
基于社交媒体的事件脉络挖掘研究进展
2019-11-18 02:43:58张晨昕樊笑冰
中文信息学报 2019年11期
张晨昕,饶 元,樊笑冰,王 硕
(1. 西安交通大学 深圳研究院,广东 深圳 518057;2. 西安交通大学 软件学院 社会智能与复杂数据处理实验室,陕西 西安 710049)
0 引言
以微博为代表的社交媒体随着Web 2.0和移动计算应用技术的快速发展而迅速壮大,用户产生的信息呈爆炸式的增长。挖掘和利用这些海量的社交媒体数据不仅可以快速感知和跟踪突发的社会动荡事件[1]、异常灾害事件[2]以及流行疾病事件[3]等突发信息,也可以利用社交媒体数据来预测比赛的状况走势[4]以及市场变化导致的股市趋势变化等现象。面对海量且纷繁复杂的社交媒体信息,如何对碎片化的数据进行深入挖掘与分析,形成基于特定主题事件演化过程的脉络化结构,让用户在较短的时间内能够快速且直观地了解和把握事情发展的过程与脉络成为了一个重要需求。
但是,针对社交媒体进行事件挖掘并生成事件脉络结构还存在着一些关键性技术问题: 一是基于短文本多模态信息的事件抽取。由于社会媒体中信息内容短,不但语法不规范、多冗余,而且还包含了大量的图片、视频、音频等多模态的复杂信息[5],如何从基于多模态的复杂数据中抽取事件,并形成事件脉络是目前一项重要的研究任务。二是基于社交媒体动态变化信息中事件脉络的实时地生成。由于社交媒体中存在大量的转发、评论、点赞等行为特征以及时间与位置等动态信息,如何从快速动态变化的社交信息中实时地感知并捕获各种热点事件,并快速形成事件脉络,帮助用户及时了解事件并预判事件发展趋势显得尤为重要。第三,多特征条件下,不同粒度的事件融合策略。社交网络中不同节点的影响力以及信息可信度等因素所引起信息传播级联的层次与影响范围广度的差异[6]对事件的准确识别带来了重要影响,特别是所挖掘出的事件粒度存在着不同的大小或者层次结构,如何将这种分层次、多粒度的事件有机地整合到整个事件发生与发展的脉络结构之中[7],已成为学术界、工业界共同关注的研究焦点。
本文针对上述问题,从事件与事件脉络的概念定义出发,针对多模态信息融合与事件脉络生成、跨媒体、实时碎片化的数据融合与事件挖掘、分层次且多粒度的事件分析等方面对社交媒体中事件脉络生成过程中所涉及到的关键技术与最新方法进行文献综述。
1 社交媒体事件脉络的定义
在基于社交媒体的事件分析研究中,存在着多种不同的概念。例如,Zhao Q等[7]将事件定义为一组社会行动者在某一特定时期内针对某一特定主题的信息流;Imran M等[8]认为事件是由一个或多个诸如主题、时间、人物和位置等属性集合构成的信息结构体;CEC则将事件定义为: 在某个特定的时间和环境下发生的、由若干角色参与的、表现出若干动作特征的一件事情;而ACE则将事件定义为: 事件=<触发词,事件类型,论元,论元角色>四元组所构成的知识结构。
一般地,事件可分为元事件和主题事件两类。其中,元事件通常由动词或名词性短语所对应的触发词触发,表示一个动作的发生或状态的变化,如ACE的定义。一个事件可以包含多个信息,由分散在不同文档中的子事件(即事件的方面)构成,子事件往往由多个元事件组成,它包含了多个动作或状态的变化。因此,事件具有层次性,事件之间以及不同层次的子事件之间存在一定的关系。在上述定义的基础上,本文对事件脉络进行如下定义。
定义1事件脉络(storyline)表示基于社交媒体数据中,随着时间的演化,事件与事件之间关系形成的集合,它可以形式化地表示为以下二元组,如式(1)所示。
storyline=
(1)
其中,E表示事件所构成的集合,如式(2)所示。
E={eventi,1≤i≤n}
(2)
一般地,事件由某些原因和条件触发,并在特定时间、地点,涉及特定的对象(人或物)以及伴随某些必然的结果;并且每一个事件均可以由不同的子事件来构成,如式(3)所示。
eventi={eventij,1≤i,j≤n}
(3)
其中,eventij表示第i个事件中包含的第j个子事件,其中子事件具有嵌套性。
R则表示不同事件之间或者子事件之间存在的关系集合,如式(4)所示。
R={relk,1≤k≤m}
(4)
目前,事件间的关系可归纳为以下4种[9-10]:
(1) 跟随关系: 表示事件在时间上的先后顺序。
(2) 因果关系: 事件A导致了事件B的发生。
(3) 相关关系: 指同一主题的事件或子事件存在的语义联系。
(4) 补充关系: 指与事件相关的背景知识。
2 事件脉络挖掘核心任务与挑战
根据以上定义可知,构造一个事件脉络的核心工作主要在于两个方面: 一是抽取出相应的事件与子事件的信息集合;二是挖掘事件关键信息以及清晰定义事件关键信息之间和子事件之间的关系,如式(5)所示。
(5)
因此,本节在针对社交媒体中事件脉络生成过程中的事件检测、子事件挖掘以及关系脉络构造三个核心任务进行综述的基础上,进一步对存在的关键性技术挑战进行分析。
