
基于词向量相似度的食品安全问答系统设计与实现
2019-10-15 02:21杨晨张鹏
软件导刊 2019年8期
关键词:食品安全
杨晨 张鹏
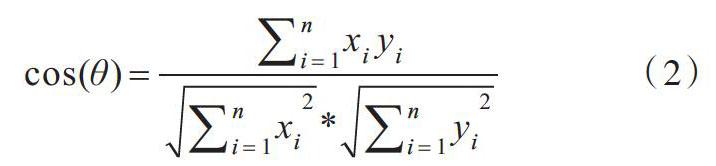


摘 要:针对目前食品安全问答系统准确率不高且无法满足智能化问答要求等问题,基于词向量相似度设计食品安全问答系统。采用深度学习方法构建食品安全领域知识库及词向量模型,结合近义词库提出问句相似度计算方法,将问句与知识库内所有问句进行匹配,返回相似度最高问句对应的答案。实验结果表明,该系统问答准确率达到80%,能满足食品行业用户的日常问答需求。
关键词:食品安全;词向量;句子相似度;问答系统
DOI:10. 11907/rjdk. 182790 开放科学(资源服务)标识码(OSID):
中图分类号:TP301文献标识码:A 文章编号:1672-7800(2019)008-0016-05
Application of Food Safety Question Answering System
Based on Word Vector Similarity
YANG Chen, ZHANG Peng
(School of Computer Science, Jiangsu University of Science and Technology, Zhenjiang 212003, China)
Abstract:Aiming at the current problem of the accuracy of the question and answer system in the field of food safety, and the inability to meet the requirements of intelligent question and answer,a food safety question and answer system based on word vector similarity is proposed. The system uses the deep learning method to construct the knowledge base and word vector model in the field of food safety, and combines the thesaurus to propose the method of calculating the similarity of questions, matching the questions with all the questions in the knowledge base, and returning the corresponding questions with answers of the highest similarity. The experimental results show that the accuracy rate of the system is 80%, which can meet the users' daily need of questions and answers in the food industry.
Key Words:Food safety; word vector; sentence similarity; question answering system
作者简介:杨晨(1994-),男,江苏科技大学计算机学院硕士研究生,研究方向为智能信息处理;张鹏(1994-),男,江苏科技大学计算机学院硕士研究生,研究方向为智能信息处理。
0 引言
随着网络技术的发展,信息来源愈加丰富,但也带来信息质量参差不齐、难以得到准确信息等问题,利用自然语言处理技术构建面向不同领域的问答系统应运而生[1]。
相关研究有:考虑到命名实体和实体关系对答案匹配的影响,通过分析命名实体和实体关系,于根等[2]构建了基于信息抽取技术的问答系统,并提出基于層次的答案提取方法;秦兵等[3]根据用户提问内容构建候选问题集,通过计算问题集与问句相似度并返回答案的方法实现基于常见问题集的问答系统,并证明此方法能有效提高问题匹配的准确率;苏斐等[4]通过对问答系统中问句信息的深入挖掘,实现了基于问句表征的问答系统,有效改善了问答系统的答案抽取准确性和系统性能。
