
基于SSD和MobileNet网络的目标检测方法的研究
2019-11-12 05:41任宇杰刘方涛张启尧
计算机与生活 2019年11期
任宇杰,杨 剑,刘方涛,张启尧
中北大学 软件学院,太原 030051
1 引言
众所周知,近几年来,深度学习[1]的人工智能思想方法在各行各业中的应用更加普及,相比传统方法其具有更好的鲁棒性和更高的准确性。随着计算机视觉技术的快速发展,目标检测的技术作为其中一个热点的分支也备受关注,一直是研究的热点[2-4]。图像的目标检测是指识别图像中的目标在原图像中的大小以及位置。基于深度学习方法的图像目标检测,特别是基于深度卷积神经网络的图像目标检测技术发展十分迅速。
另外,现有的基于神经网络的目标检测模型可以做到多目标识别的任务。并且,基于神经网络[5]的模型,在数据样本量和硬件资源计算能力有限的情况下可以通过深度学习的方法来实现多目标的识别。
基于图像的目标检测的研究工作也有其自身的发展阶段,经历了从基于图像的全局特征进行检测,到基于图像的局部特征进行检测,再到现在基于深度学习方法思想的特征进行检测。
近几年来,随着技术的快速发展,相继出现了很多种基于深度学习[6]方法思想的目标检测模型,例如基于区域建议(region proposal,RP)方法的R-CNN(regionbased convolutional neural network)模型[7]、Fast R-CNN模型[8]、Faster R-CNN 模型[9]、R-FCN(region-based fully convolutional networks)模型[10]和基于回归方法的SSD(single shot multibox detector)模 型[11]以 及YOLO(you only look once)模型[12]全部都是基于神经网络。SSD 模型是当中检测精确度相对更高的网络结构,但是由于其自身也有一定的缺陷,比如只有使用最后一层的低层特征层进行目标检测,导致大量的目标特征信息丢失,使得检测效果不尽如人意。
为了解决SSD 基础模型的这些基本缺陷,很多学者针对提升SSD模型在中小目标检测方面的能力进行了相应的研究。例如,Tang等[13]在原有SSD模型的基础之上采用多视窗的方法,通过多视窗多通路的思想同时进行检测从而提升准确率,但是这种方法的区域划分不固定,对于目标检测的准确性和鲁棒性产生了一定的影响。Fu等[14]提出了DSSD(deconvolutional single shot detector)模型,通过反卷积的思想提升小目标的检测能力,但是由于网络模型结构层数较深,使得模型的检测能力在实时性方面表现较差。Li等[15]提出了FSSD(feature fusion single shot multibox detector)模型,具体方法是通过特征融合和下采样的操作对获取到的多尺度特征进行重构,提高中小目标的检测效果,结果准确性确实有明显提高,但是检测速度相对较慢,提高检测的实时性比较依赖硬件资源条件。陈幻杰等[16]对SSD模型的改进,通过小目标特征区域进行放大提取,额外提取多个高层特征层的信息,利用更深的网络结构改善中等目标的检测结果等方法,较大地提高了对中小目标的准确率,检测速度相比原有的SSD 模型下降了将近一半,在满足准确性的基础上实时性受到了较大的影响。
本文基于SSD基本模型和轻量级的深层神经网络MobileNet 的思想构建目标检测网络结构。该网络结构采用特征金字塔的多尺度全卷积结构,能够实现对多尺度目标的检测;同时获取到不同特征层的特征信息构建新的金字塔特征层,随后基于该金字塔特征层对其进行目标的分类和定位的操作。实验结果表明,本文模型在较低的硬件资源条件下,满足当前对视频流图像的处理速度的前提下,相较于传统的SSD算法在检测性能和效果上有明显提升。
2 目标检测模型的构建
本文利用Tensorflow 平台构建多目标识别深度学习模型,由于模型对于大型占比目标的检测已比较成熟,故模型在构建的时候着力针对中小型占比目标。其中,一般将目标检测框大小小于32×32的目标认为是小型占比目标,目标检测框大小介于32×32至96×96的目标认为是中型占比目标,目标检测框大小大于96×96的目标认为是大型占比目标。
首先,配置深度学习所需要的开发环境。其次,整理模型在训练时所需要的带有标记的图像数据。再者,根据具体条件选取合适的目标检测模型。最后,在数据样本更加丰富的MS COCO 数据集[17]和PASCAL VOC 2007 数据集上完成模型的训练、验证和测试,最终获得符合本文场景的模型。
2.1 SSD模型结构
基本的SSD模型是在VGG(visual geometry group)网络模型[18]的基础上构建新的网络结构,通过融合不同卷积层的特征图来增强网络对特征的表达能力,采用多尺度卷积检测的方法来进行目标检测,进而大幅度提升目标检测的速度。具体的SSD模型结构如图1所示。
由图1 可知,模型基于VGG 模型的特征提取方法的思想,将各级的卷积特征图作为该一级的特征表示,不同的卷积级别的图像卷积特征分别描述了不同的语义信息[19],卷积层越深则表达的图像特征的予以信息的级别也就越高。
SSD 模型中结合特征金字塔的多尺度卷积神经网络的思想主要体现在获取不同卷积层、不同尺度的特征图数据来进行目标检测。而在SSD模型中特征的提取采用的是逐层提取并抽象化的思想,低层的特征主要对应于占比较小的目标,高层的特征主要对应于占比较大的目标的抽象化的信息[19]。即如果待检测的目标在图中占比越小,特征图在经过层层卷积、池化的操作之后,在高层特征层可能出现信息丢失的情况,以致于检测不到占比较小的目标。并且在SSD模型中是通过低特征层的特征信息检测小型占比目标,通过高特征层的特征信息检测中型和较大占比目标。基本的SSD模型通过金字塔特征层进行特征提取,且不同特征层之间是相互独立的,没有目标信息的相互补充,且在SSD 模型的结构之中,低特征层仅有Conv4_3 层用于检测小型占比目标,因而在缺乏充足的特征信息的情况下存在特征提取不充分的问题,因而导致对小型目标的识别效果一般。
SSD 模型中多尺度的思想从其算法中也不难看出,其公式[20]为:


Fig.1 Structure map of SSD图1 SSD模型结构
在式(1)、式(2)中,Tn表示第n层的特征图,Sn表示由第n-1层特征图经过非线性运算得到的第n层特征图,S1(I)表示输入图像I经过非线性运算得到的第一层特征图;dn(⋅)表示第n层特征图上的检测结果,D(⋅)表示将所有检测的中间结果进行集合化得到的最终的结果。由式(1)、式(2)可以看出,第n-1层的特征信息决定了第n层的特征信息,且层与层之间相互独立。因此,要更加准确地检测出对应的目标,就必须获取足够量的特征信息,即足够大小的特征图,结合网络结构得到要获取的特征。
2.2 小占比目标检测改进的具体实现方法
针对基本的SSD模型对于图像多目标识别的缺陷,无法很好地检测中小型目标,本文采用改进的多尺度卷积神经网络结构进行目标检测,对SSD 模型中的低特征层和高特征层采用不同的改进策略提高模型的检测能力;同时融合MobileNet 的基本思想,提高网络结构的检测速度,提高模型的准确性、实时性和鲁棒性。
为了提高SSD 模型对于小型目标的检测能力,对低特征层采取特征提取、反卷积操作保留特征图中更多的特征信息,进而对于小型目标的特征区域,通过特征映射在保留有更多小型目标特征信息的特征图上进行特征提取,对于提高模型的小型占比目标的检测能力是十分有必要的。
低特征层包含有更多的细粒度的特征信息,保留更多细节的特征信息可以更加准确地检测目标。反卷积操作扩大了卷积运算之后的特征图的大小,同时也保留了更多的细节特征信息,提高了模型的特征表达能力。但是既然保留了更多的特征信息,那么在运算时必然会使得运算时间增加,降低检测速度,影响一些模型整体的检测效果。其基本思想如图2所示。
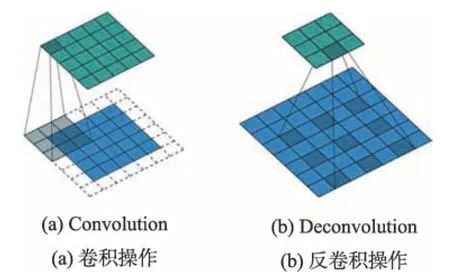
Fig.2 Sketch of convolution and deconvolution图2 卷积和反卷积示意图
反卷积操作[21-23]也称为空洞卷积操作。反卷积操作和卷积操作过程相反,反卷积操作其实就是通过对输入的特征图填充补零,再通过反卷积核的作用得到放大后的特征图。反卷积的公式为:

