
基于Spark的分布式机器人强化学习训练框架
2019-11-13 07:16黄增强徐建斌马新强
图学学报 2019年5期
方 伟,黄增强,徐建斌,黄 羿,马新强
基于Spark的分布式机器人强化学习训练框架
方 伟1,2,黄增强3,徐建斌4,黄 羿1,5,马新强1,5
(1. 浙江大学智能系统与控制研究所,浙江 杭州 310027;2. 淮北职业技术学院计算机科学技术系,安徽 淮北 235000;3. 杭州电子科技大学计算机学院,浙江 杭州 310018;4. 国家电网浙江省电力有限公司物资分公司,浙江 杭州 310000;5. 重庆文理学院大数据智能计算与可视化研究所,重庆 402160)
强化学习能够通过自主学习的方式对机器人难以利用控制方法实现的各种任务进行训练完成,有效避免了系统设计人员对系统建模或制定规则。然而,强化学习在机器人开发应用领域中训练成本高昂,需要花费大量时间成本、硬件成本实现学习训练,虽然基于仿真可以一定程度减少硬件成本,但对类似Gazebo这样的复杂机器人训练平台,仿真过程工作效率低,数据采样耗时长。为了有效解决这些问题,针对机器人仿真过程的平台易用性、兼容性等方面进行优化,提出一种基于Spark的分布式强化学习框架,为强化学习的训练与机器人仿真采样提供分布式支持,具有高兼容性、健壮性的特性。通过实验数据分析对比,表明本系统框架不仅可有效提高机器人的强化学习模型训练速度,缩短训练时间花费,且有助于节约硬件成本。
机器人;强化学习;Spark;分布式;数据管道
目前,大多数传统智能机器人系统都是基于精确模型的控制方法,如果实现较为精准可靠的控制性能则需要花费大量成本预先建立精准模型,且上述机器人控制模型对于未知环境输入适应性不强。强化学习与传统控制方法相比,无需建立精准模型,经由大量采样数据训练得到可行的控制模型。但是,强化学习在模型训练过程中,大量的数据采集需要通过与机器人的交互获得,在使用真实机器人进行大量数据采样时存在数据获取速度慢、损耗大等问题,特别对于类似四翼飞行器的飞行机器人,甚至会出现严重的危险状况。为了克服数据采样困难,南加州大学开发了可用于机器人强化学习的Gazebo仿真器系统,一定程度上节约了训练成本和缩短了训练时间,加快了采集数据的速度。结合强化学习进行机器人系统的训练模拟已经有较多的成功先例,如Google的AlphaGo Zero[1]、波士顿动力的Atlas[2]等。强化学习要想达到更佳的训练效果也要经过足够大量采样的训练,但是限于计算机的运算能力,训练时间成为了一个重要瓶颈,因此很多技术人员开始尝试在分布式仿真平台上进行训练,但是目前没有专门针对机器人强化学习训练的分布式处理框架作为支持,训练效果依然无法让人满意[3]。因此,在现有开源框架的基础上,本文提出一套适用于机器人强化学习的分布式训练框架系统,可实现机器人控制仿真的并行化加速[4-5]。
