
一种基于用户偏好的移动计算卸载决策算法
2019-12-09 03:24:56蒋青苗
中国传媒大学学报(自然科学版) 2019年5期
蒋青苗
(中国传媒大学 信息与通信工程学院,北京 100024)
1 引言
智能手机是科技时代的产物,它的普及改变了人们的生活方式。智能手机承载的诸多应用几乎渗透进人们生活的各个方面,例如手机导航、电子支付、网上购物等,使得手机用户在移动状态下也可享受各种服务,掌握各种信息。而在智能手机越来越丰富的功能背后,是云计算、边缘计算等计算模式在默默地提供着技术支持[1]。云计算、边缘计算是高效和灵活的计算模式,并基于移动互联网而存在。将云计算、边缘计算等计算模式与计算卸载技术相结合,通过互联网将智能手机端中的计算密集型应用程序传输到服务器端运行并返回结果,称为移动计算卸载。移动计算卸载技术可以显著地缩短智能手机应用程序的执行时间,减少智能手机的能量消耗,保证智能手机的流畅运行,大大提高手机用户的使用效率。其中,移动计算卸载决策算法是移动计算卸载的关键,负责对智能手机(移动端)中的应用程序进行划分,程序划分的结果直接影响着移动计算卸载的最终优化效果。
绝大多数的移动计算卸载决策算法在决策参数的考虑方面,只取决于应用程序的特性,如输入数据量的大小,占用的内存,应用程序的输出精度,以及终端的处理能力,包括移动终端CPU的频率、移动终端存储器的容量,移动终端运行时的资源占用率以及终端所处环境的网络时延等[2]。在只考虑这些客观因素的条件下,却忽视了用户的个性化需求。不同的用户对手机的使用情况不同,例如重度游戏玩家对游戏的流畅度更加重视,在使用移动终端玩游戏时由于希望获得更好的网络带宽,可能不倾向于进行计算卸载;而商务型的手机使用者会对手机的待机时长有一定的期望,且比较频繁使用网络进行通讯,因此更倾向于进行计算卸载。因此,不同用户的个性化需求也有必要在计算卸载决策中得到一定程度的满足。
本文以改善移动计算的个性化需求为目的,结合机器学习算法设计了一个用户兴趣分布模型,深度研究用户的个性化需求,从而使移动计算可以为用户提供个性化的服务。通过预测用户对于手机的使用需求,将此预测结果对移动计算的卸载策略进行优化,“对症下药”地提供个性化的计算卸载服务,以此来提升用户体验。
本文其余的部分如下:第二节介绍移动计算卸载算法的相关研究;第三节提出基于用户个性化需求的卸载模型;第四节阐述基于用户个性化需求的卸载算法;第五节对算法进行测试和性能评估;第六节总结本文的内容。
2 相关研究
根据优化目标的不同,移动计算卸载决策算法的研究可分为三类:
2.1 缩短执行时间的卸载决策算法
Liu J等[3]研究了单个移动终端将计算密集型任务卸载到边缘云的问题,将该应用场景下的计算任务调度策略归纳为双时间尺度随机优化问题,将任务的传输模型看做缓冲区队列,计算任务的调度采用在缓冲区排队的方法,根据本地处理单元的状态和传输队列的状态共同决定调度策略。提出的卸载算法的优化目标是在最小化任务的平均延迟的情况下,保证移动设备的平均功率不超过最大平均功率阈值。Mao Y等[4]针对一个带有能量收集(EH)设备的绿色边缘云系统开发一种有效的计算卸载决策算法。将执行成本,包括任务执行延迟和任务失败成本作为性能指标。将执行成本最小化(ECM)问题归纳为高维马尔可夫的决策问题,提出了一种低复杂度的,基于Lyapunov优化的动态计算卸载决策(LODCO)算法。
2.2 节约能耗的卸载决策算法
Kamoun M等[5]研究了改造后能支持云服务功能的基站的计算卸载问题,问题的主要目标是通过找到最佳调度卸载策略来做出决策,使移动用户终端在规定的应用程序最大容忍延迟的约束之下的能量消耗最小化。并提出了两种离线的计算和无线电资源的资源卸载策略。Sardellitti S等[6]研究了在一个MIMO多小区系统中,有多个移动用户(MU)要求将计算任务卸载到一个公共云服务器的问题。论文将该计算卸载问题归为包含无线电资源,移动用户发送的预编码矩阵,计算资源,以及由云分配给每个移动用户的CPU频率的联合优化问题,以便在满足延迟限制的同时,最小化整体移动用户的能量消耗。论文[7]考虑了多个移动用户将计算任务通过多个无线电接入点卸载到多个云服务器的应用场景,将计算卸载问题归纳为无线电和计算资源的联合优化问题,优化目标是使在移动终端侧总能量消耗最小化,同时满足延迟约束。