2.1 事件检测
事件检测起源于美国国防高级研究计划局发起的TDT(topic detection and tracking)项目,该项目旨在对新闻媒体信息进行新话题的自动识别和已知话题的持续跟踪。与传统新闻文本不同,社交媒体文本具有长度短、信息不规范、多模态等特点,因此,针对社交媒体文本已经衍生出多种事件检测的方法,而针对社交媒体的事件检测方法主要分为: 基于文档的事件检测方法和基于特征的事件检测方法[11]。
基于文档的事件检测方法是根据文本内容,利用聚类算法来实现相似文本的聚类,从而实现事件的检测。张小明等[12]提出一种基于增量聚类的话题检测算法,该算法利用话题的延续性特征来预聚类文档,实现了话题数量与话题内容的准确且高效检测。在此基础上,Alsaedi N等[1]针对Twitter提出一个基于滑动窗口时间框架的在线聚类算法来实现事件检测,该算法在聚类前,先对推文进行有监督分类并过滤掉垃圾帖子,显著减少了推文的计算量且提高了运算效率,从而实现社交媒体流中不同规模的事件快速检测。Mu L等[13]针对新浪微博提出了一种基于生命周期的事件演化模型,它首先基于时间片划分微博并抽取事件元组,其次基于5W1H命名实体信息增强聚类效果来检测事件。一般地,相同或者相似的事件在时间维度上往往存在一定的关系。基于此,Mathews P等[14]提出了一种使用概率方法来合并时间信息的社会媒体事件响应聚类(SMERC)。通过分析推文之间的时间间隔分布,发现相关推文对之间的时间间隔呈指数衰减,而不相关推文之间的时间间隔近似一致。基于这一认识,该文使用概率参数来估计一对推文相关的可能性。与基线方法相比,精确率达到0.866,F值达到了0.789。
除了上述传统的检测事件方法外,基于主题模型的事件检测方法也得到了较为广泛的研究。特别是自从Blei等[15]提出LDA (latent dirichlet allocation)以来,大量的研究利用LDA模型以及改进算法进行主题的发现。Wang D等[16]提出了一种增量半监督的tweet-LDA模型,对推文流进行分析并生成基于地理编码的交通事件,和传统的twitter分类文本挖掘方法相比,该方法的准确率达到90%以上。Shi L等[17]提出了基于超文本主题搜索的主题决策方法(hypertext-induced topic search based topic-decision,TD-HITS),以及一种基于LDA的三步模型TS-LDA。TD-HITS可以自动检测主题的数量,并在大量的文本中识别相关的关键文本。TS-LDA根据帖子和用户信息识别关键事件,可以更好地、及时准确地了解这些关键事件中所涉及的用户。Chen X等[18]提出了RL-LDA的主题模型,通过位置、文本、hashtag和转发行为来检测事件。在此基础上提出了一种动态参数更新策略来维护实时流下的RL-LDA模型,从而实现了事件的增量更新。
基于特征的事件检测方法是指: 事件出现时,某些特征词的频率会急剧上升,通过分析这些特征词来进行事件的识别与发现。基于这个思想,Yang S等[19]首先基于文本关键词共现关系构造关键词图(KeyGraph),再结合社区检测算法对关键词图进行划分,利用提取出的主题特征来检测社交媒体流中的事件。Ge T等[20]提出了一种基于突发信息网络(BINet)的事件检测模型NDM,该模型首先识别BINet上的关键节点或关键区域作为质心并构造集群,从而将将事件检测问题转化为在BINet网络上实现社区检测。另外,还有一些基于地理位置等特征来实现事件的识别与检测,例如,Zhou X等[21]利用位置、时间约束主题模型LTT(location time constraint topic)来发现事件。Zhang C等[22]提出了GeoBurst+,一个基于地理关键字和推文关键字相结合的本地突发事件的检测模型,加入关键词嵌入模块来捕获推文消息的语义[23],能够有效地提高事件的检测效率。此外,张鲁民等人提出了基于情感符号的在线突发事件检测算法,通过实时监测微博的文本流,可以及时发现情感特征的生产与爆发,实现突发事件的识别。还有一些研究关注推文中的hashtags在事件检测上的有效性。其中Yang S F等[24]利用推文中的hashtags作为特征,并结合K-means聚类进行事件检测,实验表明当K值设置为hashtags数量的十分之一以上时,聚类效果优于基线算法。Barros P H等[25]注意到当社交媒体用户开始对正在发生的事件做出反应并进行交互时,从推文中提取的二元语法的熵会经历一个连续的相变。因此,提出了一种基于推文内容熵计算的推文事件检测方法。与基线方法相比,事件检测准确率、关键词准确率和关键词召回率三个指标的平均值最高,表明该方法能更加准确地检测同时发生的事件。
