
基于音视频的自动化低成本VR视频生成方法研究
2019-10-09 00:00李鹏付则宇邱柯妮张梁
软件 2019年7期
李鹏 付则宇 邱柯妮 张梁
摘 要: 虚拟现实(VR)技术的发展和相应硬件设备的普及,使得VR视频内容具有非常大的发展潜力。但VR视频的制作存在两个方面的挑战:一是新内容的VR视频生成成本很高;二是过去的影音资料难以重新录制成VR视频。本文提出一种新颖、低成本的利用已有影音资料生成VR视频的方法,该方法结合自然语言处理技术(NLP)、3D建模、虚拟现实等技术,可以快速、低成本生成VR视频。实验表明,本文方法可以大幅度节省制作成本,过去的音视频也可以生成沉浸感强的VR视频。
关键词: VR视频;NLP;自动化;低成本;沉浸感
中图分类号: TP391.9; N39 文献标识码: A DOI:10.3969/j.issn.1003-6970.2019.07.004
本文著录格式:李鹏,付则宇,邱柯妮,等. 基于音视频的自动化低成本VR视频生成方法研究[J]. 软件,2019,40(7):2230
【Abstract】: With the development of virtual reality (VR) technology and the popularity of corresponding hardware devices, VR videos present a very bright developing prospect among the emerging technologies. However, there are two major challenges in the production of VR videos. First, the cost of producing new VR video is very high. Second, it is difficult to transform past audio or video data to VR formats using the normal VR generation approaches. Addressing these problems, this paper proposes an automatic and low-cost method to generate VR videos using the existing low-cost audio and video materials. The proposed method integrates the technologies of Natural Language Processing (NLP), 3D modeling, virtual reality to produce high quality VR videos in a fast, low cost and automatic way. Experimental results show that cost can be greatly saved by the proposed method. Furthermore, it is a novel way to provide VR videos for the old precious audios or videos.
【Key words】: VR video; NLP; Automatic video generation; Low-cost; Immersive experience
0 引言
2016年1月国际CES(International Consumer Electronics Show)展会上,虚拟现实(Virtual Reality, VR)相关展品抢尽风头。随后国内外VR厂商陆续推出一大批消费级虚拟现实设备。硬件设备的爆发以及用户对VR体验的渴望,推动VR产业进入高速发展时期。如今虚拟现实(VR)技术在我们的生活[1]、科技[2]、医疗[3]、教育[4]中有广泛的应用。丰富的内容是VR生態链中重要的一环[5],然而VR内容的创作是一件非常耗费时间、精力和财力的工作。再者,过去的音视频资料限于当时的软硬件水平和录制手法,导致这些资料的画面质感和录音质量普遍不高。对于这些珍贵的影音材料,一方面修复会面临诸多挑战,另一方面也无法重新录制成VR版本的视频。