2.3 权衡能耗与时延的卸载决策算法
Chen X等[8]建立数学模型研究了多个信道无线环境中移动边缘云计算的多用户计算卸载问题,考虑噪声的影响。将无线环境下的移动设备用户之间的分布式计算卸载决策问题看做多用户计算卸载博弈问题,并针对该问题设计了一种基于分布式的计算卸载算法,该算法可以达到纳什均衡。Chen M H等[9]考虑了移动云计算场景,场景内包括了一个具有多个独立任务的移动用户,一个计算接入点和一个远程的云服务器。提出了一种基于半定松弛的有效卸载决策算法,以及一种新的随机映射方法来降低能源,计算和延迟三个指标的综合成本。Muoz O等[10]研究了利用传输速率和系统负载控制多用户通过无线信道进行计算卸载的优化问题,讨论了无线应用程序卸载中的执行延迟和能量损耗之间的权衡。提出了一种改变上行链路数据速率的方法,通过调整此速率以在给定当前系统负载的情况下,最大化移动用户的QoS来实现移动终端的节能。
3 基于用户个性化需求的卸载模型
本小结提出了基于用户个性化需求的计算卸载决策算法的模型框架,阐述了用户个性化需求模型的构建思路和方法。
3.1 用户个性化卸载模型框架
为了将用户的个性化需求纳入到移动计算卸载决策算法的决策参数中,我们设计了如图1所示的基于用户个性化的计算卸载决策模型框架。
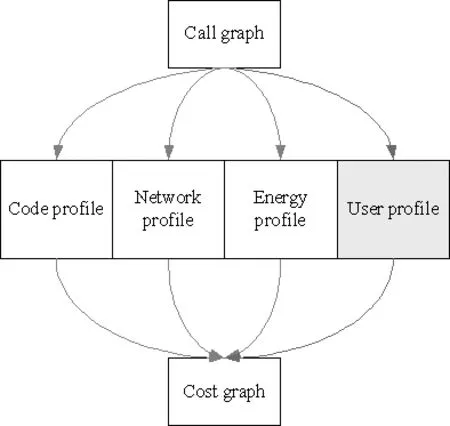
图1 基于用户个性化需求的计算卸载模型
模型的输入是移动终端应用程序的调用关系图(Call graph),调用关系图反映了应用程序源代码中的各实体,如函数(method)、进程(process)、线程(thread)的相互依赖关系。调用关系图经过Code profile、Network profile、Energy profile和User profile四个模块,分别提取代码调用关系,网络状况,能量消耗状况,以及用户个性化需求对卸载决策的影响大小,最终输出一个定义为Cost graph的无向连通网络图。
3.2 用户个性化需求模型的构建
Code profile、Network profile、Energy profile分别采集移动应用程序的运行时间、网络状态、能量消耗等客观信息[11]。
对于User profile模块来说,由于其采集的是用户偏好,一般很难量化。本文中采用了基于机器学习的方法来训练用户个性化需求模型,以更好地描述用户偏好。我们使用机器学习算法训练的模型的概率估计来产生权重,用来预测特定用户对程序执行时间,网络通信延迟,能量消耗的重视程度。由于不同的用户对这些性能参数有不同的关注,该模型能够提供更加个性化的计算卸载决策参数和更加智能的计算卸载决策划分结果。以下我们将详细说明数据集的收集和模型的构建过程。
用户个性化数据的收集主要采用了调查问卷的方法。首先,将个性化卸载需求模型与用户的使用偏好挂钩,按照用户的使用习惯及兴趣爱好,设计调查问卷。问卷主要从用户使用手机时关注的耗电量、使用时的流畅度、CPU性能、内存大小、隐私安全保密性、信号的移动接收能力等几个方面展开。着重调查用户使用最频繁的APP类型,每天平均使用手机的时长,常驻后台应用个数,手机垃圾与缓存的清除频率以及使用状态(是否经常在高速移动中使用)。从以上问题中可以了解用户的使用习惯以及使用环境。问卷还设置了辅助的问题,以便更全面地了解用户的个性化需求。包括用户在手机过热时的处理方式,使用时能容忍的延迟上限,充电的频率以及对隐私安全的重视程度(这里主要指将数据同步至云端)。具体调查问题如下:
(1)您每天平均使用手机时长为?(2)您经常使用的手机APP应用类型为?(3)您平时常驻后台应用个数为?(4)您平均多久清理一次手机垃圾或应用缓存?(5)当手机使用过热时,您会?(6)您能容忍的延迟上限?(7)您的手机平均多久充一次电?(8)您在使用手机应用时,会考虑隐私安全问题吗?(9)您平时使用手机的地点?(10)对于手机,您最关注什么?
