
基于单边带调制的隐蔽语音传输方案
2019-11-05 07:42:02徐争光
应用科学学报 2019年5期
余 鑫,徐争光
华中科技大学电子信息与通信学院,武汉430074
随着智能手机的普及,手机使用的安全性越来越受到重视.语音通信是一种日常生活中使用非常频繁的业务,普通的4G 电话、QQ 语音、微信语音消息都属于语音通信范畴.智能手机的这些新功能虽然为人们提供了方便,但也给木马、病毒提供了可乘之机.木马软件通过监听或录音窃取用户语音信息,对用户造成很大危害.因此,手机防窃听方案的研究工作是非常有价值的.
抵抗木马软件窃听的防御手段主要有两种:一是语音加密,二是语音隐藏.语音加密是将用户的语音通过某种方法进行加密,从而保证在传输过程中即使攻击者截获语音信息也难以破译.常见的语音加密方案包括混沌加密[1]、DCT 加密[2]、AES 加密[3]等.加密后的语音往往与正常语音不同,容易引起攻击者的注意,而且这些语音加密方案都是基于软件实现的,攻击者要破解这些方案需要足够强大的算力.相比之下,语音隐藏方案不易引起攻击者的注意,安全性能更好.文献[4]提出了一种能够用于电话电路的隐蔽语音传输方案,该方案将隐蔽语音量化编码后采用最低比特替换的方式加入明文语音中,通信质量较好.但该方案如果在智能手机上实现,需要修改手机的系统软件,实现成本较高.文献[4]采用的是时域方法,后来研究人员提出了变换域方法实现语音隐蔽技术(如DCT 变换[5]、小波变换[6])将保密语音隐藏到变换域的系数中,这些基于变换域的方法对于噪声和重量化攻击具有较好的鲁棒性,但抗重采样能力较弱.同时,基于变换域的方案往往计算量较大,不利于实时实现,即使采用高性能的DSP 来实时实现,也会提高保密系统的成本.
近年来,隐蔽语音传输的研究成果较少,主要原因是随着计算机网络的发展,数据传输的需求大大高于语音传输,研究人员纷纷转向数据文件的隐蔽传输研究[7].虽然语音量化编码形成数据文件后可以降低传输的数据量,但也会增加实现成本,应用到手机上往往需要改动手机的软硬件.因此,本文提出一种应用简单、成本低且抗干扰防篡改的隐蔽语音传输方案,可以方便地应用于现有手机电话业务及各种聊天软件的语音传输中.对用户来说,在发送端只需通过麦克输入隐秘语音和正常通话语音,就可以完成隐秘语音嵌入;同样,在接收端通过耳机或者外放设备就可以听到隐秘语音和正常通话语音,不会增加用户使用的难度.
与传统隐蔽语音传输方案相比,本文提出的方案优势如下:
1)应用简单.无需改动现有手机的软硬件,可方便应用于不同品牌手机.
2)抗干扰能力强.嵌入的隐蔽语音是模拟信号,本身具有较高的冗余性,即使在传输过程中,隐蔽语音存在一定畸变,在接收端仍可通过人耳分辨出发送者要传输的信息.
3)隐秘性强.压缩和编码等数字域的处理方案仍可以从统计和编码特征等角度发现隐藏信息的痕迹,在模拟域进行音频信号的处理,不会引入数字特征,对后续的压缩和编码没有依赖和影响.
4)成本较低.采用时域处理嵌入隐蔽语音,避开了复杂的变换域计算,可采用全模拟器件实现,所需硬件成本较低.
本文进行了仿真验证且已完成原型系统实现,能够实现电话、QQ、微信中的隐蔽语音传输.
1 隐蔽语音传输方案
1.1 系统工作原理
单向工作原理如图1所示.正常语音和隐蔽语音通过语音合成器实时组成一个合成语音,然后通过音频线输入到手机的音频输入口,发射手机按照正常处理流程对音频口输入的模拟语音信号进行量化、编码、调制处理,然后通过天线发射出去.接收手机从天线上收到信号后,经过正常解调、解码后还原出模拟语音,将模拟语音通过音频输出口传输给语音分离器,语音分离器实时分离出正常语音和隐蔽语音.
