
基于多特征融合的人体行为识别∗
2019-11-12 06:38:34刘昕张冰
计算机与数字工程 2019年10期
刘 昕 张 冰
(江苏科技大学电信信息学院 镇江 212003)
1 引言
如今的生活中,人们对计算机的依赖程度越来越深,视频作为传递信息的载体也具有获取快捷、内容丰富、表现直接等突出优势。而基于视频的人体行为识别主要是通过计算机对外部传感器采集到的视频序列,采用模板匹配、状态空间、基于模型等方法进行处理、分析、学习并理解其中人的动作行为。近年来,为了进一步提高识别率,Niebles[1]等提出了将几何信息引入到概率潜在语义分析模型中,这类高层语义分析方法可以有效提高识别率[2],但同时存在复杂度高,耗时长等问题。因此,如何在提高识别率的同时又将计算复杂度控制在一定范围内,就成为了当前研究行为识别的焦点之一[3],而特征融合恰好可以解决这一问题。
单一的特征虽然也可以较为准确地描述视频中人体行为的运动信息,但是它只能表达动作的部分属性,不同的特征描述的视频信息的侧重点也不同,所以仅仅使用单一的特征表达的信息比较片面,无法准确全面地描述人体运动,从而限制了行为识别准确度的提高。多特征融合将多种信息以一定的方式进行合并,使不同的信息相互补充,既可以更加准确地表征运动,又可以减少信息冗余,在精度和效率上都有较大的优势。本文提出了一种基于特征融合的描述方法,选取三维梯度方向直方图(3DHOG)与三维光流方向直方图(3DHOF)作为特征融合的基础。
2 人体行为识别框架
本文主要对人体行为识别技术进行探究,那么对人体的特征提取是必不可少的。特征一般可以分为全局特征和局部特征。相对于全局特征,局部特征具有良好的鲁棒性,而时空兴趣点就是常用的局部特征之一[4]。在对运动人体提取到兴趣点之后,采用融合了三维梯度直方图(3DHOG)与三维光流方向直方图(3DHOF)的新特征描述子对提取到的兴趣点进行量化描述,得到一个多维特征向量。对该特征使用视觉词袋模型BOW 进行降维处理[5],最终通过支持向量机SVM进行识别[6]。

图1 人体行为识别框架
2.1 背景分割
人体行为识别过程中,运动中的人体才是研究目标,而时空兴趣点的检测对复杂背景较为敏感。因此,在对视频序列的处理中,如何减少来自背景中的无关兴趣点十分重要。背景减除法在获取视频中人体运动部分和去除无关背景信息方面,能够发挥很好的效果。但是,对于视频来说,如果摄像机静止,场景固定,就可以认为背景是已知的,然而实际情况下,视频的背景也会发生变化,那么背景模型的建立和不断更新就显得尤为重要。为了解决这一问题,本文采用混合高斯背景建模的方法提取出前景[7],可提取出完整的前景目标,如图2(a)所示。
图2(a)中是混合高斯背景建模法提取的前景目标,(b)是KTH数据库中walk的一帧。

图2 (a)混合高斯背景建模法提取的前景目标;(b)KTH数据库中walk的一帧
2.2 提取时空兴趣点
在对图像序列的处理过程中,总是关注变化较为明显的部分。因此,我们对图像中像素点变化强烈的点非常感兴趣,这些变化强烈的像素点包含了图像的大部分信息,目标可以用这些兴趣点进行可区别的表示。本文采用局部特征对目标信息进行表示,这样可以有效避免目标遮挡、目标形态变化等复杂情况。
比较主流的兴趣点检测有3D-Harris时空兴趣点检测算法,该算法对于变化强烈的局部特征,具有很好的提取效果,但是该算法得到的时空兴趣点在数量上较少,只能在动作方向发生改变时才能发挥更好的作用。对于一些变化程度较小的运动不能够有效提取到足够的兴趣点。虽然视频处理提倡使用稀疏的局部时空特征,但是获得的时空兴趣点太少时,就不能把视频中的运动信息表述清楚。为了弥补这一缺点,本文采用Dollar 时空兴趣点检测[8],该方法检测到的时空兴趣点要比3D-Harris算法提取到的兴趣点稠密的多,具体原理如下:
I(x,y,t)为一个视频序列,R为响应函数