问卷在设计过程中,力求客观与全面,问题的排列结合应答者的思维逻辑,结构比较合理。问题的设置比较通俗易懂,为了使应答者愿意作答,题目在长度设计中力求一目了然。考虑到答卷者普遍不会有耐心回答过于冗长的问题,问卷在设计时,将问题数量筛选到10个,每个问题都简洁明了。以此避免因题目过多过长而乱答的现象,保证数据的准确性。在题目以及选项的设计中,还考虑到了后期的统计工作,尽量做到用最少的变量来解决更多的问题。我们设计的调查问卷的部分截图如图2所示。
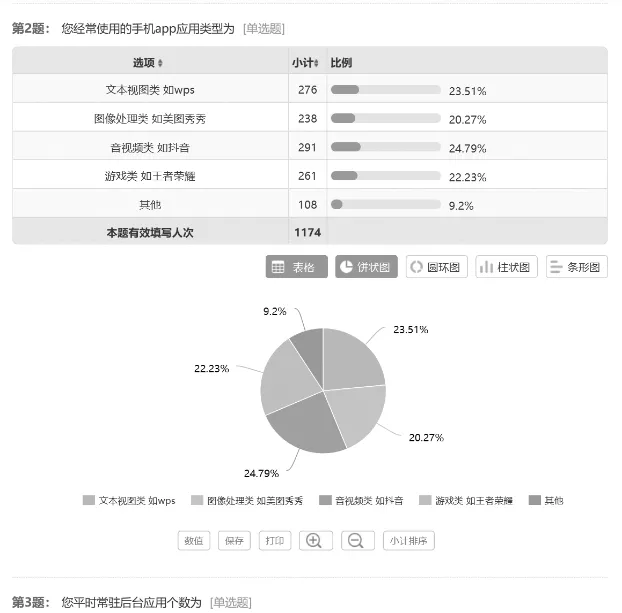
图2 用户个性化卸载需求的调查问卷截图(部分)
在调查问卷设计完成后,进行了问卷的发放与收集工作。问卷的发放方式主要包括线上发放和线下发放两种。线下通过发放纸质的问卷来收集,线上则通过电子问卷的形式,主要在微信,QQ空间等社交平台上收集。发放过程中为了保证数据的说服性和样本的丰富性,发放的人群包括学生,上班族以及离退休老年人,年龄覆盖面较广。
经过为期两到三周的问卷收集,由于志愿者在填写问卷时是匿名提交,我们相信所有的答卷都是真实的,因此将所有的调查结果都进行了保存。在使用这些数据进行训练之前,我们使用数据清理方法过滤了几个无效数据(我们清理了提交问卷后1s以内即完成调查,以及提交时间早于问卷发布时间的异常结果数据)。在通过筛选掉一些不合格的问卷后,共有1035份数据可供使用。但这些数据都是文本信息,无法直接使用,需要将其数字化,以便后面的处理和使用。首先将每个问题按abc……编号,再对每个问题中的选项进行数字编号,例如第六个问题的第二个选项编为f2。这样,就把文本信息简化为字母和数字组合的数据,以便数据的分类与数据集合的制作。
在模型的训练阶段,我们采用了SVM算法[12]对数据集进行了训练。我们的User profile模型是采用了10个问题来构造输入,输出为程序运行时间、网络延时、能量消耗这三个影响因素的重视程度的预测概率。我们使用了交叉验证,即将数据集合的70%用作训练,30%用作测试。利用Libsvm工具[13],在设置c参数的值为512.0,g参数的值为0.0001220703125的情况下进行优化,预测的准确率由87.3333%提高到95.3333%。
(1)
其中,wr为关注应用程序运行时间的概率,wd为关注网络延时的概率,we为关注能量消耗的概率。
4 基于用户个性化需求的卸载算法
4.1 Cost graph的构建
