
面向高维数据环境的个性化推荐质量控制模型研究
2019-10-30 13:04宋梅青
现代情报 2019年11期
宋梅青


摘 要:[目的/意义]在高维数据环境下,推荐的精准度和实时性存在相互制约的现象。如何在精准度与实时性之间取得平衡,实现对推荐质量的有效控制是值得研究的问题。[方法/过程]本文首先分析了高维数据环境的成因及其对推荐质量的影响,在此基础上构建了一种个性化推荐质量控制模型,该模型先评估推荐质量在精准度和实时性两个方面的损失,再结合应用环境,得到相应的质量控制策略。[结果/结论]实验分析的结果证明该模型可以在高维数据环境下实现对推荐质量的有效控制,让推荐系统可以更好地适应不同的应用环境。
关键词:高维数据环境;大数据;个性化推荐;推荐质量;控制;模型;应用环境
DOI:10.3969/j.issn.1008-0821.2019.11.003
〔中圖分类号〕G202 〔文献标识码〕A 〔文章编号〕1008-0821(2019)11-0023-07
Abstract:[Purpose/Significance]The accuracy and the real-time performance of recommendation exist mutual restraint under high dimensional data environment.How to achieve the balance between accuracy and real-time performance and to realize effective control of recommendation quality are problems worth studying.[Method/Process]At first,the causes of high dimensional data environment and its affects to recommendation quality were analyzed.On this basis,a quality control model of personalized recommendation was constructed.This model first assessed the loss of recommendation quality from two aspects of accuracy and real-time performance and then combined with the application environments to get the corresponding quality control strategies.[Result/Conclusion]The result of experimental analysis illustrated that the model was able to realize effective control of recommendation quality under high dimensional data environment,so that personalized recommendation system could better adapt to different application environments.
Key words:high dimensional data environment;big data;personalized recommendation;recommendation quality;control;model;application environment
