
基于Windows的离线关键词语音识别系统设计与实现
2019-10-18 02:57孙林超秦会斌崔佳冬
软件导刊 2019年9期
关键词:语音识别
孙林超 秦会斌 崔佳冬


摘 要:由于传统人机交互大多使用键盘、鼠标等交互方式,速度较慢,因此语音识别开始受到越来越多人的青睐。但语音识别也存在如扩展性太差、可复制性不好造成单个产品价格过高、过于依赖外部条件导致对自身使用有所限制等问题。设计并实现一种基于本地的语音识别系统,通过构建抽象语法树,实现语音控制操作。实验结果表明,该系统的离线识别准确率可达70%以上,可以在局域网内实现语音操作。
关键词:语音识别;离线识别;XML文件;语法树
DOI:10. 11907/rjdk. 192017 开放科学(资源服务)标识码(OSID):
中图分类号:TP319文献标识码:A 文章编号:1672-7800(2019)009-0116-05
Design and Implementation of Offline Keyword Recognition Based on Windows
SUN Lin-chao,QIN Hui-bin,CUI Jia-dong
(Institute of Electron Devices & Application, Hangzhou Dianzi University,Hangzhou 310018, China)
Abstract:In view of the shortcomings of the keyboard and mouse interaction methods used in the traditional human-computer interaction mode, such as slow speed and easy travel, voice recognition is increasingly favored by everyone. Nowadays, there are different problems in the speech recognition, such as extremely poor expansion, poor reproducibility of individual products, and relatively limited dependence on external conditions. We have designed and implemented a local speech recognition system in which an abstract grammar tree is constructed to realize operation controlled by speech. The experimental results show that the accuracy of the design is over 70%, and the effective speech recognition is realized. By setting off-line keywords with good extensibility and reproducibility, we can achieve the independence of speech recognition and the desired voice operation in the LAN.
Key Words:speech recognition;offline recognition;XML file;grammar tree
0 引言