目前特定领域(如食品安全)问答系统研究较少,且存在回答效果差、性能低下等问题[5]。因此,利用自然语言处理技术进行特定领域问答系统的研究有着重大意义。本文通过引入近义词词典,提出一种基于近义词词向量相似度的问句相似度算法,实现了基于此算法的食品安全问答系统。
1 相关技术
1.1 自然语言处理
文本预处理是实现自然语言处理的基础[6],文本预处理主要包括分词、去除停用词等操作。中文文本的分词方法[7]主要有基于字符串匹配的分词方法、基于理解的分词方法和基于统计的方法。
基于字符串匹配的分词方法主要包含正向最大匹配法、逆向最大匹配法、最少切分和双向最大匹配法。在正向最大匹配分词算法基础上,常建秋等[8]提出一种正向最大逐字匹配方法,提高了分词的准确性,增强了基于字符串匹配分词方法的实用性。
基于理解的分词方法[9]需要大量的信息和语言知识作为基础,但汉语语言知识的复杂性、多样性使基于理解的分词方法难以在实际中运用。
基于统计的分词方法则是利用统计机器学习模型对已分词后文本进行词语切分规律的学习,进而对未知文本进行分词。基于统计的分词方法,常用的统计模型有最大熵模型[10](ME)、隐马尔可夫模型[11](Hidden Markov Model ,HMM)、N元文法模型[12](N-gram)和条件随机场模型(Conditional Random Fields,CRF),从而衍生出最大熵分词方法、最大概率分词方法等基于统计的分词方法。
常见的分词工具有jieba分词、IKAnalyzer、汉语词法分析系统(ICTCLAS)和Stanford 汉语分词工具[13]。
文本中词汇间的关系难以依靠词语本身获得,只有将其转换为向量形式并放入一个较大的语料库中,才能判断词汇之间的关系[14]。
Word2vec是Google于2013年推出的一个自然语言处理工具,它采用两种神经网络语言模型CBOW和Skip-gram模型实现词的分布式表示[15]。CBOW模型和Skip-gram模型都属于浅层的双层神经网络,包括输入层、隐藏层和输出层。CBOW模型的基本原理为输入一个特定词的上下文相关词的词向量,输出这个特定词的词向量,而Skip-Gram模型的原理则是将特定的一个词的词向量作为输入,输出是特定词对应的上下文词向量。Skip-gram模型的精度一般优于CBOW模型[16],因此本文采用Skip-gram模型进行训练。
1.2 相似度计算
相似度计算是实现问答系统的重要一步[17],通过计算用户输入的问句与知识库中每一条知识所对应问题的相似度,返回相似度排名中较为靠前的知识,从而确保答案更加精准。计算语句相似度方法很多,包括计算余弦相似度[18]、N-gram相似度[19]等方法。
(1)N-gram相似度是一种模糊匹配方法,通过两个相似句子间的“差异”衡量相似度。计算方法为将原句子按长度N(N一般取值为2或3)切分得到词段,即原句中所有长度为N的子字符串,对于这两个句子,则可通过共有子串的数量定义相似度,公式如下:
[P(T)=P(w1|begin)*P(w2|w1)*?*P(wn|wn-1)] (1)
其中,[P(w1|begin)]可以理解为以[w1]开头的所有句子在句子总数中的比例,[P(w2|w1)]表示[w2,w1]同时出现的次数与[w1]出现的次数比值。
(2)余弦相似度指利用向量空间中两个向量夹角的余弦值表示两个个体间差异的大小程度。余弦值越接近1表示夹角越接近0°,即两个向量越相似;反之,余弦值越接近0表示夹角越大,说明这两个向量不同,称为“余弦相似性”。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上的差异。
[cos(θ)=i=1nxiyii=1nxi2*i=1nyi2] (2)
其中,[xi]为句子1中的某一个特征词的词向量,[yi]为句子2中某个特征的词向量。
2 基于词向量的问句相似度算法
2.1 分词处理
将用户输入的问句记作[Si],同时将知识库中对应的问句记为[Ai],通过jieba分词工具对[Si]和[Ai]进行分词,然后去除停用词,得到一个由N个词组成的句子[Si'={x1,x2,?,][xN}]与一个由M个词组成的句子[Ai'={a1,a2,?,aM}]。
2.2 分词替换为标准词
近义词采用人工录入方式进行。经过多年积累,系统常用词汇基本上都有比较全的近义词集,其中词条已达千万级。针对零售行业系统也作过相关业务词的近义词扩展。
