
采用消息队列实现数据一致性方法①
2019-09-24 06:21满曙光周立军
计算机系统应用 2019年9期
张 杰,满曙光,刘 凯,周立军
1(海军航空大学 航空基础学院,烟台 264001)
2(烟台市公安局,烟台 264001)
随着企业级应用的业务复杂度和规模的不断扩大,传统的单体应用系统在维护、部署、扩展以及稳定性、并发性等方面,普遍存在难以逾越瓶颈,这也导致各种相对独立的传统软件系统在集成时面临的困难,如系统堆砌、问题定位难、扩展性差、可靠性不高、维护成本高等[1],为适应移动互联网高速发展以及在项目开发敏捷、精益、持续交付等应用需求背景,传统的单体应用系统面临功能重复开发、功能监控与评估(性能)难以进行,由于软件构件复用效率低,当面对业务需求变更时,使得应用系统臃肿、维护困难,频繁部署,甚至给软件测试带来更多不确定性,导致系统无法持续工作[2],此外高并发性是单体应用难以逾越的鸿沟,为解决上述问题,使用微服务(micro-service)实现组件化成为系统设计的新选择,并得到飞速发展和应用,微服务架构通过将系统按服务组件化分解,服务之间通过Http 等通信协议进行协作,并且各个服务都可单独开发、部署,最终通过服务之间组合与调用对外完成系统功能[3,4].
微服务在解决上述问题同时,也引入了诸多不确定因素,如执行一项完整的业务,需要调用多个微服务协同工作,当依赖微服务调用出现故障(操作失败),已经完成的微服务如何处理[5,6],此时主要涉及微服务的可用性与数据一致性等问题,针对上述问题,本文首先阐述了单体系统中事务与分布式系统事务的基本原理,分析了微服务在数据一致性问题上遵循的原则,提出了一种使用事务型消息队列实现微服务数据最终一致性方法,通过典型应用场景分析,给出使用RocketMQ消息队列实现了分布式数据一致性方法,通过实验表明事务型消息在解决上述问题时具有易于实现、可靠性高、并发处理能力强等特点,最后总结RocketMQ事务型消息队列实现难点及不足.
1 数据一致性基本原则
传统的单体应用系统中,通常使用一个关系型数据库,通过关系型数据库事务保证数据的一致性,这种事务有四个基本要素(ACID)[7]:原子性、一致性、隔离性、持久性.为了应对高并发的挑战,应用系统需要多个数据库来支持,可通过分布式事务来保证数据一致性,根据CAP 理论:分布式系统不可能同时满足一致性、可用性和分区容错性这三个要求,最多只能同时满足两个[8].鉴于网络硬件出现闪断、延迟丢包等问题不可避免,分区容忍性必须需要实现,同时可用性体现了分布式应用系统持续提供服务的能力,若满足一致性则需付出在满足一致性之前阻塞其他并发访问的代价[9],事实上可用性与分区容忍性优先级要高于数据一致性,所以只能在数据一致性上做出取舍,分布式数据一致性级别又可分为:
强一致性:类似于单体事务数据一致性,但实现起来往往对系统的并发性能影响大.
弱一致性:约束了数据更新成功后,不承诺立即可以读到写入的数据,也不久承诺多久之后数据能够达到一致,但会尽可能地保证到某个时间级别(比如秒级),数据能够达到一致状态.
最终一致性:作为弱一致性的一个特例,系统会保证在一定时间内,能够达到数据一致的状态.
在微服务架构中,数据访问与分布式架构相比更加复杂,通常情况下,数据都是每个微服务私有,只能通过API 的方式访问数据.这种方式可以实现微服务间的松耦合,使彼此独立的微服务更容易的进行扩展.随之带来问题是:数据不一致性既不能依靠底层数据库事务实现,也无法通过统一的事务协调器来完成数据一致性,传统的本地事务或分布式事务不适合微服务架构.
微服务架构作为分布式架构的一种,数据一致性通常采用BASE 理论,BASE 理论是对CAP 理论的延伸,核心思想是即使无法做到强一致性[10],但应用可以采用适合的方式达到最终一致性(Eventual Consitency),BASE 模型完全不同ACID 模型,该模型牺牲高一致性,获得可用性和可靠性[11].
在微服务实现数据一致性时,首先应保证调用微服务具有幂等性,幂等性是指一个操作(特定服务一次调用)至多只会被处理一次,后续调用都将返回第一次调用时的处理结果[12].
