
基于SPSO优化Multiple Kernel-TWSVM的滚动轴承故障诊断*
2019-11-06 05:20徐冠基
振动、测试与诊断 2019年5期
徐冠基, 曾 柯, 柏 林
(重庆大学机械传动国家重点实验室 重庆, 400044)
引 言
滚动轴承是机械设备的重要零部件,其运行状态关系着设备的正常运转,国内外很多学者对滚动轴承的状态监测做了大量的研究,并且随着近年来人工智能领域的迅猛发展,滚动轴承的故障诊断技术得到了长足的发展。信号获取的方法大多是采用加速度传感器测量振动信号,特征提取是状态辨识的大数据基础,常用的振动信号特征提取方法包括时域分析,频域分析以及时频域分析。其中:时域分析包括峰值,峭度,均方根值和方差等;频域分析包括快速傅里叶变换和离散傅里叶变换等;时频分析法包括小波变换,短时傅里叶变换,希尔伯特变换和Winger分布等。上述特征提取方法是建立在振动信号是线性和平稳信号的基础之上,而滚动轴承在高速运转过程中滚动体与内外圈的接触是非线性的,并且其载荷的分布以及接触刚度的变化也是非线性的,因此滚动轴承在产生故障时会使其运转周期消失并产生非线性振动[1]。传统的线性、平稳特征提取技术,容易丢失重要的非线性状态信息,不能很好地从复杂非线性信号中提取真实反映其非线性振动本质的有效状态特征[1]。分形维数和熵特征利用相空间重构技术将滚动轴承振动信号映射到高维空间中以复原原始信号中的混沌特征[2],分形维数是描述事物分形特性的一种有效方式,同时也是将事物分形特征进行量化的度量参数[3],熵特征是用来反映系统的混乱程度和复杂性,熵累计得越多表示系统混乱程度越高,反之越低[4],而系统的混乱程度和复杂性又与其故障状态有着密切的关联性。可见,利用分形维数和熵特征来对滚动轴承故障信号进行非线性特征提取能更加有效地辨识轴承的故障状态。
状态辨识的实质是机器学习与模式识别,近年来人工智能的快速发展促进了故障诊断技术的进一步提高,常用的模式识别方法有支持向量机和BP神经网络等,SVM是一个二分类算法,对均衡或近似均衡分布的样本,分类效果显著[5],如果遇到存在多种状态类别的多分类问题,SVM只能通过二叉树或者偏二叉树等方法来细化分类,这样做可能会导致训练样本不均衡问题,而SVM在处理该类问题时往往不尽人意[6]。Jayadev等[7]提出了TWSVM,TWSVM算法专门处理样本非均衡问题,其核心思想是构造两个非平行的超平面,使正类样本靠近正类超平面而负类样本尽可能地远离,使负类样本靠近负类超平面而正类样本尽可能远离。TWSVM其训练速度较快,有着能较好求解异或问题和分类性能优越等明显的优势[8],由于使用非平行的分类超平面,TWSVM在解决两类样本成交叉分布的分类问题时,具有更强的泛化能力[9]。TWSVM的主要原理在于是利用核函数来把高维向量空间中的内积计算转换为原低维空间中某个函数的函数值代替,以解决训练样本线性不可分问题。其核函数的选择与优化对其分类性能的提高起着至关重要的作用。不同种类的核函数也具有不同的特性,比如高斯核函数是局部核函数,多项式核函数是全局核函数,基于局部核函数和全局核函数的双核函数[10],基于高斯核和多项式核的双核函数[11]等。但这些核函数改进融合大多用于提高传统SVM模型分类性能中,尚未见对TWSVM核参数进行优化选择的报道。因此,为解决其核函数性能单调的缺点,提出了将加权的高斯核和多项式核双核函数引入到TWSVM分类模型,以提高TWSVM的分类性能和泛化能力,并采用简化粒子群优化(simple particle swarm optimization,简称SPSO)[12]算法对核函数权值,分类模型参数和核参数寻优。实验结果表明,基于分形维数和熵特征的非线性特征提取方法能够有效地提取滚动轴承的故障特征,并且双核TWSVM分类精度和泛化性能要高于单核TWSVM,另外在同等条件下对比BP神经网络的分类精度,单核TWSVM和双核TWSVM模型分类性能要优于BP神经网络。