近年来,随着深度学习算法的快速发展,基于深度学习的事件检测已经成为研究重点。Wang Z等[26]使用标准的长短期记忆模型(long short-term memory,LSTM)来学习不同任务之间的共享推文表示,并提出了一种将事件滤波、聚类和事件总结相结合的神经网络模型来发现事件。Lee K等[27]提出半监督卷积神经网络(convolutional neural network,CNN)模型,只需使用一组标记数据和未标记的推文流进行训练就可以检测出推文中的不良药物事件。Yen A Z等[28]提出了一种多任务的LSTM模型来检测和分类Twitter上的个人生活事件。在此基础上,Feng X等[29]将Bi-LSTM(双向LSTM)和卷积神经网络相结合,从而进行句子级的事件检测。该方法首先使用Bi-LSTM,根据其前后信息对每个单词的语义进行编码,其次通过添加一个CNN来捕获上下文的结构信息。在ACE 2005英语事件检测任务中,该方法的F值达到73.4%。此外,该模型在中文和西班牙文的事件触发词提取中显示了良好的性能。在社交媒体如Twitter中,一些人使用英语,一些人使用法语等其他语言,因此需要考虑使用多种语言来确保对事件进行全面检测,而传统模型面临特征的高维性、稀疏性和冗余性的挑战,针对此,Zhao L等[30]提出了一种多语言空间社会事件检测和预测模型——异构多任务学习远程监控(DHML)。该模型将多语言异构特性映射到几个潜在的语义空间中,然后在所有这些语义空间中强制使用相似的稀疏模式,并对涉及的所有语言使用远程监控。该方法在10个数据集中有8个数据集的性能平均优于其他方法15%。
2.2 子事件的检测与挖掘
事件通常随着时间的推移而演变出多个不同的子事件,即事件方面,每个子事件不仅与事件具有强的相关关系,并且从不同角度反映事件某一侧面信息的发展变化情况。因此,关于子事件的检测与挖掘也是构成事件脉络的关键。
针对子事件检测问题(即事件方面的挖掘), Meladianos P等[31]引入了一个依赖于所使用术语频率的子事件检测方法。Dehghani N等[32]在构造时间相似性超图的基础上,通过社区检测方法对图进行社区划分,每一个社区代表一个不同的子事件。一些学者采用分割的思想来实现子事件检测[4,33]。Huang Y等[4]从事件参与者的角度出发,将整个事件流划分为多个参与者相关的子事件;Schinas M等[33]提出执行基于时间的分割算法,创建以一天为周期的时间片,来聚集相同时间版下相应的主题片段和信息集群来发现子事件。此外,Srijith P K等[34]提出了一种基于概率主题模型的分层狄利克雷过程(HDP)方法来检测子事件,HDP通过学习与子事件相关的子主题,来处理子事件中细微的变化。Chen G等[35]提出了一种基于编码—存储—解码的社交媒体子事件检测模型(EMD),该模型采用数据驱动的方式,利用递归神经网络对单词序列进行建模,实现对子事件的最佳表示,将子事件检测问题转换为选择最合适的子事件表示方法,并利用迁移学习来处理过拟合情况。
2.3 事件脉络的关系挖掘
检测到事件及子事件后,如何从这些存在大量冗余,且无结构的碎片化数据中挖掘出反映事件发生与发展的关键节点信息以及它们之间存在的关系则是一个关键问题。针对此问题,目前的研究方法主要分为以下两类。
第一类方法是基于主题相关的方式来提取与事件高度相关的关键词或者其他关键信息或事件摘要作为事件的总结[2,36]。Rudra K等[2]针对灾难事件,提取推文中有关灾难事件的关键信息,例如,伤亡人数、地名、医院等来汇总事件。Xu Z等[36]通过提取文本关键词、图片、位置以及时间等关键词来总结事件的发展阶段。在上述研究的基础上,李莹莹等[37]在挖掘事件的脉络时,首先形成事件下各个主题的各个分支,形成分支时不仅考虑了事件之间在时间上的关系,还考虑了事件在地理位置上的相似关系,以及事件的参与者、事件核心词的相似度关系。其次将这些分支利用生成树的形式形成脉络结构。Yang L等[38]从事件时间特征的角度,提出了一种事件周期检测算法来检测事件之间的关系,同时利用低阶统计量进行简单的统计检验和到达间隔直方图对事件序列进行总结,获取事件的关联关系,提出最小描述长度原则来生成事件的总结。该方法事件序列的平均压缩比达到99.7%。近年来,深度学习的方法被用于生成事件的总结。Yang M等[39]提出了一种多任务实时事件总结框架MARES(multitask learning algorithm for web-scale real-time event summarization),该模型将关联预测和文档过滤作为两个子任务,使用分层LSTM模型学习查询和文档的表示,同时基于关联预测组件的共享文档编码层,采用强化学习算法学习如何最大化长期回报。
