
基于GPU的圆迹视频SAR实时成像算法
2019-11-11 02:12:2022
雷达科学与技术 2019年5期
22
(1.南京航空航天大学电子信息工程学院, 江苏南京 211106;2.南京航空航天大学雷达成像与微波光子技术教育部重点实验室, 江苏南京 211106)
0 引言
视频合成孔径雷达(视频SAR)[1-2]以动态的方式再现场景信息,有效扩展了时间维的信息,能够对热点区域持续监测,并能直观地反映出运动目标的位置、速度及运动趋势等,具有重要的军事和民用价值。视频SAR系统要求高分辨率和实时成像,这对成像算法和硬件平台提出很高的要求。为了同时满足这两项要求,一方面要设计一个高效精确的成像算法,另一方面还要通过高效的硬件处理平台对大量回波数据加速处理,实现实时成像。
在保证高分辨率成像的前提下达到视频SAR成像的帧率要求是研究的关键。目前,视频SAR成像主要采用后向投影(BP)算法,BP算法是一种时域算法,需要逐点遍历得到精确聚焦的图像,计算量相当庞大。文献[3-4]通过加大相邻帧间数据重叠率,减少每帧图像需要加入的新脉冲分量,解决BP计算量大的问题,以达到实时成像的要求。该方法依赖于相邻帧间数据重叠率,适用性受到一定的限制。文献[5]针对圆迹视频SAR的特殊回波模型提出了一种改进的去斜Chirp Scaling算法。该方法处理速度虽然不依赖于帧间数据重叠率,但利用中央处理器(CPU)处理成像速度较慢。随着硬件处理器的发展,基于硬件平台的实时成像处理算法日趋成熟。当前主流的硬件平台有:DSP、FPGA和GPU。文献[6-7]利用DSP分别实现BP算法和距离多普勒(RD)算法用于SAR的实时成像,但DSP始终受到串行指令流的限制使其并不真正适用于实时成像。文献[8-9]在现场可编程门阵列(FPGA)上实现PFA以满足SAR的实时处理需求。该方法相比CPU处理速度有所提升,但是依然无法满足视频SAR实时成像的要求,并且FPGA时序难规划,处理程序调试周期长,算法实现困难。文献[10-12]利用可编程图形处理器(GPU)实现BP算法加大成像处理速率,该方法虽然利用GPU得到了很高的加速比,但仍未满足视频SAR成像的帧率要求。GPU已经由以前的专用图形处理器演化成高并行度、多线程、拥有强大计算能力和极高存储器带宽的多核处理器,在解决计算密集型问题上具有很高的性价比[13-14],并且基于CUDA C的编程起点低,非常适合复杂算法的快速实现。
