
基于深度学习的面向IP-over-EON 的可编程跨层网络业务性能感知系统
2019-12-03 07:54:40朱祖勍孔嘉伟牛彬唐绍飞房红强刘思祺
通信学报 2019年11期
朱祖勍,孔嘉伟,牛彬,唐绍飞,房红强,刘思祺
(中国科学技术大学信息科学技术学院,安徽 合肥 230027)
1 引言
当前,随着云计算和大数据等新兴业务的飞速发展[1-3],主干网中的网络流量在飞速增长的同时,其统计特性也变得越来越复杂。这些网络流量给现有基于IP-over-Optical 的主干网体系架构带来了新的挑战[4-6],也使传统波分复用(DWDM,dense wavelength division multiplexing)网络的可扩展性和灵活性呈现出不足。为了解决这一问题,基于灵活栅格的弹性光网络(EON,elastic optical network)应运而生[7-11],它们提供更细的频谱分配粒度和更加灵活的频谱分配机制,从而极大地提升了光层的灵活性和频谱利用率。在此基础上,人们开始考虑用 EON 替换传统 IP-over-Optical 主干网中的DWDM 层,以实现IP-over-EON[12-14],集成IP 技术和EON 技术的优势。与此同时,软件定义网络(SDN,software-defined networking)[15-16]技术通过分离网络的控制面和数据面并提供集中式的网络控制与管理(NC&M,network control and management)机制来保障网络的可编程性,SDN 在EON中已经获得了应用并证明了其优越性[17-20]。因此可以预见,将SDN 应用于IP-over-EON 中,即实现SD-IPoEON(software-defined IP-over-EON),有助于改善主干网的适配性和可编程性。
为了全面地体现SD-IPoEON 架构的优势,还需要实时的、细粒度的网络监测,以保障其中各类网络应用的服务质量(QoS,quality of service)。但是,现有的传统网络监测技术难以满足实时监控和自动网络调整的需求,造成这一问题的原因主要有以下3个方面:首先,因为IP-over-EON 是一个复杂的多层网络,针对其的故障监测与定位需要采用跨层的方法,同时分析IP 层与EON 层的情况,然而,当前的主流技术基本上都是单层的,仅针对IP层或EON 层进行分析,并没有将两者结合起来;其次,现有技术大多仅通过带外的方式收集网络状态信息[21-22],这决定了它们难以实现实时的、端到端的和细粒度的监测,而且它们会增大控制器的负担,可扩展性较差;最后,现有技术较少考虑业务级别(App-level,application level)的监测,考虑到不同的App(Application),有着各自不同的QoS需求,它们的异常监测与故障恢复机制会有不同。
考虑到以上问题,本文通过引入带内网络遥测(INT,in-band network telemetry),并在其基础上设计网络监控系统,将EON 层的信息通过INT 的方式采集出来,以实现跨层带内网络遥测(ML-INT,multi-layer INT)机制[23],同时将IP 层和EON 层的信息封装到ML-INT 分组中,完成实时的、分布式的和流粒度的端到端App-level 网络监测。注意到,尽管App-level 的网络监控能很好地采集业务的端到端QoS 参数,它并不能单独完成网络故障的定位和网络状态的及时调整,因此,本文在这一分布式网络监控系统内加入集中式的网络监测,利用SDN控制器完成链路级别(link-level)的网络监测。