
混合现实的目标识别技术和YOLO算法的对比
2019-11-06 00:28:06张笑宇
微处理机 2019年5期
张笑宇
(西安工程大学电子信息学院,西安 710600)
1 引 言
随着智能移动设备的广泛普及和硬件配置的不断提高,混合现实技术受到越来越多人的重视,成为了当下研究的热点。目前混合现实技术在识别二维图像或标志物方面效果不错,可在被识别的图像上生成虚拟的模型、文字、视频等,但是在识别三维物体上效果不是很好,而且识别的距离较短。这些问题都亟待解决,需要一个新的方案来改变混合现实识别技术的现状。随着神经网络的出现,深度学习在图像识别领域有了迅猛的发展,人们对深度学习的研究也日益深入。文献[1]中针对混合现实技术识别距离短的缺点,使用ARToolKit 增强现实系统,提出了基于轮廓特征点的目标识别方法,增加了识别距离,但其所使用的是有标志物的识别方式,应用的场景比较有限;文献[2]中构建了基于深度传感器的远距离跟踪技术,把Kinect 传感器的坐标系和摄像头的坐标系相匹配,协调两者作为追踪系统,为增强现实的远距离识别提供了一种思路,但需要借助Kinect设备,在目前的智能手机上无法推广使用;文献[3]在LeNet-5 模型的基础上,提出一种基于深度卷积神经网络,识别现实场景里的目标物体,接着在物体上渲染虚拟模型的方法,成功识别了三维物体,解决了混合现实不能识别三维物体的问题,但是虚拟模型和目标物体的契合度不够好;文献[4]搭建了AR+深度学习的平台,为在线学习提供了新的形式,也为混合现实技术和深度学习相结合提供了一种新思路,但是平台的扩展性不够好,每加入新的内容都需要重新开发;文献[5]使用深度学习来增加图像识别的准确度,使用SIFT 算法提取校园景点的特征,把它保存为一维向量并和数据库里保存的信息进行匹配,结合AR 技术制作了一个校园导航应用,把深度学习和AR 完美的融合在了一起,但是卷积过程花费了太多时间,在移动设备上运行CNN 时,使用3D模型出现了明显的延迟;文献[6]提出了一种基于YOLO 和SIFT 的猫鼻子识别系统,首先在Darknet中使用YOLO 检测猫鼻子,检测成功后从图像中裁剪鼻子,以数据库中的猫鼻子图像为参考,利用SIFT 方法和k-NN 算法进行识别,平均精度达到95.87%,这种方法为混合现实中特征点的提取提供了思路;文献[7]使用YOLO 进行实时的行李检测,给出了一个支持参数设置的GUI,有了这个GUI,监测系统可以不受光照和摄像机位置的影响,同时使用GUI 界面可以设置事件,用于某些特定的情况,大大增加了YOLO 的功能;文献[8]将YOLO 网络模型用于行人检测,在深度网络前增加了三个透层,并将原YOLO 网络中的透层连接数由16 层改为12层,提高了网络读取浅层行人特征的能力,有效提高了YOLO 检测行人的精度,降低了误检率和漏检率,但对部分距离较近的人的识别效果不太好。
基于上述研究成果,通过对YOLO 算法和混合现实进行一系列对比实验,可提出一种新设想,利用YOLO 算法来改进混合现实的不足。首先对混合现实技术和YOLO 的原理及发展现状进行介绍,在此基础上,分别对混合现实技术和YOLO 在目标识别方面的效果进行实验。
2 混合现实的发展及相关原理
