
基于RFM模型的商场会员画像的建模与验证
2019-09-26 06:59:46李海燕王松响
郑州铁路职业技术学院学报 2019年3期
李海燕,王松响
(郑州铁路职业技术学院,河南 郑州 451460)
会员画像研究是当前的一个热门话题,最早是由交互设计之父Alan Cooper提出的,他认为会员画像是根据一系列用户的真实数据而挖掘出的目标用户模型。用户画像的本质是消费者特征“可视化”,通过收集与分析用户的基本属性、购买特征、行为特征等多个维度的主要信息,将会员标签综合起来,即可勾勒出会员的整体特征与轮廓。在商业领域,会员画像所能实现的会员识别、精准营销、改善经营、拓展市场等功能,是企业应用会员画像的主要驱动力。
本研究的目的是针对会员的消费情况数据,建立一个RFM数学模型,利用python软件实现刻画每一位会员购买力,以便能够对每个会员的价值进行识别,为商场对会员进行精准促销提供数据支撑。
数据来源于2018年全国大学生数学建模竞赛的C题《大型百货商场会员画像描绘》(简称《竞赛题》)。题目数据中给出了某大型百货商场会员的相关信息,附件1是会员信息数据表,附件2是近几年的销售流水表,附件3是会员消费明细表,附件4是商品信息表,附件5是数据字典表。
1 RFM模型
RFM模型是衡量客户价值和购买力的重要工具和手段。该模型通过一个客户的近期购买行为、购买的总体频率以及消费金额来描述该客户的会员价值画像。三个指标分别是最近一次消费时间(Recency)、消费频率(Frequency)和消费总金额(Monetary)[1]。