具体来说,App-level 监测通过ML-INT 实现端到端的实时细粒度网络监测,对采集到的数据进行分布式分析,利用深度学习(DL,deep learning)实现故障的初步识别与定位[24],然后将异常信息上传给控制器。控制器再结合自身link-level 的带外监测信息,进一步实现精确的故障定位并采取相应的故障恢复措施。本文提出的基于深度学习的跨层网络业务性能感知系统,融合了分布式网络监测与集中式网络管控的优点。类似于人类的神经系统,集中式的SDN 控制器为大脑,负责集中式网络管控;分布式的App-level 监测为神经感应元,负责分布式的细粒度网络监测。因此,将其称为网络神经系统(NNS,network nervous system)[25]。通过搭建小规模但真实的网络平台,实现并用实验展示了NNS 的优势,实验结果证明其可以针对网络业务的QoS 需求,实现精确有效的故障识别、定位和恢复。同时,实验结果也表明,本文所提的NNS 比传统的网络监测系统具有更良好的可扩展性和更灵活的可编程性。
2 系统架构
图1展示了NNS 的整体架构[23,25],系统的数据平面由一个IP-over-EON 组成。EON 层由光纤链路和带宽可变的光交换机(BV-WSS,bandwidth variable wavelength-selective switch)构成[26-27],并可以建立光路,其中,光性能监测器(OPM,optical performance monitor)监控各个链路的状态,采集各条光路的光信噪比(OSNR,optical signal-to-noise ratio)、中心波长和功率等信息。IP 层由可编程交换机和业务主机构成,业务主机上运行着不同QoS需求的业务;可编程交换机通过INT 代理(INT agent)和OPM 进行信息交互,INT agent 通过轮询的方式从OPM 中获取所需的光路信息,并发送至可编程交换机。如图1所示,可编程交换机同时将IP 层和EON 层的数据插入INT 头部的INT 数据字段中。IP 层数据包括可编程交换机的交换机标识(switch ID)、分组所经过的端口信息和排队时延信息,EON 层的数据包括OSNR、中心波长和功率信息。当业务主机A 与业务主机B 的通信分组被转发到最后一台可编程交换机(INT sink)上,INT sink将INT 头部拆除并将其发送至数据分析设备(data analyzer)。因此,ML-INT 技术对于通信的业务主机之间是透明的。data analyzer 通过解析INT 头部的INT 字段,便可以依次获取业务主机A 与B 的通信路径上每一台可编程交换机和每一条光路的信息,然后将解析出的ML-INT 数据发送至DL 故障识别和定位模块。

图1 NNS 整体架构
由图1可知,App 中集成了App-level 监测模块,App-level 监测模块包含QoS 异常监测模块和DL 故障识别和定位模块。其中,QoS 异常监测模块通过监测QoS 参数,如接收端带宽和抖动等,可以实现基于业务的独特QoS 需求定义异常,并及时将异常汇报给DL 故障识别和定位模块。DL 故障识别和定位模块接收到异常信息后,开始对data analyzer 发来的ML-INT 数据进行分析,实现光路级别的故障识别和定位,并将初步的识别和定位结果传输至SDN 中央控制器。