
一种基于知识图谱的警用统一对象描述模型及其应用
2019-09-19 10:31白云胡海曹国栋匡璐
数码设计 2019年2期
白云,胡海,曹国栋,匡璐
(1.成都市公安局信息通信处;2.成都市公安科学技术研究所,四川成都,610017)
引言
近年来,全国公安机关深入实施警务大数据战略,各地公安大数据应用得到蓬勃发展。随着海量数据的汇集,数据治理成为深化大数据应用的重要工作。由于公安工作的特殊性,公安大数据多源、异构、自治、高维、低质的特征非常明显,在数据治理过程中数据的清洗、转换和再组织一直是警用大数据系统的重要内容。这其中数据再组织一直是警用大数据的一个重点。在公安信息化早期,数据再组织主要通过建设专题库实现。信息系统数据从业务库进入专题库的过程中,通过一系列转换后成为具有某个公安业务属性的专题数据,从而支撑对应的应用。在数据仓库技术普及后,建立数据仓库成为数据再组织的重要内容。然而,专题库往往基于某个业务需求制定的规则而建立,其适用范围必然收到业务的限制,甚至在规则不够普适的情况下更受到规则的限制,造成专题库的应用范围较窄。随着公安信息化的深入,数据汇集加大,数据共享需求宽泛后,专题库建设也愈发频繁,不可避免的因为各种原因造成建立很多专题库,但其中又存在大量的冗余数据项。而数据仓库更适合统计分析,在以OLTP为主要应用的场景,数据仓库并不能很好的支持。因此,在数据仓库出现后,公安信息化部门不仅要维护专题库,还要维护数据仓库,数据维护压力更大。在RMDBS技术环境下,随着数据的增长,无论是专题库还是数据仓库规模不断增加,其性能增长明显滞后于需求发展,而维护复杂度却显著超前于数据增长。大数据技术出现后,基于分布式文件系统和列式数据库技术能够有效满足超大规模数据库应用需求,但是在警用大数据建设应用过程中,我们发现,仅仅使用大数据技术在数据治理过程中仍然体现出被动性。主要表现在无论是使用Hive还是HBase,使用MapReduce或者Spark,在面对公安应用场景时存在计算复杂、效率不高的情况。因为公安应用场景重点在于对公安关注的对象,这种对象可能是人、地、案、事、物等公安五要素的一个多个,及其吃住行消乐网等行为的分析。这种分析是多元的,对数据要求是多源的,只使用传统大数据技术仍然会陷入过往专题库建设的困境,即对不同应用需求要么建立专题库,要么使用诸如虚拟表等技术临时组织,这样虽然能满足需求,但实践表明效率不高。特别是公安民警在使用大数据系统时,由于线索掌握不足,多数时候查询精确度不高,在多人并发时系统性能下降非常明显。而这种方式在面对更复杂的查询,如“张三密切联系的人”等,更多是依靠人工定制的方式建设专属功能,但这种方式显然难以满足在大数据应用普及下层出不穷的需求。
在公安大数据建设中,需要一种统一的描述模型,用于对公安关注的对象进行描述,并具有较好的普适性能够用于公安业务的不同场景而不需专门针对业务定制数据模型。这种模型既要具有丰富的社会属性,能够表达出不同种类、不同属性的社会生活中公安关注的对象(后文为表述方便,我们均统一称之为对象),同时又能够便于在社会关系分析中使用。在构建社会关系网络过程中,我们发现一般的社会网络缺乏语义的支持,在进行社会关系分析时灵活性不高,语义网络具有较好的支持性,如果加入恰当的领域知识或本体,则在进行知识推理的同时,实际上也能够作为基本的模型来使用。因此,在参考知识图谱有关概念的基础上,我们提出一种基于知识图谱的警用统一对象描述模型,实际应用表明其能够较好满足当前公安大数据应用场景下的大多数需求,具有较好的描述性、推理性和性能。
1 知识图谱的概念及应用
