
基于LeNet-5的编组站站内机车车号识别系统的研究
2019-09-19 11:08李瑞辰姚宇峰蒋元华
铁路计算机应用 2019年9期
李瑞辰,姚宇峰,蒋元华
(1.中国铁道科学研究院 研究生部,北京 100081;2. 中国铁道科学研究院集团有限公司 通信信号研究所,北京 100081)
目前,编组站综合自动化系统(SAM)普遍应用于我国大中型编组站,通过列车与调车的综合管控技术,提高了编组站的自动化程度与运输生产效率,最大程度地降低了作业安全风险[1]。由于无法第一时间准确获得担当主要牵引任务的机车(简称:本务机车)的信息,本务机车的综合管控技术一直难以实现。
国内外针对车号识别的研究已取得了诸多重要成果,目前,主要由自动识别设备 (AEI,Automatic Equipment Identification)识别法和图像识别法两部分组成[3]。对于AEI识别方法,现阶段大多数站场都配备有AEI车号自动识别系统,但是由于机车标签位置较低,维护困难,而射频识别(RFID, Radio Frequency Identification)标签容易损坏、丢失,所以机车AEI系统识别正确率不能保证[2]。近些年来,图像识别技术高速发展,基于图像识别方法的铁路车号识别研究也取得了一定的成果。基于颜色空间及灰度形态学的车号定位方法,能有效地自动定位、分割和识别铁路货车车号[3];针对车号区在野外使用过程中容易受灰尘或运输货物的污损,在提高货车车号识别率方面做了相关研究[4]。
本文在前人对车号识别研究的基础上,选择并改进图像识别算法,同时设计一个机车车号识别系统,实时识别驶入编组站的机车车号,并将机车车号识别结果实时共享给车站与机务段。
1 系统结构设计与实现
1.1 系统结构
机车车号识别系统组成,如图1所示。
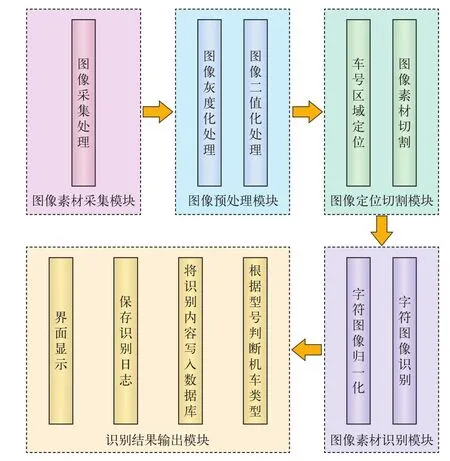
图1 机车车号识别系统模块分析图
1.2 界面设计与技术实现
通过使用.NET开发平台的WinForm搭建前端图形化界面,调用通过Python语言实现图像的预处理、图形定位切割、识别等算法实现对机车车次图像素材的识别,并通过识别结果输出模块输出机车车号与机车类型,界面如图2所示。
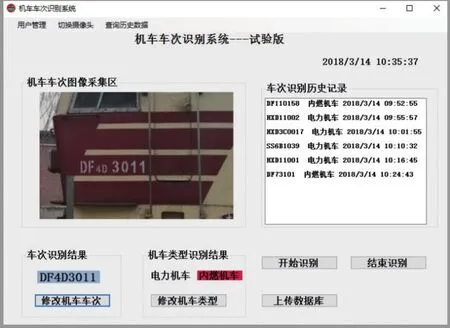
图2 机车车号识别系统主界面
高清摄像头在铁路编组站中广泛应用,可实时获取全站站场视频图像数据。因此,可以利用设置在咽喉区与站段交界处的高清图像数据,点击开始识别,系统将自动识别经过此咽喉处的机车车号,并通过识别出的机车型号与数据库内机车类型进行对比,推出通过咽喉区处的机车类型,系统支持修改机车车次、修改机车类型、查询历史识别数据的功能。
2 识别算法选择与改进
2.1 卷积神经网络
卷积神经网络是近些年发展起来的一种高效识别方法,广泛应用于手写字符识别、行人识别、人脸识别中。卷积神经网络主要由卷积层与池化层两部分组成[5]。
