
基于语义分割的室内动态场景同步定位与语义建图
2019-11-15 04:49席志红韩双全王洪旭
计算机应用 2019年10期
席志红 韩双全 王洪旭

摘 要:针对动态物体在室内同步定位与地图构建(SLAM)系统中影响位姿估计的问题,提出一种动态场景下基于语义分割的SLAM系统。在相机捕获图像后,首先用PSPNet(Pyramid Scene Parsing Network)對图像进行语义分割;之后提取图像特征点,剔除分布在动态物体内的特征点,并用静态的特征点进行相机位姿估计;最后完成语义点云图和语义八叉树地图的构建。在公开数据集上的五个动态序列进行多次对比测试的结果表明,相对于使用SegNet网络的SLAM系统,
所提系统的绝对轨迹误差的标准偏差有6.9%~89.8%的下降,平移和旋转漂移的标准偏差在高动态场景中的最佳效果也能分别提升73.61%和72.90%。结果表明,改进的系统能够显著减小动态场景下位姿估计的误差,准确地在动态场景中进行相机位姿估计。关键词:语义分割;动态场景;室内场景;位姿估计;视觉同步定位与地图构建;语义同步定位与地图构建
中图分类号:TP242.6
文献标志码:A
Abstract: To address the problem that dynamic objects affect pose estimation in indoor Simultaneous Localization And Mapping (SLAM) systems, a semantic segmentation based SLAM system in dynamic scenes was proposed. Firstly, an image was semantically segmented by the Pyramid Scene Parsing Network (PSPNet) after being captured by the camera. Then image feature points were extracted, feature points distributed in the dynamic object were removed, and camera pose was estimated by using static feature points. Finally, the semantic point cloud map and semantic octree map were constructed. Results of multiple comparison tests on five dynamic sequences of public datasets show that compared with the SLAM system using SegNet network, the proposed system has the standard deviation of absolute trajectory error improved by 6.9%-89.8%, and has the standard deviation of translation and rotation drift improved by 73.61% and 72.90% respectively in the best case in high dynamic scenes. The results show that the improved method can significantly reduce the error of pose estimation in dynamic scenes, and can correctly estimate the camera pose in dynamic scenes.
