
基于决策树的网络高维数据软子空间聚类方法研究
2019-11-12 11:38张勇陈菊
现代电子技术 2019年20期
张勇 陈菊
摘 要: 典型网络高维数据软子空间聚类方法采用软子空间聚类算法,根据目标函数最优解判断聚类是否最优,最优解计算过程容易过度拟合陷入局部最优,导致分类结果精度低。故文中提出基于决策树的网络高维数据软子空间聚类方法,根据信息增益选择决策树节点,在信息增益基础上添加分裂信息项防止决策树节点过度分类,获取不同树节点属性类别划分结果。在此基础上采用后剪枝技术删除含有噪音和干扰属性结点,将包含样本数量最多的分类结果视为网络高维数据软子空间的分类结果。仿真实验结果表明,所提方法聚类分析正确率随着网络高维数据集维数的增加而增加,且随样本数量增加的同时运行时间增长幅度较低,用时较短,是一种应用价值高的网络高维数据软子空间聚类方法。
关键词: 聚类方法; 软子空间; 高维数据; 决策树; 信息增益; 仿真分析
中图分类号: TN711?34; TP311 文献标识码: A 文章编号: 1004?373X(2019)20?0081?03
Research on network high?dimensional data soft subspace clustering
method based on decision tree
ZHANG Yong, CHEN Ju
(College of Medical Information Engineering, Chengdu University of Traditional Chinese Medicine, Chengdu 611137, China)
Abstract: The typical network high?dimensional data soft subspace clustering method is used to determine whether the clustering is optimal or not according to the optimal solution of the objective function, which adopts soft subspace clustering algorithm. The calculation process of the optimal solution is easy to fall into the local optimum by overfitting, which may result in low accuracy of classification results. A network high?dimensional data soft subspace clustering method based on decision?making tree is proposed. Decision?making tree nodes are selected according to information gain, and the split information items is added on the basis of information gain to prevent over?classification of decision?making tree nodes. The partition results of attribute classification of different decision?making tree nodes are obtained. On this basis, the post?pruning technique is used to remove the nodes containing noise and interference properties, and the classification results