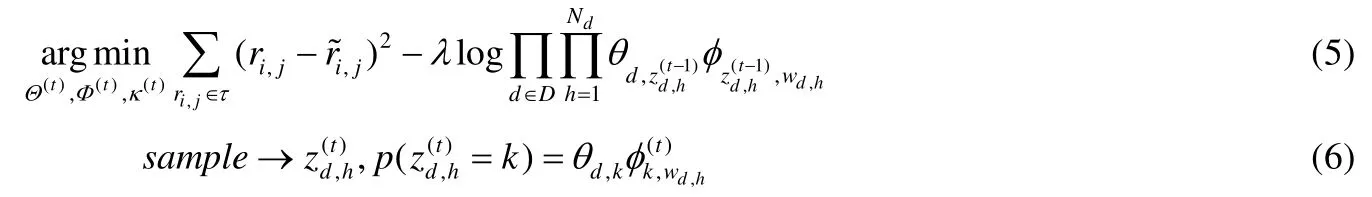
主题发现似然函数是通过单条评论作为文档进行输入,并建立隐性特征之间的映射关系.在公式(5)中,通过对参数求偏导数,使用拟牛顿法进行求解.公式(5)经过变换,见公式(7).

其中,d表示一个文档,D表示文档数,nd,k表示文档d中出现主题k的个数,其他参数可以参见前文描述的意义.为了能够使用拟牛顿法求解各个参数,需要求解未知参数的偏导数.μ,bi,bj可以在中求得,φ可以在求得.接下来需要从公式(8)中取得参数p,q以及控制参数κ的偏导数.

参数p,q和κ的部分重要偏导式如公式(9)~公式(11)所示.

从前面的阐述中可知,主题分布θ并非是从潜在狄利克雷分布中获取,而是从前一步中的Θ(t)得到.整个潜在特征同步学习算法的伪代码如算法2 所示.
算法2.潜在特征同步学习的参数求解.
输入:Ds评分评论集合.
输出:目标函数最小化而求得的局部最优参数解.
1. 分词等数据预处理
2. 得到评论文本corpus
3. 定义一条评论为一篇文档
4. 统计主题词等用于偏导计算
5. 当迭代次数小于主题模型参数求解的最大迭代次数时(公式(4)和公式(5))6. 当迭代次数小于梯度法迭代次数时
7. 构建误差目标函数f(公式(7)),f←lsq(W[NW]),W[NW]为优化参数数组
8. 拟牛顿法求解Lib-BGFS-Operation(f)
9. 重复步骤7 和步骤8,直到迭代次数不满足循环条件
10.重复步骤6~步骤9,直到迭代次数不满足循环条件
11.返回求解得到的参数数组W[NW]
2.2 PreferenceMF中的用户个性偏好引导
基于邻域影响的矩阵分解模型(SVD++)是在传统的矩阵分解模型中添加了邻域的影响,邻域可以看作是一种用户偏好引导项.此外,目前矩阵分解模型结合评论文本主要有两种策略:一种是从正则项来约束,另一种是通过文本信息来引导.融合了上述两种策略的方法得到了较好的推荐效果.本文提出的方法也是融合两种策略的方法,然而不同于目前已有的研究工作在于:引导项不是直接通过用户评论集合和商品评论集的主题分布进行引导,而是用第2.1 节中潜在特征同步学习中的映射关系进行引导,正则项使用公式(2)的主题正则约束.
潜在特征同步学习中,将单条评论文本的主题同步映射至打分矩阵的用户隐因子(个人偏好)和商品隐因子(商品特性),目标函数再通过与主题正则项结合,从而预测该用户对未打分商品的评分.本节在潜在特征同步学习的基础上考虑用户个性偏好引导,即在矩阵分解模型中引导潜在因子矩阵的计算.例如,用户潜在因子矩阵解释为用户在某一种潜在因素上的偏好,评论文本中又能反映用户的个人打分偏好,因此将评论中发现的个人打分偏好融合进潜在因子矩阵更能够反映用户的真实偏好.本节基于前面的潜在特征同步学习,再进一步添加基于主题引导的融合方法,得到完整的PreferenceMF 方法.它以每一条评论文文档进行主题发现,将其映射到引导项,并将主题概率分布添加到正则约束中,PreferenceMF 的参数逻辑关系如图3 所示,参数的含义同图2.
本文定义符号yi表示用户的个人偏好向量,即从评论文本中学习得到的潜在主题分布,用于引导潜在因子向量,得到预测评分公式,参见公式(12).

