
基于双层随机森林算法的短期负荷预测模型
2019-10-10 06:55邢书豪高广玲张智晟
广东电力 2019年9期
邢书豪,高广玲,张智晟
(1.青岛大学 电气工程学院,山东 青岛 266071;2.国网技术学院,山东 济南 250000)
准确的电力系统短期负荷预测是电力系统制订发电计划的基础,也是系统安全稳定运行的保障,一直以来都是电力系统研究的重要方向[1]。为了提高预测精度,国内外专家提出了诸多预测方法,包括人工神经网络[2]、数据挖掘法[3]、小波分析法[4]、混沌理论[5]、支持向量机[6]等。人工神经网络计算简单、非映射性强,但网络收敛速度慢,易陷于局部极值点[7];数据挖掘法的预测值可以体现负荷变化的连续性,而且算法运算速度较快,但在进行负荷预测时没有考虑到影响因素,预测误差较大[8];小波分析法是一种时域-频域分析算法,可以良好地处理敏感奇异信号以及突变信号,其不足之处在于仅考虑了负荷序列的变化,忽略了天气等因素对负荷的影响[9];基于混沌理论的电力系统负荷预测方法可以较好地刻画负荷物理属性和影响因素,然而模型存在过拟合现象且泛化能力不足[10];支持向量机采用结构最小化风险原则,可以避免局部最优解,具有较好的泛化能力,但在参数选择上较为困难,核函数的确定仅凭经验选取,预测精度与速度难以进一步提高[11]。
随机森林算法是基于传统决策树的统计学习理论,它可有效处理高维数据,具有较高的预测准确率,克服了过拟合的问题,现已被广泛应用于医学、农学、经济学、水文科学、生物信息等领域[12]。黄青平等[13]将模糊聚类技术与随机森林算法结合起来,利用模糊聚类技术选取相似日后,以相似度高的样本训练随机森林预测模型,提高了预测精度;刘琪琛等[14]提出了Spark平台和并行随机森林回归算法的短期电力负荷预测方法,利用Spark分布式运算平台,通过3次弹性分布式数据集转换,实现了随机森林算法的并行化改进,改进模型鲁棒性好且预测准确性高;刘达等[15]利用集合经验模态分解算法对输入变量进行分解,再对各种分量用随机森林算法选取最优参数进行建模,该模型对月度负荷预测精度优于单独随机森林预测模型。以上研究成果均是对单层随机森林算法进行的改进与组合,并且研究发现单层随机森林算法不能充分读取样本中的有效信息,影响预测性能。基于此,本文使用双层随机森林算法,该算法除了具有单层随机森林算法的优点之外,对含缺失值或者噪声的数据有更好的鲁棒性,而且可以深度分析复杂的特征变量,从而更加充分挖掘数据中的有效信息。在算法中,将第1层随机森林中的训练残差加入原始训练样本中构建新的训练样本去训练第2层随机森林,可以更准确地提取并利用历史样本中的有效信息,从而得到更精确的预测结果。最后通过算例分析,对本文所提出的基于双层随机森林算法的预测精度和稳定性进行验证。