1 Spark分布式训练框架优化分析
2012年加州大学伯克利分校的AMP实验室开源了类Hadoop MapReduce[6-8]的通用并行框架Spark。Spark的系统架构选择了经典的一主多从结构,内存计算使其能够很好地支持普通的机器学习算法的运行,尤其是借助大量数据的训练。但是,Spark的分布式迭代作业是基于任务级别,对强化学习这种需要频繁交换参数的任务无法做到很好地支持[9]。为了解决Spark对强化学习等算法无法高效支持的问题,实现基于分布式框架Spark与流数据处理组件Flume的训练平台原型显得尤为重要。Flume NG是由Cloudera开发的一个具备高可用性、高可靠性、分布式的日志采集、聚合和传输系统[10],其支持定制数据发送,两者通常被结合用来开发具备近实时的数据管理系统,借助此特性,为实现开发一个基于Spark与Flume NG的强化学习训练平台提供了可能。
强化学习任务中参数的耦合关系相较机器学习算法更加强,所以基于MapReduce结构的Spark任务抽象方式并不适用分布式设计,因此有必要独立设计一种针对强化学习任务的分布式系统[11]。考虑到工作量的关系,基于分布式框架Spark进行后续开发能够更加快速地完成一个可用、稳定的训练框架[12]。因此,如何在MapReduce的结构上进一步抽象强化学习任务,并提供快速、可靠的服务是本文原型系统的重点考虑之处。
1.1 任务抽象方式
Spark下的机器学习算法的并行化以K-means[13-14]为例,其步骤分为:①从数据集中随机选择初始聚类中心(K-means++等算法优化对初始类中心的选择有不同处理);②计算其余所有的点到类中心的距离,并把每个点划分到离其最近的聚类中心所在的类别中去(距离公式根据需要亦有不同);③重新计算每个聚类中的所有点的均值,并将之作为新的聚类中心;④重复步骤②、③直至聚类中心不再改变。Spark的K-means的实现中将第②步进行了并行化处理,第③步将重新计算后的新的类中心数据汇总。数据集的操作均是通过弹性分布式数据集RDD来进行,而强化学习算法通过自身的经历进行自我学习,其中最重要的3个因素是状态、行为和激励参数,所以Spark简单的将任务并行以及单一的数据集并不适用于强化学习任务,有必要将Spark的抽象方式通过封装得到一种新的抽象方式,并设计一种合适的数据传递方式[15-16]。
