
多源异构数据融合的电力变压器状态评价方法
2019-10-10 07:05:56蒋逸雯彭明洋马凯李黎
广东电力 2019年9期
蒋逸雯,彭明洋,马凯,李黎
(1.华中科技大学 电气与电子工程学院,湖北 武汉 430074;2. 广东电网有限责任公司电力科学研究院,广东 广州 510080)
随着“数字南网”的提出与建设,南方电网正在向数字化转型,目标为基于大数据、人工智能等先进的数字化应用技术,对南网系统内的海量数据进行分析、学习、计算,通过应用系统自动决策与自动执行[1-2]。结构化数据由明确定义、易于检索的数据类型组成,非结构化数据通常由定义模糊、不易检索的文本、视频等格式的信息组成[3]。其中,电力变压器缺陷记录文本包含丰富的故障信息,是对变压器数字化运检数据的重要补充。然而,由于其数据类型为描述性文字,属于非结构化数据,难以依靠常规的数据分析方法进行处理,尚未得到有效的信息挖掘,因此变压器的运行状态评价仅能依靠结构化的数字化运检数据。运检、运行维护记录文本的数据信息提取(即文本挖掘)对进一步改进输变电设备的智能运检工作具有重要的意义。
在先前的文本挖掘研究中,Rudin等通过文字描述的电缆故障记录,利用信息检索结合支持向量机的方法预测电缆本体和附件出现绝缘击穿故障的风险[4];Zheng等搜集历史上变电站发生故障的事件记录,结合当时的天气信息,用朴素贝叶斯方法进行变电站故障与恶劣天气的关联性预测,以评估变电站设备绝缘配合设计的科学性[5]。但是目前大多数方法都是基于传统机器学习模型的浅层架构,在解决复杂问题时,学习能力和泛化能力都会受到限制。随着更深层次训练模型的完善,深度学习的概念被提出,且已经被用于文本记录的信息挖掘。Sutskever等提出具有多层长短时记忆(long short-term memory, LSTM)的机器翻译框架[6];Liwicki等运用LSTM网络识别手写数字[7];Socher等利用循环神经网络(recurrent neural network, RNN)进行句法分析[8]。随着逐层学习和参数微调技术的出现,卷积神经网络算法(convolutional neural network, CNN)获得了快速发展,在句子建模[9]、语义分析[10]和搜索查询[11]方面取得了较大的成果。针对不同文本记录内容的数据集,学者们还提出了一些改进的模型架构,有更少的训练耗时和更优的分类效果,譬如CNN-LSTM、RNN-LSTM[12]和动态记忆网络[13]。近两年来,杜修明和刘梓权分别利用LSTM和CNN,对电网设备故障案例及缺陷记录文本进行信息挖掘,实现了缺陷因果特征的自动提取及故障类别的自动判别[14-17]。然而,这些文献都是单独对文本记录信息进行分类研究,尚未与数字类型的结构化数据相结合,提出综合设备评价方法。
有鉴于此,本文基于电力变压器缺陷记录文本的特点,采取逐层学习和参数微调措施,建立深度学习模型,自动辨识缺陷文本记录信息所反映的设备缺陷情况。以交流220 kV主变压器(以下简称“主变”)油浸式变压器作为研究对象,将源于缺陷记录的非结构化文本与源于在线监测和常规例行试验的结构化数据相结合,提出了基于多源异构数据融合的变压器运行状态评价的新思路,旨在实现不同信息结构间的数据流转及数据共享。
1 电力变压器非结构化缺陷记录
1.1 缺陷记录的内容
在电力变压器的日常运行和维护过程中,缺陷信息由巡检人员记录,并被输入至生产管理系统。输入内容包括设备类型、投运年份、电压等级、缺陷描述、缺陷位置、缺陷原因、备注等。缺陷记录中包含一些相似的语义关系,模糊性较强的语义可能无法被准确辨识及理解。因此,有必要深度分析缺陷记录的语义。
为简单起见,本文不对变压器的故障类型进行判断,而是根据电力部门运行维护实际情况,对设备运行维护检修发现的缺陷类型进行分类判断,据此为运行维护检修策略提供必要依据。本文假定缺陷记录的分类等级可按缺陷严重程度,分为一般、严重和危急3类[18],见表1。

