
基于模糊聚类的大学生网络情感分析研究
2019-12-10 09:48仲伟伟刘丽萍汪方正
电脑知识与技术 2019年28期
仲伟伟 刘丽萍 汪方正

摘要:正值于青少年时期的大学生很容易受到各种外界因素的影响,导致心理情绪波动较大。特别是进入21世纪以来的大学生大多都是独生子女,通常具有感情色彩丰富、心理较脆弱的特点,如果长期处于一种负面情绪的状态则很有可能会引发一些极端的不良事件,因此维护大学生的心理健康成为高校教师的重点工作。而传统的心理测评往往容易受到主观条件的影响不能准确和及时地反映当前学生的心理问题,本文结合当前互联网大数据时代的特征,提出一种利用模糊聚类算法对大学生在微博等网络社交平台的文本状态进行情感分析的方法,旨在能够及时有效地发现学生的心理健康问题避免不良的影响。
关键词:模糊理论;聚类算法;大数据;情感分析;人工智能
中图分类号:G434 文献标识码:A
文章编号:1009-3044(2019)28-0226-03
Abstract: College students who are in adolescence are very susceptible to various external factors, resulting in greater fluctuations in psychological mood. In particular, most of the college students who have entered the new century are only children. They are usually characterized by rich emotions and psychological weakness. If they are in a state of negative emotion for a long time, they are likely to cause some extreme adverse events. Mental health has become a key task for college teachers. However, the traditional psychological assessment is often susceptible to subjective conditions, which can not accurately and timely reflect the current students' psychological problems. This paper combines the characteristics of the current Internet big data era, and proposes a fuzzy clustering algorithm for college students to socialize on Weibo and other networks. The method of emotional analysis of the textual state of the platform aims to be able to timely and effectively discover the mental health problems of students to avoid adverse effects.
