
基于网络的地理目标数据获取与处理方法研究
2019-10-30 08:28:02战略支援部队信息工程大学葛磊刘海砚杨瑞杰
网信军民融合 2019年10期
◎ 战略支援部队信息工程大学 葛磊 刘海砚 杨瑞杰
随着网络信息资源的不断丰富,基于网络实现对地理实体目标信息的快速采集和更新成为可能。本文根据地理实体相关信息的分布和结构特点,对现有地理目标位置数据的获取方法进行了分析,提出了通过属性归一化、基于规则匹配抽取半结构化地理目标属性和基于弱监督的条件随机场模型抽取非结构化文本中地理目标属性的方法,并针对多源地理目标数据的不一致问题提出了数据融合处理的一般方法。
随着“互联网+”概念的提出,网络已经作为社会的基础设施成为人类生活中不可分割的一部分。随着各种传统行业、服务行业与互联网的深度结合,互联网集聚了各行各业的信息资源,已成为人类各种信息的主要来源。然而,互联网上的原始数据都是非结构化或者半结构化的,不能直接作为地理信息产品使用,如何快速准确获取结构化的地理实体目标数据仍面临着许多挑战。
一、地理空间数据网络获取现状分析
地理空间数据获取的主要手段是Web爬虫技术,即根据给定的一个网页,通过对网页中的链接进行解析发现其他网页,然后不断进行迭代爬取,直到完成对所有相关网页的爬取。另一类信息获取技术是利用一些专业网站提供的Web开发接口或者服务接口获取特定类型的数据,这类数据通常质量较高,数据结构良好,比较适合专业数据的获取。地理空间数据获取主要包括位置数据和属性数据的获取。
位置数据获取方面,目前基于Web的地理信息获取研究较多,大多集中在对地理实体位置数据的获取,还存在数据获取不完整、数据损失和数据冗余等问题,数据的准确度和数据结构的完整性不能保证,同时对多源数据的融合和统一转换问题的研究仍相对较少。
属性数据获取方面,MUC(消息理解会议,Message Understanding Conference)系列会议通过具体的任务进行信息抽取并建立了严格的评价体系对各个抽取系统进行评测,逐渐完善了基于模板和规则的信息抽取方案,形成了一套面向领域、基于规则的信息抽取体系,同时形成了一套完善的信息抽取结果评价指标体系。中文信息抽取的研究开始较晚,另外由于中文和英语在母单词、语法和语义基本单元差别,使很多英文信息抽取方法不能直接应用于中文信息抽取。