
基于生成模型的古壁画非规则破损部分修复方法
2019-11-13 07:13:08温利龙钱文华
图学学报 2019年5期
温利龙,徐 丹,张 熹,钱文华
基于生成模型的古壁画非规则破损部分修复方法
温利龙,徐 丹,张 熹,钱文华
(云南大学信息学院,云南 昆明 650500)
为了更好地保存和修复珍贵的古代壁画艺术,在现有的人工修复技术之上,结合数字虚拟修复方法,使用深度学习中生成网络的方法自动生成壁画缺失部分,可以有效地提高修复效率,降低修复成本。用于修复的网络整体上是一个自编码器结构,编码器将待处理壁画图像和破损部分对应的掩膜作为输入,进行特征提取。解码器将编码器得到的特征图通过反卷积的方法恢复到原来尺寸,完成修复,自动将破损区域进行补全。同时,通过对待修复壁画进行分块修复再拼接的方法实现了对任意尺寸壁画的修复。与其他数字壁画修复方法相比,该方法更加通用,不受壁画种类和破损情况的限制。在一般破损的壁画上可以得到超过目前先进水平的修复效果,并且在人眼无法辨识有效信息的大面积破损的壁画上,仍可以恢复得到有完整语义的图像。
壁画修复;卷积神经网络;生成模型;自编码器
壁画作为一种古老的绘画形式,有着独特的美学价值和研究价值。但是由于其年代久远,不可避免地受到不同程度的自然因素和人为因素的破坏,其修复工作一直是古文化研究领域重要的研究课题。传统人工修复方法依靠科研工作者丰富的经验和绘画技术,但耗时较长并且对修复者有极高的要求。随着计算机技术的发展,数字图像处理技术为该领域提供了强有力的工具。通过对壁画的进行数字化采集和数字修复,可以对实体修复提供具有指导意义的修复方案,降低了修复难度,提高了修复效率,减少了对人力的依赖。
数字图像修复技术利用破损区域以外的图像已知信息和图像本身的风格信息,推测出破损区域的图像内容,再填补回原图像达到修复的目的。传统的数字图像修复技术大多依赖单张图片中的已知信息,使用扩散或块匹配的方法进行修复,在实际应用中往往无法完全满足需求。近年来,深度学习在计算机视觉和图像处理领域的研究不断取得进步,使用海量图片对网络进行训练,使得训练好的模型可以具备大量的先验知识,为图像修复提供了另外一种思路。尤其是对抗生成网络[1]的提出,在图像修复、补全领域取得了很好的效果。
1 相关工作
传统的数字图像修复方法根据待修复区域的大小可以分为2类:①针对较小的破损区域使用信息扩散方法,将已知区域的信息扩散至破损区域达到修复的目的[2-5];②则是针对较大缺损块的合成匹配方法[6-7]。针对单幅图像可能不存在可匹配块的情况,SIMAKOV等[8]将匹配块的搜索范围扩大到了单张图片以外,但是其计算量极大,在实际应用中很难实行。BARNES 等[9]针对此问题提出了一种快速邻域算法来加速块搜索的过程,很大程度上解决了计算量过大的问题。
