
基于性能测试的信息系统监测与调优方法研究
2019-09-19 11:08:02李天翼杨佳愉
铁路计算机应用 2019年9期
于 澎,李 琪,李天翼,杨佳愉
(1.中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081;2.北京经纬信息技术有限公司,北京 100081)
信息系统软件作为交付给用户使用的产品,其质量的好坏直接关系到用户对产品的体验度。测试是保证软件高质量的必要手段,其中,软件性能测试是整个测试过程中不可缺少的一部分。对于铁路12306互联网售票系统,其逻辑结构复杂,系统层次划分较多,应用服务、中间件和数据库大多分布在Unix或Linux服务器上,或以集群的方式提供服务,其性能的好坏直接影响到交易量[1]。因此执行性能测试的主要目的是通过监测服务器的性能指标,发现网站的性能瓶颈,并通过调整服务器参数使系统运行达到最优。
本文旨在从信息系统的服务器瓶颈分析出发,基于性能测试过程中系统每秒处理事务数(TPS,Transaction Per Second)、响应时间和吞吐量等指标,建立一套对系统性能监测与调优的方法,为系统平稳运行提供保障。
1 系统性能测试研究
1.1 性能测试指标分析
性能测试通过使用多种测试工具来模拟大量用户发起某个业务请求的情景,从而对系统运行产生压力。在此过程中,系统监测是检查系统运行指标和发现系统瓶颈的过程;系统调优则是消灭系统瓶颈的过程。系统的吞吐量是指在给定的时间段内系统所完成的交易数,其中,互联网系统的吞吐量与用户发送的请求对服务器CPU、内存、外部接口、I/O资源等的消耗紧密关联[2]。单个用户请求对CPU消耗越高,外部系统接口和I/O响应速度越慢,系统吞吐能力越低,反之吞吐能力越高。并发数、TPS和响应时间是衡量系统吞吐量的主要参数,并发数为系统同时处理的事务数,TPS为每秒钟系统处理的事务数,响应时间为系统处理完成事务的平均时间,对于互联网系统的事务,响应时间是指系统接到请求、进行处理并返回回应的整个过程的时间。三者之间的关系为:TPS=并发数/响应时间,三者关系如图1所示。系统的吞吐量主要由TPS和并发数两个因素决定,每个系统的TPS和并发数都有极限值,在模拟大量用户请求压力下,若其中某一项达到系统最高值,系统的吞吐量就无法继续升高,如果压力持续增大,系统的吞吐量反而会下降。其主要原因是系统已超负荷工作,服务器的CPU、内存和接口资源等的消耗导致系统的性能下降[3]。