显然,这里的语音合成器要满足如下要求:1)不能对正常语音造成过多的失真;2)嵌入的隐蔽语音在通过手机语音压缩算法处理后不会出现太大的失真;3)合成语音过程中对于正常语音带来的延迟不能过大;4)合成算法要尽量简单,从而降低语音合成器的硬件成本.同理,语音分离器也要满足类似的要求.下面讨论语音合成器和语音分离器的具体实现方案.

图1 系统工作原理示意图Figure1 Schematic diagram of the system principle
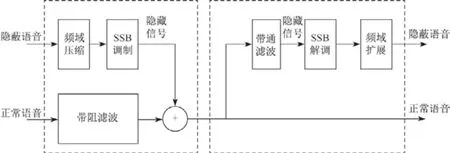
图2 系统实现框图Figure2 Schematic diagram of the system implementation
1.2 系统实现方案
如图2所示,语音合成器包括带阻滤波器、频域压缩模块、单边带调制(single side band,SSB)调制器3 部分.理想带阻滤波器的传递函数定义为
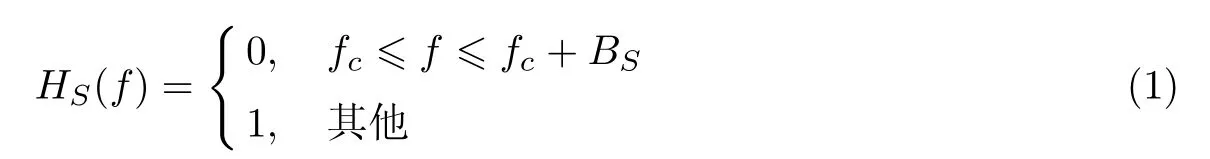
式中,fc为SSB 调制的载波频率,B为带阻滤波器的阻带带宽.正常语音信号通过这个带阻滤波器以后,在频率上形成一个带宽为B的频域空洞,而调制出来的SSB 信号就放入到这个频域空洞中.选择单边带调制方式是因为单边带调制后信号的带宽与待调制信号相同,不会增加信号带宽.
下面介绍SSB 的调制原理.设待调制的信号为m(t),经过希尔伯特变换后可表示为(t),这里的希尔伯特变换是一个宽带移相网络,对m(t)中任意频率分量均相移π/2 即可得到(t).于是SSB 调制信号可表示为[8]
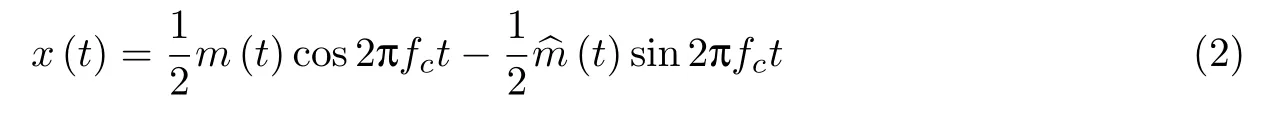
若信号m(t)的带宽为Bm,则调制后SSB 信号x(t)的带宽仍然为Bm.因此,上述SSB 信号也可以通过将双边带信号m(t)cos 2πfct通过如下的高通滤波器得到

因此,在实际工程中可以用移相器或者高通滤波器来实现SSB 调制.
由于要传输的隐蔽语音带宽至少为B=4 kHz,直接采用SSB 调制后带宽仍然为4 kHz.显然带阻滤波器所形成的频域空洞小于这个带宽,因此必须对隐蔽语音的带宽进行压缩.根据带宽和持续时间成反比的关系,压缩带宽的代价就是隐蔽语音持续时间的拉长.设隐蔽语音表示为s(t),持续时间为T.如果将其频带压缩到原来的1/M,则可通过内插函数将其持续时间拉长为MT.例如原来1 s 有8 000个采样点,通过插值以后变成64 000个采样点.仍然通过原有采样率8 000 Hz 进行播放,这样播放时间就延长到了8 s,于是就拉长了持续时间.具体地,设s(t)采样率为fs= 2B,可将其重采样为s′(t),其采样率f′s= 2 MB.如果仍以原有采样率来看,s′(t)的持续时间增长为原来的M倍,带宽变为原来的1/M,从而满足BS=B/M,使压缩后的信号能够放进带阻滤波器产生的频域空洞中.