式中,t表示步长,m表示反卷积核的大小,k表示输入特征图的大小,s表示反卷积操作之后获得的特征图的大小。具体思想如图3所示。
由图3 可以看出,SSD 模型中主要结构VGG16模型有5个池化层,若不对其进行修改,则在pool5层之后特征图会变成10×10的大小,会丢失大量细节特征信息。因此本文通过设置rate名为扩张率的参数,通过反卷积操作将特征区域放大,保留更多的小型占比目标的特征信息,便于提升对小型目标的检测能力。由于SSD 模型是对于300×300 的输入图像进行输出的区域建议,因此本文将反卷积操作之后的图像增大至300×300,一方面保证了充足的特征信息,另一方面也可以获得更加准确的目标区域建议。
2.3 特征映射策略
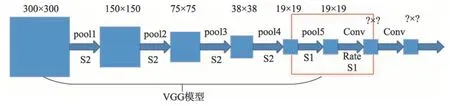
Fig.3 Framework of decovolution of SSD model图3 SSD模型反卷积操作框架图
在进行反卷积操作之后,对获取到的特征图进行特征区域映射。从而根据卷积核的大小或图像与特征图大小的比例关系建立起输入图像的目标区域与特征图的某一点的对应关系,将用于进行目标检测的特征图的每个位置映射到原图像中相应的位置,并在对应的位置生成不同比例大小的预测框。
基本的SSD模型在预测框映射时是默认针对整个图像数据进行的,并且对低层特征层的特征图进行区域映射是针对输入图像进行的。但是这里低层特征层在执行反卷积操作后,是将SSD 模型输出后的图像作为特征图数据进行区域映射的模板。
具体思想如图4所示。
在对低层特征层进行特征提取、放大特征图时,原本SSD模型是根据特征图与输入图像的大小关系将目标区域映射到特征图上对应位置,具体公式为:

在式(4)、式(5)中,tw、th表示默认框在映射特征图上的宽度和高度;iw、ih表示输入图像的宽度和高度;yw、yh表示映射特征图的宽度和高度;dw、dh表示区域建议的宽度和高度。
由图5看出,假设输入图像大小是300×300,设定的产生默认框的特征图大小是5×5,在原图像上产生的红色、黄色、蓝色代表不同比例大小的默认框。假设选取特征图上的(2,2)进行默认框映射,由于原本SSD 模型是利用产生默认框的大小与原图像的大小之间的比例关系进行映射,可计算出特征间隔为300/5=60,相应的在原图像上(180×180)的位置产生对应的默认框。
在本文模型中,通过将模型输出图像作为低层特征经反卷积操作之后的区域映射的模板,默认框映射到原图像的对应位置。具体公式为:

Fig.4 Sketch of low-level feature mapping图4 低层特征映射示意图

Fig.5 Sketch of default box feature mapping of SSD图5 SSD模型默认框特征映射示意图
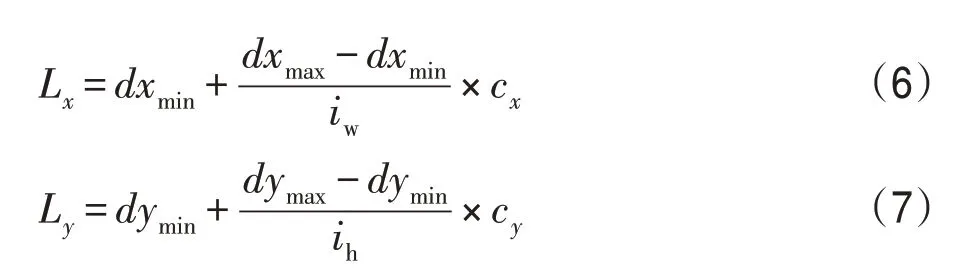
在式(6)、式(7)中,iw、ih表示产生默认框的区域映射特征图的宽度和高度,cx、cy表示默认框在区域映射特征图上的中心坐标,(dxmin,dymin,dxmax,dymax)表示预测框左上角和右下角的坐标,Lx、Ly表示默认框在原图像上对应位置的中心坐标。
由图6看出,假设输入图像大小是300×300,设定的产生默认框的特征图大小是5×5,在原图像上产生的红色、黄色、蓝色代表不同比例大小的默认框,黑色框表示SSD模型输出的建议区域,其位置信息由4部分组成,分别为建议区域的左上角和右下角的坐标。假设为(90,60,170,200),在X轴方向的映射间隔计算为(170-90)/5=16,Y轴方向的映射间隔计算为(200-60)/5=28。在特征图上对于(0,0),对应于黑色建议框中起始位置(90,60)处产生默认框;特征图中Y轴对于(0,1),对应于黑色建议框中起始位置(90,88)处产生默认框;特征图中X轴对于(1,0),对应于黑色建议框中起始位置(106,60)处产生默认框。

Fig.6 Sketch of default box feature mapping of this paper图6 本文模型默认框特征映射示意图
2.4 中型占比目标检测改进的具体实现方法
本文针对中型占比的目标检测,提取多个高层特征层的信息,对原有的SSD模型结合MobileNet思想进行改进,通过对参数的再训练提高模型对中等目标的检测能力。具体思想如图7所示。

Fig.7 Sketch of high-level feature extraction图7 高层特征层特征提取示意图
从图7 中可以看出,分别获取SSD 模型中的Fc7层、Conv8_2 层、Conv9_2 层、Conv10_2 层、Conv11_2层的特征图信息。通过目标检测之后的处理策略对目标检测的结果(包括预测框的位置和目标检测类别)进行筛选并输出,同时基于再训练的SSD模型的参数进行特征提取,通过多轮多次迭代以及参数调整获取优化模型。
2.5 代价函数、匹配策略和消除冗余数据
本文原有SSD 模型采取特征金字塔的基本思想,获取多个卷积层的特征信息。特征金字塔与单层特征图的区别如图8所示。
图8 中左边的单层特征图的方法是针对输入的图片获取不同尺度的特征映射,但是在预测阶段仅仅使用最后一层的特征映射;而SSD 模型不仅获得不同尺度的特征映射,同时在不同的特征映射上面进行预测,考虑了更多尺度的特征,在增加运算量的同时也提高了检测的精度。

Fig.8 Schematic diagram of single feature map and feature pyramid hierarchy图8 单层特征图与特征金字塔示意图
因为要对获取到各层特征信息的金字塔层进行目标的分类和定位,所以本文算法的目标损失代价函数主要分为两部分:一部分是计算相应的预测框与目标类别的置信度的损失Lconf(confidence loss),即分类损失;另一部分是相应的位置回归损失Lloc(location loss),即预测框的定位损失,具体公式如下:

在式(8)、式(9)、式(10)中,N表示匹配到默认框的预测框的数量,α是用于调整置信度损失(confidence loss)和位置损失(location loss)之间的比例,默认α为1,通过调节可以降低各层样本对于整体网络训练的影响。i表示第i个默认框,j表示第j个真实框,p表示第p个类。其中={1,0}表示第i个预测框匹配到了第j个类别为p的真实框,并且位置回归的损失函数(location loss)是L1损失函数,比L2损失函数具有更强的适应性,对异常值不敏感。g表示真实框(ground truth box),l表示模型输出的预测框(predicted box),d表示默认框(default bounding box)。
在模型训练的时候,真实框与预测框按照如下的方式进行配对:
(1)寻找与每一个真实框有着最大交并比(intersection over union,IOU)的预测框,这样可以保证每一个真实标注框与唯一的一个预测框对应起来。
(2)将剩余的还没有配对的预测框与任意一个真实框进行尝试配对,只要两者之间的交并比(IOU)大于阈值,就可以认为配对成功(基本的SSD 300 模型的阈值为0.5)。
(3)成功与真实框配对的可以认定为正样本(positive,对应于式(9)中,没有配对的认定为负样本(negative,对应式(9)中
配对匹配的基本思想如图9所示。
在训练过程中产生的是不分类的目标,其中会有很多的包含相互重叠的目标,如果直接进行特征提取,那么在计算过程中会代入很多的冗余信息,因此本文通过非极大值抑制的思想,消除冗余的目标候选区域,使得负样本的数目减少,使模型效果趋于稳定。这里的操作主要为了消除冗余预测框,不考虑目标的具体类别,通过采取设置较大的阈值(比如设置为0.8)选取极少的预测框,保留了最接近真值的目标窗口,目标被这些预测框基本上都包含等。
2.6 MobileNet基本思想
MobileNet的网络结构是基于深度级可分离卷积块的堆叠设计。通过权衡延迟时间和精度要求,基于宽度因子和分辨率因子构建合适规模、合适速度的MobileNet 结构。其网络结构的基本思想是将通道间的相关性和空间相关性完全分离出来,同时大大减少计算量和参数量。
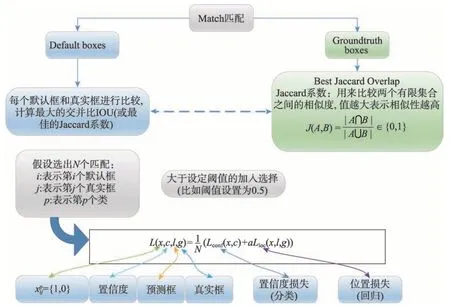
Fig.9 Sketch of ground truth boxes and default bounding boxes图9 真实框与预测框匹配示意图
该网络结构与传统的卷积网络结构有所不同体现在对特征图的各个通道进行卷积操作(比如设置为3×3×1),将卷积操作之后的各个特征图通道进行合并,通过1×1 卷积降低其通道数。由于MobileNet网络结构中使用了大量的3×3的卷积核,极大减少了计算量,同时对于模型准确率下降的影响也很小,不仅保证了模型的准确率,同时加快了模型的运算速度,保证了模型的实时性要求。
由于SSD 模型是一种不需要产生候选区域,直接产生物体的类别概率和位置坐标,经过单次检测即可得到最终的检测结果。而MobileNet 是使用这种算法的具体网络结构,用于进行特征提取。这使得二者可以结合,文献[24]也证实了这一点。通过SSD 模型融合了MobileNet 的网络思想,结合了二者的优势,保留原有SSD 模型的网络结构,使用3×3 的卷积核进行特征处理,保证了模型的准确率。在此基础上,本文模型将原本的大量冗余的参数变成小型参数结构,减少网络计算量的同时,降低了对于硬件资源的消耗,有利于加快模型的收敛速度,改善模型的基本性能。