Key words: Fuzzy theory; Clustering algorithm; Big data; Sentiment analysis; Artificial intelligence
1 引言
目前我国高校大学生的心理健康问题正日益成为社会关注的焦点,当代大学生正处于一个心理素质快速成长的青少年阶段,他们的思想开放又活跃、同时情感色彩丰富且表达愿望强烈。但是心理上的不成熟通常使他们容易受到外界因素的影响而导致情绪失常,例如失恋、考试以及就业压力等都会对大学生造成一定程度的负面影响,如果不能及时做出自我调整往往会形成抑郁和焦虑等心理健康问题,以至于频频出现大学生自杀新闻,甚至发生马加爵事件和复旦投毒案这样对社会造成严重影响的恶性案件,因此心理健康教育成为广大教育工作者的重中之重。
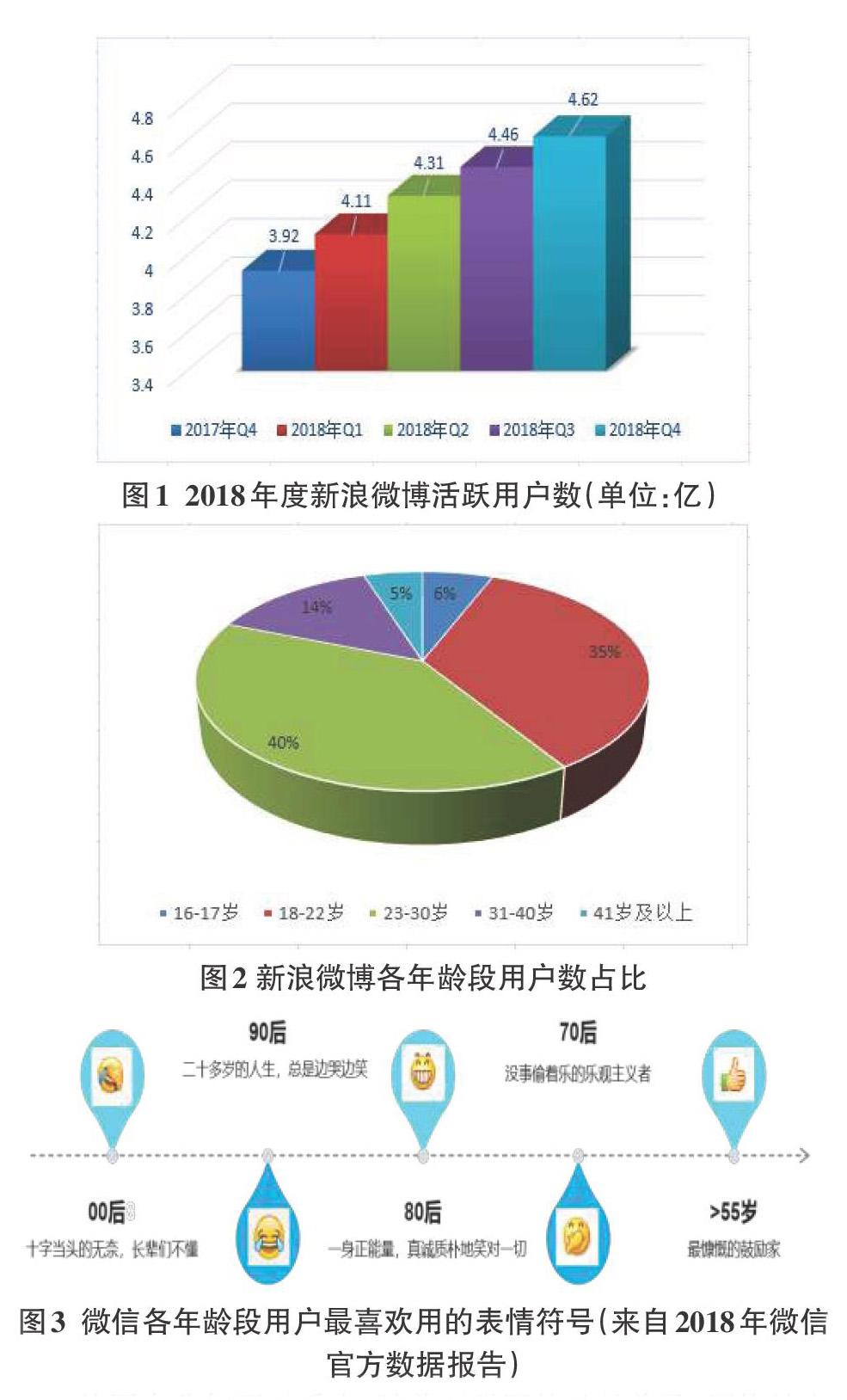
情感是心理学中的一个重要概念,是人对客观事物是否满足自身需要而产生的一种态度体验,能够反映出在某个特定时刻某人的心理状态[1]。人类之所以区别于动物或者机器,很大程度上是因为人类善于表达自身的七情六欲,高兴的时候笑逐颜开,伤心的时候郁郁寡欢,生气的时候又咬牙切齿。而在互联网时代,人们更多的会在微博、微信朋友圈或者QQ空间等网络社交平台表达自己的情感,下图是来自于2018年新浪微博和腾讯微信官方的用户数据报告:
从图中我们可以看出,随着互联网的日益普及,网络社交平台的用户数逐渐增多,截至2018年第四季度新浪微博的活跃用户数已经达到4.62亿,同时在活跃用戶的各年龄段数量占比中18-22岁以及23-30岁的人数最多。这在客观上反映了在校大学生以及刚毕业初入社会的职场青椒们更喜欢在社交平台上分享自己生活中的各种喜怒哀乐,而从整体数据上也可以看出他们相对于中年人朴素乐观的心态使用更多的是无奈和苦笑的表情。
针对网络社交平台上海量的文本信息,使用传统的人工识别方法显然不能实时和有效地掌握大学生的情感动态。因此,利用大数据的技术手段从海量文本信息中挖掘出带有感情色彩的词语进行智能的情感分析具有重要的研究意义,本文通过数据挖掘中经典的聚类算法来对大学生网络社交平台中的文本进行情感分析,提出一种能够及时有效地发现学生心理动态的技术方法和预警机制。
2 基于模糊聚类的情感分析方法
当我们在微博或者朋友圈中更新一条状态或者发表一段评论时,通常会通过文本或表情符号等形式表达自己的情感信息,而将文本中的情感词进行量化并计算出整段文本的情感值就是情感分析的目的。然而中文文本中的情感词汇很丰富,还包括的大量的否定词和修饰词等,具有一定的模糊性和不确定性,难以准确地计算出整段文本的情感值,因此本文将文本识别技术与模糊理论思想结合,计算出每个情感词隶属于基本情感种类的隶属度,关键的步骤如下:
2.1 文本中情感词和表情符号的提取
首先是网络情感词典的构建,其中基础情感词主要源自著名的HowNet在2007年发布的情感分析专用词语集,该文件中共收录了17887个中英文情感词,其中中文部分包括219个“程度级别”词汇、3116个“负面评价”词汇、1254个“负面情感”词汇、3730个“正面评价”词汇、836个“正面情感”词汇以及38个“主张”类词汇;网络情感词典的另一部分则是由心理学领域的专业词汇以及社交平台中出现频率较高的网络热词组成,如“宽心”“中年油腻”“戏精”等等;表情符号则选取了微博和微信中的最常用的基础表情,包括“哈哈”“鼓掌”等37个正面表情以及“怒火”“伤心”等49个负面表情。