图1 并发数、TPS和响应时间关系图
1.2 服务器瓶颈分析
信息系统一般由多台服务器或集群搭建而成。一台服务器的性能瓶颈主要发生在CPU、内存、I/O和网络4个部分。系统调优是通过配置参数来平衡这4部分的运行状态,解决服务器瓶颈,使系统整体达到最优。这4个部分并非孤立运行,而是相互关联的,某个部分过高的利用率会导致其他部分出现问题,使整个系统无法达到最优。例如,I/O系统中大量的整页读取会导致数据占满内存队列,网络流量过大会导致网络控制器消耗CPU资源,从内存中向存储空间进行大批量的写操作会导致消耗CPU和IO通道资源等等。系统调优是一个诊断与解决瓶颈的过程,其难点在于看似是某个部分的问题表象,但真正产生问题的原因是其他部分过载所引起的[4]。
2 系统性能监测与调优
进行信息系统性能检测和调优需先通过业务分析来确定该系统各服务器的类型。通常电子商务类网站的后台服务器可以分为两类:重I/O型和重CPU型。重I/O型的服务器会消耗大量的内存和存储资源,原因是应用程序会使用大量的数据,而数据信息会在内存和存储系统之间传输。这种应用一般不需要大量的CPU资源,系统执行完I/O请求,CPU即转为睡眠状态,利用率较低,存储系统与服务器之间大多都配有高速专有网络,因此网络消耗也较低。通常数据库服务器属于重I/O型。重CPU型又可以称为重计算型,应用程序会使用服务器中大量的CPU资源进行批量处理和数值计算,通常应用服务器和中间件服务器属于重CPU型[5]。
2.1 系统性能检测工具
大多数Unix和Linux操作系统都装有一系列的监测工具,不同版本的操作系统中工具用法会稍有不同。部分版本的Linux甚至将监测工具作为系统安装的一部分,或者作为安装附件,管理员可以自行安装使用。系统性能监测的主要工具如表1所示。
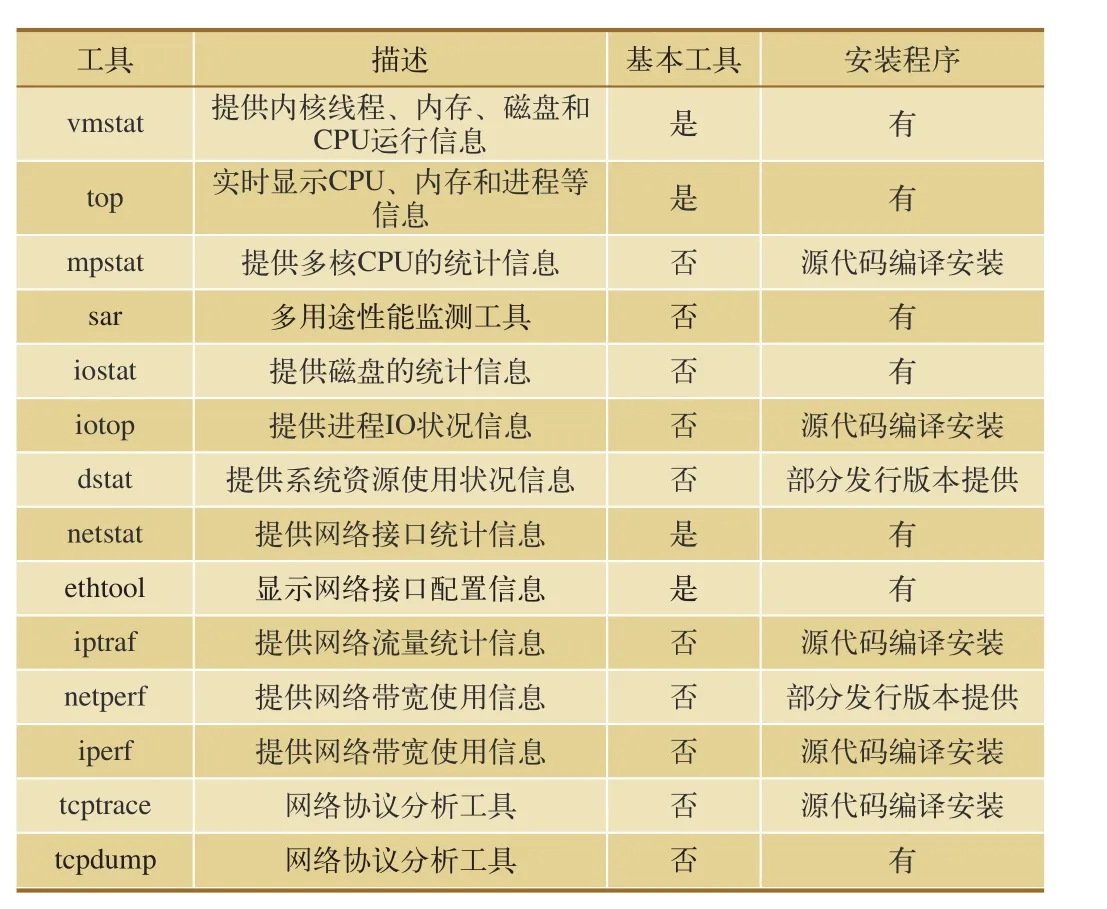
表1 系统性能监测主要工具
2.2 CPU监测与调优
2.2.1 CPU利用率