表1 分类等级及对应的现象描述Tab.1 Classification grades and phenomenal description
1.2 缺陷记录的文本特征
不同于普通文本,电力变压器的缺陷记录文本有3个显著的特征:①文本专业性强,包含各种电气术语。由于专业术语未囊括至文本分词软件的语料库内,无法被正确识别,因此无法正确划分语句。②记录的文字中掺杂着数字与单位。例如,在短文本“减压阀漏油,1 min 15~20滴”中,数字1、15、20起着重要作用。③文本的长度不同,且语法可能不符合规范。这是因为缺陷文本是由人工记录并上报或输入的,不同巡检人员的语言组织能力和逻辑思维方式有差异。因此,传统信息提取中的关键技术,如命名实体识别和句法分析,不能很好地应用于缺陷文本中。
1.3 文本的预处理流程
对于已获得的原始文本数据,为了便于计算机识别并理解,首先需将其转换为数字形式,这是文本预处理阶段。它由3部分组成,即文本分词、删除停用词和生成词向量。
1.3.1 文本分词
分词是指将一段汉字语句切分成一个个单独的词。英文文本很容易根据自带的空格划分为一个个单词。但是,中文段落间没有空格,因此对其进行正确的分词是中文文本处理的必要步骤。
Python语言中的jieba分词组件是基于概率语言建模的中文分词工具,它使用动态编程来查找概率最大的分词路径。重要的是,对于未包含在软件语料库中的单词,jieba支持通过调用函数jieba.load_userdict来导入自定义词典。 因此,为了提高分词准确率,本文总结电力变压器的专业术语,并将它们导入至jieba语料库中。
1.3.2 删除停用词
停用词是指在信息检索中,为节省存储空间和提高检索效率,在处理自然语言数据信息之前或之后,自动过滤掉某些字或词,这些字或词被称为停用词。为了减少文本冗余,在文本分词之后需要去除不能表示设备运行状态的词语。因此,文本预处理的第2阶段是建立一个停用词词典,并将其导入到“删除停用词”阶段。
1.3.3 生成词向量
该阶段是为了将以自然语言表达的单词转换为计算机可以理解的词向量。由Mikolov等人提出的工具Word2Vec,可以处理不同长度的序列,且将非结构化文本转换为结构化的词向量形式[19]。词向量的每个维度代表语义特征,一个句子可表示为N×M的矩阵。其中N为句子中的单词数,M为词向量的维度数。将部分缺陷文本的三维词向量进行展示(如图1所示),图中数值源自Word2Vec的输出。