語言是人们最常使用的交流方式之一,因此语音识别技术也成为人们关注的焦点。语音识别是将语音信号转化为机器可理解信号的技术[1],涉及概率论、人工智能、信号论等多学科知识。语音识别始于上世纪50年代,当时主要实现了针对特定说话人的数字识别[2]以及对10个单音节词的识别[3]。之后苏联学者Vintsyuk[4]以及日本的Itakura[5]、Sakoe[6]提出动态时间规划与线性预测编码技术,对于特定人与特定词的语音识别取得了较好效果;1973年,美国的卡耐基梅隆大学和贝尔实验室等研究单位构造了Harpy[7]等系统,为之后语音识别技术的快速发展奠定了基础;进入80年代后,语音识别技术进入高速发展期,工具包HTK(Hidden Markov Toolkit)[8]等开源开发包与卡耐基梅隆大学搭建的SPHINX[9]的出现极大降低了语音识别技术的研究门槛,引发了语音识别技术新的研究热潮;90年代之后,随着技术的不断进步,尤其是新声学模型[10]的出现,例如线性动态模型(Linear Dynamic Model,LDM)[11]、隐藏动态模型(Hidden Dynamic Model,HDM)[12]等,语音识别技术开始从实验室走向实际应用。近年来随着运算与存储技术的不断成熟,语音识别技术开始大规模商用,国内外公司都纷纷推出自己的语音识别系统,如国外的微软和苹果,国内的百度、科大讯飞等公司,可以预见未来语音识别的商业应用范围将会更广[13]。
语音识别一般分为3类:孤立词语音识别、连续语音识别与关键词语音识别[14]。用于语音识别的技术手段较多,主要分为基于语音芯片与基于云平台语音接口两种方法。基于语音芯片的方法利用微处理器芯片上的嵌入式系统实现语音识别,但是存储容量有限,给以后的二次开发带来了较大困难[15];基于云平台语音接口的方法因为其将语音片段存储于云端,可节省本地内存,降低二次开发难度,但是同样存在因网络不稳定导致的问题,限制了其在部分局域网内的语音识别应用。
因此,针对以上问题,本文设计了基于Windows操作系统的离线关键词识别软件,可解决因存储容量有限造成二次开发难度较高,以及网络通信不畅时语音识别效果差等问题,同时充分考虑对语音要素的识别,在关键词设置上充分考虑关键词的通用识别性,以提高离线识别率。
1 语音识别基本流程与应用场景设计
1.1 语音识别基本流程
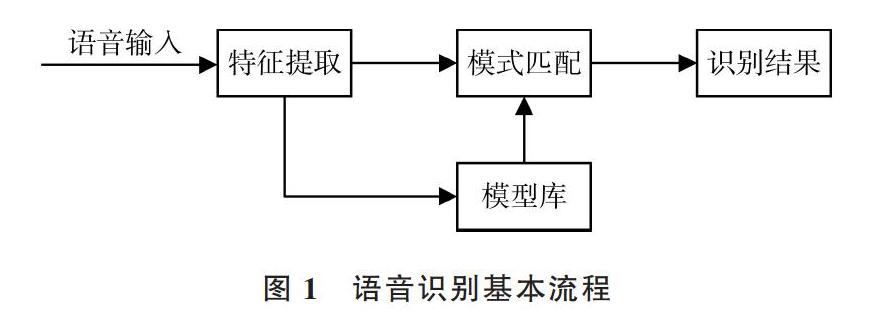
语音识别(SR)的本质是将输入的音频流信号借助训练好的声学模型转变为文本信息的过程。该过程是一个搜索匹配过程,对存储空间与系统计算能力有一定要求,也可以看成一个前端(Client)和后端(Server)的处理与通讯过程。语音识别基本流程如图1所示。
前端过程为:将获取到的录音按照训练的声学模型进行切片处理,然后从每个单独切片中获取可能表示某个字词的发音单元,然后将其转换成该音频信号中表示的数值。所以麦克风采样率越高,对录音的识别也越准确。
从技术层面上看,语音识别的后端处理更像是一个专门的搜索引擎,其接收前端产生的输出并搜索3个数据库:声学模型、词典及语言模型[16]。主要分为3部分:①声学模型可以训练识别特定用户的语音模式与声学环境特征;②词典列出该语言中的大量单词,并提供每个单词如何发音的信息;③语言模型表示单词组合方式。
对于任意给定的声音片段,语音识别质量取决于搜索改进情况,以消除不良匹配,并选择更可能的匹配。无论是处理声音还是搜索模型,在很大程度上都取决于语言与声学模型质量及其算法的有效性。
虽然识别器的内置语言模型旨在表示综合语言域(如英语口语),但语音应用程序通常仅需处理对该应用程序具有特定语义的某些语言。 应用程序不应使用通用语言模型,而应使用限制识别的语法,以仅侦听对应用程序有意义的语音。该方式具有以下优点:①提高识别准确性;②保证所有识别结果对应用程序都有意义;③使识别引擎能够识别文本中固有的语义值。
1.2 离线关键词语音识别设计应用场景
现有网络系统主要分为两类:广域网与局域网。广域网网络连接外网系统,优点是易于扩展、系统处理能力强,但缺点是其严重依赖外网,如果外网出现问题,整个系统则难以运行,而且连接外网也会带来一定安全风险;局域网不连接外网,在处理能力上不如广域网系统,但不会面临外网攻击的危险,因此在使用过程中可靠性较高。广域网系统与局域网系统分别如图2、图3所示。
对于语音识别开发而言,语音识别分为在线识别与离线识别两类。因为在线语音识别的主要识别过程位于云服务器上,所以在线语音识别又称为云语音识别。由于云服务器强大的存储与计算能力[17],在线语音识别方法对长语音的识别准确率较高,但其缺点也很明显,由于广域网系统严重依赖于网络连接,可能会产生网络延迟等问题。在一些特殊场景下,如在局域网内或外网连接环境较差时,则要考虑采用离线语音识别方法。离线语音识别受限于系统自身条件,识别语句相对较短,准确率也较低,但其相对在线语音识别更加稳定可靠。