知识图谱由Google于2012年5月17日正式提出[1],最初是为了提高搜索引擎的能力,提升搜索质量,让用户获得更好的搜索体验。其本质是Google的语义网络知识库[2] [3],采用语义检索技术从多种信息源收集与某一主题相关的实体或概念,以及他们之间的关联所形成的网络图,图中的节点对应实体或概念,图中的弧对应实体或概念之间的关联关系。知识图谱为互联网上海量、异构、动态的大数据表达、组织、管理以及利用提供了一种更为有效的方式,使得网络的智能化水平更高,更加接近于人类的认知思维。随着智能信息服务应用的不断发展,知识图谱已被广泛应用于智能搜索、智能问答、个性化推荐等领域[4]。
虽然知识图谱最初是用于网页中的知识的建模,但是由于网络中的信息本身就反映了现实社会,因此知识图谱建模的过程,将网络空间包含的各类实体关联知识用有效的组织方式存储,其实质反映的是社会生活中各类实体及其之间的关联关系,知识图谱中实体的概念就自然被扩大为广义对象,包含世界中客观存在的事物以及人类思维空间中的概念[5]。因此知识图谱近年来已逐渐从传统的知识分析应用扩展到对社会实体及其关系的研究和应用中,特别是在行业知识图谱应用领域得到广泛应用。另一方面,知识图谱具有适用于表示和融合碎片化知识的优点,不仅给出了局部知识到全局知识的统一表示形式加速知识融合,也简化了碎片化知识间关联关系的搜索[6]。知识图谱的这两个特点特别适合公安领域应用。一方面,公安机关面向的对象就是社会上各类个体,主要工作内容就是分析个体及个体间的关系并开展相应的工作;另一方面,公安机关获取的信息天然就是碎片化的,但是公安工作必须要将碎片化信息整合为全局性信息才能正确开展。因此,知识图谱对公安工作具有很好的适应性,同时知识图谱也给出了一种全局知识统一表现形式,对警用大数据建设提供了很好的启发。
当前对知识图谱的研究比较多,官赛萍等总结了当前主要的面向知识图谱的知识推理技术[7],李娟子等对知识图谱的知识表示、构建和应用进行了研究[8],刘峤等重点研究了知识图谱的构建技术[9],杨玉基等提出了一种“四步法”的知识图谱构建技术[10],张香玲等对实体搜索技术进行了研究[11]。这些研究更多是针对网页等半结构化、非结构化的通用型知识图谱的一般性技术。在行业应用领域,陈德华等提出了一种基于深度学习的临床领域时序知识图谱链接预测模型[12],金贵阳等采用知识图谱技术在钢铁企业中应用取得了较好效果[13],结合国内其他的一些文献可见,当前在行业领域的知识图谱应用主要还是用于文档分析,服务于智能搜索。针对公共安全领域的知识图谱研究除了情报学领域是主要应用外,冯元为对公安情报工作中关注的信息采用知识图谱进行建模和分析[14],Neumann等对涉毒资金洗钱采用语义网进行分析[15],Szekely等使用知识图谱减少人口交易[16]。但是这些公共安全领域应用仍然主要基于Web的分析和应用,多从语义解析上来建立实体间联系,且主要应用于某一个具体的应用中。
公安工作场景下使用知识图谱,需要结合实际情况做具体分析,采取合适的做法。当前在公安大数据建设过程中,汇集的海量数据来自于各种途径,而不仅限于网络,但得益于长期的结构化数据积累,很多在Web环境下困扰知识图谱构建的语义问题,在公安业务环境下已通过人力进行了语义的解析和清晰的归类,数据的可信度较高,语义的歧义性较少。如电子警察采集的车辆过车数据,本身是比较可信的,即使车牌识别错误,也不存在可能是A车牌或可能是B车牌的问题,错误车牌也是准确值。又如户籍业务产生的数据,一个成都户籍名叫范冰冰的女生,肯定不是影星范冰冰,因此公安知识图谱构建较其他领域可能在实体、实体属性和直接关系构建上会相对简单一点。但是公安领域的实体间关系更为复杂多变,因此关系与关系之间的推理机制会相当复杂。如甲与乙是同学,乙与丙是同学,并不代表甲与丙是同学,即使甲与丙是同学,也不代表甲与丙相识,这种情况下基于知识图谱的推理就需要更多的参数。