我们假设有一个资源受约束的移动设备端,可以与一台资源丰富的服务器进行数据通信,它们通过无线网络进行连接。对于移动计算卸载来说,网络带宽的占用主要来自于移动端与服务端的数据传输。程序的总执行时间包括服务端的计算时间和网络上的通信时间。一些研究表明移动设备端的能量消耗主要由三类消耗组成:移动设备上的计算消耗,移动设备的待机消耗和无线网络上的通信消耗[14]。在卸载过程中,有一段时间服务器在计算结果,此时移动设备处于空闲状态,但是也要消耗一些功率以保持一些基础设施服务运行,即操作系统和通信接口开销。通信引起的能量消耗几乎与无线网络上的通信量成正比。通信量包括传输的数据量和函数代码量的大小。总之,在分析了不同类型资源消耗的构成之后,我们可以抽象出三类成本:计算成本,通信成本和迁移成本,我们将它们构成了每种资源的总消耗。
假设移动端应用程序用一无向图G=(V,E)表示,顶点设置为V,边集为E⊆V×V,其中顶点Vi表示函数,Ci和Cj的边eij表示函数Ci与函数Cj存在依赖关系。为了代表三类成本,我们将顶点权重和边权重添加到图G,称为成本图。顶点Vi的权重由三元组(Cm(Ci),Cc(Ci),Cs(Ci))表示,其中Cm(Ci)表示函数Ci的迁移成本,Cc(Ci)和Cs(Ci)表示它分别在移动终端和服务端上的计算成本。如果函数Ci无法在客户端或服务器上运行,则Cc(Ci)=∞或Cs(Ci)=∞,如果它无法在两台机器之间迁移,则Cm(Ci)=∞。边eij的权重由Cc(Ci,Cj)表示,其值等于分量Ci和Cj之间的通信成本。
因此,总资源消耗等于以下四个值的总和:(1)移动设备端上所有函数的权重Cc(Ci)之和;(2)服务端上所有函数的权重Cs(Ci)之和;(3)计算卸载时连接移动端和服务端的函数的所有边缘的权重Cc(Ci,Cj)之和;(4)将函数从移动端迁移到服务端的所有函数的权重Cm(Ci)之和。为了最小化资源的消耗,我们将该问题转化为公式(2),其中SC和Ss分别是移动端端和服务端上的函数集合,Se是连接移动端和服务端函数的所有边缘的集合,Sm是一组迁移函数集合。

(2)
4.2 个性化参数调整
公式(2)给出了进行计算卸载所需要的成本,这一决策公式只考虑了客观参数的影响,如表示函数Ci迁移成本的Cm(Ci),分别表示在移动终端和服务端上的计算成本Cc(Ci)和Cs(Ci),上述参数都可以通过工具进行比较准确的测量。但根据我们的研究目标,是需要考虑用户个性化卸载需求的。因此,我们要将训练好的用户个性化模型的系数纳入到成本评估模型来。系数修改不仅保证我们的卸载决策是根据实时系统条件进行的,还能兼顾个人的需求。
(1)首先,我们基于注意力的机制[15]计算当前移动终端的操作系统运行情况下的用户兴趣分布概率,如公式(3)所示:
(3)