基于上述问题,本文提出了一种基于GPU的圆迹视频SAR实时成像算法。首先建立了圆迹视频SAR的回波模型,并分析了视频帧率与回波重叠率的关系。其次在GPU上实现了基于Chirp Scaling操作的PFA。最后对实测数据做并行处理成像,验证了本文所提算法的正确性和高效性,所以该算法可以适用于视频SAR实时成像。
1 信号成像处理算法
1.1 圆迹视频SAR模式
视频SAR工作于圆迹模式,其成像几何如图1所示。机载雷达在高度为H的平面里以固定区域中心为圆心作圆周运动,飞行中波束始终照射场景中心O;雷达观测角θ的值可达到360°;雷达俯仰角φ0和雷达到场景中心的距离R0均为常数,在整个运动过程中不变。传统的圆迹模式是通过增大观测角度来提高方位向分辨率,而视频SAR是通过对圆迹模式下回波数据的合理分割实现视频成像。
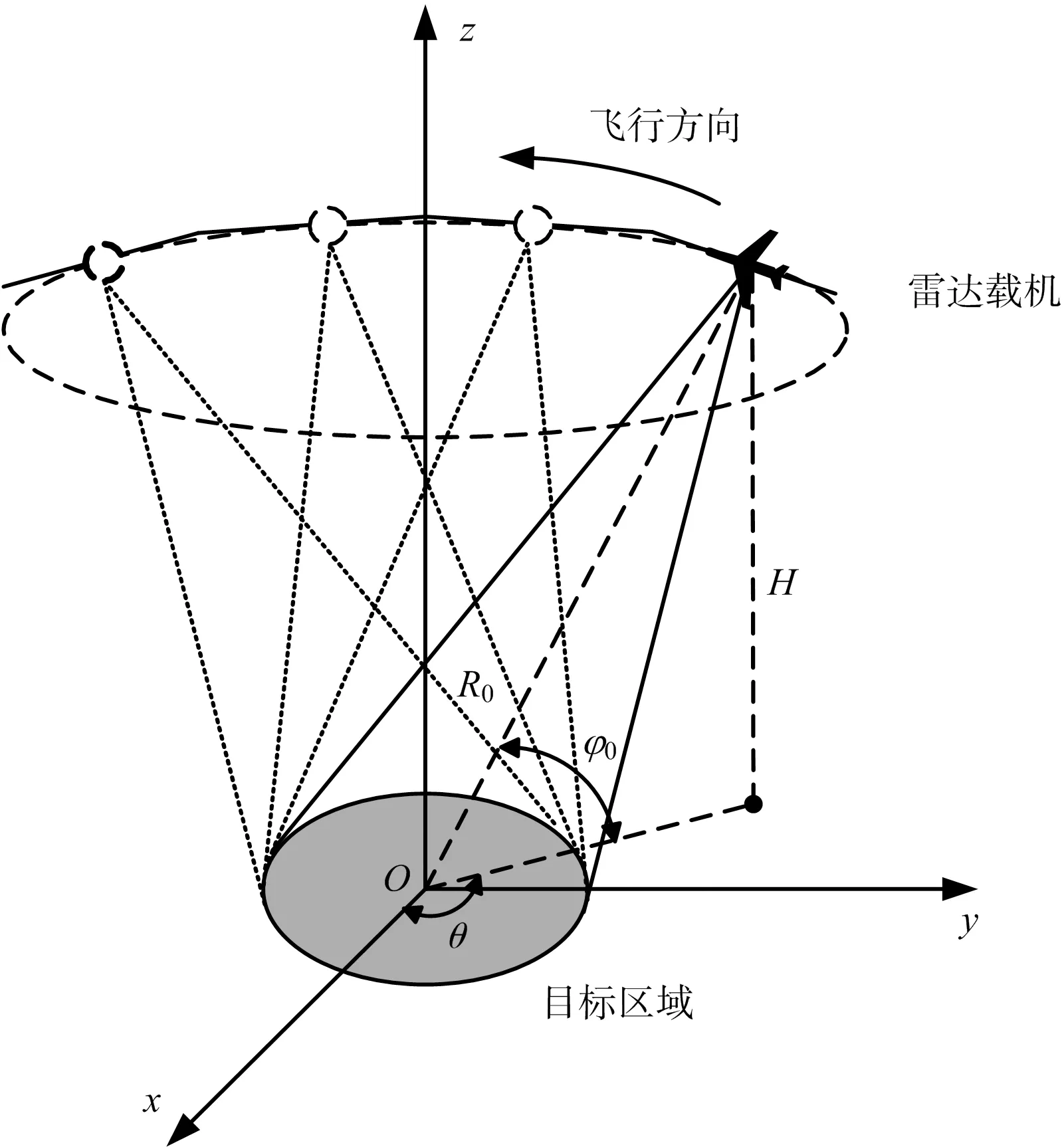
图1 圆迹视频SAR几何模型
1.2 圆迹视频SAR回波数据分割
为了保证视频SAR图像显示的流畅性,视频SAR图像帧率应不小于5 Hz[15]。由文献[15]的分析可知,视频SAR帧率与相邻帧数据重叠率的关系满足:
(1)
式中,ρa为方位向分辨率,V为雷达平台移动速度,R为视频SAR到目标区域的最短斜距,c为光速,fc为载波频率,M为相邻帧数据重叠率。因此,在给定帧率和载频的前提下,对圆迹模式下回波数据进行分割时,相邻帧之间的数据就不可避免地要有重叠,相邻两帧之间的重叠关系如图2所示。
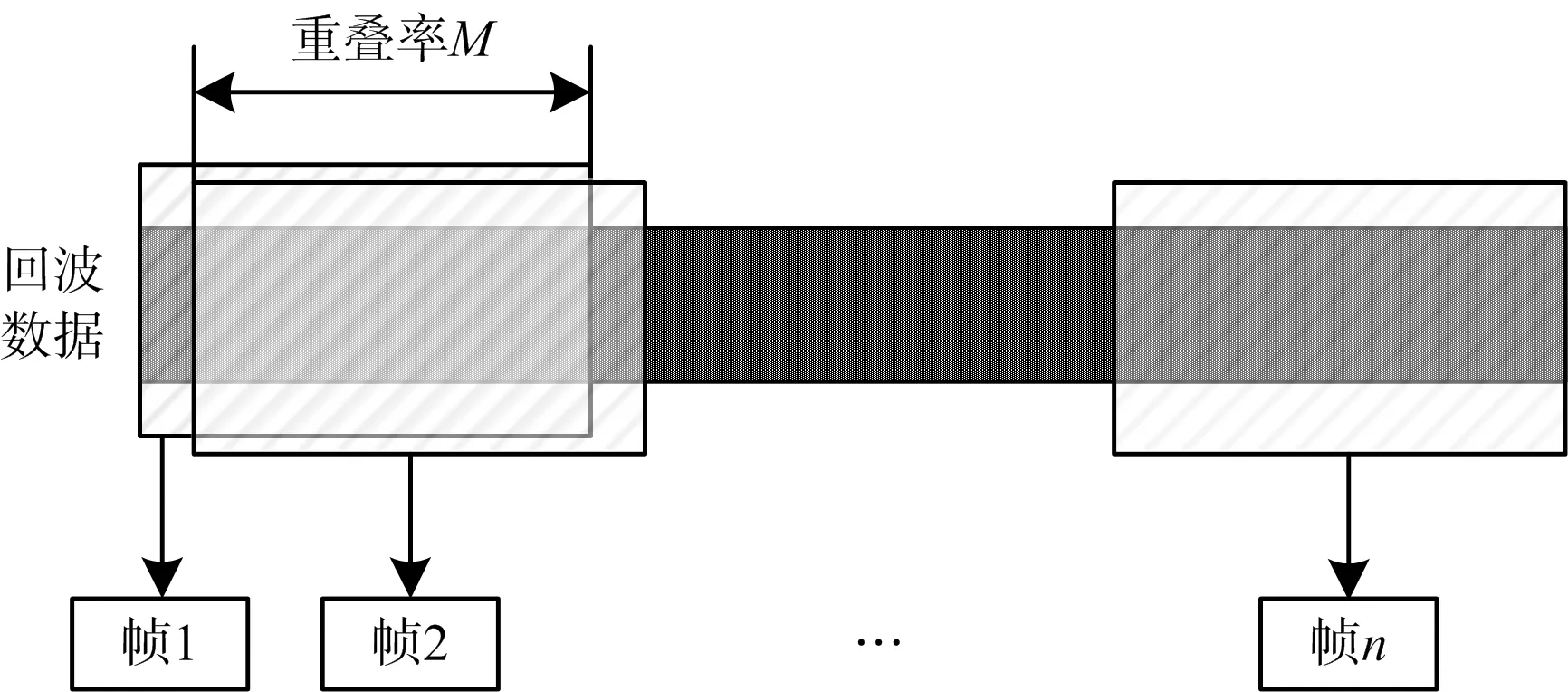
图2 相邻帧之间重叠关系示意图
1.3 基于Chirp Scaling操作的PFA
针对圆迹视频SAR的成像特点,在回波数据划分为若干帧后,用传统的直线聚束SAR对其进行近似,并对每一帧数据用基于Chirp Scaling操作的PFA成像。基于Chirp Scaling操作的PFA流程如图3所示。

图3 基于Chirp Scaling的PFA处理流程
根据直线聚束SAR的成像几何,解调后去斜信号的回波表达式为

(2)