除近义词关系外,系统还考虑了其它关系,如 “检验”是一个词汇,包含“检验流程”、“检验单位”等,为这种“包含”关系定义 “检验父类”进行管理。“检验”本身又可表述成“检查”等,为这种同义词关系定义 “检验近类”进行管理。通过这种词汇级的语义关系管理,最真实且精确地表达了词汇本身的含义,从而为精确的语义理解打下基础,同时为每一种语义设定标准,此分词称为标准词。
此步骤把[A'i=a1,a2,a3,?,aM]中的各个分词元素替换为标准词。
2.3 词向量训练
Word2vec的训练模型具有一个隐含层的神经元网络,输入词汇表向量,以词汇表为参照,对于训练样本中的每个词,若词存在词汇表中,則将其在词汇表中的位置标志置为1,否则置为0。输出结果是词汇表向量,对于训练样本标签中的每一个词,把在词汇表中出现的位置值置为1,否则置为0,最终将输入样本中的词转化为128维的向量。
使用Word2vec模型将[S,i]和[A,i]表示为词向量:
[xi'={ω1,ω2,?,ωn}](i=1,2,…,n) (3)
[aj'={φ1,φ2,?,φm}](j=1,2,…,m) (4)
其中[ωi]和[φi]分别表示词向量[xi]和[aj]在第i维的向量值,[xi']和[aj']分别表示词[xi]和词[aj]由word2vec处理成的词向量,则[Ai]与[Si]间的词向量相似度为:
[Sim1(Ai,Si)=i=1nωiφii=1nωi2*i=1nφi2] (5)
2-gram相似度计算:计算输入问句和知识中答案对应的问句之间的2-gram相似度前,分别计算[Ai]和[Si]的2-gram序列:
[Aseqi={Bw1,w1w2,?,wn-1wn,wnE}] (6)
[Sseqi={Bw'1,w'1w'2,?,w'n-1w'n,w'nE}] (7)
其中[B]和[E]是特殊符号,分别表示输入问句(知识库中答案对应的问句)的开始和输入问句(知识库中答案对应的问句)的结束,则[Ai]和[Si]间的2-gram相似度为:
[Sim2(Ai,Si)=|Aseqi?Sseqi||Aseqi?Sseqi|] (8)
搭配相似度计算:在计算输入问句和答案对应的问句之间搭配相似度前,对输入问句(知识库中答案对应的问句)进行搭配分析,获取输入问句(知识库中答案对应的问句)中的搭配对,其中[Acoli]為[Ai]的词搭配集合,[Scoli]为[Si]的词搭配集合,则[Ai]和[Si]间的搭配相似度为:
[Sim3(Ai,Si)=|Acoli?Scoli||Acoli?Scoli|] (9)
最终相似度计算:通过多特征的相似度融合算法计算输入问句与知识库中答案对应问句的相似度为:
[Sim(Ai,Si)=α1*Sim1(Ai,Si)+α2*Sim2(Ai,Si)+α3*Sim3(Ai,Si)] (10)
其中[α1,α2,α3]分别表示这3种相似度权重,满足[α1+][α2+α3=1]。
3 系统设计
食品安全问答系统由食品安全知识库、文本预处理、问句与知识相似度计算以及答案生成4个部分组成。
3.1 食品安全知识库构建
食品安全知识库构建是食品安全问答系统的基础和重要环节。系统通过各种渠道收集食品安全领域知识,对这些知识进行分类和整理后存入数据库中。每条知识数据包含以下信息:所属类别、知识库问句、知识库答案、知识来源。这些知识包含300个知识库问句和500个对应的知识库答案,其中食品安全法律问句80个,对应的食品安全法律答案120个;食品安全常识问句90个,对应的食品安全常识答案140个;伪劣食品防范方法问句70个,对应的伪劣食品防范方法答案130个;食品经销存储管理办法问句60个,对应的食品经销存储管理办法110个。
3.2 文本预处理
(1)对食品安全知识库中答案对应的问句进行预处理,包括去除标点、停用词以及分词等。本文采用的分词工具为jieba分词,jieba分词支持3种分词模式:将句子作最精确切分的精确模式、扫描出句子中所有可以合成为词组的全模式、在精确模式上再度切分的搜索引擎模式。
(2)分词完成后对分词结果采用术语语义网扩展分词语义网(semantic web)。语义网是一种描述事物的网络,运用计算机能理解的方式构建,如图1所示。
图1 语义网结构
语义网由7层组成[20],分别为:
(1)Unicode和URI。“统一字符编码”与“统一资源定位”是语义网的基础,统一国际编码格式以实现事物的统一表达。
(2)XML和NS。用XML语言实现数据与形式的剥离,提取出数据,并将表现形式格式化。
(3)RDF和EDF Schema。表示Web上的元数据。
(4)Ontology vocabulary。对数据资源分析,提取出语义信息。
