
基于评论数据中隐式邻居关系的推荐系统研究
2019-10-08 08:34吴晓桐梁永全
软件 2019年7期
吴晓桐 梁永全


摘 要: 传统推荐系统大多使用基于协同过滤的方法进行推荐,然而在现实场景中,大多数用户只对很少的项目进行了评分,因为缺少历史评分数据造成了冷启动问题,导致协同过滤方法的推荐质量不佳。本文使用丰富的评论数据挖掘用户之间和项目之间的隐式邻居关系,并联合项目信誉问题建立基于评论数据的社交矩阵分解模型ReTOMF。实验表明,与对应的其他推荐模型相比,ReTOMF展现了更好的推荐性能。
关键词: 评论数据;隐式邻居关系;项目信誉
中图分类号: TP311 文献标识码: A DOI:10.3969/j.issn.1003-6970.2019.07.034
【Abstract】: Traditional recommendation systems mostly use collaborative filtering-based methods for recom-mendation. However, in real-life scenarios, most users only score very few items, because the lack of historical score data causes a cold start problem. This paper uses rich comment data to mine the implicit neighbor relationship, and combines project reputation to establish a social matrix decomposition model ReTOMF. Experiments show that ReTOMF exhibits better recommendation performance than the corresponding other recommended models.
【Key words】: Comment data; Implicit neighbor relationship; Project reputation
0 引言
近年来,推荐系统越来越多的帮助用户从大型资源集合里发现其感兴趣的项目,用户对项目的偏好用评分表示,并通过预测评分对用户进行个性化的推荐,传统的推荐方法,例如矩阵分解,用户和项目由低维潜在向量表示,并且偏好度由相关向量的乘积计算。但是这种显示反馈在对用户建模时经常面临冷启动的问题,因此,很多研究者开始关注不同类型的隐式反馈,而评论数据是隐式反馈中最常见的数据资源之一。它可以比评分更加清晰的显示出用户对物品的偏好侧重,对用户进行个性化推荐[1-3]。例如在音乐评论中,有些用户关注的是歌曲风格,有些用户关注的是歌手,明确用户的侧重点,可以在推荐过程中获得更大的精度。但是,评论数
据并没有被充分的利用,在不同平台和系统中对评论数据建模也具有很大的挑战性。
目前常用的推荐算法可以分为基于内存的推荐算法和基于模型的推荐算法。基于模型的推荐算法可以很好的融合先验知识,现有的基于模型的算法的基本思路是从已有的评分矩阵中挖掘用户和项目的潜在特征,并通过矩阵相乘的方法对缺失评分预测,这种方式已经得到了广泛的实践[4]。但是这类推荐算法普遍基于一种假设,既用户之间的关系是相互独立的,这种假设在很大一部分情况下是不符合实际情况的。所以,基于社会关系的推荐系统开始被更多研究者青睐。在社交平台越来越流行的今天,社交关系信息更易获取,虽然有些关系不能够直接应用于推荐系统中,但是我们可以挖掘隐式邻居关系[5],用于表明用户之间和物品之间的潜在相关关系。
在本文中,我們挖掘用户之间和项目之间的隐式邻居关系。研究表明,用户之间的相似性来源于用户之间相似的偏好,用户的行为会受其直接邻居的影响。通过用户的历史评分可以挖掘出用户之间的相似性,但是评分数据的稀疏性影响了推荐系统的性能,为了解决数据稀疏性问题,本文利用评论数据挖掘用户之间和项目之间的隐式邻居关系。