最近一次消费时间指会员最近一次的购买时间。理论上,最近一次的消费时间越近的会员价值越高。消费频率是指在一定时间内会员的消费次数,一定时间内的消费次数越多,越说明会员喜欢在该商场购物,会员的忠诚度越高。消费总金额指在一定时间内的消费总金额,金额越高说明该会员的消费能力越强。
运用软件,采用K-means聚类分析的方法,将会员划分为8类。
2 数据预处理
对于《竞赛题》附件1会员信息数据表、附件3会员消费明细表数据预处理如下:
将“登记时间”一列中的空白数据删除。
选取2017年10月1日—2017年12月31日的消费记录。
对第一步处理完毕会员消费明细表中的异常数据进行清洗,即筛选出能反映会员消费特征的有效数据。异常数据有两种情况:一种是商品售价与消费金额差距较大的数据。这种情况可能是由于产品打折或商场促销造成的,由于优惠活动的实施背景无法确定,所以以打折为唯一因素,并以一折为最低优惠限度。用Excel对数据进行筛选,将消费金额小于售价一折的产品数据和负数据删除。另一种是销售量、消费金额、积分都为负数的数据。
数据字典表中与相同会员消费明细表中的单据号可能不是同一笔消费,在提取数据时,将同一卡号下相同的单据号当作一次消费。
在会员消费明细表中用vlookup函数匹配会员信息数据表中的数据,将未匹配到的数据删除,以此筛选出该商场会员的所有消费数据。
3 Python软件
Python软件是一种解释性的、高级的、通用的计算机编程语言,由荷兰计算机工程师吉多·范罗苏姆(Guido van Rossum)创建,并于1991年首次发布,它的设计理念强调代码可读性,特别是使用强制缩进格式。Python语言具有简洁性、易读性以及可扩展性,完全开源,非常多的科学计算库都提供了Python的调用接口。它具有丰富和强大的库,常被昵称为“胶水语言”,能够把用其他语言制作的各种模块很轻松地联结在一起。
