
图书评论特征抽取研究综述
2019-10-06 02:40祁瑞华杨明昕徐琳宏关菁华
现代情报 2019年9期
关键词:综述
祁瑞华 杨明昕 徐琳宏 关菁华

摘 要:[目的/意义]图书评论是出版社、图书馆和用户研究读者观点的重要线索,评论特征抽取研究是提高图书评论观点精准挖掘效率和准确率的基础性工作。[方法/过程]分别从评论特征抽取研究和图书评论特征聚类、语义表示、隐性特征抽取的典型方法等方面对国内外研究现状进行客观分析,梳理相关领域研究发展脉络和趋势。[结果/结论]指出图书评论特征抽取效率和准确率的提高需要考虑特征聚类、语义表示和隐性特征抽取等关键问题。
关键词:图书评论;特征抽取;综述
DOI:10.3969/j.issn.1008-0821.2019.09.018
〔中图分类号〕N99 〔文献标识码〕A 〔文章编号〕1008-0821(2019)09-0160-08
Abstract:[Purpose/Significance]Book review is an important clue for publishers,libraries and users to evaluate works.Feature extraction is the basic work to improve the efficiency and accuracy of the fine grained opinion mining of book reviews.[Method/Process]This paper made an objective analysis of the current research situation at home and abroad from the perspectives of the research on the reviewfeatureextraction,the clustering of book review feature,semantic representation,and the typical methods of the extraction of implicit feature,and sorted out the development context and trends of the research in related fields.[Result/Conclusion]It is pointed out that to improve the efficiency and accuracy of featureextractionin book reviews,some key issues should be considered,such as feature clustering,semantic representation and implicit featureextraction.
Key words:book review;feature extraction;survey
图书评论是出版社、图书馆和用户研究读者对作品评价信息的重要线索。图书评论特征抽取的目标是从评论文本中抽取关键要素,在此基础上研究用户对图书具体方面所持的评价和态度。评论特征抽取既能帮助用户详细了解图书质量做出购买决策,也能帮助出版社和用户实现精准观点挖掘,从而提高图书评论观点挖掘的效率和准确率。
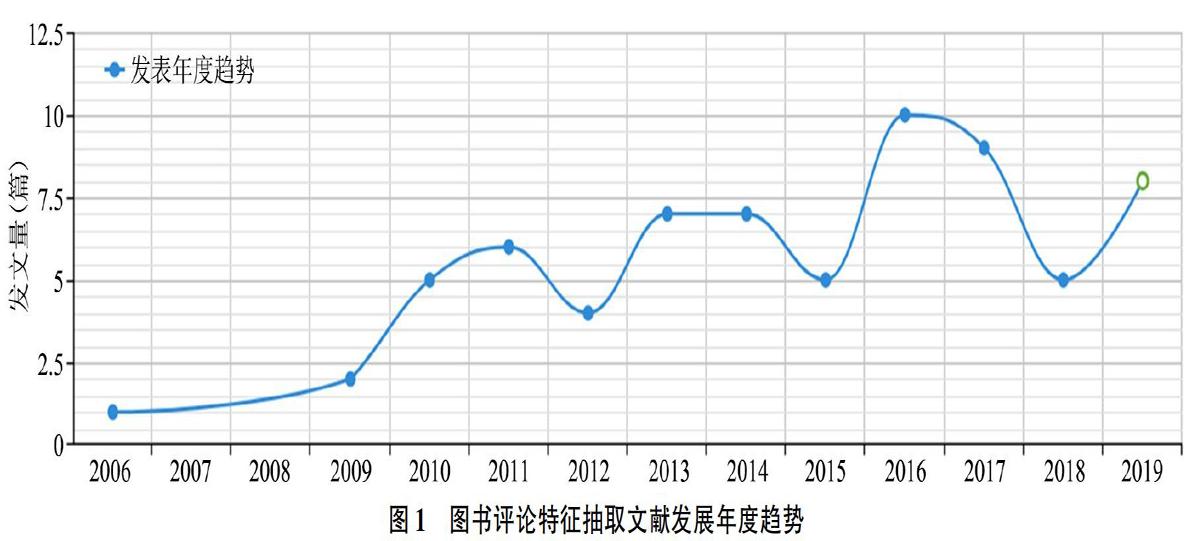