其中,wi如公式(1)所示,wr为关注应用程序运行时间的概率,wd为关注网络延时的概率,we为关注能量消耗的概率。Si为对应的客观测量指标。Sr为当前的移动终端相同的应用程序的运行时间,Sd为当前网络的延时,Se为当前运行状态下相同应用程序的能耗。这样做的好处是,进一步考虑了当前系统的运行时对计算卸载决策算法的影响,使得卸载决策更加合理。
(2)然后,我们分析移动终端上应用程序的本地运行时间。利用用户个性化需求卸载模型的预测结果,将客观影响因素和主观影响因素相结合,实现对Cost graph节点权值的调整。具体的系数调整如下:
假设程序划分之后,对于仍保留在移动设备端的函数Vi,程序的运行时间客观上只跟Cc(Ci)有关,但在主观上受到ur影响,即用户在当前情况下对应用程序的运行时间的重视程度,以及ue,即用户在当前情况下对应用程序能耗的重视程度的影响。我们定义公式(4)对本地运行时间成本进行调整。
(4)
对于卸载后将函数Vi从移动端迁移到服务端的权重Cm(Ci)和计算卸载时连接移动端和服务端的函数的边缘的权重Cc(Ci,Cj),按照同样的思路进行调整,主要考虑ud,即用户对当前网络状况下的网络延时的重视程度的输出概率,定义公式(5)、(6)如下:
(5)
(6)
综上,我们将进行调整过的资源总消耗归结为公式(7):
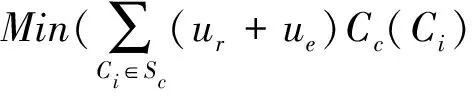
(7)
4.3 网络流图的构建
针对公式(7),利用最大流最小割定理[16]可以找到流网络二分问题的最优解。但是上述构建的成本图并不是网络流图。需要我们将应用程序的成本图转换为其流网络,其中一部分程序代码位于移动设备端,另一部分卸载到服务器端。
在获得所有顶点Vi的权重之后,我们构造用于计算卸载的max flow图。首先将节点C和节点S添加到该图中,分别表示移动设备端和服务端。接下来,对于每个模块节点,将有关联的每一条边e(i,j)在流网络中变为两条有向边e(i,j)和e(j,i)。最后,在图上标注不同的权重,以表示各节点的执行成本。如图3所示,我们使用上述方法构建的图形称为max flow min cut图,它是权重无向图。
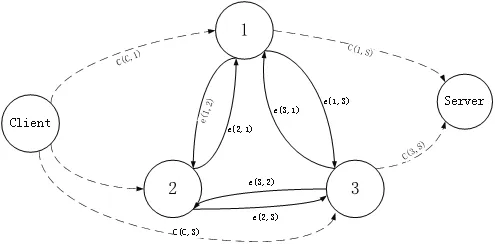
图3 网络流图示例
在构建其成本图之后,我们便可以利用所提出计算卸载划分算法将成本图转换为相应的流网络,然后使用Min-cut算法对应用程序进行处理并获得最优的函数划分。
5 实验与性能评估