在壁画修复领域,PEI等[10]针对中国古壁画使用马尔科夫随机域模型对图像进行色彩增强和纹理合成的方法进行修复;ZITOVÁ和FLUSSER[11]则在壁画修复过程中结合了化学分析的方法;WANG等[12]专门针对古壁画中人脸破损的情况提出了语义学习框架进行修复。
以上方法在图像本身有较好的结构信息或者破损面积很小的情况下(如当壁画的破损区域为划痕、裂缝),可以取得很好的效果,但是无法处理高层次的语义信息并且当缺失部分过大或者缺失信息存在唯一性时,无法进行很好地修复。与之对应的深度学习方法,则有较好的解决方案。YEH等[13]采用了一种和块匹配相似的思路,不直接在图像中寻找相似图块,而是将图像通过编码器之后寻找最接近的隐空间向量,并解码恢复为填充图块达到修复的目的。ULYANOV等[14]进一步证明了使用单幅图片结合神经网络的方法在破损区域较小时可以取得很好的修复效果。
早期的神经网络修复方法(如直接使用卷积神经网络的方法[15])对破损进行修补,将待修复的区域视为图像噪声,在破损区域较细小(如文字的遮挡等)情况下取得了很好的效果。PATHAK等[16]针对图像中间区域的缺失使用对抗生成的方法生成具有语义信息的图块对破损图像进行填充。IIZUKA等[17]在此基础上添加了全局和局部鉴别器,分别对修复得到的整幅图像和破损对应区域进行损失计算,得到了比之前更好的效果。同样基于文献[16]的工作,YANG等[18]将非破损区域的纹理信息进行了提取并应用到修复区域中,使得修复图像在纹理上有了更好的一致性。而YU等[19]则是使用了一个精炼网络对PATHAK的结果进行再次处理来得到更为精细的结果,并取代修复完成后的边缘处理过程。LIU等[20]使用非规则化卷积的操作,实现了使用卷积神经网络的方法对非规则化破损区域的修复。NAZERI等[21]首先利用生成模型得到缺失部分的边缘信息,并将得到的边缘信息和图像一同送入修复网络进行重建。LI 等[22]专门针对人脸图片进行训练,并结合了分割网络对重建的人脸进行分割计算损失来确保生成的人脸图片在语义上正确,证明了专门针对某一种类图片进行训练和网络设计可以让模型较好地学习到该领域的语义信息,尤其在人脸领域可以取得很好的效果。但是在壁画修复领域,现存的壁画在数量上相对较少,并且不同种类的壁画之间风格和色彩等相差很大,无法专门建立相应数据集进行训练,本文训练过程只使用了普通图片数据集,让网络充分学习像素间关系。实验结果证明在训练集不使用壁画数据的情况下,训练得到的模型依然能在壁画修复中取得较好的效果。
使用神经网络进行图像风格迁移[23-24]的成功对图像修复带来了很大的启发,尤其是风格损失和内容损失相结合的方法,可以使得生成的修复块与原图的拼接更加自然。YANG等[25]根据此思路提出了多尺度的网络合成修复方法,得到的修复区域不仅在纹理结构上与原图很接近,并且在内容和风格上也有很好的一致性。