为此,本文提出一种新颖、低成本的利用已有影音材料生成VR视频的方法。该方法结合NLP(自然语言处理技术)、3D建模、虚拟现实等技术,可以快速、低成本自动生成高质量VR视频。
本文贡献体现在以下三个方面:
(1)一套标准完整的自动化转化步骤,无需计算机专业相关背景知识都可以用我们的设计架构很简便地制作VR视频内容。
(2)和用摄像机拍摄VR全景视频、动态捕捉设备录制VR视频相比,本文方法可以节约技术成本、时间成本、金钱成本,短期内可以大量产生成熟作品。
(3)对一些由于年代久远,视频质量差或者只有音频的情况,我们的方法也可以很容易的转制成VR视频。
1 背景
1.1 VR视频
虚拟现实(VR)视频,又称全景视频或360°视频[6],是要借助于虚拟现实硬件设备进行播放的视频作品,其目的是为观看视频的用户带来可交互的、沉浸式的临场感体验。
VR视频是虚拟现实技术(Virtual Reality Technology, 又称灵境或临境技术)的一个重要应用方向[7],虚拟现实技术来源于计算机仿真技术。计算机仿真是通过构建虚拟环境来模拟真实世界的运动规律。通过计算机仿真技术构造的虚拟环境,既可以是一个符合现实世界规律的虚拟环境,也可以是一个完全假想的环境。虚拟现实从不同的角度定义有很多不同的描述方式,但是所有描述方式中最重要的一个共性是,虚拟现实可以通过虚拟环境给用户营造一种不受时空控制的可交互的、沉浸式的临场感体验,这个共性也是VR视频的最大特点。
1.2 VR视频的生成方式
VR视频制作流程涉及多种近现代尖端影像技术,如计算机仿真技术、图形拼接技术、动态环境建模技术、实时三维图形生成和显示技术、适人化、智能化人机交互技术等。VR视频内容的生产可以分为两种方式,一种是借助全景摄像机拍摄并生成全景视频;另一种是采用CG(computer graphic,计算机图形)技术3D建模生成视频[8]。接下来简要的介绍下每种VR视频生成方式的特点。
1.2.1 用全景摄像机拍摄全景视频
摄像机拍摄VR视频,需要用全景摄像机即多镜头摄像机拍摄各个方向的图像内容并进行图像拼接[9]。中介绍了一种用于全景视频采集的多镜头系统。全景视频的生成可以分为摄像机标定、图像融合与同步、视频流生成三个阶段。用摄像机拍摄的VR全景视频分为五种,分别是全景3D交互视频、局部全景3D视频、全景3D视频、非全景3D视频、VR全景视频。这五种VR视频拍摄难度依次降低,最终体验效果也有很大差异,其中全景3D交互视频的沉浸性效果最好。在全景3D交互视频中用户可以参与到视频的故事情节中去,通过与故事场景中的物体进行互动,作品根据用户的选择做出回应,从而影响故事情节的发展。全景3D交互视频真正实现了用户对虚拟现实环境的“真实”体验,但是VR视频中的交互问题一直是制作者的痛点[10]。用不用交互,哪里使用交互,如何用交互都是这类VR内容制作者不得不面临的问题,而且全景3D交互视频制作周期长、成本高,短时期内难以产生大量成熟的作品。
1.2.2 计算机图形技术3D建模生成VR视频
采用CG(计算机图形技术)3D建模生成的VR视频类似于3D动画的VR版本,在综合运用各种贴图、光效和渲染后,其视觉效果可以和全景相机拍摄的视频相媲美。与使用全景摄像机拍摄VR视频相比,CG技术生成VR视频方便節奏控制和工作调度,同时不用购买昂贵的拍摄装备,不需要专业的影视拍摄人员,但是同样面临创作难的问题。一是虚拟场景的搭建设计,内容剧本的设计,讲演思路的设计等,都需要付出一些有创造性的智力劳动才能完成。二是虚拟场景中角色模型的肢体动画多是通过动态捕捉设备实时录制。全套动态捕捉设备不仅价格昂贵,而且操作繁杂,需要相关技术人员和软硬件设备的协同工作。而这就在无形中抬高了制作生成VR视频的门槛。
1.2.3 生成VR视频面临的挑战