中央控制器共包含3个模块,分别为数据分析模块、网络拓扑数据库(NTD,network topology database)模块和App 处理模块。数据分析模块包含App 异常分析模块和link-level监测模块。App 异常分析模块负责接收DL 故障识别和定位模块发送的故障初步识别和定位信息,link-level 监测模块通过带外遥测方式粗粒度地收集数据面信息。需要注意的是,DL 故障识别和定位模块是App-level 的故障分析与定位,即光路级别的初步故障识别与定位。数据分析模块通过结合控制器收集到的link-level 的光层信息和故障的初步识别和定位结果,实现link-level 的精确定位。NTD 模块负责存储并更新数据平面网络拓扑信息。App 处理模块主要对业务的优先级和所属类别(例如是否时延敏感等)进行分析。当多个业务同时出现故障时,App 处理模块根据业务优先级设定故障恢复的先后顺序,并根据业务所属的类别,通过路由和频谱分配模块(RSAM,routing and spectrum assignment module)进行重路由(非时延敏感业务)或者切换到备份光路(时延敏感业务),以实现最佳的故障恢复方案。
图2详细地说明了NNS 在正常阶段和异常阶段时模块间的信息交互过程,其中模块1和模块2分别代表图1中App-level 监测模块中的QoS 异常监测模块和DL 故障识别和定位模块。NNS 在正常阶段时,中央控制器通过带外遥测方式粗粒度的方式,即轮询时间间隔长,进行link-level 监测。无论NNS 处于正常阶段还是异常阶段,data analyzer 都会及时地将解析出的ML-INT 数据发送至DL 故障识别和定位模块。值得注意的是,只有在异常阶段下,当DL 故障识别和定位模块接收到QoS 异常监测模块的异常报告时,才会对ML-INT 数据进行App-level 的初步识别和定位,并将识别和定位结果报告至中央控制器的App 异常分析模块。中央控制器收到异常报告后,将会从粗粒度方式变化为细粒度方式,即轮询间隔时间短,有针对性地对定位的故障光路进行link-level 的监测。NNS 通过结合DL故障识别和分类模块App-level 的初步识别和定位结果和控制器link-level 的监测信息进行精确的故障定位。之后中央控制器通过App 处理模块获得业务的优先级和相关信息,根据NTD 模块中存储的数据面拓扑信息进行IP 层重路由或光路重配置等App-level 的故障恢复方案。
3 系统实现
3.1 可编程ML-INT

图2 NNS 交互流程
为了实现ML-INT 技术,通过可编程协议无关分组处理(P4,programming protocol-independent packet processor)语言[28]在可编程交换机上对数据包的格式进行相关的处理。首先,当业务分组经过第一台可编程交换机(INT source)时,INT source 以一定的比例(例如50%)在业务分组中封装INT 头部,同时定义INT 结构并在INT 头部定义INT 数据字段。IP 层和EON 层数据通过可编程交换机写入ML-INT 分组中的INT 数据字段。接着,ML-INT 分组被转发至下一台可编程交换机(INT intermediate hop),INT intermediate hop 将继续向ML-INT 分组写入本机相关的IP 层信息和EON 信息。