
基于改进的代价敏感决策树的网络贷款分类
2019-11-15 04:49郭冰楠吴广潮
计算机应用 2019年10期
关键词:决策树
郭冰楠 吴广潮


摘 要:在网络贷款用户数据集中,贷款成功和贷款失败的用户数量存在着严重的不平衡,传统的机器学习算法在解决该类问题时注重整体分类正确率,导致贷款成功用户的预测精度较低。针对此问题,
在代价敏感决策树敏感函数的计算中加入类分布,
以减弱正负样本数量对误分类代价的影响,构建改进的代价敏感决策树;以该决策树作为基分类器并以分类准确度作为衡量标准选择表现较好的基分类器,将它们与最后阶段生成的分类器集成得到最终的分类器。实验结果表明,与已有的常用于解决此类问题的算法(如MetaCost算法、代价敏感决策树、AdaCost算法等)相比,改进的代价敏感决策树对网络贷款用户分类可以降低总体的误分类错误率,具有更强的泛化能力。
关键词:不平衡;代价敏感;网络贷款;集成学习;决策树
中图分类号:TP181
文獻标志码:A
Abstract: In the online loan user data set, there is a serious imbalance between the number of successful and failed loan users. The traditional machine learning algorithm pays attention to the overall classification accuracy when solving such problems, which leads to lower prediction accuracy of successful loan users. In order to solve this problem, the class distribution was added to the calculation of cost-sensitive decision tree sensitivity function, in order to weaken the impact of positive and negative samples on the misclassification cost, and an improvedcost-sensitive decision treebased on ID3 (ID3cs)was constructed. With the improved cost-sensitive decision tree as the base classifier and the classification accuracy as the criterion, the base classifiers with better performance were selected and integrated with the classifier generated in the last stage to obtain the final classifier. Experimental results show that compared with the existing algorithms to solve such problems (such as MetaCost algorithm, cost-sensitive decision tree, AdaCost algorithm), the improved cost-sensitive decision tree can reduce the overall misclassification rate of online loan users and has stronger generalization ability.Key words: imbalance; cost-sensitive; online loan; integrated learning; decision tree
0 引言
随着互联网金融市场的不断增长,网络贷款也得到了如火如荼的发展[1-2]。本文以某网络贷款征信服务公司提供的真实数据为背景,利用机器学习中的分类方法建立分类模型来识别可以给予贷款的用户,从而减少后续人工审核筛选用户的工作量,降低高违约风险用户带来的损失。