(5)Logic。提供语义推理规则。
(6)Proof。在逻辑层上利用公理进行推理与证明。
(7)Trust。提供信任机制。
本文利用术语语义网对分词进行扩展,算法如下:
算法1:分词替换为标准词算法
输入:一组分词question1
输出:扩展后的分词组question2
过程:
For each i[∈]question1 do
S = S.replace(i)//用术语语义网进行标准词替换
End For
扩展后的分词词组在食品安全知识库中不一定能找到答案对应的问句分词,需要把分词转化为标准词之后再查找答案对应的问句分词。本文通过近义词词典找出标准词。如“食品检查”、“食品测试”在近义词词典中查找出标准词为“食品检验”。
通过一系列处理将输入问句拆分成多个词语组成的集合,为进行基于词向量的相似度计算作准备。
3.3 问句相似度算法
问句与知识相似度计算是本系统核心功能,计算步骤如下:
算法2:基于近义词词向量相似度的问句相似度算法
输入:食品安全相关问句[Si={x1,x2,?,xN}]
输出:问句与知识库中所有答案对应问句的相似度集合[Sim(Ai,Si)]
(1)用户输入问句,系统将输入问句去除标点符号、去除停用词和分词。
(2)For each i[∈]Si do
i = i.replace()
End for
//在近义词词典中寻找分词结果中词汇的近义词,并替换分词为标准词。
(3)For each i[∈]Si do
i = i.Word2vec()
End for
//利用Word2vec工具分别将分词得到的结果及系统中的知识库问句转化为词向量。
[Sim1(Ai,Si)]
[Sim2(Ai,Si)]
[Sim3(Ai,Si)]
//Sim1为两者词向量间的相似度计算。Sim2为构建输入问句词集合与系统中知识库问句集合的2-gram序列,然后用输入问句词集合的2-gram序列依次与系统中每一个知识库问句词集合的2-gram序列进行相似度计算。Sim3为对输入问句词集合与知识库问句词集合进行搭配分析,获得对应的输入问句词搭配集与知识库问句词搭配集,并依次进行问句与每一个知识库问句的搭配相似度计算。
[Sim(Ai,Si)=α1*Sim1(Ai,Si)+α2*Sim2(Ai,Si)+α3*Sim3(Ai,Si)]
//综合考虑多种相似度权重,进行多特征的融合相似度计算,从而得出输入问句与系统中所有知识库问句的最终相似度。
3.4 答案返回
用户输入问句,系统运用输入问句与知识库相似度算法求得输入问句与知识库问句相似度,判断是否匹配(设立相似度阈值,超过阈值即为匹配),按匹配程度進行排序,并将与输入问句匹配度最高的N个知识库问句对应的答案返回给用户。
4 阈值计算
词向量模型训练完成后,随机从测试数据集中抽取两个答案对应的问句进行相似度计算,得两个问句的相似度值记为x,真实值为y(相同问句真实值记为1,不同的记为0)。重复此过程n次,则测试数据结果可表示为:
[(X,Y)={(x1, y1),(x2, y2),(x3, y3),?,(xn, yn)}]
满足:
xi∈[0,1] (1≤i≤n)
yi = 0 or 1 (1≤i≤n)
则阈值[λ]的求取过程可形式化为以下问题:
一个函数:[F(x,λ)=1,xλ0,x<λ]
求:阈值[λ],使得[mini=1n|F(xi,λ)-yi|]
给出定义1:函数
[F(λ)=i=1n|F(xi,λ)-yi|]
在阈值算法计算中,精度P初始值为1000,abs函数用来计算绝对值,过程见算法3。
算法3:阈值计算
输入:(X,Y),P
输出:λ
初始化:sum1 = P,sum2 = 0,z = 0
For each (xi,yi)∈(X, Y) do
xi = xi×P
yi = yi×P
end for
//把每一个相似度xi,和真实值yi都乘以精
度P,使得xi∈[0,1000],yi=0 or 1000。
For each i∈[0,1000] do
For each (xi,yi)∈(X, Y) do
If xi >i :
z=1000
Else :
z=0
T=abs(z-yi)
sum2=sum2 + T
end if
end for
if sum2 < sum1 then
sum1=sum2
λ=i
end if
end for//i从0开始遍历到1000,求出定义1函数F(λ)的最小值,同时也求出阈值λ
5 数据集与评估方法
5.1 实验数据