当前中文信息抽取在命名实体识别的基础上向关系抽取、关联抽取、属性抽取等更深层次发展。中文信息抽取系统目前仍集中在简单任务方面,国内学者采用规则匹配、机器学习等方法对文本信息的抽取进行了研究,其中,中科院的ICTCLAS和北大的会议新闻抽取系统实现了对简单文本信息的准确抽取,但完善的中文信息抽取系统尚未成型。
二、地理目标位置数据的获取
POI(Point of Interest,兴趣点)是空间信息数据最鲜活的“血液”,它通常代表的是一类真实的地理实体。互联网信息冗杂,高质量的地理信息网站是获取高质量数据的最佳来源。百度地图和高德地图拥有丰富的国内POI资源,并且提供了较为完善的开发接口,国外开源地图OSM(Open Street Map)数据完全开放,欧洲、北美等地区的数据较为丰富。因此,位置数据获取中国内数据主要基于百度地图和高德地图数据进行抽取,境外数据的获取将OSM作为数据源。
(一)国内POI数据获取
抽取百度地图POI信息可利用百度地图JavaScript API的服务类接口。百度地图提供的开放接口是有限制的,通过检索半径和检索关键词限制单次大规模下载POI数据。针对检索半径的限制问题,采用多线程思想对任务区域进行分割,逐块对每个任务区域进行处理,最后将各任务区域获取的数据合并,在避免检索半径限制的同时能够提高任务处理效率。检索关键词限制主要包括单次检索关键词数量的限制和所选关键词检索数据的完整性限制。单次检索关键词数量限制可通过多次构建任务分批进行检索。针对所选关键词检索的数据完整性限制,可采用两种解决方法。一种是使用其提供的GeocoderResult.surroundingPois接口直接获取数据,该接口不需要提供关键词,但获取数据的属性信息缺失较多;第二种是利用LocalSearch接口提供关键词检索。采用“美食”“酒店”“购物”等17个关键词对郑州地区某一区域进行了数据抽取实验,得到POI数量707个,爬全率为96.717%,数据的完整性较好。百度地图POI的获取流程如图1所示。
