
基于全卷积神经网络的空间目标检测追踪算法*
2019-09-26 02:36:56朱凌寒曾梓浩赵坤鹏
传感器与微系统 2019年10期
陈 梅, 朱凌寒, 曾梓浩, 赵坤鹏
(合肥工业大学 电气与自动化工程学院,安徽 合肥 230009)
0 引 言
机器人常用两种编程方式:示教编程、离线编程。前者易操作,但精度完全依靠示教者目测决定,对于复杂的路径示教难以取得令人满意的效果。后者降低了前者的不便,并同时进行轨迹仿真、路径优化,但对于简单轨迹,没有前者的效率高[1]。现有基于视觉的机器人图形化示教编程系统,结合两种方式优点,由双目相机记录手动示教过程,通过处理示教视频帧图像检测定位示教物体,获得目标空间轨迹,后期优化轨迹,并转换为机器人可执行代码。由于运动过程中,示教物体产生旋转姿态影响检测定位,系统选用球形物体,用霍夫变换以轮廓作为主要特征检测。但为了避免背景干扰检测,示教物体只能适当大面积占据图像画面,由此引起运动范围有限,示教复杂轨迹难度加大。前期获取有限轨迹点数目,导致后期轨迹优化处理时,容易丢失轨迹细节,如此难以提高系统控制精度。如何解决这个问题,实现空间目标检测追踪,增大可示教物体种类,扩大示教物体的示教空间,从而顺利示教复杂轨迹、提高系统控制精度成为主要解决的问题。
传统的帧差法、光流法和背景差分法结合高斯滤波、粒子群算法等目标检测算法及策略已难满足当前目标检测中数据处理的性能、智能化等多方面要求。近年来,在图像处理上,结合神经网络处理已经成为一种大的研究方向。从2014年起,先后出现R-CNN,Fast R-CNN,Faster R-CNN,SSD等越来越快速和准确的目标检测方法[2~4]。本文考虑使用一种基于全卷积神经网络的算法来解决目标检测追踪问题。
1 目标检测与追踪
图像检测是将图像目标识别与分割等问题结合在一起完成[5]。追踪是对目标图的后续处理。目标的检测与追踪具体过程[6]对于一幅完整输入的图像,提取目标部分多个特征因素,形成特征向量。依据特征向量,匹配模板,完成识别分类,标出具体目标类型。获得带有标注分类信息的分割图后,确定目标类图像坐标。为了针对性检测示教目标,本文检测过程中结合神经网络处理视频帧图像。
普通的图像分割(传统语义分割)只能提取图片的低级特征,且多需要人工干预,不适用于视觉问题上批量化处理和智能化发展趋势[7]。现有有基于神经网络的图像分割方法,通过训练多层感知机来得到线性决策函数,然后用决策函数对像素进行分类来实现分割。网络大量训练数据,巨量连接,充分引入空间信息,较好地解决图像中的噪声和不均匀问题。这种方法下,主要需要考虑选择何种网络结构。本文选用全卷积神经网络(fully convolutional neural networks,FCN)结构。
2 空间目标检测追踪算法
2.1 基于全卷积神经网络的目标检测
2.1.1 全卷积神经网络
2015年,Jonathan等人在CVPR上提出FCN实现了对图像像素级别的预测,学习像素到像素的映射[8]。该网络可充分学习图像中目标体现的各层次特征,如轮廓,纹理,边界,角点等。使用不同的训练数据集,可准确识别多类目标。具体模型结构可基于VGGNet,AlexNet等变化。本文采用神经网络模型以VGG16模型为基本,替换最后的全连接层为卷积层,网络最后一层输出结构为1*1*4。构建网络模型结构如图1所示。