首先,实验的硬件配置方面,移动测试应用程序部署在Android版5.0.2的Galaxy A7移动设备中,该智能移动终端的CPU工作频率保持在12GHZ,内存容量为1GB。服务端(采用微云cloudlet作为服务端)的应用程序仍部署在带有window7的PC工作站(2.1GHz,4.0GB内存)中。移动端与服务器端通过WiFi连接。
在实验中,我们使用图像处理应用程序作为我们的测试应用程序,程序的功能是图像滤镜程序。所有的程序模块统一使用图像格式文件作为输入和输出。每个滤镜函数具有良好的独立性,可以单独调用。程序架构采用总分式的结构,可以添加模块节点或任意改变拓扑结构,灵活性好,很适合在实验测试中组合和排列成不同的模块,形成不同的拓扑结构。图4提供了具有6个模块节点的候选拓扑结构。
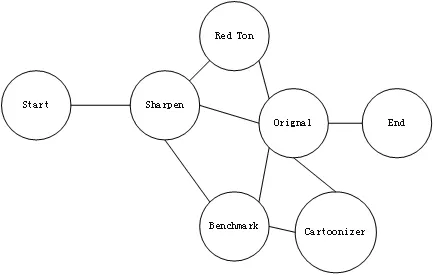
图4 实验测试的应用程序
我们选择了三个类型的典型代表作为测试用户。他们的个性化卸载需求分布如表1所示。
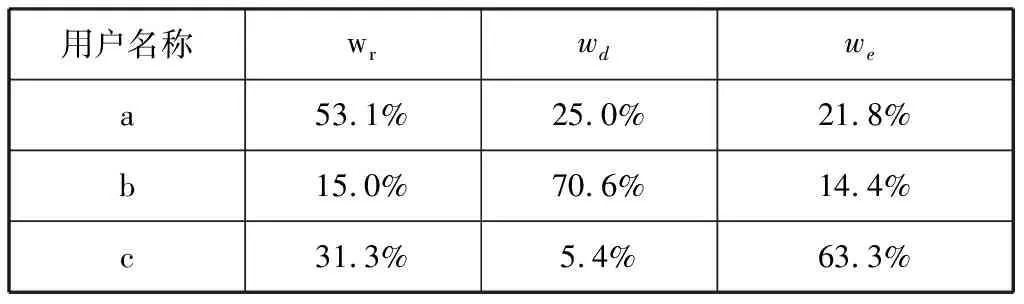
表1 典型用户的个性化卸载需求模型输出概率
我们记录运行相同应用程序时不同算法的执行时间。对于用户a,他的关注点更多是程序运行时间,因此程序的实际执行时间是我们的评估指标。对于用户b,他的关注点更多是网络时延,因此程序执行期间的网络状态是我们重点关注的指标。而用户c对移动终端的耗电量比较关注,因此我们监测程序执行期间的电量消耗。
为了准确评估基于用户个性化卸载需求的算法性能,我们选择了二个baseline:
(1)完全在云服务器上运行应用程序,用户只负责发布图像数据和接收处理结果。
(2)本地:程序代码只在移动设备上运行。
5.1 执行时间性能比较
首先,我们针对用户a进行实验,评估程序的执行时间的变化规律。图5中的数据流大小表示我们用作输入的图像文件大小。在数据量增加到2MB之前,在服务器上运行程序相对较快。因为在数据量较小的情况下,将数据上传到云服务器不会占用太多的传输时间,将整个应用程序卸载到云端仍然是最佳选择。但是,随着数据流量的增加,在云上运行的时间成本上升最快。我们发现,在4MB到8MB的范围内,我们的计算卸载决策算法相对直接在服务器上运行程序反而更佳,这说明卸载策略在大数据量的情况下有一定的优势。
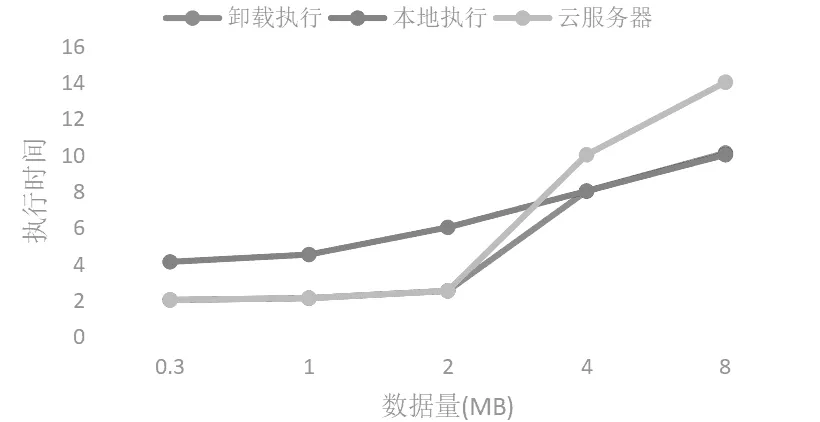
图5 图片数据量大小与执行时间的关系(用户a)
5.2 网络时延性能比较
然后,我们对用户b进行观察,如图6所示,无论在本地执行,还是在服务器上执行,这两种执行方式的网络延时相对稳定,不太受数据量变化的影响。这是因为都不涉及到数据传输。而计算卸载算法的网络时延则随着数据量的增加而变大,这是因为数据量的增大,导致计算开销增大,计算时间变长,导致结果返回的时间变长,因此时延不断增加。