个性化推荐技术在电子商务、社交、广告和新闻领域都取得了商业上的成功,受到众多学者的关注。精准度和实时性是个性化推荐质量的两个核心指标,推荐的精准度越高、实时性越强,就表示推荐质量越好。大数据时代的来临,高维数据环境对推荐系统来说已经成为常态。在高维数据环境下,个性化推荐的精准度和实时性存在相互制约的现象,即:在追求更高精准度的同时,其推荐实时性往往会下降,反之如果想实现更高实时性则精准度也会受到影响。因此,当应用环境变化需要调节推荐的精准度或者实时性时,就必须在它们两者之间取得一个平衡,不能为了提升一个推荐质量指标,而导致另一个推荐质量指标的大幅下降,这样系统的推荐质量是无法保证的。由此,本文提出一种面向高维数据环境的个性化推荐质量控制模型,该模型通过对比推荐质量在精准度和实时性两个方面的损失,来寻找有效的推荐质量控制策略,让推荐系统可以更好地应对不同的应用环境。本研究不仅丰富了个性化推荐的理论体系,也为实际应用提供借鉴。
1 相关研究
个性化推荐是通过一定的技术手段来挖掘数据中的用户兴趣,再根据用户兴趣挖掘的结果来筛选待推荐的项目,最后生成推荐集合推送给目标用户。目前有关个性化推荐的研究中,比较有代表性的有:
1)根据内容相似性来实现推荐。安悦等[1]提出一种基于内容的热门微话题个性化推荐算法,该算法通过对比内容的相似性为用户寻找感兴趣的微话题,实验结果表明该算法可以在一定程度上解决微博数据过载的问题,实现较好的推荐效果。王嫣然等[2]提出一种基于内容过滤的科技文献个性化推荐算法,该算法将访问时间权重和文献重要度两种概念与内容过滤相结合,实现了推荐精准度的提升。王洁等[3]先根据历史浏览记录对有相同兴趣的用户进行聚类,再通过内容相似性挖掘寻找推荐项目,实验证明该个性化推荐方法可以有效提升推荐的精准度。
2)根据社交网络中的用户关系实现推荐。陈婷等[4]提出一种融合社交信息的个性化推荐方法,该方法将用户评分相似度与社交网络中的信任关系两者相结合来寻找最近邻,结合用户自身偏好和最近邻的影响实现评分预测,实验结果证明该算法可以提升推荐的精准度。李鑫等[5]提出了一种基于兴趣圈中社会关系挖掘的个性化推荐算法,该算法将兴趣圈中的社会关系与矩阵分解模型相结合,实现矩阵分解的优化,实验证明该方法在解决推荐冷启动方面有较好的效果。Ma H等[6]将信任网络与用户评分结合,通过概率矩阵分解来优化推荐。景楠等[7]提出了一种基于用户社会关系的好友个性化推荐算法,该算法将用户在社会网络中的影响力和社会关系相结合实现推荐算法的改进。
3)利用标签信息来改进推荐效果。陈梅梅等[8]提出了基于标签簇的信任张量模型,再通过计算簇内和簇间的信任强度,实现对传统相似性计算的补充,从而改进个性化推荐的准确性。孔欣欣等[9]提出一种基于标签权重评分的个性化推荐模型,并结合该模型对多类传统推荐算法进行改进,实验证明了该模型的有效性。李瑞敏等[10]通过分析用户、标签和项目之间的关系建立图模型,在此基础上将初步推荐列表与间接关联集合进行综合,实现对推荐算法的改进。
4)融合情境的个性化推荐。刘海鸥等[11]提出了一种对多种情境进行兴趣建模的方法,该方法可以提升推荐的精准度。周明建等[12]用多維度建模法构建了知识情境模型,通过计算知识情境的相似性来寻找关联知识并实现推荐,实验表明该方法提升了个性化推荐的精准度。
5)基于协同过滤的个性化推荐。杜永萍等[13]将用户间的信任关系与评分相似性相结合来寻找最近邻,实现对传统协同过滤推荐算法的改进。董立岩等[14]提出一种基于时间衰减的协同过滤个性化推荐算法,该算法将遗忘曲线和记忆周期融入协同过滤推荐中,以兴趣衰减函数来优化评分相似性的判断,实验证明该算法可提高推荐的精准度。郭兰杰等[15]提出一种融合社交网络的协同过滤个性化推荐算法,该算法利用社交网络中的朋友关系来进行评分矩阵的填充,可有效缓解数据稀疏性问题,实现算法的改进。郭弘毅等[16]提出一种融合社区结构和兴趣聚类的协同过滤改进算法,该算法先识别社交网络中的社区结构,再与用户兴趣聚类信息进行融合来共同优化矩阵分解模型,实验证明该算法提升了推荐的精准度。
总体来看,目前针对个性化推荐的研究中,无论是优化相似性的度量方法,还是改进最近邻的查找流程,或是优化矩阵降维的方法等等,其改进的思路都是通过对推荐算法的不同环节进行优化改进来提升推荐质量。大数据时代,推荐系统经常面对高维的数据环境,高维数据环境下推荐精准度和推荐实时性相互制约的现象,会严重影响推荐质量的稳定,让推荐系统无法适应应用环境的变化,而目前恰恰缺少对该问题解决方法的研究。由此,本文提出一种面向高维数据环境的个性化推荐质量控制模型,为解决该问题提供参考。