本文借鉴了风格迁移中损失函数的设计,同时与对抗损失相结合,提出了一个基于自编码器结构的图象修复网络,并且针对壁画破损部分多为非规则的脱落、裂纹等形状设计了相应掩膜用于模型训练。
2 方法介绍
本文网络模型整体上是一个典型的自编码器结构,分为编码和解码2部分,网络的数据流如图1所示。其中编码部分将待处理图像和掩膜图像进行编码得到一个中间特征,解码部分对进行解码执行一个和编码器相反的操作恢复得到完整的图像。为了得到更好的训练效果,本文的编码解码部分采用了类似UNet[26]的网络结构对其中间各层特征进行了拼接融合。主要贡献有:①模型训练时充分考虑到壁画破损多为不规则裂缝与脱落,并按此设计了任意形状的掩膜;②在损失函数的计算中将所有的损失函数的计算都分为整体损失和局部损失2部分;③采用分块修复的方法实现了对任意尺寸壁画的修复。
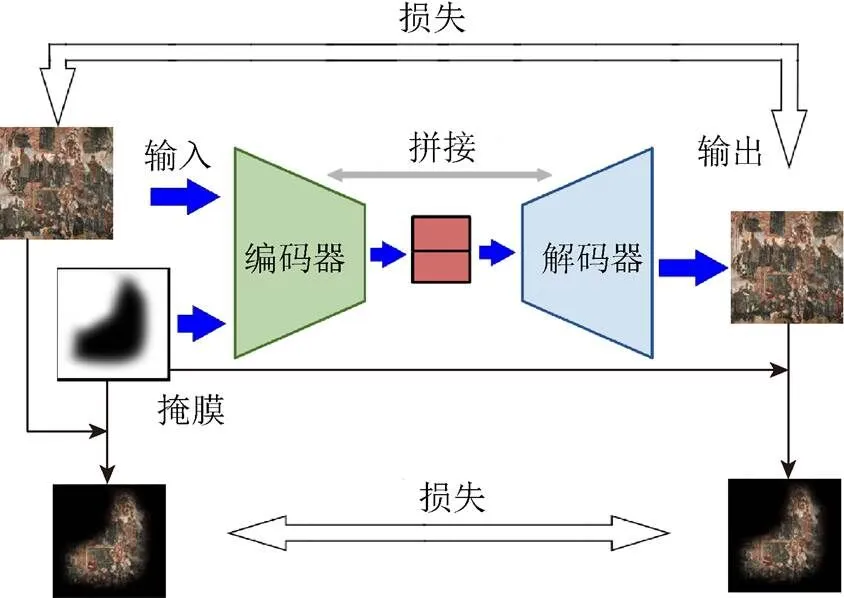
图1 网络总体结构图(E表示Encoder,D表示Decoder)
2.1 编码器
编码器部分采用了卷积神经网络的结构,将掩膜与待处理图像同时作为网络的输入。掩膜用于控制输入图像的处理过程,实现对非规则区域的处理。在一个卷积窗口的处理中,卷积结果计算式为
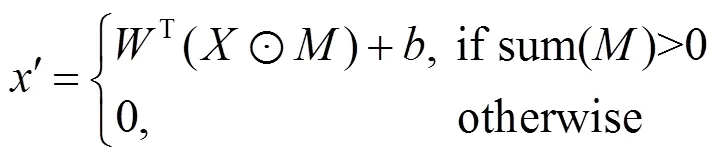
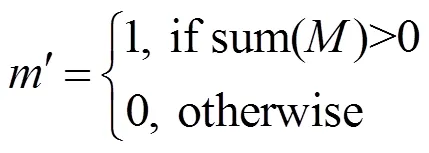
收缩方法同样通过卷积操作实现,如果在一个卷积窗口中,该窗口掩膜像素值之和大于0,则置该窗口的掩膜为1,否则仍置为0。通过每次在卷积过程中收缩掩膜的方法,在经过几层卷积操作之后,最终掩膜将会全部置为1,其过程如图2所示。可以看出,掩膜的大小随着每层卷积操作不断缩小,最终编码器的输入为2部分,一部分时输入图像的特征图,另一部分则是全为1的掩膜处理图。
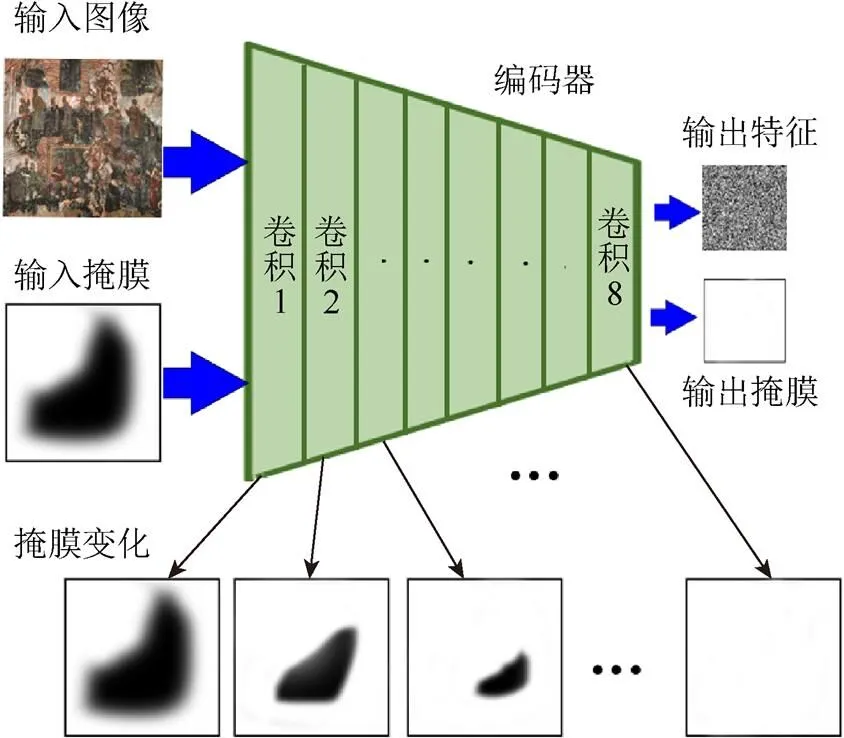
图2 编码器对掩膜的处理过程
2.2 解码器
解码器采用了与编码器相反的操作,通过对编码器处理得到的特征进行反卷积的操作,将特征恢复到与输入图像相同大小。处理过程如图3所示。其中反卷积的操作由上采样和卷积两部分操作组成,最后一层不再输入掩膜图像,而是将最后一层反卷积得到的图像进行传统的卷积操作得到最终图像。在这一部分的处理中,掩膜虽然一直随着输入特征一起处理,但实际上,全1的掩膜并不会对解码器的输入有任何影响,之所以同时输入网络是为了保持解码器与编码器在结构和特征数值上的对应关系,便于其间特征的拼接融合。最后一个卷积层有3个大小为1的卷积核,对图像尺寸不产生影响,只是将图像恢复到RGB三通道。

图3 解码器结构图
2.3 损失函数