其中,μ表示所有评分记录的全局平均值,作为整体模型的偏置;bi和bj作为用户偏置和商品偏置.考虑到在实际的评分情况中存在一些固有的特性是和用户或物品没有直接关系的,例如某些商品由于装饰和布局等等因素,用户的评分往往是高分.相反,有些商户的商品通常是低分.另外,用户自身也存在着差异,存在着一些用户习惯于给高分,另一些用户习惯于给低分.同理,在物品上,有些物品的质量较高,样式较好,通常都是高分;然而另一些则通常是低分.因此,为了能够体现这些特性,在模型中考虑添加了偏置项μ,bi和bj.

Fig.3 Logic relation diagram of parameters in PreferenceMF图3 PreferenceMF 的参数逻辑关系图
公式(12)中的pi和qj分别表示用户和商品潜在因子向量,用户的个人偏好yi与潜在因子向量pi和qj的映射关系与主题分布映射θi一样,参见公式(1).再继续加入主题偏好作为正则项,得到拟优化的目标函数,整合后参见公式(13)所示.

其中,θ,φ,z表示LDA 主题发现模型中的参数,与p和q的映射关系同公式(1).求解公式(13)可以通过求解各参数的偏导数,最后通过梯度下降法或拟牛顿法求解,流程和参数求解与算法1 和算法2 类似.
3 实验结果与分析
本节首先介绍实验数据和评价指标,然后通过对比本文的PreferenceMF 方法与已有方法在推荐质量上的差异,对实验结果进行分析和讨论.
3.1 数据集
本文使用的数据集取自于Amazon.com 电商网站,该数据集的主要内容是用户对该网站商品的打分、评论及评论的用户有用性反馈.数据的评分与评论的时间跨度是1994 年6 月~2013 年3 月约为18 年,大小约为3.3GB,共约3 500 万条评论数据,统计数量见表2.

Table 2 Dataset statistics表2 数据集统计信息
在整个数据集中按照该电商网站的商品分类,共抓取了28 种类别.每一条样本中包含有如下字段:商品标识、商品名称、商品价格、用户标识、署名、有用性反馈、评分、时间、评论标题文本、评论正文文本.实验中,为了更好地提升推荐质量,对评论文本进行了预处理,包括分词(本文使用IKAnalyzer)、去停用词、去噪等.将数据集按4:1 随机划分为训练集和测试集,进行了20 次的交叉验证,将平均值作为最终结果.由于实验在单机下完成,因此对28 组子集中大于1GB 的数据子集进行随机抽取.硬件配置为CentOS6.5,4 核Intel CORE i5 CPU,8GB 内存,使用C/C++语言实现.
3.2 评价指标
当预测输出为实数值时,通常用于评估推荐模型的指标有均方根误差(RMSE)、均方误差(MSE)和平均绝对值误差(MAE)等,都是计算预测值和真实值之间的误差.为了与对比算法[12,13]在同一评估方法下进行对比,本文采用MSE 作为推荐模型的评价指标,定义如公式(14)所示.

其中,TestSet表示测试样本集,|TestSet|表示样本集数目.MSE 值越小,表示系统的推荐质量越好.同时,RMSE 是MSE 开根号后的值,而MSE 为MAE 的平方,因此它们对推荐质量的评价与MSE 的保持一致.
3.3 评分数据的稀疏性分析
如果将电商平台中用户对商品的评分构成一个矩阵,则其规模巨大,且用户数量和商品数量都在不断地增加.然而每一个用户购买的商品总数相对来说只占很少一部分,矩阵中大部分的元素都为0,只有较少的用户评分和评论数据能够用于模型计算,这个现象被称为数据的稀疏性.本文对Amazon 全部子集中评分数据的统计结果表明其确实具有稀疏性,如图4 所示,其中,横坐标代表不同类别的数据集,纵坐标代表评分个数占商品总数的比例.