1 随机森林算法
随机森林算法在2001年被L.Breiman等人提出[16]。该算法实际上是一个包含一系列决策树分类器h(x,θk),k=1,2,…,n的集合,其中θk表示独立且相同分布的随机变量,集合中每个决策树分类器都对输入变量x的类别归属进行预测。随机森林算法较强的随机性主要体现在2个方面[17]:一方面,训练样本集是由从原始样本集中采用有放回的方式随机选取样本数据组成的;另一方面,生成决策树时随机选取特征属性构成候选分裂特征。
在算法中,随机森林通过Bagging(bootstrap aggregating)方法抽样,生成彼此之间互不相同的训练样本集,采用CART决策树作为元分类器组合为集成分类器,预测结果由所有分类器求算数平均值所得[18]。
1.1 Bagging方法取样
Bagging方法的每个样本都由初始数据集进行有放回抽样得到,是一种以可重复的随机抽样为基础的抽样方法。该方法利用Bootstrap重抽样,从原始样本集中随机抽选n个训练样本(d1,d2,…,dn),并将该过程进行ntree次循环,从而得到ntree个训练集[19]。在生成训练子集时,虽然每个训练样本都有可能被抽取,但当多次重复训练时,总会有一部分样本未被抽取,样本不被抽取的概率
(1)
式中:n为初始数据中的样本总数,当n足够大时,式(1)将收敛于1/e≈0.368,这表明样本数据足够大时将有约37%的样本不会被抽中。
图1为Bootstrap重抽样示意图。
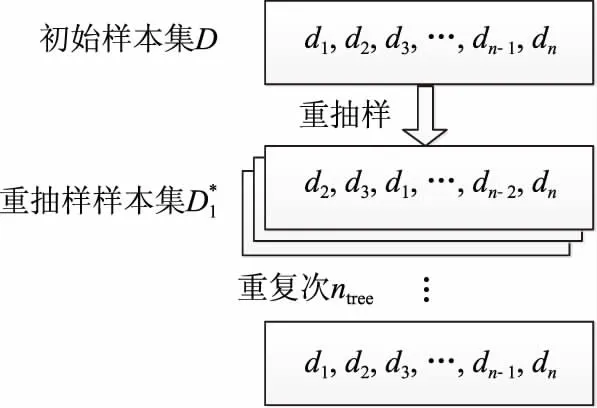
图1 Bootstrap重抽样示意图Fig.1 Schematic diagram of Bootstrap resampling
1.2 CART决策树
CART决策树算法是利用二分递归分割方法[20],把原样本集划分为2个子集,从而会有2个分支在每个非叶子节点上。在节点分裂的时候,分裂规则按照Gini指标最小原则,概率分布的Gini指数
(2)
式中:K为节点中特征样本的总种类数;pk为属于节点中第k类特征样本的概率。
样本集合D的Gini指数
(3)
式中Ck为样本集合D中属于第k类的样本子集。
每个节点划分的Gini指数
(4)
式中D1和D2为样本集合D分割成的2个子集。
1.3 随机森林的构成
设随机森林由一系列CART决策树h(x,θk),k=1,2,…,n构成,其边缘函数可表征为
K(X,Y)=

(5)
式中:X为输入向量,最多包含J种不同的类别;j为J种类别中的某一类;Y为正确的分类向量;I(·)为指示函数;ak为求取平均值的函数。
随机森林的泛化误差
Pe=PX,Y(K(X,Y)<0).
(6)
式中PX,Y为对给定输入变量X的分类错误率函数。
