
时序地理社交网络中基于动态偏好的组查询*
2019-11-12 05:41宋雨萌
计算机与生活 2019年11期
宋雨萌,陈 默,于 戈
东北大学 计算机科学与工程学院,沈阳 110169
1 引言
近几年,成熟的定位技术与社交网络相结合形成了新的地理社交网络(geo-social networks,GSNs),如Foursquare、Gowalla、大众点评等。和传统的社交网络相比,地理社交网络引入了地理因素,用户可以通过“签到”向他人分享自己此刻所在的地点,在地理社交网络平台与好友分享和传播信息[1-3]。签到行为包含了用户的行为趋势、生活习惯等兴趣偏好。挖掘签到数据中用户的兴趣偏好,以进行个性化且高实用性的查询对基于不同目的的用户、商家或第三方而言至关重要。然而用户的兴趣偏好倾向于随时间推移而变化。这是由于在生活中,用户在各种社交网络不断建立新的友谊,导致社交网络结构变化。而社交网络结构的关键性变化致使用户对外部事件的反应产生了改变[4]。Pereira 等人在文献[5]中通过带有地理标签的推特数据实验证明了在不同时间内的用户兴趣偏好存在差异。
受时间对用户兴趣偏好影响的启发,本文构建了一种能够检测用户动态偏好的时序地理社交网络模型。在GSNs 的签到数据中,时间是常见且必要的维度,带有时间标签的签到数据反映了用户在包含该时间戳的短时间内的兴趣偏好。因此时序地理社交网络模型对用户的社交关系信息、签到时间标签以及签到位置信息等建模,并通过动态偏好值模型评估用户的动态兴趣偏好。同时,提出了时序地理社交网络中基于动态偏好的组查询(dynamic preference-based group query,DPG),搜索附近区域中在指定时间窗口内具有特定兴趣的top-k个其他具有社交关系的用户,用于用户发起活动或商家推广活动。为优化查询算法,设计了UTC-tree(users'temporal check-in tree)索引用户时序签到记录,提高用户动态偏好值的计算速度。最后通过实验验证UTC-tree的有效性及DPG查询算法的可扩展性。
2 相关工作
近年来,地理社交网络的研究,如GSNs 中的查询与推荐[6],基于GSNs 数据的本地事件检测[7]、线上社交关系推断[8]、地点聚类[9]等问题引起了国内外学者的研究热潮,其中基于地理社交网络的查询及推荐为用户提供了更个性化的线下社交活动服务,文献[10-14]均为基于地理社交网络的查询与推荐研究,其目标旨在为用户查询符合要求的活动用户或POI(point of interest)。在一些用于发起活动的查询中,为了取代活动发起者手动选择活动参与者用户组,保证活动参与者用户组的社交熟悉度,许多工作中也提出了多种不同类型的组查询。文献[15-20]是用于不同场景的组查询研究。在基于地理社交网络的研究中,大量的时空数据索引研究被用于加速不同的查询方法,其中包括空间索引的研究、时间索引的研究等。文献[21-31]均为可用于基于地理社交网络查询的时空数据索引研究。
下面对与本文相关的基于地理社交网络的查询与推荐研究、组查询研究及时空数据索引研究三方面进行介绍:
(1)基于地理社交网络的查询与推荐研究。文献[10]提出一种基于签到记录的无监督时空嵌入方法,对地点、时间、用户进行编码,用于多种个性化推荐任务。Wang等人提出一种用于POI推荐的时序个性化模型TPM(temporal personalized model)[11],TPM引入Topic-Region潜在变量,对用户偏好的有序性与循环性进行建模,显著缩小预测空间,有效缓解数据稀疏性。Lian等人提出了一种基于隐式反馈的内容敏感协同过滤框架[12],解决POI推荐中的新用户冷启动问题。以上地理社交网络中的推荐模型侧重于对POI 推荐的研究,并不能完全适用于DPG 查询场景。文献[13]提出RkGSK(reverse top-kgeo-social keyword query),考虑距离、文本和社交信息为地理标记对象查询潜在客户。文中提出了混合索引GIMtree 和有效的剪枝策略解决RkGSK 查询。文献[14]提出KNNIG(K-nearest neighbor based interest group query),查询通过用户历史签到数据提取用户的兴趣值,并考虑用户兴趣值和空间距离两方面因素,使用网格索引及剪枝算法为用户返回距离其较近并且与其有一样兴趣爱好的k个其他用户的集合。以上两种查询分析用户兴趣时,并未考虑用户的动态偏好可能导致查询结果的偏差。DPG查询通过用户的签到地点与时间分析用户的动态偏好,保证用户对查询关键字在近期内具有较高的兴趣。且大多数基于地理社交网络的查询在考虑地理因素时使用不能精确衡量用户之间真实距离的欧式距离,无法满足真实的查询需求。