语音识别本质上是一个搜索匹配过程,离线语音识别要提高匹配准确率,需要在开发前为想要识别的语音设计专门的语法结构,以提高语音识别度。离线語音识别通过注册特定词汇,实现对特定声纹的识别[18],比较适合于命令型场景,例如打开浏览器等。对于大型、复杂的软件,由于交互界面按钮较多,操作十分繁琐,导致用户体验不佳,因此可以设定命令词,在说出需要的关键词后即可直接跳转到对应页面,并完成相应功能。
1.3 离线关键词语音识别设计与实现
本设计是基于微软的Windows系统平台实现的,可将复杂的控制操作转变为简单的语音命令,并实现离线情况下对命令词的识别,以及对语音命令的文本输出。具体包括以下几个步骤:①设计语音识别具体流程;②对关键的语法树构建原则进行分析;③设置测试用例;④性能测试;⑤总结。
2 语音识别具体流程
对于Windows系统而言,语音应用程序需要VC++ Runtime Library和.Net Framework 4两个运行时库,本质是构建基于SR与语音转换(TTS)引擎上语音识别API(即SAPI)的语音应用程序。在Windows系统底层原理中,将SAPI Runtime作为提供语音技术支持(SR和TTS)的服务器,而每一个Application相当于访问服务器接口的客户端,因此需要安装相关类库。SPAI体系结构如图4所示。
对于通用的语言识别有通用语言模型,但本文不使用通用语言模型,而使用限制识别的语法,以仅侦听对应用程序有意义的语音。
在开发过程中主要遵循以下流程:①初始化语音识别器;②创建要识别的内建语法;③将创建的语法载入语音识别器;④注册语音识别事件;⑤为注册的语音识别事件创建对应处理程序。主要代码如下:
首先需要设置相关的语音识别引擎。因为语音识别引擎只能根据具体某个国家、地区文化的语法、词汇表、发音、意群等进行识别,所以当设置识别时,第一步需要指定要识别的国家语言发音库、语法词法结构等。例如设置识别的语言信息是中文,之后为音频输入添加相关配置,并添加系统音频采样设备参数。如麦克风采样参数需要设置采样率在8 000Hz 以上,一般设置为 16kHz ,可确保音频信号不失真。采样率是指 A/D 转换过程中单位时间内的采样次数,采样频率越高,则信号失真越小,对语音信号的识别越准确;麦克风声道数一般设置简单的单声道即可,但为了应用于嘈杂的环境中,本文使用双声道,因为双声道降噪效果更好[19];位深度是指单次采样精度,深度越深则精度越高。其它参数包括:语句间隔停顿时间、是否使用唤醒词触发等。
然后创建并加载语音识别语法,这也是其中最重要的。对于智能语音识别,需要充分考虑用户可能表达的多种词组,然后结合语音开发规范构建语法树与词典,以确保尽可能地识别含义相近的输入。主要在SRGS xml文件中自定义语法,例如将以打开浏览器为目的的语法设置为“打开浏览器”,之后将语法文件载入程序中,作为语音识别分析与对比的对象;接下来注册并添加识别之后的处理程序,以决定识别后的结果如何输出,是以静态文本形式输出,还是以弹框形式输出;识别完成后,最后卸载语法、关闭音频输入接口、卸载语音识别引擎,完成一次语音识别过程。具体流程如图5所示。
3 语法树构建原则
在执行识别任务时,语音识别引擎将识别结果返回到语音应用,包括语音输入的语义信息,以及识别的单词和短语文本。识别结果中包含的语义信息对于应用程序而言通常比识别的文本更具有意义。通过编写语义内容,以及从识别结果中检索语义代码,为应用程序提供可操作的信息。
语音识别语法由结构化的规则列表组成,该规则列表是语音识别引擎应尝试在语音输入中识别的单词或短语。语法规则可以识别简单的单字命令,例如“打开”或“打印”,以及更复杂的句子结构,例如“我想预订从广州飞往上海的航班,下周二出发”。语法通常定义有限的词汇表,其关注于用户希望完成的特定任务或任务集上。
语法必须定义适用于特定情况的结构化逻辑语音语句。同时,语法必须足够灵活,以包容语音输入的细微变化,以实现更为自然的说话风格,提供更好的用户体验。以咖啡订购为例:①“一会儿我想要一个拿铁咖啡”;②“你可以给我一杯咖啡吗?谢谢”。
