
铁路货车大数据平台总体设计研究
2019-09-19 11:08:06喻冰春
铁路计算机应用 2019年9期
喻冰春
(中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
大数据是新资源、新技术、新理念的混合体[1]。从资源角度,大数据已经成为了一种基础性战略资源;从技术角度,大数据代表了新一代数据管理与分析技术;从理念角度,大数据采用数据驱动和数据闭环的理念,利用数据进行决策、实现自我升级[2-3]。
大数据技术在铁路的应用,有利于促进数据资源共享,以数据驱动业务创新,更有助于保障铁路行车安全,增加铁路企业的经济效益。近年来的相关铁路大数据研究已经提出了铁路大数据应用顶层设计[4]、铁路大数据平台总体方案及关键技术[5]和铁路大数据应用体系架构[6]。本文旨在结合铁路货车数据资源情况,开展铁路货车大数据平台总体设计,为铁路货车大数据平台的搭建提供设计依据,推进大数据技术在铁路货车领域的应用。
1 数据源分析
1.1 数据来源
铁路货车大数据包括了货车及关键零部件从设计、制造、运用、检修到报废的全生命周期各个环节所产生的各类数据。铁路货车大数据的数据来源主要有3类。
(1)铁路货车运用维修数据
运用维修数据主要来源于铁路货车技术管理信息系统,数据资源分别存放在中国国家铁路集团有限公司(简称:国铁集团)、铁路局集团公司(简称:铁路局)、车辆段、作业场以及货车造修工厂中,各级系统存储了系统应用至今的全部数据,每日新增数据量约2 G。
(2)铁路货车运行安全监控数据
安全监控数据主要来源于铁路车辆运行安全监控系统[7],数据资源存放在国铁集团、铁路局、车辆段中,系统利用红外轴温探测、力学检测、高速摄像、声学诊断等轨边安全监测设备对运行中的货车车辆进行动态监测与管理,每日监控车辆约1 000余万辆次,每日新增数据量约120 G,目前系统存储了近3个月的图像、实时车载数据和近2年的非图像数据。
(3)相关外部数据
相关外部数据主要来源于与铁路货车运用维修管理相关的外专业信息系统,包括铁路货物列车编组、装载及运输调度信息等,数据资源主要存放在国铁集团和铁路局。
1.2 数据特征
铁路货车大数据具有5大特征:
(1)数据体量巨大,随着物联网在车辆制造维修各领域的广泛应用,接入的信息量持续增大;
(2)数据分布广泛,分布于全路范围内的众多机器设备、各级信息系统等各个环节;
(3)结构复杂,既有结构化、半结构化的传感数据,也有图片、音频、视频、日志等非结构化数据;
(4)数据处理速度需求多样化,生产现场要求实时数据分析,管理与决策应用需要交互式或批量数据分析;
(5)对数据分析的置信度要求较高,相关关系分析不足以支撑故障诊断、预测预警等应用,需要将物理模型与数据模型结合,追踪挖掘因果关系。
2 平台架构设计
2.1 总体架构设计
结合铁路货车大数据资源现状及业务应用需要,铁路货车大数据平台的总体架构由现场数据采集传输层、平台及设施层和应用层3部分构成,如图1所示。
现场数据采集传输层以实现铁路货车及关键零部件全寿命周期数据资源采集和传输为核心,在车辆段、货车造修工厂、轨旁监测设备等基层数据采集地点进一步完善数据采集内容、强化数据采集质量,实现数据汇集及本地应用,并且通过货车技术管理信息系统、车辆运行安全监控系统等将全过程数据上传至国铁集团。
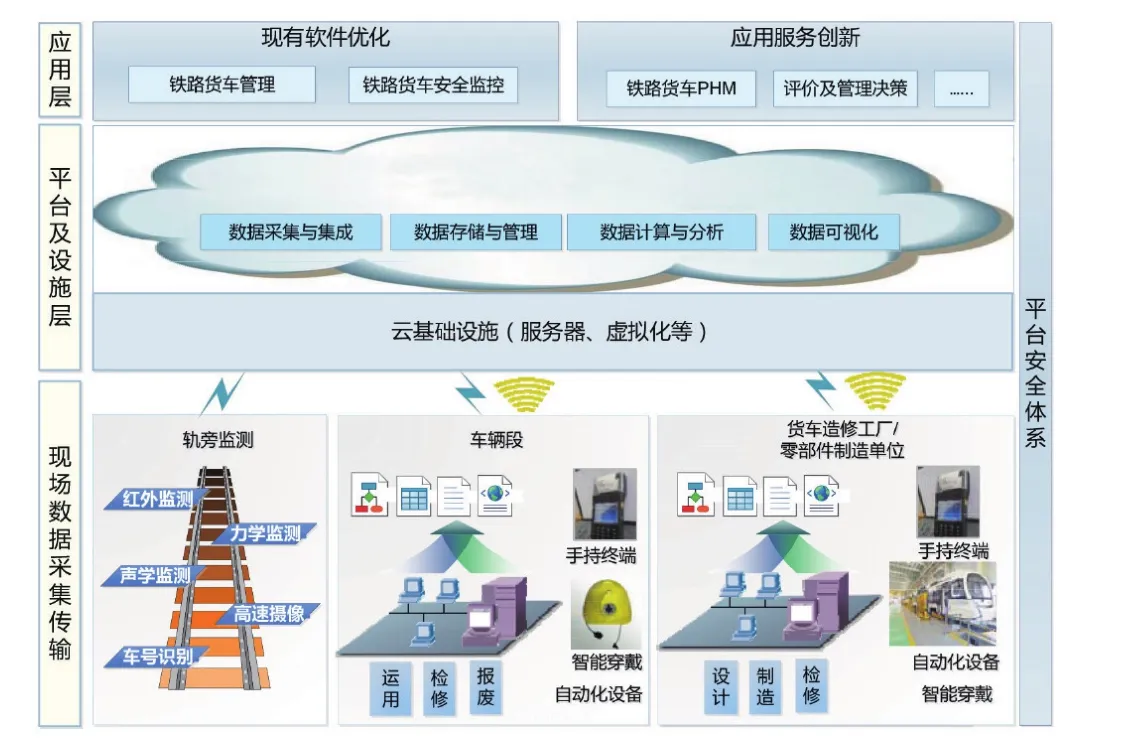
图1 铁路货车大数据平台总体架构图