与百度地图POI数据抽取相比,高德地图提供的POI数据接口只有基于关键词的周边搜索方法AMap.PlaceSearch。高德地图数据接口对单次检索所选关键词的数量没有限制,主要在于单次检索半径的限制和检索关键词所获取POI数据完整性限制。单次检索半径的限制同样可利用百度POI获取中的多线程方法进行处理。检索关键词的选取可参照高德地图POI分类标准,选择“汽车服务”“餐饮服务”“购物服务”“生活服务”等23个关键词分别进行数据检索。经对比自动检索与人工检索、实地验证相结合,对郑州某一区域POI数据检索的结果如图2所示,POI总数744个,综合爬全率96.373%,抽取数据的完整程度较为可靠。
(二)境外POI数据获取
OSM旨在建立一个任何人都可以编辑的全球地理数据库,该数据库由Steve Coast在2004年7月建立。近年来,OSM数据量增长迅速,截至2014年3月1日,OSM数据量的总体情况为:GPS数据点总共3,829,201,844个,节点数量2,223,977,668个,路径数量219,537,496个,关系数量2,406,517条,参与编辑的总用户数量1,528,868个。OSM将地理实体分为30个要素类,每个类根据标签的key和value分为若干小类。
从OSM中抽取POI要素的常用方法是直接将OSM数据转换为常用的SHP格式,然后将SHP格式中的点要素作为POI要素。这种方法主要依赖第三方工具,实现较为简单,但由于不同数据在地理位置和属性定义等方面的差异,往往会造成POI数据缺失,另外该方法存在大量冗余操作,不利于海量数据的处理。
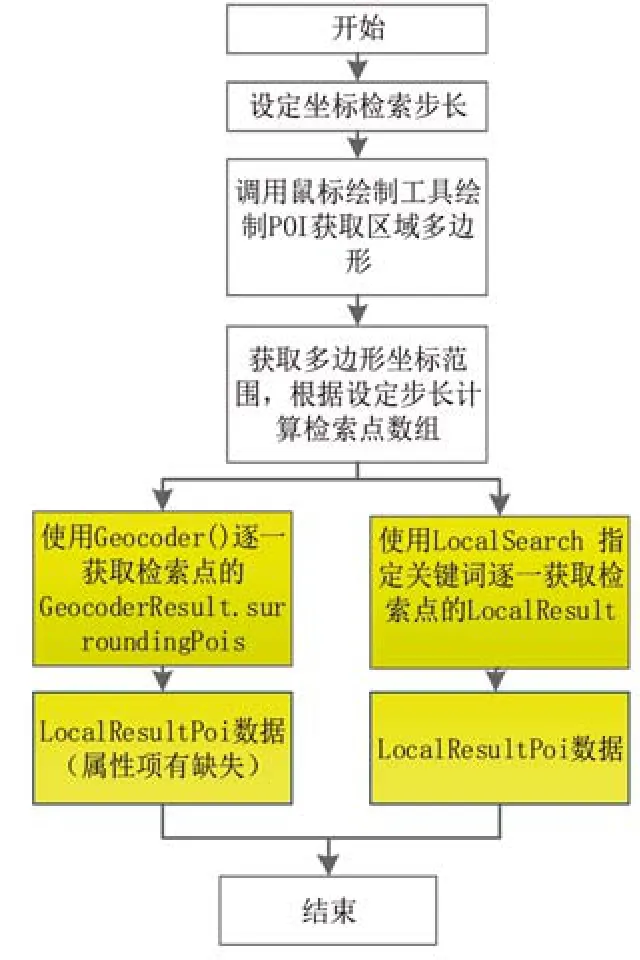
图1 百度地图POI获取流程
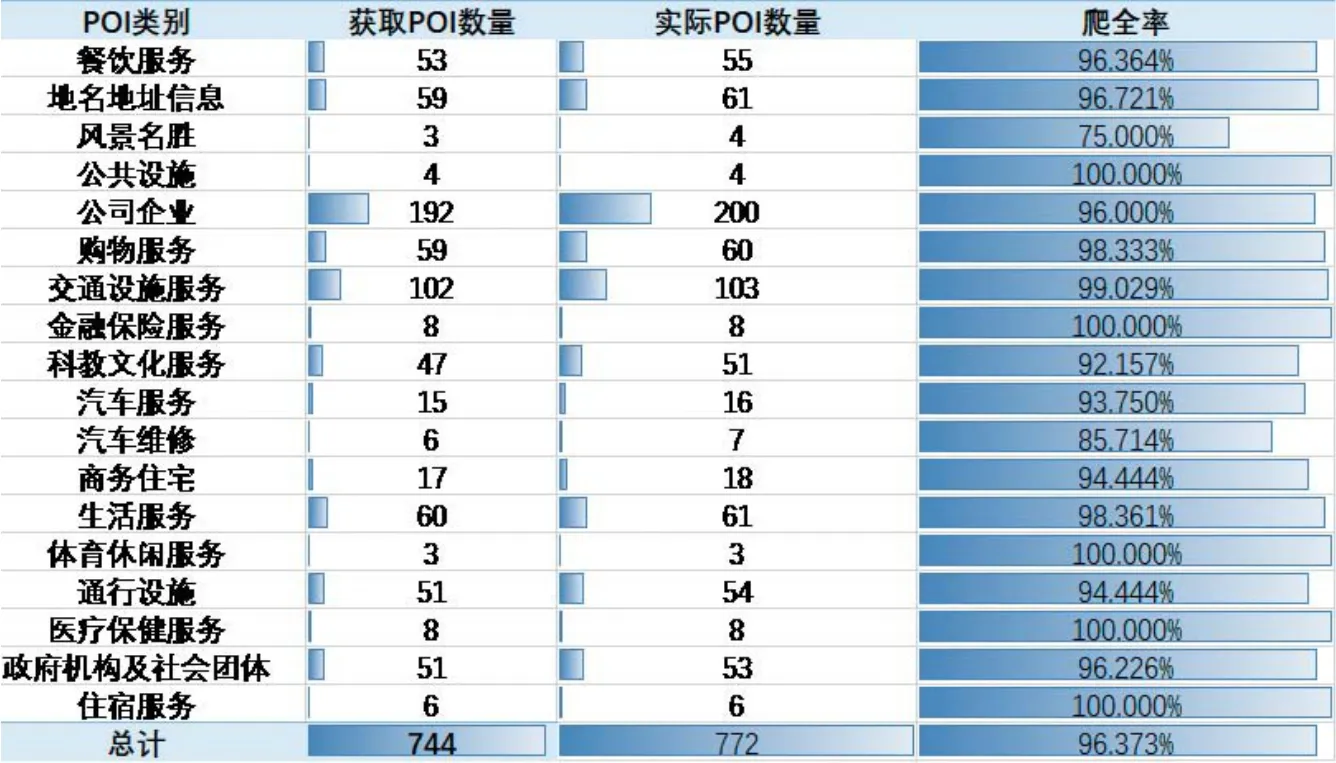
图2 高德地图获取POI信息
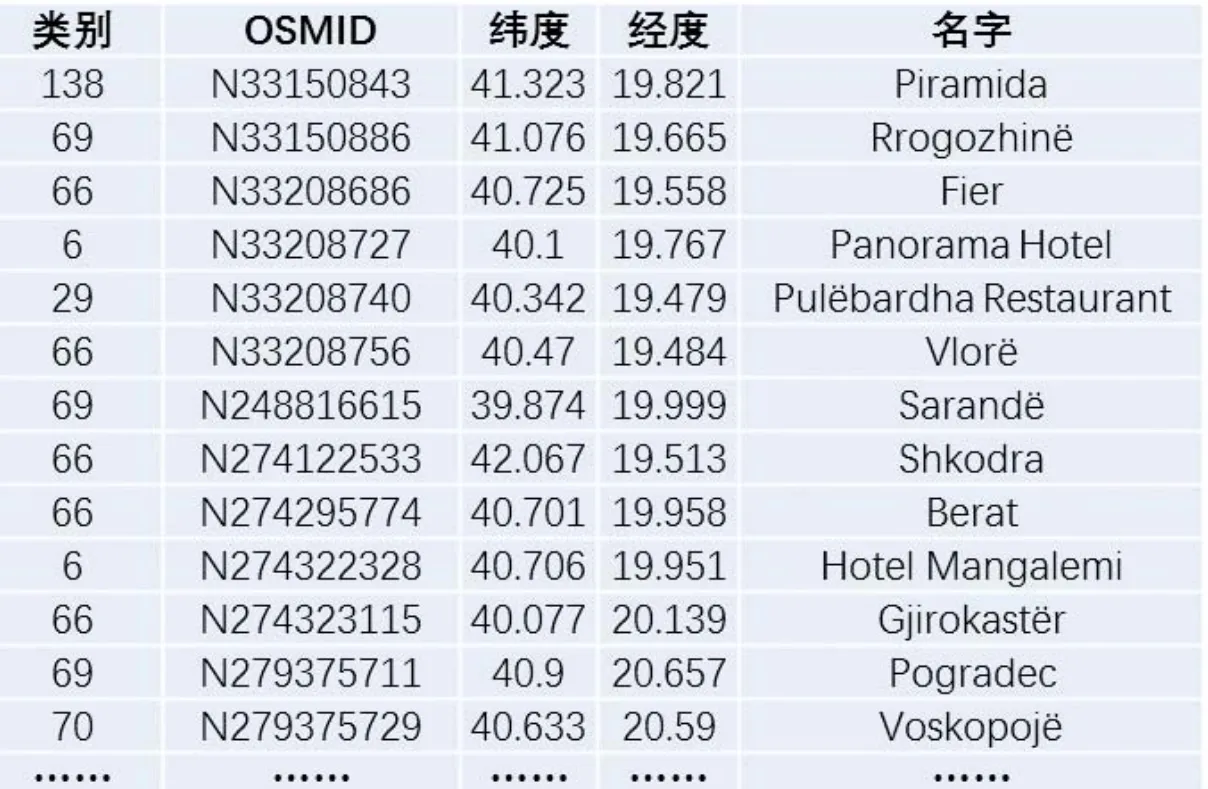
图3 对OSM中Albania地区POI数据抽取结果
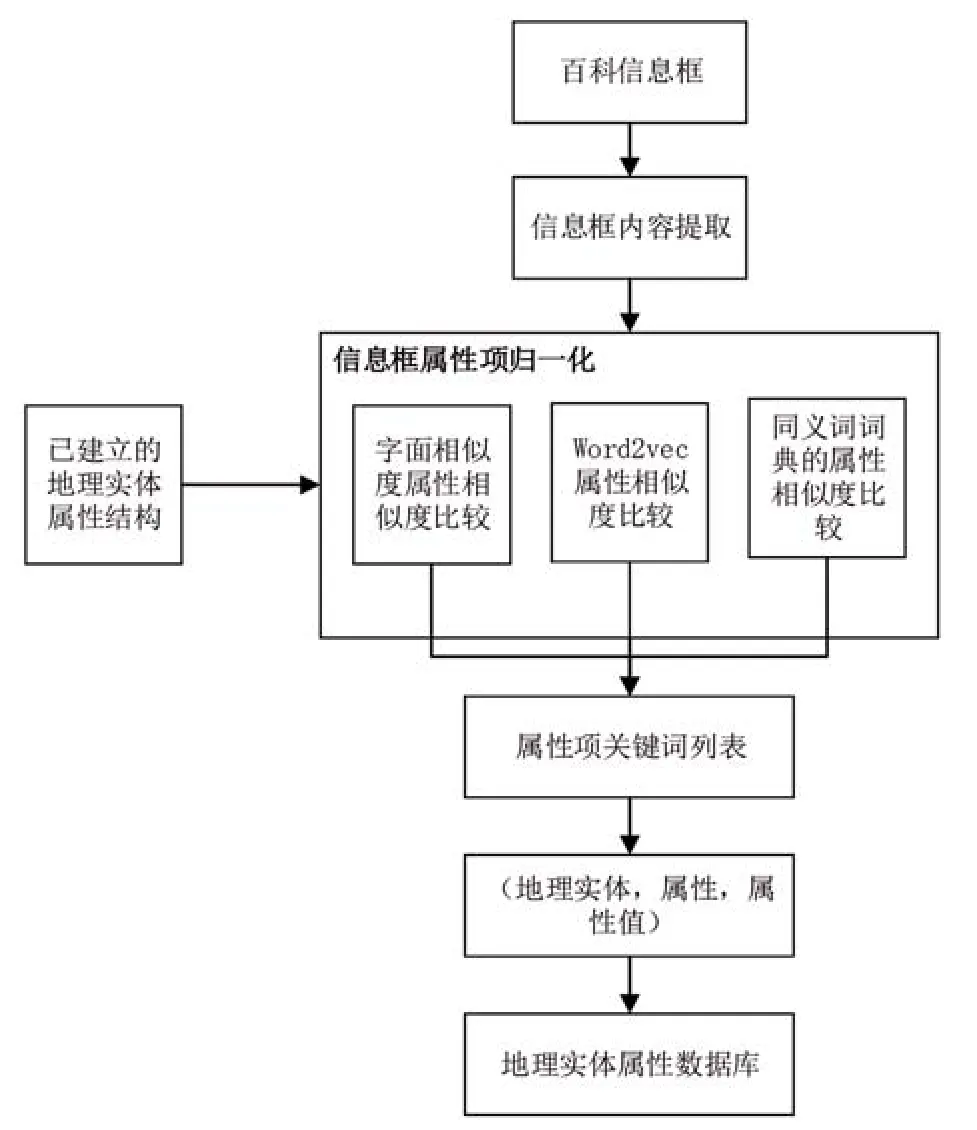
图4 基于半结构文本的属性匹配抽取流程
根据OSM数据的存储特征,可通过OSM标签中的key和value值直接提取符合要求的信息。首先,建立一个不同key和value对应的POI分类模板,确定需要提取的要素与类别,遍历数据中所有要素标签中的key和value,并与模板进行匹配,满足匹配条件则保存该要素的所有值和坐标,从而实现POI信息的提取。采用该方法对Albania 地区的POI信息进行了提取,数据为PBF格式,数据大小15.24MB。共抽取POI数据5252条,用时3850ms,分别为POI的名称、OSMID、坐标、类别等属性信息,如图3所示。该方法效率较高(相同硬件环境下,利用ArcGIS_Editor_OSM插件对上述数据进行转换耗时30秒以上)。
