
基于电网调度域设备监测实时数据采集的实现方法
2019-12-04 04:16张雄宝阮诗迪唐羿轩何伊妮曹伟叶桂南
数字技术与应用 2019年8期
张雄宝 阮诗迪 唐羿轩 何伊妮 曹伟 叶桂南


摘要:本文介绍一种基于电网调度域设备监测实时数据采集的实现方法。通过分布式任务调度技术、实时流数据处理技术和海量时间序列数据库技术,解决电网调度域设备监测实时数据采集不及时且与业务管理数据无法互通的问题,实现电网调度域设备监测数据的实时采集、处理和存储。
关键词:电网运行监控系统;实时数据采集;clickhouse时序数据库;kafka集群;分布式任务调度技术
中图分类号:TM76 文献标识码:A 文章编号:1007-9416(2019)08-0036-03
0 引言
电力行业是国民经济的基础能源产业,随着社会经济发展,各行业对电力的依赖性明显增强,对供电可靠性及电能质量的要求日益提高。近年来,随着我国电力建设逐渐由发电建设向智能电网建设转移。智能电网的建设,其中重要的技术部分,是解决如何实现设备实时运行数据与业务管理数据的融合和综合利用,即IT与OT的融合技术。在电网领域,随着大数据技术的兴起,IT与OT的融合技术研究也属于方兴未艾的阶段。电力调度领域广泛使用的OCS(电网运行监控系统)即是该技术的典型表现。通过OCS,可在展示页面上监测各设备的实时运行状态、线路的电流值、电压值。但在如何将实时运行数据与业务管理类数据进行关联、融合和利用,仍存在技术上的空白。
为了解决上述问题,本文提供了一种基于电网调度域设备监测实时数据采集的实现方法,从技术上解决目前电网调度域设备监测实时数据采集不及时且与业务管理数据无法互通的问题,本文通过分布式任务调度技术、实时流数据处理技术和海量时间序列数据库技术即IT与OT的融合技术,实现电网调度域设备监测数据的实时采集、处理和存储,实现对设备运行情况实时监控和管理。
1 实时数据采集方法
电网调度域的设备监测数据属于时序数据,具有产生频率快、数据量大、数据带有时间标签等特点[1]。针对目前电网调度域设备监测数据采集不及时的问题,本文提供了一种基于分布式任务调度技术、实时流计算技术、海量时间序列数据库技术的实时数据采集方法,可以实现电网调度域设备监测数据的实时采集、处理和存储。
实时流计算可以很好地对大规模流动数据在不断变化的运动过程中实时地进行分析,捕捉到可能有用的信息。海量时间序列数据库是一种专为时间序列数据优化而设计的数据库。时序数据具有产生频率快、数据量大、数据带有时间标签等特点,基于时间序列数据的特点,传统的关系型数据库无法满足对时间序列数据的有效存储和处理。clickhouse时序数据库通过使用特殊的存储方式,可以高效存储和快速处理海量时序大数据,是解决海量数据处理的一项重要技术[2-3]。
1.1 分布式任务调度技术
分布式任务调度技术是基于LTS框架将大批量的处理任务分配到不同的计算节点上运行[4]。LTS框架包括三种节点,具体为JobClient节点、JobTracker节点、TaskTracker节点。各个节点都是无状态的,可以部署多个,来实现负载均衡,实现更大的负载量, 并且框架具有很好的容错能力。JobClient节点用于提交任务和接收任务执行反馈结果;JobTracker节点用于接收并分配任务和任务调度;TaskTracker节点用于执行任务以及执行完任务后将执行结果反馈给JobTracker节点。
任务分配过程如图1所示,JobClient提交一个任务给Job Tracker,JobTracker收到JobClient提交来的任务,先生成一个唯一的JobID,JobTracker发现有(任务执行的)可用的TaskTracker节点(组)之后,将优先级最大,最先提交的任务分发给Task Tracker。这里JobTracker会优先分配给比较空闲的TaskTracker节点,达到负载均衡。TaskTracker收到JobTracker分发来的任务之后,执行。
任务执行过程如图2所示,JobClient提交任务到JobTracker,JobTracker将任务保存到可执行任务队列,然后将任务发送给空闲的TaskTracker执行,并把任务移到执行中任务队列,任务执行完成后反馈结果到JobTracker,如果设置了反馈客户端标识,将结果反馈到JobClient。
1.2 实时流数据处理技术
实时流计算可以很好地对大规模流动数据在不断变化的运动过程中实时地进行分析,捕捉到可能有用的信息。实时流处理基于kafka框架进行实现,kafka是一个分布式的发布订阅消息系统,它的特性就是可以实时的处理大量数据以满足各种需求场景[5-6]。Apache Kafka与传统消息系统相比,有以下优势:
(1)它被设计为一个分布式系统,易于向外扩展;
(2)它同时为发布和订阅提供高吞吐量;
(3)它支持多订阅者,当失败时能自动平衡消费者;
(4)它将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。
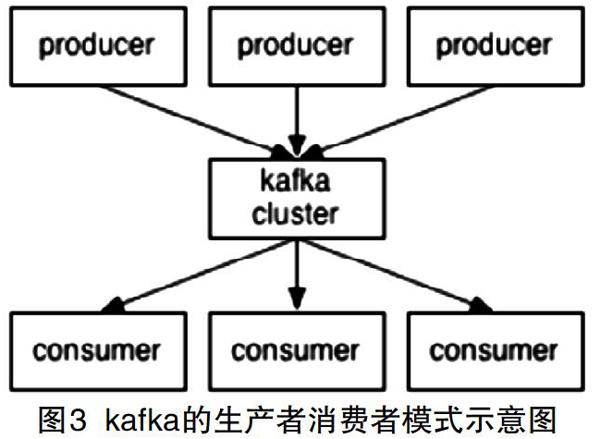
使用kafka实时流计算技术对实时数据进行计算具体是通过kafka的生产者消费者模式实现数据的实时处理,如图3所示,生产者生产数据,交给broker进行存储,消费者需要数据时就从broker中取出数据,并对数据进行处理。
下载解析后的E文件数据不间断的推送至kafka实时消息总线,并保存在kafka的topic中,然后调用kafka的filter接口对E文件数据的状态字段进行监控,以实现开关状态监控、电压、电流突变告警以及重点设备的运行状态监控。
开关状态、电压、电流及重点设备状态的实时数据经过下载解析,不间断的将数据推送到kafka消息系统。开关状态监控处理过程如下,开关狀态数据在kafka中对应是用一个topic来存储,然后调用kafka的filter接口对开关的状态字段进行监控,如果状态是0则表示开关跳闸。电压、电流突变告警及重点设备的运行状态监控的处理过程如下,首先根据要求设定电压、电流及重点设备状态数据的阀值,然后通过kafka的filter接口对数据进行监控,超过阀值的数据就是异常数据,需要将数据进行输出和告警。监控到的结果数据可以输出到应用界面进行展示,整个实时数据处理过程可以达到秒级。
1.3 海量时间序列数据库技术
电网调度域的设备监测实时数据是属于带时间标签的时序数据,数据产生频率快、依赖于采集时间、测量点多信息量大,每天产生几十GB的数据,传统的关系型数据库无法满足对时间序列数据的有效存储和处理。Clickhouse是面向联机分析处理(OLAP,On-Line Analytical Processing)的列式存储数据库,适合快速处理海量的时序数据,并能够实现快速查询和分析。ClickHouse数据库具备以下特点:
(1)真正的列式DBMS;
(2)数据压缩;
(3)数据的磁盘存储;
(4)多核心并行处理;
(5)多服务器分布式处理;
(6)支持SQL;
(7)向量引擎;
(8)实时的数据更新;
(9)索引;
(10)适合在线查询;
(11)支持近似计算。
通过Clickhouse时间序列数据库,可以实现历史数据的快速查询和分析,例如明细数据的日、月累计数据统计,历史数据的任意时间段的记录数、最大值、均值、最小值、最大值发送时间、最小值发生时间等常规统计查询。
2 具体实施方式
E语言是电力系统的数据标记语言[7],其所形成的实例数据是一种标记化的纯文本数据,E语言通过少量标记符号和描述语法,可以简洁高效地描述电力系统各种简单和复杂数据模型。调度域监测设备实时数据的源文件格式采用E语言文件格式,E文件数据包括开关状态数据、电压电流数据、设备状态数据。
本文采用分布式任务调度技术从电网运行监控系统下载E文件数据并进行解析,然后将解析后的数据推送到kafka实时消息总线并将数据保存在clickhouse时间序列数据库中进行存储和在线统计。如图4所示,基于电网调度域设备监测实时数据采集的实现方法,包括以下步骤:
E语言的数据文件无法直接存储于kafka的消息總线和clickh-ouse数据数据库,需要先经过程序的解析。优选地,所述采用分布式任务调度技术从电网运行监控系统下载E文件数据并进行解析的具体步骤包括:
(1)根据数据文件的周期,例如5分钟、15分钟、1个小时等,定时生成待处理的文件列表;
(2)根据待处理的文件列表,每个文件单独发布一个执行任务;
(3)执行任务对E文件数据进行下载和解析,执行任务在多个任务服务器节点上并发执行。
使用kafka实时流计算技术对实时数据进行计算,通过计算得到开关异常跳闸数据、电压电流突变数据以及重点设备的状态数据,从而实现开关状态监控、电压、电流突变告警以及重点设备的运行状态监控。
使用时间序列数据库clickhouse对海量时间序列历史数据进行存储和在线统计。
3 结语
