
基于CNN与关键区域特征的人脸表情识别算法*
2019-09-26 02:36:56薛建明刘宏哲袁家政王雪峤杨少鹏
传感器与微系统 2019年10期
薛建明, 刘宏哲, 袁家政, 王雪峤, 李 青, 杨少鹏
(1.北京联合大学 北京市信息服务工程重点实验室,北京 100101;2.北京开放大学,北京 100081; 3.北京联合大学 计算机技术研究所,北京 100101)
0 引 言
人脸表情识别在人机交互与情感感知领域有着广泛的研究前景,主要应用包括智能教育中的学习状态分析、安全驾驶中的驾驶人状态预测、犯罪审讯中的嫌疑人心理活动分析和智能医疗中的病人病因分析等。美国的著名心理学家Ekman P和 Friesen W V首次提出了面部动作编码系统(facial action coding system,FACS)[1],并提出了迄今为止都广泛使用的六类基本表情(惊讶,悲伤,厌恶,生气,开心和恐惧)。目前,人脸表情识别算法可以大致分为两种:传统机器学习方法和基于深度学习的方法。
传统机器学习方法大多将人脸表情识别分为特征提取和特征分类2个步骤。其中,特征提取是最关键的部分。提取能够更好表达表情信息的特征可以在很大程度上提高表情识别的准确率。根据处理对象的不同,还可以将特征提取和特征分类两个部分的算法分别细分为基于静态图像的方法和基于动态序列的方法。近年来,诸如局部二值模式(local binary pattern,LBP)、局部Gabor二值模式(local Gabor binary pattern,LGBP)[5]、梯度直方图(histogram of gradient,HOG)和尺度不变特征变换(scale invariant feature transform,SIFT)[7]等算法被应用于静态人脸表情图像的特征提取。文献[2]将SIFT特征应用人脸表情识别,取得了78.43 %识别结果。文献[3]将LBP与Gabor两种特征相结合,取得了98 %的识别结果。基于动态序列的特征提取较常用的有光流法和特征点跟踪法。通过对人脸表情图像提取特征后,还需要使用合适的分类器对特征进行分类。基于静态图像的分类器主要有K最近邻(K nearest neighbour,KNN)分类器、支持向量机(support vector machine,SVM)分类器和贝叶斯分类器等。而基于动态序列的分类器主要有隐马尔可夫模型(hidden Markov model,HMM)[4]和VSL-CRF[5]模型等。这些传统的机器方法在特定的小样本数据集中更加有效,但却缺乏泛化能力,在不受控制的环境中很难通过调整来识别新的人脸表情。然而随着技术发展,深度学习在计算机视觉领域得到了广泛应用,从而解决了传统人工设计特征的麻烦,并且能够自动地提取更深层次的人脸表情特征,达到提高识别率的目的。
Ouellet S[6]将深度卷积神经网络应用于人脸表情识别,进行高级人脸特征的提取,然后通过SVM分类器进行表情分类,最终在The Extended Cohn-Kanade Dataset(CK+)[7]数据集上取得94.4 %识别精度。 Liu M Y等人[8]通过结合表情活动单元(action unit,AUs)来构建人脸表情识别深度网络(action unit deep network,AUDN),最终在CK+数据集上取得了92.05 %的识别结果。
