
基于角标随机读取的Snort报警数据聚合方法
2019-11-28 07:54:12陶晓玲周理胜龚昱鸣
桂林电子科技大学学报 2019年4期
陶晓玲, 周理胜, 龚昱鸣
(1.桂林电子科技大学 广西高校云计算与复杂系统重点实验室,广西 桂林 541004;2.桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004;3.桂林电子科技大学 信息与通信学院,广西 桂林 541004)
随着网络技术的快速发展,安全问题也越来越突出。通常,网络管理员采用多个网络安全设备同时上线工作,以应对多样化的黑客入侵。然而,由于各个网络安全设备工作时大多处于独立状态,很容易导致同一个攻击事件产生大量的冗余报警现象。报警数据聚合是解决网络入侵检测系统产生大量重复报警数据的重要手段,旨在将同一安全事件诱发的大量性质相同或相近的报警合并成一个报警(超报警)[1],能减少报警数据冗余,降低系统误报率,提高检测率,从而有利于网络管理员及时地掌握网络的运行状态,也便于后续的报警数据融合和关联分析。通过改进入侵检测系统报警数据的读取方式及处理方法,以提高报警数据聚合方法的检测性能。
Ahmed等[2]从各个不同学科对报警聚合技术做了全面的综述,将其分为基于统计数学的聚合技术[3]、基于知识推理的聚合技术[4]、基于数据挖掘的聚合技术[5]和基于哈希函数的聚合技术[6],同时,分别阐述了各类报警聚合技术的优缺点,总结出近年来在聚类和人工神经网络方法方面的研究趋势。Elshoush等[7]指出,基于属性相似度的聚合方法存在不足之处是报警中的时间戳和IP地址等属性在聚合中具有特殊作用,将其代入运算在一定程度上缺乏合理性。冯学伟等[8]通过报警数据的源/目的IP地址之间的相互关联关系在各簇内部进行报警聚合,但此方法存在一定缺陷,不适用于处理DDOS等完整攻击场景。Ghasemigol等[9]指出时间属性窗口设置过大或过小都会影响报警聚合的有效性。针对此问题,邱辉等[10]将流式处理方法引入滑动时间窗口,从而达到报警数据聚合的目的,但该方法的不足在于当前窗口和滑动窗口的大小仍需主观确定。Fatma等[5]提到在第二阶段使用带有k-means的SOM算法并不是非常有效,因为管理员需要手动检验2个属性来确定哪个簇包含真正的报警频率和时间间隔的报警数据。Thang等[11]基于密度的方法,将报警集合的高密度区域划分为一个类,能够发现任意形状的类,且聚类精度较高,但对输入参数敏感。Banumohamed等[6]从报警数据中提取3个属性,并将这些属性结合MD5散列函数生成用于初始聚类过程的唯一哈希值,但这种技术是基于字符串散列值的比较而不是直接的字符比较,通常需要对文本进行预处理。Saad等[12]为不同的攻击类型设置不同的阈值,采用顺序聚类的方法,将相似度高于阈值的报警进行合并,操作简单,适用范围广,但具有较强的次序依赖性和缺乏灵活性。
综上所述,目前的报警数据聚合方法在读取数据时均采用顺序读取方式,处理方法单一,缺乏灵活性,从而影响聚合效果。为此,提出角标随机读取来实现Snort报警数据聚合。