第二种方法是选取有代表性的帖子并基于帖子间的关系形成事件脉络。一些研究基于特征排名来选取代表性的推文[31,40-41],Meladianos P等[31]对时间段内的每条推文使用其词汇权重之和进行评分,并将得分最高的推文作为子事件的文本描述。Alsaedi N等[40]提出在当前时间窗和前一个时间窗中,选择TF-IDF值最高的帖子作为关键帖子,根据帖子发表时间上的跟随关系实时生成事件脉络;同时,作者还提出从信息传播的角度,在时间窗口中选择相对转发量最多的帖子作为事件的关键信息;但该方法忽略了帖子转发量与时间成正比及名人效应对转发量的影响。Schinas M等[41]根据转发量及帖子与主题的相关程度进行排名从而选出关键帖子。此外,Dehghani N等[32]提出首先构建一个有向加权的事件图,并在该图中找到一个最小权值的生成树作为事件发展脉络。李培等[42]进一步采用多视图和最小权重支配集算法来挖掘关键帖子,并利用Steiner树算法将关键帖子按时间上的跟随关系平滑地连接成事件脉络。
2.4 存在的关键技术挑战
由于社交媒体的内容、结构以及传播行为等特征的特殊性,在实现事件脉络挖掘与生成的过程中,仍然面临着许多关键性的技术挑战,具体表现为以下4个方面。
挑战1基于跨媒介、多源异构环境下的事件脉络生成问题。信息越来越多地通过跨媒介的方式进行扩散与传播,对事件的分析也迫切地需要对来自多个社交平台中的数据进行关联与融合。由于不同媒介中的信息内容特征、用户特征、信息结构等特征均存在差异,这导致了跨媒介事件融合过程中存在着内容语义消歧与实体对齐等问题。因此,如何解决跨媒介、多源异构条件下,碎片化社交数据中的事件识别以及事件脉络的生成则是目前迫切需要解决的重要问题,也是目前面临的重大技术挑战之一。
挑战2基于多模态、碎片化社交数据中复杂事件的识别与融合,以及事件脉络的生成问题。由于早期的事件识别主要针对文本、图片或视频等单模态数据条件下展开,而社交媒体数据往往同时发布了文本以及图片或短视频,形成了复杂的多模态数据的复合形态,如何融合不同模态数据下的事件信息与特征,形成一个包含文本、图片以及视频等多模态信息的完整事件脉络也是一个重大的技术挑战。
挑战3基于多层次、不同粒度的事件融合与事件脉络生成。社交媒体上的热点事件往往存在着一个事件演化的生命周期,一方面在时间与空间维度上能够持续较长一段时间,影响到多个不同区域的用户人群;另一方面,事件在演化的过程中,其核心的主题也会随着时间的发展而逐步衍生出多个不同细分主题的子事件。由于事件所具有的这种层次性与多粒度的特性,导致了在分析事件的过程中,如何识别出事件的全局性特征,以及事件的细粒度的特征,并利用这些不同尺度的特征来融合成一个完整的多层次事件脉络树,是一个关键的技术挑战。
挑战4基于动态社交媒体数据中的事件实时识别与事件脉络的快速生成问题。由于社交媒体具有平台开放性、数据动态性以及分析预警实时性的特征与需求,使得传统基于静态信息的回顾式事件检测和事件脉络生成与分析技术难以实施到具体的实际应用中。因此,针对这些实时、海量、动态的社交网络数据,如何实现事件实时识别与发现,并快速生成事件的发展脉络则是目前亟待解决的重要问题。
本文在结合社交媒体上的事件脉络挖掘与生成的实现步骤基础上,围绕上述核心问题与关键挑战对目前的最新研究进展进行综述。
3 基于跨媒介的事件脉络生成
跨媒介数据比单一媒介数据来源更丰富,且跨媒介数据的差异性和丰富性也使得某一事件相关的信息更加广泛[43],但同时也增大了事件融合、事件脉络生成与数据分析的困难。针对跨媒介信息协同与事件融合这一问题,目前主要有三类方法: 基于概率模型的方法、基于特征的方法和基于主题的方法。
Zhang T等[44]提出共概率多假设跟踪算法(CO-PMHT,co-probabilistic multi-hypothesis tracking),该算法对两个域(google news和flickr)的数据集使用两个概率函数,并得到有效地结合起来,弥补了不同媒介之间的特征差异,该算法可以协同跟踪两个领域中的多个事件。
基于特征的方法是将来自不同平台的数据特征映射到同一个特征空间,达到数据融合的目的。例如,Yang X等[45]提出了基于叠加去噪自编码器的跨域特征学习算法CDFL(cross-domain feature learning),在传统的自编码器的基础上引入模态相关约束和跨平台约束,以无监督的方式学习两个不同领域数据的共享特性表示,最大化不同形式之间的数据关联。在此基础上,Qian S等[46]进一步提出了基于无参数的贝叶斯的跨域协作学习模型CDCL(cross-domain collaborative learning),该模型利用多个域之间的共享域先验特征,来共享一个共同的特征空间,模型如图1所示。
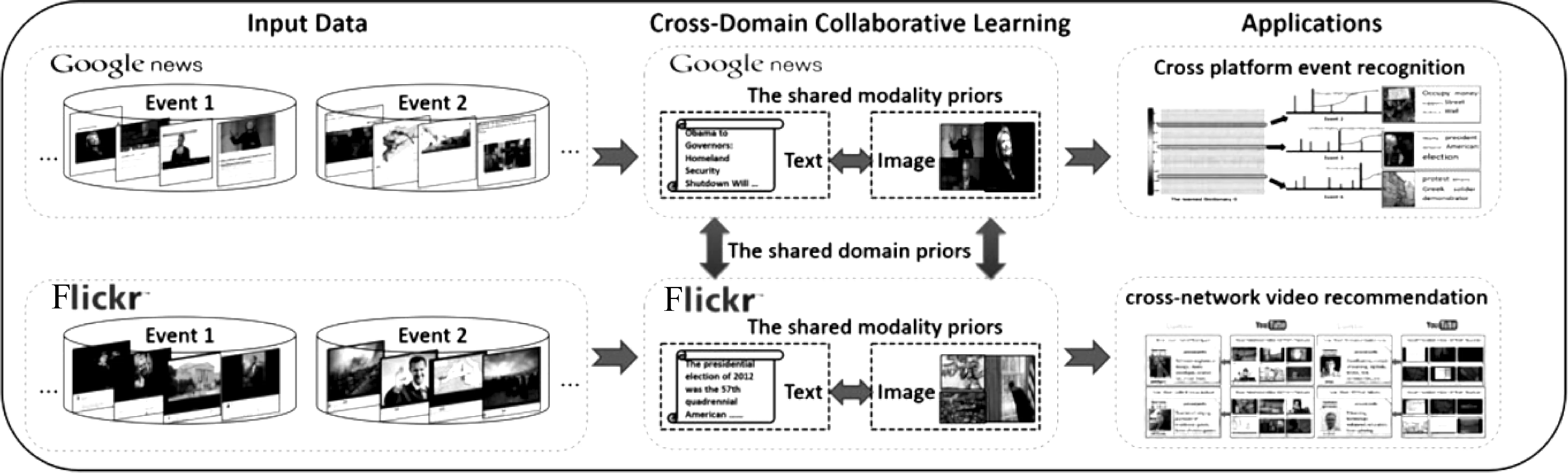
图1 跨域事件分析模型[46]