概率主题模型已成功应用于许多文本挖掘任务[6-7]。这些模型的基本思想是使用K个主题的有限混合模型对文档进行建模,并通过将数据集与模型拟合来估计模型参数。 两个基本的统计主题模型是概率潜在语义分析(PLSA)和潜在狄利克雷分布(LDA)。我们还在隐式邻居关系的基础上加入了项目信誉,因为项目信誉可以代表一个项目的质量和可信度。挖掘出隐式邻居关系后,我们将评论数据中的主题信息集成到基于信任传播的矩阵分解技术socialMF中。
1 相关工作
在众多推荐算法中,协同过滤算法因为仅仅利用评分信息受到广泛关注[8]-[9],基于物品的协同过滤和基于矩阵分解的协同过滤算法被相继提出。基于矩阵分解的协同过滤算法将用户对物品的评分信息以矩阵形式表示,挖掘低维隐特征空间,并把用户和物品在低维空间上重新表示,提出了一种基于概率矩阵分解的因子分析方法,同时使用用户的社交网络信息和评分记录来解决数据稀疏性和预测准确性差的问题;然而我们使用的评分矩阵存在数据高度稀疏并且分布不均匀,这会导致推荐系统的性能低下,冷启动问题等。
为了解决上述问题,研究人员开始引入额外信息来解决冷启动等问题,例如,文献[10]通过引入物品的内容介绍和评论信息为用户提供了信息保障。文献[11]表明在社交网络中,用户间是否存在社交关系往往依赖于用户之间是否相互信任,这种信任关系从某种程度上来说提供了用户的偏好信息。社交网络中拥有较强社交关系的用户在某些方面往往具有相似偏好且互相影响,因此有助于构建个性化推荐系统。文献[12]中将用户之间的距离作为额外的正则项添加到损失函数中。该方法把用户之间的影响看作是相等的,但是在现实世界中,用户之间的亲密程度决定了用户对其他用户的影响程度。文献[13]通过连接具有相似评分信息的用户来挖掘用户之间的隐式社交关系。但是在现实世界中,评分信息的稀疏性导致了用户之间的相似度的不可靠性。文献[14]使用聚类的方法对用户和项目建立生成模型,他们假设用户具有类别,使用生成模型计算隐式因子并聚类。但是也同样存在评分数据稀疏的问题。
本文内容安排如下:第1节介绍文章相关工作;第2节提供了有关ReTOMF的详细信息;第3节验证了ReTOMF的实际性能,并与几种有代表性的方法进行了比较; 第4节对本文作出结论。
2 模型部分
本节,我们介绍提出的推荐模型。在现实世界中,当人们购买或者选择他们不熟悉的项目时,他们会选择咨询朋友的意见以及查看商品的评论[15]-[16],用以判断商品的价值,信誉等问题,所以,基于对现实问题的观测,在我们提出的模型中,我们考虑用户朋友对项目的评价以及项目的信誉。我们首先计算用户之间的信任度,并且将这种关系定义为隐式邻居关系,结合用户信誉,综合因素提出推荐建议。
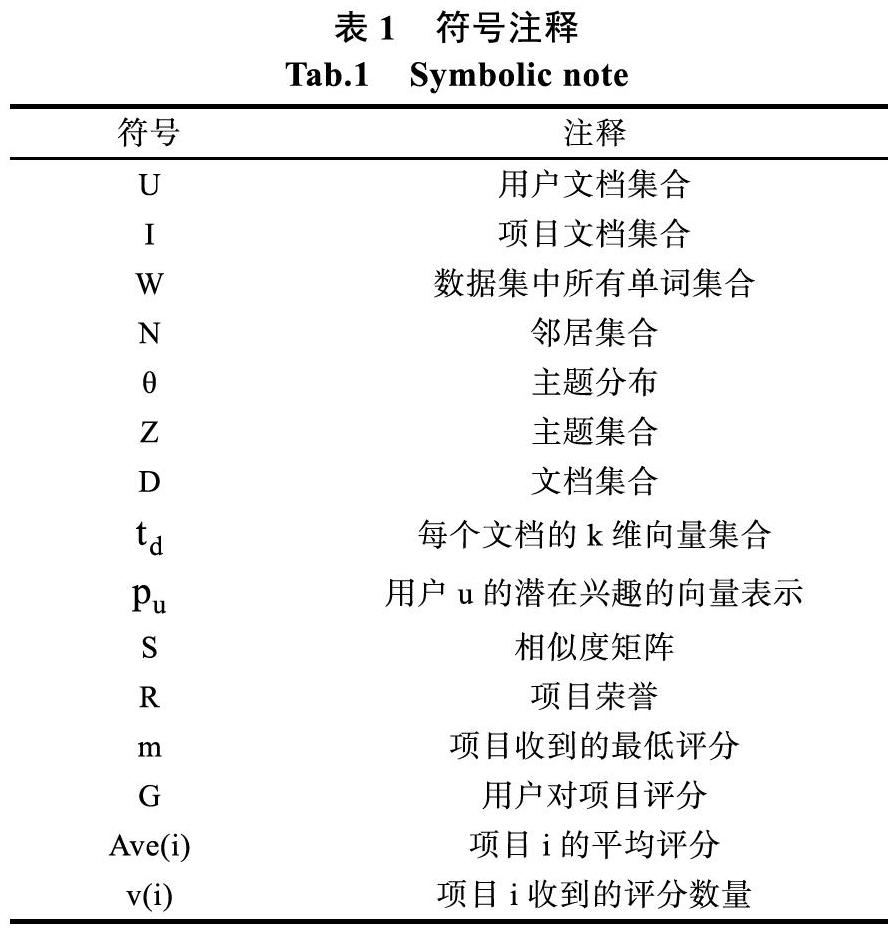
首先我们介绍基于隐式邻居关系的推荐正式的定义。在本文模型中,我们根据用户历史行为的相似性,寻找隐式的社交关系,因为这些行为可以展现用户偏好的相似性,我们把相似评论的用户看作隐式邻居并进行连接。在过去的基于评论数据的推荐系统中,项目之间保持着相对独立的假设,但是项目之间也有相应的联系。因此,在本文中,我们将使用评论数据同时对用户和项目建立隐式的社交关系。我们使用的符号如表1所示。
我们收集用户和项目的评论数据,并且将每一位用户和每一个项目的相关评论集合到一起。例如,一位用户做出过三十条评论,我们将这些评论集合到一个用户文档中,并用 表示,并对项目评论进行和用户相似的操作。用户的文档集合用 表示,用 表示项目的文档。为了便于计算相似度,我们将数据集中的所有單词表示成集合W。
2.1 主题模型计算文档相似度
在本节,我们使用主题模型计算文档相似度,我们以用户为例,具有相似主题分布的用户是隐式邻居的可能性更大,并根据其最相似的N个近邻来建立隐式邻居集 。
概率主题模型是一系列旨在发现隐藏在大规模文档中的主题结构的算法,已经被很多文本挖掘任务所应用,目前应用最广的两个概率主题模型是概率潜语义分析(PLSA)和潜在狄利克雷分布(LDA),例如,使用LDA生成主题模型的公式如下:
2.3 ReTOMF模型
我们将前两节介绍的用户信誉和主题模型集成到基于社交的矩阵分解模型SocialMF中,并将模型中的信任关系替换为隐式邻居关系。模型如图1所示。SocialMF是一种利用社交信任来提高推荐精度的基于社交的隐语义模型。它在计算用户隐式特征向量的时候,考虑用户间的信任关系,将该用户的信任用户对其的影响加入到特征向量的计算。具体地,在本文中,我们将社交推荐框架中的信任关系替换为前文建立的隐式邻居关系。在隐式邻居关系中,我们认为用户的偏好依赖于其邻居的偏好。在文献[17]中提出了SocialMF挖掘社交关系时用户隐式因子依赖其邻居,所以我们可以将模型中的信任关系替换为隐式邻居关系。和概率矩阵分解模型类似,我们的目标是最大化隐式因子的后验概率,用以学习模型的参数,我们以用户为例,用户隐式因子的先验分布为:
3 实验部分
3.1 数据集介绍
在本节中,我们进行一系列实验,用来验证我们提出模型的性能,并和其他方法进行比较。首先介绍我们使用的数据集,我们使用文献[18]爬取的亚马逊数据集,并从中选取了具有代表性的音乐数据集,电影数据集,游戏数据集。原始数据集包含用户对项目的评分,评论文本,评论时间等数据。其中,音乐数据集包含64706条评论,836006条评分数;电影数据集包含1,697,533条评论,4,607,047条评分数据;游戏数据集包含231,780条评论,1,324,753条评分数据。评分区间为1到5。我们对数据进行去停用词等的预处理,去除噪声数据和评论数少于20的数据,并对数据进行随机采样。采样后音乐数据集中包含7932名用户,45458个项目,80944条评分,评分区间为1到5,平均评分为4.33分;电影数据集包含5752名用户,35449个项目,64750条评分,平均评分为4.09分;游戏数据集包含4055名用户,7982个项目,25536条评分,平均评分为4.01分。
我们采用5-折叠交叉验证进行学习和测试。 我们将亚马逊数据随机分成5份,并使用80%的数据作为训练集,其余的20%的数据作为测试集。为保证结果的可靠性,对数据进行随机划分。实验中使用RMSE和MRR衡量模型性能。
3.2 实验结果
为了评估ReTOFM的性能,我们选择了具有代表性的方法进行对比试验。MF[19]是一个基本的矩阵分解算法,SocialMF[20],RISMF[21]是基于信任的方法,ReTOMF-Re是ReTOMF去掉项目信誉的方法,用以验证项目信誉在模型中的作用。实验结果如表2所示。
实验结果如表2所示。在实验中,把 和 设置为0.1,主题数设置为10,邻居数设置为15。从表中可以看出,ReTOMF明显优于其他方法,如RISMF和socialMF。 在三个数据集中,ReTOMF拥有最低的RMSE,和RISMF相比,平均降幅达到了2.5%,相比于socialMF,RMSE的平均降幅为4.9%。和ReTOMF-Re相比,ReTOMF有更低的RMSE,说明添加项目信誉可以获得更好的推荐效果。
主题数量和邻居数量是很难自动确定的变量,我们进行了多次实验以尝试获得最佳的主题数量和邻居数量。图2显示了不同主题数量的模型的性能,由图可以看出,当主题数为10时最适合我们建模,所以我们将主题数量设置为10。由图3可以看出,随着邻居数量增加性能逐渐增加,并在邻居数为15时达到最大值,所以我们将邻居数设置为15。
4 结束语
本文利用用户和项目丰富的评论数据,结合项目信誉,提出了基于用户评论数据的矩阵分解模型ReTOMF。我们利用评论数据挖掘出用户之间和项目之间的隐式邻居关系,并将这种关系集成到社交推荐框架中。本文还将项目信誉结合到模型中,主要依据是用户在购买不熟悉的物品时会首先选择查看评论等信息用来判断物品的信誉。在接下来的工作中,我们会使用深度学习模型卷积神经网络(CNN)进一步挖掘文档上下文信息,更好的缓解因为评分数据的稀疏引起的冷启动问题。
参考文献
[1] 张小波, 付达杰. 网络信息资源个性化推荐中隐私保护的研究[J]. 软件, 2015, 36(4): 62-66.