式中,τ为距离向时间,t为方位向时间,r(t)为天线相位中心到目标的瞬时距离,ra(t)为天线相位中心到场景中心的瞬时距离,k为距离向调频率,c为光速,fc为载波频率。
PFA距离向处理包括去除去调频引起的残余视频相位误差(RVP)、距离向尺度变换和距离向FFT,其中距离向尺度变换处理实现了距离向重采样。距离向处理中的尺度变换函数分别如下:
(3)
(4)

(5)
式中:t为方位向慢时间;τ为距离向快时间;δr为距离向尺度变换因子;α为一个虚引数,其在一定范围内具有取值任意性;T为整个采样时间;fτ为距离向频域;k为距离向调频率;r0为场景中心到雷达航迹的垂线长度。
方位向处理包括方位向尺度变换和方位向FFT,其中方位向尺度变换实现方位向重采样。方位向处理中的尺度变换函数分别如下:
h1(t)=exp[jπkat2]
(6)
(7)
h2(t)=exp[-jπδakat2]
(8)
(9)
式中,ka为多普勒频率,δa为方位向尺度变换因子,ft为方位向频域。通过上述处理,采样点排列格式从极坐标转换到了直角坐标。最后经过距离向傅里叶变换将数据变换到图像域,单帧SAR成像完成。
2 圆迹视频SAR实时成像的GPU实现
本文提出的基于GPU的圆迹视频SAR实时成像算法如图4所示,首先根据载频和帧率确定重叠率截取回波数据,并将其传输至GPU等待处理;然后在GPU上利用PFA处理数据;最后将成像结果传输至CPU即可视频成像。

图4 基于CPU+GPU的视频SAR实时成像流程
2.1 GPU成像处理关键技术
根据上节提出的视频SAR成像算法,对于PFA运算模块,需要执行CPU→GPU数据复制、数据处理、GPU→CPU数据复制3个步骤;对于PFA中方位向数据处理之前进行先排距离向到先排方位向的转置操作,以及在数据处理之后进行先排方位向到先排距离向的转置操作均利用GPU执行;对于PFA中的Chirp Scaling操作需利用GPU执行点乘运算。为了利用 CUDA 技术将这种实现方案在GPU上部署,并充分利用GPU设备的运算资源,给出了3种优化技术对程序进行优化处理。
2.1.1 异步并行技术