2 事务型消息一致性处理方法
2.1 一致性应用场景分析
在分布式架构中,以学员选课应用场景为例,基本业务逻辑如下:
(1)选课服务S1 负责学员执行选课操作,完成选课信息保存;
(2)统计服务S2 负责统计选课信息,执行汇总计算操作;
(3)通知服务S3 负责通知任课老师选课信息.
选课业务中体现的分布式数据一致性要求主要体现在:
(1) 选课服务S1 完成选课操作成功,统计服务S2 成功接收到学员选课信息,并进行汇总操作;
(2) 选课服务S1 完成选课操作成功,通知服务S3 成功接收到学员选课信息;
在图1展示的业务中,首先执行本地数据库事务方法,其次发布消息,当消息发布失败会导致消息发布者本地事务回滚,现实中数据库事务回滚的成本相对于消息发布失败高很多,这明显是不符合预期[13].
为了解决这个问题,可以采用消息队列作为中间件(如图2),消息队列普遍用于各微服务之间异步通讯[14],为实现以上数据一致性要求,采用事务型消息队列实现微服务S1、S2和S3 之间的提供异步通信服务,首先将选课服务S1 选课操作分解为3 个步骤完成,且封装在一个本地事务中:
(1)将选课信息发布事务型消息到消息队列;
(2)执行保存选课信息操作;
(3)根据执行步骤(2)执行结果,决定是否将消息投递给服务S2和S3.

图2 改造后选课业务
消息队列提供一种特殊类型的消息:事务型消息,这类消息的特点是:消息队列收到消息后不会立刻投递消息到消息订阅者(服务S2和S3),而是根据消息发布者应用的数据库事务状态决定消息是否投递.如果选课服务S1 数据库事务提交,则消息投递到订阅者(服务S2和S3);反之不投递.
2.2 RocketMQ 事务型消息队列
RocketMQ 是一个具有低延时、高并发、高可用、高可靠等特点的分布式消息中间件,可作为各个微服务、平台、应用之间的通用服务,还可完成异步解耦功能,即挡住前端(消息发送方)的数据洪峰,保证后端服务的稳定性[15],而对于事务消息,主要是通过消息的异步处理,可以保证本地事务和消息发送同时成功执行或失败,从而保证数据的最终一致性,RocketMQ事务型消息队列主要流程如图3所示.
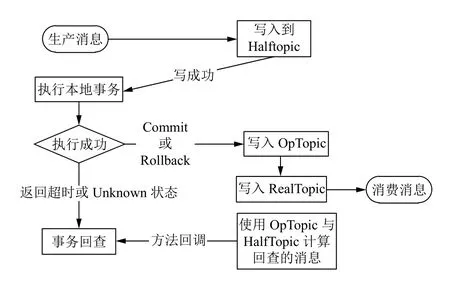
图3 RocketMQ 事务型消息队列处理流程
(1)生产者(选课服务S1)同步发送prepare 事务消息到broker;
(2) broker 接收到消息后,将该消息进行转换并写入Half Topic,写入成功后会给生产者返回成功状态;
(3)生产者(选课服务S1)获取到该消息的事务Id,进行本地事务处理;
(4)本地事务执行成功提交Commit,若失败则提交Rollback,提交超时或Unknow 状态则会触发broker的事务回查;
(5)若提交Commit 或Rollback 状态,则Broker 将消息写入到OpTopic,该Topic 的作用主要记录已经Commit 或Rollback 的prepare 消息,Broker 利用Half Topic和OpTopic 计算出需回查的事务消息.如果是Commit 消息,broker 还会将消息从Half 取出来存储到Topic 里,从而消费者可正常进行消费,如果是Rollback则不进行其他操作;
(6)如果本地事务执行超时或返回Unknow 状态,则broker 会进行事务回查.若生产者执行本地事务超过6 s 则进行第一次事务回查,总共回查15 次,后续回查间隔时间是60 s,broker 在每次回查时会将消息在Half Topic 中再写1 次.
(7)执行事务回查时,生产者可获取事务Id,检查该事务在本地执行情况,返回状态同第1 次执行本地事务一样.
RocketMQ 消息队列事务型消息一次成功投递需经3 个Topic,Half Topic 用于记录所有的prepare 消息,Op Half Topic 记录已经提交了状态的prepare 消息,Real Topic 事务消息真正Topic,在Commit 后会将消息写入该Topic,进行消息的投递.
从上述流程可以看到事务消息保证了生产者发送消息成功与本地执行事务的成功的一致性,消费者在消费事务消息时,broker 处理事务消息的消费与普通消息是一样的,若消费不成功,则broker 会重复投递该消息[16].
