
基于云计算平台的图书馆混合推荐技术研究
2019-12-09 11:18赵冉
现代电子技术 2019年23期
赵 冉
(河北金融学院,河北保定 071000)
0 引 言
用户获取图书资源的重要途径是图书馆,随着科学技术的不断发展,图书馆信息服务迎来巨大挑战[1]。在传统图书馆信息服务模式下,所有用户统一使用一个图书馆平台,用户想要获取自己所需图书信息时,只需主动向图书馆平台提交查询请求,图书馆平台通过用户查询请求后用户就可获取需求信息。但是随着信息化的不断发展,高校图书馆信息量不断膨胀[2],导致传统信息服务模式下的用户难以快速发现符合自身偏好的图书信息。在此情况下学者应将研究重点放在图书馆推荐技术上,通过设计较好的图书馆推荐技术及时将符合目标用户偏好的图书推荐给目标用户,且设计的图书馆推荐技术能过滤图书馆中的海量数据,在较短时间内响应目标用户需求[3]。该图书馆推荐技术必须具备处理大数据的能力。经过实际调查分析发现,当前主流内存计算框架是Spark,且处理大数据的能力较好,因此基于云计算平台设计图书馆推荐技术能提升处理大数据的能力和推荐效率[4]。通过云计算平台处理大数据后,应将推荐效果较好的推荐算法融合到云计算平台中,精准快速地向目标用户推荐图书[5]。通过查阅相关文献发现,当前个性化图书馆推荐技术在用户粘稠度较低的情况下,无法精准向目标用户推荐图书[6],因此需在基于云计算平台的图书馆推荐技术中添加混合推荐算法,当用户粘稠度较低时采用基于Spark 的聚类算法推荐图书,当用户粘稠度较高时采用协同过滤算法向目标用户推荐图书。根据上述分析本文研究基于云计算平台的图书馆混合推荐技术,通过该技术弥补当前图书馆推荐技术存在的缺陷,提升推荐图书的质量[7]。
1 图书馆混合推荐技术
1.1 图书馆混合推荐系统总体架构
基于云计算平台的图书馆混合推荐系统将并行计算框架作为计算前提,依照分布式结构将采集到的数据信息传输到集群,传输过程中采用Kafka 消息中间件传输数据信息,并行化处理数据信息,基于云计算平台的图书馆混合推荐系统框架结构如图1 所示。

图1 图书馆混合推荐系统Fig.1 Library hybrid recommendation system
从图1 中可清晰明了地观察出基于云计算平台的图书馆混合推荐系统推荐过程。首先,存储收集到的图书馆用户日志和图书馆图书数据,存储位置是本地数据库[8],采用Flume 的Tail 命令观测图书馆用户日志变化规律,采集图书馆用户日志信息和图书馆图书数据[9]。其次,将图书馆用户日志信息和图书馆图书数据传输到Kafka 消息中间件中,采用Kafka 消息中间件将集群订阅的图书馆用户日志信息和图书馆图书数据传输到集群中,创建分布式数据集,依照定义算子和函数预处理分布式数据,根据用户粘稠度采用不同推荐算法计算分布式数据。当用户粘稠度较低时采用聚类算法,当用户粘稠度较高时采用基于协同过滤的混合推荐算法,将推荐结果传输到HBase 数据库中,存储推荐结果。
同时将推荐结果传输到集群的核心组件中,分析计算推荐结果数据和备份推荐结果数据的同时向目标用户推荐图书,将最终推荐结果存储到HDFS 分布式文件系统中,Web 服务器可随时访问HBase 数据库和HDFS分布式文件系统中的推荐数据信息。基于云计算平台的图书馆混合推荐系统能够实现多种功能,包括分析用户日志数据、推荐图书、实时备份数据等功能[10]。分布式并行化处理显式反馈和隐式反馈的数据,其中显式反馈数据指的是用户收藏和属性特征等用户行为,隐式反馈数据指的是在某图书上用户消耗的时间或者搜索图书类别等数据。依照计算的推荐结果将图书馆中图书推荐给目标用户,目标用户可采用Web 网页访问该推荐系统[11]。该系统中最为重要的是图书推荐算法,根据用户粘稠度采用相应图书推荐算法推荐图书。