图1 特征空间中的词向量表示Fig.1 Wordvector representation in the feature space
图1中,X、Y和Z轴分别代表向量的3个维度。语义相近的词向量的坐标点较为相近,即在特征空间中相距较近,语义差异较大的词向量在特征空间中相距较远,故词向量的余弦距离可表示语义相似度。在实际应用中,可指定词向量的维度,通常取值为100。
2 融合多源异构数据的评价模型
2.1 文本挖掘模型
双向LSTM (bi-LSTM,Bi-LSTM) 不仅可以提高RNN中网络权重训练的效率,确保语义学习的稳健性,还可以获取文本序列中的上下文信息。在LSTM中引入注意力机制可更有效地获取关键词信息,故本文构建了基于注意力机制的Bi-LSTM文本挖掘模型。
2.1.1 长短时记忆网络(LSTM)
RNN是自然语言处理领域的主流架构,其可以处理任意长度的序列并捕获长期性的依赖关系[20]。 LSTM是RNN的优化架构,它解决了RNN训练时常见的梯度消失和梯度爆炸问题。但是单向LSTM 的缺点是无法获得本单元之后的单元信息,为了获取单元前后的所有信息,Bi-LSTM神经网络应运而生。图2显示了单向LSTM中的单元结构。
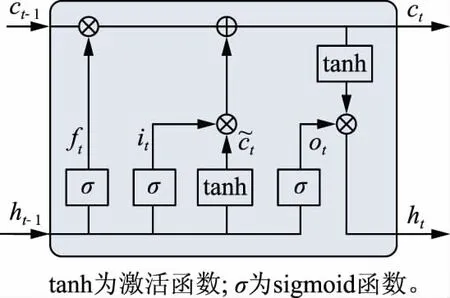
图2 LSTM的单元结构Fig.2 Unit structure in LSTM
在时刻t,LSTM的输入包括:时刻t的文本序列输入xt,时刻t-1时的LSTM输出ht-1,时刻t-1时的LSTM单元状态ct-1。在时刻t,LSTM的输出包括:时刻t的LSTM输出ht和时刻t的单元状态ct。 LSTM利用遗忘门、输入门、输出门保护和控制信息。计算原理如式(1)—(3)所示:
ft=σ(Wf·ht-1+Wf·xt+bf).
(1)
it=σ(Wi·ht-1+Wi·xt+bi) .
(2)
ot=σ(Wo·ht-1+Wo·xt+bo).
(3)
式(1)—(3)中:ft,it,ot分别是遗忘门、输入门、输出门时刻t的输出;Wf,Wi,Wo分别是遗忘门、输入门、输出门的权重矩阵;bf,bi,bo分别是遗忘门、输入门、输出门的偏置矩阵。LSTM的最终输出由输出门和单元状态决定,即:
(4)
(5)
ht=ot∘tanh(ct).
(6)
2.1.2 注意力机制
LSTM是典型的编码器-解码器模型,无论输入长度如何,输入序列都被编码为具有固定长度的矢量表示。在解码过程中,每个时刻的输出是相同的,且互相之间没有区别。因此,引入了注意力机制。
注意力机制基于一个模拟人类大脑注意力的模型。它具有人脑的特征,在特定时刻注意力可集中于特定点而忽略其他部分。因此,可选择性记忆重要单词。图3为常见的编码器-解码器框架。
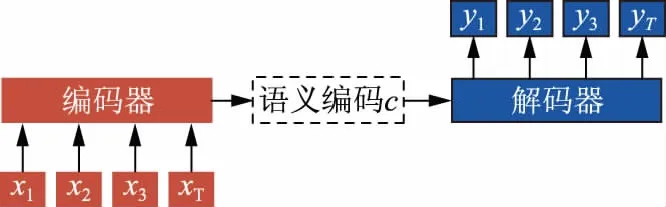
图3 常见的编码器-解码器框架Fig.3 Common encoder-decoder framework
图3中,编码器将输入的词向量x=(x1,x2,…,xT)转换为语义编码c,T是输入序列的数量,故可得到式(7)—(8),即:
ht=f(xt,ht-1).
(7)
c=q(h1,h2,…,hT).
(8)
式(7)—(8)中f和q是非线性函数。然后,解码器通过语言模型解码产生新序列:
(9)
p(yt|y1,y2,…,yt-1,c)=r(yt-1,st,c).
(10)
式(9)—(10)中:y预测结果;yt是时刻t的预测结果;r是非线性函数,其可能是多层的;st是模型时刻t的隐藏状态。
式(9)—(10)说明,在预测每个时刻的输出时,所使用的上下文向量是相同的。然而,理想的预测结果应与不同时刻的输入向量有关,如式(11)—(12)所示。因此,引入了注意力机制,如图4所示。
p(yt|y1,y2,…,yt-1,c)=r(yt-1,st,ct).
(11)
st=f(st-1,yt-1,ct).
(12)
ct是注意力机制的关键部分,它可以将输出与对应输入互相连接,即
(13)