3 实现及应用分析
建立RocketMQ 消息服务,选课业务(S1)作为消息生产者,消息服务(M1)为选课服务和通知服务、统计服务提供中间件,通知服务(S2)和和通知服务(S3)作为消息消费者角色存在.
3.1 事务型消息生产者
选课业务作为消息生产者,主要完成本地选课业务保存、选课消息产生、提供事务回查方法.选课业务回查方法可以根据由RocketMQ 回传的key 去数据库查询,判断这条数据到底是成功还是失败.关键代码如下:

3.2 事务型消息消费
以通知服务(S3)为例说明,设计事务型消息消费者关键代码:


3.3 幂等性设计
本文中选课业务作为微服务架构设计,如果不支持幂等操作,那将会出现相同的选课信息多次推送给后续的服务,为避免上述情况出现,可将通知服务和统计服务设计为幂等操作,幂等的接口实际上就是可以重复调用,每次接口调用的结果都是一样的.
幂等设计具体实现方法:将选课的课程编号与学号作为组合主键,建立一张去重表,并且把上述主键标识作为唯一索引,实现时,把选课信息写入去去重表,放在一个事务中,如果重复创建,数据库会抛出唯一约束异常,操作就会回滚.
3.4 应用分析
在实现分布式数据一致性时,尤其是微服务之间数据一致性,为了提高并发性和可用性,更多选择采用数据最终一致性方法,在上述分析选课业务中,选课微服务S1 成功完成选课操作,并不会直接在本地事务中完成对统计服务S2和通知服务S3 的调用,而是采用异步的方式通过消息队列完成,达到最终数据的一致性,即S1 完成操作,S2和S3 收到消息.
使用事务型消息队列解决数据一致性问题时,关键点在于:当消息队列收不到事务型消息的 “提交 or回滚” 消息时,如何确保数据一致性.在分布式网络架构中,不可避免会出现网络闪短、消息队列服务短时间内不可用等情况,会导致消息队列中消息长期处于Half Topic 状态,这也是消息队列提供“事务型消息” 特性必须解决的问题,如果消息队列没有收到 “提交 or回滚”消息,则无法决定是否投递消息到消息订阅者,此时消息队列会主动询问消息生产者(选课服务S1)询问该消息的最终状态(Commit 或是Rollback),该过程称为事务型消息状态回查,具体设计方案如图4.
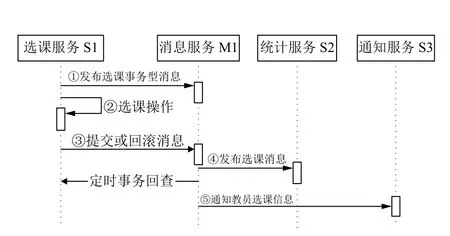
图4 消息队列事务回查
消息队列事务型消息基于“二阶段”消息实现,通过事务型消息状态回查方法,即使当消息队列没有收到 “提交 or 回滚”消息,也能保证事务型消息是否投递与消息发布者本地事务状态保持一致;在使用消息队列解决数据一致性问题时,还需要解决消息重复投递的问题,通用方法是在消费消息的微服务(S2和S3)实现幂等性,相同的选课消息至多只会被处理一次,后续的调用都将返回第一次调用时的处理结果.
4 结束语
本文总结了在处理分布式计算(微服务)数据一致性问题遵循的原则,分析实现微服务的幂等性设计的重要性,提出了一种采用事务型消息队列解决分布式微服务典型应用场景中数据一致性问题的方法,并给出RocketMQ 消息队列工作模式,分析了事务型消息队列实现数据一致性的原理与实现方式;使用事务型消息队列在处理分布式微服务数据一致性,事务消息消费端的消费方式和普通消息相同,RocketMQ 能保证消息能被消费端收到(消息重试等机制),采用事务型消息方法还需保证消息能够最终消费成功这个关键步骤,同时微服务在消费消息时,首先要保证后续业务(S2和S3) 具有幂等性,如果consumer 消费失败时,RocketMQ 需要人工介入处理,尽管这种情况出现概率极低.
猜你喜欢
中外文摘(2022年13期)2022-08-02
科学导报·学术(2020年26期)2020-10-21
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
智能计算机与应用(2016年6期)2017-05-08
青年文学家(2016年32期)2016-12-23
红领巾·萌芽(2015年5期)2015-06-16
中国信息化·学术版(2013年1期)2013-05-28
现代营销·经营版(2008年10期)2008-05-14
智能计算机与应用(2007年4期)2007-08-25