本研究的聚类算法K-means算法,来自Python的Sklearn库。Sklearn是机器学习中常用的第三方库,对常用的机器学习中的回归、分类、聚类等方法进行了封装。Sklearn库要建立在NumPy、Scipy、MatPlotLib等库之上[2]。
4 K-means算法
K-means是一个聚类分析算法, 在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好。算法的主要目的是找到数据中自然聚类的中心,使得各个类内部点的误差平方和最小。假设有n个对象,k个类,m个样本[3]。
算法步骤如下:第一步,确定有k类;第二步,在m个样本中随机选取k个样本作为类中心;第三步,计算各样本与各类中心的距离,将各样本归于最近的类中心点;第四步,求各类样本的均值,作为新的类中心;第五步,如果类中心不再发生变动或者达到迭代次数上限,算法结束,否则回到第三步,反复执行三、四、五步,直到结束[4]。
常见的距离函数有欧式距离、曼哈顿距离、余弦距离等,这里我们选取欧式距离
用误差平方和作为聚类的目标函数
式中,k表示k个聚类中心,Ci表示第i个中心,d表示欧式距离。
5 基于RFM模型的K-means 聚类算法建模
5.1 数据标准化
根据对会员数据的分析,各指标数据度量单位各不相同,且不在同一个区间,为避免直接进行数据建模对结果造成干扰,需要将数据进行标准化处理。由于F、R、M指标对顾客价值存在正相关影响,因此针对这三项指标运用正向指标的标准化方法,标准化公式为