综上所述,基于现有的通用VR视频生成方法想要低成本高质量的生产VR视频面临着一些挑战。首先,不管采用以上两种方法中的哪一种,繁杂的制作流程会大大降低视频内容的生产效率[11]。中以全景微课视频的设计与制作为例,完整的制作流程要包含教学设计、脚本构思、实景拍摄、后期制作等几个步骤。其次,不管是采用全景摄像机拍摄全景视频,还是使用动态捕捉装备录制肢体动画,都需要购买昂贵的硬件设备。这就增加了生产VR内容的制作成本,而且对制作人员的技术要求很高。最重要是,以上两种方法针对过去的一些珍贵音视频材料都无法重新拍摄或录制。
2 研究目的
近年来,随着计算机技术和网络技术的高速发展,网上积累了大量、优秀、高质量内容的视频资源。这些视频无论从内容、讲授形式、讲授思路等都是很好的资源,借助这些已有的资源进行VR内容的转制,可以有效的降低VR视频制作的创作门槛。同时,虚拟现实技术、人工智能相关技术的快速发展,相应软硬件设备的迅速普及也为传统视频向VR视频转化提供了技术支持和设备支撑。另一方面,运用现有的VR视频的生产方法又面临着上文所介绍的诸多挑战。因此在考虑技术成本、时间成本、金钱成本的情况下,运用新的技术和研究方法同时依托已有的视频资源进行创造性的三维视频转制变得很有必要。这将会有效降低VR视频的创作难度,缩短VR视频的制作周期,同时保证视频内容质量的优质性。而这方面的研究工作还很少有人涉及。
因此,本文提出了一种新颖、低成本的创作VR视频的方法,利用人工智能相关研究和虚拟现实相关技术并结合网络上已有的一些优秀的、高质量的影音材料进行VR视频转制。该设计方法尤其针对课堂、演讲等场合具有很高的应用价值。[12]中针对课程录像制作引入虚拟现实技术,通过构建虚拟场景,提供逼真的学习环境,但是该研究没有探讨虚拟形象取代真实讲师形象的可能性。我们提出的VR视频转制方法通过沉浸的虚拟环境、生动的虚拟形象,以另一种更加生动活泼的方式真实的再现课堂或演讲场景。因此本研究提出的设计架构不仅具有很强的学术价值更具有很广泛的实际应用需求。
3 研究方案
3.1 工作流程概述
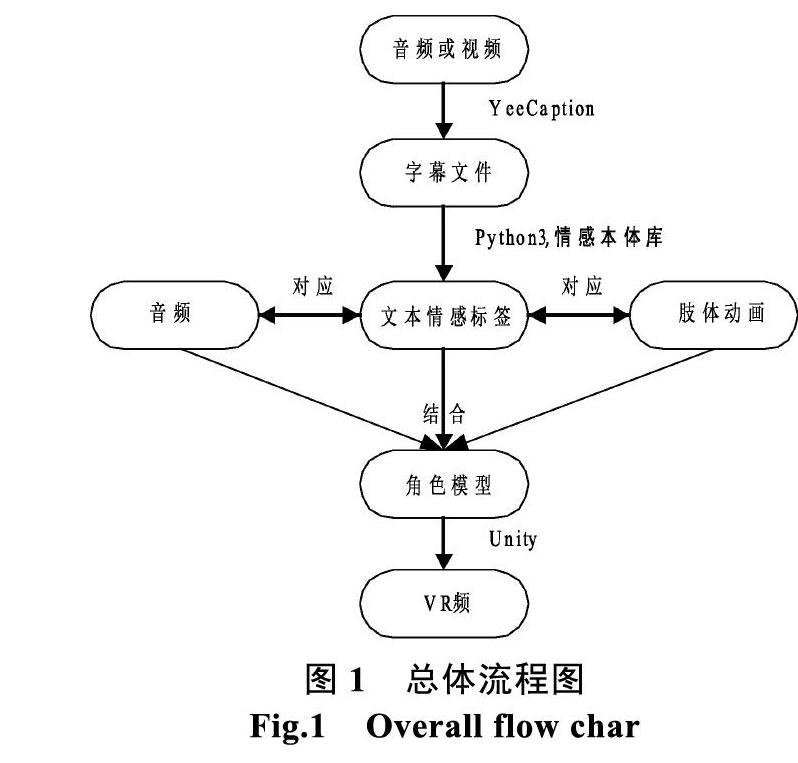
本文提出的多媒体视频或音频转为VR视频的方法概括起来可以分为三个步骤。
① 用语音识别工具提取视频或音频的文本信息。
② 对语音转化的文本进行自然语言处理获取每一句文本的情感标签。
③ 文本,音频,演讲者角色模型,肢体情感动画在三维虚拟现实场景中匹配生成VR视频。
图1为总体流程图,图中的①,②,③,代表上述三个步骤中用到的主要工具和关键技术。
3.2 语音识别获取音频字幕文件
用本文的方法进行VR视频转制,第一步是把多媒体音频或视频用语音识别工具进行文本化处理,获取影音材料的字幕文件。在选择语音识别软件方面我们要以保证语音识别一定准确度的情况下同时方便获取语音的字幕文件为出发点。
目前市面上有很多成熟的商用语音识别软件,例如科大讯飞、微软speech sdk等。经过对市面上多款语音识别软件进行实测和效果对比后,本研究采用YeeCaption这款免费智能视频翻译软件。该软件的智能性体现在能够自动对语音轴进行切分,对字幕内容和语音信息进行识别,最后字幕文件也可以很方便的一键导出。同时这款软件界面设计简单明了,功能设定明确区分,初学者也能轻松入手。最重要的是,此软件音频转文本的准确度高、导出的字幕文件包含每一句文本的时间戳信息,完全符合本研究的需要。
本文以俞敏洪老师经典的一分钟演讲《水的精神》为例,演示获得视频或音频字幕文件的过程。
(1)语音切轴获取影音材料的时间信息
把视频或者音频文件导入YeeCaption中,对导入音频进行语音切轴操作,把演讲者每一句话切分开来,获取每一句话的时间信息。如图2所示,右侧上方框框住的是每一句语音切轴,界面下方左侧框框住的是每一句语音切轴所对应的时间间隔信息。
(2)进行语音识别字幕,获取语音的字幕信息
图3是语音识别后的结果,从图中方框框住的部分我们可以看出,每一句语音切轴出现了字幕文本信息。语音转化成了对应时间间隔内相应文字。
(3)导出字幕文件
YeeCaption可以很方便的导出字幕文件。图4是导出选项中所支持的字幕文件导出形式。
3.3 自然语言处理获取文本情感标签
3.3.1 本文所用获取文本情感标签方法