CPU的利用率主要是由它所访问的资源决定的,CPU调度器负责调度内核线程、用户线程和中断请求,并给资源分配不同的预先权。其中,优先权由高到低,分别是中断请求、内核线程和用户线程,与其相对应的指标是上下文切换量、运行队列长度和CPU使用率。
现代多核架构的CPU对于操作系统来说,每个内核都是独立的,每个线程都会被分配到固定的时间片在处理器内核上运行。如果线程在指定的时间片内没有完成或是具有更高优先级的中断需要处理,内核则会通过上下文切换将线程调度到队列中排队等候运行。每个CPU都有一个线程的运行队列,保存着正在运行的和等待运行的线程。CPU的利用率是直观查看使用情况的指标,可分为以下3个部分:(1)用户利用率,CPU执行用户线程的时间比例;(2)系统利用率,CPU执行系统内核线程和中断的时间比例;(3)I/O等待占用率,CPU由于等待I/O请求所消耗的时间比例[6]。
2.2.2 CPU性能监测
测试人员可以使用vmstat工具监测CPU运行情况。vmstat工具提供了整个操作系统全局的运行信息,并且自身运行对操作系统的影响较小,运行状况界面如图2所示,相关指标含义如表2所示。
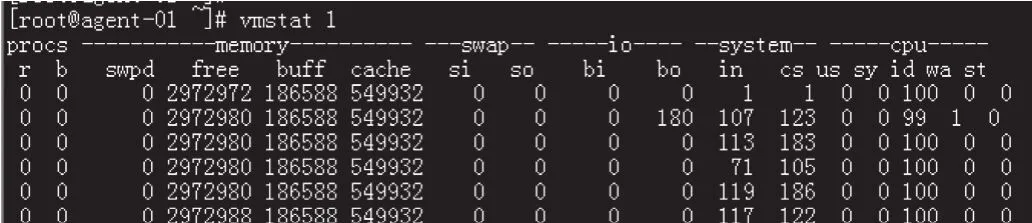
图2 vmstat工具运行状况界面
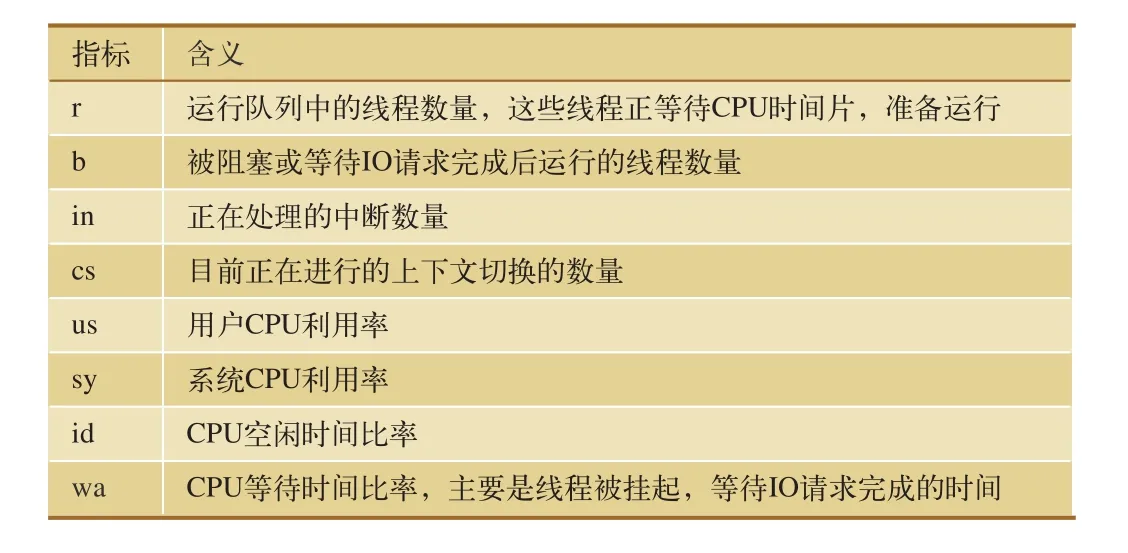
表2 vmstat工具监测CPU的主要指标
测试人员也可以使用top工具监测CPU运行情况。top工具主要用来统计并显示CPU负载,活跃进程使用CPU情况等动态信息,其中,系统负载可以分1 min、5 min和15 min进行统计显示[7],其运行状况界面如图3所示。
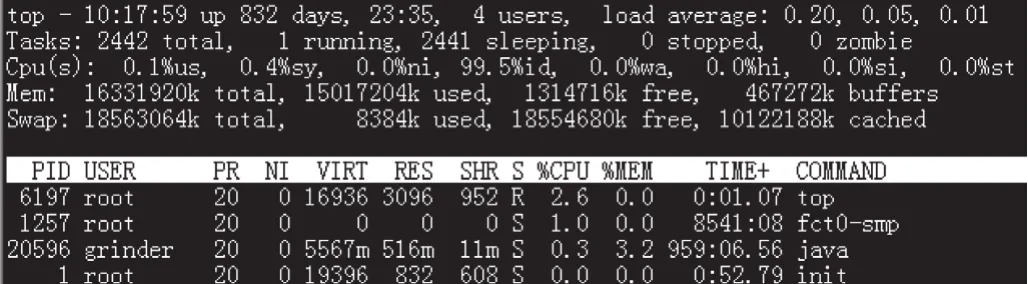
图3 top工具运行状况界面
2.2.3 CPU性能调优
(1)测试经验表明,为控制系统不超负荷运行,CPU监测过程中需进行运行队列检查,并确保每个处理器的队列不超过3个线程在排队,CPU的用户利用率和系统利用率的比例接近7:3。
(2)若CPU消耗大量时间在系统时间上,则很有可能是过载导致CPU重新调度线程的优先权。对于重CPU计算的进程和对I/O请求大的进程,两者尽可能分不同服务器处理,以免在同一服务器中产生竞争。