2 推荐系统高维数据环境的形成原因
大数据时代用户数据极大丰富,个性化推荐系统为了更好地感知用户的兴趣偏好,会通过不同渠道收集用户的各类数据,并将它们集中存储起来作为推荐算法的数据源。如果这些数据源中的数据具有很高的维度,那么推荐系统就处在高维数据环境当中。推荐系统高维数据环境的形成原因主要有以下两点:
第一,用户数和项目数的快速增长,导致推荐系统主数据源的维度大幅增加。个性化推荐系统是通过分析用户已有消费或评分记录,来判断用户的兴趣,再在用户未消费过的项目中匹配合适的推荐项目。因此,用户消费或者评分的历史记录就是推荐系统的主数据源。随着用户数和项目数的快速增长,用户历史消费记录矩阵或用户对项目的评分矩阵都会大幅扩容,形成高维数据环境。
第二,由于数据之间存在关联关系,附属数据源的维度也会快速增长。上文提到推荐系统会收集各类用户数据作为兴趣感知源。本文将历史消费信息与评分信息以外的数据统称为附属数据源。这些附属数据虽然来源很多,数据类型和数据格式也很复杂,但它们都有一个共同特点,就是可以根据用户的行为轨迹进行关联。这样一来不同类型的用户数据不再是相互孤立的,而是通过这种关联关系紧密地联系起来。因此,当主数据源的维度增加时,附属数据也必须进行相应扩容。比如将用户背景信息、社交网络、标签等与历史购买记录或用户评分进行融合来实现推荐时,当购买记录矩阵或评分矩阵的维度增加时,与之对应的用户背景信息、社交网络信息或者标签信息的数据维度也在增长,这些附属数据维度的增长速度甚至快于主数据源本身,由此进一步促使了推荐系统高维数据环境的形成。
3 高维数据环境对个性化推荐质量的影响
精准度与实时性是个性化推荐质量的两个核心指标,以下将分别介绍高维数据环境对推荐精准度和推荐实时性的影响,最后分析了精准度与实时性在高维数据环境下相互制约的原因。
3.1 高维数据环境对推荐精准度的影响
个性化推荐是通过分析用户行为数据或用户背景数据等信息来判断用户的兴趣偏好。用户的兴趣是多方面,每个方向上都可能有潜在的兴趣点,要想感知这些兴趣,就需要有相应的用户数据。总的来说,用户兴趣感知源越多,就越能从多个侧面来推断用户的偏好。当推荐系统处于高维数据环境时,主数据源和附属数据源都涵盖了大量的有用信息,推荐系统可以利用不同的算法模型来挖掘用户的兴趣。从这个角度来说,高维数据环境对提升推荐精准度有正面的作用。比如推荐系统可以利用用户背景数据与消费评价数据进行融合,在多个用户背景维度上对其兴趣进行细分,这样预测出的用户兴趣的精准度会大大提高,同样的结合项目本身的属性或者社交网络、信任关系等也可以提升推荐的精准度。总的来说,高维数据环境为推荐系统提供了丰富的兴趣感知源,为推荐精准度的提升奠定了数据基础。
3.2 高维数据环境对推荐实时性的影响
推荐实时性也是推荐质量的重要指标,当用户访问网站时,推荐系统必须快速地识别用户的潜在意图,并及时给予推荐,这样用户根据系统推荐进行进一步的选择。如果推荐集合的计算时间太长,无法保证推荐的实时性,用户可能跳转到另外一个页面,其兴趣可能已经发生转化,或者在新的页面下已经没有了推荐栏的设置,无法实现推荐。这样系统的推荐质量会大大下降,用户体验也会降低。因此,保证推荐实时性对推荐系统来说非常重要。在高维数据环境下,用户兴趣感知源的增加,对推荐精准度来说是利好,但是对于推荐实时性来说,会使得兴趣挖掘的计算复杂度大幅提升,从而导致系统开销过大,直接影响推荐系统的响应。特别是将附属数据源与主数据源进行融合挖掘时,计算复杂度的数量级会大大增加。此外,当大量用户同时访问时,系统的负担会进一步加重,系统响应时间也会延长。总的来说,高维数据环境会降低推荐的实时性。