Key words: semantic segmentation; dynamic scene; indoor scene; pose estimation; Visual Simultaneous Localization And Mapping (VSLAM); semantic Simultaneous Localization And Mapping (SLAM)
0 引言
同步定位与地图构建(Simultaneous Localization And Mapping, SLAM)是移动机器人、无人机、无人驾驶等应用的基础技术。场景中存在运动物体时,动态物体的不稳定特征点被提取后会严重影响相机位姿估计,造成轨迹误差偏大,甚至系统崩溃。基于视觉的SLAM在动态场景中仍然具有很大的挑战性,而且目前视觉SLAM通常基于几何信息建图,缺少对地图信息的抽象理解,不能为移动载体的感知和导航提供环境的语义信息,制约了感知和导航效果。因此语义信息与几何信息结合构建语义地图成为了一个研究热点。
深度学习与SLAM结合可以从几何和语义两个层次上感知场景,从而对环境内容进行抽象理解,缓解对环境特征的依赖,获得高层次的感知[1],提高移动机器人对周围环境的理解。Li等[2]将SLAM与卷积神经网络(Convolutional Neural Network, CNN)结合,选择关键帧进行语义分割,利用二维语义信息和相邻关键帧之间的对应关系进行三维建图。McCormac等[3]将ElasticFusion和CNN结合,利用稠密的SLAM系统ElasticFusion计算位姿并建出稠密的图,卷积神经网络预测每个像素的物体类别,通过贝叶斯更新来把识别的结果和SLAM生成的关联信息整合到稠密语义地图中。在动态场景中,Kim等[4]提出通过计算连续的深度图像在同一平面上的投影的差异获得场景中的静态物体。Sun等[5]通过计算连续RGB图像的强度差异、量化深度图像的分割完成像素分类,区分动态静态物体。Yu等[6]提出的
DS-SLAM(Semantic visual SLAM towards Dynamic environments)在动态场景下将SLAM与SegNet[7]网络结合,利用语义信息和运动特征点检测滤除每一帧的动态物体,从而提高位姿估计准确性,同时建立语义八叉树地图。Li等[8]提出了一种关键帧边缘点的静态加权方法用以表示一个点是静态环境一部分的可能性,减少动态对象对位姿估计的影响。Bescos等[9]将多视几何和深度学习结合,实现没有先验动态标记而具有移动性的物体的检测和分割,并且通过对动态物体遮挡的背景帧进行修复,生成静态场景地图。
本文针对室内动态场景下SLAM位姿估计和建立语义地图问题展开研究,改进了动态场景中的语义SLAM系统,主要工作如下:
1)将ORB-SLAM2[10]与语义分割网络PSPNet(Pyramid Scene Parsing Network)[11]相结合,减小了动态物体内的特征点对相机位姿估计的影响,减小了轨迹误差。2)建立带有语义信息的点云图和语义八叉树地图,为导航定位等应用提供语义地图信息。3)在相同公开数据集慕尼黑工业大学TUM(Technische Universitt München) RGB-D[12]上与DS-SLAM进行对比,评估本文系统的有效性。