本文提供了一种基于电网调度域设备监测实时数据采集的实现方法,通过分布式任务调度技术、实时流数据处理技术和海量时间序列数据库技术,实现电网调度域设备监测数据的实时采集、处理和存储,进一步提高了对设备和电网运行情况的监控力度,提高设备运行管理智能化水平。实时流计算可以很好地对大规模流动数据在不断变化的运动过程中实时地进行分析,捕捉到可能有用的信息。海量时间序列数据库是一种专为时间序列数据优化而设计的数据库。时序数据具有产生频率快、数据量大、数据带有时间标签等特点,基于时间序列数据的特点,传统的关系型数据库无法满足对时间序列数据的有效存储和处理。clickhouse时序数据库通过使用特殊的存储方式,可以高效存储和快速处理海量时序大数据,是解决海量数据处理的一项重要技术。
参考文献
[1] 曹军威,万宇鑫,涂国煜,张树卿,夏艾瑄,刘小非,陈震,陆超,等.智能电网信息系统体系结构研究[J].计算机学报,2013(01):143-167.
[2] 顾恩硕,刘海粟,白雪,等.关系数据库与非关系数据库[J].艺术科技,2016(12):84.
[3] 陈勇.银行日志仓储中心系统的设计与实现[D].湖南大学,2017.
[4] 承林,王海宁,高春成,等.分布式任务调度在电力市场交易系统中的应用设计[J].计算机应用与软件,2018(11):163-167.
[5] 金双喜,李永,吴骅,武文广,李俊臣,张新艳,等.基于Kafka消息队列的新一代分布式电量采集方法研究[J].智慧电力,2018(02):77-82.
[6] 王郑合,王锋,邓辉,柳翠寅,张晓丽,等.一种优化的Kafka消费者/客户端负载均衡算法[J]计算机应用与软件,2017(08):2306-2309.
[7] 孙世明,孟勇亮,杨雪,等.基于E语言数据交互的自动化系统监视平台设计[J].电力应用,2015(S2):4-8.
Realization of Real-time Data Acquisition for Equipment Monitoring in Power Network Dispatching Domain
ZHANG Xiong-bao, RUAN Shi-di, TANG Yi-xuan, HE Yi-ni, CAO Wei, YE Gui-nan
(Guangxi Electric Power Dispatch Control Center, Nanning Guangxi 530000)
Abstract:This paper introduces a real-time data acquisition method based on equipment monitoring in power grid dispatching area. By means of distributed task scheduling technology, real-time flow data processing technology and massive time series database technology, the problem that the real-time data acquisition of equipment monitoring in power grid dispatching domain is not timely and can not communicate with business management data is solved, and the real-time data acquisition, processing and storage of equipment monitoring in power grid dispatching domain are realized.
Key words:Power grid operation monitoring system; real-time data acquisition; Clickhouse time series database; Kafka cluster; distributed task scheduling technology
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
当代陕西(2019年14期)2019-08-26
制造技术与机床(2019年4期)2019-04-04
测控技术(2018年7期)2018-12-09
中学数学杂志(初中版)(2016年5期)2016-11-01
信息通信技术(2015年6期)2015-12-26
雷达与对抗(2015年3期)2015-12-09
华东理工大学学报(自然科学版)(2015年4期)2015-12-01
自动化博览(2014年12期)2014-02-28
测绘科学与工程(2014年2期)2014-02-27