随机森林的泛化误差最大值
(7)
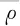
随机森林的泛化误差最大值越小,随机森林的泛化性能越好。式(7)表明,随机森林的泛化误差最大值与决策树的平均相关系数呈正相关,与决策树的平均强度呈负相关,可以通过减小决策树的平均相关系数和增强决策树的平均强度实现随机森林预测精度的提高。
随机森林结构如图2所示。

图2 随机森林结构Fig.2 Random forest structure
2 基于双层随机森林算法的电力系统短期负荷预测模型
由统计学习理论可知,每个算法都有其对应的某类假设空间,但一般单次使用某一算法只能读取该空间内的部分有效信息,影响预测性能。因此考虑在同一空间内重复使用该算法,多次读取使空间内的有效信息得到充分利用,比单次使用该算法预测时的泛化性能更佳,达到更高的预测精度。随机森林本身具有自主设定参数少、不会出现过拟合现象等优点[21],第1层随机森林的训练残差经过处理后代入原始训练样本组建新训练样本训练第2层随机森林,可以更准确地提取训练数据中所包含的有效信息,得到训练速度快且精度高的双层随机森林预测模型。


表1 模型各阶段输入输出Tab.1 Input and output in each stage of the model
模型的具体步骤可描述如下:
a)将数据进行归一化处理,模型参数进行初始化处理;
b)从原始训练集中采用Bootstrap方法随机有放回采样选出n个样本,共进行ntree次采样,生成ntree个样本集,即构建ntree棵决策树;
c)对于单棵决策树模型,假设有M个特征,随机选取m(m≤M)个特征作为每个节点的分裂特征值,计算每个特征的信息量,选择具有最优分裂能力的特征进行分裂;
d)每棵决策树都一直分裂至叶子节点,决策树的分裂过程不需要剪枝;
e)将生成的ntree棵决策树组成第1层随机森林,由ntree棵决策树预测值取平均值即为第1层随机森林模型的预测结果;
h)按照步骤b—e建立第2层随机森林模型,得到第2层随机森林模型的预测结果;
i)第1层随机森林模型与第2层随机森林模型的输出依次叠加,即可得到双层随机森林预测模型的最终输出。
整个模型的流程如图3所示。
3 算例分析
3.1 数据集及数据处理
本文采用某城市电网的历史负荷数据,因负荷受温度等外因因素影响,故模型输入数据包括每日96点(每15 min取1点)负荷值[23]以及日最高温度、日最低温度、日平均温度、日降水概率、日类型和天气状况共6类外因数据。因各类数据量纲不同,将原数据不作处理直接代入模型,可能降低某类数据的重要性,故需对输入数据进行合理量化,使量化后的数据可以更准确地表示其对预测的影响程度。