(3)针对目前流行的多核CPU均采用非统一内存访问(NUMA,Non Uniform Memory Access Architecture)技术,多个处理器不用共享一个集中的存储器和I/O总线,而是将处理器划分成多个节点,每个节点有相对应的本地存储空间,在Linux中对NUMA调优命令是numactl,命令代码如下。
numactl --menbind 1 --cpunodebind 1 --localalloc jboss
2.3 内存监测与调优
2.3.1 虚拟内存与系统瓶颈
目前服务器一般都配置较大的内存以满足应用程序的需求,一旦内存占满,系统会使用磁盘的部分空间充当虚拟内存使用,将目前不使用的数据写入到虚拟内存中,再次使用到虚拟内存中的数据时,则将数据读入到内存中。虚拟内存会被分成页进行管理,在x86架构服务器上虚拟内存页是4KB大小。系统以页为最小单元在内存和磁盘之间进行读写,磁盘上被划分出来做虚拟内存的部分通常被称做交换空间[8]。
虚拟内存的引入对于应用程序来说,扩大了内存容量。程序并不关心数据是在内存中,还是虚拟内存中。但由于系统读写虚拟内存的速度要远慢于内存,所以程序访问虚拟内存会使运行速度变慢。
2.3.2 内存性能监测
vmstat工具不仅可以监测CPU的运行情况,还可以统计内存状况,图2中和内存相关的指标如表3所示。
2.3.3 内存性能调优
服务器内存调优常调用malloc/realloc函数进行动态内存分配,但这样较为耗时,内存也容易出现碎片。因此程序应少进行动态内存分配,而采用内存池技术进行调优,目的是减少链接建立和线程创建的开销,从而提高性能,对于HTTP服务这样的短业务较为有效。

表3 vmstat监测内存主要指标
2.4 I/O监测与调优
2.4.1 I/O性能瓶颈
数据读写是整个服务器中最慢的部分,因其到CPU的物理距离较远,并且磁盘需要有物理转动和磁头移动的时间以完成数据的读写操作。系统访问磁盘的时间和访问内存的时间好比分钟级别和秒级别的差距,因此应尽可能减少由访问磁盘上的数据而产生的I/O次数。