以自然语言文本形式描述的信息占总信息资源的80%,对文本信息进行分析处理属于自然语言处理技术的研究范畴。现阶段自然语言处理的研究方法主要分为两类:一类是最近比较火热的基于数学统计的机器学习方法,另一类是基于传统语法规则的自然语言处理方法。具体采用哪种方法还是要看实际的工作需要。
本文提出一种自动化的、低成本的VR视频转制方法,出发点之一就是要尽量减少人工操作,节省时间成本、人力成本。因此本研究采用基于词典的情感分析方法,针对句子级语料进行情感分析,提取每一条字幕文本的情感标签。本文针对句子级语料而不是针对篇章级语料进行处理的原因是,语音识别导出的字幕文件是以每一个时间戳对应一行字幕文本的形式呈现的。所以我们的情感分析是以句子级为单位进行处理的。相比于篇章级的语料处理我们的方法可以进一步的降低情感分析的难度。
3.3.2 基于情感詞典获取文本情感标签
在大多数情况下,人们习惯直接用情感词来表达自己的态度和观点。例如用“excellent”来表达一种积极的观点,而用“poor”来表达一种是消极的观点。这种情感表达式称为直接情感表达(direct sentiment expression)。因此我们可以根据一句话中的情感词来大致判断该句话的情感类型。每一个领域都有各自领域不同的情感词,而不可能生成一个完备的适用于所有领域的情感词典。但是全人类情绪大的分类是一致的,例如人类的情感不外乎喜、怒、哀、乐等。本研究采用[13]中大连理工大学的中文情感词汇本体库作为情感词典进行情感分析。
Ekman是国际上具有广泛影响力的情感分类库,总共包含6大类的情感。大连理工大学的情感词典本体库在Ekman的基础上加入了情感类别“好”,构建成了包含七大情感类别(乐、好、怒、哀、惧、恶、惊)21小类别的本体情感库。本体库中的每个情感词都被分为正向、负向、中性三个情感极性,并具有从0到10等不同大小的情感程度值。大连理工大学的情感词典本题库从情感类别、情感强度及极性等方面对每一个中文词汇或者短语进行描述完全符合本研究的需求。另外我们还准备了一个否定词表(negation words)词典,以便对句子中含有否定词的情感词进行极性反向处理。
词典匹配的过程如下:
首先对句子进行分词、去停用词处理,获得只包含主干和核心词的精简句子。
然后将精简句子中的每一个词去和情感词典中的每一个词进行比对,如果词典中出现了该词就记录下该词的情感类型、情感极性、情感强度等属性。依次进行下去直到句子中的每一个词都进行了比对。
接下来再将精简后句子中的每一个词去和否定词表词典中的词进行对比,查看句子中是否包含否定词,以便对句子的情感极性进行反向处理。
3.3.3 处理字幕文件中的时间轴标签
打开音频转化后的字幕文件,我们可以看出每一句文本上面包含一个文本序号、一个时间轴标签,如图5中方框框住的部分所示,我们把这三项看成一个字幕元素。上一小节中介绍的是对字幕元素中的文本进行自然语言处理提取文本的情感标签。这一节对字幕元素中的时间轴标签进行处理,获得每一句文本出现的时间差值,最后将 srt格式字幕文件转化为Unity 中可以处理的字幕文件。
时间轴标签中包含两个时间节点,每一个时间节点中又包含时、分、秒、毫秒四个时间元素。我们把每一个时间节点都换算成毫秒,计算两个时间节点的差值,然后再用差值除以1000换算成秒为单位。这样就获得了一段文本在视频中出现的时间差值。如图6中方框框住的是第17句文本在视频或音频中持续的时间间隔。
每一句文本的情感标签,文本内容,出现在视频中的时间差值,组成一个新的字幕元素,如图6所示每一行就是一个新的字幕元素。对原始音频转化后的字幕文件中的每一个字幕元素都做以上处理,srt格式字幕文件就转化为了新的Unity 中可以处理的字幕文件。图6是新的字幕文件的一部分截图,每一行都是一个新的字幕元素,字幕元素中的元素项用$符分隔开。每一行的元素项从左到右依次是文本序号、情感标签、情感强度、文本内容、在视频或音频中持续的时间间隔。
3.4 情感动画的匹配
3.4.1 角色动画和场景模型构建
在匹配文本、语音和动画之前,需要对虚拟场景、演讲者角色模型、肢体情感动画进行构建。本研究角色动画采用3DS MAX这款软件进行建模,场景模型在Unity中构建。