1 非线性特征提取
目前对于时间序列非线性特征的分析一般采用相空间重构法,时间序列相空间重构的原理是通过延时时间和嵌入维数把时间序列映射到更高维的空间中以便提取出原混沌时间序列中所含的非线性特征信息。
实现时间序列相空间重构的一种合适的方法是G-P算法[13]。
1) 选取合适的延迟时间τ和嵌入维数m对时间序列X={x1,x2,…,xN} 进行相空间重构,得到重构的相空间如式(1)所示
(1)
其中:Nm=N-(m-1)τ。
2) 计算累积分布函数
(2)
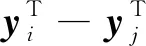
决定重构相空间的两个重要参数是延迟时间τ和嵌入维数m,Takens[14]认为延迟时间τ和嵌入维数m的选取是相互独立的过程。一般延迟时间(采用自相关函数法或者互信息法[15],嵌入维数m可选用CAO法[16],G-P方法[17]。
本研究拟采用关联维数,盒维数,近似熵,样本熵,模糊熵和Kolmogorov熵来提取时间序列非线性特征。关联维数描述的是混沌时间序列具有某种确定规律及程度,经相空间重构后的时间序列相互关联的点对个数越多,就表明系统运动的规律性就越强[2]。对于复杂机械设备的状态变化,盒维数可以用来定量地描述分形边界的统计自相似特性[18]。近似熵是用一个非负数来表示某时间序列的复杂性,越复杂的时间序列对应的近似熵越大[19]。模糊熵是衡量时间序列在维数变化时产生新模式的概率的大小,序列产生新模式的概率越大,则序列的复杂度越大,熵值越大[20]。样本熵分析方法只需要较短数据就可得出稳健的估计值,是一种具有较好的抗噪和抗干扰能力的非线性分析方法[21]。Kolmogorov熵是非线性特性的度量特征量之一[22],描述非线性系统产生信息量多少和快慢程度的物理量[23]。
2 基于SPSO的双核TWSVM原理
TWSVM比较于传统的SVM所建立的一个超平面,TWSVM构建了两个不平行的超平面,并使正类样本靠近正类超平面而负类样本尽可能地远离,而负类样本靠近负类超平面而正类样本尽可能远离。非线性TWSVM的算法原理可参考文献[5, 8]。另外,核函数的选择对TWSVM的分类性能具有重要的作用,不同的核函数具有不同的分类特性,如上所述高斯核函数属于局部核函数,多项式核函数属于全局核函数。如何结合各个核函数的优点,并对其进行优化对提高TWSVM的分类性能具有重要的作用。全局核函数泛化能力强而分类能力较弱,局部核函数分类能力强而泛化能力弱,因此可以看出核函数的泛化能力与分类能力是相互制约的,这就需要找到一个平衡点让双核函数既具备较强的分类能力也要具备较强的泛化能力。因此将加权的高斯核和多项式核双核函数其互补性强,应用到TWSVM分类模型中以解决其核函数性能单调的缺点,以此提高TWSVM的分类性能和泛化能力。
多项式核函数和高斯核函数是比较常见的两种核函数。
高斯核函数
(3)
多项式核函数
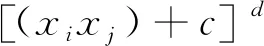
(4)
加权的高斯核和多项式核双核函数如下
Kmix=mKpoly+(1-m)KRBF
(5)
其中:Kpoly为多项式核;KRBF为高斯核;m为调节核函数所占权值大小的参数。
假设矩阵A,B分别表示两类样本集,A∈Rm1×n,B∈Rm2×n,m1,m2分别表示样本数量,n表示维度。将双核函数Kmix带入TWSVM中,可以得到双核函数的TWSVM分类优化问题,如下
超平面1