系统中某些特定情况的发生会引起I/O瓶颈,可以使用系统提供的工具进行原因的辨别,主要工具有iotop、vmstat、iostat和sar等。每个工具会对I/O的某个方面提供特定的信息。IOPS(Input/Output Operations Per Second)是评价I/O调度状况的主要指标,其与多方面因素有关,如磁盘转速、磁头移动速度和读取数据速度等因素,而每次I/O读写数据的大小与系统的工作方式有关,主要分为2种工作模式:顺序模式和随机模式。其中,顺序模式需要一次读写大量的数据信息,其性能与单次最大读取数据量相关。例如,数据库系统执行大量数据的查询操作,或是流媒体服务读取大量的数据。随机模式的I/O请求数据量一般都比较小,因此效率不由数据大小决定,而主要由磁盘能支持的IOPS决定[9]。如果系统没有足够的内存空间,程序启动运行需要内存时将使用交换空间,对交换空间的读写操作都会消耗时间。由于交换空间是磁盘设备的一部分,一旦系统对与交换空间相同的文件系统进行访问,产生读写磁盘相同盘面的竞争,继而数据会堵塞I/O通道,导致系统运行速度变得更慢。
2.4.2 I/O性能监测
测试人员可以使用iostat工具监测文件系统每个分区的详细运行信息,运行状况界面如图4所示。
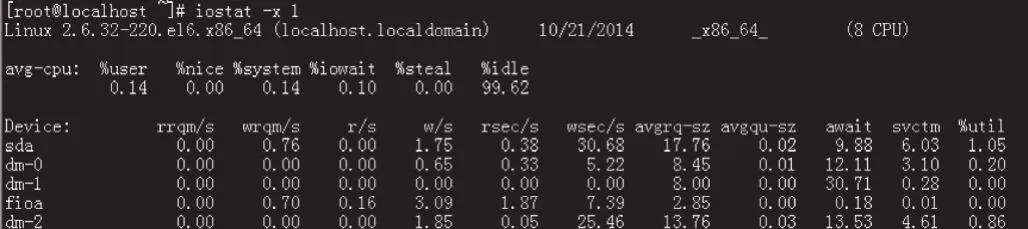
图4 iostat工具运行状况界面
使用iotop工具可以显示进程使用I/O资源的状况,输出信息与top工具类似,与iostat工具结合使用可以监测系统的I/O瓶颈,运行状况界面如图5所示。
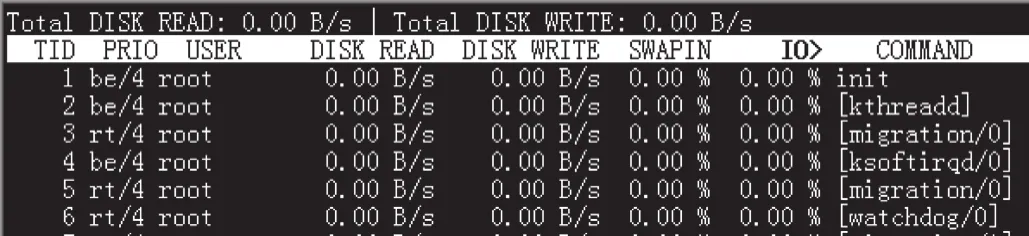
图5 iotop工具运行状况界面
2.4.3 I/O性能调优
I/O监测显示,当磁盘过载时,CPU需等待I/O请求完成,导致系统变慢。I/O性能调优的方式主要有以下3种。
(1)通过分析应用进程类型,来决定系统访问磁盘的方式,对于读写慢的磁盘需要分析和对比访问的等待时间和服务时间,以确定I/O瓶颈的具体位置。
(2)通过监测系统交换空间和文件系统,确保系统虚拟内存与文件系统I/O不会产生竞争。
(3)把内核和外设的I/O次数尽可能减少,对于读来说,读内存cache里的数据比外设快很多;对于写来说,cache写的速度也很快,但数据的实时性就会降低。因此应尽可能实现写的次数与实效性之间的平衡。
2.5 网络监测与调优
在服务器瓶颈的4个部分中,网络是最难监测的,因为网络是相对抽象的实体。对网络的监测和调优已经超越了系统的内部因素,其主要的原因有网络线路上的延迟、冲突、拥塞和包错误[10]。
