
基于双通道模型的细粒度车型识别
2019-10-15 07:17王静黄振杰王涛
现代计算机 2019年24期
王静,黄振杰,王涛
(广东工业大学自动化学院,广州510006)
0 引言
智能交通卡口是城市的出入动脉的控制手段,加强对卡口的管理可以有效协助公安机关侦破案件,加强平安城市的建设,而车辆的检测与识别是智能交通系统的核心任务。因此,精准快速地识别细粒度车型在智能交通和公共安全发挥着越来越重要的作用。
经过科技的发展,有大量的基于计算机视觉的算法应用于车型识别。传统车型算法主要由以下两个步骤:①采用人工设计的特征提取方法(如SIFT、LBP、HOG 等)将输入的车辆图片转换为一组特征向量;②再基于该特征向量和机器学习中的分类算法(如SVM、AdaBoost、随机森林等)来训练模型。Ng 等人[1]对提取到的车辆SIFT 特征进行聚类,构造了一个二级分类器先挑选一级品牌,再利用二级分类器对车辆类型进行识别。文献[2-3]采用Hu 的七种不变矩作为车辆特征进行车型识别。Zhang 等人[4]使用Gabor 小波变换和HOG 金字塔来描述车辆特征并且构造了一个级联分类器。传统方法基于人工设计的特征提取方法比较单一,通用性较差。近年来,计算机视觉技术再深度学习理论[5-7]的促进下取得巨大进步。Deng 等人[8]针对高速公路场景下,引入CNN 理论可以识别出小车、客车和货车三种粗粒度车型。Wang 等人[9]基于深度神经网络对在各个角度下拍摄的具有复杂背景的汽车图像进行网络训练,可以识别出SUV、卡车、面包车以及小轿车四类。如文献[9]建立了一个大规模的车辆数据库CompCars,并在此数据集上使用AlexNet、GoogleNet 等卷积神经网络进行训练。也有一系列文献[10-12]提出基于图像的三维信息重构法来提高识别性能,但这些方法加大了整体模型的复杂度,计算耗时也更大。
虽然已经有很多学者对车型识别做了深入研究,但是目前很多研究和方案仍然不够健全。一是对于车型识别的属性不够精细,没有包含更丰富更细粒度的信息,仅是粗粒度层次的车型识别越来越无法满足实际应用需求;二是车型识别作为细粒度图像分类问题的子问题,具有分类精细,种类过多的特点。不同车型类别之间外观辨别难度大。依靠人工标记的精细化标签来实现细粒度的目标识别代价十分昂贵,造成细粒度车型识别的训练数据集往往偏小。本文在智能卡口小样本数据下,提出一种基于多任务学习的双通道表示细粒度车型识别算法,主要从数据增强和迁移学习策略以及设计模型的角度解决智能卡口数据样本少,车型特征差别小导致过拟合的问题。实验证明,在数据扩充策略和模型结构一致的情况下,通过迁移学习利用已有的模型在小样本数据集中微调以及设计双通道模型学习样本标签信息和样本标签之间的局部信息,提高车型识别的识别精度。对比已有的文献算法,能取得较好的效果。
1 数据、模型预处理
1.1 数据预处理
深度学习模型的飞速发展离不开海量的数据体系,数据增强为研究人员提供一种增加数据多样性的可能。针对卡口车型样本不足的特点,本文在现有数据样本的基础上,通过对训练图片进行预处理减少过拟合发生的概率。具体为使用平移变换、缩放变换、亮度变换、水平翻转变换、加入高斯和椒盐噪声生成可信数据样本,增加训练样本的多样性,提高模型鲁棒性。
1.2 微调预训练模型
针对小型图片数据集,很少有人会从零开始去训练出一个神经网络模型。有一种普遍的做法是利用迁移学习方法去微调预训练模型,该方法主要解决规模不大,样本数量有限的特定领域数据。本文首先使用通过配置不同的通道数和模块里的残差块数可以得到不同的ResNet 模型;然后通过迁移学习的方法,在公开的自然摄像机环境下收集的车型识别数据集上CompCars 对深度网络进行预训练,以学习图像的底层通用视觉特征;最后利用目标数据集对网络参数进行微调,使小规模图像数据集使用深度学习的方法成为可能,以达到准确率和运行速率上的优化。
2 双通道模型设计
从车辆纹理信息复杂度来说,车型系列、车型年款属于细粒度属性,而车辆颜色、车辆类型则属于粗粒度属性。通常情况下,粗粒度特征提取相对容易,而细粒度特征提取是寻找一些细微差别的局部区域,并利用这些局部区域的特性进行分类。但是,细粒度属性每个类别包含的训练样本有限,并且难以用底层特征来表示。本文基于多任务学习的思想,从数量极少的训练样本中学习样本分类信息和样本标签之间的局部信息,提出一个双通道的神经网络架构。
如图1 所示,双通道模型具有两个独立的分支,每个分支具有相同的网络结构和权重。训练与测试时每个分支针对输入随机的一对样本进行处理并且输出两个分类结果。双通道模型则是直接将图像块相似度计算问题转换成二分类问题。通过标签信息的分类学习和标签局部分布信息的度量学习来同时训练一个双通道的神经网络,这两个任务之间相互促进,利用标签局部分布信息的度量学习构建带约束的目标函数,能够很好防止过拟合,使网络更具泛化性。