实验所用数据来自食品安全知识库,包括食品安全相关法律、食品安全常识、伪劣食品防范方法和食品经销存储管理办法等4大类共500条食品安全领域知识。
5.2 评估标准
(1)查准率(Precision)。[S]表示食品安全知识问答对,[TN(S)]表示问答系统返回知识中正确答案的个数,[RN(S)]表示问答系统返回所有答案的个数,食品安全问答系统的查准率可表示为:
[P(S)=TN(S)RN(S)] (7)
(2)查全率(Recall)。[S]表示食品安全问答对,[TN(S)]表示问答系统返回知识中正确答案的个数,[AN(S)]表示问答系统中所有正确答案的个数,食品安全问答系统的查全率可表示为:
[R(S)=TN(S)AN(S)] (8)
(3)F1-Measure。[P(S)]表示食品安全问答系统的查准率,[R(S)]表示食品安全问答系统的查全率,食品安全问答系统的F1-Measure可表示为:
[F(S)=2*P(S)*R(S)P(S)+R(S)] (9)
6 实验
6.1 实验参数设置
实验选用词向量工具word2ve的Skip-gram模型进行词向量训练,抽样匹配数(sample)设置为50 000,相似度阈值(threshold)设为0.6,匹配问句数为3,返回知识数为5,进程数(process_num)为10。
6.2 实验过程
用户在系统内输入所要了解的食品安全问题,问答系统将用户输入的问句与食品安全知识库中的问句进行相似度计算,并将相似程度大于阈值的问句答案返回给用户,由用户判断返回答案中正确答案的个数,实验评估结果如表2所示。
例句:
食品检验归谁管?
分词结果:
食品,检验,归谁,管
匹配相似度最高的前3个问句:
食品检验由谁负责?
例句与问句1的句子相似度计算结果为0.75。
食品抽样检查如何实施?
例句与问句2的句子相似度计算结果为0.65。
食品抽样检验流程是什么?
例句与问句3的句子相似度计算结果为0.62。
最佳结果:食品校验由谁负责?
返回答案:
知识1:第八十四条?食品检验机构按照国家有关认证认可的规定取得资质认定后,方可从事食品检验活动。但是,法律另有规定的除外。食品检验机构的资质认定条件和检验规范,由国务院食品药品监督管理部门规定。符合本法规定的食品检验机构出具的检验报告具有同等效力。县级以上人民政府应当整合食品检验资源,实现资源共享。
知识2:第八十五条?食品检验由食品检验机构指定的检验人独立进行。检验人应当依照有关法律、法规的规定,并按照食品安全标准和检验规范对食品进行检验,尊重科学,恪守职业道德,保证出具的检验数据和结论客观、公正,不得出具虚假检验报告。
知识3:第八十六条?食品检验实行食品检验机构与检验人负责制。食品检验报告应当加盖食品检验机构公章,并有检验人的签名或者盖章。食品检验机构和检验人对出具的食品检验报告负责。
知识4:第八十九条?食品生产企业可以自行对所生产的食品进行检验,也可以委托符合本法规定的食品检验机构进行检验。
表2 实验结果评估
[问句数\&查准率(%)\&查全率(%)\&F1-Measure(%)\&20\&76\&69\&72\&40\&68\&80\&73\&60\&80\&79\&79\&80\&82\&82\&82\&100\&77\&81\&78\&]
知识5:第八十七条?县级以上人民政府食品药品监督管理部门应当对食品进行定期或者不定期的抽样检验,并依据有关规定公布检验结果,不得免检。进行抽样检验,应当购买抽取的样品,委托符合本法规定的食品检验机构进行检验,并支付相关费用;不得向食品生产经营者收取检验费和其它费用。
对于此例句,用户判断问答系统返回答案中正确的个数为4,即查准率为80%,用户重复以上操作,可以得出结论如图2所示,可以看出基于词向量相似度的食品安全问答系统在答案的查准率上表现较好。
图2 实验结果
7 结语
本文构建了基于词向量相似度的食品安全问答系统。通过引入近义词词典和词向量相似度概念,使词汇间的相似度计算变得更加准确。同时设计了基于词向量的多特征相似度算法,将句子相似度融入输入问句与食品安全知识库问句相似度计算,使答案生成更加严谨。
通过研究问答系统中问句间的相似性,对词向量空间构建方法以及语句相似度相关计算方法有了更加深入的了解,对问答系统工作流程有了一定认识。下一步研究工作:通过扩大语料库规模和更深入挖掘问句中的语义信息等方法,对食品安全问答系统性能和准确率进行改进。
参考文献:
[1] 毛先领,李晓明. 问答系统研究综述[J]. 计算机科学与探索, 2012,6(3):193-207.