将PFA的运算模块部署在GPU上时,需要在CPU内存与GPU显存之间传输数据。为了让内存与显存之间的数据传输和PFA模块的核(kernel)函数执行并行实现,本文采用异步并行技术对数据处理加速。异步并行技术即创建若干个流,将雷达数据平均分配到每个流上,不同流中的数据传输与处理不会相互干扰,这样可以使内存与显存之间的数据交互与kernel函数并行执行。异步并行方案的实现如图5所示,图中同时比较了串行执行与4个流异步执行的运行时间,可以看出异步并行执行保证了GPU运算核心绝大部分时间处于忙碌状态,有效掩盖了数据在内存与显存中的传输时间。

图5 异步并行执行与串行执行
2.1.2 CUDA的两层并行技术
PFA中完成距离向处理后,雷达数据以先排距离向的方式存储于CPU内存,因此在进行方位向操作时,需要先对数据作转置处理。针对矩阵转置,本文采用CUDA的两层并行技术。两层并行运算:一是在同一个线程块(block)中利用线程实现的需要进行数据交换和通信的细粒度并行,二是在各个block间实现不需要进行数据交换的粗粒度并行。如图6所示,先用合并访问方式将数据从全局存储器读入共享存储器,然后每个线程与其按对角线对称的线程交换数据完成细粒度并行(效果如图中数字1与2位置交换),再按合并访问方式将结果写到全局存储器中完成粗粒度并行。这种技术利用共享存储器能极大提高程序的运行效率,同时有效避免了存储体冲突。

图6 两层并行完成矩阵转置示意图
2.1.3 分块点乘技术
整个算法的核心部分是PFA中的Chirp Scaling操作,该操作部署在GPU上时依赖于点乘实现,所以需要对点乘的实现进行优化。为了结合异步并行技术,本文对雷达数据进行分块点乘运算。两个二维矩阵的分块点乘运算如图7所示,矩阵A为雷达数据,矩阵B为尺度变换函数。雷达数据分流后距离向和方位向的点数分别为Nr和sub_Na,每个线程块(block)的维数分别为Ta和Tr,则总线程块的行数和列数分别为|(Nr+Tr-1)/Tr|和|(sub_Na+Ta-1)/Ta|,|x|表示取不大于x的整数。分块的数目与线程块的分块相同,各块的数据量与调用的线程(thread)数相同。按照分块的方法,线程块将分块后的点乘因子读入到线程块内的共享存储器中,然后将分流后雷达数据中的每个元素与对应尺度变换函数的点乘因子进行并行点乘运算即可。这种技术利用线程块内的共享存储器节省了数据拷贝时间。
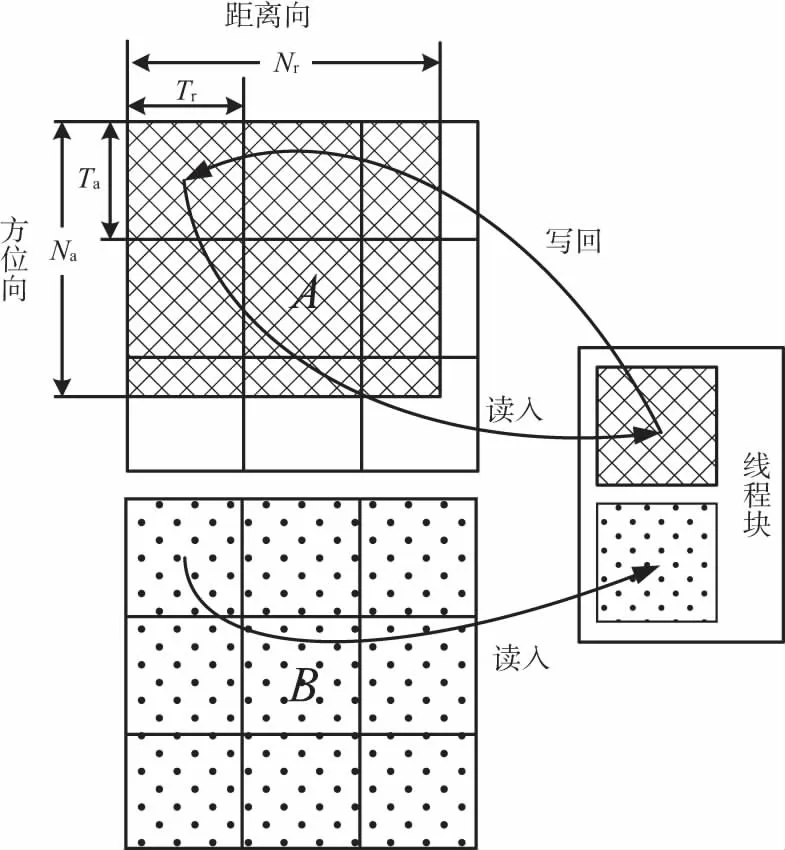