评论特征抽取属于细粒度的观点挖掘,在情报学和自然语言处理领域受到广泛关注。在中国知网全部数据库高级检索下,检索条件为(主题=“评论”或者题名=“评论”)并且(主题=“特征”或者题名=“特征”或者主题=“挖掘”或者题名=“挖掘”或者主题=“抽取”或者题名=“抽取”)时,检索到“评论特征抽取”相关文献4 166篇。但是图书评论领域得到的关注明显不足,当检索条件加上:并且(主题=“图书”或者题名=“图书”)时文献稀缺,仅检索到63篇文献,发展年度趋势见图1。
近年国内学者李光敏等[1]从产品特征频繁项、特征—意见共现关系、模型训练和显隐式特征匹配的角度分析了国内外产品评论特征抽取研究的进展和不足,指出语义表示、网络文本和隐性特征需要重点关注,但限于篇幅并未细分领域综述。
隨着大数据时代网络评论文本的大量涌现,图书评论特征抽取领域出现了新特点、新问题,这些关键问题本领域现有文献未能全部覆盖。为此本文利用文献检索顺查法和追溯法扩大文献研究范围,从中国知网和国外相关文献中,选择55篇有关“评论特征抽取”的代表文献,其中2010年前9篇,2010~2014年23篇,2015年以后23篇。国外文献32篇、国内文献23篇,其中图书评论领域文献17篇。在此基础上针对图书评论的特点,分别从特征聚类、语义表示和隐性特征3个方面重点论述与图书评论特征抽取相关的典型方法和关键问题,对国内外研究现状进行客观分析,对未来发展趋势做出展望,以期为进一步研究提供新的思路。
1 产品评论特征抽取
产品评论特征抽取的目标是从评论文本中抽取评价的具体对象,是细粒度观点挖掘和情感识别任务的基础性工作。随着自然语言处理技术的发展,机器学习方法有效改善了特征抽取模型的泛化能力。根据训练样本是否需要标注,特征抽取方法可分为有监督方法和无监督方法。
1.1 有监督方法
有监督方法将特征词抽取看作文本序列标注任务,基于训练数据与测试数据分布一致的假设,通过对训练集的学习建立模型实现对测试集的预测。有监督方法从标注数据中识别特征词的准确率较高,主要算法有隐马尔科夫、条件随机场、支持向量机、最大熵模型或决策树等。如Jin W等[2]用隐马尔科夫算法抽取产品显性特征词和观点词,鉴别特征词—观点词对进行观点词分类取得较好效果,但隐马尔科夫模型作为生成模型不适合处理内容丰富相互冗余的语料。条件随机场作为判别模型更适合处理这些语料,如Li F等[3]用Tree CRFs算法学习句法依存关系并利用Skip-chain CRFs算法克服长距离依存关系,将发现的语义关联作为输入信息抽取特征词;Hamdan H等[4]提取词根、词性、大小写等特征利用条件随机场抽取特征词。有监督方法的共性问题是人工标注语料成本高、主观性强,缺乏知识重组的过程,在复杂问题和大规模数据中的鲁棒性受限制。
近年来随着终身学习算法的提出,Shu L等[5-6]将终身学习机制引入到条件随机场算法抽取评论特征词,利用多领域知识和无标签数据使得整个学习过程保持对外界环境的感知,增强了模型的性能,是今后有监督特征词抽取方法获得突破性进展的可能途径。
此外深度学习算法在观点挖掘任务中也有很好的表现,Poria S等[7]基于深层卷积神经网络抽取视频对白文本特征,结合画面人物表情和语音多模态特征生成特征向量,将句子级别情感分析的准确率提升了14%。随后Poria S等[8]又提出七层卷积神经网络结合启发式语言模板用于观点特征词的标注,实验表明词嵌入特征能有效引入语义知识,非线性的深层卷积神经网络比线性模型更能适应自然世界中的数据。
1.2 无监督方法
无监督方法可以探索性地揭示未标注数据的规律,避免人工标注的高成本和主观性,目前主要采用统计法、词共现法、基于规则方法和主题模型等特征抽取方法。
早期研究以统计法为主,借助词频阈值等条件筛选特征词,此类方法简单高效,代表研究如Hu M等[9]通过关联规则挖掘电子产品评论中的名词词组频繁项集抽取产品特征。词频统计方法只关注高频词,往往漏掉非高频特征词。为解决这一问题,Hu M等[10]尝试将高频词附近名词补充到特征词集,Santosh R等[11]用词汇Bigram代替Unigram统计抽取特征词,韩客松等[12]、何新贵等[13]尝试词频结合词位置权重和提示信息权重方法,但不能从根本上避免统计法的局限。