(14)
et,j=a(st-1,hj).
(15)
实际上,注意力模型是嵌入Bi-LSTM中的前馈神经网络,一起进行训练过程并调节参数。此外,在几层Bi-LSTM之后,连接的是softmax层,softmax层对输入数据进行归一化分类,将表1的缺陷程度分为3类假定,输出缺陷记录文本隶属于“一般”、“严重”、“危急”等级的概率分别为p1(L1)、p1(L2)、p1(L3)。
2.1.3 评估指标
本文的问题是有3种分类等级的,分别为“一般缺陷”,“严重缺陷”和“危急缺陷”,属于三分类问题(分类类别n=3),其常用的评估指标为macro-P宏查准率(用Amacro-P表示)、macro-R宏查全率(用Amacro-R表示)、macro-F1宏综合指标(用Amacro-F1表示)。表达式为:

图4 基于注意力机制的双向LSTM模型Fig.4 Bidirectional LSTM model based on attention mechanism
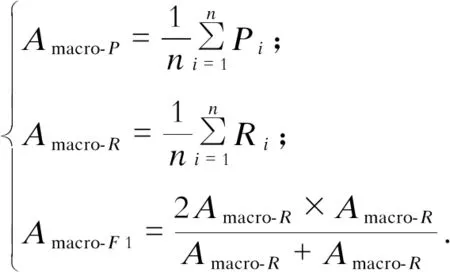
(16)
式中:查准率P、查全率R为二分类的评估指标。对于二分类问题,P、R的值是唯一的;对于三分类问题,对应3种不同的正例,P、R的值有3种。P、R的定义见表2及式(17)。

表2 二分类的混淆矩阵Tab.2 Confusion matrix of binary classification
表2中:PT(真正例) 代表正例被正确判断为正例的数目;NF(假反例) 表示正例被错误判断为反例的数目;PF(假正例) 代表反例被错误判断为正例的数目;NT(真反例) 表示反例被正确判断为反例的数目。且:
(17)
2.2 结构化数据的挖掘模型
电力变压器的监测参量及运行参量繁多,若考虑所有状态参量,缺陷诊断体系将极为复杂,且某些参量的记录参数值并不齐全。因此,需要选取最具有代表性且数据记录信息完整的参量作为指标量。文献[21]利用集对分析和关联规则,分析了变压器运行中典型缺陷与各故障征兆参数之间的关联性,并给出了缺陷诊断的24种指标量(见表3),这些指标量源自在线监测和常规例行试验。
2.1节所提的基于注意力的Bi-LSTM模型,不仅可以处理非结构化文本所产生的词向量序列,而且可以处理结构化信息所组成的数据长序列,故用于结构化数据的信息挖掘中。在时刻t,定量数
据的记录信息可记为ut,则一个ut向量内有24种指标量所对应的24个数值,即ut=(u1t,u2t,u3t,…,u24t)。本文可将不同时刻t的记录信息ut作为模型的输入集,那么,模型的softmax层可输出结构化数据隶属于L1、L2、L3等级的概率p2(L1)、p2(L2)、p2(L3)。
2.3 多源异构数据融合
对于文本序列,本文所提出的模型的softmax层可输出缺陷记录文本隶属于L1、L2、L3等级的概率分别为p1(L1)、p1(L2)、p1(L3);对于定量数据序列,模型的softmax层可输出一系列结构化数据隶属于L1、L2、L3等级的概率分别为p2(L1)、p2(L2)、p2(L3)。将两者概率的加权求和,可得变压器总体状态隶属于L1、L2、L3等级的概率分别为p(L1)、p(L2)、p(L3),即:
(18)
根据最大隶属度原则,变压器的运行状态为max(p(L1),p(L2),p(L3))所对应的状态。
图5是多源异构数据融合的流程图。图形左侧为非结构化文本挖掘框架,图形右侧为结构化数据分析框架。通过融合文本型的非结构化数据与数字型的结构化数据,可更全面地判断变压器的运行状态。
3 验证性数据分析
本文选取了2015—2017年某省电力公司23 409条缺陷文本构成的数据,文本均源于交流220 kV油浸式变压器的运行检修记录。将数据集划分为训练集、验证集和测试集3个类别,其中训练集用于训练网络参数;验证集用于调整超参数,超参数为在网络训练之前所设置的,并在网络训练过程中保持固定的参数,如学习率η、批处理大小bs、迭代次数等;测试集用于评估网络的特征提取及文本挖掘的能力。图6—7显示了部分超参数与训练网络性能的关联性。