Fig.4 Data sparsity of item ratings in Amazon datasets图4 Amazon 数据集中商品评分稀疏性
例如,在图4 中,Arts 数据集中具有4 211 件商品,其中75.3%的商品评分少于5 个,87.1%少于10 个,94.3%少于20 个;Automotive 数据集中具有47 571 件商品,其中87.7%的商品少于5 个,93.8%少于10 个,97.1%少于20 个等等.总体来看,平均75.3%的商品评分少于5 个,平均85.3%的商品评分数量少于10 个,平均92.1%的商品评分数量少于20 个.上述统计结果表明,在评分评论数据集中,评分的数据具有稀疏性,将影响矩阵分解模型的预测评分准确性.以往的研究使用数据初始化填充,基于内容的推荐等来缓解该问题.本文考虑融合评论文本的数据,对商品评论文本中单词的统计量结果如图5 所示,横坐标代表不同类别的数据集,纵坐标代表评论文本单词个数占单词总数的比例.
图5 反映了每种商品的评论单词的数量,例如,在Arts 数据集中,67.1%的商品评论中词数大于20,42.5%的商品评论中词数大于50;Automotive 数据集中,60.5%的商品评论中词数大于20,31.1%的商品评论中词数大于50;Baby 数据集中,84.5%的商品评论词数大于20,66.1%的商品评论中词数大于50.总体来看,平均统计后得到71.99%的商品评论中词数大于20,47.33%的商品评论中词数大于50.统计结果表明,文字性的评论文本能够从不同方面反映用户和商品特性,有助于缓解数据的稀疏性问题.因此,可以对评论文本内容加以利用,并融合到传统的评分数据中.
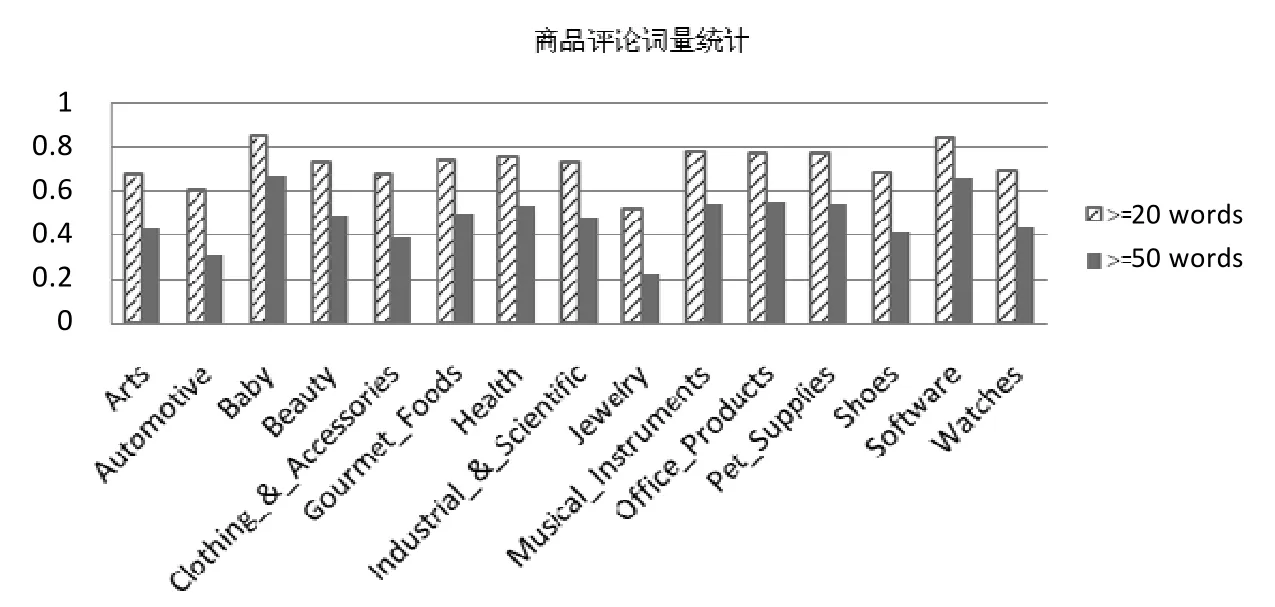
Fig.5 Word statistics in the item reviews of Amazon datasets图5 Amazon 数据集中商品评论词量统计
3.4 推荐方法结果对比
3.4.1 对比方法
本文提出的PreferenceMF 方法与以下4 种传统方法进行实验对比.
(1)Offsets 方法将直接采用全局偏置,即用户评分的平均值作为预测.这是最简单的预测方法,作为对比的基准方法.
(2)LFM(latent factor model),隐因子分解方法[9].通过矩阵分解方法进行未知商品的评分预测.此方法中没有应用到用户的评论文本信息.
(3)HFT(user)和HFT(item)方法[10],融合评分与评论文本的推荐方法.将评论划分为某用户的全部评论集或某商品的评论集作为LDA 主题模型的处理对象,得到的主题与LFM 矩阵分解中的用户潜在因子或者商品潜在因子进行融合.
(4)TopicMF 方法[11],面向全部评论集,得到每一条评论的主题分布,将主题概率分布添加LFM 矩阵分解的正则项中,其核心思想是,通过每一条评论的主题分布去正则化LFM.
(5)PreferenceMF 方法,为本文提出的优化模型.以每一条评论文文档进行LDA 主题发现,将主题偏好作为用户潜在因子的引导项,并将主题概率分布添加到正则约束中构建融合推荐模型.
3.4.2 对比结果
实验结果表明,潜在因子数K等于5 或者10 以上时,大部分方法的误差趋于稳定.此外,主题正则权重参数经过实验也选取了结果较优的参数值.因此,本文采用K=5,正则参数λ=0.5.对上述方法进行20 组交叉验证,得到平均MSE 结果,如图6 所示.