对于本文研究的网络贷款用户分类而言,贷款获批的人数较少,属于小概率事件。对于这样的小概率事件,主要存在以下问题:一是贷款成功的用户不容易检测到;二是将贷款成功的用户预测为贷款失败,比将贷款不合格的用户预测为贷款成功,所付出的代价更大。而传统的分类方法对于这样的分类问题不具有良好的性能。
在现实的分类场景中,这样的问题广泛存在,例如医疗诊断、信用卡欺诈检测、广告点击率预测等[3]。因此,基于代价敏感的学习成了机器学习中的一个热门研究方向。
目前对于代价敏感学习的研究大致可以分为以下几个方面:1)对数据集采样的代价敏感学习,通过改变原始数据集的分布,训练分类器得到具有代价敏感性的模型。在采样的过程中主要依据代价因子,插入或删除部分样本来调整数据集的分布,例如随机欠采样[4]、随机过采样[5]、合成少数类过采样技术(Synthetic Minority Oversampling Technique, SMOTE)[6]等方法;2)在学习过程中引入分类代价,使得生成的分类器给予误分类代价更高的类别更多的关注,使其更容易被正确分类,针对不同的分类方法提出了不同的代价敏感模型,如Drummond等[7]提出的代价敏感决策树;3)对分类结果的处理,主要包括决策阈值的修改以及对分类器的集成,如AdaCost算法[8]、Meta-Cost算法[9]等。文献[4-6]中提出的随机欠采样、随机过采样、合成少数类过采样(SMOTE)方法,会改变数据集的样本分布,影响分类器的性能。文献[7]提出的代价敏感决策树(cost-sensitive decision tree based on ID3, ID3cs)算法在分类过程中加入了误分类代价,使决策树在选择分裂属性时,选择能使误分类代价下降最快的。本文在文献[7]算法的基础上,引入了样本的类分布,考虑在分类节点上样本分布对分类代价的影响,以此作为选择分裂属性的依据,构造决策树;进而在形成的决策树的基础上进行分类器集成,以此得到最终的代价敏感决策树。
1 相关工作
1.1 机器学习中的代价敏感学习
传统的分类算法一般基于分类代价相等的假设,目标是最小化分类错误率,而代价敏感学习的目标是最小化总期望的误分类代价,也就是说代价敏感学习是在给定不同类别的误分类代价后,使用训练集样本学习得到一个分类器,使其在测试集上预测类别时,具有尽量小的总期望误分类代价[10]。
代价敏感学习中一般使用代价矩阵[11](见表1)表示分类器的误分类代价,其中cij表示把第i类误分为第j类所造成的损失。
1.2 代价敏感决策树
在文献[13]中,提出基于ID3决策树的代价敏感决策树ID3cs算法,主要思想是依据不同类别具有不同的误分类代价,在损失函数中加入了误分类代价,分裂属性的选择准则是使误分类代价下降最快的属性。具体描述如下:
对于一个二分类问题,数据集S包含特征Aj(j=1,2,…,n),对于每一个类别特征Aj,都含有m个不同的值Aji(i=1,2,…,m)。在Aj处的误分类代价为:
其中: p(i)表示分支i的比例;C(i)是分支i的代价。对非叶子节点i,它的代价是所有分支代价的加权和。对于叶子节点i,它的代价C(i)可以表示为:
其中: p(Pnodei)=PSi表示正样本在nodei处比例,Si表示在nodei处样本的总数目; p(Nnodei)=NSi表示负样本在nodei处比例;CP是在叶子节点nodei处正样本(贷款成功的用户)的代价;CN是在叶子节点nodei处负样本(贷款失败的用户)的代价。决策树的目标是最小化叶子节点{CP,CN}处的总代价。换句话说,如果CP≥CN,则叶子节点被标记为正;否则为负。
2.1 加入类分布的代价敏感决策树
受到C4.5算法的影响,以及文献[14]中提到类分布会影响到分裂节点的选择,因此为减弱正負类样本数量对误分类代价的影响,本文在代价敏感函数的计算中加入类分布,代价敏感函数CP、CN的计算方法修改为:
ID3决策树算法使用准确率作为剪枝的评判准则。在算法IID3cs中,树的生成和剪枝都是基于新定义的代价函数式(9)、(10),即若删除该某分支后,误分类代价减小,则进行剪枝操作;反之亦然。
2.2 代价敏感决策树的集成文献[13]中针对单一模型的不稳定性,提出对基分类器集成的思想,本文在对模型集成的过程中,采用的集成策略大致过程如下:
1)从原数据集中有放回地重采样获得L个不同的子训练集,以IID3cs作为基分类器进行训练,得到不同的、具有差异性的L个分类器[16],并计算这L个分类器的AUC值。
2)计算训练集中每个样本属于每个类别的概率和期望代价,以期望代价最小的准则将样本重标记。
3)运用IID3cs算法训练重标记的数据集,得到新的分类器M。
4)选择AUC值较高的几个基分类器(在本文选择AUC高于0.6的基分类器)与模型M进行加权,权重计算方式如式(11)所示,得到最终的分类器。将该算法称为IID3cs_Bagging。
其中第k个分类器的AUC值记为AUCk,权重为wk:
其中:l代表基分类器中AUC值超过0.6的基分类器个数;AUCM表示分类器M的AUC值;k=1,2,…,l,M。
IID3cs_Bagging算法可描述为:
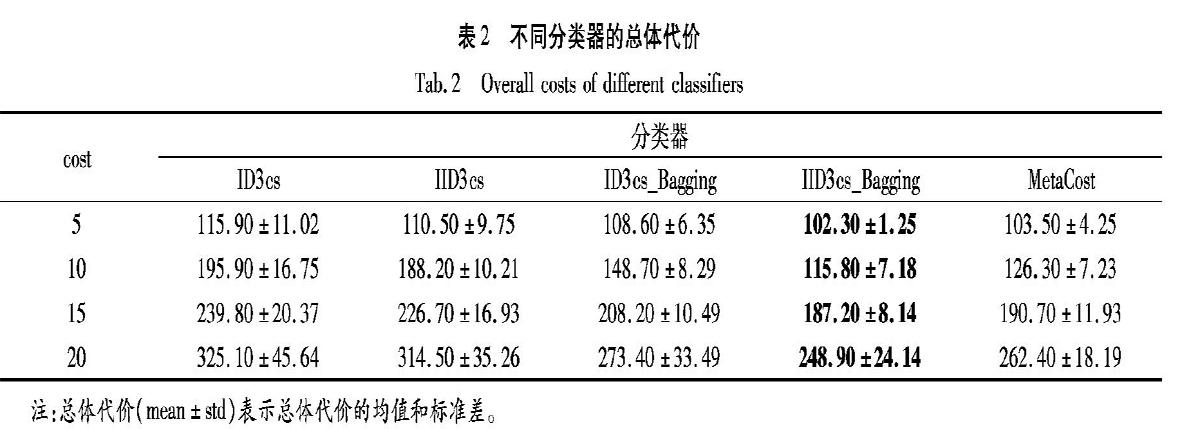
从图2中可以看到,虽然不同算法的ROC曲线出现了交叉,但是IID3cs_Bagging算法的ROC曲线位于最左上角,完全“包住”了其他算法的ROC曲线,说明在网络贷款用户分类数据集中该算法优于其他算法;ID3cs_Bagging算法和MetaCost算法的ROC曲线出现了交叉,交叉点在fpr≈0.28的位置,该点之前ID3cs_Bagging算法优于MetaCost算法,但之后MetaCost优于ID3cs_Bagging算法,进一步说明单一的代价敏感决策树在一定情况下已具有一定优势;IID3cs和ID3cs出现交叉,根据文献[15]提到,此时应比较两曲线下的面积,即AUC值的大小,根据表3,IID3cs、ID3cs算法的AUC值分别为0.684、0.629,IID3cs算法优于ID3cs算法。因此,在网络贷款用户分类数据集上,代价敏感决策树,尤其是集成后的呈现出明显的优势,说明了改进的IID3cs_Bagging算法的有效性。
从时间效率上来说,虽然在代价敏感算法中加入了代价矩阵的计算,但是它的运行效率并没有比ID3cs、ID3cs_Bagging以及MetaCost算法明显降低,因此从时间效率上分析,IID3cs以及IID3cs_Bagging算法也有一定的优越性。
3.3.3 ID3cs_Bagging中权重公式的选择
在2.1节中提出在最后由基分类器组成最后的分类器时,是先计算出各分类器的AUC值之后按照式(11)计算出各个基分类器的权重,进而合成最后的分类器。在转化中常用的转化方式主要有以下几种:
从表4和图3可以看出:在网络贷款用户分类数据集中,本文所采用的权重转换方式相对其他方式而言,具有较大优势,表现效果较好。
对于该数据集,集成分类器的大小为6,各分类器的权重为9.8%、10.3%、13.2%、14.9%、20.1%、31.7%。
以上实验结即使表明,改进的代价敏感决策树IID3cs_Bagging算法相对其他已有的代价敏感学习而言,在网络贷款用户分类数据集上具有更好的效果,而且IID3cs_Bagging算法的时间效率并不差于已有的算法。因此,在网络贷款用户分析中,本文所提代价敏感决策树IID3cs_Bagging算法具有较强的鲁棒性和泛化能力。
4 结语
本文通过对已有代价敏感决策树ID3cs算法的研究,考虑到正负类样本数量对期望误分类总代价的影响,在代价的计算过程中引入了样本的类别分布,即IID3cs算法。为进一步提高分类器的性能,以IID3cs算法作为基分类器进行集成。在网络贷款分类数据集的应用中,该算法与已有的常用于处理类别不平衡、代价敏感的算法相比,具有较好的表现,在最小化误分类总代价的同时,提高了分类准确率,尤其是少数类样本的分类准确率。
代价敏感学习仍然未能解决过拟合的问题,而且在考虑代价的过程中只是分析了误分代价,在未来的研究中,将会在这些方面进行更多的尝试。
参考文献(References)
[1] GUO Y, ZHOU W, LUO C, et al. Instance-based credit risk assessment for investment decisions in P2P lending[J]. European Journal of Operational Research, 2016, 249(2): 417-426.