1.2 参数交换的可靠性
并行任务中最重要的控制点是在任务出现耦合时,耦合点所需要的上一步结果必须保证其可靠性,即完整的结果。所以有必要设计一种控制机制,保证并行任务中参数传递的可靠性,有效地进行任务。
1.3 任务节点的容错处理
集群处理任务容易出现的另一个问题是存在节点失效的风险与可能性,因此失效节点的任务重置处理存在一定的必要性,确定的重置作业能力极大地简化了调试,透明的容错机制使用户无需显式的处理错误,而且允许用户使用廉价的可抢占资源(例如AWS上的spot实例),从而在公共云中运行时节省大量成本。
2 系统架构设计实现
为了让强化学习任务能够在集群上执行,针对基于Spark强化学习分布式系统优化的需求设计了强化学习任务的系统架构,如图1所示。合理的任务调度结构能够有效地提高强化学习任务在分布式框架下的执行效率。
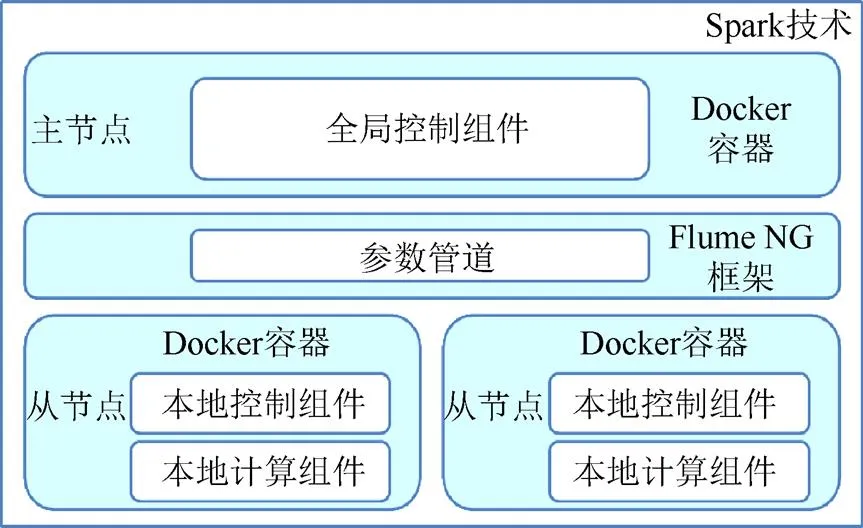
图1 系统整体架构图
(1) 全局控制组件。任务从初始化开始,负责任务的调度,参数的分发与收集,同时对节点的运行状况进行监控,并针对相应的特殊情况(如计算瓶颈)做出相应的处理。
(2) 本地控制组件。初始化后,由全局控制组件根据用户配置随机选择相应数量的节点初始化本地控制组件,负责本地任务的执行,任务所需参数的获取与简单验证,以及运行结果的上传。
(3) 本地计算组件。负责执行本地控制组件分配的任务,与环境进行交互,得到需要的反馈即激励参数。
(4) 数据管道。负责本地控制组件与全局控制组件之间参数、任务函数和运行结果的传递,需要保证一定的时效性。
2.1 编程模型的设计
Spark的主要操作有Spark SQL,Spark Streaming,MLlib,GraphX等,详细架构如图2所示。
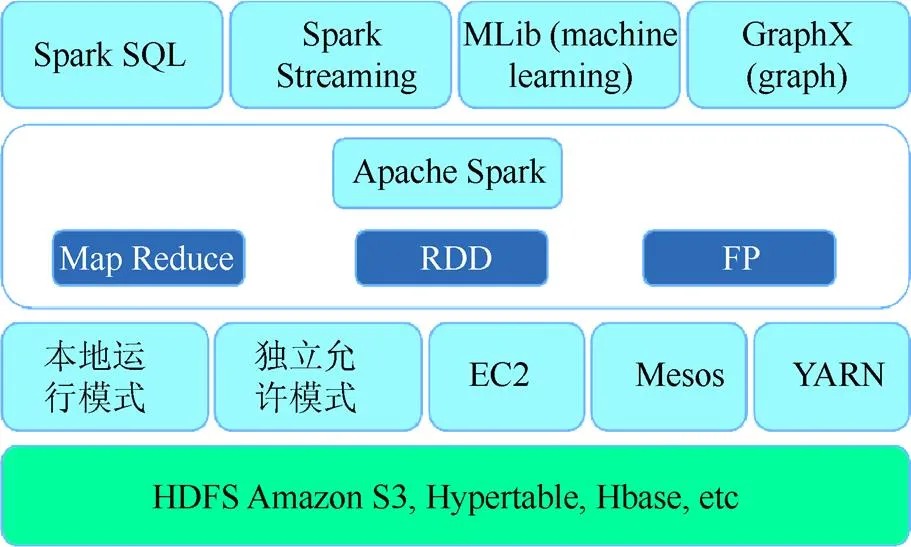
图2 Spark架构图
本系统框架根据Spark编程模型进一步封装适合于强化学习任务开发的编程模型。对Spark的数据操作对象JavaRDD类进行进一步抽象,简化数据集的操作函数,降低任务抽象方式的层,将每个函数均作为Map操作,即远程计算,同时提供部分Spark不具备的内容。为了提供强化学习交互所需要的仿真环境,本平台实现了RoboSchool环境的启动入口。调用启动入口可以初始化仿真环境的配置,并在远程函数执行时启动初始化的仿真环境,并给远程函数以相应的反馈。其次,为了处理并发任务的异构持续时间问题,进一步实现Sync()函数。调用Sync()函数时监控远程函数返回的变量列表,并记录变量内容。同时Sync()会一直阻塞监控中未完整返回的变量,直至变量完整返回。同步函数的引入一定程度上提高了高耦合的强化学习任务的容错率。