containing the maximum number of samples is regarded as the classification results of the network high?dimensional data soft subspace. The simulation results show that the accuracy of clustering analysis of the proposed method increases with the increase of the dimension of the high?dimensional data set in the network, and the running time amplification is still low while the sample quantity is increased. It is a kind of high?dimensional data soft subspace clustering method with high application value.
Keywords: clustering method; soft subspace; high dimensional data; decision?making tree; information gain; simulated analysis
0 引 言
聚类方法在数据挖掘中具有广泛的应用价值,聚类过程可将抽象对象的集合划分为多个相似对象构成的类别或簇。当前的一些聚类方法在聚类网络高维数据时存在聚类结果精度低和聚类运行耗时长的问题。出现该结果的原因可能是高维网络数据空间存在多个不相关子空间,即到定位目标类别存在哪个子空间时,仅需获取低维子空间的聚类,该过程为子空间聚类[1]。依照各个子空间局部特征进行加权划分,并对不同维度分配不同权重。因此可采用求权值的方式来获取最优子空间,根据加权方式的差异将子空间聚类分为硬子空间和软子空间聚类[2],其中软子空间聚类时的维度权值取值在0~1之间。
决策树法是数据挖掘领域应用最广泛的方法之一,尤其在网络高维数据分类方面应用较广。该方法在不同的决策树节点上选择分类精度最佳的属性[3?5],重复进行节点选择,直至决策树分类样本的精确最高。通常采用决策树进行分类需要对决策树进行剪枝处理,以提升网络高维数据软子空间的聚类精度。因此,本文提出基于决策树的网络高维数据软子空间聚类方法,提升聚类结果正确率和效率。
1 典型网络高维数据软子空间聚类方法
软子空间聚类时,将特征权值矩阵用W表示,第j个聚类中的第r个维度比重为[wjr],该值满足条件如下:
获取目标函数后,需采取一定优化求解方式计算目标函数最优解,目标函数最优值即可判断网络高维数据软子空间的分类结果是否最优。
典型网络高维数据软子空间聚类方法通过定义目标函数,根据目标函数的最优解判断是否最优聚类,聚类过程容易陷入局部过于拟合[6?7],陷入局部最优,未能有效地对网络高维数数据进行精确类别划分。因此本文对典型网络高维数据软子空间聚类方法进行改进,提出基于决策树的网络高维数据软子空间聚类方法。
2 基于决策树的网络高维数据软子空间聚类
基于决策树的网络高维数据软子空间聚类方法,在决策树生成过程时,树节点的选择是网络高维数据软子空间聚类分类的核心,决策树中树节点的选择以信息增益为标准[8],网络高维数据样本集D,具有n个不同目标属性,定义集合D分类熵为:
式中:[V(O)]表示属性O的取值集合,其中的取值结果用v表示;[D]为网络高维数据软子空间样本总数;[Dv]表示取值为v属性O的样本数。
由于信息增益标准具有偏好细划分特征,因此无论树节点属性选择是否对网络高维数据软子空间聚类最有意义,只要其划分网络高维数据软子空间类别多,在信息增益标准下该决策树节点就是所选节点。本文通过在信息增益基础上添加一个分裂信息项(SI),来惩罚分类过细的属性。