3DS MAX是目前世界上应用最广泛的三维建模、动画、渲染软件[14]。使用3DS MAX建模大体上可以分为三个步骤:①对于简单几何体,使用3DS MAX内置图形库可以很方便的建模;对于复杂的图形多采用Nurbs面片建模或者Poly多边形建模;②对建好的模型赋予材质,所谓材质就是模型的外表在3DS MAX中多采用贴图的方式给模型赋材质,贴图可以采用Photoshop软件进行加工制作;③精细调节,最后要对模型进行精修,包含调整摄像机的位置,调整模型可视角度和反光度,等这一系列操作都完成之后最后把模型渲染输出成TGA序列图像格式。
构建完成模型和场景之后,接下来的就可以在Unity中对模型、音频、字幕、动画进行匹配生成VR视频。关于拼接视频,文献[15]中方案是对全景图片的拼接,实现网络视频的三维全景展示和本文方法有本质的区别。本文是对视频元素进行处理而非对视频中的帧图片进行处理。
为了生动有趣的还原音频中演说场景,我们用《疯狂动物城》中Judy(朱迪)的虚拟形象来代替俞敏洪老师在虚拟场景中进行演讲。关于虚拟人物文献[16]中提到在沉浸式虚拟现实中,与虚拟人物的交互是最令人信服的一种体验。因为参与者和角色共享一个三维空间,参与者能够准确地感知角色的肢体语言。卡通虚拟人物构建完成之后还需构建一个卡通风格的 3D虚拟场景[17],虚拟化交互将成为一种比较有发展潜力的交互形式[18]。中探讨将环境扩展到动画和虚拟现实的下一代数字流派。图7是在3DS MAX中对Judy模型进行建模的示例图。
给Judy角色模型绑定骨骼,制作演讲状态中的肢体动画,根据实际需要我们定制出演讲中表达情绪的肢体动画,仅作为演示我们给出图8中四种演讲状态中的肢体动画效果。
给角色模型绑定骨骼和动画,生成独立的动画文件之后就可导入Unity场景中进行文本,音频,演讲者角色模型,肢体情感动画的匹配。我们在Unity中导入一个林中小屋场景,导入Judy模型后的效果如图9所示。
情感标签和角色动画匹配后,角色在Unity场景中的演讲状态我们也给出部分截图,效果如图10所示。
3.4.2 字幕、音频、角色、情感动画匹配算法
把字幕文件、音频文件、角色模型文件、情感动画文件导入到Unity3D游戏引擎中,设计算法进行匹配,在虚拟场景中还原传统视频中的演说场景。
类似于传统的流媒体视频,本研究最后生成的VR視频是一个包含人物、肢体动作、字幕、音频的完整视频,而且字幕、语言、肢体动作互相匹配。因为字幕是从语音转化来的所以语音和字幕是一致的,所以匹配算法的关键有两点,一是要让字幕和出现该字幕的时间相一致;二是字幕内容和相应肢体动画相一致。
时间和字幕同步的处理方法如下:
本研究使用的方法是借助Unity中的协程机制,播放音频的同时让Unity的主程序首先调用text字幕文件出现一行字幕文本,然后调用协程让主程序等待一段时间再去调用text字幕文件中第二行要显示的字幕文本。这个协程等待的时间就是text字幕文件中字幕文本相应行中最后一项的时间差值。与此同时,在主程序等待的这段时间内,调用情感标签和肢体动画文件匹配的算法,使字幕文本的内容和肢体动作相一致。通过以上方法就做到了语音、字幕、肢体动作相匹配。
字幕内容和相应肢体动画一致的方法如下:
每条动画制作的时候都有自己的播放时间即动画自身时间长度ClipLength。每一段字幕出现也有一个时间差值WordTime。即在WordTime时间内,相应的动画要播放完,这样才能保证字幕内容和肢体动画相一致。因为字幕出现的时长WordTime是定值,所以只有通过控制动画的播放速度来使字幕内容和肢体动画相一致。
动画速度的处理方式有以下三种情况:
1. WordTime=ClipLength Speed=1。
2. WordTime>ClipLength Speed=ClipLength/ WordTime,减慢动画播放速度。