[2] 王崇峻, 魏鹏. 基于RSS的个性化信息服务系统研究[J]. 软件, 2018, 39(7): 110-115.
[3] 安政磊, 姚文斌. 一种基于用户购买意向的个性化推荐模型[J]. 软件, 2015, 36(12): 80-82.
[4] Koren Y, Bell R, Volinsky C. Matrix Factorization Techniques for Recommender Systems[J]. Computer, 2009, 42(8): 30-37.
[5] Ma Hao. An experimental study on implicit social recommendation[C]//Proc of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM Press, 2013: 73-82.
[6] Ashton Anderson, Daniel Huttenlocher, Jon Kleinberg, Jure Leskovec. Engaging with massive online courses[J]. In Proceedings of the 23rd international conference on World wide web. ACM, 2014: 687–698.
[7] Guo P J, Reinecke K. Demographic differences in how students navigate through MOOCs[C]// Acm Conference on Learning. ACM, 2014: 21-30.
[8] 江周峰, 楊俊, 鄂海红. 结合社会化标签的基于内容的推荐算法[J]. 软件, 2015, 36(1): 1-5.
[9] 符饶. 基于位置服务的潜在好友推荐方法[J]. 软件, 2015, 36(1): 62-66.
[10] Jin Z, Li Q, Zeng D D, et al. Jointly Modeling Review Content and Aspect Ratings for Review Rating Prediction[C]// Press the 39th International ACM SIGIR conference. Pisa, Italy: ACM, 2016: 893-896.
[11] Moradi P, Ahmadian S. A reliability-based recommendation method to improve trust-aware recommender systems[J]. Expert Systems with Applications, 2015, 42(21): 7386-7398.
[12] Ma Hao, Zhou Dengyong, Liu Chao, et al. Recommender systems with social regularization[C]//Proc of the 4th ACM International Conference on Web Search and Data Mining. New York: ACM Press, 2011: 287-296.
[13] Ma Hao. An experimental study on implicit social recommendation[C]/ /Proc of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM Press, 2013: 73-82.
[14] Beutel A, Murray K, Faloutsos C, et al.Cobafi: collaborative Bayesian filtering[C]//Proc of the 23rd International Conference on World Wide Web. New York: ACM Press, 2014: 97-108.
[15] Kim D, Park C, Oh J, et al. Convolutional Matrix Factorization for Document Context-Aware Recommendation[C]// Acm Conference on Recommender Systems. New York: ACM, 2016: 233-240.
[16] Li J, Chen C, Chen H, et al. Towards Context-aware Social Recommendation via Individual Trust[J]. Knowledge-Based Systems, 2017: 58-66.
[17] Jamali M, Ester M. A matrix factorization technique with trust propagation for recommendation in social networks[C]//Proc of the 4th ACM Conference on Recommender Systems. New York: ACM Press, 2010: 135-142.
[18] McAuley J, Leskovec J. Hidden factors and hidden topics: understanding rating dimensions with review text[C]//Proc of the 7th ACM Conference on Recommender Systems. New York: ACM Press, 2013: 165-172.
[19] Salakhutdinov R. Probabilistic matrix factorization[C]// International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2007: 1257-1264.
[20] Jamali M, Ester M. A matrix factorization technique with trust propagation for recommendation in social net-works[C]//Proc of the 4th ACM Conference on Recom-mender Systems. New York: ACM Press, 2010: 135-142.
[21] 赵亚辉, 刘瑞. 基于评论的隐式社交关系在推荐系统中的应用[J]. 计算机应用研究, 2016, 33(6).