由于网络高维数据软子空间中包括大量噪声和干扰属性,因此生成的决策树节点包含大量错误信息,其虽然能够实现对网络高维数据软子空间的准确分类,但分类结果精度较低,且生成的决策树节点规模较大,该现象即为过拟合现象,剪枝技术可降低决策树的过拟合现象[9],提升决策树的分类精度。剪枝技术包括前剪枝和后剪枝两种。
前剪枝技术是在决策树生成前根据某标准降低树节点增长,前剪枝技术降低决策树拟合时虽然降低树节点,提升分类精度,但降低聚类方法的搜索范围,分类精度提升效果较差。
后剪枝技术是在生成决策树后对决策树以某标准进行节点删除[10],如删除含有噪声和干扰属性节点为根节点的子树,将其从根节点转变为叶子节点,叶子节点将样本分為n个类别[S1,S2,…,Sn],若分类中包含样本数量最多,可把该分类结果定义为网络高维数据软子空间的分类结果。重复进行决策树节点删除,且节点应为删除后可提升分类精度的节点,一直修剪直至分类结果最佳为止。后剪枝相较前剪枝的分类精度高且范围广,反复进行节点删除得到网络高维数据软子空间聚类方法分类精度高。
3 实验分析
3.1 实验环境
实验选取网络高维数据数据集用于测试分析,实验数据集中需先完成特征归一化处理,使数据集中特征在[0,1]之间。为提升实验结果的公平性,实验对所有聚类方法均进行多次重复实验,将各个方法测试结果的方差和均值均利用Matlab软件进行仿真。聚类方法评价指标包括聚类准确率(聚类方法正确划分样本所占比率)和Rand指数RI(数据集聚类后和实际划分后,两种结果的一致性)。聚类准确率值越高表明聚类方法聚类结果越优;当RI值为1时,表明聚类方法聚类结果与实际类表相同。
3.2 数据集选择
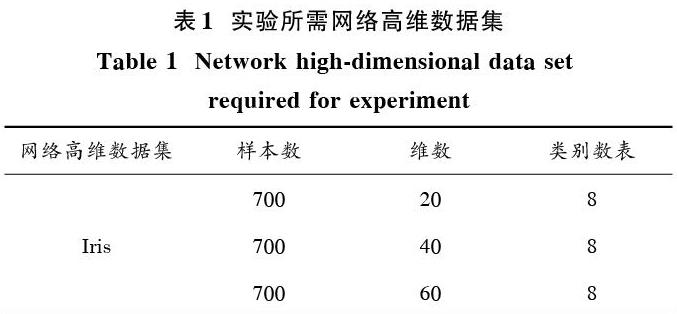
实验选择Iris为实验待聚类网络高维数据集,网络高维数据集如表1所示。
表1 实验所需网络高维数据集
3.3 测试结果
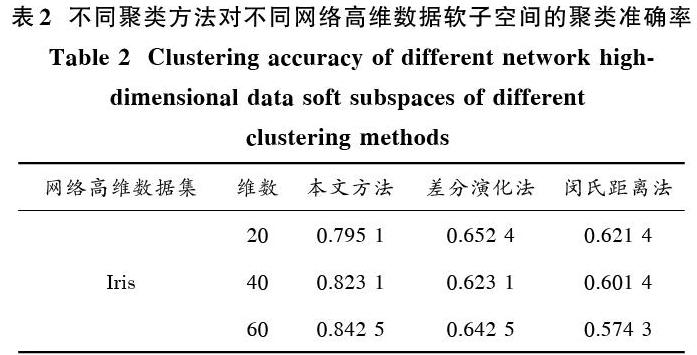
为突出本文方法聚类结果的高准确度,将基于差分演化的网络高维数据软子空间聚类方法和基于闵氏距离的网络高维数据软子空间聚类方法与本文方法进行比较。三种方法对不同网络高维数据软子空间的聚类准确率如表2所示。
表2 不同聚类方法对不同网络高维数据软子空间的聚类准确率
从表2可知,本文方法在聚类不同数据集软子空间时聚类正确率均高于差分演化和闵氏距离法。详细分析不同数据维数时的聚类正确率可知,随着数据集维数的增加,本文方法的聚类正确率呈现增长的变化趋势,而另外两种方法聚类正确率与数据维数间无明显关系,因此说明,本文方法对不同网络高维数据集软子空间的聚类结果正确率高,且随着数据维数的不断增加聚类正确率也不断提高。
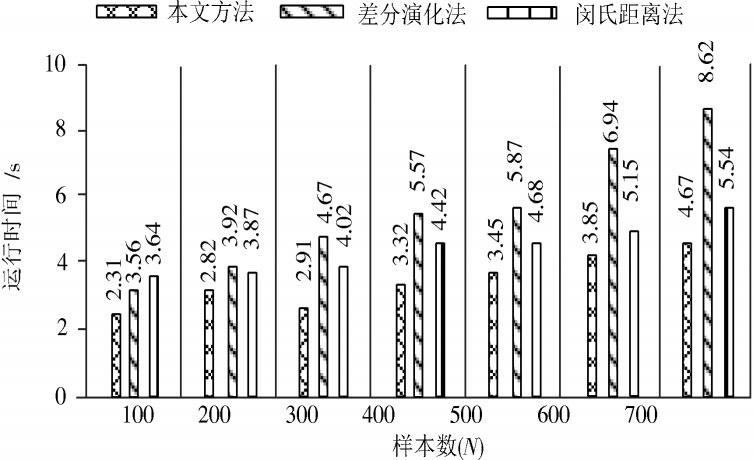
采用三种方法聚类Iris数据集进行运行效率与样本数量分析,结果如图1所示。
分析图1可知,三种方法聚类分析Iris数据集时,均存在运行时间随样本数增加而增长的趋势且增长幅度均较低。详细分析图1可知,本文方法运行时间初始值较小,而另外两种方法的运行初始值较大,随着样本数增加三种方法的运行用时差值显著,说明本文方法是一种运行效率高的网络高维数据软子空间聚类方法。
图1 三种方法聚类分析Iris数据集样本数与运行时间关系
4 结 论
本文探讨基于决策树的网络高维数据软子空间聚类算法,该方法在聚类分析时具有以下几点优势:
1) 决策树法在信息增益基础上添加分裂信息项,防止网络高维数据软子空间的过度拟合分类,提升分类结果的价值意义;
2) 后剪枝技术在降低决策树多度拟合的同时还提升聚类方法的搜索范围,扩大网络高维数据软子空间的数据类别。
经实验测试结果可知,本文方法聚类分析网络高维数据集软子空间结果正确率高,运行时间随样本数据增长变化较小,具有较强的实用性和应用性。
注:本文通讯作者为陈菊。
参考文献
[1] 牛志华,屈景怡,吴仁彪.基于Spark的分层子空间权重树随机森林算法[J].信号处理,2017,33(10):27?33.
