
中文文本汉语拼音自动产生系统设计方案
2019-11-14 08:17侯雨铃
软件 2019年9期
摘 要: 汉语中有1000多个多音字,正确的判断多音字并进行注音,是计算机拼音合成的难点之一。为了实现对多音字的自动识别标注,采用最大向前匹配、最大向后匹配法对词句进行分词处理。再构建条件概率表,对多音字进行整理归类。最后系统的进行注音。通过《中文拼音词典》模块、文本分词模块、《汉字条件概率表》模块、《汉字条件概率表》计算模块、自动产生文本拼音模块构成拼音自动生产系统。
关键词: 中文文本;汉语拼音;自动生产系统设计
中图分类号: TP391 文献标识码: A DOI:10.3969/j.issn.1003-6970.2019.09.033
本文著录格式:侯雨铃. 中文文本汉语拼音自动产生系统设计方案[J]. 软件,2019,40(9):144-147
Chinese Text Chinese Pinyin Automatic Generation System Design
HOU Yu-ling
(Beijing University of Technology, Beijing 100080)
【Abstract】: There are more than 1000 polyphonic words in Chinese. Correctly judging multi-sounding words and making phonetic transcriptions is one of the difficulties in computerized pinyin synthesis. In order to realize the automatic identification of multi-tone words, the maximum forward matching and maximum backward matching method are used to process word segmentation. Reconstruct the conditional probability table and classify the polyphonic words. Finally, the system performs phonetic transcription. Through the “Chinese Pinyin Dictionary” module, text segmentation module, “Chinese character condition probability table” module, “Chinese character condition probability table” calculation module, automatically generate text pinyin module to form a pinyin automatic production system.