混合现实技术是利用摄像头拍摄真实场景,结合移动终端里传感器的数据,实时地把虚拟物体叠加到真实场景中,并进行数据交互的一项技术,其交互的形式有很多种,如文字,视频,模型,音频等[9]。混合现实有三大关键技术:目标识别、跟踪注册以及高效渲染。目标识别技术指的是迅速在场景里找到需要被识别的目标,达到快速理解现实场景的效果;目标跟踪技术在应用中有两种形式,第一种用检测和分类的方式,使用机器学习算法训练识别目标,以生成对应的模型;第二种是用图像识别的方式,提取识别目标图像中所包含的特征信息,在系统运行时实时地提取数据流图像特征,同时与目标图像相匹配,以实现快速定位被识别目标[10]。
早期的混合现实系统受移动设备存储计算能力的限制,主流方法是使用有标志物的识别方式[11],首先使用黑白两种颜色来制作正方形模板,它的灰度直方图分布只有两个峰值,然后采用最大类间方差法来对图像二值化处理,首先识别出黑色边框,接着提取四个角点跟踪监测,以实现对摄像头位姿的估计。但这种模板存储的特征比较少,而且支持的模式有限,在实际的场景中应用起来有些笨重。所以混合现实的趋势是向无标志物的识别[12]上发展,无标志物的识别以场景的特征描述为重点识别途径,比如颜色、纹理、形状、自然特征点。这些特征都能够用一个一位的特征向量来描述,在检索阶段都要选用对应的相似度匹配方法。比较常见的相似度计算方法有汉明距离、欧几里得距离、皮尔森相关系数等。
在神经网络出现后,深度学习在图像识别领域迅猛发展。它使用TensorFlow 的深度学习框架,与LeNet-5 的神经网络结构相结合,能自动学习和提取图像里的特征。此方法在对大量图片的识别、分类的情况下尤为有效。深度学习的缺点是它只适用于大量图片的情况,若图像集过少就难以发挥作用。
3 算法对比
使用混合现实技术的基于标记和基于内容的图像识别方法跟新产生的基于深度学习的图像识别方法进行比较,选取其中具有代表性的SIFT[13]和YOLO算法进行介绍和对比。
3.1 尺度不变特征变换匹配算法
为获取不同尺度且尺度连续的众多图片,要以高斯金字塔为图片进行高斯滤波。高斯金字塔为一个原始的图像,产生不同组,每一组中又包含不同层。尺度不变特征变换匹配算法,即SIFT,通过引入尺度空间的概念引入尺度不变性,把一张图片使用高斯卷积操作生成了多个尺度的图片,然后加入多分辨率框架,每次都把采样宽高降为原图的1/2。接下来对同层的相邻图片进行差分操作,可以生成高斯差分金字塔(DoG)。在DoG 中,采用了区域搜索算法来寻找最大值或最小值点,考察其中每个点的领域点,包括周围的8 个点和上下相邻尺度的18 个点,共26 点。一个点若是在26 个领域点中是最大值或者是最小值,则可认为其是图像在对应尺度下的一个特征点。检测完所有点后,使用相应的算法来去掉其中不好的点及边缘的特征点,以此更稳定地提取特征点。
SIFT 算法首先计算特征点周围邻域像素的梯度方向,然后把方向累积直方图统计出来,接着设置累计值最大的方向当作该特征点的主方向,把后面特征点描述的坐标轴方向旋转成和特征点的主方向一致。所以旋转过的图片也会和原图片里的特征描述一致,从而实现旋转不变性。
提取完特征点后,需要建立关键点之间的映射关系,从而把同一个空间点在不同的图像里的映像点对应起来,也就是寻找帧图像与帧图像之间对应部分的一个过程。确定目标图像和图像特征点集是否相匹配,可大致分为以下几步进行[14]:
1)假设目标的特征点集和它的图像特征点集存在一个对应关系;
2)通过这个关系来计算两者之间发生的变换;
3)应用该变换到目标点上,获得变换以后的目标点集;
4)比较变换后的目标点集与图像的特征点集,以验证假设是否正确。