图6 数据量与网络时延的关系(用户b)
5.3 程序能耗性能比较
对用户C分析能耗,从图7我们可以得出结论,当数据量很小时,直接在云服务器上的耗能最小。本地执行模式的能耗表现比较稳定,因为不需要传输数据,因此消耗的能量主要由程序计算所消耗的能量构成。在数据量逐渐增大后,计算卸载算法的表现比全部卸载更优。
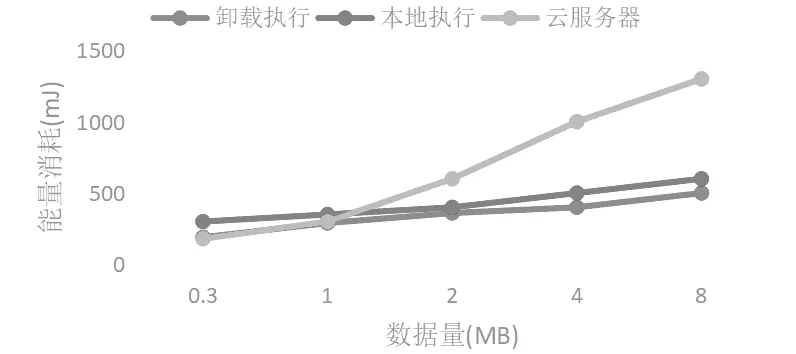
图7 用户C 数据量与能量消耗的关系
5.4 算法的综合性能
为了进一步验证基于用户个性化需求的算法性能和效果,我们将本章提出的算法与基于Min-Cut的贪婪计算卸载算法进行了比较。我们设定了图片的大小为8M,网络的带宽固定为100KB,结果如表2所示。
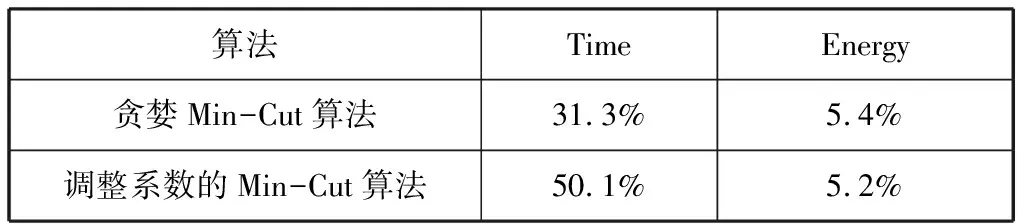
表2 算法的综合性能比较
如表2所示,贪婪Min-Cut算法的执行时间比我们提出的算法更短,这是因为该算法不需要使用模型进行预测。但是我们提出的调整权重的Min-Cut算法的能耗比贪婪Min-Cut稍低。另外,我们提出的算法在满足用户个性化用户需求方面的优势是贪婪Min-Cut算法所不具备的。
6 总结
本文提出了基于用户个性化需求的计算卸载决策算法,用于改善用户的移动计算个性化计算卸载体验。首先,结合机器学习算法设计了一个用户兴趣分布模型,深度研究用户的个性化需求,从而使移动计算可以为用户提供个性化的服务。然后,使用个性化参数调整,将用户主观卸载意愿和客观卸载决策参数进行结合,构建了基于用户个性化卸载需求的网络流图,使用最大流最小割算法对应用程序进行划分。最后,通过实验对模型的性能进行了评估。
猜你喜欢
北京大学学报(自然科学版)(2021年3期)2021-07-16 07:13:40
东北师大学报(自然科学版)(2021年1期)2021-03-27 01:22:14
电脑爱好者(2020年19期)2020-10-20 06:02:06
电子制作(2019年13期)2020-01-14 03:15:18
电脑报(2019年12期)2019-09-10 05:08:20
东华大学学报(自然科学版)(2018年1期)2018-06-29 03:35:18
消费导刊(2018年8期)2018-05-25 13:19:48
网络安全和信息化(2017年9期)2017-11-07 06:30:48
电脑迷(2012年15期)2012-04-29 17:09:47
计算机应用文摘(2011年18期)2011-04-29 00:44:03
