
基于哈夫曼编码的多线程无损压缩库的设计与实现
2019-10-16 09:07:12彭海峰刘永红赵卫东成都大学信息科学与工程学院四川成都6006成都大学模式识别与智能信息处理四川省高校重点实验室四川成都6006
成都大学学报(自然科学版) 2019年3期
鄢 涛, 彭海峰, 李 浩, 陈 超, 刘永红, 赵卫东(.成都大学 信息科学与工程学院, 四川 成都 6006;2.成都大学 模式识别与智能信息处理四川省高校重点实验室, 四川 成都 6006)
0 引 言
程序开发中,文件操作是比较常用的操作.除了创建、删除及读写操作外,压缩或解压也很重要.目前,开发具有压缩功能的程序比较常用的函数库有7z、LZ4、QuickLZ及snappy等,但是这些库普遍存在不开源、嵌入到自己的项目中不够便捷等问题.对此,本研究介绍了一种基于哈夫曼树的多线程压缩C++库.该库以哈夫曼编码为基础,实现了基本的无损压缩,同时保证了良好的压缩率,并且使用C++的多线程实现了高效的压缩速度,能够满足实际开发中高效敏捷的开发需求.文件压缩通常分为无损压缩与有损压缩.压缩软件通常用的都是无损压缩,无损压缩又分为2种:一种是将数据替换成数据加重复次数,另一种是用较短的数来替换较长的数[1].本研究使用第2种方法,由此能有效地求出所有数据的带权编码最小的前缀编码方式,同时,将采用C++的多线程来处理压缩数据过大的情况,在保证压缩率时提高压缩的速度.
1 无损压缩与哈夫曼树
1.1 无损压缩的原理
1.1.1 无损压缩.
无损压缩是指利用数据的统计冗余进行压缩,可完全恢复原始数据而不引起任何失真,但压缩率是受到数据统计冗余度的理论限制,一般为2∶1到5∶1.这类方法广泛用于文本数据、程序和特殊应用场合的图像数据,如指纹图像、医学图像等,的压缩[2].现在常用的压缩软件都是无损压缩.
1.1.2 无损压缩方式.
方式1:将数据替换成数据+重复次数.例如,某个文件的内容是AAAABBBCCCCC,就可以替换为4A3B5C,将12个字符压缩为6个字符,大大减少了存储空间,但是这种压缩比较适用于重复性大且连续重复的情况.
方式2:用更短的数来替换较长的数.在计算机中所有的数据都会以二进制进行存放,文件里所有的字符、数字,在计算机里都表现为数.将每次出现的字符根据出现的权重用二进制的1位或几位进行替换,这样1个字节就能存储多个字符,减少了普通编码文件所占的空间大小.
1.2 哈夫曼树建立
1.2.1 统计每个字符出现的频率.
若要建立哈夫曼树,首先要计算出该文档中每个字符出现的频率,然后根据出现的频率给每个字符赋予权值.假设该文档中有A、B、C与D 4个字符,出现的次数依次是10、8、5与4次,然后可以给A、B、C与D根据出现的次数赋予编码.伪代码如下:
void analyse(char * fileName)
{
while ((fread(&temp,1,1,fp))==1)//fp为该文件的指针
{
int flagExist=0;
//判断该字符之前出现过没有?
check(flagExist);
//没有出现过
if (!flagExist)
save(temp);//存储该字符
}
fclose(fp);
}
1.2.2 根据字符出现的频率建立哈夫曼树.
先简单介绍一下前缀编码,前缀编码是指任一字符的编码都不是另一个字符编码的前缀,这种编码翻译时不会出现歧义.哈夫曼编码是一种带权路径最小的前缀编码[3],非常适用于文件压缩.获取哈夫曼编码的伪代码如下:
void createCoding(FileState * pfileState)
{
//建立根节点
node * root=createHuffman(pfileState);
//创建哈夫曼树
fillHuffmanCode(root,pfileState);
//获取哈夫曼编码
int i,j;
for(i=0;i
{
printf(″%c″,pfileState->symbolArray[i].character);
for(j=0;j<20;j++)
printf(″%d ″,pfileState->symbolArray[i].huffCode[j]);
}
}
其中,FileState为文件字符总结构体,有文件中总字符数及每个出现的字符数字2个属性.