综上所述,语音合成器的工作步骤如下:
步骤1带阻滤波器将正常语音v(t)中指定频率成分滤除,得到信号vS(t);
步骤2频域压缩模块将隐蔽语音s(t)的持续时间拉长到原来的M倍,形成s′(t);
步骤3SSB调制模块将m(t)=s′(t)调制到载频fc上,得到的信号为x(t);
步骤4最后得到合成信号y(t)=vS(t)+x(t).
语音分离器的工作原理是语音合成器的逆过程,主要包括带通滤波器、SSB解调器和频域扩展模块.首先定义带通滤波器的传输函数为
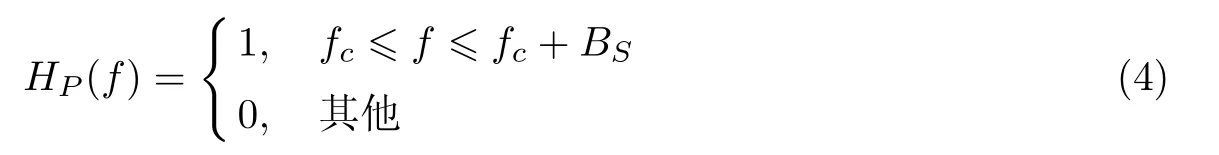
将合成信号y(t)通过带通滤波器即可得到x(t).然后通过相干解调方法对SSB信号进行解调,即用载波2cos 2πfct乘以接收信号x(t),即
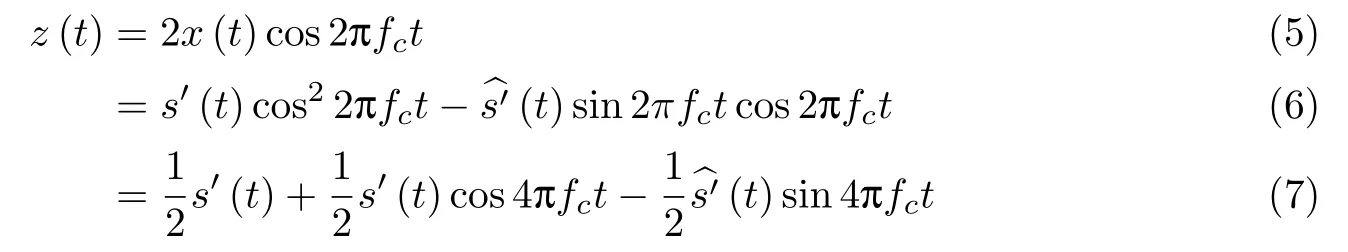
再将z(t)通过一个带宽为BS的低通滤波器,即

就可以恢复出s′(t).最后通过重采样方法将s′(t)压缩到1/M的持续时间,从而恢复出原来的隐蔽语音s(t).而对于正常语音而言,因为隐蔽语音频带很窄,以至于人耳无法识别,所以可以直接播放合成语音y(t),不会对正常语音通信造成影响.
综上所述,语音分离器的工作步骤如下:
步骤1通过带通滤波器将隐蔽语音信号x(t)提取出来;
步骤2SSB解调模块从x(t)中解调出时间拉长后的语音信号s′(t);
步骤3通过重采样将s′(t)在时域上压缩为1/M,从而恢复出隐蔽语音s(t).
2 方案参数设定和实现难点
本方案主要参数为SSB 载波频率fc、频域空洞带宽BS、频域压缩系数1/M.
1)频域压缩系数1/M.隐蔽语音频域压缩的目的是将隐蔽语音频带压缩后能放入带阻滤波器所形成的频域空洞中,因此隐蔽语音带宽B、压缩系数1/M、频域空洞带宽BS必须满足BS=B/M.通常隐蔽语音带宽B=4 kHz 是固定的,因此BS和1/M是相互可以换算的.压缩系数1/M不是独立参数可以根据BS来设定.那么,载波频率fc和频域空洞带宽BS可以自由设定.
2)fc的选择与人耳的听力范围有关,理想情况下应设置在300 Hz 以下.但语音压缩算法往往会削弱300 Hz 以下的信号,从而破坏隐蔽语音成分,因此应在人耳听力范围和手机压缩算法能力之间折中选择fc.当然,固定的fc易被察觉,未来的改进方向是融合跳频技术,通过变化的fc进一步降低人耳察觉的概率.