通过该网络结构,有效减少了模型的计算量和参数量。基于上述该网络结构的思想,也使得它在物体检测、人脸属性检测、细粒度分类和大规模地理定位等方面有着广泛的应用。
3 实验过程与结果分析
在实际应用中,由于不同的场景下有着不同的限制和要求,此时需要根据实际情况来权衡并选择最适合的检测方法。本文在实验时是基于SSD模型和MobileNet 模型针对公开数据集MS COCO 和PASCAL VOC2007 上进行训练得到适合的模型,进而评估提出的模型方法的性能。
3.1 目标检测模型的生成
本文基于深度学习的思想和相关理论,利用在大数据(COCO[17]、VOC 2007、ImageNet)上训练好的模型,应用到多目标识别的任务当中,并且不断对模型当中的参数进行微调,从而得到符合本任务需求的模型。微调工作是针对已训练的深度卷积神经网络的,因此对于硬件的计算能力和要求不会特别苛刻,也适合在个人的GPU上进行模型的训练。
通过在数据集上训练完成的SSD 和MobileNet模型思想的融合模型,即在原始的训练好模型结构不变的基础上,把训练好的模型的权重等参数作为初始值;然后通过微调参数的方法对分类的数量进行修改,设置本文应用场景具体的分类数;最后对于整个模型进行不同批次、不同轮次的训练(retrain)。最终得到目标检测精度和速度都有所提升的模型。
3.2 实验环境准备
本文提出的目标检测方法的实验框架基于Python语言,在操作系统为Windows 10 的个人计算机上搭建深度学习的开发环境完成模型的训练、验证以及测试的工作。选用Anaconda集成相关环境。
其中计算机的硬件配置为:Windows 10 64 位操作系统,处理器(CPU)型号为Intel i7,内存(RAM)为8 GB,显卡(GPU)为NVIDIA GeForce GTX。
深度学习开发环境的各个软件版本为:Visual Studio 2015、Anaconda3、CUDA 9.0、cuDNN 7.3.1、Python 3.6.4、Tensorflow-GPU 1.9.0。同时在个人配置环境时默认安装Tensorflow-GPU 1.12.0 的版本在训练时会报错,与其他环境不匹配,因此这里选择较低版本1.9.0作为训练环境。
最后,在集成环境上安装诸如pandas、numpy 等对应的Python 第三方库以及诸如Keras、Tensorflow Research Models 等深度学习的API(application programming interface),这样可以大幅度降低开发的困难性。
3.3 数据集描述及网络参数
基于SSD和MobileNet模型,利用在大规模数据集PASCAL VOC 2007(21 个类别)上进行接下来的本文的训练工作,可以大大地降低模型训练时需要的计算能力、数据量和时间成本,同时也可以满足具体任务对于目标检测的准确率和识别速率的要求。
其中再训练数据集包含5 011 幅图像和5 011 个标注信息文件,验证数据集包含4 952幅图像和4 952个标注信息文件。最后为了检测模型效果,在测试集中测试435张多目标复杂度较高的图片(诸如分类物体有交叉重叠或距离较近等特征),其中中小型目标的数量在1 153个,分析特征提取的效果和预测区域目标精修对目标检测结果的影响。
本文融合模型基于基础的SSD 模型,网络阈值设置为0.7和0.9,在较细粒度特征上考察训练好的模型在目标检测上对中小目标检测的准确性和鲁棒性。