2.2 控制组件的设计
控制组件的设计考虑到任务抽象方式不同必然会带来任务调度的不同,以及后期算法扩展、兼容等问题,并未使用Spark技术,因此,有必要重新设计并实现一个新的控制组件。
与Spark的分层调度解决方案一样,本平台调度方案也采用了全局控制组件与多节点的本地控制组件。任务节点创建任务时,先把任务交给全局控制组件,再由其根据各子节点的负载情况分发任务,当子节点的负荷过载,便将其置入待缓冲节点序列,等到该节点的负荷降至限制之下再释放。本地控制组件接受任务后,首先检索任务需要的前置条件,然后向全局控制节点请求所需变量;本地任务完成后,本地控制组件主动向全局控制组件提交该任务的结果,结果由本地及全局控制组件分别存储;全局控制组件在接收到子任务完成的结果后更新该子任务的状态,具体数据交换过程如图3所示。
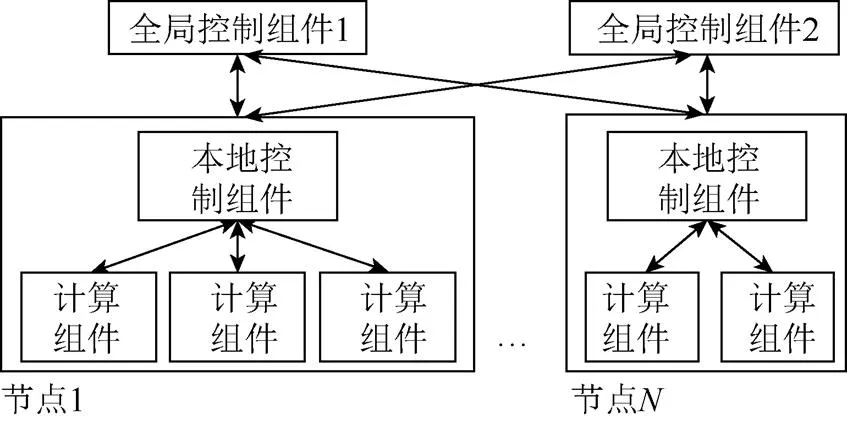
图3 控制组件之间的数据交换
2.3 数据管道的设计
为了适应强化学习任务之中的耦合,即参数传递,需要对Spark的基础数据结构进行修改,介于修改JavaRDD的难度与局限性,有必要重新构建一种基础数据结构。强化学习任务抽象后参数的传递与流数据处理相近,而且Spark与Flume结合可以做到对数据近实时处理,能够保证任务处理的速度,因此,数据管道采用了Flume NG为基础框架。
图4为数据管道类图,上行参数与下行参数均继承自参数数据类,考虑到数据均为参数矩阵或单个参数,所以统一设置为List
Sync()的同步原理是检测全局控制组件中该任务在各子节点的返回结果是否全部接收,当参数完整获取后,放弃对当前线程的阻塞。

图4 数据管道类图
2.4 参数压缩
在分布式计算过程中,模型的传递占用了节点间通信的90%以上,而各个子模型中存在相当程度的重复工作,有效地压缩模型可以缩减通信量,提高模型的训练速度。本训练框架按照本地算法计算得出一个本地最优模型,然后将各个子节点的模型进行聚合,以1%为步长逐步删除参数,经过多次实验表明,在保证模型质量的情况下删除8%的参数后,能够比较快速地完成任务。
2.5 容器层