3.3 高维数据环境下精准度和实时性相互制约的原因 在高维数据环境下,系统要想改善推荐的精准度,就希望从不同角度来深入挖掘用户的兴趣偏好,这时需要调用的用户数据会大幅增加。而调用数据的增加会使得兴趣挖掘的计算量大幅提升,推荐实时性就无法保证。如果只调用很少的数据来挖掘用户的兴趣,虽然减少了计算量但无法深入感知用户的兴趣偏好,推荐精准度就很难保证,这就是造成推荐精准度和推荐实时性相互制约的原因。
推荐系统可以使用不同的算法来实现推荐,也可以通过多类型算法相互补充实现更高的精准度。因此,需要重点说明的是精准度与实时性的相互制約是针对整个推荐系统来说的。部分推荐算法通过模型的改进,可以在提高精准度的同时也提升实时性,但这只是局限在算法的层面,改进算法相对于原来的算法,在调用数据不变的情况下可以实现精准度与实时性的同时改进。但是,当推荐系统使用这种改进算法进行实际推荐时,其调用数据的越来越多,推荐实时性必然会下降。此外,还需要强调的是推荐精准度的提升不是无限的,达到局部的峰值以后会下降。
综上,为实现高维数据环境下对推荐质量的有效控制,本文提出一种个性化推荐质量控制模型,下文将详细介绍该模型的设计,并通过实验分析验证模型的有效性。
4 面向高维数据环境的个性化推荐质量控制模型4.1 模型的详细设计
本文提出的面向高维数据环境的个性化推荐质量控制模型,包含6个主要步骤,具体如下:
4.1.1 对推荐系统的状态进行标记
在高维数据环境下,推荐系统通过挖掘历史数据中的用户兴趣来产生推荐,挖掘越深越耗时,但精准度会提升。放弃精准度的提升,降低挖掘深度就会节省时间,提升推荐的实时性。推荐系统通过调整挖掘深度来控制精准度与实时性的高低。设F={ft,0,1,2,3,…,k}为推荐系统处于不同挖掘深度时的状态集合(非空集合),ft为F中的任意一个系统状态,ft记录了系统调用的推荐算法的相关信息以及调用数据的范围。设wft表示推荐系统处于状态ft时的推荐精准度,设dft表示推荐系统处于状态ft时的推荐实时性。F中的每一个的系统状态分别对应一组精准度与实时性的值。
4.1.2 计算推荐实时性
推荐实时性可以用推荐时间来反映,推荐时间越短实时性越好。然而使用推荐时间来直接表示推荐实时性不能反映算法挖掘的细节。由此,本文在衡量推荐实时性时采用算法计算量来替代推荐时间。所谓算法计算量,为推荐算法在所调用的数据中需要比对的用户数或者项目数。在个性化推荐中,推荐时间与算法计算量成正比,即:算法计算量越大,推荐时间越长,其对应的推荐实时性越低。反之,算法计算量越小,其推荐时间越短,相应的推荐实时性越高。计算F中每个系统状态下的推荐实时性,再将F中的系统状态按照其对应的推荐实时性从高到低顺序排列,形成一个系统状态列表L。设系统状态为ft时的算法计算量为Qft,即推荐实时性dft就等于Qft的值。
4.1.3 确定推荐实时性的临界值
在个性化推荐中,系统会根据应用环境和用户反馈,设置推荐实时性的临界值。该临界值就是推荐系统能够接受的最长推荐时间,超过这个临界值,则被认定无法实现即时的推荐,精准度的高低就失去了意义。由于本文采用算法计算量替代推荐时间来评价推荐实时性,所以推荐实时性的临界值,就是算法计算量的上限值,设该上限值为B。将系统状态列表L中推荐实时性超过临界值B的系统状态删除,形成新的列表L1。
4.1.4 计算推荐精准度
计算h′ ft是为了测量其它系统状态相对于基准状态的实时性损失程度。因此,必须以Qf0为基准减去Qft,这种顺序安排对应了质量损失的意义。先计算不同系统状态下算法计算量的差值的绝对值,再判断推荐实时性的方向系数,是为了分别展示推荐实时性的变化幅度和变化方向。
当推荐实时性损失h′ ft为正数时,表示与基准状态相比推荐实时性下降了。当h′ ft为负数时,表示与基准状态相比推荐实时性提高了。
根据上述公式,计算列表L2中除基准状态f0以外的其它系统状态的推荐精准度损失和推荐实时性损失。
4.1.6 建立推荐质量控制节点
将推荐精准度损失与推荐实时性损失的结果,按照列表L2中系统状态的顺序依次排列,可以对比不同系统状态下精准度与实时性的损失程度,由此可建立推荐质量控制节点,推荐质量控制节点的格式如表1所示:
在个性化推荐中,系统都会尽量提升推荐的精准度,由于基准状态的精准度最高,所以可以让系统先以基准状态进行推荐。当系统的应用环境发生变化,需要改变推荐精准度或推荐实时性时,为保证推荐质量的稳定,避免单一推荐质量指标的大幅下降,可以先设置质量控制的目标。根据质量控制目标的要求,找到相应的推荐质量控制节点。再通过推荐质量控制节点中系统状态的信息,设置算法的挖掘深度和数据调用的范围,由此可以实现有效的推荐质量控制。
4.2 仿真实验
4.2.1 实验说明
本次实验以协同过滤推荐系统为例,对提出的个性化推荐质量控制模型进行验证,并完整的展示该控制模型的全过程,为其他学者使用模型提供参照。实验中的协同过滤推荐系统以用户—项目评分矩阵为主数据源,以用户背景中的年龄数据为附属数据源,通过将用户年龄数据与评分数据进行融合来实施兴趣挖掘。具体算法过程如下:设与目标用户年龄差值的绝对值小于等于K的用户,为目标用户的同年龄段用户。算法先将与目标用户处于同一年龄段的用户查找出来,作为最近邻的备选,再在同年龄段用户群中利用评分相似性筛选出最近邻用户集合,最后计算项目的推荐分数,生成最终的推荐列表。实验中K的取值不同,意味着算法挖掘深度和调用数据的不同,不同的K值对应着个性化推荐质量控制模型中的不同系统状态。
4.2.2 数据来源
本实验的数据来自美国明尼苏达大学的Grouplens研究项目组提供的ml-100k数据集,该数据集中的文件u.data包含了943位用户对1 682部电影的10万条评分记录,评分标准采用五分制,用户打分越高表示用户对该电影的满意度越高。由u.data生成了5组训练集和测试集。文件u.user记录了用户的背景信息。
4.2.3 结果分析
在实际应用中,设定同年龄段用户的年龄差距不宜过大,本试验依次测试k从0~6的试验结果。根据本文提出的个性化推荐质量控制模型,依次计算k的取值从0~6的7个系统状态下的推荐精准度与推荐实时性。
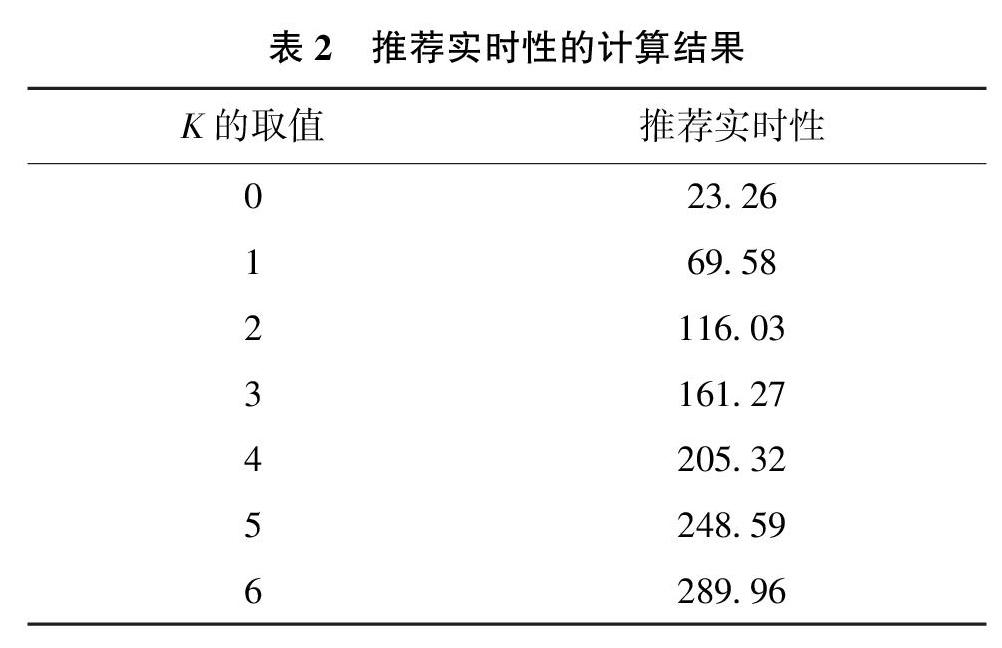
首先计算推荐实时性,本文用算法计算量替代推荐时间来评价推荐实时性。分析本实验中的推荐算法可以发现,在算法的相似性计算环节,通过对比目标用户与每一个潜在相似用户之间的评分相似性程度来寻找最近邻。因此目标用户需要对比的潜在相似用户数的变化直接反映了算法计算量的变化。先计算全部用户在K取不同取值时的潜在相似用户数,再取平均值可以作为推荐实时性的值,最终的计算结果如表2所示:
根据表2中推荐实时性的计算结果可以发现,随着K值的增加,推荐系统查找潜在用户的范围逐渐扩大,推荐实时性逐渐下降。k=0时,推荐系统需要对比23.26个潜在相似用户来实现推荐。k=6时,推荐需要对比的潜在用户数增长为289.96个。本试验设定推荐实时性的临界值为总用户数的30%,则临界值为282.9。根据个性化推荐质量控制模型,删除k=6的状态,保留k等于0~5的6个系统状态。计算这6个系统状态下对应的推荐精准度,计算结果如表3所示。
根据表3中推荐精准度的计算结果可以发现,从当K从0增长到5的过程中,其推荐精准度刚好也是逐渐上升。根据个性化推荐质量控制模型,以K=5的系统状态为基准状态,计算其它系统状态的推荐质量在精准度和实时性两个方面的损失,将计算结果按照推荐质量控制节点的格式排列,结果如表4所示:
表4中,由于k=5为基准状态,所以其推荐精准度和推荐实时性的损失都为0。通过表4可以发现,跟基准状态相比,其它系统状态的推荐实时性损失都为负值,这表示推荐实时性都提高了,与此同时推荐精准度损失都为正值,意味着推荐精准度都下降了。
按照K值从4到0的顺序,将表4中推荐实时性损失的绝对值与其相应的推荐精准度损失,绘制成图1。
通过图1可以发现,k的值从4到0的变化过程中,推荐实时性提升的程度要大大高于精准度下降的程度。本实验模拟一个应用环境来演示如何应用推荐质量控制节点来寻找合适的质量控制策略。系统刚开始以基准状态进行个性化推荐。假设短时间内访问用户数大幅增长,系统需要提升推荐实时性,但是希望推荐精准度保持在基准状态的90%以上的水平。参照表4中的推荐质量控制节点,从
图1 精准度与实时性的损失对比图
