
基于深度级联神经网络的自动驾驶运动规划模型
2019-11-15 04:49白丽贇胡学敏宋昇童秀迟张若晗
计算机应用 2019年10期
白丽贇 胡学敏 宋昇 童秀迟 张若晗


摘 要:针对基于规则的运动规划算法需要预先定义规则和基于深度学习的方法没有利用时间特征的问题,提出一种基于深度级联神经网络的运动规划模型。该模型将卷积神经网络(CNN)和长短期记忆网络(LSTM)这两种经典的深度学习模型进行融合并构成一种新的级联神经网络,分别提取输入图像的空间和时间特征,并用以拟合输入序列图像与输出运动参数之间的非线性关系,从而完成从输入序列图像到运动参数的端到端的规划。实验利用模拟驾驶环境的数据进行训练和测试,结果显示所提模型在乡村路、高速路、隧道和山路四种道路中均方根误差(RMSE)不超过0.017,且预测结果的稳定度优于未使用级联网络的算法一个数量级。结果表明,所提模型能有效地学习人类的驾驶行为,并且能够克服累积误差的影响,适应多种不同场景下的路况,具有较好的鲁棒性。
关键词: 自动驾驶;运动规划;深度级联神经网络;卷积神经网络;长短期记忆模型
中图分类号:TP391.4
文献标志码:A
Abstract: To address the problems that rule-based motion planning algorithmsunder constraints need pre-definition of rulesand temporal features are not considered in deep learning-based methods, a motion planning model based on deep cascading neural networks was proposed. In this model, the two classical deep learning models, Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM) network, were combined to build a novel cascaded neural network, the spatial and temporal features of the input images were extracted respectively, and the nonlinear relationship between the input sequential images and the output motion parameters were fit to achieve the end-to-end planning from the input sequential images to the output motion parameters. In experiments, the data of simulated environment were used for training and testing. Results show that the Root Mean Squared Error (RMSE) of the proposed model in four scenes including country road, freeway, tunnel and mountain road is less than 0.017, and the stability of the prediction