上述语言语法,包括主谓宾的陈述表达形式、祈使句形式和礼貌用语的提问形式等。但事实上,一家咖啡店绝不仅只有拿铁咖啡一种类型,可能还包含卡布奇诺等其它种类咖啡,因而还涉及到选择。又例如:①“我打开电灯”;②“我打开空调”;③“你关闭电灯”;④“你关闭空调”。
该陈述句也涉及到选择,如图6所示。
当选择结构出现时,每个语法结构中的语法单元(主语、谓语、宾语)都是一种新状态的开始,选择结束后则会转至下一状态,语音识别应能很好地应对具体用语范围内表达相同含义的不同语法结构与同义词组选择。
4 抽象语法实现
因用例识别以实现命令为主,而不需要考虑主语是谁,所以根据语法树构建原则,只需考虑谓语及宾语变化。用例主要分为以下几类命令:①控制类命令,如 “打开”、“关闭”;②改变属性类命令,如“增大”、“减小”。这些命令的作用对象主要根据具体命令类型进行确定,例如:①具体设备。如:“电灯”、“空调”、“摄像头”;②具体属性。不同设备有不同属性,例如:“亮度”之于“电灯”,“温度”之于“空调”。
但用户使用时,又会存在不同表达方式,例如:①“打开电灯”和“把电灯打开”;②“电灯”的同义词组,如“电灯”、“灯”、“智能灯”等,“打开”的同义词组,如“开”、“打开”、“开启”等。
因此,将语音识别核心处理逻辑分为两部分:①语法构建;②注册的语音识别程序处理业务逻辑。
语法构建调用CreateGrammar()函数,使用基于静态的SrgsDocument文档加载方法,因为该方法可以通过替换生成的静态SrgsDocument文档,有效应对语料库不断变更(如删减或扩充)的情况,并且无需重新编译整个语音程序。
调用CreateGrammar()函数后,则在内存中创建了语法树。调用GenerateGrammar(srgsDoc)函數后,便通过DOM技术将内存中的语法树写入类xml风格文件中,并编译生成性能更好、体积更小,但不易扩展与维护的扩展名为 “.cfg”的二进制语法树格式文件。不论是装载类xml风格的语法树文件,还是装载类xml风格编译后生成的二进制语法树格式文件,语音识别引擎都能识别出构建的语料库,区别仅在于:①“.cfg”文件需要通过编译“.xml”生成;②替换与装载“.xml”文件,或者“.cfg”文件。
5 系统性能测试
为了验证开发的语音识别系统是否可以较为准确地识别出预定义的语音指令,下面进行语音测试实验。测试环境选择较为安静的大学教室,试验设备如表1所示。选择A、B、C 3人分别读出“打开电灯”、“打开空调”、“关闭电灯”、“关上电灯”,每人平均读100次,然后统计成功率。
其中,“打开电灯”的成功率为71%,“打开空调”的成功率为72.3%,虽然低于在线识别方法90%的成功率,但仍达到了比较满意的效果[20]。对比表4、表5可以看出,在相同环境下,针对3人语音的平均识别率因命令词不同而有很大差别,一个高达71.7%,一个只有34%。其中的主要差别是“闭”与“上”,虽然语义目的相同,但是语音语调不同[21]。“上”中包含了翘舌与后鼻音,有些地方方言较重,无法区分前鼻音和后鼻音或者翘平舌,有些地方方言较轻则读音较准。但“关上”动作在系统操作中是不可或缺的,所以设计命令词时,需要回避一些难以识别的词,以增强系统可靠性。
6 结语
本文设计并实现了一个基于Windows的关键词离线语音识别系统,可根据实际应用需要设置控制词,方法较为简单,在语音识别中不需要花费大量时间与精力设计声学模型,且不依赖于网络连接。经过测试,该方法可以有效识别出文本结果,且成功率较高。由于实验条件的限制,本设计还有许多需要改进的地方,例如对一些长句识别的灵活性尚有待提高,并且需要进一步实现与移动端的结合。
参考文献:
[1] 詹新明,黄南山,杨灿. 语音识别技术研究进展[J]. 现代计算机:专业版,2008(9):43-45,50
[2] DAVIS K H,BIDDULPH R,BALASHEK S. Automatic recognition of spoken digits[J]. The Journal of the Acoustical Society of America, 2005, 24(7):669.