3)空洞带宽BS的选择.BS越小则正常语音失真也越小,要求是隐蔽语音在频域上具有更大的压缩率,但这样会导致隐蔽语音在时间上被拉得更长,从而降低了隐蔽语音的传输效率.因此,应在正常语音失真度和隐蔽语音传输效率上折中选择BS.
针对前面提出的语音合成器和分离器逐个检验需要满足以下4个要求:
1)语音失真度要求.语音失真度可以通过BS来调整,理论上BS可以无穷小,那么隐蔽语音传输的时间会拉得无穷大,因此需要在语音失真度能够容忍的范围内,合理的选择BS参数.
2)手机的语音压缩算法对隐蔽语音信号的影响.本方案中隐蔽语音信号存在于fc到fc+BS之间的狭小频带中,只要这个频带位于人耳正常的听力范围内,手机的语音压缩算法就无法区分隐蔽信号和正常语音,因此不会对隐蔽信号造成过大的影响.
3)语音合成和分离处理不能对于正常语音带来过大的延迟,通常延迟不超过20 ms.在本系统中带来延迟的主要因素是语音合成器中的带阻滤波器.随着带阻滤波器阶数的增加,滤波效果会变好,但带来的延迟也会随之增加,因此在实现语音合成器时需要同时考虑延迟和滤波效果.
4)系统实现成本问题.在语音合成器中的主要部件是带阻滤波器、频域压缩模块、SSB 调制器.其中,带阻滤波器和SSB 调制器都可采用全模拟器件来实现,频域压缩模块是对隐蔽语音的重采样,可以用专用芯片来实现,批量生产的成本会降低.语音分离器的主要部件是带通滤波器、SSB 解调器、频域扩展模块,带通滤波器和SSB 解调器同样可以用全模拟器件来实现,频域扩展模块也是对隐蔽语音的重采样,批量生产后成本也很低.因此,本方案不需要采用复杂的算法便可以实现低成本.
为了进一步提高隐蔽语音的安全性,可以在隐秘语音进入语音合成器之前对隐秘语音进行频域置乱加密处理[9],具体步骤如下:
步骤1首先对模拟语音进行数字采样;
步骤2对数字采样后的语音信号进行傅里叶变换,将语音信号转到频域中;
步骤3对频域中的傅里叶系数按照一定规则进行置乱操作,打乱原有频域分布规律;
步骤4对频域信号进行逆傅里叶变换转到时域中,即可得到对应的加密语音.
在接收端采用相反的步骤即可恢复原始隐秘语音信号.即使加密语音在传输过程中被截获,但因截获者不知道频域置乱的具体方案而无法还原隐秘语音,从而增强了隐秘语音信息的安全性.频域置乱算法是经典的模拟语音加密算法,目前该加密算法已应用于原型系统中,实验证明语音加密后可以还原.
3 算法性能仿真分析
为了衡量本文提出的语音隐藏算法性能,定义接收正常语音的失真度为接收端收到的正常语音与发送端发送的正常语音之间的均方误差,隐蔽语音的失真度为接收端收到的隐蔽语音与发送端发送的隐蔽语音之间的均方误差.根据前文分析可知,这两个失真度均与频域空洞带宽BS和滤波器阶数N有关.
图3给出了频域空洞带宽BS与失真度的关系,此时系统中所有滤波器系数N固定为160 阶.从图中可以看出随着空洞带宽增加,正常语音失真度增大,这是因为空洞带宽增大使更多正常语音成分被滤除,从而导致正常语音失真增大.在空洞带宽较小时,隐蔽语音失真度基本不变,此时隐蔽语音的失真主要由滤波器系数误差引入.当空洞带宽较大时,隐蔽语音与正常语音有较大的频谱重叠,由于带限滤波器不能完全消除正常语音成分,此时隐蔽语音失真主要由残留的正常语音产生.从图中可以看出,频域空洞带宽选择250~500 Hz 比较合适,因此在原型系统中,载频fc=2 000 Hz,带宽BS=250 Hz.