3. WordTime 通过以上三种不同情况的处理,就做到了肢体动作动画和字幕内容相匹配。 4 实验 4.1 实验环境设置 本文所提出的VR视频制作方法,从前期各种转制材料的准备到后期结果的呈现,是要依托一些软硬件设施的。即使没有计算机相关专业知识的人群,依照本文所提出的方法流程,运用VR视频制作各个阶段的软硬件设施,完全可以复现实验结果。下面给出各个阶段所用到的软硬件设施。 (1)软件 提取视频的音频操作,本研究使用的是格式工厂这款软件,这款软件界面简洁、操作方便,可以很容易的提取到所需格式的音频文件。 音频的语音识别文本化处理操作,本研究使用的是YeeCaption这款智能视频翻译软件。这款软件将繁琐的视频字幕翻译制作最大程度的便捷化,成功实现从切分时间轴、字幕(语音)识别,到字幕翻译校对及成品导出的一站式操作。 Srt格式字幕文件的自然语言处理操作,本研究使用的Python3.6.3版本程序语言构建流程函数,自然语言处理库用的是NLTK库,句子分词用的是jieba分词,情感词典用的是大连理工大学信息检索研究室整理和标注中文情感词汇本体库。 音频、字幕、动画的匹配过程是在3D游戏引擎Unity3D中完成的,我们使用的Unity3D软件的版本是Unity 2017.2.0f3 (64-bit)。 PC操作系统是Win10系统,机身运行内存8GB,存储内存500G,处理器是Intel i7处理器。 (2)硬件 制作VR及3D视频过程中所需硬件设备为个人PC, VR及3D视频完成之后结果呈现的方式之一是用VR头显。本研究结果呈现运用HTC Vive虚拟现实平台。该平台配有高清晰头盔显示器(HMD)、两个运动控制器和两个红外跟踪站。本项目在Unity3D中开发,所有脚本都是用C#语言中完成的。与虚拟环境的交互主要是通过Vive控制器完成的,控制器有几个按键可用于交互。此外,制作完成的VR视频也可以直接在PC上显示3D视频,呈现方式并不局限于VR环境。 (3)参与者 为了对我们所提出的VR视频转制方法和最后的视频呈现效果进行评价,我们通过发送电子邮件给首都师范大学不同专业背景的学生来招募实验志愿者。我们一共选择了20位志愿者,为了消除性别、年龄差异,我们招募了10名男同学,10名女同学,他们的年龄都介于22岁至23之间,所有人的平均年龄为22.28岁。所有志愿者中其中10人宣称之前体验过虚拟现实技术,大多情况下这些体验仅限于体验过虚拟现实头盔,或者基于智能手机的VR盒子。 在本实验中我们把志愿者分成两组,为了消除性别差异和对VR熟悉程度的差异,我们保证两组人员总数相同,男女比例相同,对VR了解情况相一致。 4.2 实验流程 1. 对传统制作VR视频的方法进行调研,查询整理材料,给出传统方法所花费的时间、财力、和人力成本数据并和我们所提方法的成本进行对比。 2. 让实验受试者在VR演示装备中去观看转制的视频,观看之后填写调查问卷,对视频沉浸性进行评价。 4.3 实验结果 4.3.1 VR全景视频成本 (1)拍摄设备的价格花费大 国内外比较著名的全景相机品牌有:GoPro Omni、NextVR、Facebook surrond 360、LG 360cam、Samsung Gear 360、DetuTWIN 360、Ricoh THETA S、Nokia OZO、Insta 360,暴风魔眼等,部分品牌拥有多种不同型号相机,我们只选其中一种进行价格统计,由于受市场供求关系影响和商家战略部署影响,同种品牌同型号的全景相机在不同时间、不同地区,价格会有差异。统计结果如表1所示。 (2)时间成本大,人员动用多且复杂 因VR全景视频对于拍摄者及现场拍摄环境等要求比普通跟拍视频要高,所以前期准备工作复杂,需要的策划人员沟通人员会更多,对有较多经验的全景摄影师需求也更大,同时相比较普通跟拍视频而言,VR全景视频的拍摄时间成本也会更大。 (3)后期难度高 普通视频的后期制作主要在剪辑和布置特效两项之中,而VR全景视频首先要做的是将不同方位的素材进行拼合,还要进行画面的校准等步骤,使成片塑造的环境更显真实。所以从VR全景视频后期制作方面来说,也是需要相当的时间耗费与制作功底。 4.3.2 动捕装备录制CG视频成本 (1)金钱成本大 通过对各种捕捉设备的市场行情分析,目前最低成本的小型硬件实时捕捉设备都要万元以上RMB,而且仅仅是身体运动捕捉功能部分,而表情、手部,眼睛捕捉等都需要单独购买相应的设备,全套购买齐全估计也要数十万RMB,而像Vicon跟MotionAnalysis这样著名的捕捉公司的最低配置都要100萬以上。