三、基于文本信息的地理目标属性数据获取
地理目标的属性信息主要包含在网络文本数据中。网络上的文本数据按照其结构化程度可分为半结构化文本和非结构化文本两类。半结构化文本是介于结构化文本与非结构化文本之间的一种文本形式,通常比较简短,结构特征比较明显,如百度百科的信息框;非结构化文本中的文字完全是按照自然语言规则,即按人类的理解方式产生的文本,通常有新闻报道、文献资料等,如百度百科的正文部分。网络文本数据通常以非结构化数据为主,半结构化数据为辅。百科网站中关于地理空间目标的信息通常比其他网站更为详细可靠,且同时包含半结构化文本和非结构化文本,因此将其作为属性数据获取研究的基础。
(一)基于半结构化文本的目标属性数据获取
半结构化文本的属性数据抽取中,首先根据地理实体名字获取所在百科页面信息框信息,统计信息框的所有属性,计算其与预定义属性的相似度,得到同义属性,进而抽取对应属性值,建立地理实体、属性、属性值之间的对应关系,具体流程如下图4所示。
由于文本语义表达的多样化,不同文本在表达地理实体的同一个属性时可能采用不同关键词,称为同义属性词。属性数据获取中需要对关键词进行识别,将表达地理实体同义属性词识别出来并合并为同一属性,建立每个属性项对应的关键词集合,这一过程称为属性项归一化。地理实体属性项归一化是实现半结构化文本属性数据获取的关键。
属性项归一化的实质是判断属性项词之间的同义性,因此需要对属性项的相似度进行度量,可采用字面相似度、语义相似度等指标度量属性项相似度。字面相似度的计算简单方便,不需要依赖大量的训练库和字典,适合计算简单、字面相似词的相似度;采用基于Word2vec的训练模型训练得到的词向量度量语义相似度,具有维度低、快速、准确等优点;基于同义词的语义距离度量词语相似度在计算较短词语的很有效,但处理长词语时会有偏差。可将三者进行结合,采用三个相似度中的最大值作为最终属性项相似度。
(二)基于非结构化文本的目标属性数据获取