图1 FCN模型结构
为了输出原图一样大小的分割图像[9],网络最后部分将第4层神经元的输出和第3层的输出依次反卷积,分别16倍和8倍上采样,最后叠加处理输出。
由于类似的理论到实际的应用中,网络通常存在不收敛的问题。为了解决该问题。本文所用算法对网络学习率采用实时更新的方法。引入学习和阈值的概念,设置初始学习率0.000 1,学习率lr以损失函数loss为度量,计算平均损失,设置阈值pt,按以下方式更新
(1)
2.1.2 目标检测
本文设计神经网络可识别N类物体,定义示教目标具体类别数为n,通过位图和彩色图转换原理[13],制作训练集中标签图,标记该类别颜色为c(n)=(R,G,B)。输入彩色图像P进入神经网络,经过前文所提神经网络处理后,输出和原图相同大小分割彩色图片P1。
初步获得分割图,由于网络可识别多类物体,在复杂背景下,分割图出现多种颜色。为了方便系统确定识别目标的位置,对于P1继续做简单处理
1)二值化:设定以目标类别颜色c(n)为阈值,图像中所有颜色为(R,G,B)的像素点输出为白色(255,255,255),其余像素点输出为黑(0,0,0),提取出网络识别出的目标类别图像。处理得图P2。
2)形态学处理:二值图P2上,在目标图像的轮廓边缘处,存在很多噪点。使用形态学算子处理,先开后闭,选择使用算子(核)为半径为k的圆盘。进一步消除噪点,突出目标。处理得图P3。
2.2 空间定位
通过目标检测处理,获得目标点相对明确的图P3。但网络识别准确率并非100 %,图P3上除了目标图像,必然存在误识别区域,这些区域本身作为背景而言,相对于识别目标主体,所占面积相对较小。由此,计算图像上最大连通域的质心位置来获得目标的质心,进一步明确目标。该质心坐标记录为(x,y)。(x,y)为目标点在图像坐标系下坐标,而机器人示教为空间轨迹。平面点到三维坐标的转换不可避免,故需进一步处理获得目标空间位置(X,Y,Z)。本算法采用双目视觉定位技术[10],通过目标点在左右两个相机成像画面中的坐标(xCL,yCL),(xCR,yCR),计算目标物体实际空间位置。当前两个硬件参数相同、相机平行放置,如图2所示(本文采用同一世界坐标系)。
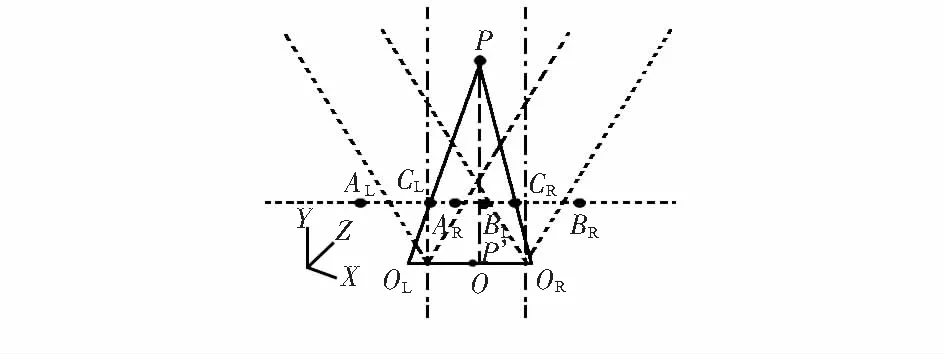
图2 双目相机空间定位示意
以两相机中心点为坐标原点,左侧相机在OL处,镜头水平向前,右侧相机在OR处,相机间距dOR-OL=d,两相机XOZ平面视角∠ALOLAR=∠BLOLBR=2θ,YOZ平面视角为2θy,画面分辨率为wh。成像画面宽度分别为:xAR-xAL,xBR-xBL。目标P在两相机成像画面上分别位于CL,CR处。转换过程如下:
P点在右画面中和左画面X方向上相对位置分别为
(2)
设像素点到X方向,Y方向实际长度换算比例为k,ky,则相机实际捕捉宽度以及焦距分别为:
实际距离
LAL-LAR=wk,f=0.5w/tanθ
(3)
dc1-cr=dol-or-w(px1-0.5)k-w×(0.5-pxr)k
(4)
由相似三角形原理得
(5)
将式(2)~式(4)代入式(5),计算得
(6)
则世界坐标系中X坐标为
X=Z(2pxl-1)tanθ-0.5d
(7)
同相似三角形原理,求解垂直坐标,其中,Pyl为P点在左画面Y方向上相对位置
(8)
得
T=Z(1-2pyl)tanθy
(9)
以上,确定目标空间位置坐标(X,Y,Z)。记录并保存,如此每隔一帧处理拍摄示教视频帧图像,定位隔帧图像中目标质心的空间位置,整体上,保存轨迹,实现追踪。
综上,可得空间目标检测追踪算法流程图如图3所示。