NIU Zhihua, QU Jingyi, WU Renbiao. Random forest algorithm using stratified subspaces and weighted trees based on spark [J]. Journal of signal processing, 2017, 33(10): 27?33.
[2] 寇广,汤光明,何嘉婧,等.一种基于变异蝙蝠算法的高维聚类方法[J].系统仿真学报,2018,30(4):49?55.
KOU Guang, TANG Guangming, HE Jiajing, et al. High?dimensional clustering method based on variant bat algorithm [J]. Journal of system simulation, 2018, 30(4): 49?55.
[3] 支晓斌,许朝晖.鲁棒的特征权重自调节软子空间聚类算法[J].计算机应用,2015,35(3):770?774.
ZHI Xiaobin, XU Zhaohui. Robust soft subspace clustering algorithm with feature weight self?adjustment mechanism [J]. Journal of computer applications, 2015, 35(3): 770?774.
[4] 亢红领,李明楚,焦栋,等.一种基于属性相关度的子空间聚类算法[J].小型微型计算机系统,2015,36(2):211?214.
KANG Hongling, LI Mingchu, JIAO Dong, et al. Attribute relevancy?based subspace clustering algorithm [J]. Journal of Chinese computer systems, 2015, 36(2): 211?214.
[5] 董琪,王士同.隐子空间聚类算法的改进及其增量式算法[J].计算机科学与探索,2017,11(5):802?813.
DONG Qi,WANG Shitong.Improved latent subspace clustering algorithm and its incremental version [J]. Journal of frontiers of computer science & technology, 2017, 11(5): 802?813.
[6] 肖红光,陈颖慧,巫小蓉.基于结构树的高维数据流子空间自适应聚类算法[J].小型微型计算机系统,2016,37(10):2206?2211.
XIAO Hongguang, CHEN Yinghui, WU Xiaorong. Adaptive clustering algorithm for high dimensional data stream based on structure tree [J]. Journal of Chinese computer systems, 2016, 37(10): 2206?2211.
[7] 费贤举,李虹,田国忠.基于特征加权理论的数据聚类算法[J].沈阳工业大学学报,2018,40(1):77?81.
FEI Xianju, LI Hong, TIAN Guozhong. Data clustering algorithm based on feature weighting theory [J]. Journal of Shenyang University of Technology, 2018, 40(1): 77?81.
[8] 王跃,肖人杰,褚芯阅,等.基于数据流形结构的聚类方法及其应用研究[J].数学的实践与认识,2016,46(14):180?188.
WANG Yue, XIAO Renjie, CHU Xinyue, et al. Clustering method based on the data manifold structure and its application research [J]. Mathematics in practice and theory, 2016, 46(14): 180?188.
[9] 邱云飞,费博雯,刘大千.基于概率模型的重叠子空间聚类算法[J].模式识别与人工智能,2017,30(7):609?621.
QIU Yunfei, FEI Bowen, LIU Daqian. Overlapping subspace clustering based on probabilistic model [J]. Pattern recognition and artificial intelligence, 2017, 30(7): 609?621.
[10] 李小玲.关于网络数据库传输中异常数据检测仿真研究[J].计算机仿真,2018,35(1):420?423.
LI Xiaoling. Simulation research on abnormal data detection in network database transmission [J]. Computer simulation, 2018, 35(1): 420?423.
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
成都信息工程大学学报(2018年6期)2018-03-21
科学与财富(2016年18期)2016-12-22
中小企业管理与科技·下旬刊(2016年10期)2016-11-18
中小企业管理与科技·上旬刊(2016年10期)2016-11-15
科技视界(2016年15期)2016-06-30
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
电测与仪表(2016年2期)2016-04-12
郑州大学学报(医学版)(2015年1期)2015-02-27