图7 线程分块点乘示意图
2.2 基于GPU的视频SAR成像流程
2.2.1 回波数据截取与传输
在成像处理开始之前,首先需要根据载频与帧率的关系确定数据重叠率划分子孔径获取单帧回波数据,并为回波数据进行内存及显存分配,在所有步骤执行完毕之后,再将所分配的内存及显存释放。为了保证该内存始终驻留在物理内存中,且提高内存与显存间复制数据的速率,使用cudaHostAlloc分配页锁定主机内存。
在进行数据传输时,使用异步并行技术分成4个流异步并行执行,并为每个流在GPU设备显存上分配存储空间用于完成PFA模块的各个计算步骤。因为PFA模块涉及到的距离向处理和方位向处理中都包括FFT(或IFFT)运算,所以有必要为每个流根据数据块二维尺寸大小调用CUDA函数中的cufftPlan1d构造FFT句柄(plan),并将所创建plan用cufftSetStream函数与所属流关联。模块执行完毕后立即调用cufftDestroy函数销毁plan,调用cudaStreamDestroy等待指定流中所有之前的任务完成,释放流并将控制权返回给主机线程。
2.2.2 基于GPU的PFA成像
PFA距离向处理包括FFT、IFFT以及雷达数据与尺度变换函数相乘三项。FFT和IFFT调用CUDA库函数。雷达数据与尺度变换函数相乘涉及到两个二维矩阵的点乘运算,即两个矩阵的每一点对应元素相乘,这里采用线程分块点乘技术来实现,如图7所示。尺度变换函数的生成通过在每个并行节点上利用GPU并行计算出其对应数值。
为了避免不必要的时间损失,调用cudaMemcpyDevice函数在显存中高效地完成距离向处理后数据的存储,并调用cudaDeviceSynchronize使用CUDA同步技术,强制运行时等待所有流中的任务都完成再进入下一步骤。
PFA方位向处理同样包括FFT、IFFT以及雷达数据与尺度变换函数相乘三项。因为距离向处理结束后方位向雷达数据在内存中是离散存储的,为了在方位向处理中能用异步并行分流处理节省,首先需要进行矩阵转置,将方位向数据变为内存中的连续存储形式,矩阵转置利用CUDA的两层并行技术如图6所示构造转置kernel。矩阵转置后沿距离向均分为Cr块并分流,再进行方位向处理,方位向处理的GPU实现方式与距离向处理相同。