最后,INT sink 将INT 头部拆除,然后发送至data analyzer 进行解析。为了尽量减小ML-INT 所带来的开销,本文指定每个可编程交换机在经过的ML-INT 分组中只插入2个INT 数据字段,从而减小INT 头部的长度。2个INT 数据字段中,第一个INT 数据字段固定为switch ID,指示数据分组的转发路径和所经过的交换机信息;第二个INT 数据字段为IP 层排队时延、EON 层OSNR 或功率,可编程交换机将这些数据依次写入多个ML-INT 分组中。由于网络中业务通信速率通常较高(例如10 Gbit/s),分组之间的时间间隔都是微秒级别。通常情况下,网络状态难以在微秒级别的时间内发生剧变,因此将IP 层和EON 层的数据分多次写入ML-INT 分组中是合理的。与此同时,data analyzer 需要解析多个ML-INT 分组方可获取完整的端到端ML-INT数据。
3.2 基于深度学习的App-level 监测
NNS 架构中,DL 故障识别和定位模块主要负责对data analyzer 解析出的ML-INT 数据进行初步故障识别和定位。传统的网络架构通常基于阈值的方式判断某类故障是否发生。随着网络规模的不断发展,故障类型逐渐增多,为不同的故障设置不同的阈值将会增加网络操作复杂度,可扩展性较差。其次,有的故障类型难以仅通过简单的阈值进行识别。如图3所示,本文通过在光路中引入噪声产生故障,当接收端带宽低于发送端的一定比例(例如90%)时即判定为异常。从图3中可以看出,第3 s 的功率值低于第5 s 的功率值,然而第3 s处于正常阶段,而第5 s 处于异常阶段。这是因为引入噪声对功率影响较小,但当OSNR 降低到一定值时,也会引发异常。所以对于噪声故障需要综合考虑功率和OSNR,不能只通过阈值进行判断。因此,本文采取基于深度学习的DL 故障识别和分类方法。
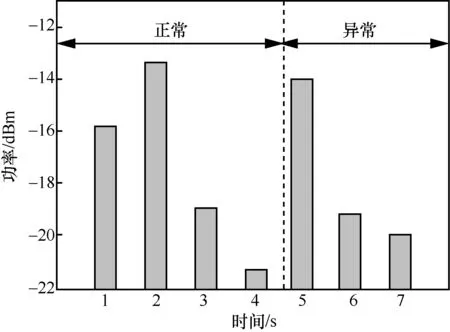
图3 App-level 功率监测
DL 故障识别和分类模块是深度神经网络(DNN,deep neural network)架构,包含输入层、两层隐藏层和输出层,通过监督式学习进行训练。输入层节点数等于要处理的数据的变量数,即3个;两层隐藏层的节点数都设置为128;输出层节点数等于每个输入对应的输出数,为4。DNN 架构中输出层的激活函数为softmax 函数,并选取分类问题中常用的交叉熵函数作为损失函数来刻画预测的概率分布和真实输出的概率分布之间的距离。DNN训练时通过反向传播和梯度下降算法调整神经网络中参数的取值,从而最小化损失函数。DL 故障识别和分类模块的输入是ML-INT 数据,包括IP层排队时延、EON 层的功率和OSNR。值得注意的是,若ML-INT 分组经过N个可编程交换机,端到端完整ML-INT 数据会包含N组输入(一组输入为排队时延、功率和OSNR)。data analyzer 在将端到端完整ML-INT 数据发送至DL 故障识别和定位模块时,会先依次从业务分组的发送端到目的端对ML-INT 数据进行N组划分。DL 故障识别和定位模块依次对N组数据进行故障识别,第一个出现故障的光路或可编程交换机即为故障位置,从而实现故障定位,这种每次仅对一组数据进行分析的方式适用于不同的网络规模,具有很好的可扩展性。