非结构化文本中目标属性数据的获取通常采用基于统计的机器学习方法。传统的有监督学习需要大量的人工标注语料进行模型训练,海量的文本数据所需的人工标注工作量巨大。基于弱监督学习可以利用一些已有知识库的实体关系生成训练数据,减少人工标注量。在半结构化文本属性抽取的基础上,采用基于弱监督的条件随机场抽取地理目标属性,利用实体属性关系对非结构化文本进行自动标注产生训练语料,基于条件随机场模型对训练语料进行学习生成地理目标属性模型,根据训练语料训练的地理实体属性模型可实现对非结构化文本中的地理实体属性的抽取。基于弱监督条件随机场的属性数据提取流程如图5所示。
语料预处理是保证文本信息抽取准确性的基础,尤其是中文文本,其基本的语义单元可能是一个或者多个字,直接抽取根本得不到预期结果。语料预处理时,首先剔除百科文档中包含的图片标签和广告标签,按照结构化的信息框和非结构化文本分割存储;采用3.1的方法将结构化信息框中相关的地理目标属性提取出来;而后将非结构化文档中的HTML标签去除得到纯文本内容,根据标点符号将非结构化文本拆分成单个句子,依据开放分类对提取的信息进行分类,为基于地理实体类别训练模型抽取属性数据提供基础。

图5 基于弱监督的条件随机场地理目标属性提取流程
基于条件随机场模型抽取地理目标属性实质是利用统计学模型学习自由文本中某个实体属性的触发词特征、属性值特征和分布特征,根据这些特征去预测并抽取输入文本中包含的地理实体属性信息。特征选择的好坏直接影响条件随机场模型的识别准确度,可采用属性特征标注、字特征、词特征和词性特征对文本信息进行训练,根据抽取任务的差异选择合适的特征以提高信息提取的准确率和效率。
四、多源地理目标数据处理
基于网络获取的地理目标数据由于来源不同,其坐标系统和数据表达方式均有所差别,需对其进行转换和融合处理,使数据能够满足不同应用的需求。
(一)多源地理数据空间坐标系统统一
坐标是空间信息的核心数据,是POI数据准确性的重要体现,是数据融合的重要依据。由于数据的采集来源、应用需求的不同和数据安全原因,通常不同来源POI数据的坐标系统也是有差异的。其中OSM数据使用的坐标系是WGS-84地心坐标系;高德地图采用的是中国国家测绘局制定的GCJ-02坐标系,该坐标系对原始坐标加入随机偏差,对地理位置信息进行加密;百度地图采用的是自定义的BD-09坐标系,该坐标系在国家测绘局GCJ-02坐标系的基础上进行了二次坐标加密。