results of the proposed model is better than that of the algorithm without using cascading neural network by an order of magnitude. Experimental results show that the proposed model can effectively learn human driving behaviors, eliminate the effect of cumulative errors and adapt to different scenes of a variety of road conditions with good robustness.
Key words: autonomous driving; motion planning; deep cascaded neural network; Convolutional Neural Network (CNN); Long Short-Term Memory (LSTM) model
0 引言
隨着社会经济的飞速发展,机动车辆的大量增长给交通环境带来了巨大的压力,造成安全事故频发。自动驾驶技术能够突破驾驶员的限制,为解决驾驶的安全、交通拥挤等问题提供契机。运动规划作为自动驾驶的核心环节,是连接车辆的环境感知与操纵控制的基础和桥梁。其目的是在考虑当前状态、感知数据以及交通规则等多种约束条件下,为自动驾驶车辆提供安全到达目的地的运动参数或可行路径,其技术除了可用于无人车以外,还可用于无人机[1]、移动机器人[2]等自主无人系统,因此具有重要的研究意义和商业价值。
目前,自动驾驶领域应用较为广泛的传统运动规划算法包括启发式搜索算法[3-5]、快速搜索随机树算法[6]和基于离散优化算法[7]。基于规则的传统运动规划算法在无人车和智能机器人等领域取得了成功的应用。然而,这类方法需要根据预先定义的规则来建立相关数学模型,在规划之内的场景能够取得较好的规划效果,而对于规则之外的场景却难以适应。此外,这类算法不能直接对感知的数据进行处理,而需要对数据进行预处理,并抽象出模型可以接受的环境表达,而这些预处理的过程相当耗费时间,导致系统规划反应时间过长,尤其是在紧急情况下存在较高的安全隐患。
近年来,深度学习的发展使得机器学习有了革命性的突破,其中应用较为广泛的两个模型是卷积神经网络(Convolutional Neural Network, CNN)[8]和长短期记忆(Long Short-Term Memory, LSTM)网络[9]。CNN能有效提取输入图像的空间特征[10],LSTM可以提取连续输入图像的时间特征[11]。而运动规划的本质,是从感知的序列数据到运动参数的映射。因此,将深度神经网络引入运动规划领域,能够实现从感知数据到运动参数的规划。目前已有一些基于深度神经网络的方法取得了较好的成果。NVIDIA公司[12]提出了一种基于CNN的端对端的运动规划算法,将道路线检测、路径规划和控制等子步骤通过CNN同时完成。该方法能有效地将驾驶图像特征映射为方向盘转角,但是没有考虑前后帧的时间特征。Chen等[13]在深度神经网络的基础上提出了13个可用于自动驾驶的场景描述指标,通过精确地学习这些指标的值后,可完成转向角的控制。该方法在没有车辆的道路的数据集中取得良好表现,但同样没有利用连续帧的信息,在路况复杂的情况下驾驶行为不稳定。Sallab等[14]使用深度强化学习提出了一种自动驾驶框架,它包含了用于信息集成的递归神经网络,使汽车能够处理部分可观察的场景。然而该方法需要通过在环境中试错来训练模型,训练时间长,且难以将模型迁移到实际环境中。此外,这些方法只利用单个前向摄像机获取驾驶信息,没有考虑周围的信息,容易造成累积误差的问题。