词共现法假设词义关联紧密程度与词共现频率正相关,通过构建词共现网络图抽取特征词,如耿焕同等[14]利用词共现图和主题间连接特征抽取文档特征词,Liu K等[15]构建异构语义和观点关系图并通过协同排序算法和词汇偏好信息抽取特征词,均改善了非高频特征词的抽取,但词共现网络图对评论文本长度敏感,当文本信息不足以构建结构合理的共现网络时,特征词抽取的准确率明显下降[16]。
当前特征词抽取普遍采用基于规则的方法,句法规则能够抽象文本内部结构、概括特征依存模式,因而被广泛采用。代表研究有Qiu G等[17]提出双向传播算法利用句法依存关系建立特征模版,在少量初始观点词种子集上迭代抽取特征词,能适应多领域,但在小规模语料上召回率低,原因在于人工抽取的语法规则无法涵盖丰富的语言事实。为解决这一问题,Zhang L等[18]基于部分—整体模式和否定词模式改进了双向传播算法,Zhao Y等[19]提出提取句法结构的直接启发式算法和结构句法结构的泛化方法,Kang Y等[20]基于规则抽取在线评论的主观特征和客观特征,这些尝试一定程度上提高了召回率,但远距离依存关系、否定关系、引用关系和句法不规范文本等仍然难以用规则显式地表示。
普遍采用的特征抽取无监督方法还有基于主题模型的方法,主要基于隐含狄利克雷主题模型及其改进模型抽取特征词,如Ma B等[21]通过隐含狄利克雷主题模型生成特征词及其同义词的候选集,Ye Y等[22]提出改进的MF-LDA模型抽取微博客特征词,Chen Y等[23]提出结合文本聚类和特征选择的FSC-LDA模型,Xie W等[24]提出基于草图的主题模型抽取推特中的突发主题,有效地对推特信息流降维并生成快照。总体上,主题模型发现的是粗粒度的评价对象,需要提前人工设置主题数量,不能发现训练集中未出现而在测试集存在的特征词,在短文本或高噪音的网络文本上效果也有待改善。
近年来无监督特征词抽取传统方法与有监督方法、深度学习、终身学习等机器学习方法结合的研究发现,模型泛化能力和准确率都得到明显改善[25],是评论特征自动抽取技术发展的主要趋势。
2 图书评论特征抽取
2.1 研究背景
图书评论是一种特殊的产品评论,国内外学者从不同角度的持续关注和探讨,为图书评论特征词抽取研究奠定了基础。
从图书推荐指标体系的角度,Sohail S S等[26-27]以计算机类图书为研究对象,将图书评论关注的方面分为7类,根据用户需求和特征重要程度分配权重计算综合评分排序推荐图书,结果由20位用户主观反馈验证。李雁翎等[28]提出综合评价作者、出版社、图书馆、销售和网络舆情信息的图书评价体系及分析模型;从评论信息有效性的角度,张丽等[29]基于统计方法从评论标题和正文、图书种类、评论有用性的维度分析了当当网年度畅销的3本图书网络评论,提出帮助用户识别有效评论的方法;从中华图书海外评论的角度,刘朝晖[30]依托接受理论和测试理论对《红楼梦》两个译本的可接受性做了定量分析,发现两个译本的可接受性无本质区别,实验中的读者是未读过原著的美国大学生;陈梅等[31]统计了亚马逊网站上100页典籍英译作品译本、译者、出版社和评分人数,发现流行译本的译者多来自英美;张阳[32]归纳了亚马逊网站上10种《论语》译本的90份读者評论特征,分析总结了阅读群体对译本风格的偏好;何晓花[33]人工归纳了米歇尔《道德经》译本的245条网上评论,研究情感极性分布及其变化;从评论特征抽取的角度,李实等[34]基于关联规则挖掘《达芬奇密码》一书在卓越网的评论,实验结果中评论特征的查准率有待提高。