式中,xnorm表示标准化后的数值,x表示原始值,xmin表示该指标的极小值,xmax表示该指标的极大值。
5.2 K-means 算法
利用 R(最近购买日期)、F(购买频次数)、 M(购买总金额三个指标),完成RFM模型的建设。聚类K-means 算法使用Python软件实现,实验过程分两个阶段。
第一个阶段,选取2017年12月共31天的数据,对算法程序进行训练,按k=8,聚类分为8簇。
第二个阶段,选取2017年10—12月的数据,运用程序运算,按k=8,聚类分为8簇。
程序分两个部分:第一部分是聚类,调用K-means 算法;第二部分是利用第一部分的数据结果,运用Matplotlib库画三维散点图。
5.3 实验结果及分析
5.3.1 第一阶段实验结果
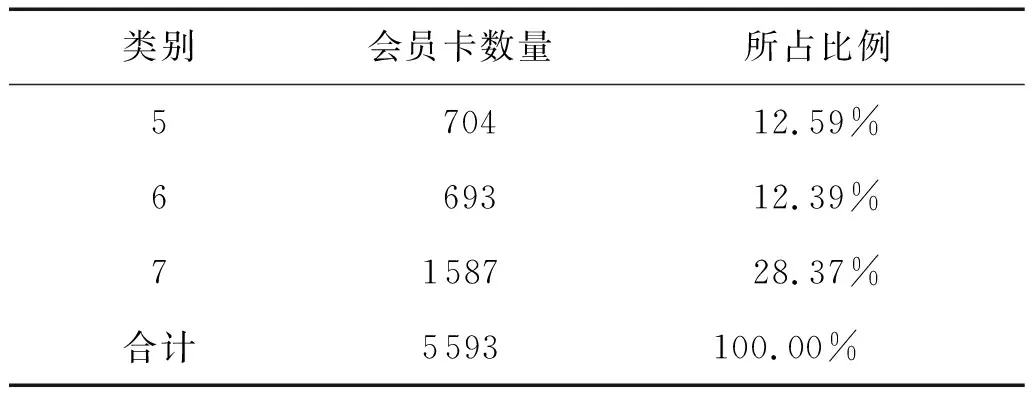
第一阶段实验结果见表1和图1。

表1 第一阶段各类会员卡数量
续表
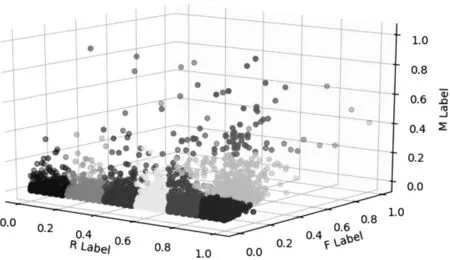
图1 第一阶段三维分类散点图
5.3.2 第二阶段实验结果
第二阶段实验结果见表2和图2。
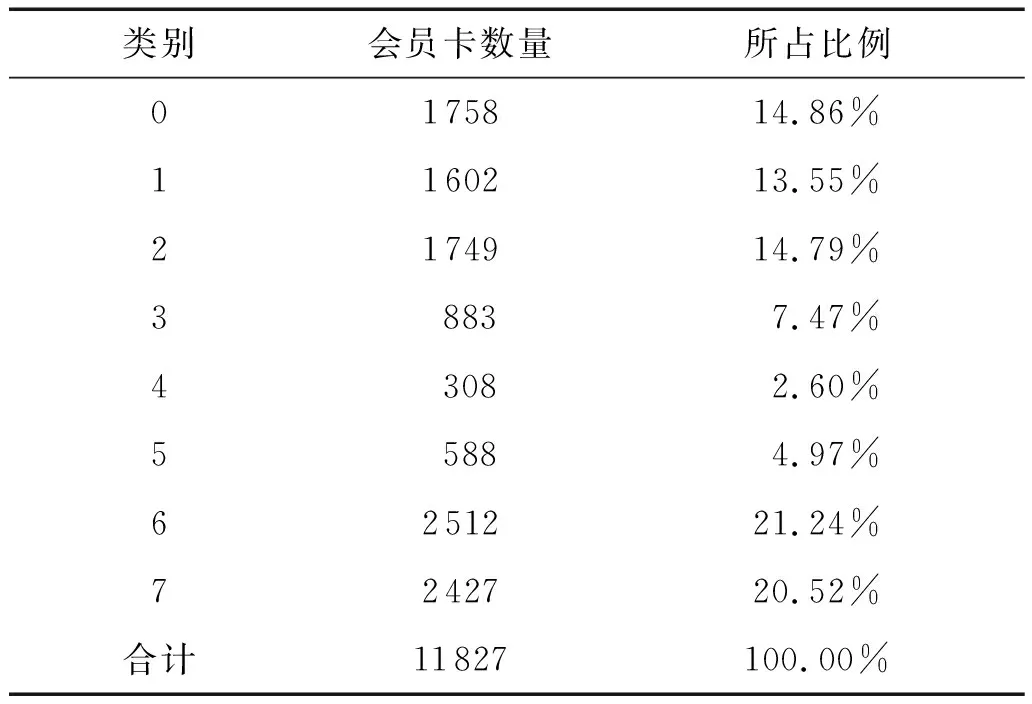
表2 第二阶段各类会员卡数量
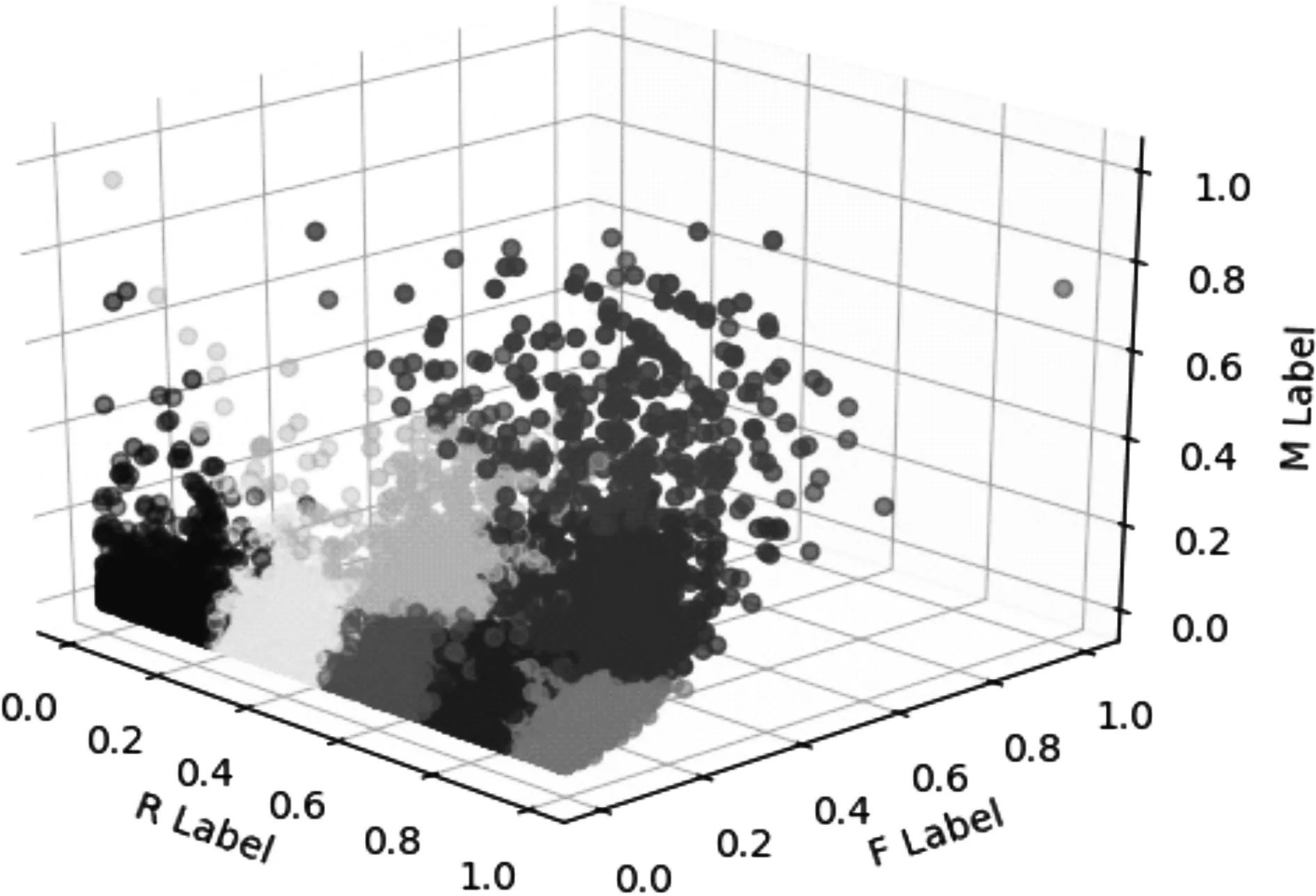
图2 第二阶段三维分类散点图
6 结果分析
将该商场会员划分为8类,其分类特征和营销策略见表3。