方位向处理通过CUDA同步技术保证所有流执行完毕后,再次调用转置kernel将显存中距离向数据变为连续存储,然后对距离向数据作IFFT,PFA模块即完成。
最后将结果由cudaMemcpyAsync函数异步写回主机内存的对应位置,并将处理结果写入图像文件,第一帧图像处理结束。陆续读取之后的子孔径数据进行处理并显示,最终将以视频的形式显示成像结果。
3 实验结果与分析
为了验证本文所提方案的正确性和有效性,下面针对实测数据进行了处理。成像环境如下:处理器Intel(R) Xeon(R) CPU E5-1650 3.2 GHz;内存32 GB;显卡型号NIVIDA TeslaC2075 1.15 GHz;显存4 GB;显卡运算能力2.0;操作系统Win 7;软件环境Visual Studio 2010及CUDA 5.5。实验所用原始数据是微型SAR按圆迹模式逆时针飞行获得,数据大小总共为2 048×56 112,每帧成像数据大小为 2 048×2 048,实验参数如表1所示。因为载频为9.7 GHz,由式(1)计算得重复率为99%时,帧率能达到5 Hz,即满足视频SAR成像要求,所以本实验中回波数据重叠率选为99%。
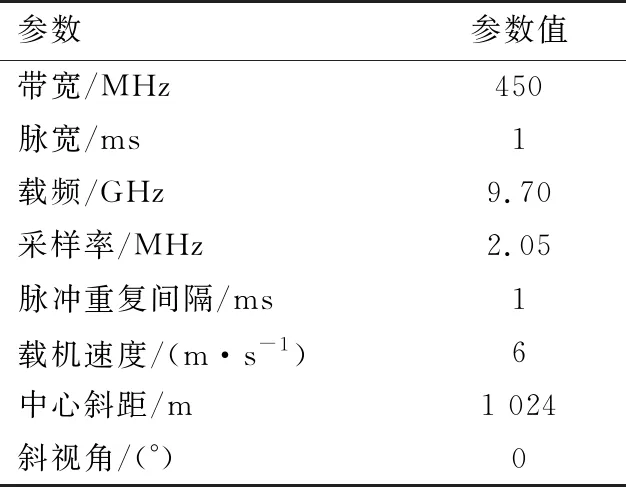
表1 视频SAR实验系统参数
从实验结果中截取四帧成像结果如图8(a)、8(b)、8(c)和8(d)所示,为了清晰地看出圆迹SAR的运行轨迹,本文每隔500帧截取一帧。从成像结果中可以明显看出载机围绕中心目标按圆迹模式逆时针飞行,也清楚地看到凹凸的地形、5个建筑物和周围的树木,具有非常高的分辨率。

(a) 第100帧

(b) 第600帧

(c) 第1 100帧

(d) 第1 600帧图8 视频SAR成像结果
本文利用Chirp Scaling操作替换PFA中传统的二维插值,相同性能的GPU分别实现这两种方式,并处理同一帧2 048×2 048大小的数据。如表2所示,基于插值的PFA处理一帧图像用时0.25 s,而基于Chirp Scaling操作的PFA处理一帧图像用时0.18 s,Chirp Scaling操作比插值节省38.8%的时间。可见,基于Chirp Scaling操作的PFA是更高效的处理算法。