1 Snort报警数据聚合方法
1.1 报警数据标准化
不同的IDS系统产生的报警数据格式不同,若直接聚合分析,将造成很大不便。基于此,必须对报警数据进行统一的标准化,方便后续的聚合处理。借鉴国际标准入侵检测消息交换格式IDMEF(intrusion detection message exchange format)来规范IDS入侵检测报警格式。目前大多数的安全检测系统都支持IDMEF格式报警的输出。一个Snort报警数据包括规则号、规则名称、优先级别、时间戳、原始IP、目的IP、协议类型、源端口、目的端口、报警类别等10种属性构成的10元组,形式化Alert={signature,sig_name,sig_priority,timestamp,ip_src,ip_dst,ip_proto,layer4_sport,layer4_dport,sig_class_id},本研究以每个报警数据包代表每条报警数据,其每个属性的含义如表1所示。
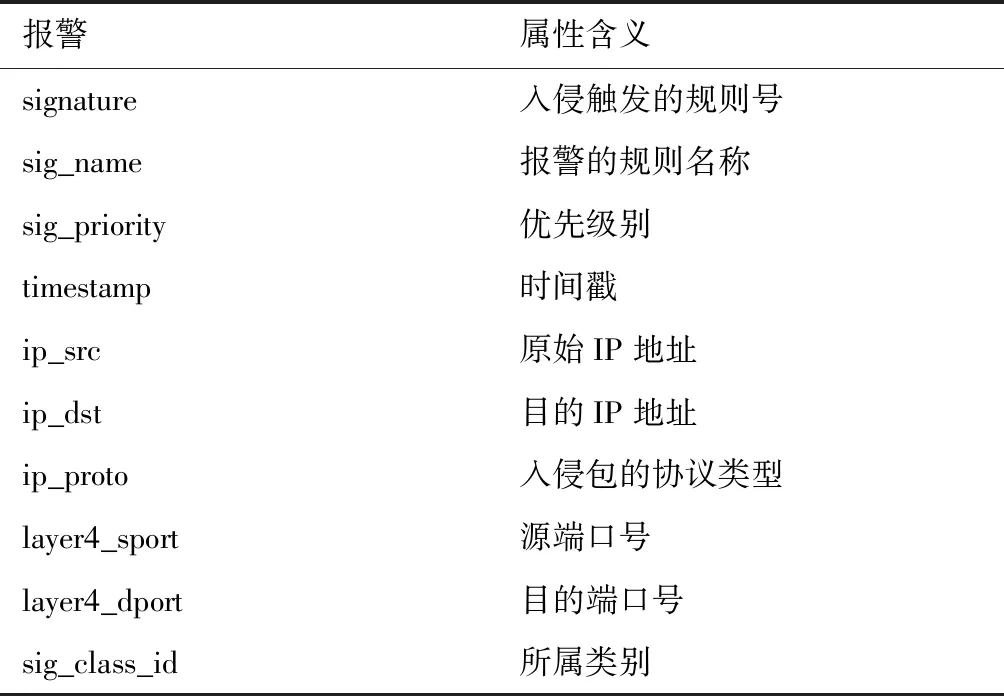
表1 报警数据属性含义
1.2 报警数据预处理
报警数据的预处理从传感器采集到的原始报警数据出发,采用数据清理、属性选择和数据过滤等方法来初步消除原始报警数据本身的缺陷,从中抽取能够用于聚合的主要属性并存储在数据库中,最后通过设置计数迭代式固定时间阈值过滤的方法,减少重复报警数据的数量。其中,重复报警数据是每2条报警数据间除了时间属性之外其他属性内容均相同的报警数据,其参数符号说明如表2所示。

表2 参数符号说明表
以下给出了计数迭代式固定时间阈值预处理方法的具体伪代码。
algorithm:SnortAlertProcessingByFilter(A,time,count,timeDiff,N)
Input:alert set in uniform formatA={n∈N,a1,a2,…,an};
Output:AlertByFilterB={n∈N,b1,b2,…,bn};
1. Begin
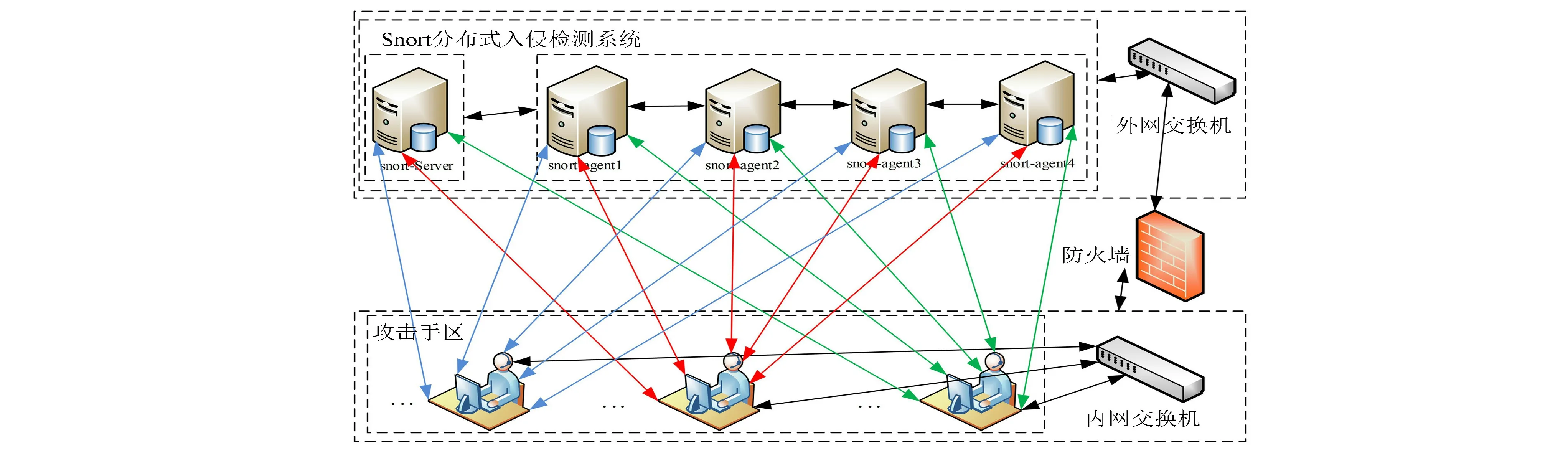
2. for (n=0;j 3. time=0 4. ifA=φthen 5. break 6. else 7. while new two alertai,ai+1is received do 8. if(timeDiff(ai,ai+1)<60) andai_attributes=ai+1_attributesthen 9. delete(ai+1) 10. B.add(ai) 11. count=count +1 12. else 13. B.add(ai), B.add(ai+1) 14. time ++ 15. if (time=1) 16. then FileReader(“AlertByFilter.txt”) 17. else FileReader(“AlertByFilter”+(time-1)+”.txt”) 18. end 由伪代码可知,计数迭代式固定时间阈值预处理过程分为4个阶段:1)对需预处理的Snort报警数据进行集合封装(表3的Input部分)。 