本研究需要先建立哈夫曼树,每次依次寻找节点数组中最小的2个数,然后将其组建成一个二叉树,直到让所有的节点都组建到这棵二叉树上为止,然后根据哈夫曼树对左右两边的节点赋予编码,即得到哈夫曼编码.注意,用1、2进行编码而不是0、1,因为0可能会与一个字节初始的0产生混淆,所以用2来代替,在压缩和解压时需要把2替换成0,以便进行位的操作[4].
2 文件的压缩与解压
2.1 文件的压缩
根据获取的哈夫曼编码来读文件,将读到的数据按编码进行替换,再用C++的位操作将每个字符的0、1编码合成1个字节,再存到文件中,这样1个字节就可以存储多个字符,从而达到压缩效果.伪代码如下:
void compressor(char * fileName,char * newFileName)
{
//打开文件
ostream outFile;
if (outFile.open(fileName,ios::out)==0)
{
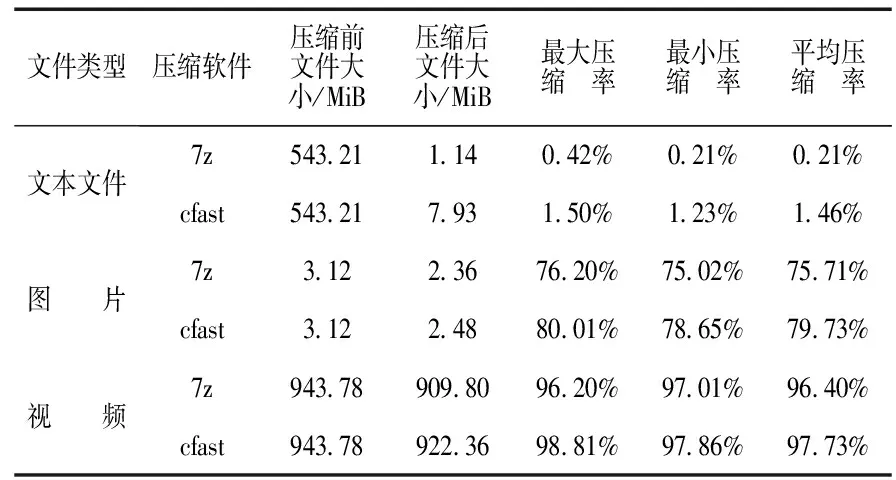
cout<<″打开失败″< return; } ostream inFile; if (inFile.open(newFileName,ios::in)==0) { cout<<″打开失败″< return; } //将字典结构体先写到文件里面,方便解压时读取 writeHeader(fp2,pfileState); //根据字典对文件重新编码实现压缩效果 writeCode(fp1,fp2,pfileState); outFile.close(); inFile.close(); } 本研究修改文件的后缀为ycf,即Linux下的压缩文件格式,然后对照着编码表,将每个字符翻译成二进制中的位,再用C++中的位操作将这些位合成字节实现压缩. 解压过程正好与压缩过程相反.解压过程是,依次读取文件中每个字符,然后根据字符的二进制对照哈夫曼编码进行翻译,将翻译的结果存储到指定的文件中,这样就完成了解压[4].解压伪代码[5-6]如下: void deCompress(char * fileName,char * newFileName) { memset(&fileState,0,sizeof(fileState)); //读取文件获得相关信息存储到fileState中 readHeader(fileNmae, & fileState); //创建哈夫曼树 node * root=NULL; root=createHuffman(&fileState); //翻译哈夫曼编码得到新的解压文件 writeDeCompressfile(fp,fileName,root,newFileName); } 解压时,先读取文件,然后依次翻译当中的每个字节,将字节中的位翻译成字符,因为哈夫曼编码是一种前置编码,在翻译过程中不会产生歧义,这样读完整个文件即可完成解压过程. 如果处理的文件较大,则单线程的设计模式效率就会很低.压缩一个文件可能需要几分钟甚至更久,由于这么长的压缩时间不能满足实际开发需要,所以必须要引入多线程的设计模式[7-8].本研究使用C++11的多线程开发加快压缩速率.压缩过程的伪代码如下: void compress(char * fileName,char * newFileName) { //用2个线程让分析文件与创建哈夫曼编码同时进行 std::thread th1(analyse,fileName); std::thread th2(createCoding, & fileState); //阻塞主线程 th1.join(); th2.join(); writeFile(fileName, & fileState,newFileName); } 本研究使用C++11库中的thread类来进行并发操作,同时使用2个线程让分析文件与创建哈夫曼树同时进行,这样能大大加快压缩速度. 