现有的优秀的机器人模拟、强化学习训练框架大多是基于Ubuntu平台开发的,而用户使用的系统不一,且版本较杂乱,为了能够灵活的对多系统平台兼容,且提高平台部署的便捷性,引入Docker容器技术。选择将框架集成到一个镜像中,对外开放通信必须的端口,用于框架与Spark的通信。用户代码通过映射的方式在镜像启动时挂载到该镜像下,在启动脚本中指定子节点数量,以及用户程序入口及其他参数即可通过启动脚本启动程序,任务结束后启动的镜像会根据任务启动时的部署命令自动回收镜像,保证集群资源的可用性。平台容器化后,通过管理容器能够实现对硬件的更充分、更灵活地使用,Docker与虚拟机架构图如图5和图6所示。
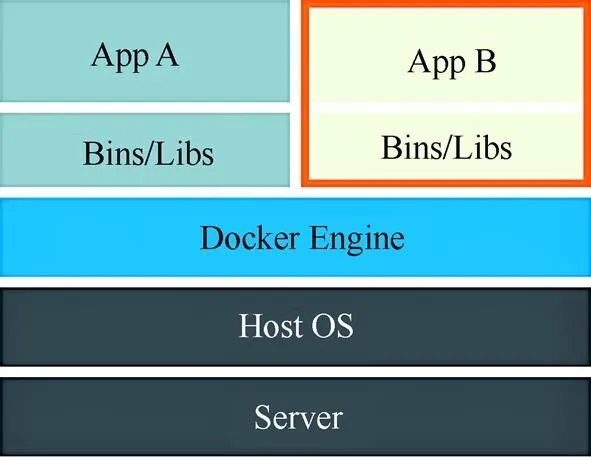
图5 Docker架构
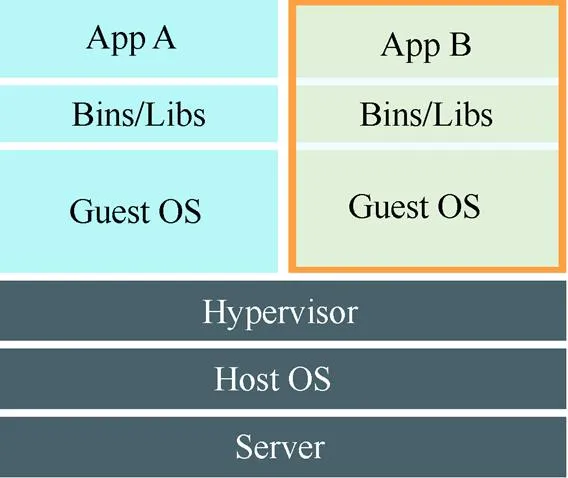
图6 虚拟机架构
3 实验与评估
通过实验数据测试分析基于Spark的强化学习分布式系统与其他传统平台在流数据处理性能、计算成本以及在节点扩展性能等方面,综合的测试本平台各方面性能表现。表1和表2分别为CPU和GPU实验平台硬件及系统配置说明,实验均在这2个平台进行,由于设备的采购时间不同,因此设备的价格以实验时的价格为准。

表1 CPU实验平台硬件及系统配置说明
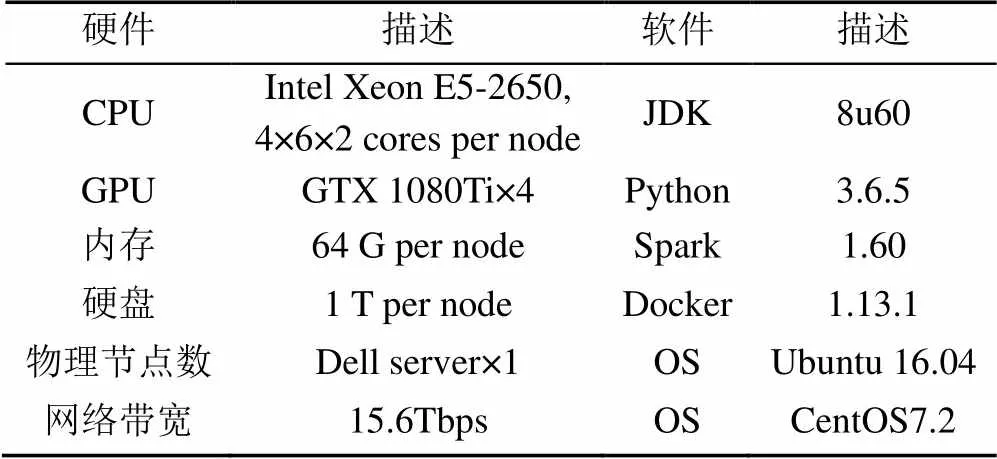
表2 GPU实验平台硬件及系统配置说明
平台结合的模拟环境在常见的Ray提供的gym,集合了与mujoco相似的RoboSchool等模拟环境。以上实验的模拟环境均使用了较为常见的RoboSchool模拟环境Walker2d。
3.1 流数据处理性能
流数据处理在机器学习或强化学习中是常见的操作,能够体现系统节点之间数据交互的速度与计算能力,因此是机器训练学习的一个重要的测试指标。Spark作为本平台分布式主体计算框架,得到了广泛使用,并形成了成熟的生态体系。与Spark平台进行对比实验能够充分验证本实验平台在传统流数据处理方面的性能。
实验结果如图7所示,在CPU数量较少时本平台要具有更大的优势,此任务下适当的增加节点数量的处理方式对Spark更有效。表3给出了同样CPU数量下完成任务所使用的时间以及本平台所损耗的时间比例,可以发现本平台对流数据处理能够将运行时间的损耗保持在–2%~7%。

图7 流数据处理性能对比

表3 流数据处理时间及损耗对比
3.2 扩展性
实际的使用环境中,集群配置不同、节点数量不同、不同实验所需要的计算性能的不同等因素都会对平台提出严格的要求,所以分布式平台的节点扩展性是一个非常重要的性能指标,一个可用的分布式平台必须具备良好的扩展性。