【Key words】: Chinese text; Chinese pinyin; Automatic production system design
0 引言
在生活中,我們经常会遇到一些不认识的字或不知道准确读音的字,可是却很少有人会真正地去查它的读音。因为我们没有足够的时间去翻开字典并找到那个字,这导致有很多中国人在交流的时候会说出错误的读音。甚至在各种中文演讲的时候会出现读音不准的问题,在下面听演讲的人也会不自觉地记住错误的读音[1-5]。
例如,声调的错误在日常生活中经常发生。枸杞中的“杞”应读三声;浙江的“浙”应读四声等,这些都是人们在平时容易读错的读音。
又如,有些汉字的读音很特殊。例如,和面、和稀泥中的“和”字应该读“huò”,而不是“hé”,许多中国人都经常把这些字读错。
不光中国人为汉字的读音发难,外国人学中文的时候也会为读音发难。在国外,学中文最难的一步就是学汉字的读音,尤其是中文还有很多多音字。假如一个外国人在学一篇中文课文,而汉字的读音他一个也不知道,他难道要一个一个在字典里查吗?那么查一天也查不完。这就给他学中文的梦想造成了很大的阻碍。
虽然现在互联网上的电子词典很多,但是它们有很多常见的错误。
以上这些事情都说明了要给汉字注音的重要性。既然用人工来给汉字注音费时费力,那么给汉字注音这个工作由计算机来执行,学习效率高得多。基于人工智能的计算机查字典的速度要比人类快的多,因此设计了“中文文本汉语拼音自动产生系统”[6-10]。
1 中文文本汉语拼音自动产生系统的设计
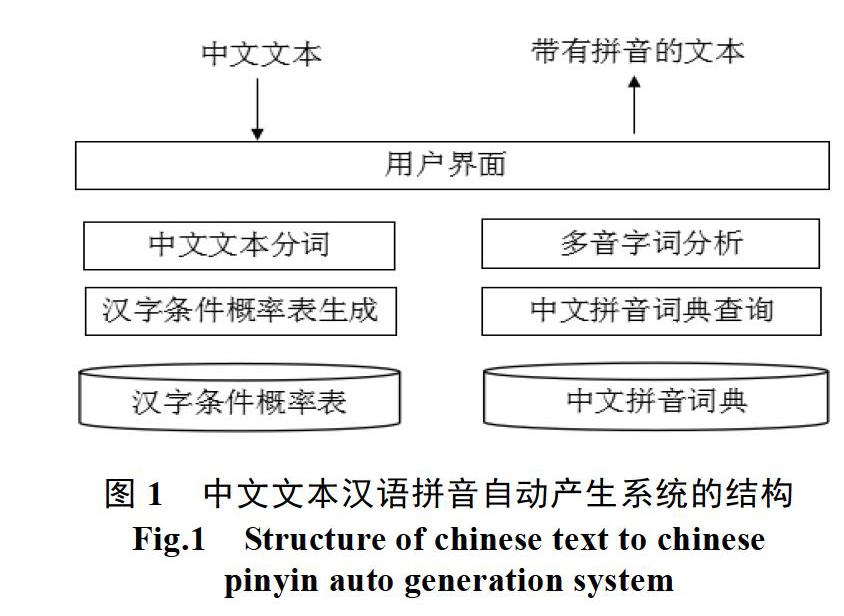
中文文本汉语拼音自动产生系统由《中文拼音词典》模块、文本分词模块、《汉字条件概率表》模块、《汉字条件概率表》计算模块、自动产生文本拼音模块所构成。
《中文拼音词典》模块为自动产生文本拼音的基础,文本分词模块对输入的中文文本进行分词,形成一个一个字和词。《汉字条件概率表》计算模块从《中文拼音词典》中计算在一个汉字后面接一个汉字的条件概率,为消除汉字的不同读音提供基础。自动产生文本拼音模块通过查《中文拼音词典》,并且使用《汉字条件概率表》,对分词后的文本进行拼音自动生成,就像人查词典一样,同时对多音字的情形,经过思考,确定多音字的准确拼音[11-13]。
图1给出了中文文本汉语拼音自动产生系统的结构。
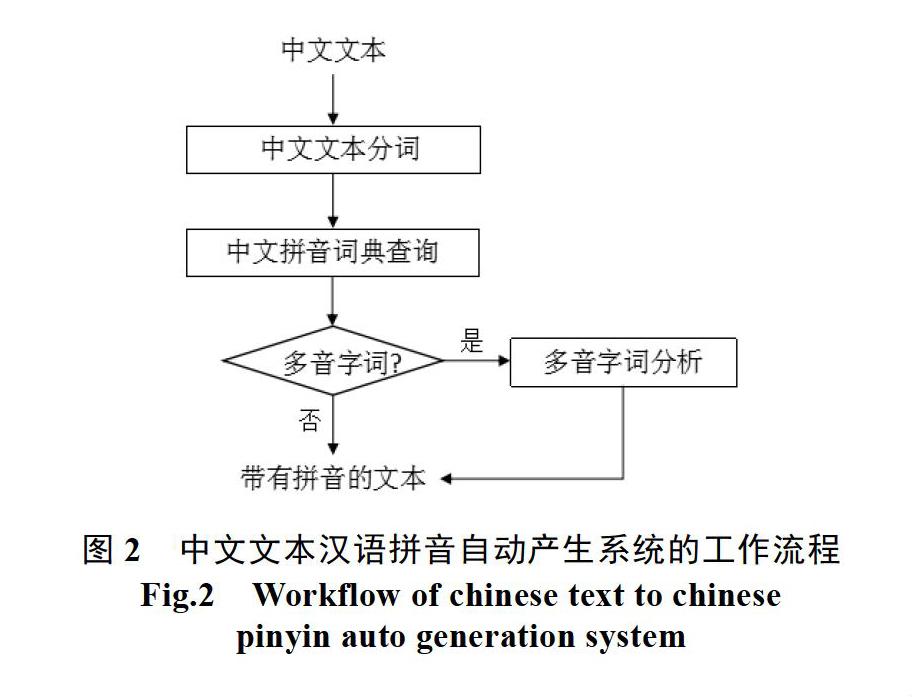
图2给出了中文文本汉语拼音自动产生系统的工作流程。
在图2中,有关“多音字词分析”的过程,如图3所示。
2 《中文拼音词典》的设计
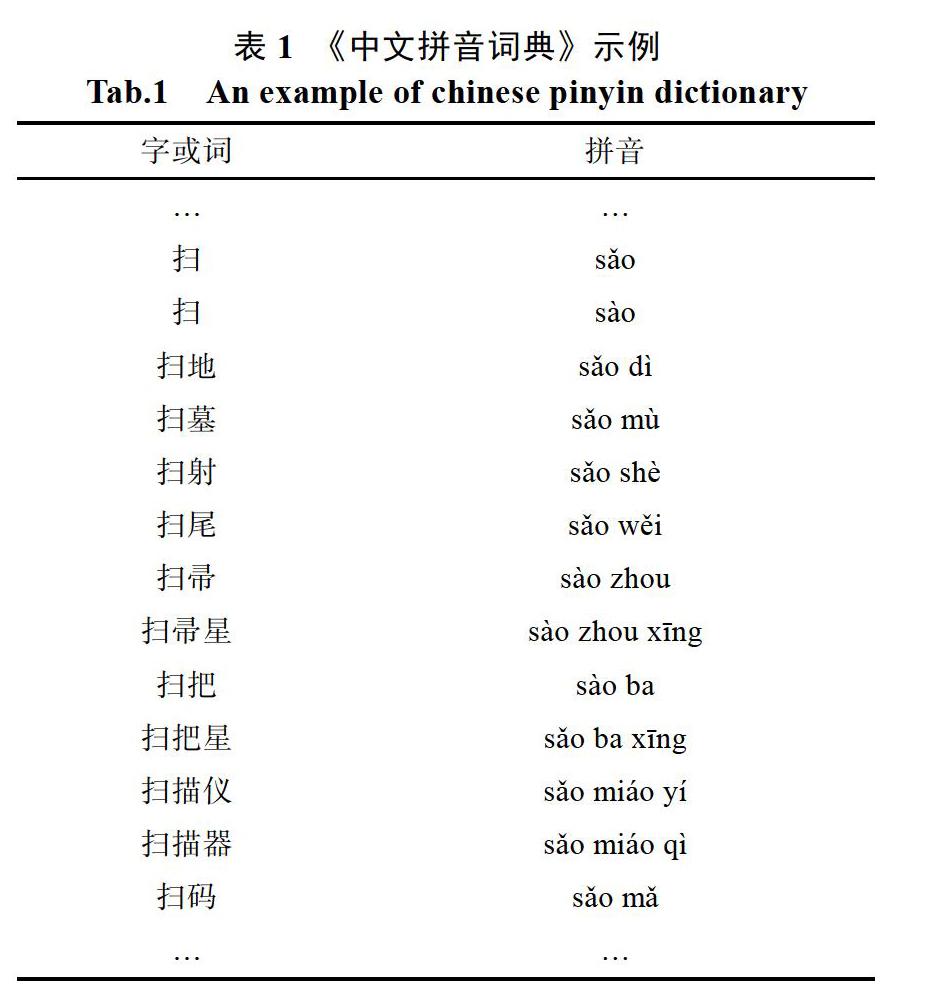