目前,现有的算法也有通过提取关键区域的手工特征来进行表情识别,并没有与深度学习相结合。本文提出一种新的应用于人脸表情识别的区域特征融合并行网络框架。本文的主要创新点为:1)提出了一种人脸表情图像分块的提取方法,能够准确的提取人脸表情表达的两个关键区域;2)提出了一种简单有效的并行网络的框架用于融合人脸表情图像的全局和局部特征并很好地结合了迁移学习的思想,提高了表情识别的准确率。
1 相关理论
深度卷积神经网络由于其具备优异的特征学习能力而被广泛地应用于深度学习的各个领域,尤其是图像分类方面。深度卷积神经网络的应用大大提高了特征提取的效率。相比于传统的机器学习分类问题,深度卷积神经网络的输入数据格式也得到了一定程度上的简化。因为传统的机器学习分类问题不能直接将数据输入,往往需要经过一系列的预处理,例如:量纲的归一化,格式的转化等。鉴于深度卷积神经网络的优越性,本文的基础模型采用的是VGG—16模型[9]。该模型为了能够有效减少参数使用3个的卷积层来代替1个的卷积层,并且还在3块卷积层后面都使用了ReLU层,从而使最终的决策函数的判别性更强。虽然VGG—16的预训练模型参数较大,但公开的预训练模型很方便获取和使用。因此,本文采用迁移VGG—16的预训练模型,来实现本文所提的算法。
2 关键区域特征融合的人脸表情识别算法
2.1 总体框架
为了能够将含有丰富的表情表达的区域更好的利用,提出了基于区域特征融合的并行网络的人脸表情识别算法。
2.2 人脸检测
使用文献[10]中的MTCNN方法。采用在MXNET框架下的MTCNN实现,对表情数据集中经纯脸部图像提取后的图像进行人脸检测,然后再给出人脸中5个关键点的预测位置。5个关键点位置分别是两眼中间位置,鼻尖位置和两边嘴角的位置。
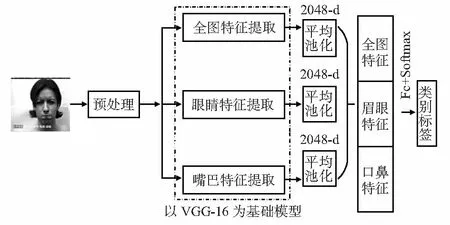
图1 区域特征融合并行网络框架
2.3 关键区域提取
将5个关键点表示为P={PEL,PER,PNC,PML,PMR},其中,下标E代表眼睛,N代表鼻子,M代表嘴巴,L和R分别表示左右。以眼睛区域为例。
首先,计算出眼关键点位置的中心对称点PC1
PC1=|PEL-PER|/2
(2)
式中 |PEL-PER|为两点的横纵坐标对应相减并取绝对值。
然后,计算得出该关键区域的宽和高
W=W1+W2,H=H1+H2
(3)
式中W1和W2分别为中心点PC1到该区域左边缘和右边缘的距离。同理,H1和H2分别为中心点PC1到该区域下边缘和上边缘的距离。W1,W2,H1和H2的计算公式如下
W1=|PEL∶x-X1|/2+|PEL∶x-PC1∶x|
(4)
W1=|PER∶x-X2|/2+|PER:x-PC1∶x|
(5)
H1=|PNC∶y-Y1|
(6)
(7)
式中X1,X2,Y1,Y1分别为二维图像左、右边缘的横坐标和下、上边缘的中坐标,P∶x和P∶y分别为是点P的横纵坐标。