其中,g( x,y;σ2)用来进行空间域滤波,是一个二维高斯平滑核函数:
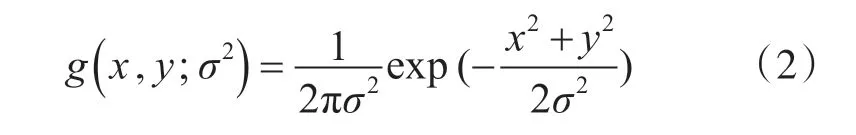
用Gabor 滤波器对时间维度进行滤波,hev和hod是一对正交的Gabor滤波器:

实验过程中,判断像素点是否为时空兴趣点,要先设定Dollar 算法的阈值λ,将响应函数R 的局部最大值与阈值λ 的大小进行比较,若响应函数值大于λ 就认为该点为时空兴趣点。设置λ 的大小就可以控制时空兴趣点的数量。
3 时空兴趣点描述
3.1 3DHOG描述子
3DHOG 即三维空间的梯度方向直方图[9],它是二维HOG 描述在三维空间的继承与扩展,该描述子继承了其在二维平面上,对光照变化的良好抵抗性。由于时空兴趣点在不同时间和空间尺度下,对其领域进行描述时,所描述的立体大小是不同的,因此描述子所描述的三维空间区域随着当前的时间尺度和空间尺度的变化而变化[10]。
为了得到三维空间的梯度,这里使用积分视频,方便计算和实现。
1)计算梯度
v(x,y,t)是一个视频序列,vx、vy、vt分别是对x、y、t 方向的偏导,则积分视频可以定义为
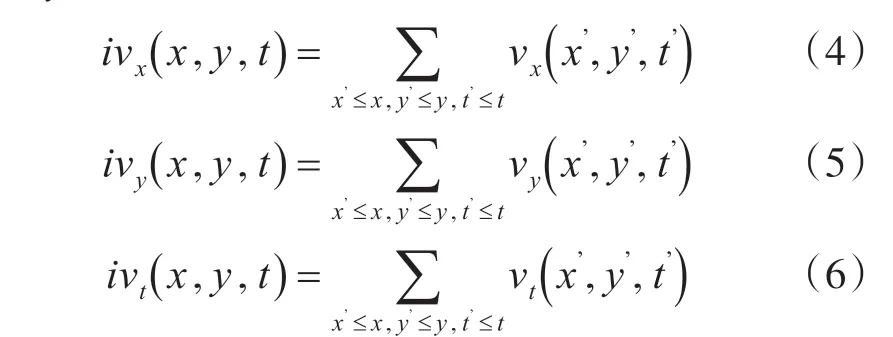
a=(x,y,t,w,h,l)T表示宽、高、长分别为w、h、l的视频立方体,a=(ax,ay,at)T表示平均梯度,其中:

2)量化梯度
为了统计梯度向量直方图,需要将向量根据方向量化到不同的通道内,量化过程与二维平面中量化n 个方向的梯度类似,在三维空间中,实际上就是把正多边形变为正多面体。
一个正n 面体,在三维欧式坐标中,使其中心对应坐标的原点,通过映射,将平均梯度映射到正多面体每个面的中心。
pi=( p1,p2,…pn)T(i=1,2,…n)表示正n 面体的中心,定义向量P
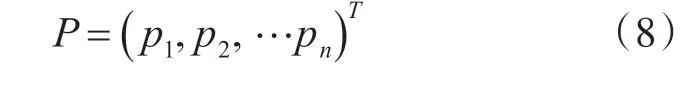