2)从本地数据库的相关Snort表进行join操作,生成所需的报警数据表,同时,对整个Snort报警数据文本进行每2条顺序读取加载,若读取到最后一行,则直接跳出循环,否则一一加载到集合(伪代码的第1~6行)。 3)将报警数据记录按照指定的时间属性升序排序,在排序后的数据集上移动一个60 s的固定大小时间窗口,每次只检测timeDiff小于窗口内的报警数据。判定它们是否匹配,以此来逐步减少比较次数,从而达到初步预处理过滤的目的(伪代码的第7~13行)。 4)以计数迭代不断循环比较出最精简记录的方式,使得重复率达到最低(伪代码的第14~17行)。 角标随机读取方法用于将精简后的中间Snort报警数据以随机生成角标的方式达到每条报警数据随机打散排列的目的。算法用到的相关参数符号如表3所示。 表3 角标随机读取算法参数符号说明表 以下给出了角标随机读取方法的具体伪代码。 algorithm:CMRR(B,Q,M,I,N,R) Input:AlertProcessingByFilterB={n∈N|b1,b2,…,bn}; Output:AlertByCMRRC={n∈N|c1,c2,…,cn}; 1. Begin 2. forn=0 toN-1 3. ifB=φthen 4. break 5. else 6. Collections.sort(B(Snort),newComparator 7. Public int compare(Snort s1,Snort s2) 8. return s1.getTimeStamp().compareTo(s2.getTimeStamp()) 9.Q(B(Snort))=getSnortsWithMonth(B(Snort)) 10. fori=0 toQ.size 11.I(i)=getRandomIndex(Q[i]) 12.M(i)=getRandomSnortsByMonth(I(i)) 13.R.add(M(j)) 14. returnR(Snort) 15. End 由伪代码可知,基于角标随机读取方法的过程分为3个阶段: 1) 对精简后的Snort报警数据进行集合封装(伪代码Input部分)。 2) 对整个Snort报警数据文本进行逐条顺序读取加载,若读取到最后一行,则直接跳出循环,否则一一将加载到集合(伪代码的第1~5行)。 3) 对数据按照时间属性进行升序排序和分月份划段处理,再对每个月内的数据进行随机打散排列。 其中,先将每个月内随机打散后的中间报警数据用M集合存储,再统一用R集合重新存储,得到最后的报警数据(伪代码的第6~14行)。其中,每遍历一次,取2条报警数据所在行号,得到生成的随机数与角标标记区进行比较,若第一次出现,则将其存入并退出当层循坏,否则重新生成随机数取值再进行比较。 报警数据相似度计算是一种基于各属性之间几何距离的简单数值运算,是数据聚合的基础。报警数据聚合方法的目标是对初级报警进行数据聚合,找到它们之间的关联性,从而生成高级报警,消除重复报警。 给出各个Snort报警数据属性特征的相似度计算函数。 