图书评论特征抽取研究取得了一定成果,然而网络图书评论的规模迅速膨胀,海量评论信息已经超出人工处理的能力,需要采用自动方法精炼大规模信息。而目前国内相关研究还主要限于小样本数据的统计分析,缺乏有说服力的数据支持,特征提取和分析方法局限于人工归纳,欠缺对互联网环境的适应性,特征抽取的效率和质量亟待进一步提升,性能还有待改善。在图书质量评价中引入自然语言处理和语义分析已经被证明是有效的,但尚处于研究的初级阶段,方法还未成熟[35]。下面结合图书评论特征抽取的3个关键问题:主题聚类、语义表示和隐性特征抽取进行分析。
2.2 主题聚类
与传统文档相比,网络评论文本多源异构、噪音大、主题稀疏、不规范表达多[37];与电子产品评论相比,图书评论偏重于用户体验的表达,图书评论中的微主题呈现相对分散的特点[35],图书评论特征抽取需要解决的问题首先是快速高效降维。
主题聚类能够在缺乏先验知识的情况下自动抽取评论文本的结构与特点,提炼大规模文本的关键内容,提高特征抽取的效率和质量,加快读者阅读和获取信息的速度。目前图书评论主题聚类主要采用隐含狄利克雷模型及其改进模型,如Zhang P等[37]针对图书评论微主题相对分散的特点,提出基于Group-LDA的读者检测方法,结合图书章节信息描述文档主题,检测主题类别与读者群体类型之间的相关性。陈晓美[38]结合观点分离与观点摘要集成算法,提出基于隐含狄利克雷模型的图书评论观点识别和深度观点判定方法,但只在《卡尔威特的教育》一书上进行了实证研究。张凤瑜[39]在10本图书评论上通过聚类算法和人工筛选,分别建立了图书评论特征词典和倾向性词典,语料范围比较有限。
图书评论主题聚类现有研究主要面向特定少量作品数据,难以适应网络评论大数据环境。解决思路可以借鉴电子产品评论主题聚类方法,如Santosh R等[11]用组平均聚类算法抽取亚马逊网站商品评论中的名词词组,根据聚类结果计算特征词评分函数,方法适应多领域和不同规模的数据集;Fitriyani S R[40]面向大数据主题检测任务提出小批量K-means方法,有效缩减了计算时间;Pang J等[41]从相似度扩散视角提出相似度层叠聚类方法,有效处理噪声和稀疏问题;Schouten K等[42]提出基于词共现关联规则主题聚类,为大数据集的特征抽取提供了思路。
2.3 语义表示
文本语义理解往往存在歧义,引入语义知识是提高网络评论特征抽取精准程度的关键,是当前研究的前沿和热点[43]。图书评论中最受用户关注的是图书内容[29],网络评论中对图书内容的引用表达形式多样,大量冗余信息干扰着图书评论特征抽取。引入语义表示有助于图书评论全局语义信息的准确表达,是值得关注的技术方法。
图书评论语义资源构建方面,郭顺利等[44]将豆瓣网图书评论用户情感分为7类,利用改进SO-PMI算法和同义词林扩展方法,基于情感种子词自动构建了中文图书评论情感语义词典,指出图书评论中的副词和连词对情感类别判断有明显影响,此方法的性能依赖短文本的准确分词、情感种子词数量和语料规模。领域语义资源应用方面,陈炯等[45]借助同义词词林建立产品属性模板,挖掘图书评论中的语言知识,但实验结果召回率低,原因是人工标注存在主观性,此外隐性产品特征识别也存在困难。张凤瑜[39]基于自建的特征词典和倾向性词典提出基于规则与统计的图书语义好评度计算方法,还需在大规模数据上进一步验证。
在以自然语言形式表达的评论文本中,领域知识的表现形式主要是短语实体以及实体间的关系,近年广泛应用在智能问答、知識推理和搜索引擎等领域的常识知识库和领域知识库已成为特征抽取重要的知识来源,是提高图书评论特征抽取准确率和效率的主要趋势之一[46]。