Yang Z等[47]从迁移学习的角度出发,针对网络新闻媒体和社交媒体数据,提出了一种跨领域和跨模态的迁移学习模型CDM(cross-domain and cross-modality transfer learning),它利用基于字典的对齐策略对数据对象进行对齐,还利用基于类特定的重构残差来识别数据样本中的事件标签。Yang Z等[48]提出了一个共享的多视图数据表示学习模型SMED来处理跨域和跨模态的事件检测场景。通过对数据样本与字典库之间进行特定于视图的相似性计算,对异构双域数据进行对齐,得到统一的向量形式的特征表示;最后从数据重构的角度设计了分类残差模型从异构的多域数据中发现事件。SMDR的优点是共享表示、重构误差、低秩和局部不变性。
基于主题的融合方法指首先分别从不同的平台挖掘事件或主题,然后从主题或事件层面进行数据融合。例如,Wang S等[49]提出了一种无监督的框架从Twitter和Instagram上检测和追踪事件,该框架首先分别在这两个平台上检测事件,然后基于二分图和文本相似性将事件融合,并进一步追踪事件变化。Tiwari A等[50]针对Twitter、Instagram、Flickr等数据,提出了一种基于主题相似性的跨域事件融合方法。通过联合数据建模和链接的方法来分析跨媒介事件,并采用基于马尔可夫随机场(markov random fields,MRFs)的相似性度量方法将不同平台的主题跨时间间隔进行关联,同时利用平台间的显式链接进行参数学习与共享,该模型如图2所示。在该模型中,首先进行数据预处理,并应用主题建模方法来识别数据中的不同主题,将主题下的文本和视频内容统一表示为主题图的形式;随后基于MRFs测量两个主题图的相似度并合并相同时间间隔内的相似主题。最后将事件关键内容选择问题转化为一个多模态子模优化问题,并构建图形用户界面,向用户显示生成的事件脉络。针对社交媒体跨媒介条件下的事件脉络挖掘问题,本文对现有方法的总结如表1所示。
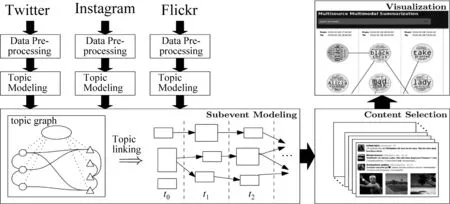
图2 A Tiwari等联合数据建模和链接[50]
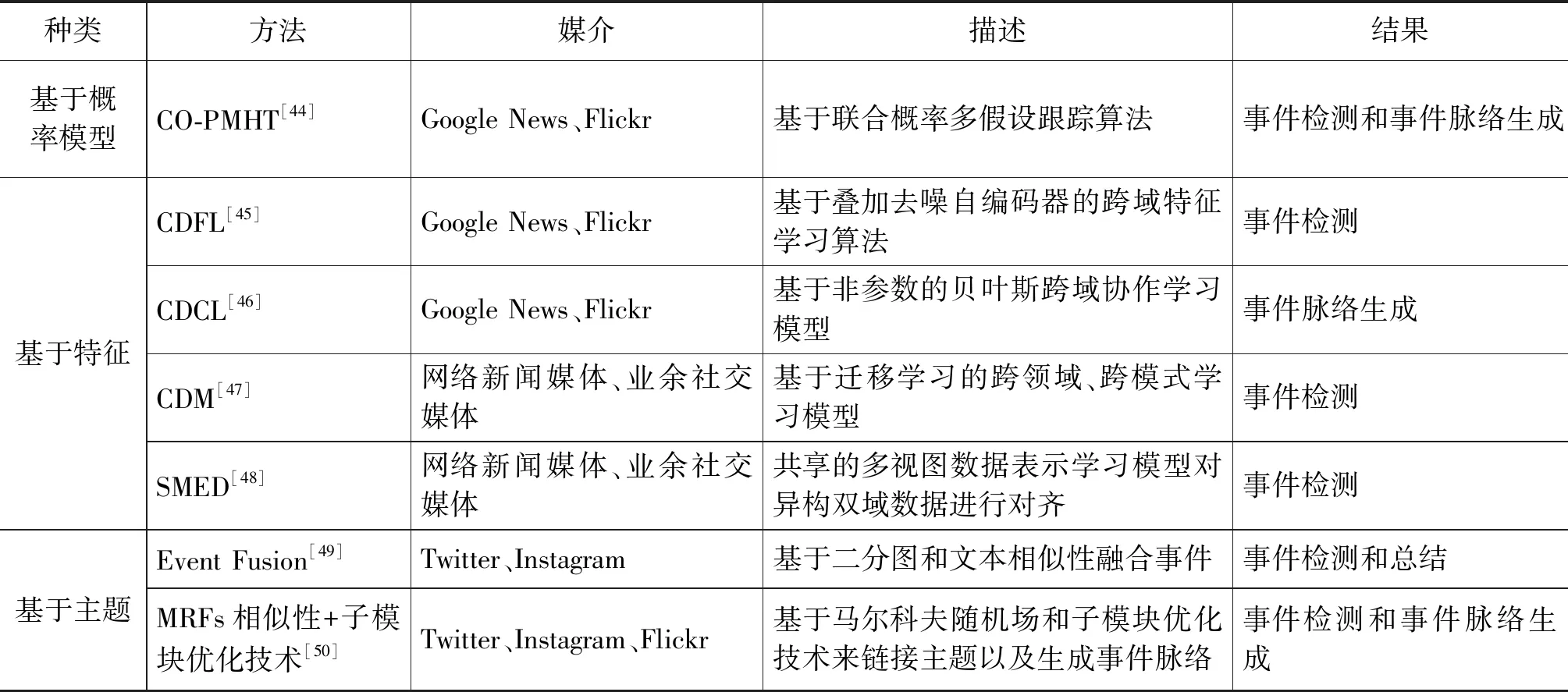
种类方法媒介描述结果基于概率模型CO-PMHT[44]Google News、Flickr基于联合概率多假设跟踪算法事件检测和事件脉络生成基于特征CDFL[45]Google News、Flickr基于叠加去噪自编码器的跨域特征学习算法事件检测CDCL[46]Google News、Flickr基于非参数的贝叶斯跨域协作学习模型事件脉络生成CDM[47]网络新闻媒体、业余社交媒体基于迁移学习的跨领域、跨模式学习模型事件检测SMED[48]网络新闻媒体、业余社交媒体共享的多视图数据表示学习模型对异构双域数据进行对齐事件检测基于主题Event Fusion[49]Twitter、Instagram基于二分图和文本相似性融合事件事件检测和总结MRFs相似性+子模块优化技术[50]Twitter、Instagram、Flickr基于马尔科夫随机场和子模块优化技术来链接主题以及生成事件脉络事件检测和事件脉络生成
4 基于多模态社交数据的事件脉络融合
社交媒体信息除文本信息外,还存在着大量的视觉、交互、情感、位置等多模态信息,对这些多模态信息的有效挖掘能更丰富地呈现出事件的发生与发展脉络。目前针对该领域问题主要的研究方法可以分为以下三类: 基于图论的方法、基于特征的方法和基于机器学习的方法。
针对基于图论的事件检测和事件脉络挖掘方法,Chen F等[51]通过建立实体与实体、实体与属性及实体之间关系的异构网络图,来融合文本、图片、用户、交互等多模态信息,并提出了NPHGS算法,通过采用非参数统计模型来解决社交媒体中语言非正式、语法错误多且持续动态更新等问题,从而更加准确地检测和预测事件。Xu J等[52]提出了一个统一的异构图模型来综合事件网络下的多模态信息及关系,如图3所示。
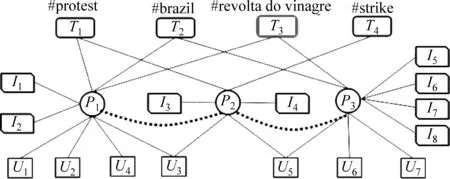
图3 多模态数据融合[52]
其中,Pi代表原贴,不包括转发,Ti代表帖子标签。Ui指参与一个帖子的评论、点赞、转发的用户;Ii表示帖子的图片;实线边表示属性链接,虚线边表示帖子间在时间上相近;随着时间的推移,节点和边逐渐添加到图中。随后利用基于图的流行排序算法(manifold ranking)选择具有代表性的图片并形成事件的可视化总结。与方法NPHGS相比,该方法针对确定时间下的图片使用基于排序算法已在选择有代表性的图片对事件进行总结,可以更清晰地呈现出事件的脉络。但以上两个方法存在的共同缺点是: 图的建立与维护过程比较复杂,同时,在数据量大以及实时性要求较高时性能较差。在此基础上,Schinas M等[41]提出MGraph模型来创建事件的可视化总结。生成的故事线包含文本和图片。在多模态信息融合这一问题上,该算法将每个帖子表示成一个元组{id,内容,用户,发布时间,图片,交互元组}来融合多模态信息。整个算法模型如图4所示。