图3 算法流程
本文所提算法将从一定程度上扩大示教物体示教空间,如此,对于相同的轨迹点,可以最大程度上保留轨迹细节信息,方便后期对轨迹信息的进一步处理。
3 实验结果与分析
本文利用基于视觉的免编程系统平台对算法进行识别定位测试,测试平台如图4(a)所示。计算机与下位机(伺服驱动器)采用OPC通信,数据经过处理传输至伺服驱动器,机器人获取指令,执行操作。
3.1 训练网络
本文采用VOC2011数据集训练FCN(8 s)网络训练参数:批处理数目为5个,训练次数为10 000次,权重衰减为0.000 5,基本学习率0.000 1,可识别目标种类为4种。学习率采用定期自学习更新(每训练100次)的方式。初始设置最终网络误差收敛于0.131 5,保存网络第10 000次训练的参数,作为预训练网络模型。网络可识别物体N=4,识别准确率达80.6 %符合使用需求。
实验中以人手作为识别目标,定义为第n=4类,标记颜色 ,以“五指张开”姿态进行拍摄检测。示教环境如下:光照均匀;背景为自然背景,不刻意近距离人为遮挡(若近距离黑布等遮挡,影响光线强度分布,容易产生误识别)。
3.2 目标检测定位
实验开始拍摄示教轨迹示教视频,图4(b)为双目像机拍摄视频中某帧图片(以左目图片处理为例),其彩色分割图如图4(c)。

图4 实验平台、实验图像及FCN分割处理结果
如前文所述,对网络处理所得彩色分割图,依次做二值化,形态学处理,核半径k=10,获得图像,如图5(a1),(a2)所示。求取最大连通域的质心位置,获得手掌在空间中的质心位置,标记显示为*。如图5(b)所示。

图5 后续图像处理及确定位置
通过以上处理(右目图片同样处理),经过空间转换,保存获得目标在空间中的具体位置。实验最终获得目标物运动空间大小形状如图6所示,本文所用检测追踪算法下,检测目标物的运动范围为ABCDEFGH(后标fcn)区域。普通识别检测算法(霍夫变换)检测目标物体的运动范围为ABCDEFGH(后标hf)区域。(忽略双目相机中间视觉盲区)。

图6 实验目标运动空间对比
具体,两种算法实验数据性能对比如表1、表2。

表1 实验结果对比
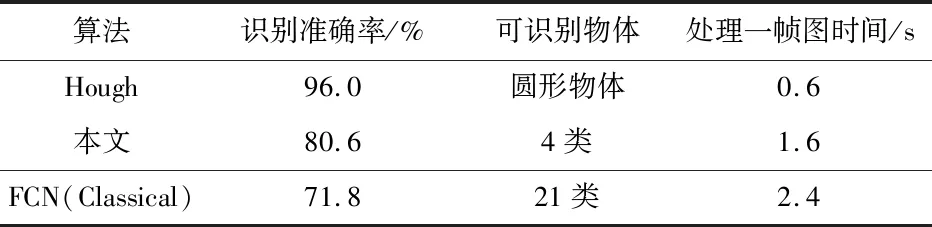
表2 实验结果对比
4 结 论
本文使用的算法扩大示教目标运动空间5倍多,可识别多类无规则物体,而且提出以自学习的方式更新学习率,使得理论到实际应用的过程中,网络顺利收敛。本文改进采用的FCN相比较传统FCN,提高了识别准确率。虽然使用霍夫变换通过物体圆形轮廓识别物体,捕捉物体的精度高,但实际可识别的区域范围小,不符合实际使用需求。只有提高可检测物体范围,才能当示教物行走复杂轨迹时,增大轨迹点的数量,放大轨迹细节,方便后期对于轨迹的优化。
同时,本文所用算法可识别多类物体,具有针对性,示教物不再局限于某类或某几类。实验中虽然处理时间长,但是该值受硬件条件影响,此类方法(深度学习)在一定程度上,已有相关文献证明验证,可通过后续改进达到实时效果[11],实际实施可行性大。结合图形化示教编程系统,在工业机器人编程系统中,有很好的应用前景。
为了减小计算量,缩短处理时间,在当前网络识别准确度已符合需求的情况下,本文未在网络后添加条件随机场(conditional random field,CRF)等算法,仅使用简单图像处理,后续仍可以继续优化算法,进一步提高算法识别准确率。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
中学生数理化·高一版(2020年1期)2020-02-20 13:24:32
电子制作(2019年11期)2019-07-04 00:34:38
中学生数理化·八年级物理人教版(2018年10期)2018-12-06 09:33:16
现代装饰(2018年5期)2018-05-26 09:09:39
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中国三峡(2017年2期)2017-06-09 08:15:29
科普童话·百科探秘(2015年4期)2015-05-14 07:06:42