在常识知识库中,自然语言的实体关系表示为计算机可理解的结构化语义知识,现有的Freebase、Google's Knowledge Graph等大规模知识库中存储了大量常识和事实,但仍有自然世界中的词汇在知识库中未得到体现。对此学界持有不同观点。闭合世界假设认为知识库中不存在的实体关系就是错误的,而开放世界假设认为,知识库中不存在的实体关系可能是正确的,也可能是错误的。本文认为,现有知识库无法穷举自然界中的所有实体关系,因此开放世界假设更合理,对知识库尤其是垂直领域知识库的自动补全是评论特征抽取下一步研究的重点。可借鉴研究有Poria S等[47]利用句子依存关系、WordNet和SenticNet常识知识库,基于规则检测产品评论中评价对象,提高了在公开数据集上的准确率和召回率。Su Q等[48]利用中文概念词典等多源知识,基于COP-Kmean聚类算法思想提出相互强化规则来挖掘产品特征类别和观点词群之间的关系,通过隐性产品特征和观点词之间的映射提高特征抽取性能。
领域知识库能够精确表达特定领域的先验信息,对领域智能问答、情感分类等任务都起到重要的作用,是评论特征抽取的关键因素。可借鉴研究有Dengel A[49]从亚马逊网站上健康追踪器产品评论中抽取常用名词短语,结合WordNet的语义知识建立了评论特征领域模型,指出特征抽取错误与领域名词相关,因为单纯考虑名词词频会忽略一些稀有而重要的特征。宋晓雷等[50]针对汽车领域基于词形模板、词性模板、模糊匹配方法、剪枝法、双向Bootstrapping方法和K均值聚类方法提出评论特征抽取方法。孟雷等[51]针对金融领域提出基于依存句法分析的事件元素核心词抽取方法,结合短语结构句法识别事件元素边界,有助于提高特征抽取的准确率。
2.4 隐性特征抽取
根据特征是否在评论文本中显性出现,可分为显性特征和隐性特征。隐性特征是未显性出现的语义层面上的实际评论对象或情感,图书评论中隐性特征占相当的比例,如评论“书拿起来软塌塌的”中的实际评价对象“书的质量”和负面情感都是隐性表达的,隐性特征机理复杂没有固定的表达范式,涉及的词性和语法结构多变,是需要创新性思考的研究难点。
目前图书评论领域隐性特征抽取的文献稀少,国内有陈晓美[38]尝试分析一本著作评论文本的隐性特征。可借鉴的隐性特征抽取研究有Cruz I等[52]基于人工标注的隐性特征词标识,采用线性链条件随机场序列标注算法,在公开语料的隐性特征抽取实验中获得了较好效果;Poria S等[7-8]和Su Q等[48]分别基于聚类和基于规则方法,同时抽取产品评论的显性特征词和隐性特征词;Zhang Y等[53]基于共词关系抽取隐性特征词,优势在于不需要先验知识或人工标注,但共词关系无法体现同义词、近义词等语义关联;Hai Z等[54]提出两阶段共现关联规则挖掘隐性特征词,应用共现矩阵显著关联规则集的聚类为特征抽取生成健壮规则;聂卉[55]从信息整合的视角构建基于特征序列描述的隐特征聚类模型,利用依存句法和词法修饰关系量化用户评价观点。
總体上,现有文献为隐性特征词挖掘奠定了基础,但现有方法主要面向特定的领域,尚无文献提出跨领域的通用方法,图书评论领域隐性特征词抽取还需进一步深入研究。国内外关于评论特征的研究总体情况见表1。
3 总结与展望
现有研究为评论特征抽取奠定了良好的基础,但直接以图书评论特征词抽取为研究对象的文献非常有限,实践层面对图书评论的主题聚类、语义表示和隐性特征研究关注不足,以图书评论为研究对象的文献多为基于主观判断的例举式定性研究,即使采用定量研究也仅对小样本数据统计分析,具体观点内容分析限于人工归纳,缺乏有说服力的数据支持。