图1 基于分类学习和度量学习的双通道模型框架图
3 损失函数
基于分类学习和度量学习的双通道模型由两种损失函数组成,因此,总目标函数是两种损失函数的加权和。
3.1 分类损失函数
双通道模型的两个分支都使用分类损失函数Softmax,用来学习车型数据样本和真实标签信息之间的误差。车型数据集包含M 个不同类别的N 个不同样本,分类损失函数Softmax 表达式如公式(1)所示:

其中,xi是样本xi在各分支上的分结果的输出。表示预测的概率。W 是模型权重参数,Wt是第t 类的输出权重,即t=1,…,M。yi是样本xi的真实值。
3.2 度量损失函数
双通道模型具有两个权重共享的独立的分支,能够输入随机的一对样本同时输出两个分类结果。对于车型识别的分类问题,双通道模型则是直接将输出标签之前的相似度计算问题转换成二分类问题,用于判断两个样本相似或者不相似。把双通道模型全连接层的前一层的输出向量作为对应输入样本的特征向量,用欧氏距离定义两个特征向量之间的距离,公式如(2)所示:

其中,Si(xi|θ)代表输入样本xi的时候,参数为θ 模型的输出特征向量,Sj(xj|θ)代表输入样本xj的时候,参数为θ 模型的输出特征向量。把距离结果S2作为一个判断相似性的更高级特征向量,后面接一个只有两类的全连接层来表示输入的样本xi和样本xj是否属于同一类,度量损失函数表达式如(3)所示:
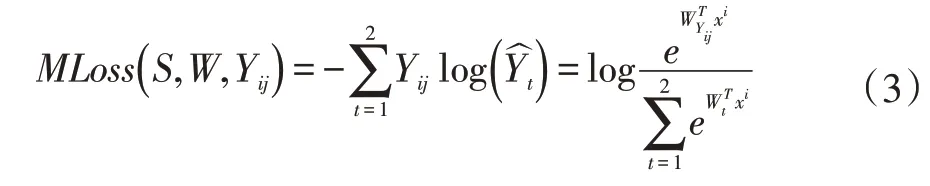
其中,S 是样本对xi和xj在模型中的输出特征向量之间的距离向量S2表示预测的概率,Wt是第t类的输出权重,即t=1,2。Yij是样本对的真实值为相似或不相似。
3.3 总损失函数
将分类损失函数和度量损失函数加权和,双通道车型识别模型的总目标函数如公式(4)所示:

其中,α>0 是权重超参数,根据样本对的输入策略来调节。由于双通道模型的两个输出是共享权重的,所以让两个分类损失函数Softmax 的权重比例为1:1。
4 实验与结果
4.1 数据集
(1)CompCars 数据集
CompCars 数据集是用于细粒度分类的大规模车辆数据集,它包括互联网场景性质和监控场景性质下的车辆图片。监控场景下的车辆图像与卡口车型识别数据非常相似,因此我们只选用监控场景下的车辆图片。该场景下的数据集一共有44481 张图片,分辨率约是800×800,按车型系列分类,一共有281 类,例如:数据库里的一汽轿车如图2 所示。