k=5时的系统状态到k=2时的系统状态,算法的计算量减少53%,推荐实时性大幅提升,而此时推荐精准度只下降了9%,符合质量控制目标的要求。由此可以根据k=2时的系统状态实施推荐。如果应用环境进一步改变,系统可设定新的质量控制目标,再和上述过程一样找到合适的推荐质量控制节点实施推荐,由此实现了对个性化推荐质量的有效控制。
5 结 语
本文以大数据时代为背景阐述了推荐系统高维数据环境的形成原因,并且详细分析了高维数据环境对个性化推荐质量的影响。然后针对性地提出了一种个性化推荐质量控制模型,该模型可以在高维数据环境下通过对比推荐精准度与推荐实时性的损失,形成一系列推荐质量控制节点。再根据应用环境的差异,选择合适的推荐质量控制节点。最后根据该控制节点的系统状态信息,实现推荐系统的状态切换,从而达到对推荐质量进行有效控制的目的。未来笔者将进一步对该领域进行深入研究。
参考文献
[1]安悦,李兵,杨瑞泰,等.基于内容的热门微话题个性化推荐研究[J].情报杂志,2014,33(2):155-160.
[2]王嫣然,陈梅,王翰虎,等.一种基于内容过滤的科技文献推荐算法[J].计算机技术与发展,2011,21(2):66-69.
[3]王洁,汤小春.基于社区网络内容的个性化推荐算法研究[J].计算机应用研究,2011,28(4):1248-1250.
[4]陈婷,朱青,周梦溪,等.社交网络环境下基于信任的推荐算法[J].软件学报,2017,28(3):721-731.
[5]李鑫,刘贵全,李琳,等.LBSN上基于兴趣圈中社会关系挖掘的推荐算法[J].计算机研究与发展,2017,54(2):394-404.
[6]Ma H,Yang H,Lyu M R,et al.SoRec:Social Recommendation Using Probabilistic Matrix Factorization.In:Proc.of the Intl Conf.on Information and Knowledge Management.ACM Press,2008:931-940.
[7]景楠,王建霞,许皓,等.基于用户社会关系的社交网络好友推荐算法研究[J].中国管理科学,2017,25(3):164-171.
[8]陈梅梅,薛康杰.基于标签簇多构面信任关系的个性化推荐算法研究[J].数据分析与知识发现,2017,(5):94-101.
[9]孔欣欣,苏本昌,王宏志,等.基于标签权重评分的推荐模型及算法研究[J].计算机学报,2017,40(6):1440-1552.
[10]李瑞敏,林鸿飞,闫俊.基于用户-标签-项目语义挖掘的个性化音乐推荐[J].计算机研究与发展,2014,51(10):2270-2276.
[11]刘海鸥,孙晶晶,苏妍嫄,等.面向图书馆大数据知识服务的多情境兴趣推荐方法[J].现代情报,2018,38(6):62-67,156.
[12]周明建,赵建波,李腾.基于情境相似的知识个性化推荐系统研究[J].计算机工程与科学,2016,38(3):569-576.
[13]杜永萍,黄亮,何明.融合信任计算的协同过滤推荐方法[J].模式识别与人工智能,2014,27(5):417-425.
[14]董立岩,王越群,贺嘉楠,等.基于时间衰减的协同过滤推荐算法[J].吉林大学学报:工学版,2017,47(4):1268-1272.
[15]郭兰杰,梁吉业,赵兴旺.融合社交网络信息的协同过滤推荐算法[J].模式识别与人工智能,2016,29(3):281-288.
[16]郭弘毅,刘功申,苏波,等.融合社区结构和兴趣聚类的协同过滤推荐算法[J].计算机研究与发展,2016,53(8):1664-1672.
[17]项亮.推荐系统实现[M].北京:人民邮电出版社,2012:2-63.
[18]Pazzani M,Billsus D.Learning and Revising User Profiles:The Identification of Interesting Web Sites[J].Machine Learning,1997,(27):313-331.
(責任编辑:郭沫含)