根据网络微调,最终选择基于某目标检测点生成的预测框数目为6;预测框大小与原图占比最小0.20,最大占比0.95,宽高比率分别为1.00、2.00、3.00、0.50、0.33;网络初始化的标准差设置为0.03,均值设置为0;学习率为0.004,衰减因子为0.005;为防止过拟合,生成预测框中采用Dropout 方式,用其中随机80%的神经元进行工作计算;激活函数使用Relu_6 代替传统的Relu 函数,有利于网络对数据分布的稀疏矩阵的学习,缓解过拟合的产生等。
3.4 评价指标
本文基于PASCAL VOC 2007 数据集使用平均精度均值(mean average precision,mAP)、图片传输速率、交并比IOU 和目标的检测率这些基础指标对提出的模型效果进行评价。
(1)交并比IOU 指的是对于检测目标产生的预测框与真实标注框之间的交集与并集的比值。通过该指标可以衡量检测到目标位置准确性。
(2)平均精度均值(mAP)[25]指的是检测出的目标中正确的目标所占比率。
(3)图片传输速率(frame per second,FPS)用于衡量在现有硬件条件下不同模型处理数据的速度,对于目标检测的实时性的衡量有着重要的作用。
(4)检测率指的是检测出目标在所挑选目标总数中的占比,本文主要对中小型目标的检测效果进行衡量。
3.5 模型训练测试的过程及结果
本文的目标检测选取VOC 2007数据集中的7个类别的图像数据进行模型的训练、验证以及测试工作。类别种类分别为:人(person)、自行车(bicycle)、摩托车(motorbike)、汽车(car)、公交车(bus)、猫(cat)、狗(dog)。
模型训练测试过程如下:
(1)采用基础SSD 模型方法以及本文模型针对选取的7类目标进行检测。
(2)从VOC 2007 数据集中选取训练集、验证集和测试集。将对本文改进的SSD模型应用到上面选取到的7类数据中进行目标检测,通过训练再进行调参,最终通过实验迭代多轮多批次得到最优化模型数据结果。
(3)使用基本SSD模型结果、Chen等提出的改进FSSD模型,与本文模型的结果进行对比。
由于该模型准确性与SSD 模型、DSSD 模型、FSSD模型等相比准确性最高,因此在本文实验结果中选取它作为对照参考模型[13-16]。具体结果通过平均精度均值(mAP)、检测速度表示,如表1 所示。通过基本SSD 模型结果和本文模型结果,对照改进的FSSD 模型结果,将三者进行比较,评价模型的准确性和鲁棒性。
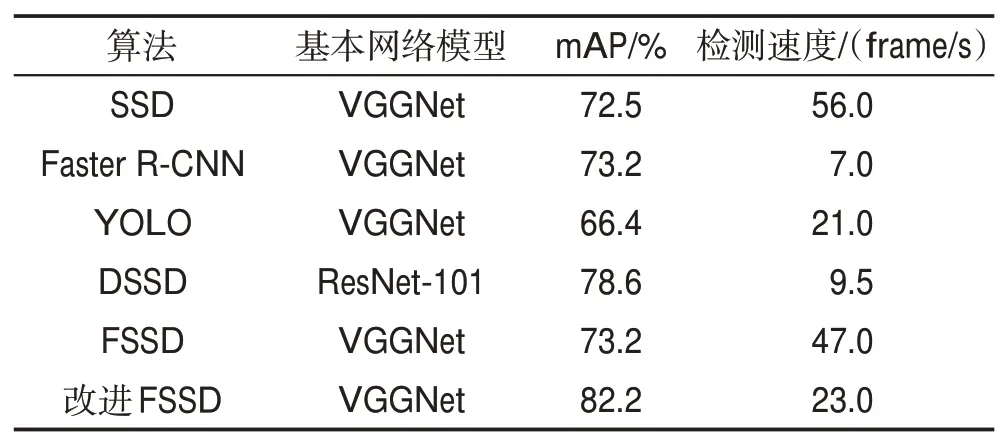
Table 1 Comparison of detection accuracy results between different algorithms表1 不同算法检测准确性的结果对比
本文采用多尺度卷积层获取到的特征信息作用于目标检测,其中中低层特征主要用于检测小型目标,高层特征主要用于检测中型目标。
在同样的训练集、验证集和测试集的条件下对上述3种模型的检测结果进行比较,其检测效果使用评价标准中的mAP值来衡量。
在网络阈值设置为0.7 的条件下,对比不同的类别在不同模型下的中等目标的检测精确度。其结果如表2所示。
从表2中可以看到,基本SSD模型针对中等目标的mAP 值为58.5%,Chen 等提出的改进FSSD 模型的mAP 值为75.1%,本文模型对中等目标的mAP 值为75.6%,相较于基本的SSD 模型再训练拥有17.1%的提升。
在网络阈值设置为0.9 的条件下,对比不同的类别在不同模型下的小型目标的检测精确度。其结果如表3所示。
从表3中可以看到,基本SSD模型针对中等目标的mAP值为17.5%,Chen等提出的改进FSSD模型的mAP 值为40.5%,本文模型对中等目标的mAP 值为41.6%,相较于基本的SSD 模型再训练拥有24.1%的提升。