2.5.1.3 网络数据包监测
与提供统计信息的网络工具不同,tcpdump工具主要用于网络抓包,可监视指定网口的网络数据包的传递方向,并输出数据包的报文头信息,为网络中的数据包分析提供强大的支持,与网络封包分析软件配合使用可以对网络数据包进行筛选和分析,tcpdump工具网络抓包界面如图11所示。
2.5.1 网络性能监测
2.5.1.1 网口速度和工作模式监测
因为在网络上存在多种不同速度和工作模式的网络设备,服务器上的以太网接口大多自动探测网络速度并设置其工作模式。使用ethtool工具可以显示并设定网口的速度和工作模式,运行状况界面如图6所示。
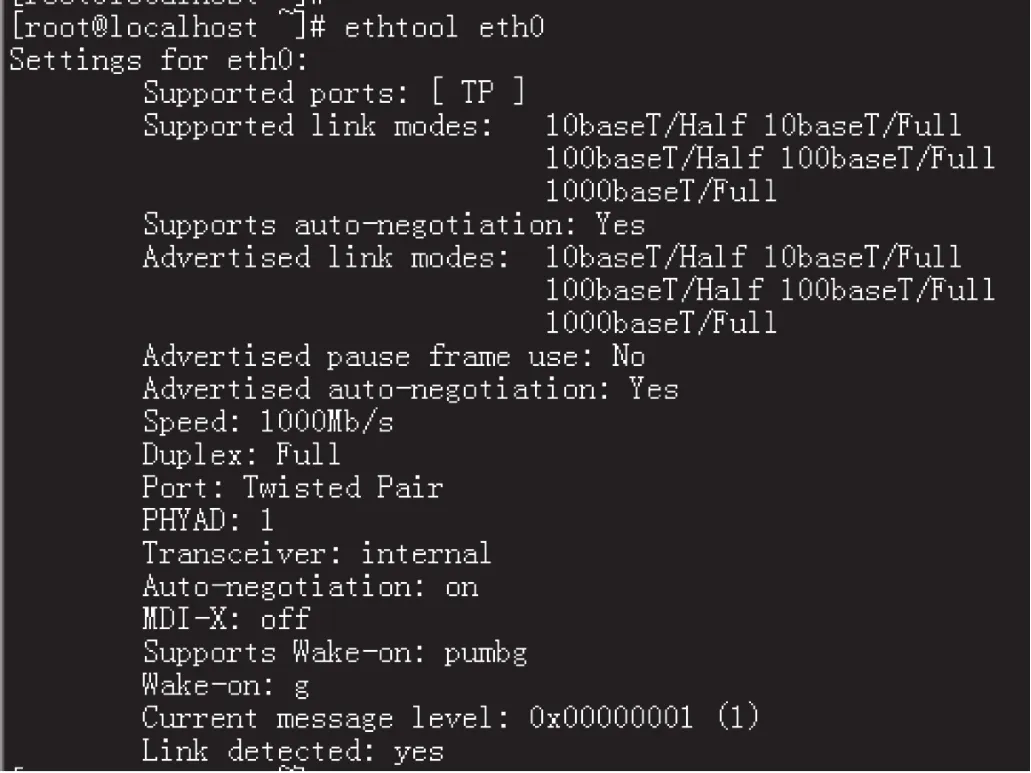
图6 ethtool工具显示网卡的状况界面
2.5.1.2 网络流量监测
由于网络上用户和服务器之间的数据会经过交换机、路由器和网络连线等设备,所以网络存在带宽问题。因此监测网络流量最好的方法是在网络中发送和接收数据,同时收集和分析网络速度和延时。
通过iptraf工具可以监测系统网卡上的流量,但其提供的可分析信息较少。netperf工具可以分析网络上点到点之间的流量,对于客户端到服务器之间网络流量分析有很大帮助。该工具有客户端和服务器2种运行模式。在服务器上以服务器模式运行netperf,在想要测试的网络上以客户端模式运行netperf,两者之间会通过网络发送和接收TCP协议包,运行结束后,netperf会统计发送和接收的数据包,并计算出网络带宽。netperf不仅对有线局域网可用,而且对无线网络监测也有效。netperf服务器模式运行界面如图7所示,运行及结果显示界面如图8所示。

图7 netperf工具服务器模式运行界面

图8 netperf工具运行及结果显示界面
与netperf工具类似,iperf工具可以监测网络上任意两结点之间流量的动态信息,提供TCP和UDP协议包的窗口大小和服务质量信息,对于TCP/IP配置调整具有指导作用。iperf工具可以在服务器和客户端模式下运行,其中,服务器端默认开启5001端口,在客户端运行可实时监测到服务器网络带宽,服务器模式运行界面如图9所示,运行及实时输出结果如图10所示。
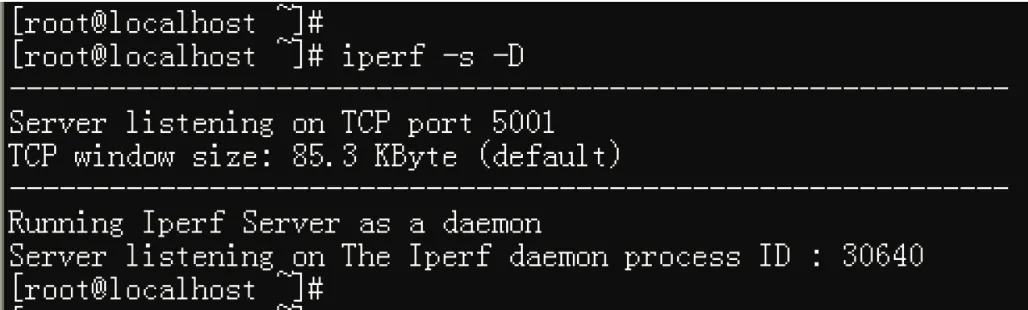