一般情况下匹配算法基于欧式距离,达到所设置的距离阈值,即为所接受的匹配点对。特征点匹配完成后,需要确定真实环境和目标图像之间的位置关系,为三维注册做好准备[15]。混合现实的效果好坏主要由三维注册决定,它把虚拟物体的大小、位置等信息与真实场景的标志物进行对位匹配,匹配程度越高,混合现实的效果越好,这便是混合现实技术的工作原理[16]。
3.2 实时目标检测算法
实时目标检测算法,即YOLO,其CNN 网络把要输入的图像分为S×S 的网格,网格里每个单元负责检测中心点落在网格里的位置。每个单元格需要预测B 个边界框的值,包括坐标、宽高、置信度[17]。
每个网格在输出边界框值时要给出其存在物体的类型,记为Pr(Classi|Object),这是条件概率。输出的种类概率值只和网格有关,和边界框无关,所以一个网格只能输出C 个种类信息。在检测目标时,通过有关算法可得到每个单元格的每个种类的置信度得分,包括预测的类别信息和对边界框值的准确度判断。随之可设置一个阈值,滤掉低得分单元格,把剩下的进行非极大值抑制,从而得到最终的标定框。
4 对比实验方案
根据对混合现实特征点匹配技术中SIFT 算法和YOLO 算法的原理分析,可知SIFT 算法对尺度缩放、旋转等具有鲁棒性,是一种非常稳定的局部特征算法。但其生成的描述子维度太高,且时间复杂度很高,在实际应用中效率不够高。另外,使用SIFT 在图像配准中有着误匹配和漏掉正确匹配对的问题,算法的匹配效果对阈值非常敏感,效果不太理想。YOLO 算法有着速度快、准确度高的优点,但YOLO的每个单元格只预测两个边界框,且属于同一种类别,即是说每个单元格只能预测一类物体,所以在识别小物体上的效果不尽如人意。在测试图像中,同一种物体若是出现不常见的比例等特殊情况,YOLO的泛化能力较弱。在损失函数方面,定位误差是影响检测效果的关键原因,YOLO 在处理大小不同的物体的方法还需要改进。
由此可以看出,混合现实的特征点匹配技术中的SIFT 算法还存在着许多不足之处,这在很大程度上决定着混合现实的识别效果,目前的混合现实技术识别中,许多问题与此有关,比如:识别速度较慢,通常要2 秒钟才能成功显示虚拟信息;识别出来的虚拟信息不稳定,容易出现抖动、变形等现象;识别的距离太短,通常只可在2 米范围内进行识别等。而YOLO 算法在识别方面有着极大的优势,它识别速度快,准确度高的优点正好弥补了混合现实技术最大的不足。所以可以把YOLO 算法和混合现实技术在目标识别方面结合起来,从而改进混合现实识别速度慢、不稳定的现状。
为此,对混合现实技术进行如下两组实验:首先进行混合现实有标志物和无标志物的识别比较;再对混合现实的识别距离进行测试;接着测试混合现实的多目标识别效果;然后通过对三维物体的全方位拍照,组成一个三维的特征点集,从而实现对三维物体的识别;最后改变三维物体的角度,测试混合现实对三维物体的识别效果。
再对YOLO 算法进行如下实验:首先测试YOLO的识别距离;然后测试YOLO 对多目标的识别效果;最后测试YOLO 对不同角度的物体识别效果。
在两组实验完成后,对各组结果进行比较,为两者的结合做好准备工作。方案的流程见图1。
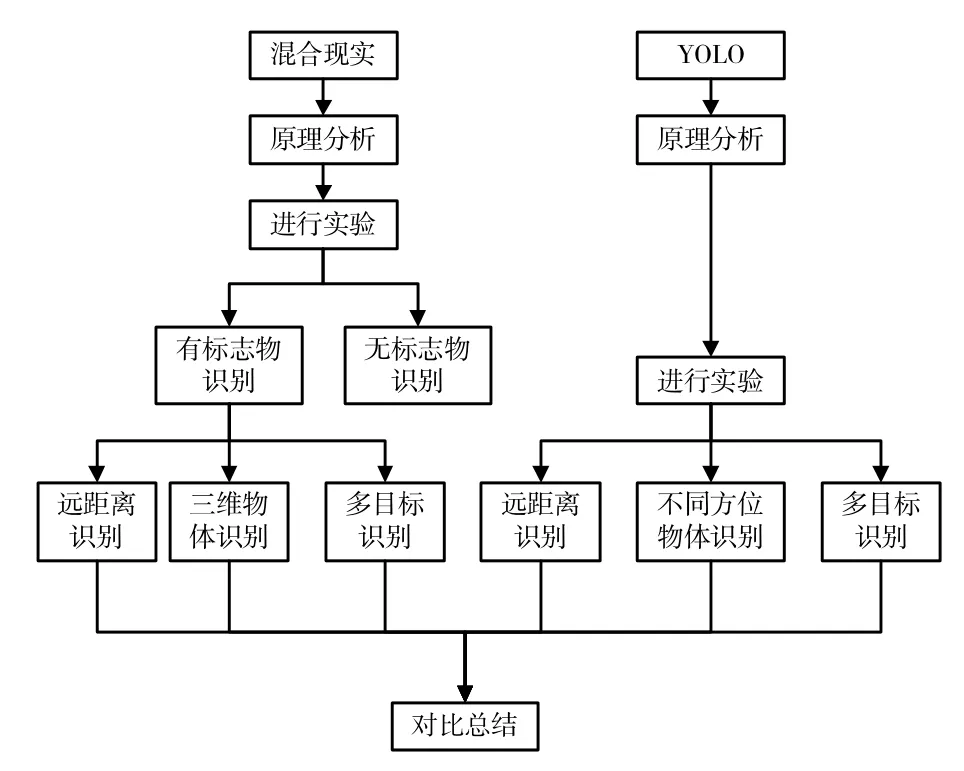
图1 新方案流程图
经实验,混合现实的特征点匹配技术与YOLO在目标检测方面的效果对比可归纳为表1。

表1 混合现实的特征点匹配技术与YOLO 对比