平台及设施层在国铁集团构建基础设施虚拟运行环境,对数据资源进行采集与集成、数据存储与管理、数据计算与分析和数据可视化展示,通过数据统一规划、数据集成与综合治理等大数据技术,提高货车数据资产价值。
应用层实现现有软件的优化和应用服务创新。利用大数据计算分析结果支持货车技术管理信息系统、车辆运行安全监控系统等现有系统的功能优化,同时,为实现货车故障预测与健康管理(PHM,Prognostic and Health Management)[8]、大数据质量评价及管理决策等应用创新提供支撑。
2.2 技术架构设计
铁路货车大数据平台技术架构以整合、集成成熟的Hadoop生态圈开源技术为主,主要由数据源、数据采集、数据存储、数据计算分析、数据应用5部分组成,如图2所示。
(1) 数据源:包括与铁路货车大数据分析有关的数据,主要来源于货车技术管理信息系统、车辆运行安全监控系统等相关信息系统,数据类型可分为结构化数据和非结构化数据。
(2) 数据采集:通过数据抽取转换加载(ETL,Extract Transform Load)工具将原始采集数据进行抽取、清洗、转换、加载,将各关系数据库利用Sqoop进行关系数据抽取和转换,对于系统日志、操作日志等非结构化数据利用Flume进行文件转换存储,对于图片、视频等以数据流的方式通过Kafka进行采集。
(3) 数据存储:利用HDFS、HBase、Hive进行数据存储,实现货车数据资源的统一规划和分布式存储与管理。
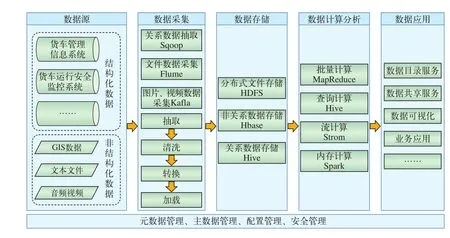
图2 铁路货车大数据平台技术架构
(4) 数据计算分析:利用MapReduce进行批量数据并行计算,利用Hive进行数据查询计算,利用Spark进行内存化实时分析,利用Storm进行数据流实时分析。
(5) 数据应用:根据业务需求和数据分析结果,提供数据目录服务、数据共享服务、数据可视化等多种数据应用。
(6) 元数据管理、主数据管理、配置管理、安全管理:提供各类基础数据管理及服务。
3 平台关键技术和应用场景
3.1 平台关键技术
3.1.1 大数据采集与存储技术
铁路货车大数据平台主要利用数据ETL、分布式存储等技术,进行关系数据库数据抽取、文件数据采集、实时流数据采集等多个功能的封装,实现铁路货车海量、多样化的数据采集与转换。结合不同的数据处理需求,采用数据仓库和分布式文件系统、分布式数据库等技术,实现对铁路货车大数据资源的统一规划和存储管理。
3.1.2 大数据治理技术
为确保铁路货车大数据完整、准确、唯一,铁路货车大数据平台采用以下数据治理技术:
(1)对铁路货车基础数据进行统一管理、及时更新、动态发布、全路共享;
(2)建立货车基础技术、新造、运用、检修等关键数据的数据标准,明确各级采集、维护、管理对象及机制,实现统一来源、统一使用;
(3)对历史数据进行重新审查和校验,剔除无效、不符合规范的数据;
(4)加强系统间数据共享和校验,对关键数据的质量问题进行分析、识别、监控、预警等,提升数据质量。
3.1.3 算法和模型
铁路货车大数据分析算法包括分类、回归、聚类、决策树、贝叶斯、支持向量机、深度学习等核心机器学习算法。铁路货车大数据专业模型主要用于评价分析和状态预测,针对具体的业务应用场景建立货车及零部件实时技术状态评价及故障预测、货车运用质量评价、货车检修质量评价、货车源头质量评价等专业模型。
3.1.4 大数据计算分析
(1)对于铁路货车运行安全监控产生的顺序、快速、连续、大量的数据,采用流计算分析方法,实现实时在线统计和预警;