1) 报警标识相似度的计算。signature,sig_priority,ip_proto,lay4_sport,lay4_dport若相同,则相似度设为0,若不相同,则相似度为1。 2) 报警名称相似度的计算。sig_name对应于每条报警规则语句里的Msg,如将从每条报警数据该属性对应的字符串Snort Alert[1∶2 000 419∶0]值中提取2 000 419,考虑自身数据特点,得知介于区间[2 000 334,2 221 030]和[2 400 001,2 522 312],基于此,结合Tableau工具,统计此属性的特点,计算出相似度值,其计算公式设置为 Simname(Alerti,Alertj)= (1) 其中:Simname(Alerti,Alertj)是报警数据的名称相似度值;Alerti和Alertj分别表示第i条和第j条报警数据;Alert.signame是报警数据的名称属性。 3) 报警时间戳相似度的计算。在报警聚合中报警时间是很重要的一个因素,对计算全局相似度的时候具有重要的影响。将时间间隔Tinternal与预设的最小阈值tmin及最大阈值tmax进行比较,当时间间隔小于tmin,则相似度为0,大于tmax,则相似度为1,若在tmin和tmax之间,则由公式计算得到。tmin和tmax的选取,不同参考文献给出不同的数值。参考Long等[13],给出tmax-tmin=300 s及实际情况将阈值计算公式为 Simtimestamp(Alerti,Alertj)= (2) 其中:Simtimestamp(Alerti,Alertj)是报警数据时间戳的相似度值;Alerti和Alertj分别表示第i条和第j条报警数据;Alert.signame是报警数据的名称属性。 4) IP地址相似度的计算。对于IP地址的比较,采用无类别域间路由的格式进行分析,将每2条报警数据相同的二进制位个数r除以IP地址二进制位长度的值作为2个IP地址的相似度[14],其计算公式设置为 (3) 其中:Simip(Alerti,Alertj)是报警数据的IP相似度值;Alerti和Alertj分别表示第i条和第j条报警数据。 通常对于报警数据属性权重的确定计算方法,一般来说有2大类:一类是人为的主观判断对不同属性打分,比如基于一些专家的结论来进行打分,根据层次不同来进行分析、认为经验来进行判断等;另一类是客观方法,如熵权计算方法、主成分分析方法等。因在评标过程中,不同属性的权重对被评价对象的不同得分影响非常大,因此需要尽可能客观去评价和打分,所以,通过客观计算法计算属性的权重是优先考虑的。同时,考虑到一般采用PCA需要数据比较,难获取且存在相关及多重共线性问题,同时,它并不考虑因变量和自变量之间的关系,无法充分体现每个主成分的作用,因此选用熵值法来确定各个指标的权重计算。 报警数据能否聚合关键取决于报警数据之间的全局相似度,在计算全局相似度时,需为每种报警属性设置一个权重W,用来衡量该属性在计算全局相似度中的重要性。