从表中可见,混合现实的特征点匹配技术在表现形式上很有优势,可以准确识别物体,并用多样的方式表现出来,生动而直观;YOLO 则只能用单一的边界框和注释来表现,有时还会产生误识别。但在识别距离、速度、稳定性以及识别物体个数上YOLO有很明显的优势;要想识别一个物体,1m 的距离显然远远不够,很有必要增加识别距离;混合现实的特征点匹配技术追求虚实融合,要尽量贴近真实的环境,如果识别速度过慢、识别出来的虚拟物体不稳定,会给用户一种不真实的感觉,极大影响了用户的体验;混合现实的特征点匹配技术要为每个将被识别的物体添加虚拟信息,如果物体太多工作量会很大,而YOLO 通过对一组图片进行训练来学习图片特征,很适合大数据集的工作,但如果数据集过小,则无法提取足够的特征,很难成功识别。
5 实验过程与结果分析
实验在移动端使用Android 9 手机,在电脑端使用Windows 10 笔记本电脑。混合现实是通过Unity3D引擎搭配Wikitude SDK 来搭建框架。将搜集到的相关fbx 格式模型导入Unity3D 中,再把准备好作为标志物的图片上传到Wikitude Studio 中,并下载所生成的wtc 格式文件。把包含标志物信息的文件导入Unity 中,搭配下载好的模型便可成功运行有标志物的识别,如图2(a)所示。无标志物的识别和上述方式类似,但不需要预先准备好标注物,只需把模型直接手动拖拽至指定位置便可,如图2(b)所示。

图2 混合现实的两种识别方式
混合现实还可以同时识别多个标志物,但识别距离较短过程较慢,实验结果如图3所示。

图3 混合现实多标志物的识别
由图3可看出,当摄像头距离标注物1 米(左图)时可以同时识别多个标志物,但当摄像头距离标志物2 米(右图)时就很难再顺利识别。
目前混合现实在识别图像上已经越来越稳定,技术也日渐成熟,但在识别三维物体的方面,混合现实技术还不够完善。如何更好地识别三维物体是当下混合现实技术的一项难题。把识别二维图像的思路应用到识别三维物体上,拟对三维物体拍一张照片并把照片作为标志物进行识别,实验发现仅使用一张照片无法成功识别该物体。接下来对三维物体进行全方位拍照,共拍摄十张照片,并将照片上传到Wikitude Studio 中,如图4所示。

图4 Wikitude Studio 界面
由Wikitude Studio 提取图像中的特征点,并把所有图像中的特征点组合起来,搭建成一个三维的特征点集,下载所生成的wto 格式文件,再把下载的含有被识别物体信息的文件导入Unity3D 中再次实验。结果表明用十张照片提取特征点后能够成功识别,效果图5所示。

图5 混合现实物体识别实验效果图
对比图5中的两幅图可明显看出,使用混合现实的特征点匹配技术对物体进行识别的效果不太稳定。当被识别的物体进行稍微的移动或旋转时,为物体添加的虚拟信息会产生大幅度的偏移或扭曲,这在实际应用中很难给用户良好的体验。除此之外在实验中还暴露了混合现实特征点匹配的识别技术存在的许多问题,比如识别距离过短,用户必须把摄像头置于距物体一米以内才能成功识别该物体;识别时间稍长,用户必须把物体和摄像头都稳定住至少两秒钟,才能顺利识别,物体或摄像头的轻微移动都可能会终止识别等。
随后使用DarkFlow 框架,Python 3.6+TensorFlow 1.11+NumPy1.15.2+OpenCV 3.4.3 的环境运行深度学习的YOLO,实验效果如图6所示。
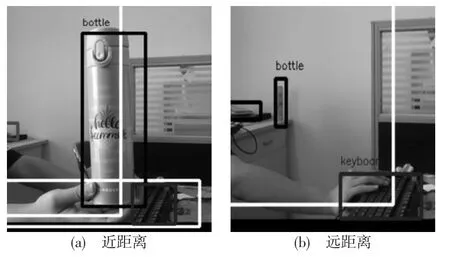
图6 YOLO 实验效果图