提高计算速度的关键是应用 GPU达到CPU不能实现的处理速度,下面将GPU上的处理时间与CPU上的处理时间进行比较,如表2所示。处理2 048×2 048大小的数据,CPU的处理时间为6.27 s,明显不能达到视频SAR的成像帧率要求;GPU的处理时间为0.18 s,与单线程的CPU处理相比GPU处理的加速比为34.83倍。可见,选用 GPU作为视频SAR数据处理平台具有很大的优势。
最后,基于GPU的视频SAR成像处理算法能否满足实时性要求,取决于成像帧率。利用本文所用算法处理一帧图所需时间约为0.18 s。对于距离采样点数为2 048的视频SAR系统,一部Tesla C2075便可满足视频SAR 5 Hz的视频帧率要求。因此利用GPU并行处理高分辨率频域处理算法进行视频SAR实时成像处理是可行的。另外,在此基础上,还可以通过增加GPU设备个数扩充设备的处理能力,以达到增加距离采样点数的要求。

表2 实测数据成像时间比较
4 结束语
本文提出了一种基于GPU的视频SAR实时成像算法,给出了算法的详细流程,其中主要包括回波数据划分方法以及PFA的CUDA实现方法。为了让系统更高效,对整个成像算法的并行处理进行了优化,极大地发挥了GPU并行计算的优势。最后在GPU并行平台上进行了视频SAR成像实验,验证了并行算法性能,有效解决了视频SAR高分辨率成像的实时性问题。
猜你喜欢
幼儿园(2021年12期)2021-11-06 05:10:20
当代陕西(2019年13期)2019-08-20 03:54:22
环球市场(2017年36期)2017-03-09 15:48:21
中国修辞(2016年0期)2016-03-20 05:54:32
幼儿100(2016年28期)2016-02-28 21:26:17
火控雷达技术(2016年2期)2016-02-06 02:29:00
测绘科学与工程(2014年5期)2014-02-27 07:06:14
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
杭州电子科技大学学报(自然科学版)(2010年5期)2010-01-08 07:28:38
电脑爱好者(2009年13期)2009-07-07 09:52:52