《中文拼音词典》是文本拼音自动生成的基础。对每个单字或词,给出了它们的拼音。当一个字是多音字时,词典收集了它们的所有读音。
《中文拼音词典》共分为两列。第一列是词或字,第二列是它的拼音。表1给出了词典结构和样例。
目前,《中文拼音词典》涵盖所有常见的汉字,也含有从小学到大学的各种日常词条、专业词条,共计有185285多万条。
在今后的应用中,该词典今后可以不断扩充,从而增加了本系统的应用范围。
3 中文分词方法的设计
本项目采用两种分词方法:最大向前匹配、最大向后匹配。同时本项目也采用三种策略,来选择一组分词结果:第一,当这两种方法的分词结果不一致时,采用分词个数少的那一组分词。第二,如果它们的分词结果中的分词个数一样,那么选择单字个数少的那一组分词结果。第三,如果它们的分词结果中的单字个数也一样,那么选择最大向后匹配的那组分词结果。
例如,对句子“他出席了中国人大会议”,
最大向前匹配的结果是:他 出席 了 中国人 大 会议
最大向后匹配的结果是:他 出席 了 中国 人大 会议
按照第二条策略,本项目选择了最大向后匹配的结果,因为它的单字只有1个,而最大向前匹配的结果有2个单字。
4 《汉字条件概率表》的设计和计算
有些汉字可能有多个读音,读什么音往往与它们在句子中所处的位置有关。因此,需要计算汉字与拼音之间的条件概率,形成一个程序可以使用条件概率表。
在中文文本汉语拼音自动产生系统中,《汉字词条件概率表》的格式有两种如下:
字1字2字1的拼音P 字1的拼音P的概率
词1null 词1的拼音P 词1的拼音P的概率
其中,字2是字1的后接汉字。
《汉字条件概率表》的产生是根据《中文拼音词典》进行的。过程是:
对一个词W,它由 字1字2 ...字n构成,它们对应的拼音为:拼1拼2 ...拼n。記住(字1 字2 拼1)出现1次,同样,(字2 字3 拼2)出现1次,…。
另外,在《中文拼音词典》中,可以计算出字1读成拼1的次数、字2读成拼2的次数,等等。所以,我们可以按照以下方式计算《汉字词条件概率表》中的:

对词(至少含两个汉字)而说,如果它有多个拼音,则按照以下方法计算:

5 中文拼音词典查询方法的设计
为了快速查到《中文拼音词典》的字词和对应的拼音,需要定义一种快速的数据结构。本项目采用字词到拼音向量的map方法,及map
这种结构既满足了快速定位字词,也满足标记字词的多音字的需要。
6 多音字词分析方法的设计
在从中文拼音词典中查询一个字词的拼音时,如果它具有k个拼音P1,…,Pk(k>1),那么就得判断哪个拼音为正确的。这本身是一个困难的问题。为此,我们设计了三种策略,来处理多音字词问题。
策略1:对三字或三字以上的词W,如果它有多个拼音,那么任意选一个拼音。这个策略是合理的,因为三字或三字以上的词读成不同的拼音,这个可能性非常低!
策略2:对二字词W1W2,如果它有k个拼音P11P12,P21P21,…,Pk1Pk2。如果k=1,那么直接使用W1W2的拼音P11P12;否则,选择W1W2的拼音为Pi1Pi2,其中Pi1Pi2的在《中文字词条件概率表》概率最大。