在模拟环境Walker2d下(图8),双足机器人不断尝试向前移动,当机器人无法移动时结束当前循环,每次迭代将机器人的行进距离作为奖励反馈给算法。重复训练实验并以24为步长逐渐增加训练使用的CPU数量,实验结果如图9所示,不同颜色线条代表实验不同的回合,结果表明对于同一个训练任务,训练节点的增加在节点数量较少时能够有效减少训练时间,随着节点的增加训练时间减少效果逐渐减弱,但是并未因节点数量的增加而过度的增加节点间通信损耗。

图8 Walker2d双足机器人仿真
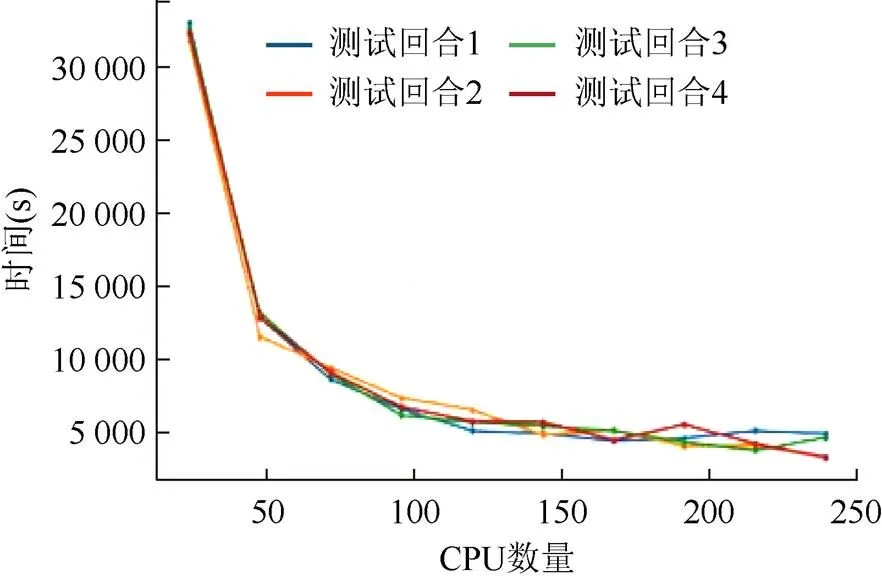
图9 扩展性测试
3.3 健壮性
在任务执行中,框架的健壮性、容错性是任务能否继续顺利进行的保障,而不是中断任务,浪费已经花费的时间与精力。实验中,通过随机中断某子节点的通讯来模拟子节点的崩溃现象,观察框架在出错时对错误的处理能力是否继承了Spark的健壮性。如图10所示,实验分别在第100 s和第200 s随机关闭了一个节点的通信,测试实验稳定的继续完成了剩余任务。本测试任务进行了10次,均完成了实验任务,说明基于Spark扩展的本框架继承了Spark的健壮性。
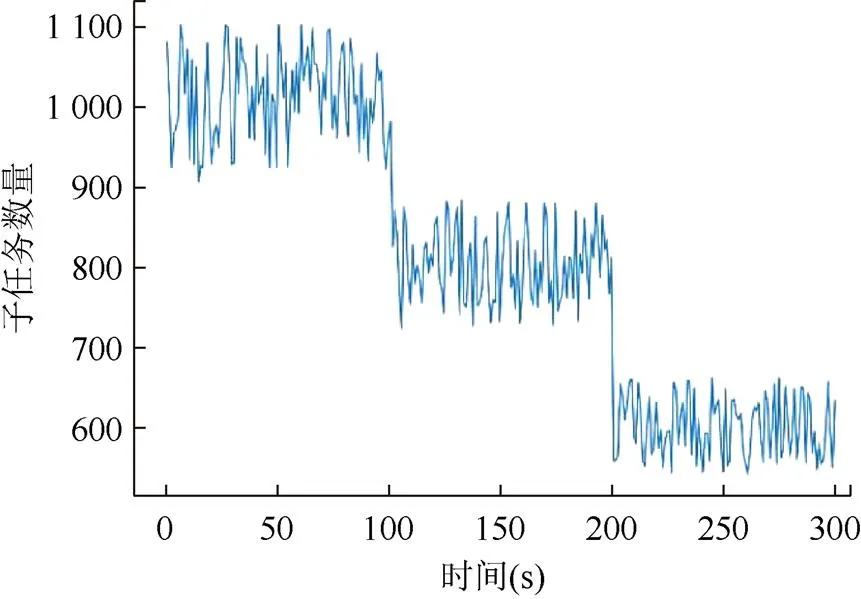
图10 健壮性测试
3.4 对比测试分析
Dryad是用于粗粒度数据并行应用的通用分布式执行引擎,具有优秀的性能。Dryad应用程序将计算顶点与通信通道结合起来形成数据流图,通过在一组可用计算机上执行该图的顶点来运行应用程序,并通过文件、TCP管道和共享内存FIFO进行适当的通信。本平台与Dryad就在ES算法的训练任务中的表现进行了对比,实验结果如图11所示,从图中可以看出本平台相对Dryad能够更快地进行任务的迭代循环,从而获得良好的训练效果。
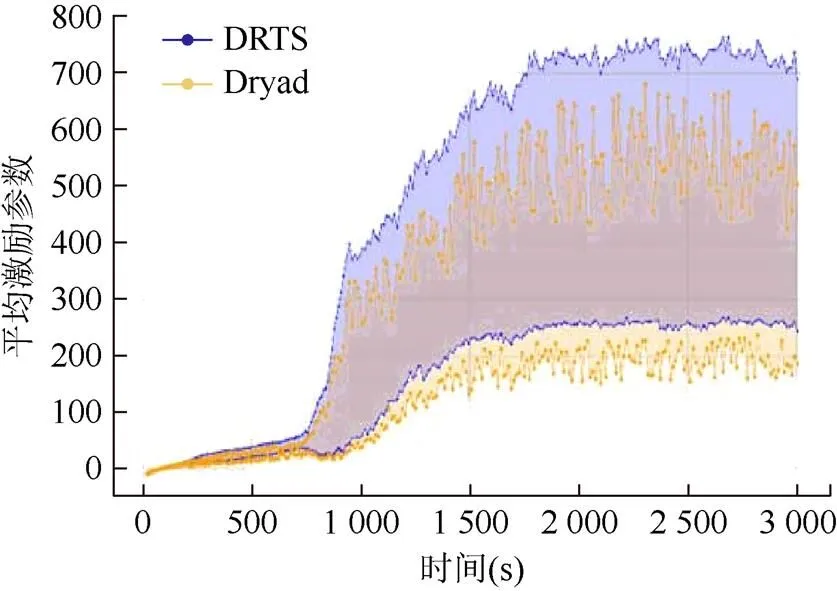
图11 与Dryad多次实验对比
4 结束语
为了解决机器人模拟与强化学习在分布式计算方面的需求,本框架在Spark与Flume NG的流数据处理的基础上进行了补充与封装,完成了一个具备一定可用性、稳定性、可扩展的训练框架。最后,通过多个实验分别验证了本平台与传统框架相比分别在流数据处理、健壮性、可扩展性方面均具备良好的训练效果。该分布式智能机器人训练系统已在国网浙江省电力有限公司物资分公司智能财务机器人发票分拣中起到了提高算力等作用。