本文通过搭建一个小规模但是真实的IP-over-EON 测试平台,模拟产生各种故障(拥塞异常、功率衰减异常和噪声异常),从而获得训练数据。例如,本文通过功率衰减器衰减光路中的功率,在光路中引入噪声和加入背景流让可编程交换机产生拥塞来分别模拟功率衰减异常、噪声异常和拥塞异常。同时,如果接收端的带宽低于发送端的一定比例(例如90%),即判定产生异常,为训练数据贴上标签(例如0、1、2和3分别代表正常、功率衰减异常、噪声异常和IP 层拥塞异常)。训练时,每次只产生一种异常。故障样本总共采集了约17000组,每组训练数据包含排队时延、功率和OSNR 数据,其中训练集和测试集各占90%和10%。通过离线训练,AI 模型在测试集上的准确率达到96.99%。
4 实验展示与结果分析
4.1 NNS 实验验证
本文通过搭建如图4所示的实验平台展示和验证NNS 架构功能。IP 层包含6台可编程交换机,端口为10 GbE 光端口,通过2台商用的分组发送工具来模拟端上的2个业务主机进行通信。EON 层包括6个1×9的BV-WSS 光纤、6个OPM 和8个掺铒光纤放大器(EDFA,erbium-doped fiber amplifier)。BV-WSS 工作频率范围为1528.43~1566.88 nm,频谱分配粒度为12.5 GHz。OPM 采用光信息监测仪(OCM,optical channel monitor),光谱分辨率为312.5 MHz。图4中的箭头表示的是业务通信时的路由路径。从图4中可以看出,业务主机A 与业务主机B 通信时经过2个光路。第一个光路从可编程交换机1到可编程交换机2,包含a 一条链路,第二个光路从可编程交换机2到可编程交换机3,包含b 和c 共两条链路。中央控制器基于开放式网络操作系统(ONOS,open network operating system)平台与数据平面进行通信。为了验证NNS 架构的有效性,本文在EON 层和IP 层各做了一个故障识别、定位和恢复的实验。实验中发送端业务的吞吐量为8 Gbit/s,分组大小为1024 B,INT source 上ML-INT分组的比例设置为50%。EON 层的实验中,通过功率衰减器在c 链路上对功率进行衰减,用Wireshark抓取NNS 架构间的通信数据分组,从而验证NNS架构的功能。图5(a)虚线框展示的是data analyzer(IP 地址为192.168.108.40)向DL 故障识别和定位模块(IP 地址192.168.108.229)发送的一组ML-INT数据,包括switch ID、排队时延、功率和OSNR。每个可编程交换机都有预先定义好的switch ID,通过switch ID 对故障进行定位。例如,业务主机A和业务主机B 通信时IP 层经过3个可编程交换机,switch ID 分别为1、2、3。在c 链路进行功率衰减,第一条光路正常,第二条光路异常。DL 故障识别和定位模块依次ML-INT 数据进行分析,故障类型为1,switch ID 在2和3之间。如图5(b)虚线框所示,Wireshark 抓取的是DL 故障识别和定位模块发送至中央控制器(IP 地址为192.168.108.225)的数据分组,分组中包含的故障类型为1,switch ID 为2和3。中央控制器获取异常信息后,通过带外遥测方式细粒度(例如每1 s 获取1次)获取switch ID 在2和3之间所有链路的光路信息(中心频率、功率和OSNR)并与正常阶段下通过粗粒度(例如每10 s获取1次)获取的光路数据进行对比和分析。由于DL 故障识别和定位模块传输故障类别为1,即功率衰减故障,中央控制器依次分析b 链路和c 链路最近一段时间的功率变化趋势,通过功率变化范围判断(例如功率降低范围超过4 dBm)链路是否产生异常,从而得出c 链路故障。最后,中央控制器通过App 处理模块获取业务的优先级和所属服务类型等信息,将c 链路通过BV-WSS 切换到备份链路进行故障恢复。