通过MATLAB 2016计算得知,权重矩阵为[ 0.000 1 0.045 2 0.013 0 0.047 1 0.000 5 0.004 6 0.035 3 0.272 1 0.582 1]。 Simsum(Alerti,Alertj)= (4) 其中:Simsum(Alerti,Alertj)为报警数据的总相似度;i,j为属性权重时报警数据所在的行号;c为报警数据的属性所在的列号;Wc为报警数据各个属性的权重;Alert(i)attributes和Alert(j)attributes分别为第i条和第j条报警数据的每个属性的集合;n为报警数据的条数。 由于Snort收集到的大量报警数据中存在重复冗余数据,通过设置较高期望值可有效去除一定的冗余,达到进一步精简报警数据目的。Snort聚合计算用到的相关参数符号如表4所示。 表4 Snort聚合计算参数符号说明表 以下给出了Snort聚合计算的具体伪代码。 algorithm:SADAA(S,W,SW,H,a,b) Input:AlertBySW SW={n∈N|Sw1,Sw2,…,Swn}; Output:AlertBySADAAE={n∈N|e1,e2,…,en}; 1. Begin 2. forn=0 toN-1 3. if SW=φthen 4. break 5. else 6. fori=0 to SW.size 7. for(H=0.1 to 0.9) 8. if getSumSim(SS(i)) >Ha++; 9. elseb++; 10. computeAggregation(); 11.End 由伪代码可知,分为4个阶段: 1) 对计算总相似度后的Snort报警数据进行集合封装(伪代码的Input部分)。 2) 对整个Snort报警数据文件进行逐条顺序读取加载,若读取到最后一行,则直接跳出循环,否则一一将加载到集合(伪代码的1~5行)。 3) 读取指定的每条报警数据总相似度属性列的内容,分别与期望阈值集合进行比较,并统计满足条件的报警条数(伪代码的6~9行)。 4) 进行聚合函数计算(伪代码的第10行)。 为了验证提出的基于角标随机读取的Snort报警数据聚合方法的有效性,实验室搭建了真实的数据采集平台,环境为OSSIM开源平台下的Snort分布式入侵检测系统。实验整体采集环境拓扑图如图1所示。 图1 数据采集平台拓扑图 通过搭建入侵检测系统Snort并配合搭建LMAP、PHP、PEAR、ADOdb、BASE、HTML、MySQL、Libdnet、Libpcap、DAQ、Barnyard2的环境来直接对采集到的报警数据进行预先查看和分析。系统搭建完成后,通过BASE登录,将实时监控网络数据包,并通过数据库输出接口将入侵日志传送到MySQL数据库中,数据分析控制台则可通过数据库接口读取数据,并显示在BASE上。 数据预处理环境为:Win 10 + VMware Workstation 12 + CentOS 6.5 + Snort 2.9.7.0 + Barnyard 2.1.13+ Base 1.4.5 + MySQL5.1.73 + Eclipse Mars。数据属性相似度及权重计算环境为:Win 10 + Eclipse Mars。