1 本文系统
1.1 SLAM系统框架
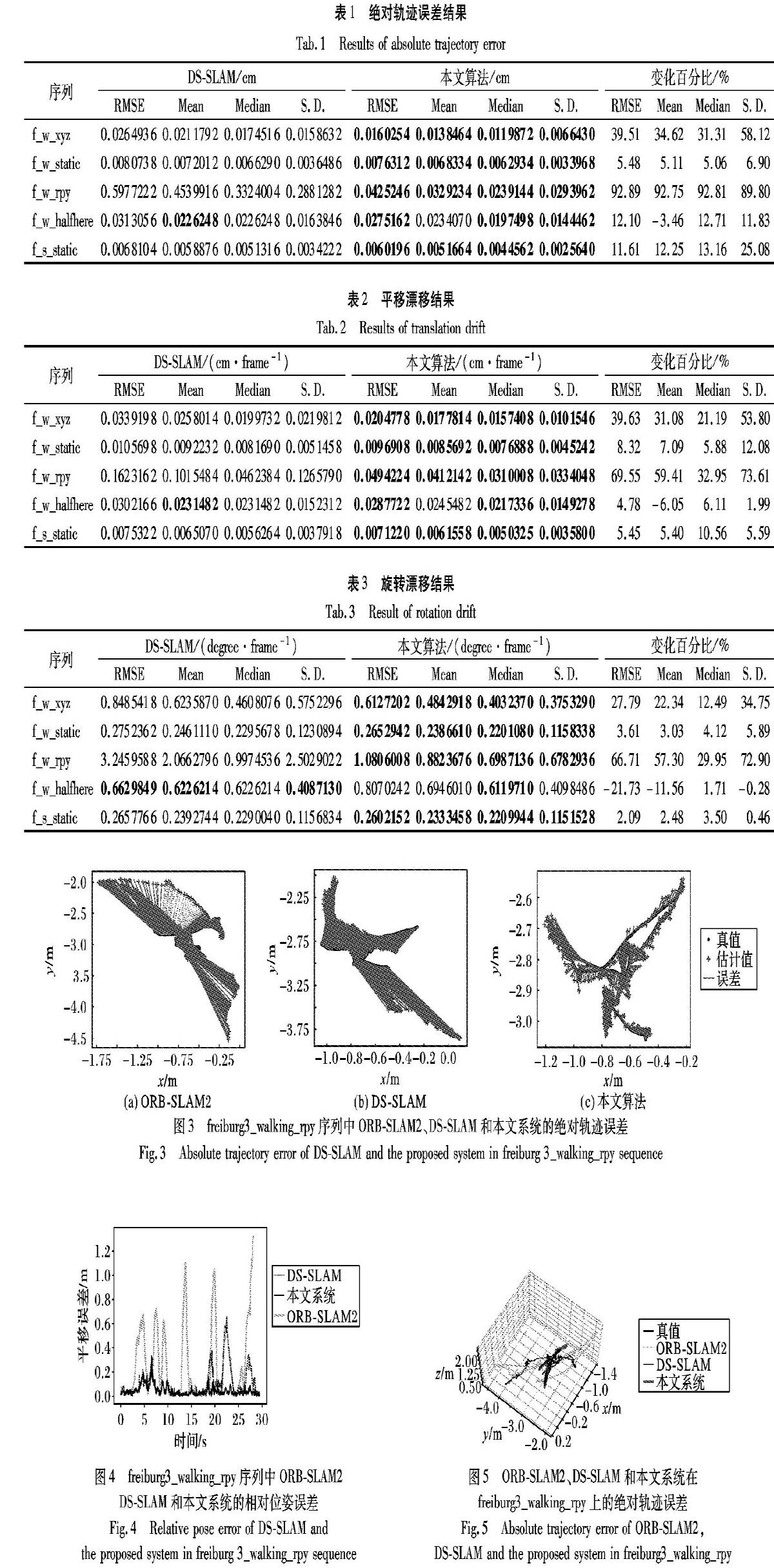
ORB-SLAM2被认为是目前最完整、最稳定的SLAM系统之一,可以运行单目、双目和RGB-D相机。本文SLAM采用ORB-SLAM2来提供SLAM方案,并行运行五个线程:语义分割、跟踪、局部建图、闭环检测和稠密地图构建。本文SLAM系统框架如图1所示,RGB-D相机捕获的原始RGB图像先在语义分割线程中处理,得到每个像素语义标签;然后由跟踪线程提取ORB特征点,由移动一致性检查检测潜在的外点,若ORB特征点落在语义分割预测的动态物体中,则将这些特征点作为外点剔除,用剔除外点后稳定的静态点估计相机位姿。
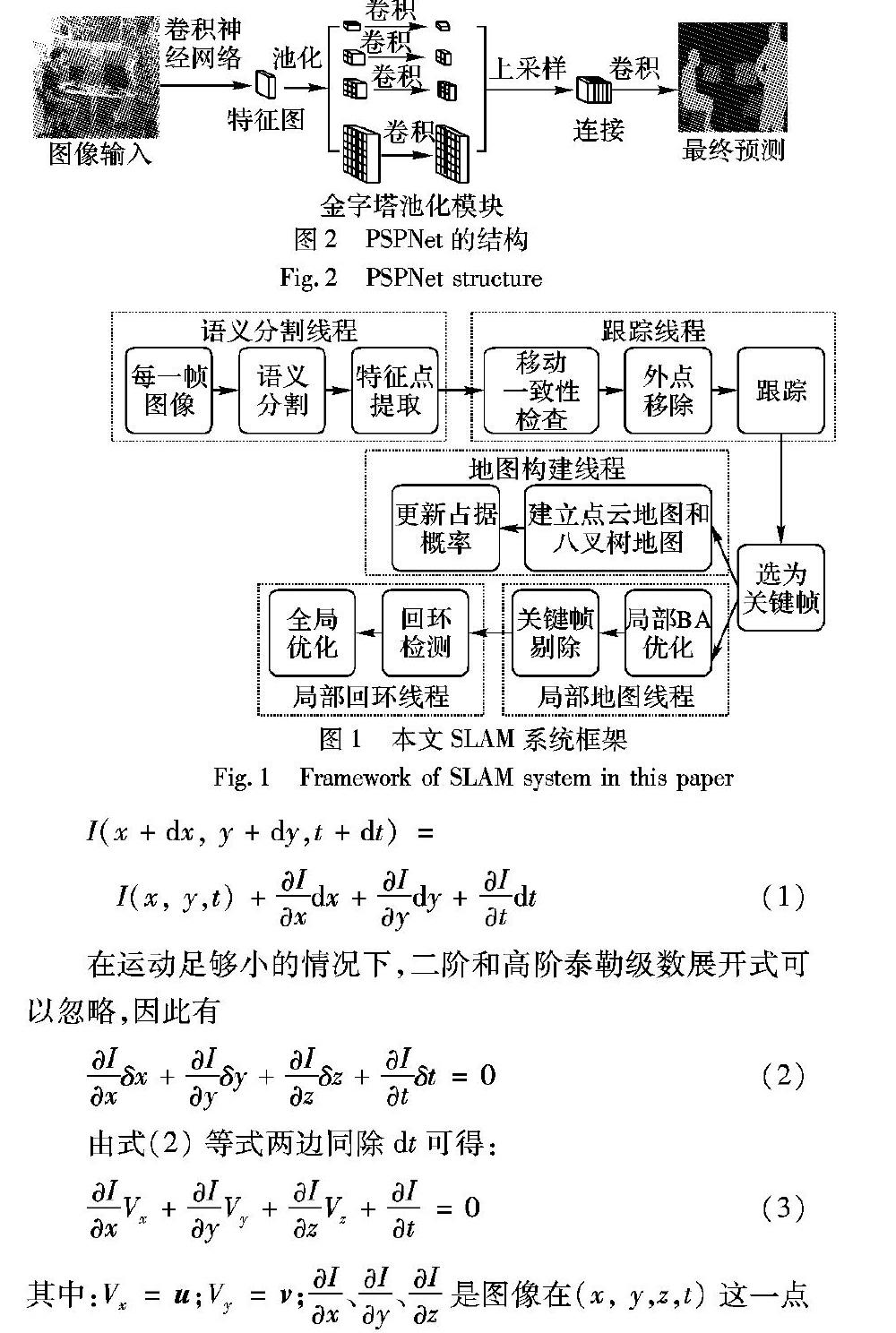
1.2 语义分割DS-SLAM采用的语义分割网络是基于全卷积神经网络(Fully Convolutional Network, FCN)[13]的SegNet,由VGG-16网絡修改得到,但FCN存在几个问题:缺乏依据上下文推断的能力,不能通过类别之间的关系弥补标签之间的关联;模型可能会忽略小的东西,而大的东西可能会超过FCN接受范围,从而导致不连续的预测。总之,FCN不能很好地处理场景之间的关系和全局信息。而PSPNet提出了一个金字塔场景解析网络,能够将难解析的场景信息特征嵌入基于FCN预测框架中,将局部信息和全局特征融合到一起,并提出了适度监督损失的优化策略,既能获取全局场景信息,还可以有效地处理场景之间的关系。因此,本文SLAM系统采用基于Caffe[14]的逐像素语义分割网络PSPNet。在PASCAL VOC2012[15]数据集上训练的PSPNet总共划分20个类别。PSPNet的结构如图2所示。输入的图片经过卷积神经网络提取特征图,提取后的特征图经过金字塔池化模块,得到不同尺度下的带有整体信息的特征,在上采样后将金字塔生成的不同层次的特征图连接,最后经过卷积层获得每个像素的分类。
1.3 移动一致性检查和外点剔除动态点的检查方法采用DS-SLAM的移动一致性检查。如果移动一致性检查得到的动态点落在分割的对象内,并且动态点数量大于一定阈值,则该对象可以被视为动态对象。动态点检测方法如下:
第1步 计算光流金字塔以获得当前帧中匹配的特征点。
第2步 如果匹配点对太靠近图像边缘或者匹配点对中心的3×3
图像块的像素差超过设定阈值,
则匹配点对将被丢弃。
第3步 通过随机采样一致性方法和匹配点对计算基础矩阵,对于每一对匹配点,根据参考帧的像素坐标和基础矩阵计算极线,确定从匹配点到其对应的极线的距离是否小于等于某个阈值:如果距离大于阈值,则认为它是一个动态点[6]。
其中:光流金字塔的计算采用LK(Lucas-Kanade)光流金字塔算法,假设亮度不变、运动幅度小、空间一致。画面移动过程中,图像上每个像素的偏移量为(x, y),若第t帧A点的位置是(x1, y1),则第t+1帧时,假如A点的位置是(x2, y2),可以确定A点的运动为(u, v)=(x2, y2)-(x1, y1)。假设原图是I(x, y,z,t),移动后的图像是I(x+δx,y+δy,z+δz,t+δt),两者满足图像约束方程:
在运动足够小的情况下,二阶和高阶泰勒级数展开式可以忽略,因此有
由式(2)等式两边同除dt可得:
由于LK算法假设是小位移,需要在多层图像缩放金字塔上求解,每一层的求解结果乘以2后加到下一层即可解决位移大的问题。