损失函数分为生成过程中的对抗损失和整体的生成图像和输入图形间的风格损失、内容损失和总变分损失。所有损失在计算过程中充分考虑生成的整体图像和掩膜对应的缺失部分图像。为了使对抗损失更加适应本文的应用场景,本文使用式(3)和式(4)的对抗损失的设计,表示分别对生成的整体图像和掩膜对应部分计算对抗损失,即
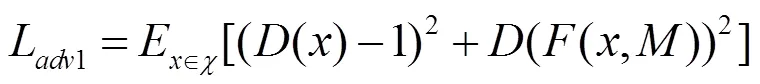
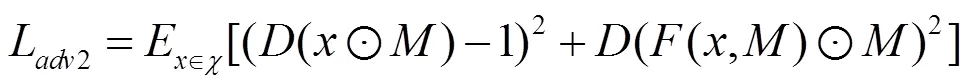
其中,函数为整个编码解码网络;和分别为输入的图像和掩膜;为一个简单的鉴别网络。
内容重建损失的计算如式(5)和式(6),分为2个部分:一部分是掩膜对应图像的重建损失,另一部分是掩膜之外图像的重建损失,即

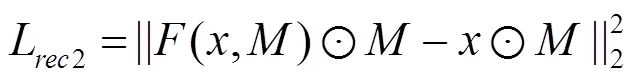
为了使生成的缺失部分和原图像风格一致,在损失函数中同时加入风格迁移中的风格损失和总变分损失。其中,风格损失的计算依赖于从预训练好的卷积神经网络中提取到的特征与葛郎姆矩阵,其定义如式(7),采用VGG16[27]作为特征提取网络,其中为网络的第层。

风格损失同样也分为2个部分:一部分对应生成的完整图像,另一部分用于计算掩膜对应的缺损位置生成的图像,其计算公式为


为了达到平滑性的需求,本文同时使用了总变分损失,其计算如公式为

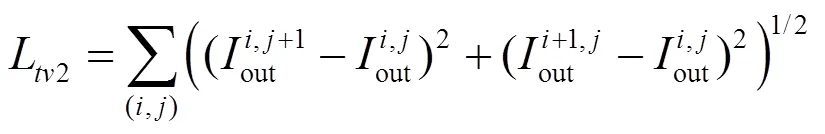
最终网络的整体损失函数计算公式为

其中,各个损失的权重是在多次实验测试中得到的效果较好的一组权重值。
2.4 掩膜设计
针对数字壁画图像中破损部分形状的特点,为了达到更好的修复效果,需要对训练过程中使用的掩膜进行专门的设计。
本文使用的掩膜图像是通过使用自适应阈值分割的方法对收集到的古壁画图像进行粗略的破损区域提取得到,并将提取得到的掩膜图像进行分割、旋转、对称变换,以及膨胀腐蚀等形态学操作进行扩充。但是由于收集到的壁画图像有限,尽管经过大量的变换操作,仍无法得到与大规模的训练数据集的数据规模相匹配的掩膜数量。因此,在训练过程中,每次加载掩膜图像时都使用自动化脚本随机在掩膜图像上添加圆圈和线条的组合。图4展示了一些掩膜图像,图4(a)~(f)为从壁画图像中得到的原始掩膜,图4(g)~(i)为每次训练时在原始掩膜上添加随机绘制形状后得到的掩膜图像。

图4 使用到的掩膜图像示例((a)~(f)为从壁画中得到的原始掩膜图像示例,(g)~(i)为每次训练时在原始掩膜上随机绘制后得到的掩膜图像示例)
2.5 分块修复
现实中,待修复的数字壁画尺寸是任意的,但是神经网络有着固定的输入大小。为为,本文采用了对输入图像分块处理再拼接的方法,其处理如图5所示。将大于512×512的图片进行分割,长、宽不足512的部分进行空白填充。然后将各个图块分别输入网络中进行修复,最后再将修复好的图块拼接在一起得到最终完整的修复图,在此过程中,掩膜也随之一起进行分割。