数据聚合及系统评价指标环境为:Win10 + Eclipse Mars + JDK1.8 + Matlab2016 + IBM SPSS Statistics 24。 利用数据库的输出插件Barnyard2,将采集到的报警数据记入到数据库MySQL。通过在OSSIM环境下部署snort-agent1到snort-agent4共4个数据采集节点,snort-server作为服务端节点。总共采集Snort报警数据63 306条。以每个Snort报警数据类别属性为分析基础,进一步细化得到的分类结果如表5所示。 表5 原始Snort报警数据分类表 采用计数迭代式固定时间阈值预处理过程的方式来对报警数据进行预处理,将原始报警数据集A进行数据标准化,对其以time计数迭代来不断循环,达到控制每相邻报警数据间的比较目的,将timeDiff小于设定窗口值内的重复报警数据精简到最低。 为了衡量报警数据预处理的效果,实验分析中定义报警数据精简率来作为评价标准。假设原始报警数量为srcsnort个,精简后报警为dstsnort个,其报警数据精简率公式为 (5) ReduceRatesnort用来反映聚合方法消除重复和冗余报警的效率,ReduceRatesnort越大,表示精简越高,也就说明报警冗余去除的效果越明显,提供给下一层数据聚合处理的数据源质量也就更高。精简前后各类别的Snort报警数量分别如图2和图4所示,精简前后各类别的Snort报警数量占比情况分别如图3和图5所示。 图2 精简前各类别的Snort报警数量 图3 精简前各类别的Snort报警数量占比 图4 精简后各类别的Snort报警数量 图5 精简后各类别的Snort报警数量占比 通过实验结果得到srcsnort为63 306条,dstsnort为22 162条,总的报警精简率为65%。 为了验证提出方法的有效性,将本方法与文献[15]的方法进行对比,通过训练取期望值H在不同值时聚合效果对比,结果如图6所示。从图6可看出,在H<0.6时,聚合率均低于50%,且有小幅上升,在0.7≤H≤0.9时,聚合率维持在90%左右并保持平稳。同时,期间发生了一次较大幅度的增长跳跃变化,通过分析,变动期望值可以将相似度较高的报警数据合并为一类,从而进行下一步分析,由此生成超报警信息库,因而将期望值设为0.7。 图6 不同期望值下Snort报警数据聚合率对比 由此可见,在一定程度上本方法从反向思维来计算报警数据属性相似度,相比常规手段的顺序聚合而言,更能使得聚合率提高并维持平稳。 同时,为了验证所提方法的有效性,还定义了误报率和检测率来作为评价系统检测性能的指标。基于此,根据以下规则对收集到的报警数据进行了标定。 如果一条报警数据满足[15]以下3个条件: 1) 源IP地址符合模拟的攻击IP地址; 2) 目的IP地址符合模拟攻击的受害机IP地址; 3) 报警的时间戳在模拟攻击所发生的时间窗之内。 则该条报警被标记为真报警,否则就被称为误报警。 经标定后,数据集含有45 002条真报警和18 004条误报警。以70%随机抽取作为训练数据集,30%作为测试数据集。