
分布式水文模型EasyDHM在增江流域的应用研究
2019-11-28 06:44吴梦琪廖卫红廖春梅
中国农村水利水电 2019年11期
吴梦琪,廖卫红,廖春梅,刘 攀
(1. 武汉大学水资源与水电工程科学国家重点实验室,武汉 430072;2.中国水利水电科学院,北京 100038;3.国家电网公司西北分部,西安 710048)
0 引 言
增江是东江的一级支流,纵贯增城市中心城区,增江流域地区为自北向南地势由高逐渐变低,中南部丘陵山地较多,然而由于降雨时空分布不均,造成流域内径流量的时空分布不均。同时,随着经济的不断发展和人民生活水平的不断提高,地区用水量急剧增加、水质日益恶化,致使广州市增城区出现水质性缺水[1]。
对增江流域的径流量变化、流域内降水的时空分布等方面研究较多,但基于水文模型对增江流域水文循环过程进行模拟的研究还相对较少,其中毛维新等[2]研究了数字高程模型和新安江模型相结合的半分布式水文模型的建模思路,并证明在该流域内切实可行;刘战友等[3]针对增江流域水循环和水文资料特点,建立了三水源新安江模型与GIS结合的半分布式水文模型。本文考虑到增江流域地区为丘陵地带,下垫面情况复杂,因此建立增江流域分布式水文模型,通过对水文站的径流进行模拟,为下一步实现流域洪水预报及水资源评价工作奠定基础。
1 分布式水文模型EasyDHM
本文采用的是中国水利水电科学研究院自主研发的分布式水文模型EasyDHM模型。目前,分布式水文模型的难点在于模型的建立,而EasyDHM模型拥有一套自己的建模工具,由EasyDHM模型代码和MWEasyDHM系统组成。EasyDHM模型代码包含产流模块、汇流模块、地下水模块、水质模块、土壤侵蚀模块、人工用水模块、水库调度模块、参数识别模块等8大模块[4]。EasyDHM模型系统--MWEasyDHM以开源GIS软件MapWindow作为基础,由以下两大模块组成:模型前处理,其中包括水文分析、子流域划分、模型参数推求、气象数据插值等功能,为EasyDHM模型提供了一个快速建模的软件环境;模型后处理,其中包括模型实时计算、参数自动/手动识别模块、模型结果分析、模型结果时空展示等,为EasyDHM模型提供了一个快速计算、快速率定的软件环境[5]。
该模型基于流域DEM、河流分布、土壤分布、土地利用分布等下垫面数据对研究区域进行单元划分。首先,根据水文站和水利工程的空间分布将研究区域划分为若干个参数分区,可在各个参数分区中分别进行参数率定工作;为更好地体现流域的空间差异性,同时能解决采用小网格单元带来的计算负担过重的问题,基于下垫面属性,每个参数分区又被细化分为多个子流域和内部空间单元。在研究流域被进行空间划分之后,运用插值方法将降水、风速、温度、湿度、太阳辐射等[6]气象信息也进行空间离散。在对水循环过程进行模拟时,该模型不仅支持自主开发的EasyDHM产流模型,同时也支持新安江模型、WetSpa模型、TOPMODEL等模型。汇流模拟可选用圣维南方法、马斯京根法进行计算。
EasyDHM中还嵌入了多套参数敏感性分析方法和参数优化方法。现有参数敏感性分析方法一般可分为局部分析法和全局分析法。一次二阶矩法、随机OAT法等均属于局部分析法,主要是选取局部参数变化,分析对模型输出造成的影响。全局分析法侧重分析所有参数对模型模拟结果的影响,包括Monte Carlo方法、Latin-Hypercube模拟法、基于方差的分析法、LH-OAT方法等。在分布式水文模型的参数优化中,优化算法一般分为局部优化算法和全局优化算法。全面优化的结果较局部优化更有说服力,模型中可选用遗传算法(GA)、多目标粒子群算法(MOPSO)、动态维度搜索算法(DDS)、SCE-UA算法等进行优化计算。对于目标函数,模型中也有多种类型可供选择。在此次增江流域的EasyDHM模型参数率定中,选择DDS算法,以残差平方和SSQ为目标函数进行参数率定。
2 模型建模
建立分布式水文模型需要的数据包括增江流域的DEM数据,数字河网,土地利用数据,土壤类型数据及流域的水文数据。本研究采用的DEM地表高程原始数据来自美国联邦地质调查局的HYDRO1K;土地利用源信息来自于《中国资源环境遥感宏观调查与动态研究》课题的研究成果数据的全国分县土壤覆盖矢量数据,采用增江流域2000年的土地利用类型数据;土壤基础信息采用来自第二次全国土壤普查的汇总资料。
本研究中选取增江干支流上的2个水文控制站点和上游1个水库参与流域模型构建。在EasyDHM中,为了精细刻画模拟流域水文过程,采用了子流域划分、气象数据插值、根据流域的下垫面属性初步确定产汇流参数,再根据参数的敏感性分析结果对敏感性较高的参数进行参数的自动率定等步骤。
首先,对原始DEM数据进行降低实际河网位置对应的栅格的修正处理,通过给定最小水道集水面积阈值50 km2,将集水面积阈值超过给定阈值的栅格定为河网的单元,从而可得到数字河网水系,如图1所示。EasyDHM模型可根据不同的土地利用类型,推求得到模型所需的部分产流、汇流参数初始值,而土壤质地特征直接影响降雨的产流过程[7-9]。