最后,以点PC1、宽W和H高这三个参数来确定眼部关键区域。同时,嘴巴关键区域的提取与眼部关键区域提取方法一致。本文将该方法同时在2个公开表情数据集中进行关键区域提取的实验,证明了该方法在保证不丢失关键区域像素信息的情况下,还能够很好地去除冗余信息。
2.4 特征提取与融合
本文采用在Imagenet[11]数据集上训练好的VGG—16模型作为本文算法中的特征提取器。由于人脸表情数据集的量级都较小,采用训练好的模型通过把从大数据集中学习的到知识迁移利用起来,从而能够有效地防止过拟合,同时还可以加速训练的过程,节约人力和物力。本文算法使用3个并行的VGG—16模型来分别对全图、眼睛关键区域和嘴巴关键区域进行特征提取,然后依次通过池化层和Concat操作实现特征的融合,最后在模型后面连接上2层全连接层和Softmax层作为分类器。提出的算法简单有效。
3 实验与结果分析
3.1 数据集选取与预处理
本文采用日本女性面部表情数据集JAFFE[12]和CK+人脸表情数据集来进行实验验证。
采用JAFFE的全部数据;对于CK+表情数据集只在有327个序列图像选取3张峰值图片作为验证实验的表情数据集。实验时,将每一类表情分别随机分成训练集、验证集、测试集,将每一类训练集、验证集、测试集合并,其分布比例为8∶1∶1。
对选取的2个表情数据集进行预处理主要是对其中所有图片进行纯脸部图像的提取,并对提取后的纯脸部图像统一缩放到224×224×3大小,如图2所示。

图2 CK+和JAFFE表情库纯脸部样本示例
3.2 实验具体实施
对人脸图像进行表情丰富区域裁剪,分别是眼睛、鼻子和嘴巴3个部位。裁剪后得到2个局部区域图像,再将这2张图像统一缩放到224×224×3的尺寸,如图3所示。
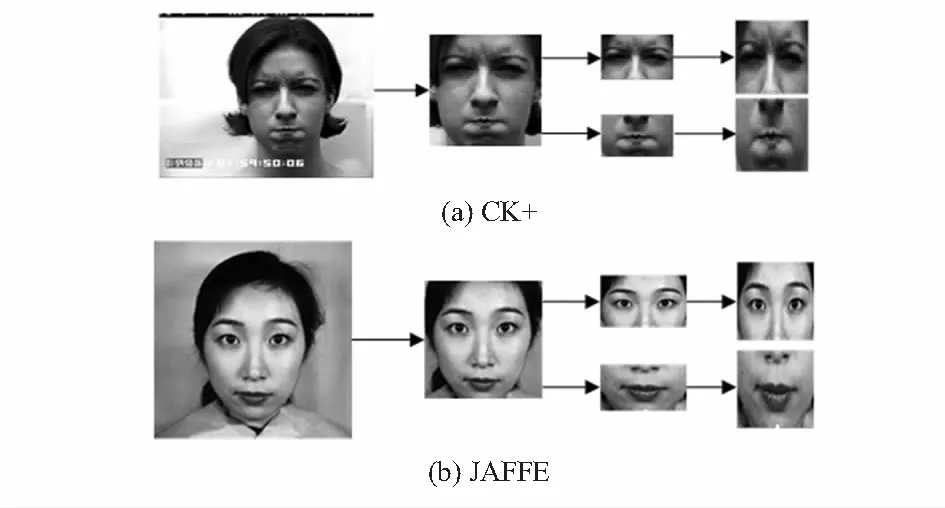
图3 CK+和JAFFE表情数据集关键区域提取实例
提取人脸图像的关键区域后,将得到的2个关键区域图像与全图馈送到3个以VGG—16模型为基础的并行网络中提取人脸表情特征。为获取更多的表情特征信息,本文选取模型中的Relu6这一层的输出来作为的人脸表情特征的表达,尺寸为1×4 096。将得到的3个表情特征进行最大池化处理后,再使用Concat操作进行特征融合,然后再馈送到由2层全连接层和Softmax层组成的一个分类网络进行训练,其中损失函数为交叉熵损失,优化算法采用的是Adam方法。由大量的实验得出,在对2个表情数据集上进行网络训练时最小批数量采用的是32,训练轮数设置为70,在兼顾准确率的同时节约了训练时间。
3.3 实验结果分析
本文在分别在CK+和JAFFE这两个表情数据集上对所提算法进行了实验验证。表2和表4为本文所提方法在两个表情数据集上得到的7种表情分类结果的混淆矩阵,并且表1和表3还给出了没有融合局部区域特征的情况下,得到的分类结果的混淆矩阵。

表1 CK+测试结果混淆矩阵(纯脸部图像)

表2 CK+测试结果混淆矩阵(纯脸部图像+局部区域特征融合)