(2)组查询研究。NSG(nearest star group query)[15]检索m个用户的最近k个子图,其中每个子图中有一个用户与其他所有用户有社交关系。GSGQ(geosocial group query)[16]查询具有最小的好友约束的用户组,保证一个有凝聚力的群体。Yang 等人提出STGQ(social-temporal group query)[17],查询考虑了候选者的可用时间和社交关系,为用户寻找最佳的活动时间和社交关系最亲近的参与者用户组,使用有效的剪枝技术与枢轴时间槽的思想减少运行时间。Hung 等人提出用户社区发现框架,使用概率后缀树结构存储用户轨迹信息[18],并对轨迹之间的距离使用聚类算法形成不同用户组社区。Li 等人提出SaRG(social-aware ridesharing group query)[19],通过考虑社交关系和空间最近邻查询一组乘客,由于SaRG 查询是一个NP 难问题,文中提出一组剪枝技术与几种增量策略减少重复计算。文献[20]为用户查询一个包含查询顶点的具有共同价值观的空间敏感社区,保证社区内具有高度结构内聚性与空间内聚性。其中结构内聚性主要衡量社区的社交关系,空间内聚性主要衡量社区地理位置的紧密程度。提出的DPG查询更关注组成员的共同兴趣偏好而不是他们的社交关系与地理距离。以上组查询不完全符合DPG 查询背景,无法评价用户组动态偏好和用户组中空间路网距离关系。
综上所述,本文提出的DPG查询其优势在于,不仅考虑空间及社交关系的约束,同时考虑用户的动态偏好,获取较好的查询效果。在空间上考虑用户之间的路网距离,保证更有实用价值的查询工作。在查询中使用剪枝算法提高查询效率。
(3)时空数据索引研究。在数据索引方面,许多空间索引可用于最近邻查询,但它们只关注空间维度,无法处理时间维度,不能用于DPG查询,例如,网格索引、R-tree索引、四叉树索引等。网格索引[21-22]是将空间划分成相同大小或不同大小的网格,查询时首先计算查询区域覆盖的网格单元,再在具体网格中查找对象。网格索引易于实现,可以快速查找符合条件的对象。R-tree 索引[23]使用最小外接矩阵(minimum bounding rectangle,MBR)作为存储节点,中间层节点的MBR覆盖所有孩子节点的MBR,实体存放在叶子节点的MBR中。R-tree索引能够有效提高存储和查询的效率。四叉树索引[24]是一种基于空间划分的索引结构。四叉树索引将整个空间区域递归划分成不同层次的树结构,每个子空间区域划分为大小相同的四个区域。当数据均匀时,四叉树索引具有较高的空间数据插入和查询效率。一些相关的索引也不能适应DPG 查询,例如B-tree(selftunable spatio-temporal B+-tree)[25]、RUM-tree(R-trees with update memos)[26]、TPR*-tree(time parameterized R*-tree)[27]等时空索引主要关注于对可预测轨迹的移动对象的索引,并不能应用于DPG 查询。SWST(sliding window spatio-temporal index)[28]和PIST(practical index for spatio-temporal)[29]可用于索引离散移动的目标,但不能有效索引空间中的文本信息。aRB-tree[30]由R-tree和B-tree组合而成,每一个R-tree中的区域指向一个B-tree,B-tree 中存储每一个时间标签下在该区域的历史集合。Tao等人在文献[31]基础上提出sketch索引,解决了aRB-tree不能重复计数的问题,即某对象在不同时间标签访问同一区域。但由于B 树不能索引时间间隔,因此无法对以上索引进行时间间隔的调整,若在等长的时间间隔下,仅根据空间范围进行索引不能有效加速DPG查询。