3)直方图的建立
定义一个立方体快C=(xc,yc,tc,wc,hc,lc)T,划分的子块大小为S×S×S ,计算每个子块的直方图。
如图2(b)所示,对每一个视频子块ai,它的平均梯度gˉai经过量化处理后,都会得到每个子块的直方图qai。最终,视频序列的直方图由子块的直方图累加得到。

然而,本文的3DHOG 描述是基于时空兴趣点展开的,每个时空兴趣点所在尺度不同,S 的大小也 不 同。即 对 于 一 个 时 空 兴 趣 点S=(xs,ys,ts,σs,τs)T,(xs,ys,ts)为它的三维时空坐标,σs,τs分别为空间尺度和时间尺度,兴趣点S 的邻域为RS=(xs,ys,ts,ws,hs,ls)T,其 中 ws=hs=σ0σs2+n1,ls=τ0τs2+n2,参数σ0,τ0表示了像素与尺度的比例关系。将像素快RS分成一组M×M×N 个单元,将每个单元的梯度方向直方图按照一定顺序组合在一起,形成最终的时空梯度方向直方图,即ds=(hc1,hc2,…,hcM×M×N)。
3.2 3DHOF描述子
光流反映了像素运动的瞬时速度,代表了图像序列中相邻序列之间的运动信息,HOG 描述子是对像素点的梯度方向进行统计,而HOF 描述子就是对像素点的光流信息进行统计。3DHOF 描述子则是在时间和空间对光流求取梯度后,再进行三维时空量化,构建三维光流梯度方向直方图特征[11~12]。具体方法如下:
1)稠密光流提取
步骤一:对视频帧构建尺度总数为Numδ的图像金字塔,相邻图层之间的比率为1 √2。视频帧在不同尺度下每个w 像素进行网格采样,获得稠密采样点。然后选取特征角点,本文采用Dollar 时空兴趣点检测法对稠密采样点进行筛选,去除平滑区域的采样点,其中λ 的取值方法在2.2 节中有具体描述。
步骤二:去除静止角点,假设采样点处的光流flowp=( )flowpx,flowpy,如果∥flowp∥≥Tflow,则将该点作为兴趣点并记入兴趣点总数Nump,否则认为该点不能作为兴趣点。
步骤三:特征点跟踪,具体方法如下:对t 时刻的图像It,若计算得到该点的稠密光流为flowt=(ut,vt),其中ut,vt分别为t 时刻光流在水平和垂直方向上的分量,则图像It中的一个像素点Pt=(xt,yt),在图像It+1中的跟踪位置Pt+1为