经过反复研究,我们认为在公安大数据应用中,需要使用知识图谱来进行知识检索。在这种检索过程中,我们将其内涵进行扩展,让这个知识图谱成为公安视角下社会态势的反映,从而成为一种警用大数据的社会描述模型,进而我们将其作为大数据应用的基础层,统一用其来支撑各类应用,成为了一个统一的警用大数据模型,用来描述各类对象,对象间的关系,以及对象集合的各种状态。
2 一种警用统一对象描述模型PUODM
2.1 PUODM的有关定义
警用统一对象描述模型(Police-used Unified Object Descriptive Model, PUODM)参考了知识图谱的三元组定义,结合公安工作实际增加了更多的元素和属性。
定义1:对象。对象是民警关注的人类社会中的个体或概念,这种个体可以是物理存在的,也可以是虚拟存在的,在PUODM中都作为类似于知识图谱中的实体,以节点形式存在,用O表示。每个对象o∈O,有 o=(id,P),其中id是对象的唯一标识,P是节点o的属性的集合。
定义2:关系。是对象间关系的简称,是现实社会中对象与对象之间的具有社会属性的彼此关联,在PUODM中类似知识图谱中的关系,以边的形式存在,用R表示。每个关系r∈R,有r=(rid,rP),其中rid是关系的唯一标识,rP是边r的属性的集合。
定义3:对象图。是对现实社会中多个对象及关系的具体的反映,在PUODM以图的形式存在。用OG表示。
定义4:警用统一描述对象。是一个三元组,PUODM=(O,R,O),对于OG有OG⊆PUODM。
定义5:属性。属性是刻画实体或关系内在特性的,所有属性都是二元组p=(av,γ),其中av是属性-属性值对,γ是属性的可信度(reliability),取值为[0..100]。
定义6:属性有效时间。属性的属性值是一个二元组(v,τ),其中v是属性具体的值,τ是属性值的有效时间段。超出这个时间段属性值无效,即属性无效。
针对以上定义,我们设定如下公理:
公理1: 单向性。所有关系都是单向的。关系单向用oi→oj表示。如果两个对象间互有关系,用oi→oj和oj→oi分别表示。
公理2: 关系传递性。所有关系都是可传递的,即∀oi→oj, oj→ok,则有oi→ok。
公理3: 关系传递可信度不保证。关系传递过程中,新的关系的属性可信度γ可能会因为传递而发生变化,甚至变为0。
公理4: PUODM不删除原则。PUODM中的所有元素,无论是对象还是关系,以及其属性,一旦确定即不可删除。
为便于OG构建和使用,我们在PUODM中约定所有传递的关系,除非应用需要,不作为新的一条关系在OG中存储。
特别说明,以上定义和公理,以及约定都是根据公安工作实际特点而专门设定的,与一般意义的知识图谱的定义有所不同。
2.2 PUODM的构建
由于公安的现有数据多为结构化数据,大量的非结构化数据如视频、图片等也通过图像识别等进行了结构化的摘要,所以PUODM的构建主要基于结构化数据开展。又由于我们的结构化数据基本具有较好的语义,因此和文献[10]提出的“四步法”相比,领域本体构建和语义标注两个步骤相对简化。我们将PUODM的构建分为基础构建、关系补全、更新融合三个步骤。其中基础构建是以公安掌握的现有数据资源为基础,构建出初始的PUODM,相当于知识图谱的知识抽取阶段。关系补全是在初始PUODM基础上,计算出隐含的关系并增补到PUODM中,更新融合则是进一步通过计算对PUODM的对象和关系进行更新,或增/改属性,或增/改关系,这两个步骤相当于知识图谱构建的知识融合阶段[4]。在基础构建步骤中,我们将公安掌握的数据分为基础类、属性类、行为类三类。基础类包括人口信息、车辆信息等描述公安要素的基础信息,属性类是公安工作中产生的对公安要素的描述性信息,如嫌疑人信息、车辆违章信息等,行为类是公安机关掌握的关于公安要素因为某种行为而产生的具有时空属性或与其他要素有关的信息,如盘查信息、走访信息等。