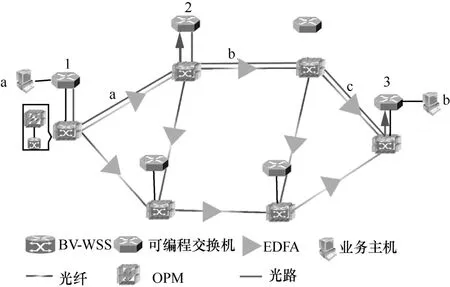
图4 实验测试平台
接收端统计的是每秒收到的帧数,当数据分组大小为1024 B 时,8 Gbit/s 约为950000 frame/s。当c 链路功率衰减异常时,接收端的带宽降为约600000 frame/s,低于QoS 异常监测模块的阈值。c链路上OPM 监测的功率随时间变化趋势如图6(a)所示。OPM 上功率恢复时延经过5次测量取平均值,约为1.97 s。恢复时延主要包括OPM 扫描光谱、DL 故障识别和定位模块进行故障初步识别和定位、中央控制器下发光流表和BV-WSS 重新配置切换链路的时延。图6(b)展示的是业务主机B 的接受带宽随时间变化趋势,端到端恢复时延约为2.99 s,之所以比OPM 上功率的恢复时延要长,主要是由于本文通过商用的分组发送工具来模拟端上的2个业务主机进行通信,然而分组发送工具接收端带宽以秒级进行更新,会对端到端的恢复时延造成一定的影响。
在IP 层,通过加背景流的方式使Switch ID 为2的可编程交换机产生拥塞。背景流发送速率为4 Gbit/s,业务主机A 和业务主机B 之间通信速率为8 Gbit/s,可编程交换机的端口最大接受速率为10 Gbit/s。因为IP 层的拥塞会导致分组丢失,从而导致接收端带宽变低,所以QoS 异常监测模块通过监测接收端的带宽来判断是否有异常发生,然后将异常信息报告至DL 故障识别和分类模块。DL 故障识别和分类模块接收到异常信息后,对ML-INT 数据进行分析,并将故障识别和定位结果报告至中央控制器,其数据分组和图5(b)所示的数据格式相同,故障类型为电层拥塞(对应数字为3),switch ID 1和2传输的分别为拥塞交换机的上一跳可编程交换机(switch ID 为1)和拥塞的可编程交换机(Switch ID 为2)的switch ID。中央控制器结合NTD 存储的底层拓扑信息,通过RSAM 从上一跳可编程交换机进行重路由,避免拥塞的可编程交换机。

图5 Wireshark 抓取数据分组验证NNS 架构
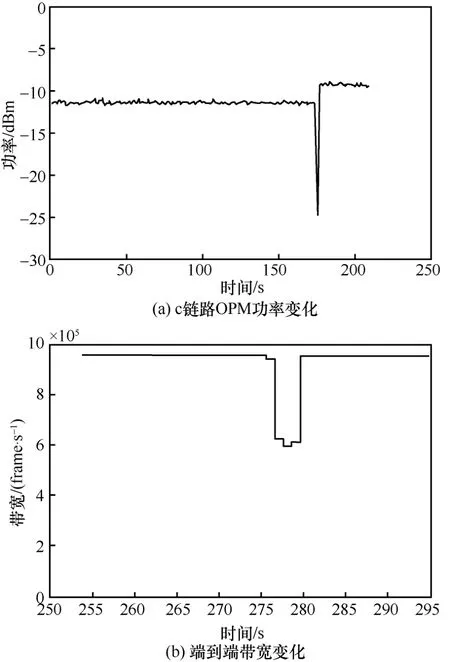
图6 EON 层故障分类、定位和恢复
图7(a)展示的是switch ID 为2的交换机上排队时延变化趋势,正常阶段下排队时延约为0.1μs,拥塞时最高排队时延达到120μs 以上。图7(b)展示的是接收端带宽变化趋势。经过5次测量求平均值,可编程交换机上的排队时延恢复时间约为0.85 s,接收端的带宽恢复时延约为1.99 s。由于分组发送工具接收端的带宽数据以秒级进行更新,导致端到端的带宽恢复时延长于可编程交换机的恢复时延。
4.2 NNS 架构可扩展性验证