1.2 图书馆混合推荐算法
图书馆混合推荐算法在不同粘稠度的状况下分别采用相应算法推荐图书馆图书。假设用户粘稠度较低,即存在新用户的情况下,应采用聚类算法,假定同类用户具有相同的读书偏好,依照聚类结果向目标用户推荐图书。当用户粘稠度较高时,应采用基于协同过滤的混合推荐算法向目标用户推荐图书,下面详细讨论不同粘稠度下图书馆推荐算法的计算过程。
1.2.1 聚类算法
当用户粘稠度较低时需聚类用户,假定同类用户读书偏好相同,基于聚类结果向目标用户推荐图书。本文采用聚类算法聚类用户[12],将图书馆图书数据划分成多个片区,每个片区大小相同,聚类操作多个片区,合并聚类结果得到最终所需聚类。算法详细步骤如下所示:
1)通过Flume 采集图书馆图书数据,创建弹性分布式数据集RDD。
2)读取map 函数,通过双层并行遗传算法获取聚类中心b1和b2,通过获取的聚类中心得到新弹性分布式数据集RDD1。
3)MapToPair 操作原有弹性分布式数据集,通过每个点和聚类中心之间的距离聚类划分原有弹性分布式数据集,得到RDD3。
4)reduceBykey 操作RDD3,计算新聚类中心,同时判断聚类中心收敛性,当聚类中心不收敛时,需继续迭代聚类中心[13],如果聚类中心出现收敛的状况,需依照key 值合并聚类中心。
5)采用filter 函数筛选出需要的聚类中心,依照聚类中心用户读书偏好向目标用户推荐图书。
1.2.2 基于协同过滤的混合推荐算法
当用户粘稠度较高时,采用基于协同过滤的混合推荐算法分析用户阅读偏好,在用户群中筛选出与目标用户阅读偏好较为一致的用户,采用近邻用户产品评价信息数据计算目标用户对图书馆的预测评分,通过预测评分数据探析目标用户对图书馆中某类图书的需求程度[14],根据需求程度的高低向用户推荐相应的图书馆图书。基于协同过滤的混合推荐算法过程主要包括以下两个步骤:
1)选取近邻用户。假设Di=(y1,y2,…,yj)表示其他用户和目标用户评价向量,当用户m和目标用户的Dm之间相似性与既定阈值相符合时,将用户m当成是目标用户的近邻用户,此时选取用户m为评分预测的计算用户集。通过Pearson 系统计算用户之间相似程度,相似度计算公式如下所示:
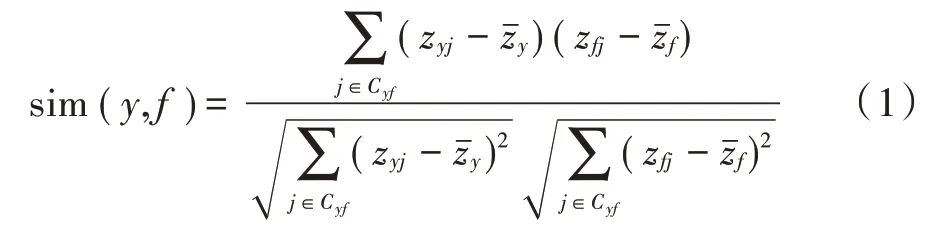
2)预测评分。采用全局数值算法预测评分,将上文计算的相似度当成权值,组合多个权值产生预测评分,其计算公式如下所示:
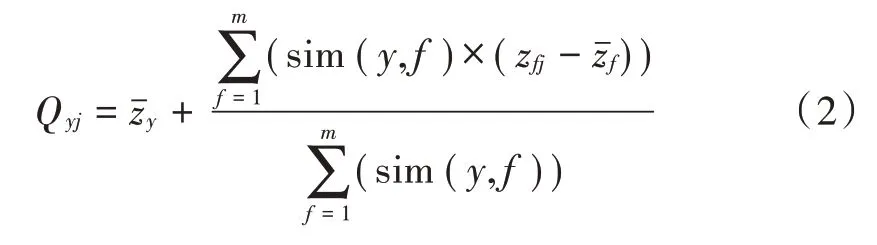
式中:m表示计算用户集中用户数量;Qyj表示用户y对图书j的预测评分。
综上所述,基于云计算平台的图书馆混合推荐过程是当目标用户登录基于云计算平台的图书馆混合推荐系统后,系统需要判断用户粘稠度,粘稠度较低时,需聚类用户,假定同类用户有相同读书偏好,依照聚类算法获取聚类中心,通过聚类中心中用户读书偏好向目标用户推荐图书;当粘稠度较高时采用基于协同过滤的混合推荐算法,寻找近邻用户,采用评分向量计算用户相似性,预测评分,依照预测评分结果向目标用户推荐图书[15]。
2 实验验证
为验证本文基于云计算平台的图书馆混合推荐技术的性能,需采用Windows XP 系统,双核CPU 1.85 GHz和4 GB 内存的计算机,本次实验的测试数据为某高校图书馆读者借阅图书数据。
2.1 推荐效果