[2] ANGELINI E, CAMBA-MENDEZ G, GIANNONE D, et al. Short term forecasts of euro area GDP growth[J]. The Econometrics Journal, 2011, 14(1): 25-44.
[3] ZHOU Z, LIU X. Training cost-sensitive neural networks with methods addressing the class imbalance problem[J]. IEEE Transactions on Knowledge and Data Engineering, 2006, 18(1): 63-77.
[4] LIU A, GHOSH J, MARTIN C E. Generative oversampling for mining imbalanced datasets[EB/OL]. [2018-12-10]. http://wwwmath1.uni-muenster.de/u/lammers/EDU/ws07/Softcomputing/Literatur/4-DMI5467.pdf.
[5] JAPKOWICZ N. Concept-learning in the presence of between-class and within-class imbalances[C]// Proceedings of the 14th Biennial Conference of the Canadian Society for Computational Studies of Intelligence, LNCS 2056. Berlin: Springer, 2001: 67-77.
[6] CHAWLA N V, BOWYER K W, HALL L O, et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2002, 16: 321-357.
[7] DRUMMOND C, HOLTE R C. Exploiting the cost (in) sensitivity of decision tree splitting criteria[C]// Proceedings of the 17th International Conference on Machine Learning. San Francisco: Morgan Kaufmann, 2000: 239-246.
[8] FAN W, STOLFO S J, ZHANG J, et al. AdaCost: misclassification cost-sensitive boosting[C]// Proceedings of the 16th International Conference on Machine Learning. San Francisco, CA: Morgan Kaufmann, 1999: 97-105.
[9] DOMINGOS P. MetaCost: a general method for making classifiers cost-sensitive[C]// Proceedings of the 5th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 1999: 155-164.
[10] 周宇航, 周志華. 价敏感大间隔分布学习机[J]. 计算机研究与发展, 2016, 53(9): 1964-1970. (ZHOU Y H, ZHOU Z H. Cost-sensitive large margin distribution machine[J]. Journal of Computer Research and Development, 2016, 53(9): 1964-1970.)
[11] 李航. 统计学习方法[M]. 北京: 清华大学出版社, 2012: 22-24. (LI H. Statistical Learning Methods[M]. Beijing: Tsinghua University Press, 2012: 22-24.)
[12] BANBURA M, MODUGNO M. Maximum likelihood estimation of factor models on datasets with arbitrary pattern of missing data[J]. Journal of Applied Econometrics, 2014, 29(1): 133-160.
[13] 邹鹏, 莫佳卉, 江亦华, 等.基于代价敏感决策树的客户价值细分[J]. 管理科学, 2011, 24(2): 20-29. (ZOU P, MO J H, KIANG M, et al. A cost-sensitive decision tree learning model — an application to customer-value based segmentation[J]. Journal of Management Science, 2011, 24(2): 20-29.)
[14] 李秋洁, 赵雅琴, 顾洲. 代价敏感学习中的损失函数设计[J]. 控制理论与应用, 2015, 32(5): 689-694. (LI Q J, ZHAO Y Q, GU Z. Design of loss function for cost-sensitive learning[J]. Control Theory & Applications, 2015, 32(5): 689-694.)
[15] 周志华. 机器学习[M]. 北京: 清华大学出版社, 2016: 86-128. (ZHOU Z H. Machine Learning[M]. Beijing: Tsinghua University Press, 2016: 86-128.)
[16] 付忠良. 不平衡多分類问题的连续AdaBoost算法研究[J]. 计算机研究与发展, 2011, 48(12): 2326-2333. (FU Z L. Real AdaBoost algorithm for multi-class and imbalanced classification problems[J]. Journal of Computer Research and Development, 2011, 48(12): 2326-2333.)
猜你喜欢
科学与信息化(2019年28期)2019-10-21
河北工业大学学报(2019年6期)2019-09-10
科学与财富(2016年32期)2017-03-04
无线互联科技(2016年14期)2017-02-06
软件导刊(2016年12期)2017-01-21
求知导刊(2016年28期)2016-11-28
科技视界(2016年7期)2016-04-01
科教导刊·电子版(2016年3期)2016-03-14
智富时代(2015年3期)2015-05-22
智富时代(2015年3期)2015-05-22