Fig.6 Results of six recommendation approaches in terms of mean square error (MSE)图6 6 种推荐方法平均均方误差(MSE)结果
从图6 中6 种推荐方法的比较结果可以发现,本文中提出的PreferenceMF 方法MSE 值最小,将没有考虑用户偏好引导的TopicMF 方法的误差降低了0.91%,并且与offsets,LFM 以及HFT(user)相比优势明显.
上述6 种方法可以分为3 类:第1 类是非矩阵分解方法(offsets),第2 类是潜在因子矩阵分解模型(LFM),第3 类是融入了评论文本信息的潜在因子矩阵分解模型(HFT(user),HFT(item),TopicMF,PreferenceMF).
第1 类方法没有采用基于潜在特征的矩阵分解,第2 类方法是使用了矩阵分解方法.从结果上来看,矩阵分解方法推荐质量较高,减少了预测评分误差.从理论上看,矩阵分解得到的潜在因子为高层特征,反映了有用户历史信息的偏好,这对于预测未评分的用户有显著的积极作用.
第3 类方法融入了评论文本主题,差别在于融合的方法以及融合程度,以及在评论文本主题挖掘上的不同.TopicMF 方法以单条评论为一篇文档进行主题发现,与用户和商品隐因子矩阵同时融合,比仅融合用户偏好的HFT(user)方法更优.本文提出的PreferenceMF 不仅将主题发现融合到潜在因子分解矩阵,而且用主题分布作为偏好引导项,其优点在于同时考虑了用户偏好和商品特性.
3.4.3 数据子集上的对比结果(融入评论文本的方法)
本文提出的PreferenceMF 方法添加入用户偏好的引导,以MSE 作为评估方法,在28 组Amazon 的数据子集上进行了实验,结果同HFT(user),HFT(item)、TopicMF 这3 种融入了评论文本的推荐方法进行了比较,并给出相对于TopicMF 的预测评分误差减少的比例,见表3.