部分品牌动捕装备的价格统计如表2所示。 (2)人员动用多且操作流程复杂 捕捉设备包含身体运动捕捉设备,表情、手部,眼睛捕捉等相应设备,同时还需要多角度的控制器定位系统,而这些都需要专业人员提前进行调试、布置。如图12中所示,角色演员要穿戴布满传感器的设备,在可定位的区域内活动,专业的技术人员要实时的操控相应的软件进行动作的捕捉。整个过程是非常繁杂的,如果设备某个部分发生了故障,设备调试也要花费很长时间。 4.3.3 本文所提VR及3D视频生成方法成本 我们所提方法不需要全景相机,不需要动捕装备,因此可以很大程度降低金钱成本,同时也降低了时间成本和人力成本。只需要针对已有的音视频进行再次创作就可以生成高质量的VR内容。在这个过程中几乎不花费金钱成本,只需要几款软件就可以进行VR视频的转制。人力成本方面最多两个人就足够了,一个人负责建模,一个人负责Unity中视频的拼接。综合以上VR内容生产成本的调研和分析我们可以得出表3中的结论。 相较于全景相机录制全景视频的方法、全身动捕装备录制VR视频的方法,我们所提出的利用已有音视频资料生成VR视频的方法,可以快速、低成本自动生成高质量VR视频。 4.3.4 对转制VR视频的效果进行评价 实验受试者分A,B两组。志愿者们首先观看原视频,然后体验转制的VR视频,体验之后针对“我认为转制后的VR视频和原始视频相比更有吸引力、沉浸性更强。”问题对VR视频的效果进行评价[19]。中针对VR环境下解剖学领域的空间结构学习能力的提升的对比实验[20],中关于虚拟现实环境下条形按钮和圆形按钮的对比实验,评价方法都是采用上面所述的调查问卷评价方法。评测效果分5个等级从高到底分别是非常同意、同意、中立、不同意、非常不同意。评测结果如下。 由图13,14中数据可以看出A,B两组横轴每一项的数据差异不是很大,A组中40%的同学非常同意VR视频的呈现效果要好于原视频,同意占比为30%。在B组中也有相似的结果,同意以上占比为70%。综合A,B两组数据我们可以看出70%的同学对我们所提实验方法转制的VR视频呈现效果表示满意,5%的同学保持中立,不同意以下占比为25%。 5 结语 随着虚拟现实技术和价格更加亲民化的硬件设备普及,VR视频内容的需求在逐渐增加。但现有的VR视频的生成方法面临着制作成本高,创作难的问题,而且对于过去珍贵的音、视频资料很难按照VR的传统生成模式来重新录制。由此,本文提出一种新颖、低成本的利用已有音视频资料生成VR视频的方法。实验表明,相比于传统的VR视频的制作方式,我们提出的方法可以大幅度节省时间成本、人力成本、金钱成本。 在将来的工作中,我们将会继续该方面的研究来提高自然语言处理的准确度、优化匹配算法、建立一个包含更精细情感分类的肢体动画库,加入面部表情的情感匹配, 使我们的VR视频制作流程更加简洁,生成的VR视频内容更加的真实、细腻。我们还将会研究专门针对演讲、授课的情感分析,由此增强VR视频的现场感染力。 参考文献 [1] 杨琪, 黄建明. 家居漫游系统的设计与实现[J]. 软件, 2015, 36(1): 26-31. [2] 徐雯皓, 李忠, 苏鑫昊. 基于 3D 引擎的汶川震前水文变化三维模拟演示系统设计[J]. 软件, 2018, 39(4): 176-179. [3] 唐实, 任淑霞, 王佳欣, 等. 基于虚拟VR技术的心脏医疗辅助系统的设计与应用[J]. 软件, 2018, 39(6): 23-25. [4] 高伟, 王昱霖, 吴倩莲, 等. 基于VR技术的教育游戏在英语教学中的应用与发展前景[J]. 软件, 2018, 39(5): 60-65. [5] 王跃华. 浅析虚拟现实视频的发展和应用[J]. 现代电影技术, 2016(07): 21-23. [6] 郭宗明, 班怡璇, 谢澜. 虚拟现实视频传输架构和关键技术[J]. 中兴通讯技术, 2017, 23(06): 19-23. [7] 赵乐明子, 刘荣. 虚拟现实视频市场的问题及对策研究[J]. 现代商业, 2018(02): 39-40. [8] 董振江, 张东卓, 黄成, 等. 虚拟现实视频处理与传输技术[J]. 