类似Pietraszek[15]定义的反映报警处理性能的指标,给出了一个混合矩阵C,如表6所示,表中“+”代表真报警(攻击报警),“-”代表误报警。 表6 混合矩阵C 基于此,定义一组反映报警处理性能的指标。 Snort报警数据检测系统的系统检测率(TPsnort)计算公式为 TPsnort=C11+C22/(C11+C12+C21+C22)。 (6) Snort报警数据检测系统的系统误报率(FPsnort)计算公式为 FPsnort=C21/(C21+C22)。 (7) 使用SPSS里的CHAID树算法作为Snort报警数据检测系统的检测方法,系统分别采用本方法(简称方法1)和文献[13]的聚合方法(简称方法2)进行检测性能比较。两者的系统检测率和误报率对比情况如表7所示。 表7 系统检测率与误报率对比 % 由表7可知,方法1的检测率为89.64%,高出方法2的检测率13%左右,在一定程度上说明对真报警还是误报警的判定有着明显的作用,而且误报率也有所降低。 同时,为了对比2种方法的运行效率,定义了系统检测平均运行时间为 TA=T/n。 (8) 其中:T为检测方法运行的总时间;n为测试数据样本总数。2种方法的平均运行时间对比如表8所示。 表8 平均运行时间对比 由表8可知,方法1比方法2的系统检测平均运行时间略少,可以稍微加快系统检测运行效率。 针对现有的Snort报警数据聚合方法中报警数据读取方法单一,进而影响聚合效果的问题,提出了一种基于角标随机读取的Snort报警数据聚合方法。该方法通过角标随机读取算法实现报警数据随机打散读取,并灵活计算属性相似度。实验结果表明,提出的方法有效地提高了Snort报警数据的聚合率,而且提高了入侵检测系统的检测性能。针对动态复杂情况下持续性攻击引发的多个报警事件时间间隔变化的问题,如何进一步有效地提高报警数据聚合效果,将是后续研究的主要内容。1.3 角标随机读取算法设计

1.4 属性相似度的计算

1.5 属性权重的确定
1.6 聚合计算

2 相关工作实验及结果分析
2.1 实验环境

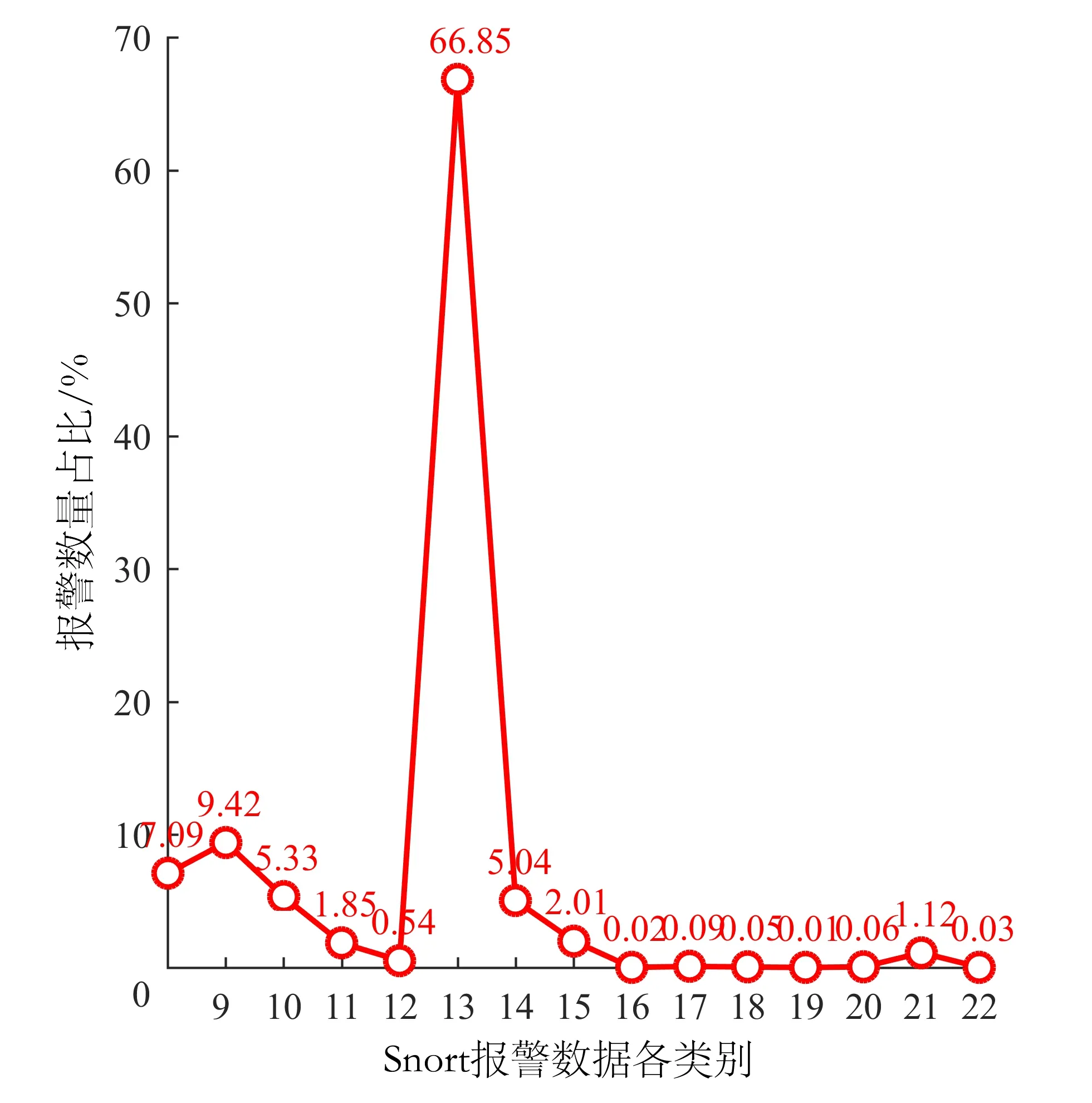
2.2 预处理结果及分析



2.3 聚合结果及分析




3 结束语
猜你喜欢
海南热带海洋学院学报(2022年2期)2022-05-09 13:22:56
铁道通信信号(2020年11期)2020-02-07 01:02:20
课程教育研究(2019年22期)2019-07-02 08:58:20
特别健康(2018年2期)2018-06-29 06:14:00
电子制作(2017年17期)2017-12-18 06:40:47
黑龙江电力(2017年1期)2017-05-17 04:25:16
计算机工程(2014年6期)2014-02-28 01:25:08
作文与考试·小学低年级版(2013年5期)2013-04-29 00:44:03
作文与考试·小学低年级版(2013年6期)2013-04-29 00:44:03
计算机应用文摘(2010年4期)2010-04-29 00:44:03