[2] 于根,李晓戈,刘睿,等. 基于信息抽取技术的问答系统[J]. 计算机工程与设计,2017,38(4):1051-1055.
[3] 秦兵,刘挺,王洋,等. 基于常问问题集的中文问答系统研究[J]. 哈尔滨工业大学学报, 2003, 35(10):1179-1182.
[4] 苏斐,高德利,叶晨. Web问答系统中问句理解的研究[J]. 测试技术学报,2012,26(3):29-34.
[5] 陶永芹. 专业领域智能问答系统设计与实现[J]. 计算机应用与软件,2018(5):16-21.
[6] 王灿辉,张敏,马少平. 自然语言处理在信息检索中的应用综述[J]. 中文信息学报,2007,21(2):35-45.
[7] 孙铁利,刘延吉. 中文分词技术的研究现状与困难[J]. 信息技术, 2009(7):187-189.
[8] 常建秋,沈炜. 基于字符串匹配的中文分词算法的研究[J]. 工业控制计算机,2016, 29(2):115-116.
[9] 苏勇. 基于理解的汉语分词系统的设计与实现[D]. 成都:电子科技大学,2011.
[10] 李素建,刘群,张志勇,等. 语言信息处理技术中的最大熵模型方法[J]. 计算机科学,2002,29(7):108-110.
[11] 魏晓宁. 基于隐马尔科夫模型的中文分词研究[J]. 电脑知识与技术,2007,4(21):885-886.
[12] 冯连刚. 一种改进的基于N元语法模型的中文分词方法[J]. 自然科学,2016(10):00284-00287.
[13] SONG M,CHAMBERS T. Text mining with the Stanford CoreNLP[M]. Measuring Scholarly Impact. Springer International Publishing,2014:215-234.
[14] 张志昌,周慧霞,姚东任,等. 基于词向量的中文词汇蕴涵关系识别[J]. 计算机工程,2016,42(2):169-174.
[15] 唐明,朱磊,邹显春. 基于Word2Vec的一种文档向量表示[J]. 计算机科学,2016,43(6):214-217.
[16] 熊富林,邓怡豪,唐晓晟. Word2vec的核心架构及其应用[J]. 南京师范大学学报:工程技术版, 2015(1):43-48.
[17] 王麗月,叶东毅. 面向游戏客服场景的自动问答系统研究与实现[J]. 计算机工程与应用, 2016, 52(17):152-159.
[18] 武永亮,赵书良,李长镜,等. 基于TF-ID F和余弦相似度的文本分类方法[J]. 中文信息学报,2017,31(5):138-145.
[19] 宋彦,张桂平,蔡东风. 基于N-gram的句子相似度计算技术[C].全国计算语言学学术会议, 2007.
[20] 李洁,丁颖. 语义网关键技术概述[J]. 计算机工程与设计, 2007, 28(8):1831-1833.
(责任编辑:杜能钢)
猜你喜欢
法制与社会(2016年32期)2016-12-01
中小企业管理与科技·上旬刊(2016年11期)2016-11-28
商场现代化(2016年26期)2016-11-21