s.t. 0≤α≤c1
(6)
其中:α=(α1,α2,...,αm2)T;G=[Kmix(B,CT)e2];H=[Kmix(A,CT)e1];CT=[ΑT,ΒT];z1=[u(1),b(1)]T=-(HTH)-1GTα;e1,e2为单位向量;c1为惩罚因子。
超平面2
s.t. 0≤γ≤c2
(7)
其中:γ=(γ1,γ2,…,γm1)T;P=[Kmix(A,CT)e1];Q=[Kmix(B,CT)e2];z2=[u(2),b(2)]T=(QTQ)-1·PTγ;c2为惩罚因子。
最终判别公式为
(8)
其中:Label为类别变量;class为具体类别。
从式(3)~(8)可看出,双核TWSVM要优化的参数有惩罚因子c1和c2,高斯核参数σ,多项式核参数d,c以及双核函数权值m。这些参数的选取对双核函数TWSVM的学习能力及泛化能力有很大的影响,只有选择出更优化的参数才能保证该方法的可靠性和稳定性,因此拟采用SPSO[12]的方法来确定最优参数,由粒子位置来控制粒子的更新,解决了算法后期收敛慢的问题。
SPSO算法首先是设定粒子数并对种群进行初始化,然后在每次迭代的过程中通过适应值函数来更新粒子的个体极值和全局极值,然后根据本次迭代后的个体极值和全局极值更新种群中所有粒子的位置。其位置更新方程为
(9)
其中:b1和b2为常数项,一般取值为2;r1和r2为[0,1]的随机数;Pid为个体极值;Pgd为全局极值;xid为粒子位置;ω为惯性权重。
式(1)右边第1项代表前一代粒子对后一代粒子的影响,第2项表示个体极值对粒子自身的反馈,第3项表示整个粒子种群的信息共享。SPSO只有位置更新方程而没有速度参数项,其简化和优化了粒子群计算规模。
3 实 验
为了研究笔者提出的非线性特征提取方法和SPSO优化的双核TWSVM对滚动轴承状态类别的辨识性能,本研究选取由凯斯西储大学提供的不同状态类别的滚动轴承振动信号作为研究对象,实验台如图1所示,包含了一个1.5 kW的电机,扭矩传感器,译码器以及一个示功器。选择驱动端轴承座上采集的加速度信号作为原始数据集,其采样频率为12 kHz,选择的实验轴承为SKF的深沟球轴承,采用电火花加工以模拟轴承故障类型和故障程度。

图1 滚动轴承模拟故障振动实验台Fig.1 Test board of fault simulation of rolling bearings
数据集共包含4种状态类别,分别为内圈故障,外圈故障,滚动体故障和正常状态,每种故障类别包含有3种故障尺寸,分别为0.017 78,0.035 56,0.053 34 cm,再加上正常状态,共计10种状态类别,分别为正常,内圈故障为0.017 78,外圈故障为0.017 78,滚动体故障为0.017 78,内圈故障为0.035 56,外圈故障为0.035 56,滚动体故障为0.035 56,内圈故障为0.053 34,外圈故障为0.053 34,滚动体故障为0.053 34 cm。
在数据样本的10种标签类别中,每类标签选取50个信号样本,每个样本信号截取2 048个点,一共构成500个信号样本。对500个信号样本提取非线性特征,即每个样本分别提取关联维数,盒维数,近似熵,样本熵,模糊熵和Kolmogorov熵。由此组成维数为500×6的特征矩阵,所列特征值都经归一化处理,去除量纲影响,其中6种故障类型部分特征向量参数如表1所示。

表1 非线性特征值表
从表1中可以看出,本研究所选取的6个特征对故障类别有很强的辨识能力,即参考某一特征下不同的状态类型所对应的特征值大小不同,这是区别轴承状态类别的一个基础指标,也即特征值不同对应的状态不同,当参考某一个特征下不同状态的特征值会有相同,但是这只是在一个特征下(也即1维空间下)的样本聚类特征,当特征越多进而特征向量的维度越高,在高维空间中不同状态类别的数据样本之间的区分度将会更好,重叠现象将会减少甚至消失。