综上,已有的相关索引不适用于本文提出的DPG 查询。为此,本文提出新的索引UTC-tree 加速DPG 查询,其优势在于同时考虑时间、动态偏好、用户三种约束,使用B+树对时间维度进行索引,使用Bloom计数过滤器对用户id与兴趣标签进行过滤,在查询过程中可对UTC-tree 进行快速剪枝,有效提高动态偏好值的计算速度。
3 问题定义
3.1 时序地理社交网络模型
签到数据中,签到地点与用户兴趣偏好相关,签到时间标签则反映了用户偏好的时序性,而现有的地理社交网络查询研究中[10-14],地理社交网络模型并未包括用户的签到时间信息,无法评估用户的动态偏好。因此,本文构建了时序地理社交网络模型用于用户的动态偏好研究。时序地理社交网络为一无向图,用三元组G(U,P,E)表示,其中:
(1)U={u1,u2,…,un}为用户节点集合。
(2)P={p1,p2,…,pn}为兴趣点节点集合。每个兴趣点pi与一个兴趣标签集合相关联,表示在pi签到的用户具有中的兴趣偏好,例如在羽毛球馆签到的人则对羽毛球感兴趣偏好。
(3)E=EUU∪EUP是网络中所有边的集合。EUU={(ui,uj)|ui∈U,uj∈U}表示用户-用户边集合,即该边连接的两个节点ui、uj是好友关系。EUP={(ui,pj)|ui∈U,pj∈P}表示用户-兴趣点边集合,即用户ui在兴趣点pj进行签到行为。每个用户-兴趣点边e(ui,pj)与一个时间标签集合Ti-j相关联,表示用户ui在兴趣点pj的签到时间,其中是ui在pj点第k次签到的时间戳(精确到秒),对于任意
图1是一个时序地理社交网络示意图,其中“●”为用户,“▲”为兴趣点,兴趣点附近的矩形框中为兴趣点相关的兴趣标签集合,实线表示用户之间的社交关系,虚线表示用户与兴趣点的签到关系,虚线中的时间标签集合表示用户于相应兴趣点的签到时间标签集合。由图可知,用户u1与u2为好友关系,且都于兴趣点p1签到,p1与兴趣标签h1、h2、h3相关。u1分别于在p1进行过4次签到。用户u7与图中任何人都不是好友,他分别于在p3签到3次,于在p4签到1次。
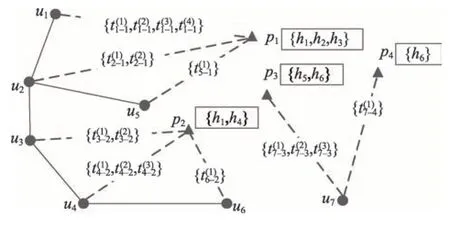
Fig.1 Example of temporal geo-social network图1 时序地理社交网络示意图
3.2 动态偏好值模型
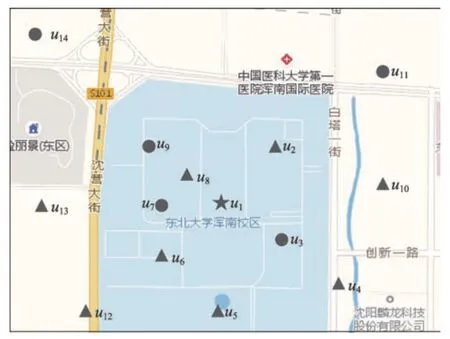
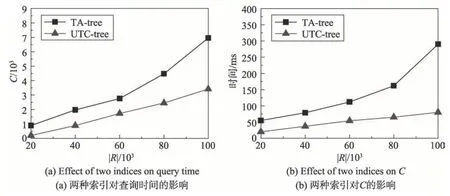
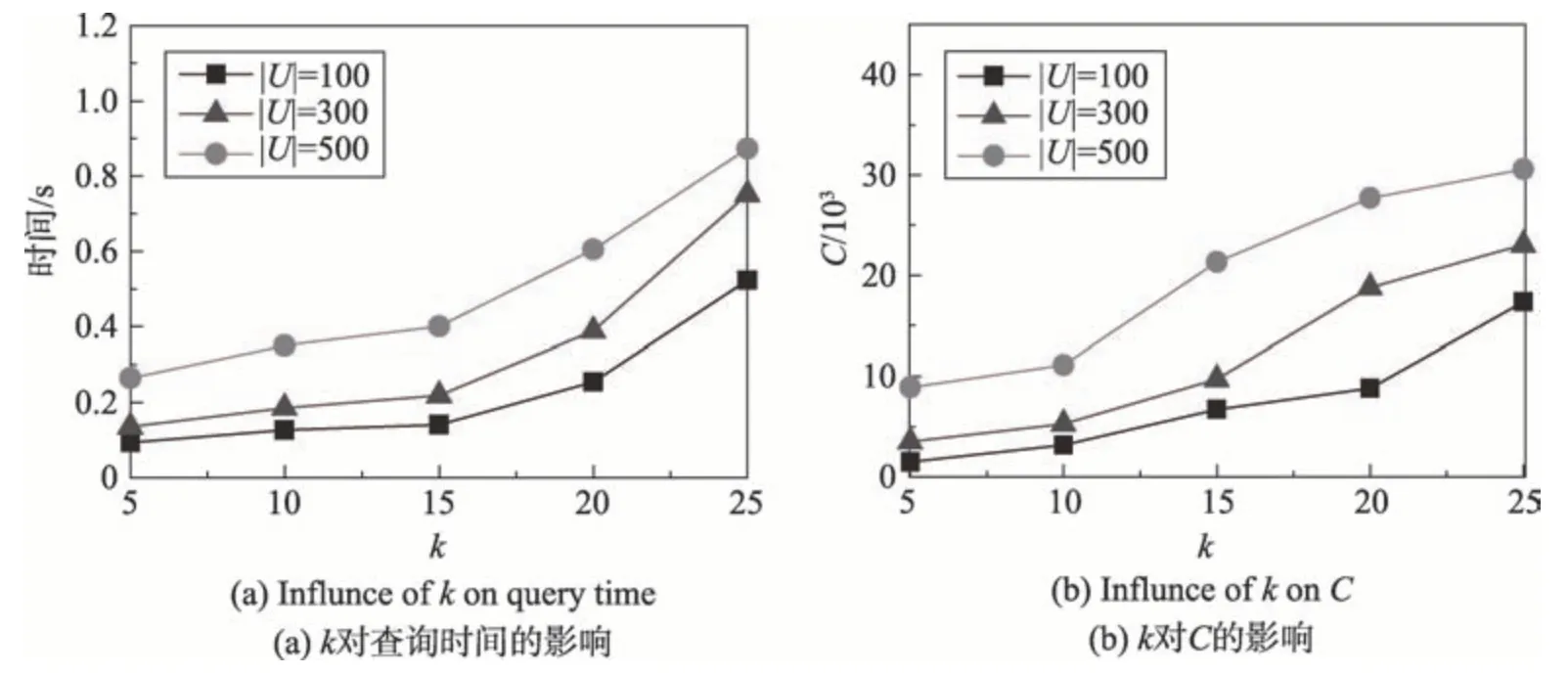
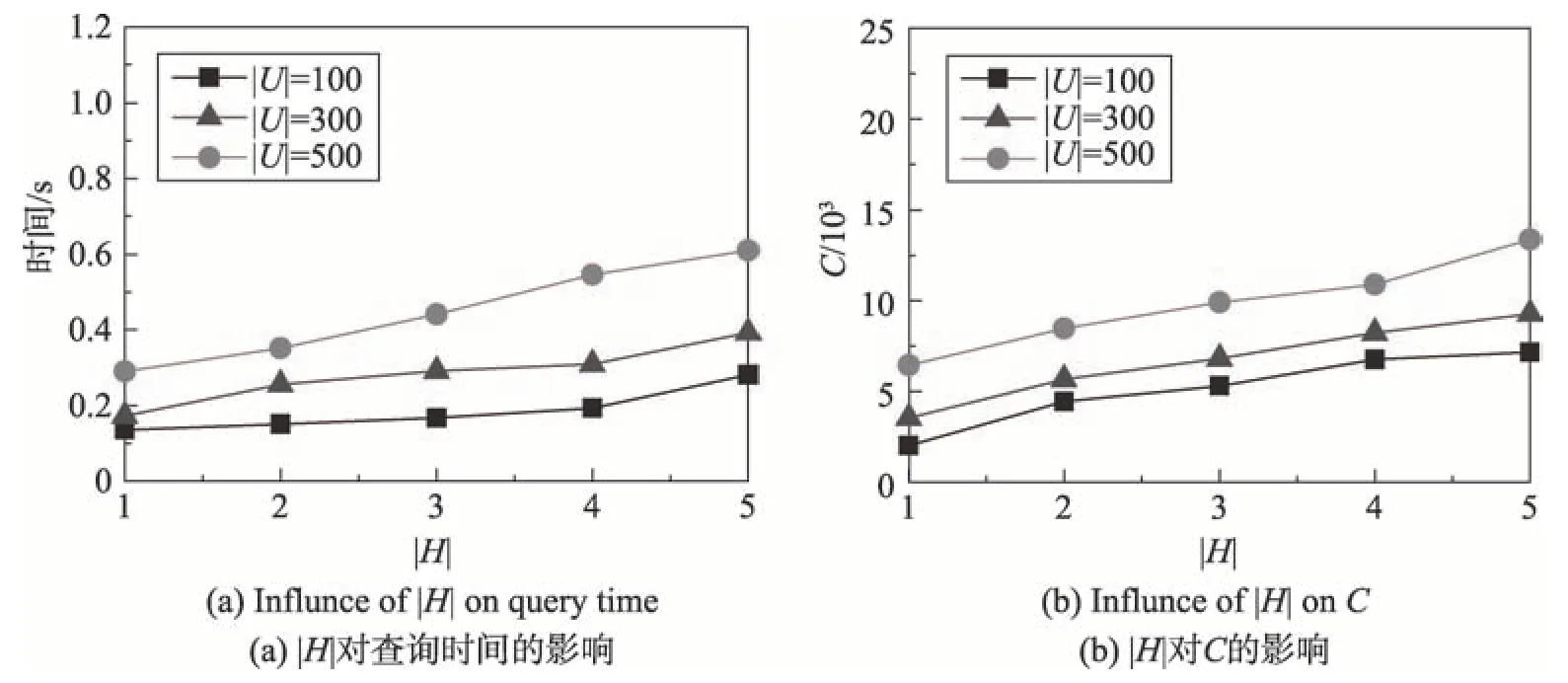
设U为用户集合,其中每个用户u(u∈U)为一个二元组,用表示。其中,id为用户的唯一身份标识,如该用户在某社交网络中的用户名,为用户的动态偏好向量,记录了该用户在时间窗口 定义1(动态偏好值)用户u在时间窗口 其中,Du表示用户u在时间窗口 表1 为用户u1在时间窗口<2018-05-01 00:00:00,2018-05-07 23:59:59>的动态偏好向量。动态偏好值越大表示用户近期对该兴趣标签越感兴趣。如表1所示,在过去一周内用户u1对“运动”比“读书”更感兴趣。 Table 1 Example of u1's dynamic preference vector in<2018-05-01 00:00:00,2018-05-07 23:59:59>表1 用户u1在时间窗口<2018-05-01 00:00:00,2018-05-07 23:59:59>的动态偏好向量 Fig.2 Location of u1and surrounding users图2 u1及周边用户位置图 Table 2 User data of u1's friends表2 u1好友的用户数据 基于时序地理社交网络模型及动态偏好值模型,提出DPG 查询。