对负荷和温度数据进行归一化处理[24],使处理后的数据在[0,1]之间,负荷数据和温度数据归一化公式可表征为
(8)
式中:lin为原始输入数据;lmin为原始输入数据中同类数据的最小值;lmax为原始输入数据中同类数据的最大值;l为归一化处理之后的输入数据。
日降水概率取值区间为[0,1]。日类型分为工作日(周一至周五)和休息日(周六和周日),工作日影响因子取值为1,休息日影响因子取值为0.5。天气状况分3种情况,晴天影响因子取值为1,阴天、多云或者雾类天气状况影响因子取值为0.5,雨雪或者其他恶劣天气影响因子取值为0。
本文所用模型为双层随机森林模型,第1层随机森林的训练残差构成第2层随机森林的训练数据集,因训练残差数值太小,故训练残差也需经式(8)进行归一化处理,归一化处理后组成第2层随机森林的训练数据集。
电力系统短期负荷预测的预测性能评价指标有很多[25],本文采用相对误差绝对值的平均值EMAPE和最大相对误差EMAX来讨论预测精度。
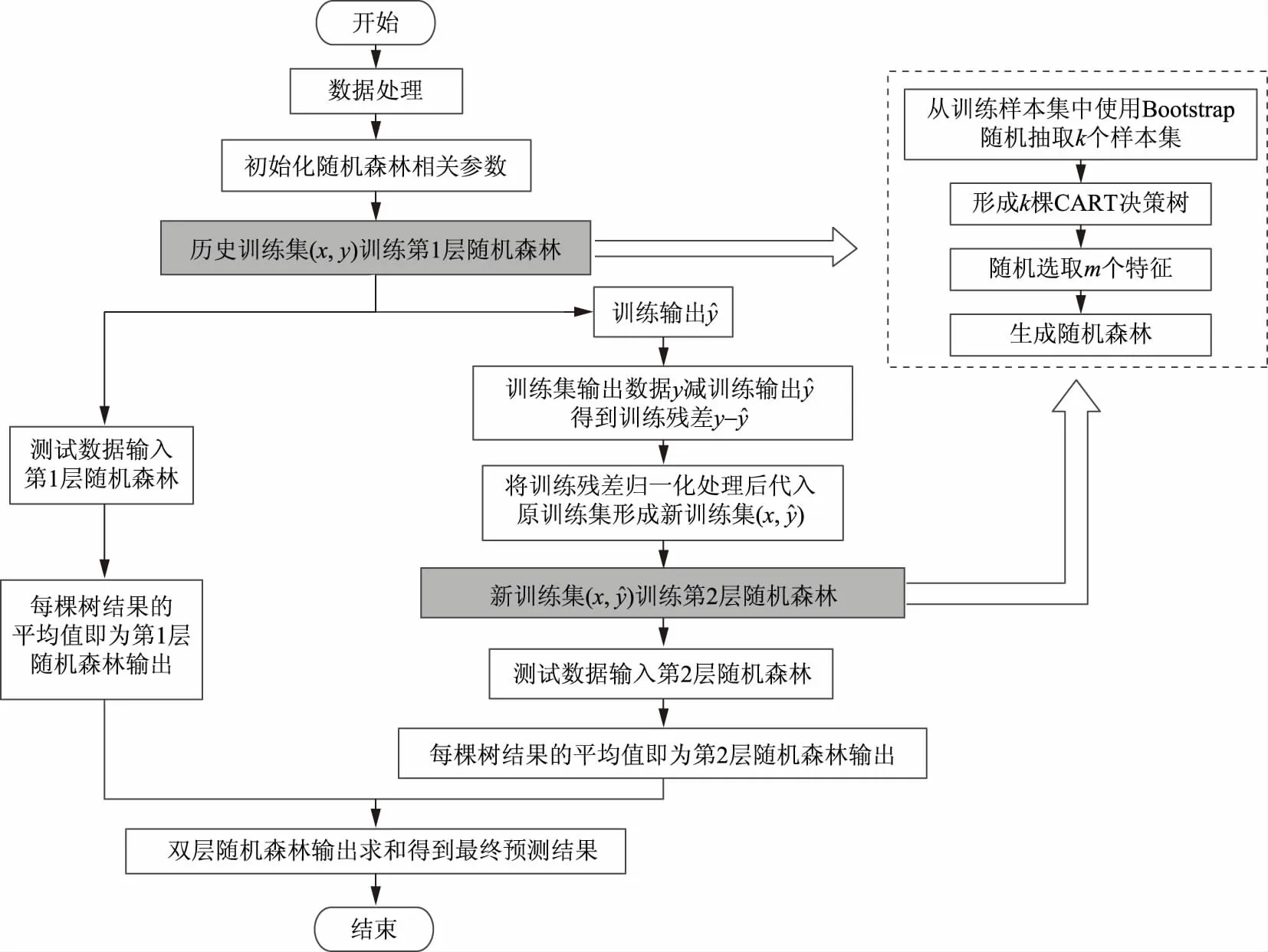
图3 模型预测流程Fig.3 Prediction process of the model
(9)
式中:Yk为第k个采样点的实际负荷值;yk为预测负荷值;n为采样点个数。EMAPE越小,表明预测精度越高。
本文采用预测日前3 d数据对预测日96个点的负荷进行预测,预测k时刻负荷值时输入向量如图4所示。图4中,d为日期序号,Ld,k为第d日第k个采样点的负荷值,Td,max、Td,min、Td,ave分别为第d日的日最高、最低、平均温度,rd、dd、wd分别为第d日的降水概率、日类型、天气状况。

图4 模型输入向量Fig.4 Input vector of the model
模型输入向量为33维,包括负荷数据9维,外因因素24维。模型输出向量为1维,即预测日第k个采样点负荷值[26]。
3.2 算例结果分析
基于双层随机森林算法的预测模型(M1)的主要参数设置如下:随机森林中的决策树数量取1 000,分裂特征数取11。基于单层随机森林算法的预测模型(M2)数据处理和参数设置与模型M1一致。为了验证模型M1的预测性能,将2种模型预测效果作比较。因为工作日和休息日负荷模式差别较大,故分别选取某一工作日和某一休息日为测试日[27],经算例仿真可得2种模型预测值与实际值曲线对比图,如图5和图6所示。
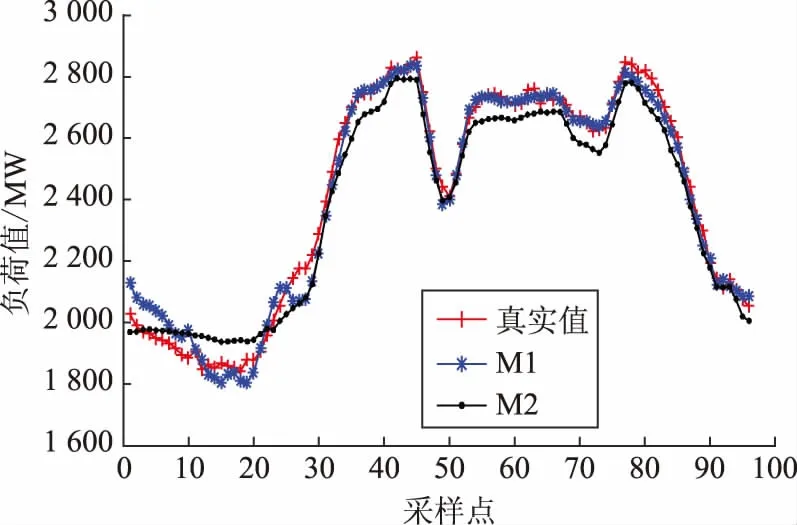
图5 工作日2种预测模型预测值与实际值曲线对比Fig.5 Curves of predicted value and actual value of two forecasting models on working days