基于几何的方法提取动态物体轮廓时间开销大,而用语义分割的方法去提取轮廓耗时少,因此,在本文SLAM系统中采用了语义分割网络,可以快速地获得对象的完整轮廓。如果通过移动一致性检查产生一定数量的动态点落在分割对象的轮廓中,则确定该对象正在移动。如果确定分割的对象正在移动,则移除位于对象轮廓中的所有特征点。通过这种方式,可以精确地消除外点。此外,错误分割的影响也可以在一定程度上降低。
在实际场景中,人是动态场景中的主要动态物体,因此将人作为实验的动态物体。在语义分割结果出来之后,如果没有检测到人,则所有ORB特征将直接与最后一帧匹配估计位姿;否则,使用移动一致性检查结果确定人员是否在移动。如果人被确定为静态,则直接估计位姿;否则在匹配之前删除属于人物轮廓的所有ORB特征点。这样,可以显著降低动态对象的影响。
1.4 语义点云地图和语义八叉树地图
系统构建的语义点云地图和语义八叉树地图,能够较好地呈现出室内的场景,语义分割识别出的物体被标注了不同的颜色信息,并且场景中的动态物体(在数据集中即为人)得到了很好的剔除。相对于语义点云地图,语义八叉树地图所占的空间约是语义点云地图的1%,能够节省大量的硬盘空间,为机器人提供导航地图,并且能够提供语义信息。
2 实验与分析
2.1 数据集实验所需的数据集TUM RGB-D是TUM(德国慕尼黑工业大学)开源的大型数据集,包含RGB-D数据和地面实况数据,目的是为视觉测距和视觉SLAM系统的评估建立新的基准。本文的数据集主要采用数据集中Asus Xtion采集的5个序列,分别为
。 freiburg3_sitting_static序列中两个人坐在办公桌前,相机保持在适当位置,视为是低动态序列,其他四个序列均为两个人走过办公室,视为高动态序列。 freiburg3_walking_static序列相机保持在适当位置, freiburg3_walking_xyz序列相机沿三个方向(x, y,z)移动,reiburg3_walking_halfsphere序列中相机在大约一米直径的小半球上移动, freiburg3_walking_rpy序列中相机沿主轴(滚转俯仰偏航)在相同位置旋转。
另外,数据集还提供了用于系统评估的方法——绝对轨迹误差(Absolute Trajectory Error, ATE)和相对位姿误差(Relative Pose Error, RPE)。其中:ATE代表轨迹的全局一致性,而RPE测量平移和旋转漂移。
2.2 实验结果
在本节中,将展示本文SLAM系统实验结果以说明系统在公共数据集TUM RGB-D的动态场景数据集中的性能。所有实验均在配备Intel i7 CPU,GTX1070 GPU和16GB内存的计算机上进行。
2.2.1 定量结果
定量比较结果显示在表1~3中。实验对比了本文系统与DS-SLAM在数据集五个序列中的实验结果,评价指标是均方根误差(Root Mean Squared Error, RMSE)、平均误差(Mean)、中值误差(Median)和标准偏差(Standard Deviation, S.D.)。其中:均方根誤差(RMSE)描述估计值与真实值之间的偏差,因此值越小,代表的系统估计的轨迹越接近于真实值;平均误差反映所有估计误差的平均水平;中值误差代表所有误差的中等水平;标准偏差(S.D.)反映系统轨迹估计的离散程度。这几种客观评价算法表现出系统估计的轨迹与真实值之间的差距,反映了系统的稳定性和可靠性。
从表1~3可看出,相对于DS-SLAM,本文SLAM系统可以使大多数高动态序列的性能得到提高,在动态程度较高的序列freiburg3_walking_xyz和freiburg3_walking_rpy中,提升明显。结果表明,本文SLAM系统可以提高SLAM系统在高动态场景中的鲁棒性和稳定性。但是,在低动态序列中,例如fr3_sitting_static序列,性能的提高并不明显,原因是DS-SLAM可以处理低动态场景并获得良好性能,因此可以改进的空间有限。