DPG 查询为用户在附近区域内搜索当前距离最近且近期对某兴趣标签集合的动态偏好值最高的社交好友用户组。图2 和表2 为DPG查询的一个示例。图2为用户u1及周边用户位置图,其中“★”为用户u1所在位置,“▲”为u1好友所在位置,“●”为非u1好友所在位置。u1发起查询,查找3名好友共同打羽毛球。表2为u1好友当前距u1的距离,以及最近一个月、三个月、半年、一年内对羽毛球的偏好度。其中A 为高偏好度,B 为中偏好度,C 为低偏好度。偏好度即用户对某兴趣标签的热衷程度,若某用户在一时间窗口内多次参加同一活动,则认为用户对该兴趣有高偏好度。若u1的查询距离为1 500 m 内,当动态偏好查询时间窗口为一个月时,DPG 查询将会返回结果集{u2,u5,u8},该结果集较其他用户集而言距用户u1较近且在最近一个月内对羽毛球偏好度较高,将更适合参与该次活动。当动态偏好查询时间窗口为三个月时,由于u5在三个月内对羽毛球偏好度很低,而距u1较远的u4在三个月内对羽毛球具有中偏好度,故DPG 查询的查询结果集为{u2,u4,u8}。 定义2(动态偏好评分函数)动态偏好评分函数I*(u,q.H, |q.H|为兴趣标签集合中的兴趣标签个数,Ihmax为候选用户在时间窗口 假设DPG 查询q1的兴趣标签集合为q1.H1={“运动”},DPG 查询q2的兴趣标签集合为q2.H2={“音乐”},q1、q2的查询时间窗口均为<2018-05-01 00:00:00,2018-05-07 23:59:59>,且I“音乐”max=I“运动”max,在表1 中,用户u1在时间窗口内对q1.H1的动态偏好评分高于对q2.H2的动态偏好评分。 为了真实评价用户之间的距离,查询距用户最近的k个其他好友,DPG查询使用路网距离计算用户间距离。 定义3(路网距离)路网由一带权无向图G=(V,E,W)表示,其中V为路网中所有节点的集合,E为路网中两个节点之间的道路e的集合,W为e的权值集合。每条道路e的权值w表示两个相邻节点之间的路网距离。 若某用户u位于边e=(vi,vj)上,u与节点vi之间的长度为lu,则u在路网上的位置表示为 定义4(DPG 查询评价函数)Rank(G,q)评价候选用户集合G(|G|=k)对DPG查询q的符合程度,该函数考虑了动态偏好值与距离两方面影响因素。 Dmin为当前距查询发起点q.l最近的k个用户到q.l的路网距离和,∑u∈Gdist(u,q.l)为当前检验的用户集合G中用户到q.l的路网距离和,dist(u,q.l)为用户u的位置点u.l与查询发起点q.l之间的路网距离,q.H为兴趣标签集合,∑u∈GI*(u,q.H, 定义5(基于动态偏好的组查询,DPG)给定查询用户q.u、查询兴趣标签集合q.H、查询点q.l、查询范围半径q.r、查询时间窗口 DPG 查询系统的框架如图3 所示,包括用户界面、用户模块、好友模块、签到模块、DPG 查询模块5个功能模块以及数据库。DPG查询模块实现DPG查询算法。DPG查询算法使用用户时序签到记录索引UTC-tree计算用户动态偏好值,避免大量签到记录的遍历,再由剪枝算法过滤距离或动态偏好值不符合要求的用户,生成结果用户集。UTC-tree由签到记录及POI数据生成,根据兴趣标签及时间窗口筛选签到记录,加速用户动态偏好计算,优化DPG 查询速度。用户实时定位数据为DPG查询提供准确的用户经纬度位置,联合路网数据可计算用户间的路网距离。用户好友关系数据存储具有好友关系的用户,由好友模块进行维护,用于满足DPG查询的好友约束。 4.2.1 UTC-tree索引构建 DPG 查询对签到记录与POI 数据建立UTC-tree索引,UTC-tree索引可以避免遍历所有签到记录而进行动态偏好评分计算,加速DPG 查询。UTC-tree 索引受TA-tree(temporal activity tree)[32]的启发,TA-tree是一嵌入Bloom 过滤器的B+树索引,叶子节点由数据项组成,其中ui为用户身份标识,tp为ui参与活动ak的时间标签,为描述ak的关键字集合。