为检测本文方法的推荐效果,检测本文方法查准率和误判率判断推荐效果,其中,推荐成功图书和推荐图书总数之间的比值表示查准率,推荐失败的图书总数和推荐图书总数之间比值表示误判率。系统统计结果如图2 所示,同时将采用本文方法推荐图书的界面效果用图3 呈现出来。
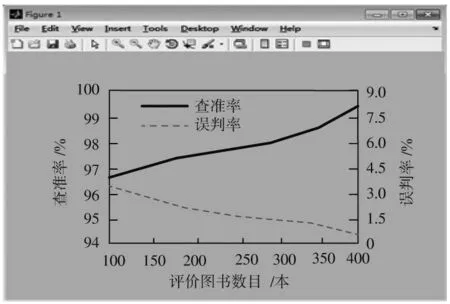
图2 统计结果Fig.2 Statistical results

图3 推荐界面Fig.3 Recommended interface
从图2 中可以看出,随着用户评价图书数目的不断增加,本文方法推荐的查准率逐渐上升,误判率逐渐下降,且本文方法推荐查准率不低于95%,说明本文方法查准率较高,本文方法推荐效果较好。
从图3 中的推荐界面可以看出,采用本文方法后用户能够清晰明了地从推荐界面中看到推荐图书,简单快速地寻找自身感兴趣图书,目标用户可从界面中观察推荐图书的推荐分值,选取自己感兴趣的图书,降低搜寻时间。
2.2 推荐性能评估
为检测本文方法的推荐性能,需研究不同推荐列表长度下本文方法推荐的精准度和多样率,通过精准度表示推荐列表中符合目标用户阅读偏好的图书占有比重,通过多样率表示推荐图书的多样性,研究结果如表1所示。

表1 本文方法推荐性能Table 1 Recommending performance of this method
由表1 可得本文方法推荐精准性和图书两两相异性多样率之间呈反比,随着推荐列表长度的增加,与目标用户阅读偏好较为一致的图书进入列表比重会逐步上升,方法精准性会显著上升,多样性会显著降低,且方法推荐精准性最高,最高数值为99.72%,推荐性能较好。
2.3 运行情况
为验证本文方法在计算机中的运行情况,检测用户量不同情况下本文方法的响应时间、内存使用情况和CPU 使用情况,通过SAS 绘图软件显示检测结果,如图4所示。

图4 本文方法运行情况Fig.4 Operating status of this method
从图4 可看出,随着用户人数的增加,采用本文方法向目标用户推荐图书馆的响应时间逐渐增加,且内存使用情况和CPU 使用情况也随着用户人数的增加而不断增加,但是从总体上看,采用本文方法向目标用户推荐图书后计算机的内存使用情况和CPU 使用情况不超过60%,本文方法响应时间不超过0.2 s,即本文方法推荐时间较短,且采用本文方法向目标用户推荐图书的整个过程中较少使用CPU,占有内存较小,说明本文方法响应时间快,能够节省计算机内存空间。
3 结 论
当前图书馆中含有海量图书信息,基于云计算平台的图书馆混合推荐技术能够快速有效地从图书馆中采集到所需图书馆用户日志信息,依照用户粘稠度采用相应算法向目标用户推荐图书。本文方法充分考虑用户粘稠度,弥补当前个性化图书馆推荐技术无法向粘稠度较低的用户推荐图书的缺陷,经过实验分析发现,本文方法推荐精准度高,可将本文方法应用到实际的图书馆推荐中。
猜你喜欢
南风(2020年22期)2020-09-15
康颐(2020年5期)2020-09-10
小学生优秀作文(低年级)(2019年5期)2019-04-25
饮食保健(2018年6期)2018-01-27
小学阅读指南·低年级版(2017年12期)2017-12-26
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
环境与生活(2015年10期)2015-12-16
电子设计工程(2015年6期)2015-02-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