Table 3 Comparison of PreferenceMF with other recommendation approaches using review text (MSE)表3 PreferenceMF 与其他融入评论文本的推荐方法比较(MSE)
从表3 中可以看到,带有偏好引导的PreferenceMF 方法在16 组数据子集上优于其他3 种融合方法,最大提升了3.32%.PreferenceMF 的平均MSE 相对于TopicMF 的平均MSE 提高了0.92%.同时,通过计算可知,相对于HFT(user),PreferenceMF 提升了2.32%;相对于HFT(item),PreferenceMF 方法提升了0.68%.综上可知,同时添加主题偏好引导和主题正则化项的PreferenceMF 推荐质量最优.
3.4.4 数据子集上的对比结果(未融合评论文本的方法)
从图4 中可以看到,融合评论文本的方法比没有融合评论文本的方法推荐质量要高.本节对没有融合评论文本offsets 和LFM 两种方法进一步对比.基于全局偏置的Offsets 方法,是通过商品的平均值作为该商品的预测值,即用户i对商品j没有打分,使用商品j所有打分的平均分来预测.LFM 方法采用的是带有偏置的SVD 模型,如公式(15)所示.

公式(15)的参数含义与公式(12)一致,模型使用随机梯度下降法(SGD)求解在Amazon 不同数据子集上Offsets 和LFM 方法的结果见表4.
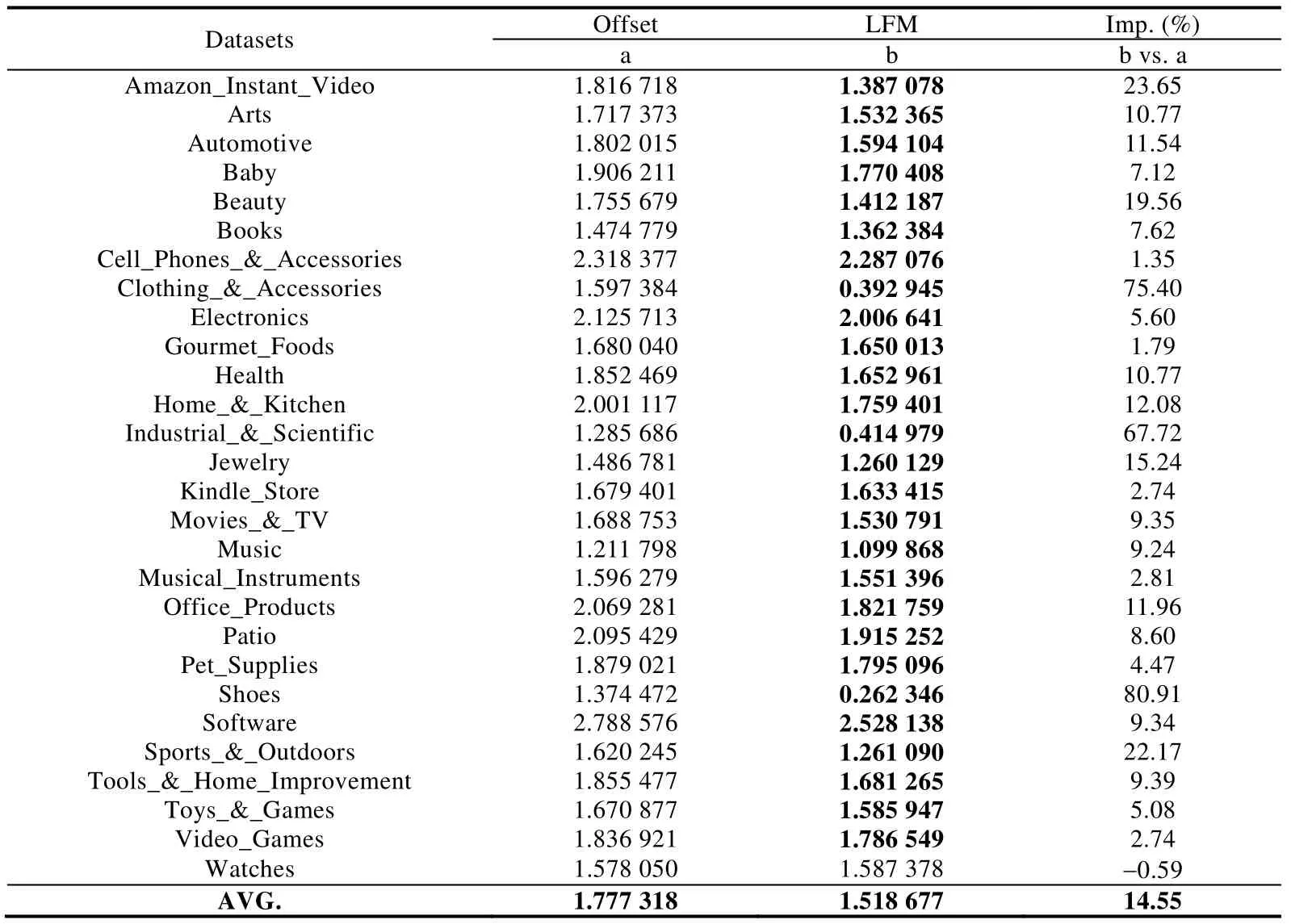
Table 4 Comparison experimental results of offsets and LFM without using review text (MSE)[3]表4 不考虑评论文本的Offsets 和LFM 的实验结果比较(MSE)[3]
表4 中粗体表示MSE 的值最低.从表中可以看出,基于矩阵分解的方法在几乎所有子集合上(除watches 子集合外),都比基于全局偏置的Offsets 方法更优,将Offsets 方法的均方误差减少了14.55%.因此可以得出结论,潜在因子矩阵分解模型是推荐质量较好的方法.
3.5 实验结果分析
从上面的实验结果可以看出,本文提出的PreferenceMF 方法在整体上表现最优.我们对上述实验中的6 种方法进行归纳总结如下.
•没有融入评论文本的Offsets 和LFM 方法推荐质量不如融入评论文本的方法、基于矩阵分解的LFM优于Offsets.