图2 CompCars数据集中部分一汽轿车样本
(2)卡口场景下自建的车型识别数据集
针对智能卡口场景,选取了卡口常见的50 类车型系列来验证算法的有效性,包括大众-宝来、大众-高尔夫、奥迪-A3、日产-轩逸、日产-天籁等车型系列,记为CarSeries。如图3 所示,每个车型系列大约有200 个样本,样本的分辨率约为600×600,样本主要是在白天不同光照条件下和黑夜环境下采集的。

图3 CarSeries中部分车型系列样本
4.2 实验方案
实验一:为了确定一个适合公开车型识别数据集CompCars 的模型容量,分别对ResNet10、ResNet14、ResNet18、ResNet34 和ResNet50 模型进行训练,从模型复杂程度、预测推断时间和准确率三个方面来选择合适层数的ResNet 模型作为实验的骨架网络。

表1 ResNet10、ResNet14、ResNet18、ResNet34 和ResNet50的结构细节
在ResNet18、ResNet34、ResNet50 的基础上设计了ResNet10 和ResNet14,ResNet10 是在ResNet18 的基础上把卷积层的层数缩减了一半,ResNet14 是在ResNet50 的基础上把每层的block 的重复次数都改为1。 ResNet10、ResNet14、ResNet18、ResNet34 和ResNet50 的结构细节如表1 所示。ResNet10、ResNet18、ResNet34 采 用 的 是 Basicblock 结 构。ResNet14 和ResNet50 采用的是Bottleneck 结构,主要区别是引入1×1 卷积,作用是:①对通道数进行升维和降维(跨通道信息整合),实现了多个特征图的线性组合,同时保持了原有的特征图大小;②相比于其他尺寸的卷积核,可以极大地降低运算复杂度。
实验基本设置如下:数据集与验证集的划分比例是4:1;图片全部resize 到150×150,然后像素值缩放到0 到1 也就是除以255;权重随机初始化;batch 大小设置为32;使用Adam 优化器;epochs 设置为30,保存模型和绘制准确率和损失曲线图。
实验二:为了验证所提出的基于分类学习和度量学习的多任务学习算法的有效性,将设置如下的实验组作为比对:①标准的单通道分类网络,使用分类损失函数Softmax,权重随机初始化,记为OneNet_Random。②标准的单通道分类网络,使用分类损失函数Softmax,加载在数据集CompCars 训练好的模型权重,记为OneNet_PreTrain;③双通道分类网络,结合分类损失函数和度量损失函数,加载在数据集CompCars 训练好的模型权重,记为DoubleNet。
实验基本设置如下:数据集与验证集的划分比例是4:1;图片全部resize 到150×150,然后像素值缩放到0 到1 间,也就是除以255;batch 大小设置为64;模型收敛的判断标准是:当2 个epochs 内验证损失函数不再下降,学习率降低为原来的1/10,当3 个epochs 内,验证损失函数不再下降,提前终止训练,保存模型和绘制准确率和损失曲线图。
训练过程:首先,选择实验一的ResNet 作为骨架网络,使用实验一中的设置在数据集CompCars 训练,直到收敛,保存模型作为下面实验的预训练模型。
(1)OneNet_Random 单通道模型:
权重随机初始化,使用Adam 优化器,在数据集CarSeries 上训练,直到收敛。
(2)OneNet_PreTrain 单通道模型:
①加载ResNet 预训练模型,然后修改全连接层fc的输出类别,这时fc 层是随机初始化的,所以,冻结除全连接层fc 外的所有层,使用Adam 优化器,在卡口车型数据集CarSeries 上训练,收敛则停止训练。
②解冻ResNet 模型的最后两个block,进行微调,使用SGD 优化器,学习率设置为0.001,动量设置为0.9,继续训练,直到收敛。
(3)DoubleNet 双通道模型:
①加载ResNet 预训练模型,把一个全连接层改为两个全连接层fc1、fc2 输出,这时fc1、fc2 层是随机初始化的。冻结所有层,损失函数权重设置为1:1:0.5,也就是使用分类损失函数和度量损失函数的加权和,训练多分类和二分类模型,使用Adam 优化器,在卡口车型数据集CarSeries 上训练,收敛则停止训练。
②解冻ResNet 模型的最后两个block,进行微调,使用SGD 优化器,学习率设置为0.001,动量设置为0.9,损失函数权重设置为1:1:0.5,继续训练,直到收敛。
实验三:为了验证所提出算法的有效性,与已有文献算法进行比较。文献[13]改进模型结构,结合Inception 模块和ResNet 结构作为基本模块,使用全局平均代替全连接层,同时引入中心损失函数来进行车型识别,记为BRSC。文献[10]基于多任务学习进行多属性识别,通改进AlexNet 模型,修改全连接层,实现车辆多属性(车型系列、车辆类型和车辆颜色)识别,记为Multi-BestNet。
实验基本设置与实验二一致,训练过程如下所示。
(1)BRSC 的训练过程:
①首先,在数据集CompCars 训练直到收敛。
②然后修改全连接层fc 的输出类别,冻结除全连接层fc 外的所有层,使用Adam 优化器,在卡口车型数据集CarSeries 上训练,收敛则停止训练。
③解冻模型的最后两个Inception block,进行微调,使用SGD 优化器,学习率设置为0.001,动量设置为0.9,继续训练,直到收敛。
(2)Multi-BestNet 的训练过程:
①首先,在数据集CompCars 训练直到收敛。
②然后把一个全连接层改为三个全连接层fc1、fc2、fc3 输出,这时fc1、fc2、fc3 层是随机初始化的,因此,除fc1、fc2、fc3 外,冻结所有层,损失函数权重设置为1:1 训练,收敛则停止训练。
③解冻模型最后3 个卷积层,进行微调,使用SGD优化器,学习率设置为0.001,动量设置为0.9,损失函数权重设置为1:1:1,继续训练直到收敛。
4.3 结果分析
(1)评价指标:使用准确率来评估模型的性能,定义为:对于给定的测试数据集,分类正确的样本个数占总样本个数的比例。公式如(5)所示:

其中,ncorrect为被正确分类的样本个数,ntotal为测试数据集中的总样本个数。
(2)实 验 一:ResNet10、ResNet14、ResNet18、ResNet34 和ResNet50 在数据集CompCars 上的准确率曲线图和识别性能分别如图4 和表1 所示。
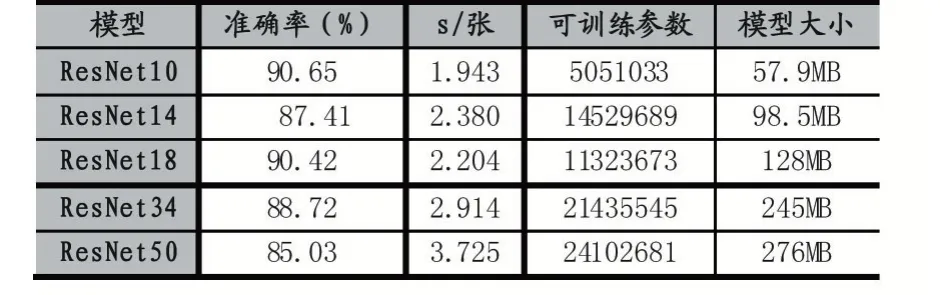
表2 不同层数的ResNet 模型在CompCars 上的识别和性能结果
分析表2 和图4 可知,得益于残差模块的特点,不同层数ResNet 模型都有较高的识别准确率,但是ResNet14、ResNet34 和ResNet50 在小数据集上准确率有小幅度的下降,说明模型的可学习参数过多,学习到额外的噪声,模型的泛化能力下降。ResNet10 和ResNet18 的模型拟合能力都很好,在保持准确率的前提下,为了节省存储空间和加快预测推断速度,选择ResNet10 作为实验二的骨干网络。
(3)实验二:OneNet_Random、OneNet_PreTrain 和DoubleNet 的识别精度和准确率曲线图分别如图5 和表2 所示。
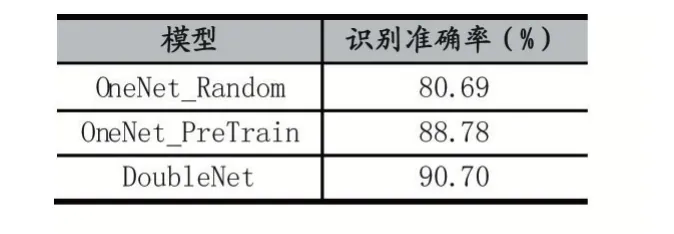
表3 不同网络设计在CarSeries 上的识别精度
分 析 表 3 可 知,对 比 OneNet_Random 和OneNet_PreTrain 可知,使用相似数据集上预训练的模型,通过微调,可将其中可用的知识迁移出来,从而在卡口车型数据集较小的时候,能大幅度提高车型识别的准确率,提升了近8%。对比OneNet_PreTrain 和DoubleNet 的可知,显然度量损失函数可以帮助提高Softmax 分类的效果,特别是在样本数据比较少的时候,提升了近2%。分析图5 的图可知,由于OneNet_Random 的权重是随机初始化的,训练准确率随着时间线性增加,而验证准确率在第15 个epoch 时就开始达到最大值,开始上下波动,这也就意味数量小非常容易产生过拟合现象。对比OneNet_PreTrain 和DoubleNet 的准确率曲线可知,DoubleNet 的曲线波动比较平缓,而且准确率提升更高,说明度量损失函数可以帮助模型学习到更加泛化的特征。