针对基于传统的运动规划算法存在的需要预先定义规则、预处理复杂,以及基于深度学习方法中没有利用连续帧之间的时间特征、模型训练时间长、没考虑累积误差等问题,本文提出一种基于深度级联神经网络(Deep CNN, DCNN)的自动驾驶运动规划模型。该模型利用CNN和LSTM构成深度级联神经网络,分别提取驾驶场景序列图像中的空间和时间特征,并与车辆的方向盘转角建立映射关系,从而实现直接从感知图像到运动参数的端到端的运动规划;并且,为了解决累计误差的问题,训练时使用左、中、右三个摄像机采集的前向视频构成数据集,解决在线测试时累计误差的自动修正问题。该模型采用深度学习的方法解决自动驾驶运动规划的问题,让规划算法具备学习能力,能够应对多种复杂的道路场景,并且不需要预处理过程,实现端到端的运动规划。本文方法既解决了自动驾驶中复杂道路场景的时空特征表达问题,也为端到端的运动规划提供新的方法。
1 基于深度级联神经网络的运动规划模型
本文提出的基于DCNN的运动规划模型如图1所示,模型输入为前向车载相机的序列图像,经过网络后输出为当前预测的方向盘转角。深度级联神经网络由CNN层和LSTM层组成。其中,CNN层对每一帧图像提取空间特征,然后输入到LSTM层提取连续帧图像的时间特征,最后模型输出得到方向盘转向角的预测结果。该过程可用式(1)来描述:
在训练阶段,将左、中、右三个摄像机采集的序列图像数据集作为输入,模型预测输出方向盘转角。此外,利用输入图像对应的真实方向盘转向角,即数据标签,与预测的转向角之间的误差计算损失函数,经过反向传播算法对CNN和LSTM网络中的权值进行更新。为了消除数据采集中的误差影响,本文对人工采集的真实方向盘转角进行低通滤波处理。在测试阶段,仅将中心摄像机采集的视频作为输入,用训练好的模型预测当前输入下的方向盘转角,实现从输入图像到运动参数端到端的运动规划。
1.1 CNN层网络设计
近年来,CNN被广泛应用于大规模的图像识别任务中。由于其使用了局部连接和权值共享的方式,在处理二维图像时,特别是在识别位移、缩放以及其他形式的扭曲不变性应用上有着良好的鲁棒性。自动驾驶场景复杂,车载相机获取的图像中目标种类较多,有效提取这些图像特征是一个较为困难的任务。
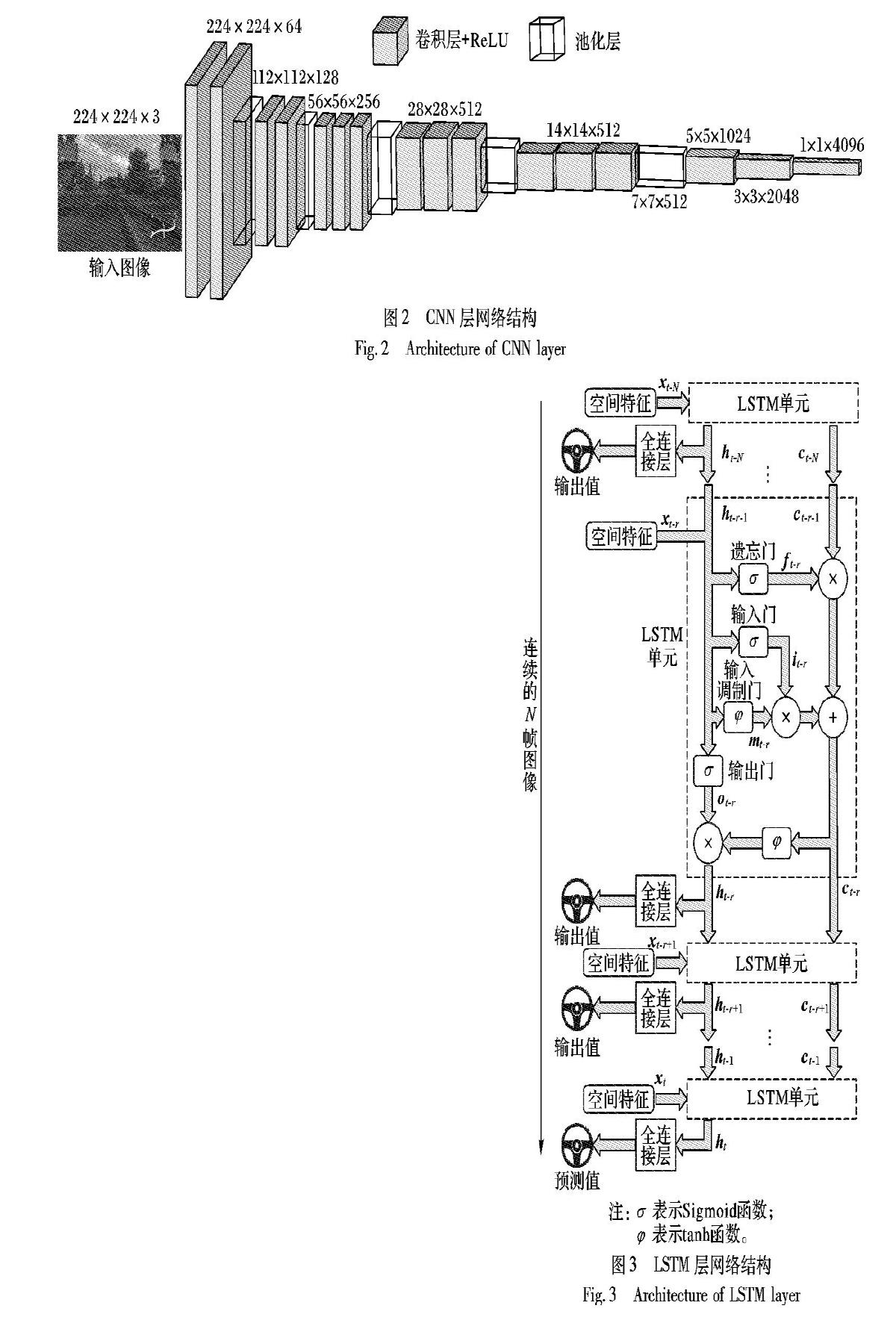
VGG-Net(Visual Geometry Group Net)[15]是牛津大学计算机视觉组和Google DeepMind公司的研究员在2014年提出的一种CNN,采用ImageNet数据集进行训练,并广泛用于目标检测等图像识别领域。而自动驾驶场景中建筑物、车辆、行人等目标已经包含在该数据集中,因此本文选择VGG-Net作为CNN的网络结构基础,依据级联网络的设计进行改进,并利用驾驶场景数据集对网络权值进行微调,以此减少训练时间。此外,考虑到运动规划对实时性的要求,本文实验中采用VGG-16作为本文CNN层的基础模型,并进行改进。改进的VGG网络结构如图2所示,将224×224的三通道图像作为输入,在经过5个卷积层与5个池化层之后,通过三个卷积层输出得到1×1×4096的特征矢量。其中,所有的卷积层使用3×3的卷积核,同时使用修正线性单元(Rectified Linear Unit, ReLU)作为激活函数。前5个卷积层的滑动步长为1个像素,卷积层的空间填充固定为1个像素,用来保持卷积后图像的长宽尺寸与卷积前一致。池化层采用尺寸为2×2最大池化方法,步长为2。