[1] SILVER D, SCHRITTWIESER J, SIMONYAN K, et al. Mastering the game of go without human knowledge [J]. Nature, 2017, 550(7676): 354-359.
[2] EL ALAMI A. A survey of the vulnerable cuvier′s gazelle (gazella cuvieri) in the mountains of ait tamlil and anghomar, central high atlas of morocco [J]. Mammalia, 2018, 83(1): 74-77.
[3] MAILLO J, RAMÍREZ S, TRIGUERO I, et al. kNN is: An iterative Spark based design of the k-nearest neighbors classifier for big data [J]. Knowledge Based Systems, 2017, 117: 3, 15.
[4] XI N, SUN C, MA J F, et al. Distributed information flow verification for secure service composition in smart sensor network [J]. China Communications, 2016, 13(4): 119-130.
[5] 赵玲玲, 刘杰, 王伟. 基于Spark的流程化机器学习分析方法[J]. 计算机系统应用, 2016, 25(12): 162-168.
[6] 程敏. 基于PostgreSQL和Spark的可扩展大数据分析平台[D]. 深圳: 中国科学院深圳先进技术研究院, 2016.
[7] 陈虹君, 吴雪琴. 基于Hadoop平台的Spark快数据推荐算法分析与应用[J]. 现代电子技术, 2016, 39(10): 18-20.
[8] 乔非, 葛彦昊, 孔维畅. 基于MapReduce的分布式改进随机森林学生就业数据分类模型研究[J]. 系统工程理论与实践, 2017, 37(5): 1383-1392.
[9] 张繁, 袁兆康, 肖凡平, 等. 基于Spark的大数据热图可视化方法[J]. 计算机辅助设计与图形学学报, 2016, 28(11): 1881-1886.