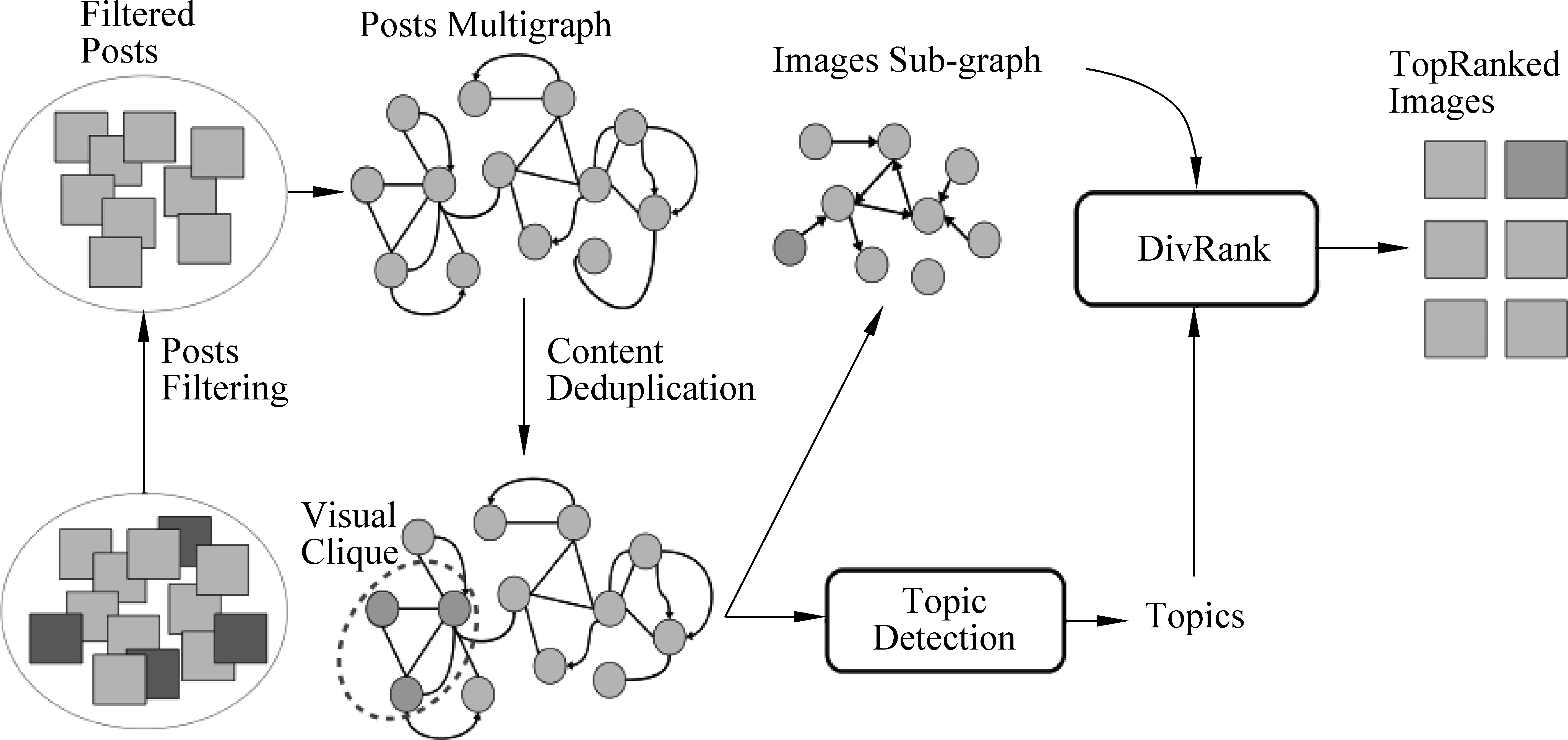
图4 MGraph模型[41]
由图4可以看出,该模型首先过滤掉低质量的帖子并根据图片、时间、文本相似性来构建事件图,并利用CPM派系过滤算法检测、删除重复内容,同时使用网络结构聚类算法(SCAN)检测事件主题,最后,根据转发量、帖子和主题的相关程度及图片和主题的相关性和多样性进行排名,选择有代表性的文本和图片来生成事件脉络的可视化总结。Guo B等在MGraph基础上建立了CrowdStory模型[10],根据一个事件下帖子的文本相似性和时间相似性来挖掘事件的不同方面与阶段,并根据图片和交互信息挖掘出事件各个方面之间存在的因果、补充与相关关系、从而生成事件的细粒度脉络,实验结果优于基线算法。在文本与图片结合的基础上,Amato F等[53]还结合了视频,提出了一种基于OSNs的多模态主题事件总结方法。该方法采用影响分析方法来确定与一个或多个主题相关的最重要的多模态对象,并结合启发式算法来获得优先级(关于某些用户关键字)、连续性、多样性和非重复性的多模态事件总结。
针对基于特征的多模态事件检测和事件脉络挖掘方法[23,36,54]。张鲁民等[23]将微博中表情符号的变化态势和文本信息相融合来挖掘突发事件。Xu Z等[36]考虑到社交媒体中丰富的时空信息,将内容与图片特征、文本关键词的相关特征与基于OpenStreetMap挖掘的位置词相结合,用文本、图片、时间、空间四种模态来实现城市突发事件的检测与事件总结,但该算法仅实现了对事件的简单总结,并未进一步挖掘出事件脉络的发生与发展路径。Choi J等提出了一个Event360模型[54],如图5所示。
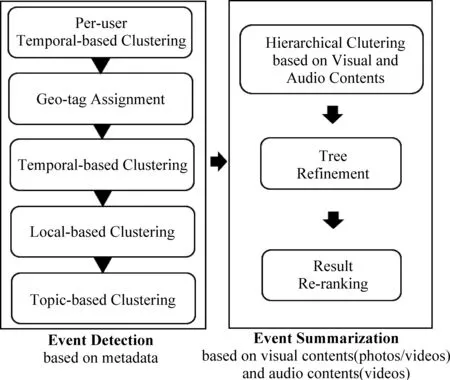
图5 Event360模型[54]
图5中,在多模态语料库中分别基于时间、主题、位置、空间以及文本元聚类来实现事件的检测,并结合视觉特征和音频特征与信息进行层次聚类,向用户提供可视化的事件总结。
前两种方法都是根据多模态信息之间的相似性关系对事件脉络进行分析与建模,第三种方法则是基于深度学习方法来融合多模态信息进行事件检测和事件脉络挖掘。Zhang T等[55]提出一种将文本特征和视觉特征进行集成,并基于CNN联合训练多模态事件的提取方法,该方法相比基线方法,在事件触发标记方面的F值增益达到7.1%,在事件参数标记方面的F值增益为8.5%。Chen Z等提出一种基于GAN(generative adversarial networks)的多模态模仿学习方法MIL-GAN(multimodal imitation learning via GAN)来生成故事线[56],核心思想是学习并模仿用户提供的事件情节,了解事件脉络中的关系和结构,来揭示事件的脉络。为弥补文本和图像间的信息鸿沟,该模型将生成对抗网络和基于确定性策略梯度的多模态学习方法相结合,不同模态之间相互学习,模型如图6所示。
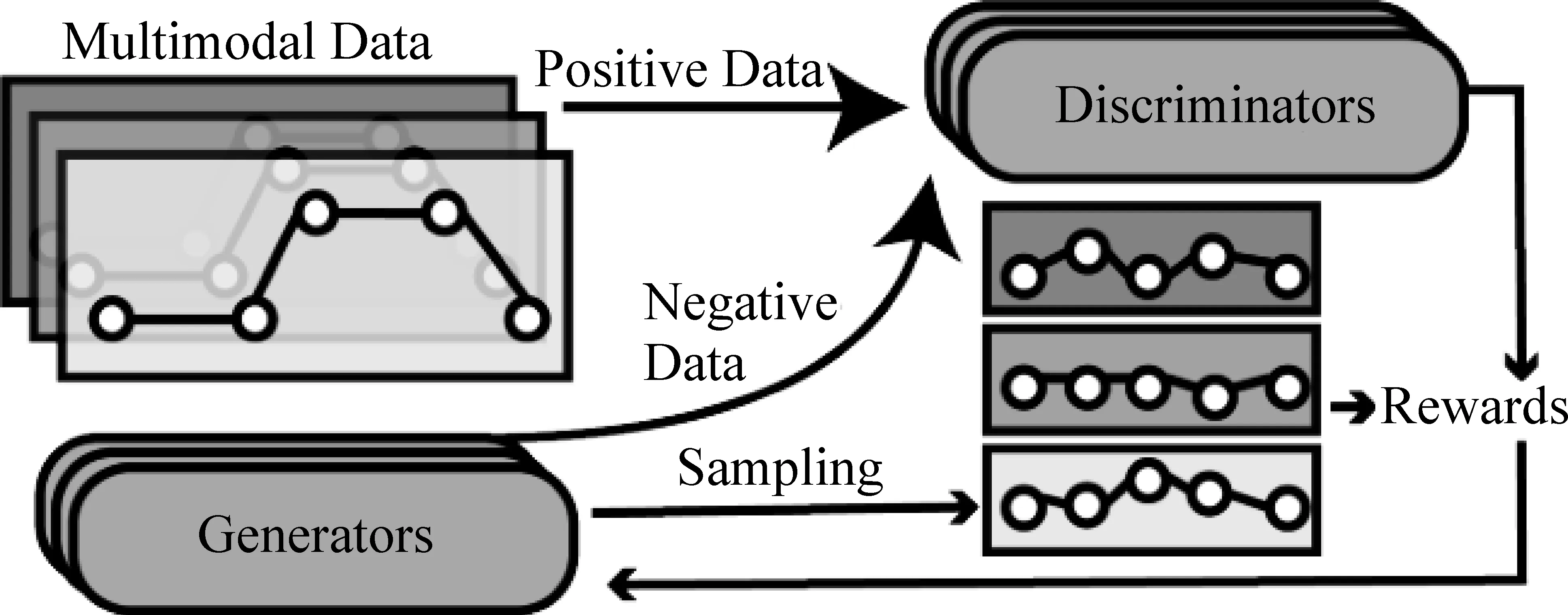
图6 MIL-GAN模型[56]
图6中,大箭头表示GAN训练中的数据流,小箭头表示策略梯度内的过程,其中,多模态数据是基于一组事件的数据集,即故事线对{D,S},D表示一个数据集合,S表示由实体节点{ei,0≤i≤n}组成的集合。D和S中都包含有文本与图片间的映射关系,其目标是揭示出用户生成故事线的核心策略。针对社交媒体多模态事件处理与融合的问题,本文对现有方法总结如表2所示。
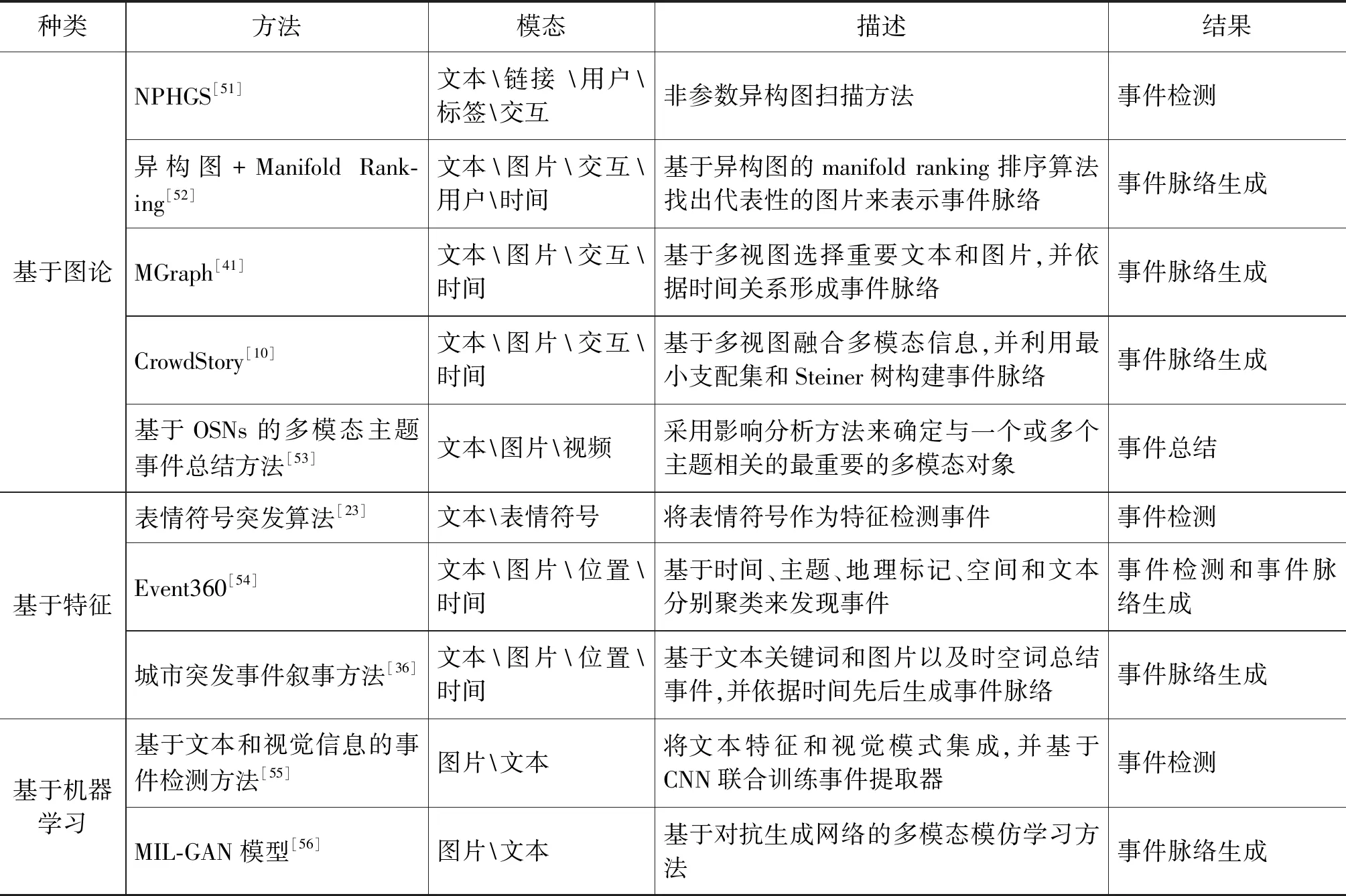
表2 多模态信息融合方法总结
5 基于多层次、不同粒度的事件脉络生成
由于事件在时间和空间上往往呈现出层次化结构,分层次、多粒度的事件脉络则能更清晰地反映事件的实事。针对事件的分层、多粒度分析方法,目前主要分为以下两大类: 基于时空粒度的方法和基于事件—方面的方法。
基于时空粒度的事件检测与事件脉络生成方法核心思想是将事件的时空信息融入事件分析过程当中,分层次、多粒度地挖掘事件以及事件发展演变等相关信息。如EventBuilder[57]利用维基百科获取关于事件更多的上下文信息,并将事件的图片和文本总结映射到地图上,形成事件地图。由于一些事件的持续周期较长,于是Feng W等[58]基于分层时空标签聚类技术,提出了一个基于空间和时间维度的层次结构数据立方STREAM CUBE,如图7所示,并基于该数据结构来建立时空分层算法模型,针对不同时空粒度的事件进行分析与总结,如图8所示。
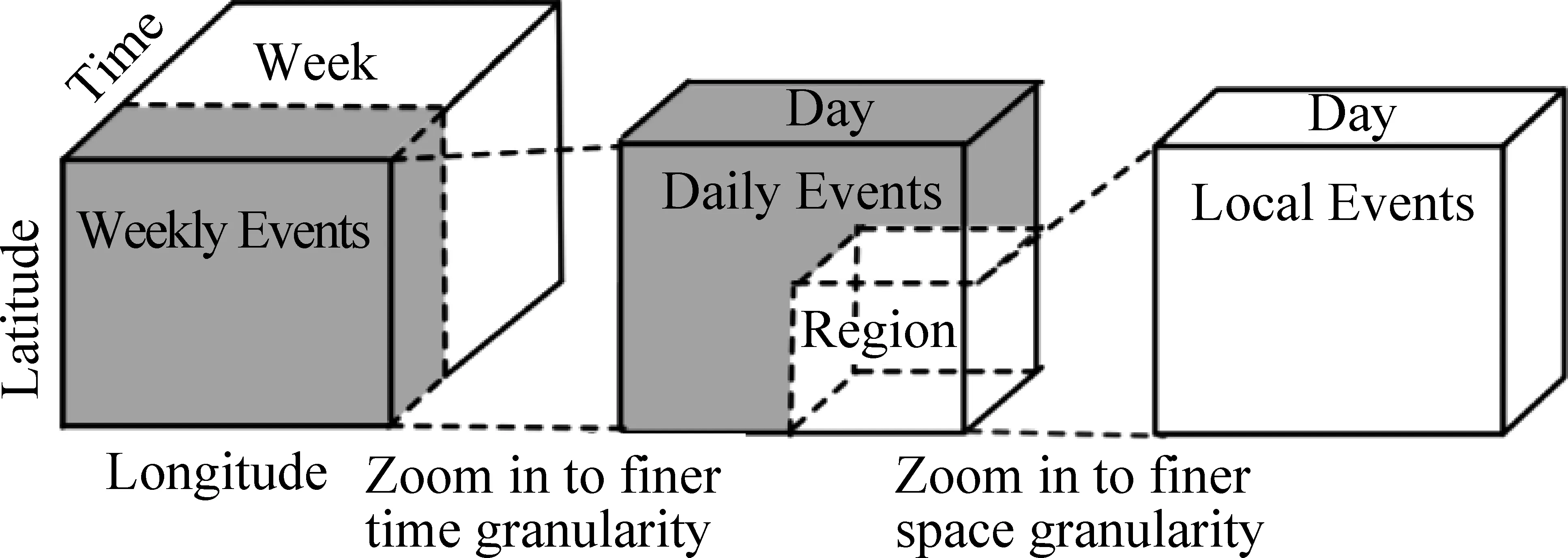
图7 STREAM CUBE数据立方[58]
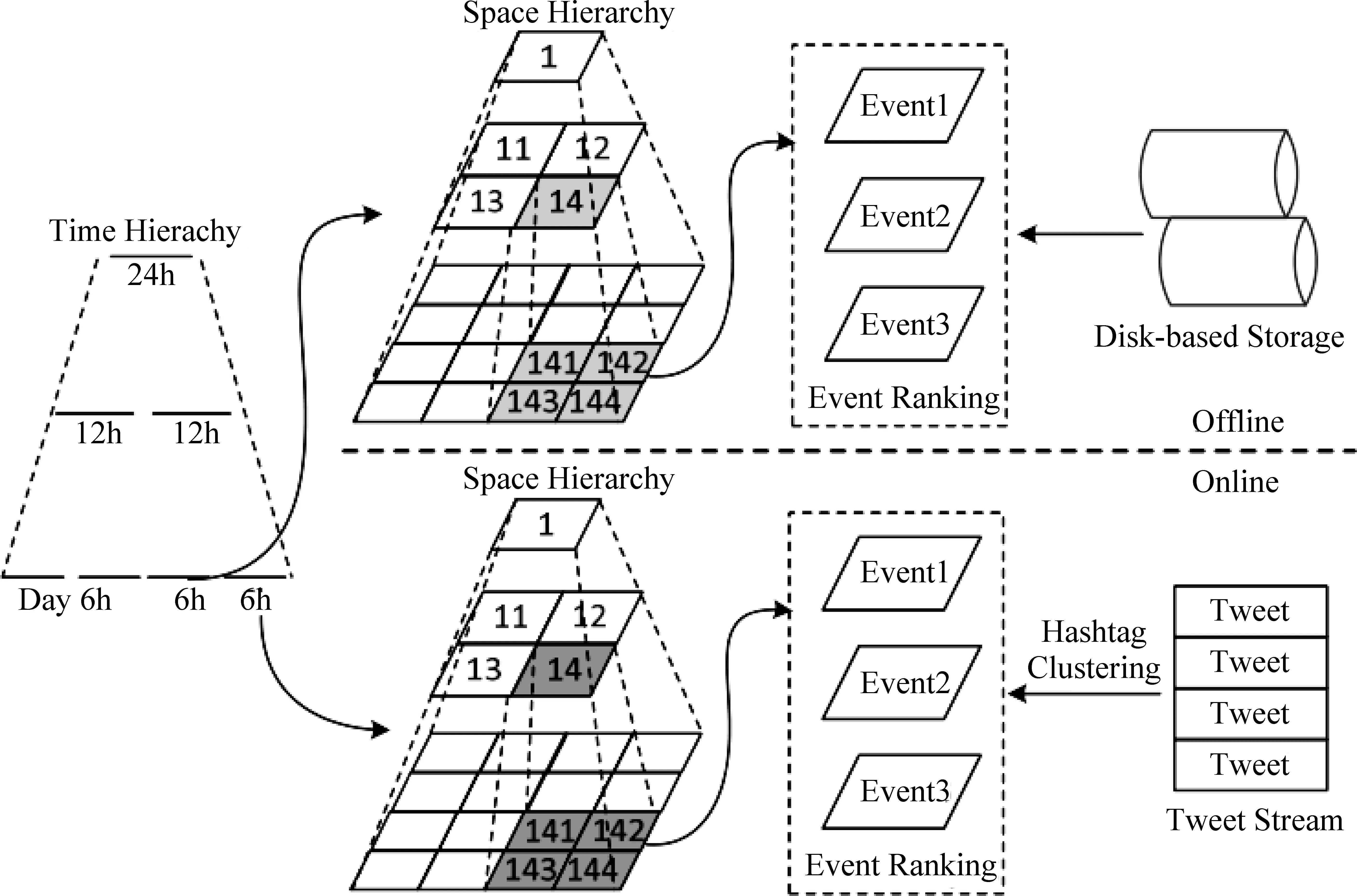