CNN中,卷积层和池化层一般用于提取图像特征,而全连接层一般作为分类器用于对目标进行分类。由于本文提出的深度级联网络中,CNN的目的是提取驾驶场景图像的空间特征,不需要进行分类,因此本文去掉了原始VGG-16中的最后3个全连接层,用3个3×3、滑动步长为2的卷积层代替原始VGG-16网络中的全连接层。相对于较大的卷积核,较小卷积核需要训练总的参数数量更少,更有利于训练时的收敛,减少训练时程序占用的计算资源。
1.2 LSTM层网络设计
LSTM是一种经典的循环神经网络,可以学习长期依赖信息。由于其加入了门控和LSTM细胞状态等机制,其网络的权重可随时间尺度动态地改变,因此可以提取长期时间的序列特征。图3中虚线矩形框中LSTM单元描述了LSTM单元的内部结构,其中,其中:Wxi与b分别表示对应门控单元的权值与偏差;xt-r表示LSTM单元的输入;ht-r与ht-r-1分别表示当前LSTM单元的输出与上一个单元的输出;ct-r与 ct-r-1分别表示当前细胞状态与上一个单元的细胞状态; ft-r表示遗忘门;it-r表示输入门;ot-r表示输出门;mt-r表示输入调制门;“⊙”为点乘。在LSTM单元中设置了四个控制门,每一个控制门都是由多层感知机与激活函数构成的。在LSTM中,首先由遗忘门读取xr和hr-1,在决定丢弃的信息后输出fr。下一步决定让多少信息加入到细胞状态,这个过程分为sigmoid层决定需要更新的信息ir和一个tanh层生成备选的用来更新的内容mr两部分组成,这两部分联合起来对细胞状态进行更新。在更新细胞状态时,把fr与旧状态点乘后加上ir⊙mr完成细胞状态更新。最后确定输出信息,由一个sigmoid层来确定细胞状态的输出部分,并把细胞状态通过tanh进行处理并将它和sigmoid门的输出相乘,得到最终输出的信息。由于运动规划的輸入视频图像在时间上是相关的,因此LSTM适合于提取视频中时间前后帧的关联信息。
本文中LSTM网络设计如图3所示。对于每一帧图像,CNN网络输出一个特征向量x,对于连续n帧图像输出n个特征矢量。本文设计的CNN层的输出为1×1×4096的向量,在这里作为空间特征向量输入到LSTM单元中,经过LSTM层和全连接层后输出转向角的预测。对于当前时刻t,其输出的值由特征向量xt与上一个LSTM单元的输出 ht-1和状态ct-1决定,在经过全连接层与输出节点,即得到当前方向盘转角的预测值。在LSTM网络中,LSTM单元中的权值是共享的,即对应于不同时刻的驾驶图像,其对应的LSTM单元中的四个控制门的权值是一样的。在如图3所示的网络结构中,LSTM单元是同一个LSTM单元在复用,在上一时刻LSTM单元的输出值与细胞状态会传入下一时刻的单元中。
1.3 网络输出与目标函数设计
车辆的方向盘转向角度是一种连续的变量,因此转向角的预测问题可以看作是神经网络的回归问题。由于本文的预测的运动参数只有转向角,所以设计的深度级联神经网络的输出节点数量为1。此外,为设计目标函数训练深度级联神经网络,本文采用转向角的预测值与真实值之间的欧氏距离作为损失函数,如式(8)所示:
其中:L表示损失函数; pg表示对应的方向盘转角真实值,由人工采集获取;s为模型的输入图像;M为神经网络模型。为防止网络训练的过拟合问题,本文采用L2正则化的方法。因此,本文设计的目标函数更新方法如式(9)所示:
1.4 网络的训练与测试