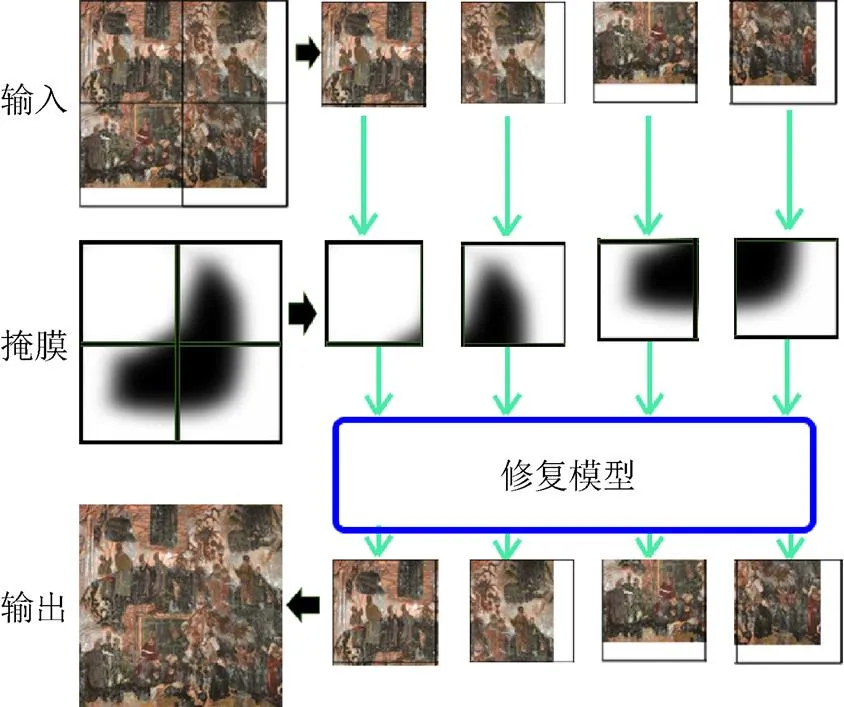
图5 分块修复拼接示意图
3 修复结果分析
使用本文提出的模型对一些现存的数字壁画进行修复,取得了较好的效果。图6显示了在裁剪的敦煌壁画上进行测试的结果。可以看出,在壁画存在轻微破损和一般破损时,很容易修复得到完整的结果图,甚至在严重破损的情况下,该模型也可以得到一个在风格和语义上与原图接近的结果。

图6 在敦煌壁画上的测试结果
针对一些大面积块的破损,本文方法也得到了较好的修复效果,如图7所示。

图7 在较大面积破损情况下修复结果
本文针对不同类型、不同破损情况的真实壁画图像进行修复,得到的结果如图8所示。
从修复结果中可以看出,使用本文提出的模型在各种古壁画破损情况下均可以取得很好的效果,掩膜所覆盖的非规则破损区域均可以通过该生成模型得到在纹理结构和语义上都与原图相符的修复结果,证明了本文方法的有效性。

图8 针对不同风格、不同破损类型的古壁画的修复结果
为了进一步证明本文方法在古壁画修复上的优越性,本文与目前在非规则破损区域修复上效果最好的模型[20]进行了比较,比较结果如图9所示。其中,掩膜2是掩膜1经过膨胀操作扩大以后得到的掩膜。

图9 与其他方法进行对比
可以看出,在使用相同大小的掩膜1的情况下,本文方法可以得到一个较好的修复结果。而对比方法中则会因为掩膜较小而出现修复得到的区域色彩明显浅于周围区域的问题,在适度扩大掩膜区域之后该问题才会得到解决。最终得到的结果与本文方法相比在细节上也较为模糊。本文方法在利用相同的周围信息的情况下可以得到更好的修复结果,并且修复结果更为清晰。
4 结 论
本文使用深度学习的方法对壁画进行虚拟修复。通过使用生成模型的方法对壁画缺损部分进行生成,填充到破损区域达到修复的目的,取得了较好的修复效果,并且与之前的方法相比更为通用,不受破损情况的限制,在损失信息极大的情况下仍可以恢复出一个语义上完整的结果图,并且可以利用较少的周围信息就可以得到较好的结果。同时该修复结果说明了在修复任务中不需要特定领域的图像参与训练来提高这一领域相关图片的修复效果。
[1] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [C]//Proceedings of the 26th International Conference on Neural Information Processing Systems. Goslar: Eurographics Association Press, 2014: 2672-2680.