2.2 卷积层与池化层
卷积层主要是将前一层的特征图与一个可学习的核进行卷积,得到的结果再通过激活函数后形成这一层的特征图,每一个特征图都有可能与上一层的几个特征图建立卷积关系。卷积层数学函数表达如式(1):
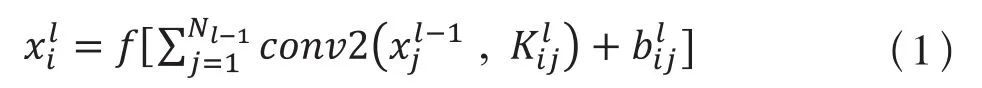
其中,l为层数为特征响应图为卷积核;Nl-1为l-1层特征图的个数;conv2(x,y)为对x,y进行卷积操作为输出图的偏置。
池化层主要是对输入的上一层特征图素材进行抽样操作,经过抽样后的特征图的图像大小改变为原来的1/2,池化层数学函数表达如式(2):
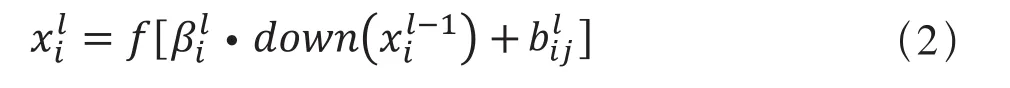
其中,down(x)为次抽样函数,bl
ij为输出图的偏置。
2.3 LeNet-5算法
卷积神经网络LeNet-5算法是由Y.LeCun提出的一个多层的神经网络,对于二维图像的特征提取有着出色的表现。LeNet-5网络模型结构,如图3所示。主要由7层组成,每一层都包括可以训练的参数。
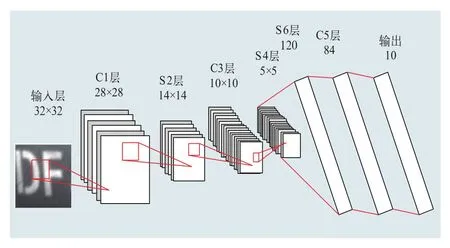
图3 LeNet-5神经网络的结构
该网络的输入是32×32的图像,其中,C层是由卷积层神经元组成的网络层,S层是由池化层组成的网络层。
(1)输入图像后,经过6个可训练的卷积核进行卷积操作,在C1层产生6个28×28的特征响应图;
(2)每个特征响应图经过池化操作后,S2层产生6个14×14的特征响应图;
(3)经过16个可训练的卷积核进行卷积操作得到具有16个特征响应图的C3层;
(4)经过池化操作,S4层产生具有16个5×5的特征向量图;
(5)将S4层的所有特征响应图向量化,输入到全连接神经网络,输出120个神经元;
(6)经过两个全连接层,到达输出层,输出层具有10个神经元,每一个神经元代表一个阿拉伯数字。通过得到的一个长度为10的行矩阵,最终确定属于哪一个数字[6-7]。
2.4 LeNet-5改进算法
LeNet-5最初是用于识别手写数字的,输入的类别数目为10个,铁路机车型号与数字相比,需要进行分类的类别数目要多很多,除了10个阿拉伯数字组成的机车号码外,还包括D、F、C、S、B、H、X、N共8个英文数字组成的机车型号。针对机车型号字符组成与手写数字之间的区别,对传统的LeNet-5进行改进,将传统的LeNet-5的输出层由10个神经元改为18个神经元。
3 机车车号识别模型训练与识别
3.1 训练与识别流程
机车车号识别模型的训练和识别流程图,如图4所示。
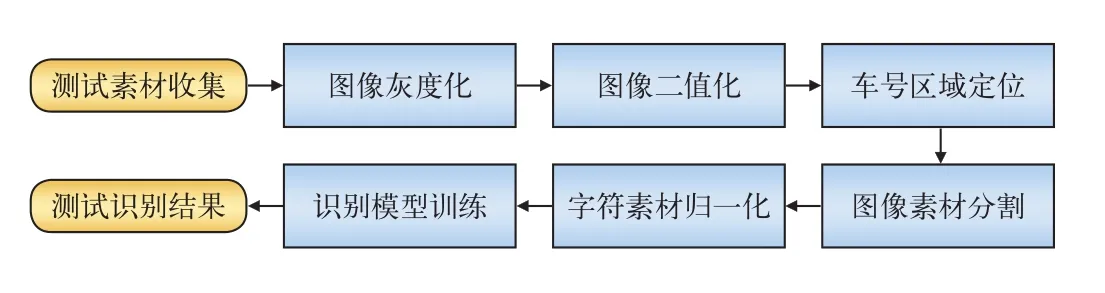
图4 识别与训练流程图
3.2 试验数据准备