表3 变压器的缺陷诊断指标量Tab.3 Transformer defect diagnostic indicator
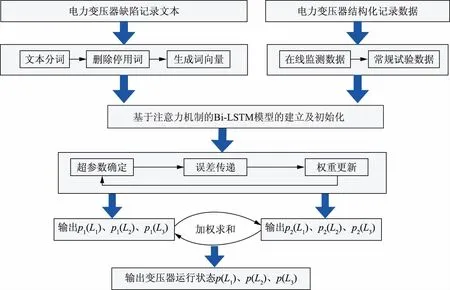
图5 多源异构数据融合的流程Fig.5 Flowchart of multi-source heterogeneous data fusion

图6 学习率与macro-F1之间的关联性Fig.6 Relevance between learning rate η and macro-F1
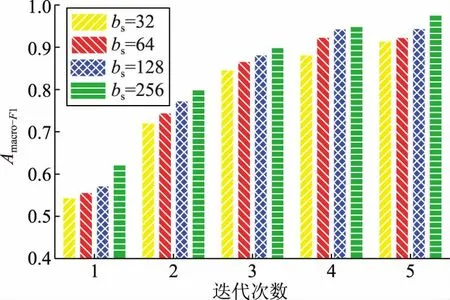
图7 批处理大小与macro-F1之间的关联性Fig.7 Relevance between batch size bs and macro-F1
图 6展示了学习率η和Amacro-F1间的关联性。当η=10-2时,Amacro-F1达到最大值,故η的最佳设置应为10-2。同理,由图7可得,批处理bs的最佳设置是256。此外,仿真设置词向量的维度为100,特征图个数为128,随机失活率为0.5,正则化系数为0.005,且共有3层基于注意力机制的LSTM,单元数分别为64、128、32。
3.1 特征提取能力
为了直观地表示特征提取能力,在模型的softmax层之前插入隐藏层,其单元数为2。因此,隐藏层可以输出二维的特征向量,如图8所示。同时,将与特征降维任务中常用的主成分分析法(principal component analysis,PCA)进行对比。利用PCA 对模型的初始输入进行特征提取,将前2个主成分投影至平面直角坐标系中,如图9 所示。
在图8—9中,蓝色原点表示“一般缺陷”,红色标记表示“严重缺陷”,绿色标记表示“危急缺陷”。在图8中,不同类别的样本各自聚集成簇,2簇发生重叠的面积很小,即通过多个隐藏层映射的二维特征具有良好的区分特征。在图9中,不同类别的样本之间存在大面积重叠,即PCA产生的二维特征无法准确区分不同的类别。这是由于PCA是基于线性变换的思想提取特征,易忽略不同类别之间的特征,故对底层数据的特征提取能力是有限的。对比可得,基于注意力机制的Bi-LSTM拥有比PCA更佳的特征提取能力。