另外,图2中的(a)~(f)分别为关联维数、盒维数、近似熵、样本熵、模糊熵和Kolmogorov熵的特征值图,横坐标表示样本数,即总共500个样本,纵坐标表示特征值。从图2中可以看出,不同状态类别特征值的相互区分度较好,与表1所反映的情况基本一致,也出现了某些特征值图在某些状态类别下的特征值出现了重叠,正如前文所述那只是在1个特征也即1维空间下的样本聚类特性。文中共选取了6个特征,这6个特征向量所组成的6维空间中,每个状态类别样本可以聚集在不同的空间区域,这将有利于双核TWSVM建立分类超平面。
为了能够直观地观察不同故障类别的样本在空间中的聚集状态,下面将画出不同类别样本的聚类图,但是由于6维空间的点不能在人们所熟悉的笛卡尔坐标系中表示,笛卡尔坐标系最多只能表示三维空间的点。因此为了简化该问题须在这6个特征中选择每3个特征为一组,共4个组分别如图3(a)~(d)所示,以研究特征的聚类程度。从图3中可以看出,10种状态类型的3维样本点在空间中表现出分类聚集特点,每一个块状或云状聚集点为一种故障类别,因此可以看出所选特征的聚类性很好。虽然观察图3可以发现不同状态类别的样本之间任有一些重叠,分析原因是因为所选取的特征值的维度只有3维,在将特征值维度扩展到6维之后,特征向量将被映射到更高维的空间中,将会具有更加明显的特征聚类特性。
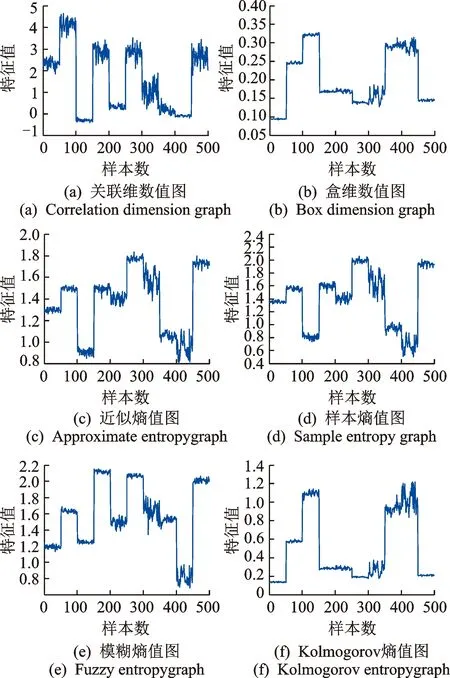
图2 关联维数、盒维数、近似熵、样本熵、模糊熵和Kolmogorov熵的特征值图Fig.2 Eigenvalues map about correlation dimension, Box dimension, approximate entropy, sample entropy, fuzzy entropy and Kolmogorov entropy
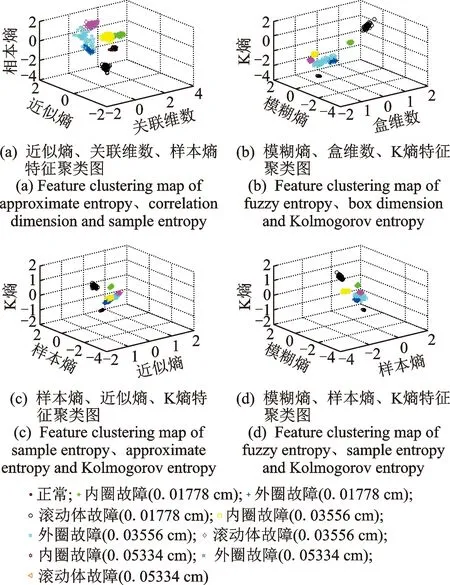
图3 3个特征值维度下的特征聚类分析Fig.3 Clustering analysis of features based on three characteristic value
本实验中对训练样本和测试样本分配策略是在总共500个样本中固定训练样本和测试样本数,文中选定训练样本数为400个,测试样本数为100个,并且训练样本和测试样本互不交叉,然后再在总的400个训练样本中按25%,50%,75%和100%的比例抽取训练样本对分类模型进行训练,用100个测试样本进行分类预测得出当前比例下的分类准确率。
单核的TWSVM所用到的核函数是高斯核函数,高斯核函数是一种局部核函数,其分类能力强而泛化能力弱,为了兼顾TWSVM的泛化性能和分类能力,现将高斯核函数和多项式核函数通过加权的方式组成双核函数引入到TWSVM中,在双核TWSVM模型的训练中采用的SPSO方法对参数进行优化。在第2节中提到了需要优化的参数有惩罚因子c1和c2,高斯核参数σ,多项式核参数d和c以及双核函数权值m,上述参数均无量纲。由于SPSO算法的计算量会随着优化参数的增加呈现近乎指数型增长,因此为了提高优化效率需减少待优化参数个数,多项式核函数中参数c和d的选择[24]一般比较固定,取c=1,d=2.需要优化的参数只剩下c1和c2,σ和m,试验表明只需设置种群大小为30,当迭代次数为30次时适应度函数就可达到最大值。