WGS-84坐标系是国外地图服务商和数据供应商常用的地理坐标系,GCJ-02是所有国内公开发布的地理信息数据必须使用的坐标系。WGS-84坐标系和GCJ-02坐标系两个坐标系的转换是不可逆的,即WGS-84坐标系下的坐标可以精确转换至GCJ-02坐标系而不发生随机位置偏移;但是GCJ-02坐标系下的坐标转换至WGS-84坐标系下会产生较大的随机位置偏移。BD-09和GCJ-02坐标系则可以互相进行精确转换。
根据三种坐标系的特点,从数据获取和应用两方面综合考虑,对多源POI数据的坐标系统进行统一,境外数据采用WGS-84坐标系进行组织管理,后期应用中可根据需求自由转换;国内数据统一采用GCJ-02坐标系,需将百度地图数据转换为GCJ-02坐标与高德地图数据统一进行管理。坐标转换可以通过百度和高德地图提供的接口实现,转换精度较高。
(二)多源POI数据融合方法
多源POI数据融合主要有基于空间位置和基于非空间属性的融合方法。POI数据分布密集,空间位置相近,数据属性项较少,可采用空间位置和非空间属性相结合的方法进行数据融合。POI数据融合主要包括同名实体的匹配和属性字段的融合两个方面。
1、同名实体匹配
同名地理实体通常具有相同或者相似的名字、地址和相近的地理坐标,在空间位置和非空间属性上具有较高的相似度,因此同名实体的识别主要基于POI名字和地址属性的相似性和地理位置信息的相似性实现。
基于非空间属性的相似度匹配以语义相似度和字符相似度为基础,首先将文本信息划分为基本语义单元,如“哈尔滨饺子馆”划分为“哈尔滨”和“饺子馆”两个语义单元,再根据字符相似度匹配算法对基本语义单元进行匹配。该方法既考虑了POI名字和地址中的语义信息,又避免了因过度利用语义信息而可能产生的POI名字误匹配。
基于空间位置的相似度匹配主要有基于拓扑关系和基于度量关系的匹配方法。本文采用的数据源POI为点状地理实体,其空间关系主要为度量关系,因此采用基于度量关系进行相似度匹配。地理实体度量关系的相似性实际就是两个POI点之间的空间距离,当该距离小于某一阈值时,可将二者作为匹配对象。
2、属性字段融合
同名实体匹配后需将POI属性字段合并以获取更加完整的数据集。POI属性字段融合主要包括对多源POI唯一属性项和共有属性项的处理。唯一属性项通常直接加入合并的融合数据集中,丰富数据集的属性信息。共有属性项的处理中通常只保留单一来源数据或合并所有来源的数据。