本文提出的基于DCNN的运动规划方法,利用事先采集的训练样本进行模型训练,然后利用训练好的模型对测试样本进行离线测试。但是由于离线测试中存在累积误差的问题,如果不加以修正,难以直接用于在线测试。为了解决该问题,在采集训练数据时设置了3个摄像机,分别是左摄像机、中心摄像机和右摄像机。中心摄像机的主光轴与车身竖直方向平行,左、右两个摄像机的主光轴设置与中心摄像机有一定的夹角(本文中夹角设置均为25°)。三个摄像机采集的图像如图4所示。左、右两个摄像机能够显示车辆从当前车道中心的不同位移,以及与道路方向的偏航角度。从左、右摄像机分别获得两种不同位移的图像,通过对最近的摄像机图像进行视点变换,模拟摄像机与各偏航角之间的附加位移,并将转换后的图像样本的转向角标签作相应的角度调整,作为补充训练数据集。左、右摄像机与中心摄像机采集的样本数据及标签一起构成训练数据集。通过补充数据集中样本的训练,自动驾驶车辆能够在航向角偏离正常航线时及时自动修正方向,不让误差形成累积效应。
在训练阶段,使用包含多种场景的驾驶数据的训练集对网络进行训练,使用反向传播算法在每一次迭代中更新网络的权值。本文使用随机梯度下降算法来计算每一次更新的权值。由于训练集样本较多,随着迭代次数的增加,网络参数逐渐向最优参数逼近。本文中,迭代总次数设置为200000,初始学习率为0.0015,batchsize的大小为4。
本文测试分为离线测试和在线测试。离线测试中,测试数据采用未经训练的路段驾驶视频流输入到网络中,记录每帧对应的输出,并与真实数据作对比,从对比的结果中判断网络输出的结果是否能作为准确的规划结果;在线测试主要是验证累积误差的修正问题,让算法在模拟器中运行,验证自动驾驶车辆是否能安全行驶。
2 实验与结果分析
为保证测试的安全性,本文实验在模拟器的环境下开展。欧洲卡车模拟器2是目前经典的一种驾驶模拟器,其逼真的模拟场景、大范围的地图和多路况和天气的模拟,很适合作为自动驾驶的模拟器。本文使用Europilot框架进行数据采集,通过模拟方向盘、油门和刹车踏板采集人工驾驶的方向盘转角数据作为训练样本的标注信息。
在实验中,人类操作该模拟器以30 帧/秒的帧率进行三个摄像机的图像采集,每帧图像的像素尺寸为1853×1012,输入网络时将图像缩小为224×224。为保证驾驶场景的多样性,实验采集了约8h的驾驶数据,包括4种不同的道路,分别是乡村路、高速路、隧道和山路。由于本文方法没有考虑交通标志信息,因此没有将城市道路作为实验路段。实验中每种道路取一段路作为测试集,其他数据均作为训练集,使用训练集中的数据对本文提出的DCNN模型进行训练,再使用测试集的数据对网络的输出进行测试。由于模仿学习是学习人类的驾驶行为,因此评判模型预测的准确性就以人类专家的驾驶数据作为标准。将测试结果与人类驾驶的数据进行对比,采用均方根误差(Root Mean Squared Error, RMSE)来衡量模型的性能,公式如下所示:
稳定性也是衡量自动驾驶模型好坏的一个重要的指标,驾驶的稳定性影响着舒适度和安全性。由于均方误差的大小可以是从零到无穷大,只是针对每帧预测准确性作评估,无法衡量驾驶的平稳性,因此本文使用式(11)作为驾驶稳定性的衡量标准:
其中:ST为稳定度指标。对于弧度不同的弯道,稳定度指标有着较大的变换范围,因此该指标只能衡量同一场景下不同模型的稳定度,而不能对不同场景下的情况作出评判。
本文实验的软件环境为Ubuntu 16.04,深度神经网络框架采用Caffe[16],硬件环境CPU为Core i7-7700K (Quad-core 4.2GHz)、GPU为 NVIDA GTX 1080Ti、内存为32GB。实验同时测试了未使用LSTM的原始VGG-16和NVIDIA训练的神经网络[12]作为对比。实验的结果如图5~7,以及表1~2所示。根据实验结果,可得到如下结论:
1)深度级联网络模型中的空间特征提取层基于改进的VGG设计,能够有效提取不同复杂场景的图像特征,因此对于不同的场景能够作出准确的预测。从图5中可以观察DCNN的预测曲线与真实曲线比较相近,4个场景的RMSE均不超过0.017,大约为转向角输出值范围的1%。图7為同一时刻三种方法与真实数据的对比,可以看出相对于原始的VGG网络与
文獻[12]方法所采用的网络,由于使用了LSTM,改进的网络预测更为准确。从表1可知在四个场景中原始的VGG和文献[12]方法的均方根误差均高于DCNN方法,而且4种场景的均方根误差都在同一水平。
2)本文方法预测的转向角具有较好的稳定性。在4个场景中,预测转向的稳定度与真实转向的稳定度相差不大,而且远好于原始的VGG方法与文献[12]方法。与人类专家的驾驶稳定度相比,DCNN的稳定度与人类专家相近,而原始的VGG和文献[12]方法的稳定度指标高于人类专家一个数量级,相差比较大。这是因为人工采集的数据由于手的抖动和输入设备等问题,存在一些噪声。而本文方法中利用了滤波器对输入数据进行平滑,且增加了LSTM层,使得网络能够将时间上前后相邻的几帧图像联系在一起,输出更加平滑的预测值。
3)本文方法能有效地修正行驶中的累积误差。本文在训练网络时除了前向中心摄像机的图像,还增加了左、右两个摄像机的采集的图像作为训练样本来训练模型,使模型能够在偏离正确航向时修正方向,不让误差累积起来。图6为一段连续在线测试的图像。从图6的右后视镜中可以看出,第1帧中车辆有稍微向右偏离当前车道,但是模型能够自动修正误差,从第8帧开始回到当前车道中央。
4)本文设计的深度级联神经网络算法采用了GPU加速,因此在处理速度上相对于传统的单线程算法具有一定速度上的优势。视频流从输入神经网络到输出预测值大约需要0.05s,即每秒钟约20次规划。而人类的反应时间大约为0.2s[17],要远大于本文方法预测的时间,因此本文方法能够满足在自动驾驶中运动规划的实时性要求。
3 结语
本文提出了一种深度级联神经网络,并利用该网络实现从输入图像到运动参数的端到端的自动驾驶运动规划。该方法中,利用前向车载相机的序列图像作为输入,使用提出的深度级联神经网络对自动驾驶的运动参数做回归,实现对方向盘转向角的预测。深度级联网络融合了CNN和LSTM两种经典的深度模型,使模型不仅能够提取驾驶场景的空间特征,还提取了连续图像的时间特征,实现对输出结果的准确预测;并且,训练时额外利用了左、右两个摄像机采集的数据作为补充数据集,解决了在线测试时的累计误差修正问题。实验结果表明,通过大量数据的训练,该网络能够有效、实时地针对不同场景的驾驶转向角作出预测,能够适应复杂的动态场景。由于该方法没有考虑交通信息以及全局路径信息,只能从网络的输入得到规划的结果,因此无法应用于城市道路。未来的工作将集中在如何将全局路径信息和交通信息融合于模型,让模型能够适应更复杂的城市道路。
参考文献(References)
[1] 余翔, 王新民, 李俨. 无人直升机路径规划算法研究[J]. 计算机应用, 2006, 26(2): 494-495. (YU X, WANG X M, LI Y. Study of a path planning algorithm for unmanned helicopter[J]. Journal of Computer Applications, 2006, 26(2): 494-495.)