[3] OLSON H F,BELAR H. Phonetic typewriter[J]. IRE Transactions on Audio, 1957, 5(4):90-95.
[4] VINTSYUK T K. Speech discrimination by dynamic programming[J]. Cybernetics, 1968, 4(1):52-57.
[5] ITAKURA F. Minimum prediction residual principle applied to speech recognition[J]. IEEE Trans. Acoust. Speech Signal Process,1975.
[6] SAKOE H,CHIBA S. Dynamic programming algorithm optimization for spoken word recognition[J]. IEEE Transactions on Acoustics, Speech, and Signal Processing,1978, 26(1):43-49.
[7] LOWERRE B. THE harpy speech understanding system[M]. Readings in Speech Recognition, 1990:576-586.
[8] AL-QATAB B A Q,AINON R N. Arabic speech recognition using hidden Markov model toolkit(HTK)[C]. Information Technology (ITSim), 2010 International Symposium in. IEEE, 2010.
[9] LEE K F,HON H W,REDDY R. An overview of the SPHINX speech recognition system[J]. IEEE Transactions on Acoustics, Speech and Signal Processing, 1990, 38(1):35-45.
[10] 劉聪. 声学模型区分性训练及其在LVCSR系统的应用[D]. 合肥:中国科学技术大学, 2010.
[11] FRANKEL J F J,KING S K S. Speech recognition using linear dynamic models[J]. IEEE Transactions on Audio Speech and Lanuage Processing,2007,15(1):246-256.
[12] DENG L. Dynamic speech models—theory, algorithms, and applications[J]. IEEE Transactions on Neural Networks,2009,20(3):545-546.
[13] 孙晶,凌云峰. 语音识别系统技术及市场前景探析[J]. 科技资讯,2011(20):1.
[14] 张帅林. 基于HMM的关键词语音识别技术在智能家居中的应用研究[D]. 兰州:兰州交通大学,2017.
[15] 陈哲. 智能家居语音控制系统的设计与实现[D]. 成都:电子科技大学,2013.
[16] 马志欣,王宏,李鑫. 语音识别技术综述[J]. 昌吉学院学报,2006(3):93-97.
[17] 吴吉义,平玲娣,潘雪增,等. 云计算:从概念到平台[J]. 电信科学,2009,25(12):1-11.
[18] 郑方. 声纹识别技术及其应用现状[J]. 信息安全研究,2016,2(1):44-57.
[19] 李晓雪. 基于麦克风阵列的语音增强与识别研究[D]. 杭州:浙江大学,2010.
[20] 苟鹏程. 基于Android的语音识别设计及应用[D]. 天津:天津大学,2017.
[21] 李如龙.论汉语方言语音的演变[J]. 语言研究,1999(1):102-113.
(责任编辑:黄 健)
猜你喜欢
科技创新与应用(2017年3期)2017-02-18
中国新通信(2016年21期)2017-01-06
现代电子技术(2015年11期)2015-07-28
现代电子技术(2015年8期)2015-07-09
