
基于SVM的豆类作物病害识别研究
2019-11-03 13:11彭勤高士彭佳红
电脑知识与技术 2019年24期
彭勤 高士 彭佳红


摘要:病害智能预测识别在农业信息化领域起着重要的作用,也是一实用性很强的应用技术。基于机器学习中的支持向量机SVM分类技术,对豆类病害特征属性进行分类与豆类作物斑病进行智能识别。结果表明,支持向量机SVM建立的识别模型准确率为93.27%,能够辅助豆类作物的生产与科学管理。
关键词:豆类作物;支持向量机;病害
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2019)24-0210-02
开放科学(资源服务)标识码(OSID):
1 概述
随着国内豆类作物产量需求的提高与计算机智能识别技术的迅速发展,豆类作物病害的智能识别及预防越来越受到大家的关注。病害预测识别是一门实用性很强的科学应用技术,在农业信息化领域起着重要的作用。
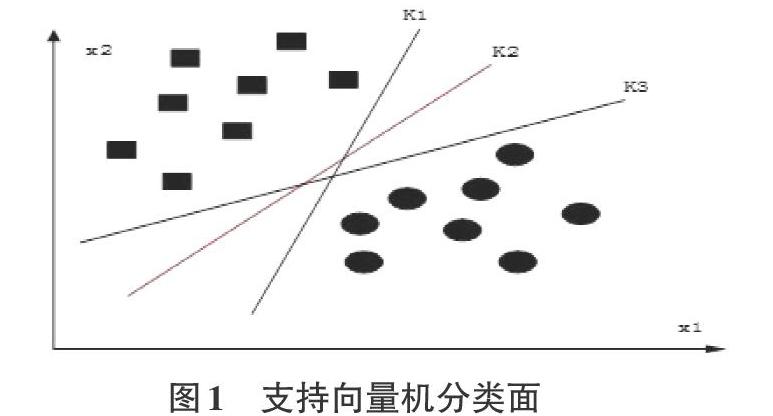
支持向量机SVM(Support Vector Machine)是一種监督性的机器学习,主要运用于数据的分类和回归分析,同时SVM也称最大间隔分类器[1],其最大间隔分类器原理如图1所示。
超平面K1、K2、K3都能将数据类进行分别。但基于二分法健壮性约束,K2分割平面是最鲁棒性的。
在样本分类空间中,线性支持向量机的分割超平面方程[2]表示如下:
[wT?x+b=0;]
其中w为超平面的法向量[3],b表示测试原点到超平面的偏移量,当测试数据可以被超平面分割时,就需要选择鲁棒值最高的分割超平面。而“最大间隔”的平面寻找即选择支持向量平面之间能平分距离的平面。支持向量的平面可以表示为:
[-1≤wT?x+b≤1;]
由此可以得出两个支持向量平面之间的距离γ为2b或2/||w||[4]。因此,平面间隔之间最大,则||w||取最小即可。所以取两端值是最好的,如图2所示。
2 豆类病害SVM识别
基于网络爬虫技术获取了豆类病害样本数据401条,对于豆类病害将其分成斑类病害与非斑类病害两类。病害症状的描述为颜色、斑形状、斑部位等,对原始数据进行数值化见表1。
利用SVM算法组件对样本数据预测识别[6,7],模型如图3所示。
其中,sjjy-1为原始数据表,a、b、c、d、e为特征列,f为标签列;线性支持向量机的正例惩罚因子设置为1.0,负例惩罚因子设置为1.0,收敛系数设置为0.001,计算的核心数自动调优,每个核心的内存也自动调优。通过训练学习建立最优二分类预测模型;xyg.sjjy-2为检验数据表(取原始数据表的前100行),只有特征列;输入预测模型“预测-2”进行预测。将预测结果输入到表“sjjy_jg-1”,即表2。
结果表明,SVM建立的识别模型准确率为93.27%,错误率为6.73%。
3 结束语
豆类作物产量是我国农作物产量的核心之一,保证豆类作物产量的持续提升是国家关注的重点,而豆类病害是制约豆类作物产量的重要因素之一,影响着豆类作物的生产和质量。本文基于机器学习中的支持向量机SVM分类技术对豆类作物的斑病进行智能识别,能够辅助豆类作物的生产与科学管理。
参考文献:
[1] 曹正凤. 随机森林算法优化研究[D]. 北京:首都经济贸易大学, 2014.
[2] 刘东启,陈志坚,徐银,等.面向不平衡数据分类的复合SVM算法研究[J].计算机应用研究,2018(4).
[3] 叶明全,高凌云,万春圆.基于人工蜂群和SVM的基因表达数据分类[J].山东大学学报:工版,2018,48(3):1-8.
[4] 潘曙光,刘香,唐圣学, 等.基于网格搜索的改进SVM模拟电路故障诊断方法[J].微电子学,2018,48(1):108-114.
[5] 朱刘影,杨思春.基于SVM的地理试题自动分类[J].计算机应用研究,2018(9):1-2.
[6] 汤荣志, 段会川, 孙海涛. SVM训练数据归一化研究[J]. 山东师范大学学报:自然科学版, 2016, 12(15): 114-117.
[7] Huang Shujun,Cai Nianguang,Pacheco Pedro Penzuti,et al. Applications of Support Vector Machine (SVM) Learning in Cancer Genomics[J]. Cancer genomics & proteomics,2018,15(1):67-145.
【通联编辑:谢媛媛】
猜你喜欢
今日农业(2022年3期)2022-06-05
今日农业(2021年8期)2021-11-28
烟台果树(2021年2期)2021-07-21
今日农业(2020年19期)2020-11-06
今日农业(2019年13期)2019-08-12
当代水产(2018年12期)2018-05-16
中国水运(2016年11期)2017-01-04
科学与财富(2016年28期)2016-10-14