Table 2 Comparison of medium targets'mAP among different categories表2 不同类别下中等目标mAP对比 %

Table 3 Comparison of small targets'mAP among different categories表3 不同类别下小型目标mAP对比 %
图10中左边的图表示原有SSD模型再训练的目标检测结果,右边的图表示本文模型的目标检测结果。通过比较二者的结果不难看出,左图中出现了一些检测率较低或者检测不到的情况,右图中很好地对左图的情况进行了完善,对于图像数据当中的中小型目标检测效果更好,准确率也更高,该模型的效果更好。
再者,针对测试集中测试435张多目标复杂度较高的图片(诸如分类物体有交叉重叠或距离较近等特征),其中中小型目标的数量在1 153个,通过评价标准中的检测率[26]来衡量该模型在总体上的目标检测的能力,具体公式如下:

Fig.10 Comparison of detection results between SSD and model in this paper图10 SSD模型与本文模型检测效果对比

式中,P表示检测率;C为被检测图像数据样本的检测正确的数量;S表示当前与C对应的样本种类的总数。根据不同算法得到的检测率结果对比如表4所示。

Table 4 Comparison of calculation results of detection rates among different algorithms表4 不同算法检测率计算结果对比 %
从表4中可以看出,经过对所有目标检测结果的统计,本文模型的检测率相比于Chen等改进的FSSD模型提升了3.1%,相比于现有的SSD 模型经过再训练的检测率效果提升了12.8%,并且对于图像数据中的中小型目标的定位也更加明确。
在本文搭建的实验环境下,对于基本的SSD 模型再训练、Chen等改进的FSSD模型和本文模型在检测速度上也进行了比较。具体结果如表5所示。

Table 5 Comparison of detection speeds among different algorithms表5 不同算法检测速度的结果对比
从表5中可以看出,基本SSD模型再训练的检测速度可以达到每秒检测56 帧图片,Chen 等改进的FSSD模型检测速度为每秒23帧图像,本文模型的检测速度为每秒31帧图像,检测速度相比SSD模型有所下降,与改进的FSSD模型相比又有一些小的提升。
该模型的检测速度之所以相比SSD模型有所下降,原因如下:
(1)在网络结构中,对于低特征层进行特征提取时使用反卷积操作,在保留了更多的特征信息的时候,也使得数据量增大,导致计算量增大,使得计算比较耗时。
(2)在网络结构中,对于高特征层进行特征提取时由于网络结构本身的原因,增加了模型计算运行的时间。
(3)综合上面两方面的原因,使得本文模型的检测速度有所下降。
本文模型的检测速度相较于SSD模型有所上升的原因在于模型结构基于MobileNet的基本思想,使用可分离的卷积在模型计算的延迟度和准确率之间达到有效的平衡,有效减少参数的同时兼顾模型大小,使得模型的计算速度有了一定的提升。
4 结束语
为了提升目标检测的SSD模型的检测准确率及检测速度,满足其在较低的硬件资源配置条件下也能达到一般性视频流的检测速度的要求,本文根据基本SSD 模型,结合轻量级的深层神经网络MobileNet的思想,构建一种结合特征金字塔的多尺度卷积神经网络结构。结合反卷积操作、特征提取和区域映射、正负样本处理等方法改善模型对中小型占比目标的检测效果。实验结果表明,本文模型模仿精确度优于SSD 模型,且在较低的硬件配置条件下达到视频流图像处理的速度要求。在今后的研究工作中,将继续优化改进本文的网络模型,尽可能多地尝试其与更多的深度学习模型的思想相融合,进一步提升模型的检测性能。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
西安邮电大学学报(2020年1期)2020-12-17
计算机系统应用(2019年9期)2019-09-24
电子制作(2019年11期)2019-07-04
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
北京航空航天大学学报(2018年1期)2018-04-20
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