B+树以tp为关键字构建,内部节点中每个指针嵌入一Bloom过滤器,Bloom过滤器由当前指针指向的叶子节点中每个数据项的生成。由于TAtree中的Bloom过滤器只通过过滤关键字加速查询,无法对用户id 进行筛选,同时普通的Bloom 过滤器无法删除数据,无法进行索引的动态维护,故不适用于DPG查询。 Fig.3 DPG query system architecture图3 DPG查询系统框架 图4是一个UTC-tree索引示例。与TA-tree索引相似,UTC-tree也是一种B+树,但在内部节点的每个指针中嵌入Bloom 计数过滤器。使用Bloom 计数过滤器替代Bloom 过滤器的优势在于前者能对过滤器中元素进行删除,而后者不能。UTC-tree叶子节点中的数据项为签到记录三元组 Fig.4 Example of UTC-tree index图4 UTC-tree索引示例 在UTC-tree中,Bloom计数过滤器的哈希函数的选择会影响过滤的错误率[33],当哈希函数个数k=(ln 2)×(m/n)时,错误率最小,其中m为位数组的大小,n为输入元素个数。由于UTC-tree 中签到记录条数随时间增加而增加,为保证Bloom计数过滤器的有效性,DPG 查询对UTC-tree 实行增量更新策略。在建立UTC-tree 时设Bloom计数过滤器输入元素个数为n*,n*=|R|+α|R|,α∈[0,1],其中|R|为当前签到记录条数,α为可新增签到记录条数与全部签到记录条数之比。当新增签到记录时,使用变量count对新增签到记录条数进行计数,若count≤α|R|,则直接将记录加入UTC-tree,否则重新构建UTC-tree。当n*-|R|较大时,将减少整体更新次数,但会牺牲过滤的准确性。若n*-|R|较小,可以保证过滤时具有较低的错误率,但需要在短时间内整体更新多次。 4.2.2 基于UTC-tree的优化算法 下面给出UTC-tree 的优化查询过程,分别采用UTC-tree 叶子节点查询算法和UTC-tree 动态偏好评分算法实现。UTC-tree 叶子节点查询算法用于查询UTC-tree 节点node的子树中包含特定的签到记录{ 算法1UTC-tree 叶子节点查询算法LeafNode Query(node,ts,te,q.H,q.U) 输入:UTC-tree的节点node,时间窗口起始时间ts,时间窗口终止时间te,兴趣标签集合q.H,待选好友用户集合q.U。 输出:node节点子树中包含签到记录{ UTC-tree 动态偏好评分算法能够快速查询用户u在时间窗口 算法2UTC-tree 动态偏好评分算法getIstar(u,q.H,ts,te,root,Ihmax) 输入:用户u,兴趣标签集合q.H,时间窗口起始时间ts,时间窗口终止时间te,UTC-tree 根节点root,候选用户在时间窗口内对查询兴趣标签h的前k个动态偏好值之和Ihmax。 输出:用户u的动态偏好评分Istar。 DPG查询使用UTC-tree加速计算用户动态偏好评分,快速过滤候选用户,并采用剪枝策略对候选用户进行剪枝,加快查询速度。算法伪代码如算法3所示。算法首先使用UTC-tree叶子节点查询算法在时间窗口 算法3DPG查询算法 输入:候选好友用户集合U,查询兴趣标签集合q.H,查询点q.l,查询范围半径q.r,UTC-tree根节点root,查询用户数k,起始时间ts,终止时间te。 输出:结果集G。 DPG查询算法示例图5是一个DPG查询算法的运行示意图。查询q的查询中心为q.l,查询人数k=2,查询兴趣标签集合H={“羽毛球”},时间窗口 Table 3 Example of DPG query algorithm表3 DPG查询算法示例 如图5(a)所示,首先u1、u2出队,初始结果集G={u1,u2},结果集G的DPG查询评价函数值为Rankmax=0.594。在图5(b)中,u3出队,依次替换G={u1,u2}中的用户。当u3替换u1时,=0.656;当u3替换u2时,。两次替换中最大的,则u3替换u2,更新G={u1,u3},Rankmax=0.801。