图9 iperf工具服务器模式运行界面

图10 iperf工具运行及实时输出结果界面

图11 tcpdump工具网络抓包界面
2.5.2 网络性能调优
对系统网络的调优主要针对以下几点。
(1)检查以太网接口是否运行在合适的速度和工作模式上,通过对网卡输入和输出流量的监测和统计确保系统运行在合适的网速上。
(2)通过对网络数据包的分析确定网络数据类型,设定系统对相应数据处理的优先级,以达到系统网络运行最优模式。
(3)针对基于HTTP协议应用的网络调优主要关注TCP链接开销,服务器可以支持的TCP链接数量是有限的,TCP链接配置中,KeepAlive参数定义了发送包后没有收到回应自动断开链接并回收资源的等待时长,对于HTTP短链接,一般设置KeepAlive的值为1~2 min。
3 结束语
性能测试过程中对系统的监测和调优是一个复杂的过程,这个过程一般是由表及里、由外到内的,是发现问题、定位原因、调整参数、反复执行的过程。基于本文所述的系统性能监测与调优方法,对铁路12306互联网售票系统进行多轮次、多场景的性能测试,通过监控服务器运行状态和分析系统性能指标,消除系统瓶颈,最终提升了用户体验。本文对系统普遍适用的工具和方法做了研究和总结,通过对系统各类性能瓶颈的监测和运行参数的调优,使系统运行在最佳状态,用户体验满意度得到提升。

猜你喜欢
小太阳画报(2020年11期)2020-12-10 06:50:08
小太阳画报(2020年10期)2020-10-30 01:57:15
当代陕西(2019年13期)2019-08-20 03:54:22
读者(2017年18期)2017-08-29 21:22:03
环球市场(2017年36期)2017-03-09 15:48:21
测绘科学与工程(2014年5期)2014-02-27 07:06:14
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
杭州电子科技大学学报(自然科学版)(2010年5期)2010-01-08 07:28:38
电脑爱好者(2009年13期)2009-07-07 09:52:52
计算机应用文摘(2005年21期)2005-04-29 00:44:03