本文结合现有图书评论特征抽取的研究基础,针对互联网大数据应用环境的挑战,从两个方面对图书评论挖掘研究进行展望:首先,加强大数据环境下的图书评论特征研究有助于国际视野下的图书评论分析,综合运用大数据采集、机器学习和深度学习、终身学习等新兴技术,可以客观地分析国内外读者对于热点图书出版物的观点态度,能够有效对比特定图书不同版本的读者反映和观点摘要,形成的研究模式可以推广到跨语言图书评论观点挖掘,从更广泛意义上探讨对我国图书出版事业的启示。其次,国内图书评论挖掘研究的深度和广度尚待加强,从深度方面,图书评论领域的本体构建、知识图谱推理、命名实体识别、情感分析和语料自动标注技术的深入研究有助于改善海量高噪音的互联网图书评论挖掘的准确率和效率,但国内现有研究较少涉及;从广度方面,国内已有研究文献的数据来源比较单一,而来源广泛的在线图书评论语料有助于更加公平客观地获取读者观点和市场反馈。
参考文献
[1]李光敏,陈炽,邢江,等.网络文本评论中产品特征抽取综述[J].现代情报,2016,36(8):168-173.
[2]Jin W,Ho H H.A Novel Lexicalized Hmm-based Learning Framework for Web Opinion Mining[C]//Proceedings of the 26th Annual International Conference on Machine Learning,2009:465-472.
[3]Li F,Han C,Huang M,Zhu X,et al.Structure-aware Review Mining and Summarization[C]//Proceedings of the 23rd International Conference on Computational Linguistics,Association for Computational Linguistics,2010:653-661.
[4]Hamdan H,Bellot P,Béchet F.Supervised Methods for Aspect-based Sentiment Analysis[C]//Proceedings of the 8th International Workshop on Semantic Evaluation,2014:596-600.
[5]Shu L,Liu B,Xu H,et al.Supervised Opinion Aspect Extraction By Exploiting Past Extraction Results[J].arXiv Preprint arXiv:1612.07940,2016.
[6]Shu L,Xu H,Liu B.Lifelong Learning Crf for Supervised Aspect Extraction[J].arXiv Preprint arXiv:1705.00251,2017.
[7]Poria S,Cambria E,Gelbukh A.Deep Convolutional Neural Network Textual Features and Multiple Kernel Learning for Utterance-level Multimodal Sentiment Analysis[C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing,2015:2539-2544.
[8]Poria S,Cambria E,Gelbukh A.Aspect Extraction for Opinion mining with a Deep Convolutional Neural Network[J].Knowledge-Based Systems,2016,108:42-49.