在图5(c)中u4出队,依次替换u1、u3,故不更新G。由于I*(u5,q,H, 为更好地满足用户的查询需求,DPG 查询算法提供增量更新算法,以保证在滑动的查询时间窗口中可以动态地根据其他用户新增和删除的签到记录更新DPG查询结果集。增量更新算法首先对在新时间窗口中新增签到记录的用户集U*中的每个用户u*计算签到记录绝对增量A(u*),A(u*)=|W(u*)′-W(u*)|-|W(u*)-W(u*)′|,若A(u*)>0 则将u*加入增量候选集合U′。其中W(u*)为原时间窗口中的用户u*在含有DPG 查询兴趣标签集合q.H的POI 点签到的签到记录集合,W(u*)′为新时间窗口中用户u*在含有DPG查询兴趣标签集合q.H的POI 点签到的签到记录集合,|W|为W集合中签到记录的条数。对于每个u′∈U′,根据距q.l的路网距离升序加入增量候选队列queue′。将queue′中的用户依次出队,执行算法DPG查询算法第14至19行,通过相同的剪枝算法计算用户是否能替换结果集G中的用户,新的用户结果集G′即是增量更新的DPG查询结果。 Fig.5 Running example of DPG query algorithm图5 DPG查询算法运行示例图 本文提出的DPG查询算法的时间复杂度由动态偏好评分计算开销和选择计算开销两部分组成。动态偏好评分计算开销是由于通过筛选签到记录计算动态偏好评分引起的,选择计算开销是由计算DPG查询评价函数引起的。假设n为全部候选用户,α为查询范围内需要计算动态偏好评分的用户占全部候选用户的比例,m为平均每次查询遍历UTC-tree的叶子节点数,p为每个叶子节点索引的签到记录数,k为查询人数,则DPG查询算法的动态偏好评分计算开销为O(αn×mp),选择计算开销为O(k×αn)。对于增量更新算法,假设β为签到记录绝对增量A(u)大于0 的用户占全部候选用户的比例,则增量更新。算法的动态偏好评分开销为O(βn×mp),选择计算开销为O(k×βn)。由于增量更新算法选择签到记录绝对增量大于0的用户进行更新计算,故β≤α,可见增量更新算法在动态偏好评分计算和选择计算两方面较重新计算查询结果的更新方法节省了开销。 实验环境为PC 机,操作系统为64 位Microsoft Windows 7 旗舰版SP1,使用MyEclipse 作为开发工具,使用java编写完成。实验数据使用来自地理社交网站Gowalla在2009年2月到2010年10月用户签到及好友关系的真实数据集[34]。数据集中包括195 485个用户在2009 年1 月至2010 年12 月之间产生的6 442 887条签到信息,签到记录包括用户id、签到时间、签到经纬度信息,同时数据集中还包含1 900 654条以上用户的好友关系信息、好友关系信息记录用户与其好友的id。 在实验中,用户签到记录相关的兴趣标签信息为模拟产生,为满足用户的兴趣分散性,对每条签到记录生成1~3个兴趣标签。在以下实验中,每一组实验查询100次,最终求出平均值作为实验结果。 根据DPG 查询算法实现了一个DPG 查询系统。DPG 查询系统由jsp 完成界面设计,java 编写系统内核模块,使用mySQL1.5 数据库,Strut2 框架,Tomcat8 服务器。DPG 查询系统包括登录、立即签到、发起活动、好友中心、活动中心等功能,提供用户个人信息维护、社交关系维护、活动数据维护、DPG查询等功能。DPG查询系统主界面如图6所示。 为了获取精确的DPG 查询结果,DPG 查询需要实时获取用户的精确位置及路网距离以计算DPG查询评价函数值Rank(G,q)。现在市面上已有较多的成熟的地图开发工具,DPG 查询系统使用第三方地图API、百度地图API[35]。百度地图API 可支持GPS、Wi-Fi、基站融合定位,获取用户的实时经纬度位置。通过经纬度位置,快速计算用户之间的实时路网距离。图7 为DPG 查询系统使用百度地图API 建立的uid为Michelle 的用户uq的好友地图。在图7(a)中,好友地图中uq所在位置为没有姓名标签的跳动红色标志点,图中共有6位在uq所在位置附近的好友,以静止红色标志点表示,红色标志点右上角为好友uid。