图1 增江流域DEM图及水文气象站点分布图
在生成的数字河网的基础之上,利用通用复杂流域、区域子流域划分算法进行子流域的划分[11,12]。由于麒麟咀水文站之后只有水位站的数据而没有水文站及雨量站的资料,缺乏实测流量记录,无法进行参数率定,同时麒麟咀以下河段受到潮位影响,流量会有周期性变化,不能单纯地用水文模型来进行预报。综合以上因素,此次建模选择了麒麟咀水文站作为流域出口。研究区域共划被分为25个子流域。在本模型研究中,根据2个水文站、1个水库,将增江流域划分为3个参数分区,如图2。天堂山水库、渡头水文站、麒麟咀(二)水文站为各区控制点,各个分区分别进行参数率定工作。

图2 增江流域的子流域及参数分区划分示意图
雨量数据来自17个雨量站的实测数据,气象数据来自该流域内及周边气象站的观测数据,包括温度、太阳辐射、湿度、风速等,所有气象及雨量数据均为点数据,需要进行空间离散展布为面数据。增江流域模型中采用泰森多边形法进行空间展布[10],根据距离栅格最小站点的数据作为此栅格的数据,再统计到子流域中,得到子流域的面平均气象数据。
3 模型参数敏感性分析
EasyDHM模型参数包括产流参数和汇流参数[10,11]。本文采用LH-OAT全局分析法[16]对残差平方和SSQ及平均流量两个指标对参数进行多次敏感性分析,得出各参数的相对敏感度大小,从而可分析出各因子对模型影响程度。两目标函数分别如式(1)、(2)计算:
(1)
(2)
式中:Xsim,i为模型在时段i模拟出的水文站出口流量,m3/s;Xabs,i为时段i对应的水文站实测流量,m3/s。
(3)
算法中采用公式(3)计算参数的敏感度,式中Si,j为参数ei第j个LH抽样集合的敏感度,fi为参数ei的变化比例,M(e1,…,ei,…,ep)代表第j个LH抽样集合的指标函数,M[e1,…,ei(1+fi),…,ep]代表第i个LH抽样集合上改变ei为ei(1+fi)后的指标函数。根据相对敏感度大小,可分为4类:极高敏感(≥1.0)、高敏感(0.2~1.0)、中敏感(0.05~0.2)和低敏感(<0.05)。
模拟结果以Nash-Sutcliffe系数(以下简称Nash系数)来进行评定。Nash系数越接近1,则模拟效果越好。Nash系数计算公式为:
(4)
参数敏感性分析结果以渡头站为例,如表1所示,图3为渡头站的不同目标函数各参数敏感度分布图。
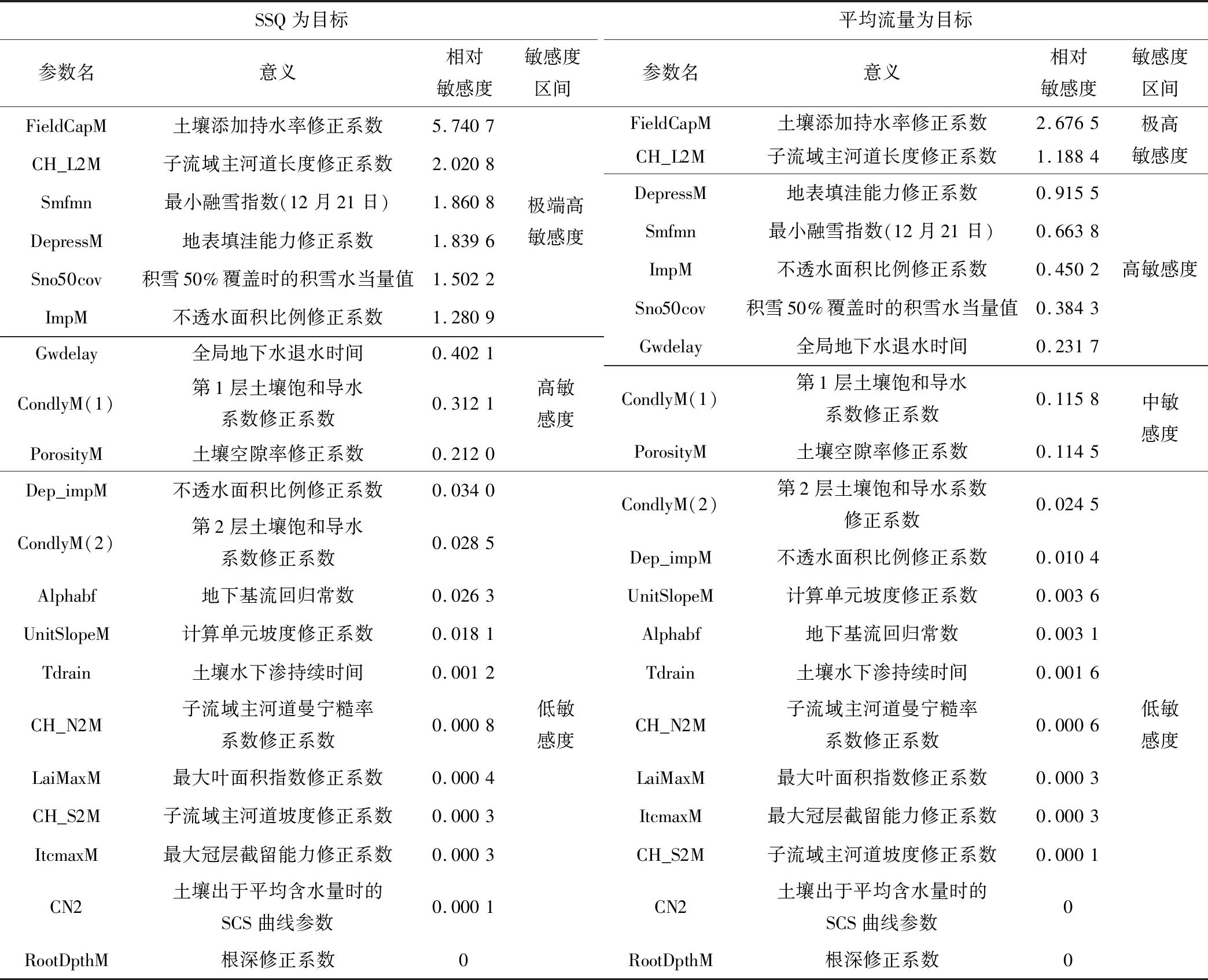
表1 渡头站参数敏感性分析结果