图8 时空分层算法模型[58]
该时空分层算法模型由时空聚合、事件聚类和事件排名三部分组成。时间层次上分为24h、12h、6h三层结构;空间层次上使用四叉树将全局空间组织成三层结构来支持可缩放的数字地图;在给定的时间框架下,用户可以探索具有不同空间粒度的事件。基于以上研究,Rehman F U等提出了基于时空特征的细粒度级事件提取系统[59],该系统将非结构化数据流在特定时空粒度下进行分层聚类,提取事件并形成事件地图。
而基于事件—方面的方法则是将事件进一步划分为子事件,即事件方面,并在此基础上进一步挖掘事件脉络。例如, Hua T等[60]提出一种分层贝叶斯模型ASG,将事件脉络表示为事件脉络、事件和主题三层结构并测量它们之间的关系,除此之外,ASG模型忽略了推文的噪声上下文,利用Twitter用户制作的标签来提高性能。在上述研究基础上,Guo B等提出CrowdStory模型[10],此模型通过文本相似性和时间相似性将事件划分为几个方面,并挖掘每个方面的事件发展线索,从而细粒度地分析事件的发展脉络。社交媒体中存在大量干扰性的噪声信息,这不利于事件分析,此外,以上方法对于子事件的研究不够全面,因此,在以上研究基础上, Qian X等[61]提出了一种基于子事件的社交媒体的事件摘要框架,该框架首先采用由粗到精的滤波方法来消除噪声信息,并对给定事件保留相应的原始信息;其次,采用一种用户文本图像聚类方法(UTICC),联合用户属性信息、文本、图像等多模态数据来增强子事件聚类结果,最后识别具有代表性的文本和图像,形成事件的整体可视化总结。上述方法虽然从子事件的角度对事件进行了细粒度的总结,但是并未形成层次化的事件脉络。针对层次化事件脉络问题,Zhou Q等提出的两层事件脉络生成框架[6],如图9所示。
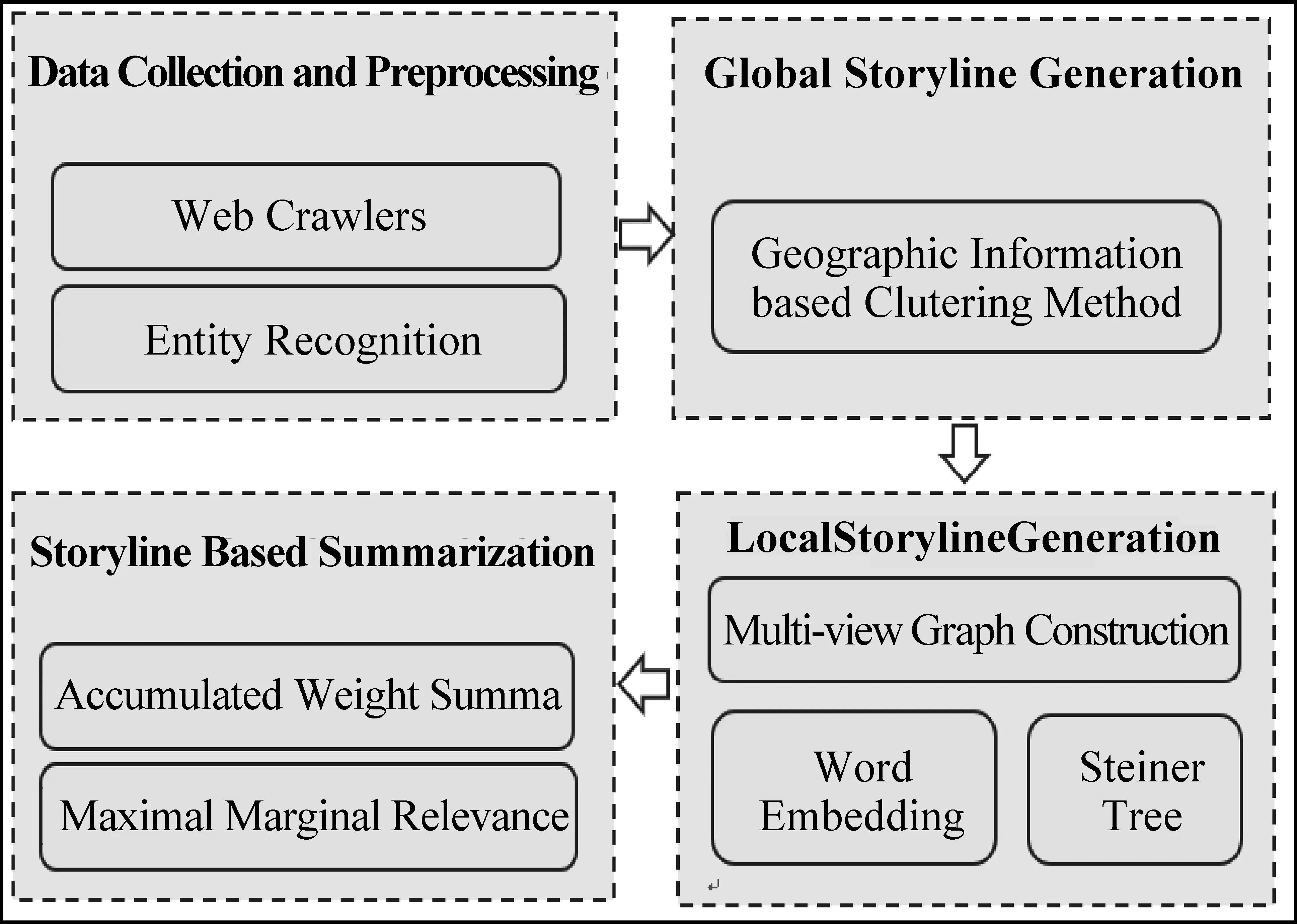
图9 基于MEA的两层故事线生成框架[6]
该框架首先基于位置聚类将文本流划分为不同的类簇,每个类簇以一个位置作为全局事件脉络的框架。其次,针对每个局部文档集,构造多视图并选择代表性的推文来代表事件,同时,采用Steiner树算法来平滑地生成本地事件脉络;最后,总结本地事件脉络作为全局的故事情节。然而,由于时间、空间、异构性和信息过载,大多数现有的故事情节仅基于文本数据,传递的信息有限,Yuan R等[62]介绍了一种多模态两层故事线生成框架。该模型采用生成式对抗网络来实现一个无监督的双语文档摘要模型。然后将图像和文本合并问题转化为多标签学习问题,利用卷积神经网络训练分类模型。最后,将双语文档和图像联合归纳并嵌入到一个两层的故事线生成框架中。针对分层多粒度的事件脉络生成问题,本文将现有的方法总结如表3所示。
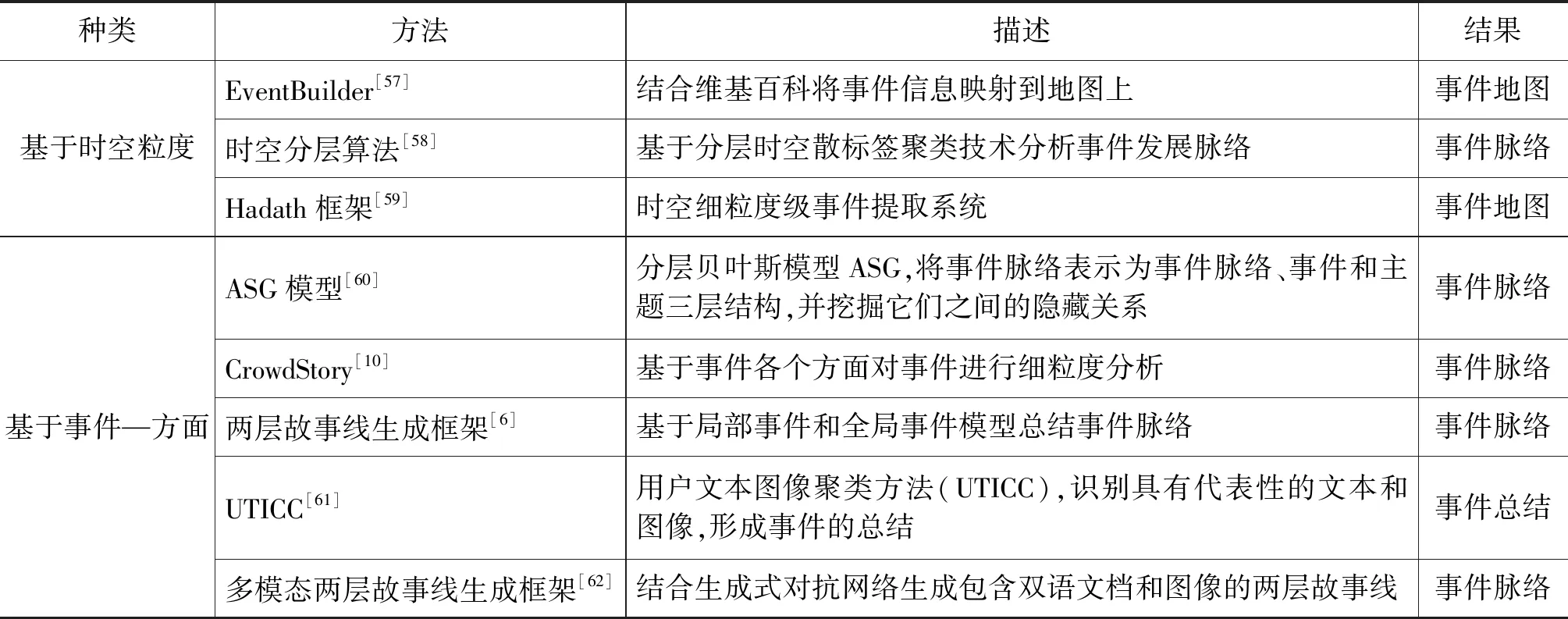
表3 分层、多粒度的事件脉络分析方法总结
6 实时数据动态组织
实时地检测跟踪微博中的事件,如犯罪事件、自然或人为灾难事件等,对犯罪监控、灾难预警等具有重要意义。一般地,社交媒体等短文本实时数据流的处理,往往可以采用基于相似度的流聚类方法以及基于Dirichlet过程的聚类方法。
基于相似度的文本流聚类方法首先采用向量空间模型来表示文档,并选择余弦相似度等来度量文档或集群之间的相似度,实时地聚类文本。例如,Malas M D等[63]提出了一种渐进式推文流的聚类方法,其核心思想是当新的推文流到达时,根据相似度将它添加到满足相似度阈值条件的最大集群中或者形成新的集群去代表一个新的事件。但是社交媒体中有大量的事件,并不是每个事件都有进一步分析的价值。因此,Hasan M等[64]提出TwitterNews+框架,该框架结合了反向索引和增量聚类方法,从Twitter数据流实时检测有新闻价值的事件,该方法大大提高了算法的时间效率。另外,还有一些方法结合时间窗来处理实时文本流聚类问题。Nguyen D T等[65]提出在固定大小时间窗内,采用基于密度的聚类算法检测事件。此种聚类方法的优点是不需要预先定义集群的数量,属于无监督的方法;缺点是无法追踪事件的变化。为解决此问题,Wang S等[66]通过分解实时到达的推文流来检测事件,并基于重叠滑动窗口(overlapping sliding window,OSL)来消除事件关键字的发展演变从而实现事件的平稳跟踪。由于社交媒体短文本不规范并包含许多噪声数据,这严重影响了聚类的结果,因此Fahy C等[67]提出了一种基于密度的蚁群流聚类算法(ant colony stream clustering,ACSC),该方法基于滚动窗口每次读取固定大小的、不重叠的数据块,形成初步的粗糙集群,并进一步根据概率函数合并这些集群。实验结果表明,该算法鲁棒性和抗噪声性较好。但是以上介绍的方法中,相似度阈值参数的设定对算法结果有很大影响,因此,Chen G等[68]提出了一种基于神经网络相似性度量学习的实时事件检测与跟踪方法。该方法首先利用神经网络模型共同学习事件的一个相似性度量和低维表示,然后通过计算推文和事件之间的相似性来有效地跟踪事件的发展演变。