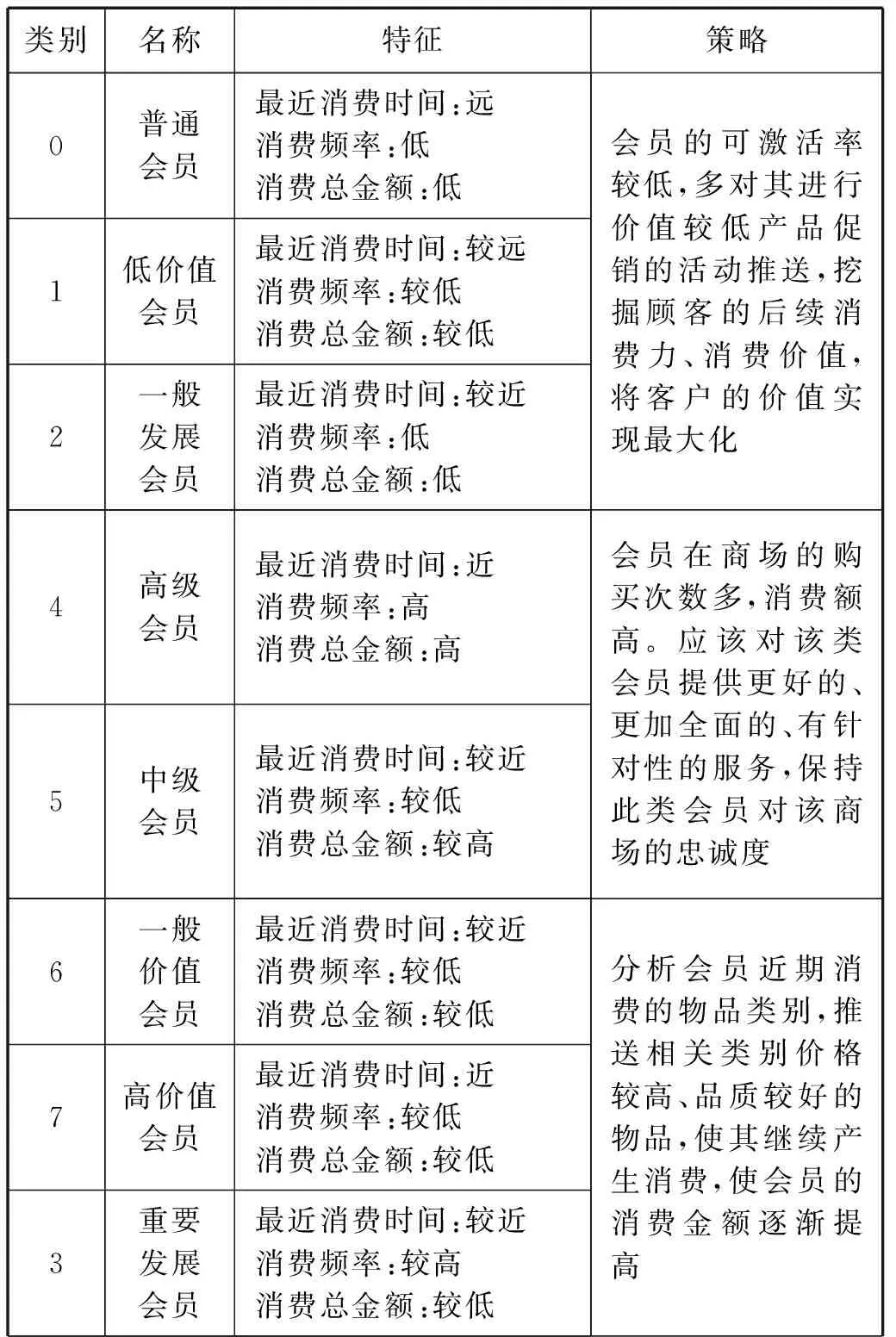
表3 会员特征及营销策略
其中,消费非常高的会员(一段时间内的消费总金额超过该段时间内平均消费金额900%的会员)划分在高级会员中。
7 结语
近年来,随着大数据分析技术的发展,对客户进行会员画像,利用会员标签细分客户类型,成为认识和了解商场会员的重要工具,也为商场制定精细化的、有针对性的营销手段提供了数据支持。
本研究根据某商场2017年10月到12月的会员销售记录,通过K-means 算法聚类分析,将该商场3个月消费的会员划分为8类。通过会员的类别标签,可以对不同类的会员使用不同的营销手段,分类进行商品的宣传、推送等,挖掘顾客的后续消费力、消费价值,将客户的价值最大化。
猜你喜欢
小哥白尼(神奇星球)(2022年3期)2022-06-06 07:39:34
全面腐蚀控制(2021年7期)2021-10-28 06:34:04
新世纪智能(高一语文)(2020年9期)2021-01-04 00:42:42
石材(2020年8期)2020-10-28 07:53:18
非公有制企业党建(2020年10期)2020-10-27 06:30:14
石材(2020年7期)2020-08-24 08:28:08
石材(2020年6期)2020-08-24 08:27:08
中国特种设备安全(2019年8期)2019-10-14 00:32:38
轻兵器(2017年3期)2017-03-13 19:15:42
世界宪法评论(2016年0期)2016-12-06 08:51:48