(2)对于货车运用维修生产支持,采用内存计算分析方法,提供在线数据查询和分析;
(3)对于货车经营及管理决策支持,采用批量计算分析方法,满足大批量、综合数据的离线分析。
在数据计算分析的基础上结合专业模型,满足实时、离线的大数据分析应用需求。
3.2 应用场景
铁路货车大数据应用主要包括货车全寿命周期管理、货车PHM、货车产品质量反馈、维修生产过程优化、生产质量管控、设备预测性维修、供应链管理优化、智能决策管理等8大应用场景。
(1)货车全寿命周期管理
对铁路货车及关键零部件的设计、制造、运用、维修、报废数据进行全面集成,形成完整准确的电子履历档案,实现全寿命周期的可追溯管理。
(2)货车PHM
将铁路货车及关键零部件的实时运行数据与其设计、制造和历史维修数据进行融合,提供技术状态评价、寿命预测和运行维护建议,实现维修管理决策等健康管理应用。
(3)货车产品质量反馈
将铁路货车及关键零部件运行情况和运用维修数据反馈到设计和制造阶段,从而促进货车造修工厂改进设计和制造方案,加速创新迭代。
(4)维修生产过程优化
通过铁路货车大数据平台对生产进度、物料管理、经营管理等数据进行分析,提升货车制造、维修、排产、进度、物料、人员等方面管理的准确性。
(5)生产质量管控
基于铁路货车及关键零部件生产和维修的检查检验数据和“人机料法环”等过程数据进行关联性分析,实现在线质量监测和异常分析,强化生产及维修质量管控。
(6)设备预测性维护
针对货车大型在线检修、监测设备,平台结合设备历史数据与实时运行数据,监控设备运行状态,实现设备预测性维护,保障设备稳定运用。
(7)供应链管理优化
铁路货车大数据平台可实时跟踪现场物料消耗,结合库存情况安排相关供应商进行精准配货,推进零库存管理,有效降低库存成本。
(8)智能决策管理
借助铁路货车大数据平台整合生产现场数据、技术管理数据和供应链数据,提升经营管理及维修管理决策效率,实现更加精准与透明的分析评价与决策管理。
4 结束语
应用大数据技术进行数据采集、存储、分析并挖掘出有价值的信息,是将数据转化为生产力的必然选择[9-10]。本文结合铁路货车数据资源情况,基于大数据采集与存储技术、大数据治理技术、大数据算法和模型、大数据计算分析技术,提出了铁路货车大数据平台的总体设计及应用场景,为铁路货车大数据平台的搭建提供设计依据。
基于本文提出的铁路货车大数据平台总体设计方案,已经在国铁集团开展了铁路货车大数据平台搭建,后续需进一步针对货车大数据应用场景,建立货车及零部件实时技术状态评价及故障预测、货车质量评价及风险预警等专业模型,推进大数据技术在铁路货车领域深入应用。
猜你喜欢
幼儿画刊(2023年12期)2024-01-15 07:06:14
云南画报(2021年12期)2021-03-08 00:50:54
民用飞机设计与研究(2020年4期)2021-01-21 09:15:02
电子制作(2018年18期)2018-11-14 01:48:24
铁道通信信号(2018年7期)2018-08-29 01:17:04
中国交通信息化(2017年8期)2017-06-06 07:16:31
学与玩(2017年6期)2017-02-16 07:07:24
山东工业技术(2016年15期)2016-12-01 05:31:22
通信电源技术(2016年4期)2016-04-04 02:58:04
专用汽车(2016年9期)2016-03-01 04:16:52