[2] 张超超, 房建东. 基于定向加权A*算法的自主移动机器人路径规划[J]. 计算机应用, 2017, 37(S2): 77-81. (ZAHNG C C, FANG J D. Path planning of autonomous mobile robot based on directional weighted A* algorithm[J]. Journal of Computer Applications, 2017, 37(S2): 77-81.)
[3] BRANDES U. A faster algorithm for betweenness centrality[J]. Journal of Mathematical Sociology, 2001, 25(2): 163-177.
[4] HART P E, NILSSON N J, RAPHAEL B. A formal basis for the heuristic determination of minimum cost paths[J]. IEEE Transactions on Systems Science and Cybernetics, 1968, 4(2): 100-107.
[5] STENTZ A. Optimal and efficient path planning for partially-known environments[C]// Proceedings of the 1994 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 1994: 3310-3317.
[6] KARAMAN S, WALTER M R, PEREZ A, et al. Anytime motion planning using the RRT*[C]// Proceedings of the 2011 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2011: 1478-1483.
[7] HU X, CHEN L, TANG B, et al. Dynamic path planning for autonomous driving on various roads with avoidance of static and moving obstacles[J]. Mechanical Systems and Signal Processing, 2018, 100: 482-500.
[8] LECUN Y L, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[9] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780.
[10] 胡學敏, 易重辉, 陈钦, 等. 基于运动显著图的人群异常行为检测[J]. 计算机应用, 2018, 38(4): 1164-1169. (HU X M, YI C H, CHEN Q, et al. Abnormal crowd behavior detection based on motion saliency map[J]. Journal of Computer Applications, 2018, 38(4): 1164-1169.)
[11] WOJNA Z, GORBAN A N, LEE D, et al. Attention-based extraction of structured information from street view imagery[C]// Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition. Piscataway: IEEE, 2017: 844-850.
[12] BOJARSKI M, del TESTA D, DWORAKOWSKI D, et al. End to end learning for self-driving cars[EB/OL]. (2016-04-25) [2019-02-23]. https://arxiv. org/pdf/1604.07316.pdf.
[13] CHEN C Y, SEFF A, KORNHASUER A, et al. Deep driving: learning affordance for direct perception in autonomous driving[C]// Proceedings of the IEEE 2015 International Conference on Computer Vision. Piscataway: IEEE, 2015: 2722-2730.
[14] SALLAB A E L, ABDOU M, PEROT E, et al. Deep reinforcement learning framework for autonomous driving[EB/OL]. [2019-01-10]. https://arxiv.org/abs/1704.02532.
[15] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. [2019-01-20]. https://arxiv.org/pdf/1409.1556.pdf.
[16] JIA Y, SHELHAMER E, DONAHUE J, et al. Caffe: convolutional architecture for fast feature embedding[C]// Proceedings of the 22nd ACM Conference on Multimedia. New York: ACM, 2014: 675-678.
[17] THORPE S, FIZE D, MARLOT C. Speed of processing in the human visual system[J]. Nature, 1996, 381(6582): 520-522.
猜你喜欢
汽车周刊(2017年5期)2017-06-06
中国科技纵横(2017年4期)2017-05-16
移动通信(2016年24期)2017-03-04
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
软件导刊(2016年9期)2016-11-07
家用汽车(2016年9期)2016-11-04
软件工程(2016年8期)2016-10-25
环球时报(2016-08-16)2016-08-16
电脑知识与技术(2016年10期)2016-06-16