图3 不同目标函数各参数敏感度分布图(渡头站)
由表1及图3可知,在以平均径流量为目标函数时,最大叶面积指数修正系数、最大冠层截留能力修正系数的敏感性较高,土壤冻结冻融参数、融雪积雪参数等表现出完全不敏感,这与增江流域上游区域内的植被较多且地处亚热带气候,冬季严寒气候较少相符合。对于渡头分区,我们可以发现对比以模拟SSQ、平均径流量作为目标函数进行敏感性分析时,以SSQ为目标函数的参数敏感性更高,说明了模型模拟效果不仅仅体现在模拟结果,还应关注模拟值与实测值的相对或绝对误差。同时,结合其他站点的参数敏感性分析结果,可知各个站点参数敏感值最大的均为土壤田间持水率修正系数、地表填洼能力修正系数也较高,说明在增江流域分布式水文模型中土地利用类型及土壤类型的影响较大;而从总径流构成上来看,土壤参数敏感度及地表径流参数与地下水模拟参数的敏感度相比都较高,说明在增江流域中,地下水的影响较小,地下径流稳定,径流量的变化主要体现在地表径流及壤中流中;观察到子流域主河道长度修正系数均为极端高敏感系数,说明,在增江流域中除了产流模块影响较大之外,汇流模块也对模拟结果有着重要影响。
4 模型参数率定
由于分布式水文模型参数数目较多,对所有参数同时优化效率太低,因而仅优化经参数敏感性分析所选出的极端高敏感度参数和高敏感度参数(统一称为敏感参数),利用DDS算法[7],先进行全局搜索,随着迭代次数的增加逐渐转向近似局部的搜索,以SSQ为目标函数对敏感度高的参数进行优化率定,得出优化结果。
由于天堂山水库站资料的缺乏,本文仅以渡头站、麒麟咀站为例来说明模拟参数率定的效果。以2008年至2010年为率定期,选取三年内多场次洪水采用日时间步长水进行组合率定,得出参数最优值,如表2及表3。麒麟咀水文站选取2012及2013两年作为验证期,而由于渡头水文站缺失2012年的气象数据,因此选定2007年及2013年验证进一步验证各参数分区率定结果的可靠性。表4为率定期及验证期的部分洪水场次模拟结果。

表2 渡头站产汇流参数最优值

表3 麒麟咀站产汇流参数最优值
从表4模拟结果可以看出,水文站的率定结果都较好,挑选的洪水场次的Nash系数均在0.5以上。麒麟咀水文站的洪水模拟效果略差,从2008年的麒麟咀水文站的模拟结果图可以看出,模拟结果和实测值存在滞后效果,实测值的径流流量相对模拟值滞后将近一天的时间,麒麟咀水文站处于流域的中下游地区,在增江流域中建有多个拦水坝,而在径流过程中拦水坝影响了汇流过程,位于模拟区域的出口处的麒麟咀水文站所测得的径流流量,导致实测值滞后于模拟值。且上游建有多个中小型水库,径流流量受水库调蓄影响较大。

表4 各站场次洪水模拟结果的Nash效率系数
续表4 各站场次洪水模拟结果的Nash效率系数
为了继续验证模型中率定的参数对此流域的适应性,根据各个站点的水文数据,以2013年为例,验证期各参数分区的结果见表5。挑选的洪水场次的模拟见表4。从表4中2013年麒麟咀站的模拟结果和验证期2008年时的结果相似,存在滞后效果,证明猜想正确,流域中的拦水坝影响着汇流过程,造成了模拟结果的偏差。同时从各参数分区的验证结果可以看出,验证期间的Nash效率系数均达到0.7以上,说明模拟效果较好,分布式水文模型EasyDHM在增江流域具有良好的实用性,因此,可进一步用于增江流域实际问题的研究。

表5 模型各参数分区模拟结果
5 结 语
本文针对增江流域降水较多,下垫面情况复杂的特点,在对以收集的水文、气象、地形等数据的整理编辑之后,建立了增江流域EasyDHM分布式水文模型。在使用分布式水文模型的通过敏感性分析,识别出影响该流域的主要参数因子为:土壤添加持水率修正系数,子流域主河道长度修正系数,不透水面积修正系数等。总体上,各参数分区模拟效果较为理想,说明分布式水文模型EasyDHM在增江流域应用良好,可利用该模型实现对流域的水雨情分析,为水资源的管理提供支持,使得水资源利用更加合理,从而缓解地区资源性缺水的问题。经比较,麒麟咀分区由于流域内的拦水坝影响,导致实测值相对模拟结果存在滞后现象,将在之后的应用中重点展开对此影响因子的研究。
猜你喜欢
黑龙江水利科技(2022年9期)2022-10-13
现代仪器与医疗(2022年4期)2022-10-08
湖南水利水电(2021年6期)2022-01-18
河北地质(2021年3期)2021-11-05
河北地质(2021年2期)2021-08-21
陕西档案(2021年2期)2021-05-21
现代临床医学(2021年1期)2021-01-26
甘肃教育(2020年4期)2020-09-11
山东交通科技(2020年1期)2020-07-24
黄河黄土黄种人·水与中国(2019年4期)2019-05-16