电信科学, 2017, 33(08): 45-52. [9] Santos, Camilo Telles Pereira and Santos, Celso Alberto Saibel, “5Cam: A Multicamera System for Panoramic Capture of Videos, ” in Proceedings of the 12th Brazilian Symposium on Multimedia and the Web (WebMedia '06), 2006, pp. 99--107. [10] 吴远志, 门涛, 罗谊恒, 等. 全景微课视频的设计与制作[J]. 电脑迷, 2017(03): 137-138. [11] 薛元昕, 李鹰. 基于虚拟现实技术的课程录像制作研究与实现[J]. 烟台职业学院学报, 2011, 17(01): 48-51. [12] 张敏. 虚拟现实VR(影视)内容的发展现状和瓶颈[J]. 中国广播电视学刊, 2017(09): 64-66. [13] 徐琳宏, 林鸿飞, 潘宇, 等. 情感词汇本体的构造[J]. 情报学报, 2008, (2): 180-185. [14] 徐飞. 利用3DS MAX打造美丽世界——浅谈3DS MAX的学习与应用[J]. 科技咨詢导报, 2007(10): 20. [15] 秦晓军, 黄秋儒. 面向网络视频的三维全景展示技术[J]. 电视技术, 2014, 38(19): 120-122+154. [16] Gillies, Marco, “Creating Virtual Characters, ” in Proceedings of the 5th International Conference on Movement and Computing, 2018, pp. 22: 1--22: 8. [17] 曹瑜, 郭立萍, 杜红燕, 等. 卡通风格3D 游戏场景设计制作技术[J]. 软件, 2015, 36(3): 22-25. [18] Hailey, David E. , ”A Next Generation of Digital Genres: Expanding Eocumentation into Animation and Virtual Reality, ” in Proceedings of the 22Nd Annual International Conference on Design of Communication: The Engineering of Quality Documentation(SIGDOC '04), 2004, pp. 19--26. [19] Seo, Jinsil Hwaryoung and Smith, Brian Michael and Cook, Margaret E. and Malone, Erica R. and Pine, Michelle and Leal, Steven and Bai, Zhikun and Suh, Jinkyo, “Anatomy Builder VR: Embodied VR Anatomy Learning Program to Promote Constructionist Learning, ”in Proceedings of the 2017 CHI Conference Extended Abstracts on Human Factors in Computing Systems(CHI EA '17), 2017, pp. 2070-2075. [20] Santos, A. and Zarraonandia, T. and D\'{\i}az, P. and Aedo, I, “A Comparative Study of Menus in Virtual Reality Environments, ”in Proceedings of the 2017 ACM International Conference on Interactive Surfaces and Spaces(ISS '17), 2017, pp. 294-299.