对于在线事件发现,随着文档的增加事件(主题)的数量可能会动态增加。为了适应这种复杂性,一些研究利用狄利克雷(Dirichlet)过程来推断模型中的参数。Panagiotou N等[69]提出一个在线事件识别与发现的非参数模型FSDp(the first story detection pipeline),该模型通过利用Dirichlet过程推断模型参数,当新到达的文档包含的事件主题与之前事件主题不同时,则根据Dirichlet过程生成新的事件。该方法的缺点是没有考虑社交媒体短文本的稀疏性。针对此问题,Liang S等[70]提出了一种动态Dirichlet多项混合动态聚类主题模型DCT(dynamic clustering topic model),它可以跟踪主题在文档和词汇上的时变分布,有效地处理了短文档的文本稀疏性和主题的跨时间动态特性,从而较好地反映主题的短期和长期趋势。针对实时数据,由于事件数量随着文档的增加而动态增加,事件检测往往存在偏差,为解决此问题,Guo J等[71]结合混合高斯分布和基于密度的Dirichlet进程实时检测事件,并采用蒙特卡罗方法进行参数推理以消除实时事件检测过程中所产生的偏差。虽然上述模型可以解决实时流中的事件检测问题,但是大多假设聚类数目为固定数目,无法有效地解决文本流聚类的概念漂移问题。因此,Yin J等[72]提出了一种基于狄利克雷过程多项式混合模型的短文本流聚类算法MStream,该算法通过计算文档选择新集群的概率来自然地处理概念漂移问题和数据稀疏性问题。在此基础上该文进一步提出了一种改进的带有遗忘规则的MStreamF算法,它可以通过删除过期批次的集群来高效地删除过期文档。实验研究表明,MStream和MStreamF在多个真实数据集上的性能优于基线算法。
针对社交媒体数据的实时动态性问题,目前主要的研究方法如表4所示。
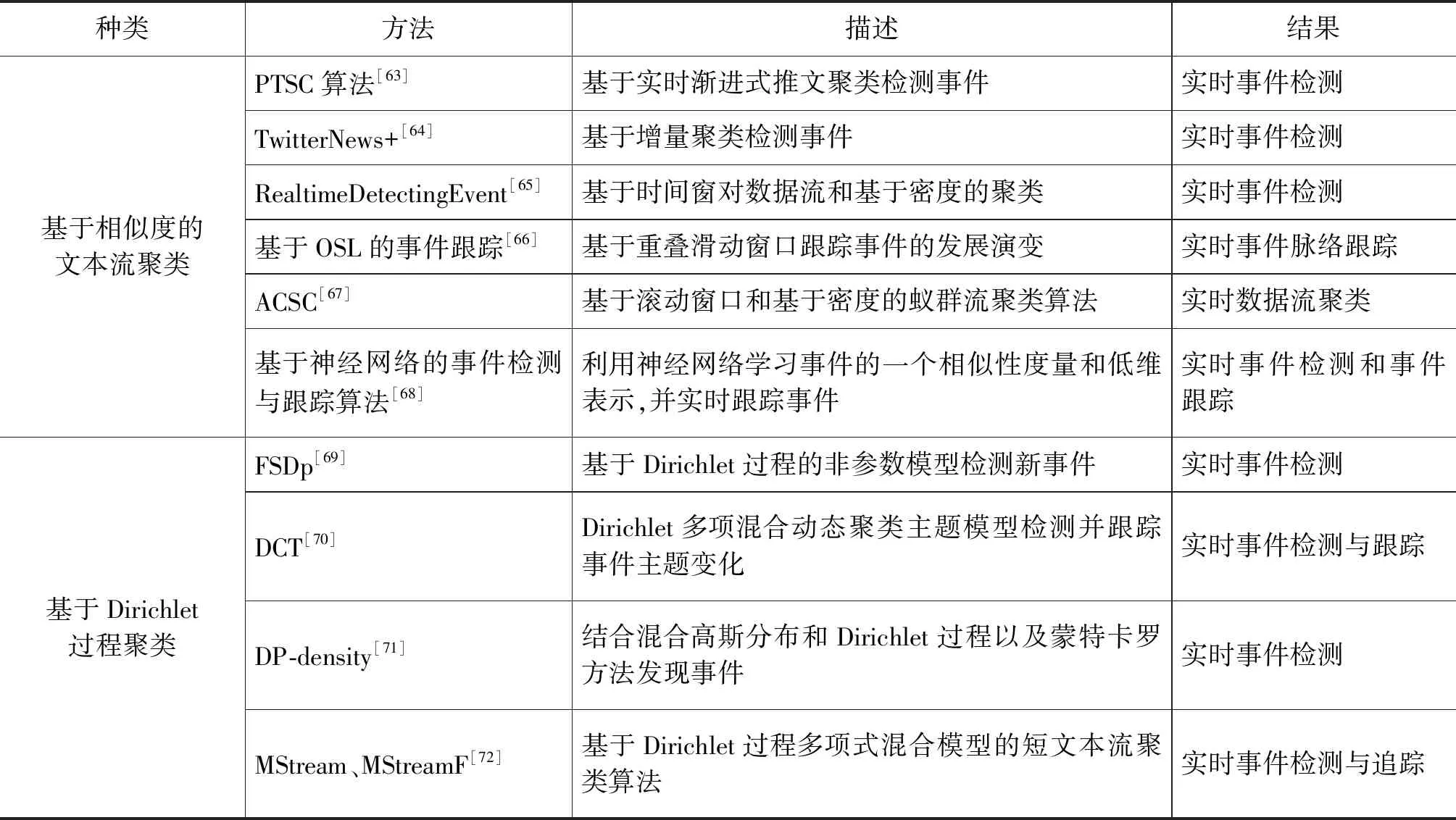
表4 实时数据下事件检测及脉络挖掘方法总结
7 总结
本文针对社交媒体事件识别与事件脉络生成与分析领域,在对事件脉络进行定义与分析的基础上,进一步归纳总结了当前四项关键性的技术挑战: 基于跨媒介、多源异构环境下的事件脉络生成问题;基于多模态、碎片化社交数据中复杂事件的识别与融合,以及事件脉络的生成问题;基于多层次、不同粒度的事件融合与事件脉络生成问题;基于动态社交媒体数据中的事件实时识别与事件脉络的快速生成问题。在此基础上,结合目前最新的研究进展与研究思路和成果,针对上述关键问题进行详细分析与综述,促进更多的研究人员在此领域开展进一步的研究工作。此外,该领域还存在着以下一些亟待解决的问题。
(1) 目前对于跨媒介生成事件脉络的研究很少,研究还不够充分和深入;同时,跨媒介的事件特征统一表示、跨媒介信息的相互补充和多样性保留、不同媒介信息的缺失补全等都是生成事件脉络研究的难点和重点,此领域的研究还存在很大的提升空间。
(2) 由于目前该领域内没有健全的公共数据集,各个算法无法在统一的数据集上进行对比实验并评价优劣,构建统一的标准数据集是下一步急需解决的问题之一。
(3) 针对事件脉络中的关系识别问题,现有算法只能识别出事件之间或者子事件之间存在关系,但并不能有效识别出具体的关系语义。针对具体关系的识别,如因果关系等,对事件脉络的生成与描述具有很重要的实际应用价值,这是下一步必然要进行深入研究的关键性问题。
(4) 实时数据的动态组织算法复杂度过高。对海量的社交媒体数据,要求快速地挖掘展现出事件发展的全貌,还有很大的提升空间。
综上,本文通过对事件的识别和事件脉络生成过程中关键技术的分析与综述,为读者提供一个深入研究的基础,以促进该领域进一步的研究发展。
猜你喜欢
乐府新声(2021年1期)2021-05-21 08:08:58
当代陕西(2020年21期)2020-12-14 08:14:32
电子测试(2017年15期)2017-12-18 07:19:27
现代财经-天津财经大学学报(2016年2期)2016-12-01 05:49:55
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
智能系统学报(2015年4期)2015-12-27 09:38:39
上海电机学院学报(2015年4期)2015-02-28 14:30:00
电子设计工程(2015年6期)2015-02-27 12:04:53
计算物理(2014年2期)2014-03-11 17:01:39
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