•HFT(user)方法是将用户评论文本的主题分布与用户评分矩阵的潜在因子向量构成映射关系,融入到训练模型中,它考虑到了用户偏好对用户评分的影响.
•HFT(item)方法是以商品特性分布与商品潜在因子向量构成映射关系,融入到训练模型中.文献[12]中指出,用户在对商品打分时关注商品特性多于关注自身的偏好.实验结果表明,HFT(item)效果优于HFT(user).
•TopicMF 方法是更换了主题发现的评论集主体,采用单条评论作为主题模型的输入.而HFT(user)和HFT(item)的对主题偏好的学习是通过整体评论集使用主题发现,定义了主题偏好分布与用户潜在因子向量和商品潜在因子向量的映射.实验结果表明,TopicMF 方法均优于HFT(item)和HFT(user),单条评论能够更精准地表达某用户对某商品的个性偏好.
•本文提出的PreferenceMF 是在TopicMF 基础上加入了主题偏好的引导.经过实验验证,该引导项可以进一步提升推荐质量.后续有待进一步研究该方法在解决冷启动问题的能力.
4 总结和展望
本文提出了融合评分与评论文本的推荐方法,即加入了偏好引导的PreferenceMF 方法.从不同角度进行分析后,给出了模型的数学表述形式和参数拟合求解的算法.最后,在28 组Amazon 数据子集上与多种相关的推荐方法进行实验对比,结果表明,本文提出的PreferenceMF 方法的推荐质量相对于目前主流的方法有进一步提升.并分析了各个方法的实验结果以及存在的问题.今后可以对隐因子数量和映射关系做进一步研究.本文在融合方法中假设主题发现的主题数量与潜在因子数相等,并且具有相同的权重,可以考虑不同权重的情况.在解决数据稀疏性、模型冷启动和长尾现象等问题上,都有待进一步展开研究.此外,本文是从最大化似然的角度来使推荐模型适应数据,今后可以采用贝叶斯估计,从最大化后验分布的角度来对模型进行建模和求解.
猜你喜欢
西北林学院学报(2022年5期)2022-10-04
昆明医科大学学报(2022年3期)2022-04-19
昆明医科大学学报(2022年2期)2022-03-29
中等数学(2020年1期)2020-08-24
小学生优秀作文(低年级)(2020年5期)2020-07-25
华人时刊(2018年17期)2018-11-19
读与写·教育教学版(2017年10期)2017-11-10
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