百度地图和高德地图POI的共有属性项包括名字、地址、电话、类别等。其中,名字是匹配相似度计算的重要参考,通常同名实体的名字和地址相同或者相似,名字相同的可直接合并,名字相似的则要综合考虑名字的准确度和描述详细程度,可采用式(1)对目标的准确度和详细程度进行综合描述,对于同名实体保留重要性高的名字。POI地址的数据特征与名字相似,可采用相同方法进行融合。

五、结论
本文以丰富的网络信息为基础,对地理目标的获取与处理方法进行了研究,综合高德地图、百度地图和OSM开源数据等数据源实现了对地理目标位置数据的批量式、高爬全率获取,为全球区域的地理实体位置数据的快速在线获取提供了支持;采用属性归一化、基于规则匹配等方法实现了半结构化地理目标属性数据的抽取,基于弱监督的条件随机场实现了非结构化地理目标属性数据的抽取,完善了地理目标的属性数据;通过同名实体匹配和属性字段融合相结合的方法实现了多源数据的自动融合处理,提高了获取的地理目标数据的质量。
由于网络信息资源过于庞大,本文仅针对部分互联网资源和部分关键点对地理目标信息的获取与处理方法进行了研究,后续研究中,如何从更多包含地理空间信息的网站中获取地理目标位置数据、基于半结构文本获取更大规模的语料、提升非结构文本标注的准确率和召回率、对获取数据质量进行更为全面准确的评价等方面是研究的重点。
猜你喜欢
河北理科教学研究(2021年4期)2021-04-19 13:34:44
计算机教育(2020年5期)2020-07-24 08:53:00
科技资讯(2019年18期)2019-09-17 11:03:28
中国科技纵横(2019年15期)2019-08-27 03:34:44
教育界·下旬(2019年1期)2019-04-26 10:06:40
中学生数理化·七年级数学人教版(2018年4期)2018-06-28 03:26:28
数学大世界(2018年1期)2018-04-12 05:39:03
中等数学(2017年2期)2017-06-01 12:21:50
计算机工程(2015年8期)2015-07-03 12:20:35
中国海洋大学学报(自然科学版)(2014年8期)2014-02-28 12:21:31