为了验证改进的LeNet-5算法对机车车号的识别情况,收集了机车车次图像数据850个,建立了测试与训练使用的数据集,每组425个,其中,训练数据中有310张图像含有8个字符(如SS6B 1079、HXD1 1001),70张含有7个字符(如DF4 9422、DF7 0031),45张图片含有 9个字符(如HXD3C 0822、HXN3B 0030),共3 375个字符学习样本,测试集与训练集样本组成相同,且训练集与测试集之间没有重叠图像。
3.3 图像灰度化
为了提高识别效率,滤除掉图像中与识别无关的大量特征,对图像进行预处理,目前常用的图像灰度化主要有最大值法、平均值法、加权平均法3种方法,且每种方法都有固定的图像分量加权式。如图5所示,通过对比灰度化的3种方法,使用加权平均法对图像进行灰度化效果最好,所以按照式(3)将图像转化为灰度图像。

其中,I为灰度图像;R、G、B为红绿蓝3个图像分量。
3.4 图像二值化
由于编组站具有全天候作业的特性,所以咽喉区摄像头拍摄的图像素材由于时间、天气、季节等原因导致素材的背景和机车车号字符灰度化后会存在很大差距。为了高效获取机车车号信息,减少由于这些原因产生的噪声影响,我们将对图像进行二值化处理。即通过设定某一指定阈值,将灰度化后的图像表示成两个灰度值表示的二值图像。即背景和车号字符素材分别用两个灰度值来表示,如图6所示。

图5 图像灰度化处理

图6 图像二值化处理
3.5 机车车号区域定位
机车车号区域定位在机车号码识别中最为重要,因为区域定位准确与否直接决定后续工作的开展。采用常用的Sobel边缘检测方法进行机车车号区域的定位,使用Sobel边缘检测算子得到机车车次号码轮廓。使用图形学知识开、闭运算,利用小噪声处理对小块噪声进行去噪处理,将大块区域进行连接,定位出机车车号区域,如图7所示。

图7 图像定位处理
3.6 图像素材分割
机车车号印刷时彼此之间都留有一定空隙,但是每一个字符的宽度都大于空隙的宽度,所以可以利用机车车号排列分布规律分割法将车号进行分割。因为所有素材都经过了灰度化、二值化处理,所以背景与机车车号位置灰度值差别明显,背景灰度值为0,字符处灰度值为255。
先进行行分割,通过计算二值化后标准图像文件格式(BMP)文件中每行中灰度值为255的像素总数,如果像素总数超过阈值Q1,则认为此行为字符行。如果像素总数小于阈值Q2,那么认为此行为空白行。如式(4)所示。
阈值Q1,Q2的选择比较重要,如果选择的过大,会导致字符被切割,无法识别。如果选择的过小,会导致图像切割不明显。经过多次试验,Q1=6,Q2=3效果最为明显。
将经过行分割后的图像素材进行列分割。同样,计算二值化后BMP文件中每列中灰度值为255的像素总数,如果像素总数>阈值Q3,则认为此列为字符列。如果像素总数<阈值Q4,那么认为此列为空白列,如式(5)所示。
m为经行切割后的起始行;n为经行切割后的终止行,经过多次试验,Q3=2,Q4=3效果最为明显。
经过行切割与列切割后,得到的图像数据,如图8所示。

图8 图像分割处理
3.7 字符素材归一化