在工作日中:M1预测曲线的EMAPE为1.47%,EMAX为5.14%;M2预测曲线的EMAPE为2.61%,EMAX为5.83%。模型M1预测曲线在总体上与实际值曲线拟合度更高。
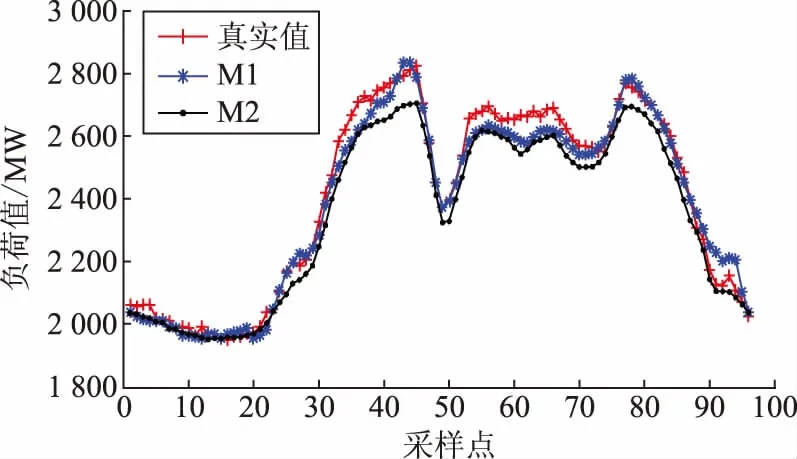
图6 休息日2种预测模型预测值与实际值曲线对比Fig.6 Curves of predicted value and actual value of two forecasting models on rest day
在休息日中:M1预测曲线的EMAPE为1.72%,EMAX为5.54%;M2预测曲线的EMAPE为2.84%,EMAX为6.29%。
相比于基于单层随机森林算法的预测模型,本文所提出的模型EMAPE在工作日和休息日分别降低了1.14%和1.12%,EMAX分别降低了0.69%和0.75%。
为了进一步验证本文所提模型预测的稳定性,对该地区一周内的负荷进行预测,预测结果的EMAPE和EMAX见表2。
与基于单层随机森林算法预测模型相比,本文所提出的基于双层随机森林算法预测模型一周EMAX略低,EMAPE有明显下降。其中周六的预测效果较差,原因是连续工作日期间用电情况更加规律且与休息日差别显著。综上所述,本文所提模型预测准确性高,误差波动较小,具有较好的预测精度和稳定性。
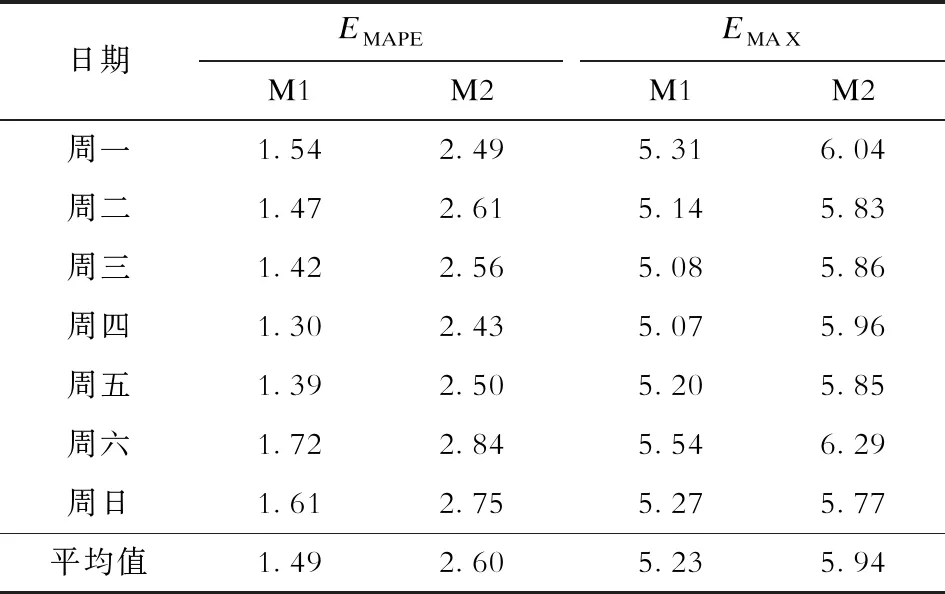
表2 2种模型预测误差统计Tab.2 Statistics of prediction errors of two models %
4 结束语
本文提出了基于双层随机森林算法的电力系统短期负荷预测模型。该模型是一种双层随机森林模型,将第1层随机森林模型中的训练残差处理后作为第2层随机森林模型的训练期望输出,从而再次读取假设空间中存在的信息,可以更加充分地利用训练数据中的有效信息,提高了模型的预测精度。通过与基于单层随机森林算法的模型对比,验证了本文所提出的模型具有更好的预测性能。
猜你喜欢
河北理科教学研究(2021年3期)2022-01-18
长江大学学报(自科版)(2021年6期)2021-02-16
现代装饰(2019年11期)2019-12-20
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
动漫界·幼教365(小班)(2018年3期)2018-05-14
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
东北电力技术(2016年2期)2016-05-17
中国化肥信息(2016年35期)2016-05-17
舰船科学技术(2016年1期)2016-02-27