[9]Hu M,LiuB.Mining and Summarizing Customer Reviews[C]//Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.ACM,2004:168-177.
[10]Hu M,Liu B.Mining Opinion Features in Customer Reviews[C]//Association for the Advancement of Artificial Intelligence,2004,4(4):755-760.
[11]Santosh R,Prasad P,Vasudeva V.An Unsupervised Approach to Product Attribute Extraction[C]//Proceedings of the 31th European Conference on IR Research on Advances in Information Retrieval,2009:796-800.
[12]韓客松,王永成.一种用于主题提取的非线性加权方法[J].情报学报,2000,(6):650-653.
[13]何新贵,彭甫阳.中文文本的关键词自动抽取和模糊分类[J].中文信息学报,1999,(1):10-16.
[14]耿焕同,蔡庆生,于琨,等.一种基于词共现图的文档主题词自动抽取方法[J].南京大学学报:自然科学版,2006,(2):156-162.
[15]Liu K,Xu L,Zhao J.Extracting Opinion Targets and Opinion Words from Online Reviews with Graph Co-ranking[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics,2014,(1):314-324.
[16]Ma T,Zhao Y W,Zhou H,et al.Natural Disaster Topic Extraction in Sina Microblogging Based on Graph Analysis[J].Expert Systems with Applications,2019,115:346-355.
[17]Qiu G,Liu B,Bu J,et al.Opinion Word Expansion and Target Extraction through Double Propagation[J].Computational Linguistics,2011,37(1):9-27.
[18]Zhang L,Liu B,Lim S H,et al.Extracting and Ranking Product Features in Opinion Documents[C]//Proceedings of the 23rd International Conference on Computational Linguistics:Posters.Association for Computational Linguistics,2010:1462-1470.
[19]Zhao Y,Qin B,Hu S,et al.Generalizing Syntactic Structures for Product Attribute Candidate Extraction[C]//Human Language Technologies:The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics,2010:377-380.
[20]Kang Y,Zhou L.RubE:Rule-based Methods for Extracting Product Features from Online Consumer Reviews[J].Information & Management,2017,54(2):166-176.
[21]Ma B,Zhang D,Yan Z,Kim T.An LDA and Synonym Lexicon Based Approach to Product Feature Extraction from Online Consumer Product Reviews[J].Journal of Electronic Commerce Research,2013,14(4):304-314.
[22]Ye Y,Du Y,Fu X.Hot Topic Extraction Based on Chinese Microblog's Features Topic Model[C]//2016 IEEE International Conference on Cloud Computing and Big Data Analysis,2016:348-353.
[23]Chen Y,Li W,Guo W,et al.Popular Topic Detection in Chinese Micro-blog Based on the Modified LDA Model[C]//2015 12th Web Information System and Application Conference.IEEE,2015:37-42.
[24]Xie W,Zhu F,Jiang J,et al.Topicsketch:Real-time Bursty Topic Detection from Twitter[J].IEEE Transactions on Knowledge and Data Engineering,2016,28(8):2216-2229.
[25]Pontiki M,Galanis D,Papageorgiou H,et al.SemEval-2016 Task 5:Aspect Based Sentiment Analysis[C].Proceedings of the 10th International Workshop on Semantic Evaluation,2016:19-30.
[26]Sohail S S,Siddiqui J,Ali R.Book Recommendation System Using Opinion Mining[C]//International Conference on IEEE,2013:1609-1614.
猜你喜欢
文化创新比较研究(2020年8期)2021-01-22
装备制造技术(2020年2期)2020-12-14
文化创新比较研究(2020年8期)2020-01-02
电子制作(2019年10期)2019-06-17
电子制作(2019年24期)2019-02-23
石油沥青(2018年6期)2018-12-29
NBA特刊(2018年21期)2018-11-24
自动化学报(2017年11期)2017-04-04
功能高分子学报(2016年1期)2016-04-26
法医学杂志(2015年2期)2015-04-17