2.2.2 定量结果
图3~4显示了在高动态freiburg3_walking_rpy序列中,ORB-SLAM2、DS-SLAM和本文SLAM系统的ATE和RPE图。图5显示了ORB-SLAM2、DS-SLAM和本文系统在freiburg3_walking_rpy上的ATE对比。可看出,本文SLAM系统的绝对轨迹误差和相对位姿误差均有不同程度的减少。
3 结语
动态物体的存在对于轨迹和位姿的估计影响较大,对动态物体剔除以减小轨迹和位姿误差很有必要。为此,本文改进系统使用了分割准确率高的PSPNet作为分割网络,用以分类场景中的物体,对于场景中的动态物体上的动态特征点予以剔除,利用稳定的静态特征点进行动态场景下的运动估计,继而完成语义地图的构建,并通过实验对比验证了本文系统在减小轨迹和位姿误差上的优势。在接下来的工作中,将研究运动模糊对动态特征点的影响并优化。
参考文献(References)
[1] CADENA C, CARLONE L, CARRILLO H, et al. Past, present, and future of simultaneous localization and mapping: toward the robust-perception age[J]. IEEE Transactions on Robotics, 2016, 32(6): 1309-1332.
[2] LI X, AO H, BELAROUSSI R, et al. Fast semi-dense 3D semantic mapping with monocular visual SLAM[C]// Proceedings of the IEEE 20th International Conference on Intelligent Transportation Systems. Piscataway: IEEE, 2017: 385-390.
[3] McCORMAC J, HANDA A, DAVISON A, et al. SemanticFusion: dense 3D semantic mapping with convolutional neural networks[C]// Proceedings of the 2017 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2017: 4628-4635.
[4] KIM D H, KIM J H. Effective background model-based RGB-D dense visual odometry in a dynamic environment[J]. IEEE Transactions on Robotics, 2016, 32(6): 1565-1573.
[5] SUN Y, LIU M, MENG M Q. Improving RGB-D SLAM in dynamic environments: a motion removal approach[J]. Robotics & Autonomous Systems, 2017, 89: 110-122.