从图6的实验中能够发现,YOLO 具有很多优点,比如:YOLO 的识别距离很长,能准确识别5 米以外的物体;YOLO 可以同时识别多个物体;YOLO的识别速度特别快,只需要不到1 秒就可成功识别;YOLO 识别物体非常稳定,边界框始终紧紧地围绕着被识别物体,没有漂移变形的现象发生等。但是YOLO 也有一些缺点,比如可能会误识别一些物体,这很可能会对用户造成误导。
同样是目标识别,混合现实的特征点匹配识别和YOLO 识别结果的表现形式还是大不相同的。比较两者对二维图像的识别效果,如图7所示。


图7 用两种方法识别二维图片
由图6和图7(a)可知,YOLO 在成功识别后只可标记识别到的物体并标记上边界框和注释,表现形式单一;而由图5和图7(b)可知,混合现实在识别成功后可以有多种表现形式,如文字,模型等,而且还可以为模型添加事件,如点击模型便可展示注释、音频等交互内容,表现形式非常丰富。
最后,比较两者对三维物体的识别效果,实验效果如图8所示。

图8 用两种方识别三维物体
可见,相比YOLO,混合现实的特征点匹配技术在识别三维物体上还有很大的进步空间。由图7(a)可见,YOLO 识别出来的边界框就好像是镶在物体边缘一样,紧紧地与物体融为一体;而由图5和图7(b)可知,混合现实的特征点匹配技术识别不够稳定,识别出来的虚拟信息经常出现抖动、变形、消失等现象,无法给人一种理想的虚实结合的感觉。由图3和图6(b)可知,混合现实的特征点匹配技术的识别距离太短,无法实现大场景远距离的识别,而YOLO 可以轻易实现。
以两者的识别速度做比较,当物体出现在摄像头前时,混合现实要等2~3 秒才能顺利识别,而YOLO 只需要1 秒便可成功识别。
比较两者对三维物体的识别情况,由图8可知,当混合现实识别的物体旋转时,上面添加的虚拟物体也会随之旋转,而YOLO 识别的物体旋转时,边界框保持原样,可见YOLO 识别的表现形式没有混合现实好。
由此可知混合现实技术在成功识别物体后可以有很多种表现形式,但存在着识别距离短,识别时间长,识别不稳定的问题。而YOLO 算法有着识别距离长,识别时间短,且识别稳定的优势,可弥补混合现实的特征点匹配技术的不足。
6 结 束 语
通过介绍混合现实技术以及YOLO 算法的发展现状和原理,把两者在目标识别方面进行了对比实验。从实验可以看到YOLO 在目标识别方面有着很大的优势,而混合现实的特征点匹配技术在这一块还存在着许多不足,所以很有必要把YOLO 结合到混合现实中去,取长补短,增加混合现实的识别距离、识别速度、稳定性,同时扩展混合现实的识别范围,让混合现实能够识别三维物体。这样才能让混合现实技术达到更加逼真的效果,带来更好的用户体验,从而大大增加混合现实技术的应用范围和领域。
猜你喜欢
文苑(2020年11期)2021-01-04 01:53:20
中学生数理化·高一版(2020年1期)2020-02-20 13:24:32
中学生数理化·八年级物理人教版(2018年10期)2018-12-06 09:33:16
中华老年多器官疾病杂志(2016年9期)2016-04-28 08:52:44
现代计算机(2016年12期)2016-02-28 18:35:29
医学研究杂志(2015年7期)2015-06-22 11:01:10
科普童话·百科探秘(2015年4期)2015-05-14 07:06:42
现代检验医学杂志(2015年6期)2015-02-06 01:44:22
现代检验医学杂志(2015年5期)2015-02-06 01:42:23
中国卫生(2014年12期)2014-11-12 13:12:38