用户可使用鼠标对地图显示范围和精度进行自由调节,同时可更换卫星及三维地图。图7(b)为uq与Lisa 的路网距离显示。淡绿色虚线为uq与好友Lisa所在位置之间的路网路线,信息框中为两人的路网距离。 Fig.6 Main interface of DPG query system图6 DPG查询系统主界面 Fig.7 Friends map图7 好友地图 本节将研究UTC-tree 索引与TA-tree 索引在建立时间、生成树空间大小、对DPG 的查询时间、I/O代价的影响及增量更新参数α对误差率的影响。 对于索引建立方面,使用两种索引对签到记录条数|R|为20 000、40 000、60 000、80 000、100 000时分别生成UTC-tree 索引以及TA-tree 索引,记录建立时间与生成树空间大小,如图8(a)(b)所示。随着签到记录条数的增加,TA-tree 与UTC-tree 的建立时间和生成树空间大小呈线性增加。由于UTC-tree 中的Bloom 计数过滤器中较TA-tree 还包含了用户身份表示的索引信息,故在建立时间上与生成树空间大小上UTC-tree较TA-tree略有增加,但都不超过TA-tree的1/3。 在研究两种索引对DPG 查询的影响中,使用20 000、40 000、60 000、80 000、100 000条签到记录建立UTC-tree 和TA-tree 索引进行DPG 查询,其中k=5,q.r=5 km, Fig.8 Effect of UTC-tree and TA-tree indexes on establishment图8 UTC-tree与TA-tree索引在建立方面的影响 Fig.9 Effect of UTC-tree and TA-tree on DPG group query图9 UTC-tree与TA-tree索引在DPG查询方面的影响 图9(b)为两种索引对查询中访问叶子节点次数C的影响。图中使用TA-tree索引查询访问叶子节点次数均多于UTC-tree,当|R|=100 000 时,使用UTCtree 索引的查询访问叶子节点次数较TA-tree 减少了51%。图9(a)(b)证明了在DPG查询中,UTC-tree较TA-tree 过滤了更多不符合查询条件的叶子节点,有效减少访问叶子节点次数,减少I/O代价。 对于UTC-tree 的增量更新方面,α对Bloom 计数过滤器的误差率E的影响如图10 所示,其中|R|为签到记录条数。随着α增加,误差率将逐渐增大。当α>0.5 时,误差率几乎全部超过50%。在实际应用中,可按照需要调节α,并选取适当的位数组位数,可保证Bloom计数过滤器的准确性。 Fig.10 Effect of α on error rate of Bloom counting filter图10 α 对Bloom计数过滤器误差率的影响 5.3.1 查询半径q.r分析 本节将讨论查询范围q.r对查询时间和查询中访问的叶子节点的个数C的影响。在5.3 节的实验中,DPG 查询均使用由200 000 条签到记录生成的UTC-tree。如图11(a)所示,在用户好友人数|U|为100、300、500条件下,随着q.r由1 km增加至10 km,查询时间均未超过0.8 s。如图11(b)所示,随着查询半径增长,由于加入查询队列queue的用户数增加,查询中访问叶子节点次数C不断增长,当q.r增长为原来的10 倍时,C不超过原来的4 倍。实验结果表示DPG查询算法对q.r具有良好的扩展性。 5.3.2 查询用户数k分析 图12(a)(b)测量了不同的k(取值范围为5 至25)对查询的影响。如图12(a)所示,DPG 查询对不同的k具有均较低的查询时间。对于k为5至15时,查询时间低于0.5 s,这是因为当k较小时,DPG查询算法的结果集G中元素个数首次达到k后,queue中待选用户较多,DPG 查询算法中的剪枝方法能快速有效地剪除queue中多余的候选用户。而当k取值大于15 时,结果集G中元素个数首次达到k后,queue中只留有较少的待选用户,降低了剪枝的可能性与有效性,故延长了查询时间。