图8 本文所提出的模型产生的二维特征向量Fig.8 Two-dimensional feature vector produced by the proposed model
3.2 与其他典型网络的性能对比
为了比较基于注意力机制的Bi-LSTM和其他分类模型的分类性能,选择几种典型的分类器用于对比实验。在基于传统机器学习的分类器中选择3种网络,包括k-最近邻(k-nearest neighbor,KNN)、支持向量机(support vector machine,SVM)和随机森林(random tree,RT)。在基于深度学习的分类器中,选择2种网络,包括LSTM和Bi-LSTM。
表4为不同分类器的分类性能评估结果。
根据表4的结果,可进行以下分析:
a)将本文所提出模型与传统分类器(即KNN,SVM和RT)进行比较。本文所提出模型的分类性能远优于传统分类器。例如,综合指标Amacro-F1提升了7%~10%。这是由于传统的分类器分为“特征提取+分类评估”2个阶段,信息可能在传输过程中丢失,且受限于模型的浅层架构,无法深入学习并提取信息。相比之下,基于注意力机制的Bi-LSTM可以统一特征提取和分类评估这2个阶段,并可以基于端到端的方式传递信息并深入学习语义。
b)将本文所提出模型与基于深度学习的分类器(即LSTM和Bi-LSTM)进行比较,结果为本文所提出模型的分类性能略优。例如,综合指标Amacro-F1提升了3%~4%。这是因为本文所提出模型具有更好的架构,它不仅可以识别局部的特征,也可获取上下文信息;同时还可以更加关注于关键信息和忽略不重要的部分。
3.3 结合结构化数据
由表4可得,本文所提出模型的缺陷分类性能十分优异,但仅凭对非结构化文本的分类研究将对电网的运行维护帮助有限,故本节旨在结合非结构化与结构化数据基础上对电力变压器的运行状态进行全面评价。表5举例分析了某台变压器在遇到不同故障情况下,非结构化缺陷记录文本与结构化监测数据的分析过程。
该变压器于不同时间段,分别发生了不同程度的缺陷。例如在2015年8月7日,运检人员记录了“主变220 kV侧A相套管引线发热90 ℃,零部件老化”的文字,根据本文所提的文本挖掘模型,计算出隶属于L1—L3等级的概率分别为0.323 0、0.610 8、0.066 2。同时,监测得出结构化数据的实测值并基于LSTM模型,计算得出结构化监测数据属于L1—L3等级的概率分别为0.213 4、0.616 6、0.170 0。由式(18)可得变压器总体状态隶属于L1—L3等级的概率分别为0.268 2、0.613 7、0.118 1,由最大隶属度原则判断,变压器总体处于“严重缺陷”,需立即进行检修。

图9 主成分分析法产生的二维特征向量Fig.9 Two-dimensional feature vector produced by the PCA

评估指标分类器KNNSVMRTLSTMBi-LSTM基于注意力机制的Bi-LSTM准确率A0.920.950.960.980.980.99Amacro-P0.920.950.920.960.990.99Amacro-R0.910.940.890.940.960.98Amacro-F10.880.920.910.940.950.98

表5 某变压器的缺陷数据及其分析Tab.5 Defect data of a transformer and its analysis
以2015年1月21日至2017年6月28日60组带有缺陷的变压器的结构化数据与非结构化数据作为输入,对其进行状态评价。图10展示了基于不同评价方法的评价结果。其中,图10(a)为基于结构化数据的评价结果,图10(b)为基于异构数据的评价结果。
图10中,圆圈圈出的点表明评价结果与实际结果不一致。因此,基于结构化数据的评价准确率为91.67%,基于结构化与非结构化数据的评价准确率为96.67%。故基于多源异构数据的评价方法能更好地评价设备的运行状态。
4 结论
本文提出了利用融合的非结构化与结构化数据,进行变压器状态评价的新思路。其中,针对电力变压器的非结构化文本,提出了一种基于深度语义学习的信息挖掘方法。根据案例分析,可得到以下结论:
a)基于注意力机制的Bi-LSTM模型具有优秀的语义特征提取能力。隶属于不同类的特征向量汇聚为不同的簇,并且不同簇之间的重叠很小。
b)基于注意力机制的Bi-LSTM模型具有优秀的语义学习能力。与传统分类器(KNN、SVM和RF)相比,缺陷分类性能提高了7%~10%;与基于深度学习的分类器(LSTM和Bi-LSTM)相比,缺陷分类性能提高了3%~4%。

图10 不同评价方法的运行状态评价结果Fig.10 Evaluation results of operating conditions of different methods
c)基于本文模型的非结构化数据的缺陷分类准确率高达98%~99%。进一步与结构化数据相结合,进行了基于多源异构数据的变压器运行状态综合评估,其评价准确度高达96.67%。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
河北理科教学研究(2021年4期)2021-04-19 13:34:44
计算机教育(2020年5期)2020-07-24 08:53:00
电子测试(2018年1期)2018-04-18 11:52:35
传媒评论(2017年3期)2017-06-13 09:18:10
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
计算机工程(2015年8期)2015-07-03 12:20:35
电测与仪表(2014年15期)2014-04-04 12:05:20