其次是文本中情感词的提取,先是利用文献[2]中基于专家系统的中文分词技术,该技术采用首字索引的数据结构在实验中精确度达到99%以上,然后将分割的词汇与网络情感词典进行比对,如果匹配到,则标记为情感词;如果匹配不到,则不参与情感计算。
2.2 情感词和表情符号的量化处理
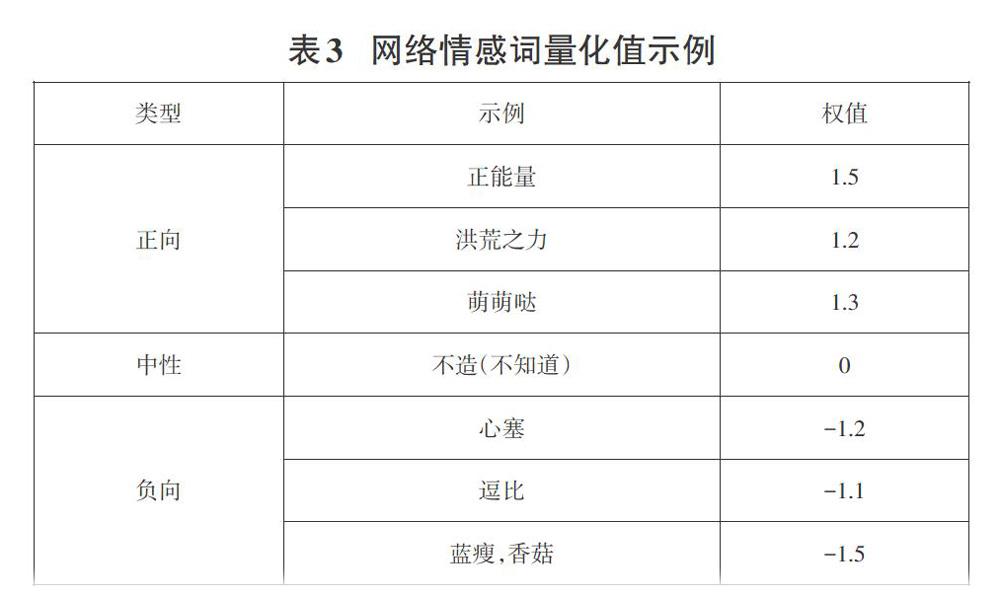
网络社交平台的文本内容通常比较简短,且一般是非书面语言,因此存在大量的修饰词或表情符号,这些词语对文本情感的判断很重要,在情感计算中占有很大的比重,例如“今天心情非常好”与“今天心情还算好”的修饰词不一样,所表达的心情好的程度也完全不同,另外如果在文本末尾加上一个“苦笑”的表情往往使前面的语句带有一定的反语性质。因此不仅需要对基础情感词典中词语进行量化,还需要对程度副词、否定词以及表情符号等进行量化。在计算过程中如果情感词带有程度副词或者否定词等,则需要乘以相应的系数;如果没有则权值不变,最后将所有情感词的权值相加就可以得到整段文本的情感值。
2.3 模糊聚类分析
客观世界中的绝大多数现象都会随着时间或环境的改变而产生相应的变化,具有一定的不确定性,模糊聚类分析就是利用模糊理论的思想建立一个隶属度矩阵,从而比较真实的反应样本之间似是而非的隶属关系。目前最经典的模糊聚类算法是1974年由Dunn[3]提出并由Bezdek[4,5]加以推广的模糊C-均值(fuzzy C-means,简称FCM)算法。
FCM算法的基本思想是用X={x1, x2, …, xn}来表示测试样本集的n个数据 ,并假设这些样本可以形成c种不同的类簇,通过随机初始化程序生成这些聚类中心,并用V={v1, v2, …, vc}的形式来表示他们。接着算法开始用欧氏距离计算测试集中的每个样本对所有初始聚类中心的隶属度,构造出一个隶属度矩阵,然后利用隶属函数不断地进行迭代计算出新的聚类中心,最后的终止条件是使目标函数的值达到最小。目标函数为:
[F(U,V)=j=1ni=1c(umijxj-vi2)] (1)
其中,m为模糊指数;U={[uij]}是隶属度矩阵,表示第j个样本属于第i个聚类中心的隶属度,
[uij=1/k=1c(dij/dkj)2/(m-1)](其中dkj[≠]0) (2)
其中[dij=xj-vi]是对象xj到聚类中心vi的欧式距离。约束为:0<[uij]<1且[i=1cuij=1],[i≠j]。聚类中心设置为:
[vi=j=1nxjuijmj=1nuijm] (3)
模糊C-均值算法具體步骤如下:
(1)设定聚类数目c和参数m,算法终止阈值[ε],迭代次数t=1,允许最大迭代数为tmax;
(2)初始化各个聚类中心vi;
(3)用当前聚类中心根据公式2计算隶属函数;
(4)用当前隶属函数按公式3更新各类聚类中心;
(5)选取合适的矩阵范数,如果[vt+1-vt≤ε]或[t≥tmax],停止运算;否则t=t+1,返回(3)。
通过以上步骤最终可以计算出每个类的聚类中心以及所有样本对于每个聚类中心的隶属度矩阵,通过不断地迭代优化使得样本点逐渐接近其隶属度最大的一个类中。
3 在大学生网络社交平台中的情感分析应用