[2] SHEN J H, CHAN T F. Mathematical models for local non-texture inpainting [J]. SIAM Journal on Applied Mathematics, 2002, 62(3):1019-1043.
[3] CHAN T F, SHEN J H. Nontexture inpainting by curvature-driven diffusions [J]. Journal of Visual Communication and Image Representation, 2001, 12(4): 436-449.
[4] BALLESTER C, BERTALMIO M, CASELLES V, et al. Filling-in by joint interpolation of vector fields and gray levels [J]. IEEE Transactions on Image Processing, 2001, 10(8):1200-1211.
[5] BERTALMIO M, SAPIRO G, CASELLES V, et al. Image inpainting [J]. Siggraph, 2005, 4(9): 417-424.
[6] EFROS A A, FREEMAN W T. Image quilting for texture synthesis and transfer [C]//Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques-SIGGRAPH’01, Not Known. New York: CAM Press, 2001: 341-346.
[7] EFROS A A, LEUNG T K. Texture synthesis by non-parametric sampling [C]//Proceedings of the 7th IEEE International Conference on Computer Vision, New York: IEEE Press,1999: 1033-1038.
[8] SIMAKOV D, CASPI Y, SHECHTMAN E, et al. Summarizing visual data using bidirectional similarity [C]// 2008 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2008: 1-8.
[9] BARNES C, GOLDMAN D B, SHECHTMAN E, et al. PatchMatch: A randomized correspondence algorithm for structural image editing [J]. ACM Transactions on Graphics, 2009, 28(3): 1-11.
[10] PEI S C, ZENG Y C, CHANG C H. Virtual restoration of ancient Chinese paintings using color contrast enhancement and lacuna texture synthesis [J] IEEE Transactions on Image Processing, 2004, 13(3): 416-429.
[11] ZITOVÁ B, FLUSSER J. Image registration methods: A survey [J]. Image and Vision Computing, 2003, 21(11): 977-1000.
[12] WANG Q, LU D M, ZHANG H X. Virtual completion of facial image in ancient murals [C]//2011 Workshop on Digital Media and Digital Content Management. New York: IEEE Press, 2011: 203-209.
[13] YEH R, CHEN C, LIM T Y, et al. Semantic image inpainting with perceptual and contextual losses [CP/OL]. (2016-02-26). [2019-05-02]. https://arxiv.org/abs/ 1607.07539.
[14] ULYANOV D, VEDALDI A, LEMPITSKY V. Deep image prior [C]//2018 Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 9446-9454.
[15] KÖHLER R, SCHULER C, SCHÖLKOPF B, et al. Mask-specific inpainting with deep neural networks [M]// Lecture Notes in Computer Science. Heidelberg: Springer, 2014: 523-534.
[16] PATHAK D, KRAHENBUHL P, DONAHUE J, et al. Context encoders: Feature learning by inpainting [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 2536-2544.
[17] IIZUKA S, SIMO-SERRA E, ISHIKAWA H. Globally and locally consistent image completion [J]. ACM Transactions on Graphics, 2017, 36(4): 1-14.