表2列出了在训练样本比例为50%的情况下SPSO对上述4个参数的优化情况。针对10种状态类别需要采用偏二叉树的方法来建立训练模型,因为TWSVM与SVM一样都是二分类模型,即一次只能进行两种状态类别的划分,如果遇到多分类问题,就要采用二叉树或者偏二叉树的方法来实现,采用偏二叉树对10种状态类别进行分类就需要训练9层分类模型,第1层区分第1类和第2345678910类,第2层区分第2类和第3456789类,以此类推,第9层区分第9类和第10类。m表示高斯核函数的权重,多项式核函数的权重自然为1~m。从表中可以看出,分类模型的不同层次中,高斯核和多项式核的权重有很大的差别,这就说明双核能通过调整权重的大小来适应不同的训练样本的空间分布特性以平衡分类超平面的泛化性能和分类能力。

表2 训练样本比例为50%时各层双核TWSVM模型参数取值情况
为了得到最终稳定的分类准确率,将每个训练样本比例下的训练和预测重复进行10次,由于训练样本的抽取是随机的,因此重复10次取平均能够得到较为稳定的预测精度。
表3给出了单核TWSVM,双核TWSVM和BP神经网络在不同的训练和测试样本比例情况下的识别性能。从表中可以看出,3种分类模型的识别准确率不管是在小样本和多样本情况下都能达到90%以上,仔细分析主要是因为笔者提出的非线性特征提取方法所提取出的特征向量具有很高的聚类特性,也即类别辨识度高,这有助于建立精准的分类超平面。另外,对比TWSVM和BP神经网络两种分类方法,TWSVM整体上要高于BP神经网络 ,这是TWSVM分类性能优越能够有效提高故障辨识精度[8],这也证明了TWSVM具有很强的泛化性能。在保证TWSVM泛化性能的基础上并提高TWSVM的分类精度,根据表3可以看出,基于双核的TWSVM相对于单核的TWSVM整体有一定提升,双核TWSVM的分类准确率能够达到100%左右,特别是在小样本情况下,即训练样本比例只有25%时,双核TWSVM相对于单核TWSVM分类准确率提高了8%左右。

表3 单核TWSVM、双核TWSVM和BP神经网络在不同训练样本比例下识别性能
4 结束语
笔者将非线性特征分析方法用来对10种状态类型的滚动轴承振动信号进行特征提取。实验结果表明,所提取的特征样本具有很好的类别辨识度,这为双核函数的TWSVM模型的训练提供了准确的样本依据。另外,由于TWSVM本身具有解决两类样本成交叉分布的分类问题时,具有更强的泛化能力以及分类准确性,实验中也证实了TWSVM的预测精度整体上要优于BP神经网络。但是TWSVM核函数的选择对于分类模型的泛化能力和分类性能有较大影响,而泛化能力和分类性能又是相互制约的,为了寻找平衡点,本研究将加权的高斯核和多项式核组成双核函数引入到TWSVM以提高其泛化能力和分类性能。从实验结果可以看出,在不同的训练样本比例下特别是小样本比例下,双核TWSVM的预测精度都要高于单核TWSVM,这说明双核函数能通过调整权重的大小来适应和平衡分类超平面的泛化性能和分类能力。因此笔者提出的非线性特征提取方法和双核TWSVM分类模型对提高滚动轴承故障诊断准确率具有重要意义。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26
房地产导刊(2022年1期)2022-02-28
计算机应用与软件(2022年2期)2022-02-19
上海理工大学学报(2021年6期)2021-12-29
中北大学学报(自然科学版)(2021年5期)2021-11-15
科技创新与应用(2020年6期)2020-02-29
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
科技视界(2011年22期)2011-12-21
初中生·博览(2011年11期)2011-12-17