基于模糊聚类的大学生网络情感分析过程如图4所示。首先,利用谷歌爬虫软件从已注册大学生的微博等社交平台获取原始的文本数据;其次,对抓取的文本内容进行预处理,获得文本中的情感词,并进行量化形成有利于聚类分析的数值形式;然后,使用模糊聚类算法对待检测的文本数据进行聚类分析,形成若干个不同的情感类簇(如正面情感、负面情感、正面评价、负面评价或是主张等);最后,通过聚类分析得到的结果,对较多或长时间处于负面情感以及负面评价的网络账号进行预警,必要时对学生进行有效的心理或学习生活上的帮助。
在聚类分析时还需要先将情感值进行标准化处理,通过公式4使得所有样本的情感值数据分布在[-1,1]的区间内,其中Xi为原始数据,Xmax为样本绝对值最大的,Xmin为样本绝对值最小的。如果是正向情感值,则标准化处理后在(0,1]之间;如果是负向情感值,则将样本数据取绝对值后经过标准化处理再乘以-1使得情感值在[-1,0)区间。通常我们根据实际分类,将文本情感值范围在[0.3,1]区间的定义为正面情感类别,而文本情感值范围在[-1,-0.3]区间的定义为负面情感类别,另外情感值范围在(-0.3,0.3)之间的则为中性情感类别。
4 總结与展望
随着互联网的日益普及,社交网络成为各类人群与外界沟通的桥梁,是我们展示生活状态或情感交流的重要平台。面对日益严峻的大学生心理健康问题,传统的心理调查方式很难及时准确地测出学生的实时情感状态,本文采用数据挖掘中经典的模糊聚类算法对大学生在网络社交平台的信息进行情感分析,提出一个针对社交平台的大学生心理情感分析方法和预警机制,从而充分发挥大数据的技术优势保障大学生的心理健康。
然而在进行大规模数据的聚类计算时,模糊聚类算法的迭代次数较多,计算量很大会严重影响系统的分析性能[6]。因此我们还需要研究基于云平台的MapReduce框架将本文算法做进一步的分布式改造[7,8],充分利用云平台的海量数据计算能力,提高整体系统的实时数据处理能力。
参考文献:
[1] 韩雪.论大学生职业生涯规划中心理健康教育的运用[J].科技咨讯,2018,16(20):220-221.
[2] 朱世猛.中文分词算法的研究与实现[D].电子科技大学,2011.
[3] J.C.Dunn.Agraph theoretic analysis of pattern classification via Tatnuras fuzzy relation. IEEE Trans.SMC,1974,4(3):310-313.
[4] J.C.Bezdek.A convergence theorem for the fuzzy ISODATA clustering algorithm.IEEE Traps.PAMI,1980,1(2):335-340.
[5] 李洁,高新波,焦李成. 基于特征加权的模糊聚类新算法[J].电子学报.2006,34(1):89-92.
[6] 余晓东,雷英杰,岳韶华,等.基于粒子群优化的直觉模糊核聚类算法研究[J].通信学报,2015,36(5):74-80.
[7] 张晓丽,杨家海,孙晓晴,等.分布式云的研究进展综述[J].软件学报,2018,29(07):2116-2132.
[8] 王志刚,蒲文彬,滕鹏国.云计算下数据安全存储技术研究[J].通信技术,2019,52(02):
471-475.
【通联编辑:王力】
猜你喜欢
现代电子技术(2016年23期)2017-01-12
预测(2016年5期)2016-12-26