k的增加也会引起C的增长。如图12(b)所示,k每增加5 人,C增长率为31%~53%。这是因为当k增大时,算法遍历更多用户动态偏好信息以满足查询人数的需求。图12(a)(b)表明随着k的增长,查询时间和空间开销依然能基本满足实际应用。 Fig.11 Influnce of q.r图11 q.r的影响 Fig.12 Influence of k图12 k的影响 5.3.3 查询兴趣标签|H|分析 图13(a)给出了|H|对查询时间的影响。随着|H|由1 增长至5 时,查询时间小幅增加,平均增长小于0.5 s。图13(b)给出|H|对C的影响。实验显示,C随|H|的增长较为平缓。查询时间和空间开销的增长是由于查询兴趣标签集合中的兴趣标签数越多,用户的动态偏好评分越低,导致DPG 查询算法在剪枝操作中最低动态偏好评分降低,影响剪枝算法的效率。两实验证明了DPG 查询算法对|H|具有良好的扩展性。 5.3.4 时间窗口参数分析 图14研究了时间窗口大小对查询时间及C的影响。如图14(a)所示,在不同大小的时间窗口Δt中,DPG 查询算法能快速地完成查询工作,且随着时间窗口的增加,查询时间曲线增长平缓,增幅小于0.5 s。图14(b)为Δt对C影响,随着Δt由30 天增长至360天,C缓慢增长。Δt直接影响访问UTC-tree时通过时间关键字t查询的叶子节点个数,故查询时间和空间开销都有所增加。实验表明,DPG 查询算法可以满足在不同大小的时间窗口Δt下的DPG查询。 Fig.13 Influnce of|H|图13 |H|的影响 Fig.14 Influence of Δt图14 Δt 的影响 本文基于当今非常热门的地理社交网络,对用户好友关系、位置关系、动态偏好进行建模,构建了一个时序地理社交网络模型,并提出可满足社交关系-空间-动态偏好三重关系的基于动态偏好的组查询,DPG 查询。用户可通过DPG 查询搜索附近区域内近期具有特定兴趣和社交关系的k个其他用户。同时,实现了交互良好的DPG 查询系统并通过实验验证了查询算法的有效性、可靠性与可扩展性。DPG查询可用于地理社交平台上的组类活动的构建和维护,提高用户社交活动的多样性和高效性。未来研究工作将对该类地理社交应用进行更多的查询语义挖掘,对用户画像进行更详尽的描述,同时将进一步研究该类查询的高效增量维护算法。

3.3 DPG查询定义

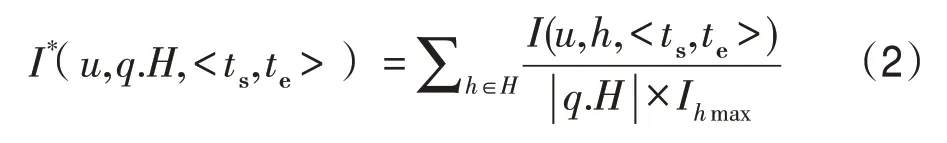

4 DPG查询
4.1 DPG查询系统框架
4.2 UTC-tree索引




4.3 DPG查询算法



4.4 算法复杂度分析

5 实验结果与分析
5.1 DPG查询系统实现

5.2 UTC-tree性能分析


5.3 DPG查询性能分析

6 结束语
 猜你喜欢
卫星应用(2022年7期)2022-09-05卫星应用(2022年3期)2022-05-23卫星应用(2022年1期)2022-03-09河南科技学院学报(自然科学版)(2020年2期)2020-05-22小型微型计算机系统(2020年5期)2020-05-14火力与指挥控制(2020年1期)2020-03-27环球慈善(2019年6期)2019-09-25World Journal of Diabetes(2019年3期)2019-04-16车迷(2018年11期)2018-08-30海峡姐妹(2018年3期)2018-05-09
猜你喜欢
卫星应用(2022年7期)2022-09-05卫星应用(2022年3期)2022-05-23卫星应用(2022年1期)2022-03-09河南科技学院学报(自然科学版)(2020年2期)2020-05-22小型微型计算机系统(2020年5期)2020-05-14火力与指挥控制(2020年1期)2020-03-27环球慈善(2019年6期)2019-09-25World Journal of Diabetes(2019年3期)2019-04-16车迷(2018年11期)2018-08-30海峡姐妹(2018年3期)2018-05-09