图3 频域空洞带宽与失真度的关系Figure3 Relationship between the bandwidth of the frequency domain void and distortions
图4给出了滤波器阶数N与失真度的关系,此时频域空洞带宽BS固定为250 Hz.从图中可以看出,随着滤波器系数增加,正常语音和隐蔽语音的失真度都在减小.这是因为滤波器系数增加时,滤波器的滤波性能更好,但相应的计算量和语音处理延迟都会增加.为了保证语音延迟在20 ms 以内,滤波器的系数不宜大于160 阶.因此,在原型系统中滤波器系数为160阶,语音处理延迟为20 ms.
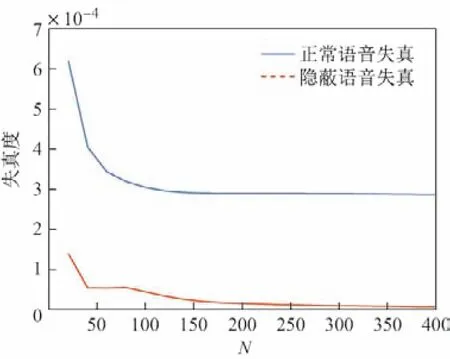
图4 滤波器阶数与失真度的关系Figure4 Relationship between the order of the filter and distortions
4 原型系统实现方案
为了验证本文算法的可行性,采用树莓派硬件平台快速搭建了一个原型系统,其硬件系统框图如图3所示,该系统采用全双工工作模式,通过麦克风接收正常语音,使用喇叭输出正常语音,隐蔽语音以文件形式保存与手机间传输混合后的语音模拟信号.
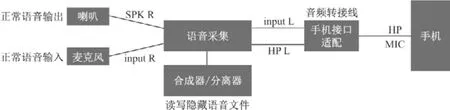
图5 原型系统硬件框图Figure5 Hardware diagram of the prototype system
在发送路径上,读取隐蔽语音文件后与正常语音经合成器模块合成后输出至手机.在接收路径上,通过耳麦接口接收的手机语音信号,经过分离器后得到还原两路语音,正常语音通过喇叭播放,隐蔽语音保存为文件.具体实现包括:
1)合成/分离器采用树莓派3B+硬件平台,基于Python 环境使用MIT 的pyaudio 库采集和播放音频,并使用scipy 库开发语音合成和分离算法.
2)语音采集使用WM8960 立体声编解码器模块,该模块支持双声道语音输入输出,原型系统中将芯片左声道输入(Input L)用于正常语音的麦克风输入,左声道耳机输出(HP L)用于混合语音发送;将右声道扬声器输出(SPK R)用于正常语音输出,右声道输入(Input R)用于混合语音接收,从而实现全双工处理.
3)手机接口适配用于实现3.5 mm 标准耳麦机接口中耳机(HP)和麦克风(MIC)的分离的电气连接和阻抗匹配.
最后实现的原型系统实物图如图4所示.在这个原型系统中,单个语音合成/分离器的成本是400 元,如果后期批量生产,采用全模拟器件来实现成本更低.

图6 语音合成/分离器实物图Figure6 Voice synthesis/separation equipment
5 结 语
本文提出了一种基于单边带调制的隐蔽语音传输方案,具有应用简单、成本低廉的特点.该系统通过模拟调制方案将隐蔽语音嵌入到正常语音的频域空洞中,从而实现隐秘语音传输.同时,为了保证隐秘语音的安全性,还引入了频域置乱加密措施,即使隐秘语音被截获,攻击者如果不了解频域置乱规则,也无法恢复出隐秘语音信息.为了验证该方案的可行性,采用树莓派硬件平台快速搭建了一个原型系统,实验结果表明该系统能够在不改变现有手机软硬件的情况下,方便的实现隐秘语音传输.
猜你喜欢
雷达学报(2018年3期)2018-07-18 02:41:34
电脑知识与技术(2018年30期)2018-01-04 11:06:12
故事作文·高年级(2017年2期)2017-03-01 13:03:27
火控雷达技术(2016年1期)2016-02-06 02:17:55
无线电通信技术(2015年3期)2015-12-23 11:37:02
新闻传播(2015年20期)2015-07-18 11:06:46
计量技术(2015年3期)2015-06-07 12:05:44
电测与仪表(2015年3期)2015-04-09 11:37:24
天津科技(2014年4期)2014-05-14 01:49:32
电测与仪表(2014年19期)2014-04-04 12:06:16