[10] KROHN M, TROMER E. Noninterference for a practical DIFC-based operating system [C]//2009 30th IEEE Symposium on Security and Privacy. New York: IEEE Press, 2009: 61-76.
[11] 罗元帅. 基于随机森林和Spark 的并行文本分类算法研究[D]. 成都: 西南交通大学, 2016.
[12] 卜尧, 吴斌, 陈玉峰, 等. BDAP:一个基于Spark的数据挖掘工具平台[J]. 中国科学技术大学学报, 2017, 47(4): 358-368.
[13] 唐振坤. 基于Spark 的机器学习平台设计与实现[D]. 厦门: 厦门大学, 2014.
[14] 张滨. 基于MapReduce大数据并行处理的若干关键技术研究[D]. 上海: 东华大学, 2017.
[15] 胡俊, 胡贤德, 程家兴. 基于Spark的大数据混合计算模型[J]. 计算机系统应用, 2015, 24(4): 214-218.
[16] 皮艾迪, 喻剑, 周笑波. 基于学习的容器环境Spark性能监控与分析[J]. 计算机应用, 2017, 37(12): 3586-3591.
Training Framework of Distributed Robot Reinforcement Learning Based on Spark
FANG Wei1,2, HUANG Zeng-qiang3, XU Jian-bin4, HUANG Yi1,5, MA Xin-qiang1,5
(1.Institute of Cyber Systems and Control, Zhejiang University, Hangzhou Zhejiang 310027, China; 2. Department of Computer Science and Technology, Huaibei Vocational and Technical College, Huaibei Anhui 235000, China; 3. School of Computer Science, Hangzhou Dianzi University, Hangzhou Zhejiang 310018, China; 4. Materials Branch, State Grid Zhejiang Electric Power Company, LTD, Hangzhou Zhejiang 310000, China;5. Institute of Intelligent Computing and Visualization Based on Big Data, Chongqing University of Arts and Sciences, Chongqing 402160, China)
Through autonomous learning, reinforcement learning can train robots to complete various tasks that are difficult for them to implement with control methods, and this can effectively avoid system designers from systemic modeling or rules making. However, the training cost of reinforcement learning in the field of robot development and application is high, and it takes a large amount of time cost and hardware cost to realize learning and training. Although the hardware cost can be reduced to some extent based on simulation, for the complicated robot training platform such as Gazebo, the working efficiency of simulation process is low, and it takes a long time for data sampling. In order to effectively solve these problems, a distributed reinforcement learning framework based on Spark is put forward, which optimizes the usability and compatibility of platform of robot simulation process, offers distributed support for the training of reinforcement learning and robot simulation sampling, and has the characteristics of high compatibility and robustness. Through analyzing and contrasting the experimental data, the system framework can not only effectively improve the training speed of reinforcement learning model of robot and shorten the training time, but also help with the saving of hardware cost.
robot; reinforcement learning; Spark; distribute; data pipeline
TP 242
10.11996/JG.j.2095-302X.2019050852
A
2095-302X(2019)05-0852-06
2019-07-31;
2019-08-24
浙江大学工业控制技术国家重点实验室开放课题项目(ICT1800413);重庆市发改委重大产业技术研发项目(2018148208);重庆市教委科技项目(KJ1601129);安徽省高校自然科学研究重点项目(KJ2018A0713);安徽高校优秀青年骨干人才国内访问研修项目(gxgnfx2018108);广东省重点领域研发计划项目(2019B010120001)
方 伟(1979-),男,安徽淮北人,副教授,硕士。主要研究方向为机器学习、计算机视觉等。E-mail:664288201@qq.com
黄 羿(1976-),女,重庆人,副教授,博士。主要研究方向为机器学习、机器人及计算机视觉等。E-mail:36931978@qq.com
猜你喜欢
湖南电力(2022年3期)2022-07-07
能源工程(2022年2期)2022-05-23
黑龙江大学自然科学学报(2022年1期)2022-03-29
小资CHIC!ELEGANCE(2022年1期)2022-01-11
无线互联科技(2020年10期)2020-08-14
装备制造技术(2019年12期)2019-12-25
制导与引信(2017年3期)2017-11-02
中国公路(2017年16期)2017-10-14
燕山大学学报(2015年4期)2015-12-25
雷达与对抗(2015年3期)2015-12-09