其中,M 是一个中值滤波器,中值滤波相较于线性滤波更加鲁棒,对处于运动边界的点也能实现很好的轨迹跟踪[13]。
2)3DHOF特征提取算法
本文中分别在时间和空间对光流求梯度,再进行三维时空量化,构建三维光流梯度方向直方图,具体步骤如下:
步骤一:获取视频帧 fi的稠密光流图像flowi(x,y)。
步骤二:根据获得的稠密轨迹点,分别计算低i帧中每个轨迹点在x,y,t三个方向上的光流梯度。
步骤三:梯度的量化,获取光流梯度量化的方向bin 和模值q,计算光流矢量与坐标轴之间的夹角,根据角度将其投影到对应的直方图bin 中,根据模值进行加权。
步骤四:首先将视频分为若干小的连通区域si,然后计算每个连通区域的光流直方图,并将所有区域的直方图连接得到3DHOF特征描述子。
4 特征融合
在特征提取中,HOG 特征描述子是对细胞(cell)中的每个像素点的梯度方向进行统计,而HOF特征描述子是对每个像素点的光流进行统计,将二维图像中的处理方法扩展到三维空间中,不同点在于二维图像中的细胞单元(cell)在三维时空域中变为立体块(Patch)。每个立体快的处理方法如下:实验中,将每个立方体分为20 个细胞,3DHOG使用4 个bin,3DHOF 使用5 个bin,则梯度方向直方图为80 维,光流直方图为100 维,再将两个特征拼接起来,成为融合特征。
本文中,先用Dollar 时空兴趣点检测方法对输入的视频进行兴趣点检测,得到兴趣点的位置坐标(x,y,t)。以检测到的时空兴趣点为中心向三维空间进行邻域扩充,得到一个立方体空间P,立方体大小为(H,W,T),用3DHOG 和3DHOF 描述子进行描述,得到时空特征向量L。然后以立方体P 的8 个顶点为中心进行邻域扩充,得到P1,P2…P8八个立方体,再次使用3DHOG 和3DHOF描述子进行特征描述,得到L1,L2…L8八个特征向量。最后,将之前得到的特征向量L 与这八个特征向量拼接在一起,融合后的特征向量为F=(L,L1,L2…L8)。
5 实验结果与析
本文利用Weizmann 数据库和KTH 数据库进行实验评估,实验在Matlab 2014a 编程环境中进行。Weizmann 数据库一共包括90 段视频,这些视频分别由9 个人执行10 个不同的动作(bend、jack、jump、pjump、run、sideways、skip、walk、wave1、wave2),视频的背景,视角以及摄像头都是静止的。实验采取留一法交叉验证,即依次把每个人的10 种动作作为测试样本,剩下的所有动作作为训练样本,整个实验过程重复10 次。本方法在Weizman 数据库中的识别结果如下图4 所示,平均识别率达到98.82%。

图4 复合时空特征算法在Weimann数据集上的混淆矩阵
KTH 视频数据库包含6 种行为,包括拍手、挥手、拳击、慢跑、快跑和走。每种动作由25个人在4个不同场景中完成,合计将近600 段视频,是一个数据量相对较大的数据库,数据库的视频样本中包含了尺度变化、光照变化、着装变化等。本实验从数据库中随机抽取15 个人的视频作为测试样本,剩余的10 个人作为训练样本,本文方法在KTH 数据库中的识别结果如下图5 所示,平均识别率为95.04%。

图5 复合时空特征算法在KTH数据集上的混淆矩阵
表1 列出了本文实验在两个不同视频数据库上的具体数据表现。

表1 本文算法在不同数据集中的表现
如表1 结果所示,在相同的验证方法下,采用复合时空特征的识别率比采用单一特征的识别率明显提高,证明了本文采取的特征融合方法的有效性。
表2 列出了本文方法和目前其他方法在Weizmann 数据集和KTH 数据集上识别率的比较[14~15]。可以看出,本文的方法取得了较高的识别率。

表2 本文算法与其他算法识别率的比较
6 结语
由于基于视频的人体行为识别在多个领域都有广泛的应用和潜在价值,成为很多领域的热门研究课题。本文主要从时空兴趣点的提取和特征描述方面出发,有效减少了背景中无关兴趣点的数量。采用了3DHOG 和3DHOF 相融合的复合特征对兴趣点进行描述,仿真实验证实本文方法在Weizmann 和KTH 数据集上都取得了较高的识别率,但由于兴趣点的提取可能不够准确、个人动作差异,不同行为的相似性等原因,仍然存在错判的情况。后期,本文有待通过获取更多的数据来消除个体差异等问题带来的影响,进一步提高算法性能。
猜你喜欢
导航定位学报(2022年5期)2022-10-13 08:35:28
铁道建筑(2021年11期)2021-03-14 10:01:48
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
科技风(2019年13期)2019-06-11 15:48:29
电光与控制(2018年10期)2018-10-13 08:19:00
中国交通信息化(2018年3期)2018-06-13 03:27:58
现代电子技术(2018年12期)2018-06-12 06:41:20
数字技术与应用(2016年6期)2016-07-09 08:06:51
中国交通信息化(2016年2期)2016-06-06 07:28:02