[6] YU C, LIU Z, LIU X, et al. DS-SLAM: a semantic visual SLAM towards dynamic environments[C]// Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2018: 1168-1174.
[7] BADRINARAYANAN V, KENDALL A, CIPOLLA R. SegNet: a deep convolutional encoder-decoder architecture for scene Segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495.
[8] LI S, LEE D. RGB-D SLAM in dynamic environments using static point weighting[J]. IEEE Robotics and Automation Letters, 2017, 2(4): 2263-2270.
[9] BESCOS B, FCIL J M, CIVERA J, et al. DynaSLAM: tracking, mapping, and inpainting in dynamic scenes[J]. IEEE Robotics and Automation Letters, 2018, 3(4): 4076-4083.
[10] MUR-ARTAL R, TARDS J D. ORB-SLAM2: an open-source SLAM system for monocular, stereo, and RGB-D cameras[J]. IEEE Transactions on Robotics, 2017, 33(5): 1255-1262.
[11] ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network[C]// Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6230-6239.
[12] STURM J, ENGELHARD N, ENDRES F, et al. A benchmark for the evaluation of RGB-D SLAM systems[C]// Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2012: 573-580.
[13] SHELHAMER E, LONG J, DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis, 2017, 39(4): 640-651.
[14] JIA Y, SHELHAMER E, DONAHUE J, et al. Caffe: convolutional architecture for fast feature embedding[EB/OL]. [2019-02-10]. https://arxiv.org/pdf/1408.5093.pdf.
[15] EVERINGHAM M, van GOOL L, WILLIAMS C K I, et al. The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Resultst [EB/OL]. [2019-01-10].
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/.