为了进一步展示NNS 架构带来的可扩展性优势,如图8所示,通过仿真的方式产生多组数据,横坐标是数据量,每组数据包括时延、功率和OSNR;纵坐标表示对应数据量下所需要的故障分类时间。分类时间在显卡为GeForce GTX 1080Ti的GPU 上进行测试。当数据量低于100组时,分类时间约为0.2 s,当数据量高于10000组时,分类时间明显增多。NNS 采取的是基于ML-INT 的分布式网络数据分析,神经网络所需的数据量基本在100组以下。传统的纯带外遥测集中式地对数据面数据进行分析,当网络设备和链路增多,或者需要采取比链路级别更加精细的网络监测与定位时(例如需要精确定位到链路中具体的设备是否故障,需要监测的数据量进一步增加),都会显著增加神经网络的分类时间和定位时间。值得注意的是,因为纯带外收集数据的方式没有结合App-level 端到端的异常信息,需要时刻对获取到的数据进行分析;而NNS 架构在无异常发生时,不需要对收集到的数据进行分析,仅需在产生异常时对数据进行初步识别和定位,因此NNS 架构在一定程度上减轻了神经网络的处理负担。
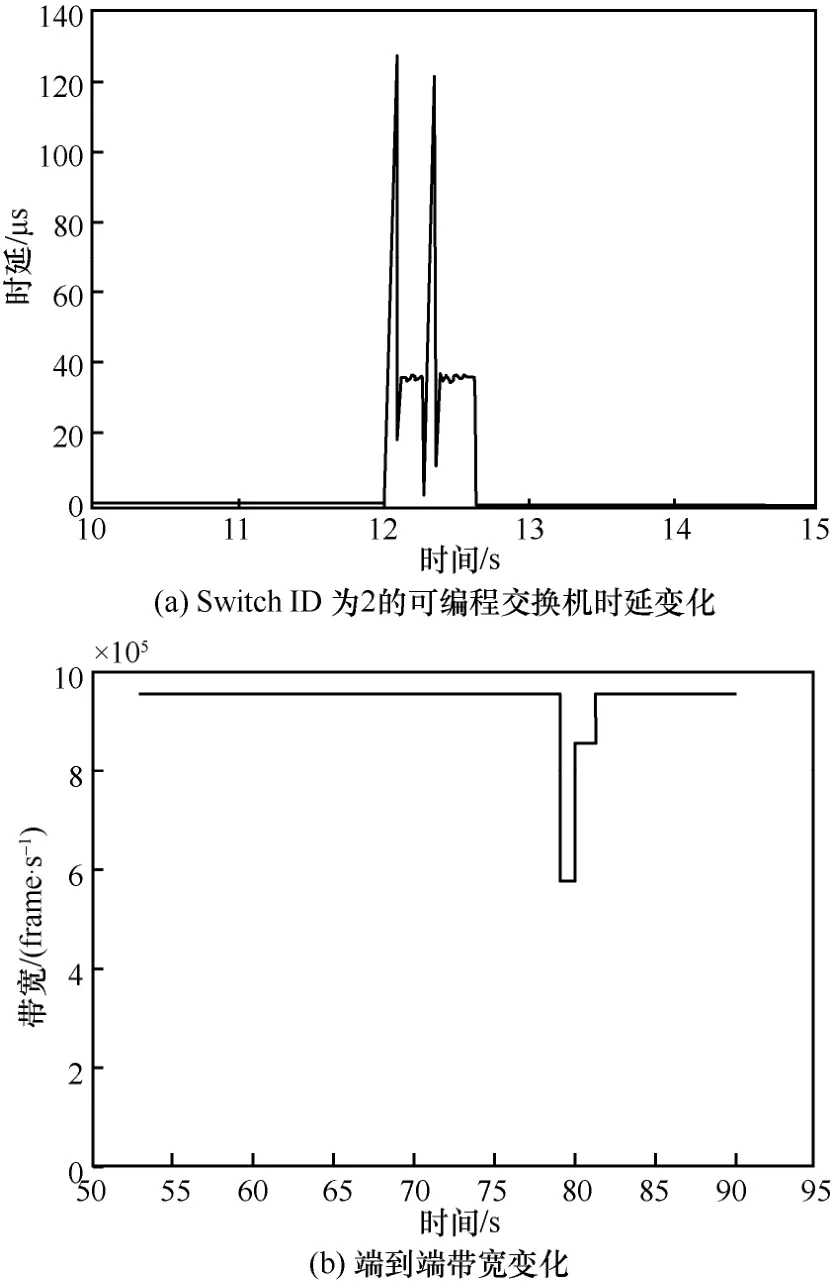
图7 IP 层故障分类、定位和恢复
NNS 架构采取App-level 的分布式方式分析,因此无异常发生时,中央控制器进行粗粒度的带外遥测,异常发生时再对故障光路进行细粒度的带外遥测。纯带外遥测方式的传统架构为了实现细粒度和实时的网络监测,无论是正常还是异常阶段,中央控制器都需要进行细粒度的带外遥测。图9展示了NNS 架构和传统架构在正常情况和异常情况下南向通信量的比例。本文设定粗粒度的轮询时间间隔为10 s,细粒度的轮询时间间隔为1 s。为了确保通信分组的大小相同,本文用同一个OPM 进行实验,通过Wireshark 获取中央控制器一段时间(10 min)内接收到的平均分组速度。如图9所示,通过5次实验获取平均值,正常阶段下,NNS 架构与传统架构的每秒平均分组速度比为0.379:2.359;异常阶段下,两架构每秒的平均分组速度之比为1:1。当发生异常的频率较低时,NNS 中央控制器每秒平均分组速度将远低于传统架构,进一步减少了控制器的负担,增加了可拓展性。
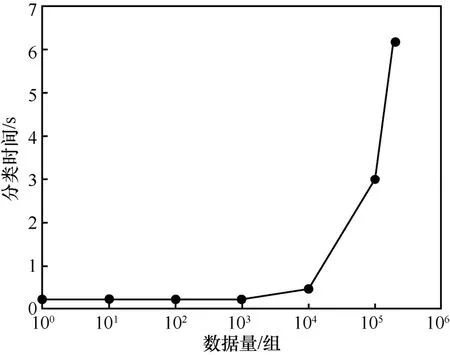
图8 AI 模块分类时间趋势

图9 中央控制器南向通信量对比
5 结束语
本文提出了基于深度学习的跨层网络业务性能感知系统,融合了分布式网络监测与集中式网络管控的优点,实现了细粒度和实时的网络监测。本文通过搭建小规模的实验平台,实现并展示了NNS 架构的优势。无论IP 层还是EON 层产生异常,NNS 架构都可以精确快速地进行故障分类、定位和恢复。同时,通过故障识别和定位时间与中央控制器南向通信量的比较,NNS 架构相比传统的纯带外监测系统,有着更加良好的可拓展性。
猜你喜欢
小学生学习指导(低年级)(2019年3期)2019-04-22 03:34:48
电子制作(2019年23期)2019-02-23 13:21:12
测控技术(2018年6期)2018-11-25 09:50:10
网络安全和信息化(2018年6期)2018-11-07 09:05:02
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:42
网络安全和信息化(2017年8期)2017-11-07 11:49:38
小学生导刊(低年级)(2017年1期)2017-06-12 12:07:42
系统工程与电子技术(2016年7期)2016-08-21 13:59:18
电测与仪表(2016年17期)2016-04-11 12:38:28
电子设计工程(2015年6期)2015-02-27 12:05:04