策略3:对单字W1,如果它有k个拼音P11、...、P1k(k>1),那么要考虑两种情形。
- 情形1:单字W1与后面的某个字W2构成离合词(如,“和了一团面”)。那么采用策略2,按照二字词W1W2来确定W1和W2的拼音。
- 情形2:单字W1不与后面的任何字构成离合词。此时,假设W1在句子中的后面的一个字是W2,那么查询《中文字词条件概率表》,就可以找到W1后接W2中概率最大的那个W1的拼音P,用它作为句子中W1的拼音。
根据上述策略,本项目采取的多音字分析的工作流程如图3所示。
7 文本拼音自动生成效果的评估方案设计
为了判断中文文本汉语拼音自动产生系统的效果,需要挑选一些课文进行测试。可以挑选小学五年级语文课本上的几篇课文,经过中文文本汉语拼音自动产生系统计算后,检查哪些自动生产的拼音是正确的,哪些是错误的,然后计算出正确的比例是多少。
在本项目中,测试课文应该在1000字左右。
8 文本拼音自动生成的效果示例
走[zǒu] 出门[chū mén],就[jiù] 与[yǔ] 微风[wēi fēng] 撞[zhuàng] 了[le] 满怀[mǎn huái],风[fēng] 中[zhōng] 含[hán] 着[zhe] 露水[lù shuǐ] 和[hé] 栀子花[zhī zi huā] 气息[qì xī] 的[de] 微风[wēi fēng] 撞[zhuàng] [le] 个[gè] 满怀[mǎn huái]。早晨[zǎo chén],好[hǎo] 清爽[qīng shuǎng] !心里[xīn lǐ] 的[de] 感觉[gǎn jué] 好[hǎo] 清爽[qīng shuǎng]。
不[bù] 坐车[zuò chē],不[bù] 邀[yāo] 游伴[yóu bàn],也[yě] 不带[bù dài] 什么[shén me] 礼物[lǐ wù],就[jiù] 带[dài] 着[zhe] 满怀[mǎn huái] 的[de] 好心情[hǎo xīn qíng],踏[tà] 一[yī] 条[tiáo] 幽径[yōu jìng],独[dú] 自去[zì qù] 访问[fǎng wèn] 我的[wǒ de] 朋友[péng you]。
9 结论
本文介绍了一种中文文本汉语拼音自动产生设计方案。通过运用采用最大向前匹配、最大向后匹配法对词句进行分词处理,再对条件概率表的拼音系统匹配,完成了注音。经过实际测试,注音结果的正确率良好。
参考文献
[1] 基于局部上下文特征的组合的中文真词错误自动校对研究[J]. 刘亮亮, 曹存根. 计算机科学 2016, 43(12), 30-35. DOI: 10.11896/j.issn.1002-137X.2016.12.005.