封装成静态库的过程很简单,只需要调节项目的相关属性,再生成项目即可.库封装好之后,调用库中函数的步骤如下: 1)更改项目的相关属性,导入库; 2)引入头文件,应用相关函数进行压缩或者解压,代码如下: //引入头文件 #include #include #include int main(int argc, char ** argv) { ycl::compressor t;//定义库中的压缩类 std::string op,tar; //被压缩的文件绝对路径名及压缩后的文件名 std::cin >> op >> tar; t.compress(op,tar);//压缩 t.deCompress(op,tar);//解压缩 return 0; } 本研究以7z的库为例介绍如何用7z库函数进行压缩与解压缩.由于7z的库中没有现成的压缩函数,而且开源社区也只有7z的源代码,程序员需要自己编译成静态库,然后导入到自己的项目中,具体步骤如下: 1)从网络下载源代码,用VS对其编译成静态库; 2)新建自己的项目导入编译好的静态库; 3)编写压缩与解压函数.这个过程非常麻烦,因为需要弄懂库中所有函数,才能将其应用到自己的函数中,这将大大降低开发的效率,增加不必要的开发难度与时间消耗[9]. 封装好库后,在Windows平台下分别对图片、文本文档及视频等常用文件进行大量的数据测试,因为实际开发中所要压缩的文件大小都是以MiB为单位,所以本研究的测试文件都为1 MiB到1 GiB之间的文件.为了保证数据的可靠性,每种文件的样本数量为100,由于手动压缩文件较麻烦,本研究先把文件存在文件夹中,然后用C语言循环遍历此文件夹进行压缩. 测试压缩率如表1所示. 表1 测试压缩率 表1中的文件大小都为样本容量中的平均文件大小.从表1可知,本研究设计的库的压缩率与现有的库还有一定的差距.但是,在CSDN、掘金、博客园等论坛上寻找的近100份问答中,一般情况下,本研究所探讨的压缩率已经能完全符合实际开发的需求,同时使用起来简单便捷,然而使用7z的平均学习时间是8 h左右,但使用本研究的库最多需要2 h的学习时间,且不需要繁琐的导入过程,开发效率高. 本研究讨论了利用哈夫曼编码的多线程压缩程序.实验表明,哈夫曼编码的压缩方法具有良好的压缩率,缺点在于需要耗费大量时间,所以在库中加入了C++11中的多线程,这样大大缩短了压缩时间.简洁的库也保证了程序员使用过程中的便捷,相对于目前常用的库较大地提高了开发效率,同时对研究文件压缩过程和压缩算法的改进具有一定的参考意义.2.2 文件的解压
3 优化、封装与性能测试
3.1 多线程优化
3.2 封装成库
3.3 性能测试分析
4 结 语
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23销售与市场(营销版)(2021年10期)2021-11-21 20:15:03小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42电子制作(2019年19期)2019-11-23 08:41:50销售与市场(营销版)(2019年6期)2019-06-21 01:16:38少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14科学与财富(2018年26期)2018-10-24 15:31:44科技信息·中旬刊(2018年4期)2018-10-21 03:34:14网络安全技术与应用(2017年9期)2017-09-20 09:54:28滁州学院学报(2016年5期)2016-12-16 07:41:46