LeNet-5卷积神经网络的输入为32×32的图像素材。经过算法比对,双三插值算法对于图像某一区域的缩小放大有非常好的效果。其思想是在所需插值像素点位置选取周围16个像素点,对选取的16个像素点分别进行水平与垂直方向的三阶插值操作,并将所得结果赋值给所需插值像素点。进行水平与垂直方向插值操作的插值函数的一般表示形式,如式(6)所示。
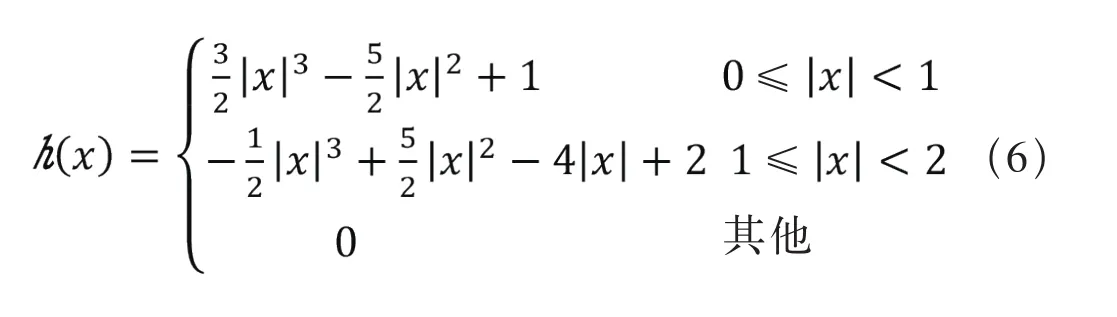
使用双3次插值算法将所有机车车号字符大小都归一化为32×32大小的字符素材,以便可以使用LeNet-5算法进行分类识别。
3.8 LeNet-5模型训练
卷积神经网络框架(CAFFE)是一种常用的深度学习框架,根据改进的卷积神经网络修改CAFFE平台中的网络结构文件和网络求解文件,通过CAFFE调用经过预处理后的图像数据进行模型训练,最终训练出稳定的分类模型,基本步骤为:(1)先进行前向传播,然后经过反向传导和梯度下降法更新卷积核,反复执行前向、反向、更新卷积核,直到满足结束条件,此时CNN训练完成;(2)使用CNN训练得到的特征向量训练SVM支撑向量机分类器,完成LeNet-5训练。
4 机车号码识别结果与分析
4.1 识别结果
使用测试集对训练完成的模型进行识别检测,训练次数与识别正确率之间的关系,如表1所示。通过识别试验结果可以发现,随着训练次数的增加,识别训练集与测试集的准确率都在增加。如果训练集的数据再丰富一些,准确率一定会更高,完全可以达到准确识别机车车次的目的。

表1 训练次数与测试集识别率的关系
4.2 错误分析
试验发现,有一些车次号识别效果并不乐观,主要是机车车次号被污染腐蚀、不清晰、机车车号图像倾斜角度过大、字符分割出现错误、图像素材经过灰度化后降噪效果不明显等原因。
5 结束语
通过研究发现,使用改进后的LeNet-5算法识别经图片预处理后的车次图像素材,识别正确率可高达94%以上。对于识别效果不乐观的情况,可以通过Hough变换对倾斜的图像进行矫正,或通过其他行之有效的预处理方法对素材进行进一步的处理。增加训练集素材数量,训练出识别率更高的模型。
目前,机车车号识别系统已在中国铁路武汉局集团有限公司襄阳北站试验,与既有的AEI配合使用。高清图像素材从车站高清货检系统处获取,识别效果良好,可以满足对机车车号识别的需求,对实现智慧型编组站提供了有力的技术支撑。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
天津医科大学学报(2021年1期)2021-01-26
哈尔滨铁道科技(2020年3期)2021-01-18
汉字汉语研究(2020年2期)2020-08-13
中国信息技术教育(2020年2期)2020-02-02
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
下一代英才(2018年4期)2018-05-21
科学与财富(2018年9期)2018-05-14