[2] Kuckich K. Techniques for automatically correcting words in text[J]. ACM Computing Surveys (CSUR), 1992, 24(4): 377-439
[3] 施得勝, 王良志, 陈志达, 等. 基于统计的中文基于统计的中文错字侦测法[J]. 电脑与通讯, 1992, 8: 19-26.
[4] 施恒利, 刘亮亮, 王石等. 汉字种子混淆集的构建方法研究[J]. 计算机科学, 2014, 41(8): 229-232, 253
[5] 张照煌. 中文错别字自动订正方法初探[J]. Comm un i cations of C0LIPS, 1994, 4(2): 143-149
[6] 刘亮亮, 王石, 王东升, 等. 领域问答系统中的文本错误自动发现方法[J]. 中文信息学报, 2013, 27(3): 77-83.
[7] 黄炳羽. 对未来中文信息处理拼音文字性编码方案的初步设计[J]. 西安文理学院学报(自然科学版), 2006, 9(4): 77-81.
[8] 赵博轩, 房宁, 赵群飞, 等. 利用拼音特征的深度学习文本分类模型[J]. 高技术通讯: 中文, 2017, 27(7): 596.
[9] 卓利艳. 字词级中文文本自动校对的方法研究[D]. 郑州大学, 2018.
[10] 赵瑛, 田宇, 李响. 汉语拼音移动学习软件设计开发研究[J]. 教师博览(科研版), 2017(5): 11.
[11] 基于多种上下文信息的联机手写中文文本识别方法及系统实现[D]. 华南理工大学, 2017.
[12] ChurchKW, GalewA Probability scoring for spelling correction[J]. Statistics and Computing, 1991, 1(2): 93-103.
[13] Islam A, Inkpen D. Real-word spelling correction using Google WebIT3-grams[C]. Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing. Volume3. 2009: l241-1249.
猜你喜欢
小学生学习指导(低年级)(2022年10期)2022-11-05
小学生学习指导(低年级)(2021年11期)2021-11-30
小学生学习指导(低年级)(2021年10期)2021-11-01
校园英语·月末(2021年13期)2021-03-15
作文周刊·小学一年级版(2016年1期)2016-08-12
作文大王·低年级(2016年3期)2016-03-11
创新作文(1-2年级)(2015年3期)2015-04-10
语文知识(2014年5期)2014-02-28
外语学刊(2011年3期)2011-01-22