[18] YANG C, LU X, LIN Z, et al. High-resolution image inpainting using multi-scale neural patch synthesis [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 6721-6729.
[19] YU J H, LIN Z, YANG J M, et al. Generative image inpainting with contextual attention [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 5505-5514.
[20] LIU G, REDA F A, SHIH K J, et al. Image inpainting for irregular holes using partial convolutions [M]// Computer Vision- ECCV 2018. Heidelberg: Springer, 2018: 85-100.
[21] NAZERI K, NG E, JOSEPH T, et al. EdgeConnect: Generative image inpainting with adversarial edge learning [CP/OL]. (2019-01-11). [2019-05-02]. https:// arxiv.org/abs/1901.00212.
[22] LI Y J, LIU S F, YANG J M, et al. Generative face completion [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 3911-3919.
[23] CHEN T Q, SCHMIDT M. Fast patch-based style transfer of arbitrary style [CP/OL]. (2016-12-13). [2019-05-02]. https://arxiv.org/abs/1612.04337.
[24] LI C, WAND M. Combining Markov random fields and convolutional neural networks for image synthesis [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 2479-2486.
[25] YANG C, LU X, LIN Z, et al. High-resolution image inpainting using multi-scale neural patch synthesis [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 6721-6729.
[26] RONNEBERGER O, FISCHER P, BROX T. U-Net: Convolutional networks for biomedical image segmentation [M]//Lecture Notes in Computer Science. Heidelberg: Springer, 2015: 234-241.
[27] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [CP/OL]. (2014-09-04). [2019-05-02]. https:// arxiv.org/abs/1409.1556.
The Inpainting of Irregular Damaged Areas in Ancient Murals Using Generative Model
WEN Li-long, XU Dan, ZHANG Xi, QIAN Wen-hua
(School of information Science and Engineering, Yunnan University, Kunming Yunnan 650500, China)
In order to preserve and restore the precious ancient mural art in a better way, based on the existing manual restoration technology, the digital virtual restoration method can effectively improve the efficiency of restoration and reduce the costs of restoration. In this aspect, using the generative network method in deep learning to automatically generate the missing part of the murals for completion and restoration can achieve good results. The network used for restoration is basically an autoencoder. The encoder takes the murals images to be processed and the mask corresponding to the damaged part as the input for feature extraction. The decoder will restore the feature chart obtained from the encoder to its original size by deconvolution, which completes the restoration. In this process, the damaged area will be completed automatically. At the same time, separating the murals into different pieces, restoring and reassembling them later makes it achievable to restore murals of any size. Compared with other digital mural restoration methods, the one proposed in the present study is applicable to more general purposes and not limited by the type of murals and their damage. In the generally damaged murals, this method can achieve a better restoration effect compared with the existing level. Moreover, even for a large-area damaged mural where the naked eyes cannot identify effective information, this method can nevertheless restore it to one containing images of full meaning.
murals repainting; convolutional neural network; generating model; autoencoder
TP 391
10.11996/JG.j.2095-302X.2019050925
A
2095-302X(2019)05-0925-07
2019-01-06;
2019-04-19
温利龙(1993-),男,山西吕梁人,硕士研究生。主要研究方向为图像处理、计算机视觉等。E-mail:wenlilong@mail.ynu.edu.cn
徐 丹(1968-),女,江苏无锡人,教授,博士,博士生导师。主要研究方向为多媒体信息处理、计算机视觉、模式识别等。 E-mail:danxu@ynu.edu.cn
猜你喜欢
读者·原创版(2022年8期)2022-11-09 10:25:33
导航定位学报(2022年5期)2022-10-13 08:35:28
中国体视学与图像分析(2021年3期)2021-11-24 02:20:44
数学小灵通(1-2年级)(2020年5期)2020-06-24 05:48:04
收藏界(2018年5期)2018-10-08 09:10:54
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
制造技术与机床(2017年10期)2017-11-28 05:20:18
学与玩(2017年6期)2017-02-16 07:07:26
电子设计工程(2017年20期)2017-02-10 03:39:29
科技资讯(2016年21期)2016-05-30 18:49:07