从表1和表2所示的混淆矩阵可以看出,开心和厌恶这两个标签的表情识别率100 %,是所有表情中最高的。因为开心的表情比较简单,易于识别,而在CK+这个数据集中,厌恶的表情表现的形式也与其他表情差别较大,所以识别率会高一些。比较两个表中的其他类别表情的识别率,不难发现,本文所提的方法使得准确率在未融合区域特征方法的基础上进一步得到了提升。进一步分析可知,将富含表情表达的区域截取,再与全图进行特征融合,这相当于将这些区域的特征进行了强化。因此,本文算法能够识别出与恐惧这个表情表达相似的一些表情之间的较为细微的差异性,从而较大程度上消除了这一个问题对识别率的影响。

表3 JAFFE测试结果混淆矩阵(纯脸部图像)
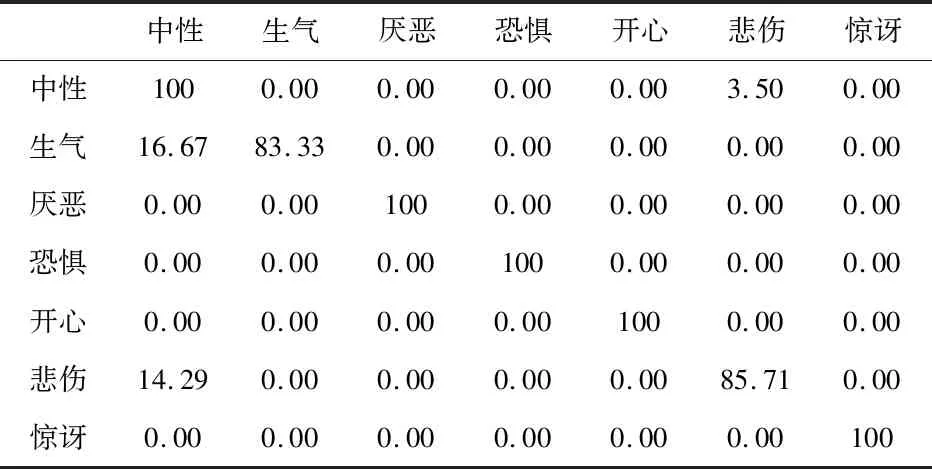
表4 JAFFE测试结果混淆矩阵(纯脸部图像+局部区域特征融合)
从表3和表4可以看出,通过本文方法,将表情表达丰富的区域进行裁剪并融合其特征,能够有效降低相似表情之间的误识别的概率。同时,从表4可以看出,有一部分表情为生气的图像被误识别为中性标签。经过查看原始数据集,可以发现,在标签为生气的样本中,存在少量的样本其表情表达并不明显,可能是因此才导致了该类表情的误识别。
将本文方法与近期其他学者所提方法的识别结果对比,文献[13~17]及本文算法在CK+上的准确率分别为96.02 %,96.60 %,98.30 %,95.73 %,97.81 %,98.48 %;在JAFFE上的识别准确率分别为89.5 %,90.90 %,93.42 %,96.30 %,95.56 %。可知,在CK+和JAFFE这两个表情数据集上,本文所提方法均取得了不错的效果。在CK+数据集中,本文所提方法的识别率均超过了其他传统机器学习的算法,其中也包括了设计提取并融合局部传统特征的方法和基于卷积神经网络的基础方法。在JAFFE数据集中,虽然本文的算法比文献[15]中的方法识别率低,但由于本文采用的是基于卷积神经网络的方法,因此避免了人工设计特征的复杂性,且仅需要简单地训练几层网络即可达到不错的识别效果,节约了大量的训练时间。同时,JAFFE数据集原始数据较少,这也是导致其识别率不高的原因之一。
4 结 论
通过设计简单并行网络模型用于人脸表情识别,易于实现,且网络的训练和测试能够在30 min内完成。同时,采用融合后的模型,能够在一定程度上突出了人脸表情表达比较丰富区域的特征信息,使得该模型更好地学习到相似表情在关键区域中的细微差异,从而降低其误判的概率,在JAFFE和CK+两个数据集上分别取得95.56 %和98.48 %的结果。在今后的研究中,应该进一步优化关键区域提取的准确性和模型的鲁棒性,从而能更好地满足现实生活的场景的需求。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
电子制作(2019年11期)2019-07-04 00:34:38
当代陕西(2019年10期)2019-06-03 10:12:04
动漫星空(2018年9期)2018-10-26 01:17:14
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
发明与创新(2015年33期)2015-02-27 10:40:09
奇闻怪事(2014年5期)2014-05-13 21:43:01