图5 不同网络设计在CarSeries上的准确率曲线图
(4)实验三:BRSC、Multi-BestNet 和DoubleNet 的识别精度如表4 所示。
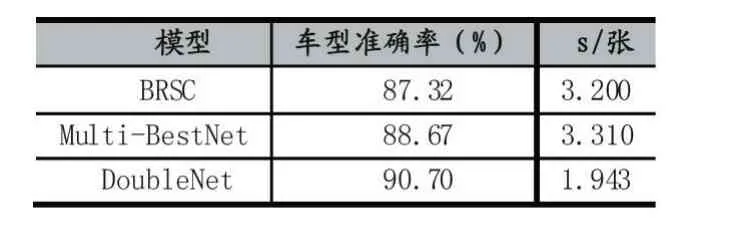
表4 BRSC、Multi-BestNet 和DoubleNet 在CarSeries 上的识别精度
对比BRSC 和DoubleNet 可知,Inception 模块和ResNet 模块都是非常优良的子模块,车型识别的准确率都非常高,但BRSC 的网络层数较深,网络推断速度较慢。对比Multi-BestNet 和DoubleNet 可知,基于多任务学习进行多属性识别的算法能有效提高车型识别的准确率,但是Multi-BestNet 需要额外的标注信息,在现实应用中,往往很难平衡不同子任务之间的样本数量,导致出现样本不均衡的情况,另外,骨干网络使用的是AlexNet,过多的全连接层导致模型较大,推断速度较慢,而且训练时比较难收敛到最优。从表4 中可以看出,DoubleNet 的车型识别准确率最高,并且在模型推断速度上优于BRSC 和Multi-BestNet。
5 结语
本文提出在小数据集下设计车型识别算法的思路和具体的方法。从数据扩充、迁移学习策略缓和了数据量少的问题,同时,基于多任务学习的思想,结合分类学习和度量学习充分挖掘标签和标签之间的监督信息,进一步约束参数的学习。实验证明,在数据扩充策略和模型结构一致的情况下,对比有的文献算法,提高车型识别的识别精度,能取得较好的效果。
猜你喜欢
今日农业(2022年15期)2022-09-20
昆明医科大学学报(2021年4期)2021-07-23
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
就业与保障(2021年23期)2021-04-06
健康体检与管理(2021年10期)2021-01-03
小天使·二年级语数英综合(2019年10期)2019-11-08
电脑爱好者(2015年22期)2015-09-10
读者·校园版(2015年19期)2015-05-14