基础构建完成后即表明基于显式数据的PUODM构建过程已经完成。关系补全则需要通过计算,主要通过规则完成。之所以主要通过规则完成是因为公安工作特性决定了我们对于关系的准确性特别重视,因此关系补全阶段主要完成是一些具有很高可信度的关系的补全。如财物所有关系:与户主是夫妻关系的女性,其丈夫所有的车辆与该女性也有所有关系等。更新融合则通过更为复杂的计算方式对对象的属性和关系进行调整修改。这方面涉及的技术较多,包括基于各种聚类、分类和机器学习算法的实体对齐、关系相似度计算等。我们在应用中对许多算法进行了测试,由于数据本身的稀疏性和数据覆盖面的原因,纯粹通过计算的更新融合在准确度上不是特别高,应用场景目前还局限在比较特殊的几个业务场景下,但是基于规则+计算的算法具有较好的准确度。限于篇幅和内容性质这里不做更多阐述。更新融合产生的新的对象属性或关系的可信度一般不太高,可作为工作中的参考。如果可信度经证实可以达到很高的标准,如95%以上,可更新到关系补全中作为关系补全的规则或算法。
PUODM构建后,包括人、车、房等物理实体和案件、警情等概念实体,以及虚拟身份等虚拟实体都转化为了对象,“有车”、“违章”、“偷手机”、“同案犯”等社会实体间的关联都转化为了关系,以一张图的形式表达了社会状态。随着新的数据到来,基础构建、关系补全、更新融合的“三步法”重复对PUODM进行迭代更新。构建示意图如图1。
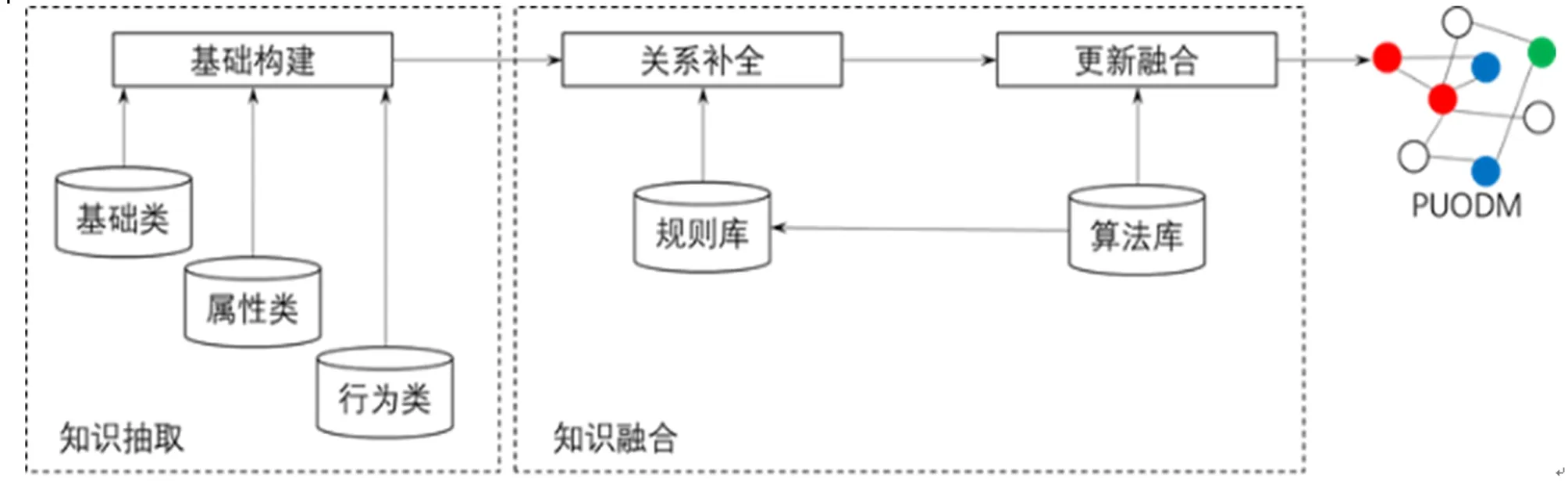
图1 PUODM构建示意图
2.3 PUODM的使用
构建PUODM后,警用大数据常用的智能检索、社会关系分析和统计预测等就转化为对图的操作。常用的智能检索转化为对节点的属性的查询。一方面,由于PUODM在构建过程中就将属性和节点进行了关联,因此对查人、查车等直接检索节点即可。另一方面,诸如“张三的密切联系人”、“密切联系张三的人”等查询就简化为对对象的关系的查询。社会关系分析转化对边的遍历。通过对属性值、有效时间段、可信度的综合计算,可以确定对象间的关系及关系可信度,按照六度空间理论,理论上所有节点都将建立其6跳以内的关系,对于民警线索摸排非常有用。而统计和预测就转化为对OG子图的综合计算。
由于PUODM相比其他模型,在引入知识图谱技术后,既包含了实体间的关系,又包含了实体的属性,我们在大数据应用的研发过程中也发现,PUODM基本能够将支持大多数的大数据应用场景并具有较高效率,因此我们将PUODM抽取出来,作为整个大数据架构的一个中间层,作为数据即服务(DAAS)的最底层,从而用一个统一的对象描述模型实现对社会态势的通用化表达,满足上层各类应用的数据描述和计算需求。目前尚未见行业内有类似研究。
3 PUODM使用效果
我们将PUODM在一个警用大数据平台中采用Neo4J加以实现。经过2年运行,实践表明PUODM能够较好的完成多种警用大数据应用场景下的数据处理任务。目前PUODM已拥有各类对象超过10亿个,属性数十亿条,关系数十亿条,日均支持各类查询10多万次。和采用POUDM之前相比,大数据平台的使用性能得到明显提升。一是数据组织能力成倍提升。以前实现多数据的统一展现必须在最初就设定好需要展现的数据种类并形成数据集,且该数据集专用于数据呈现,如果运行途中需要增加新的数据种类,必须重新组织数据,所需耗费时间超过一周,对计算资源开销也极大;而且数据种类不超过10种,因为数据种类过多数据载入时间将过长。使用后由于对单个对象查询转化为对节点的属性的查询,单个对象(实体)的信息展现已支持超过数十种数据种类,全部载入时间较以往缩短1倍以上,使用高峰期卡顿现象明显减少。图2是数据集中展现的图例。
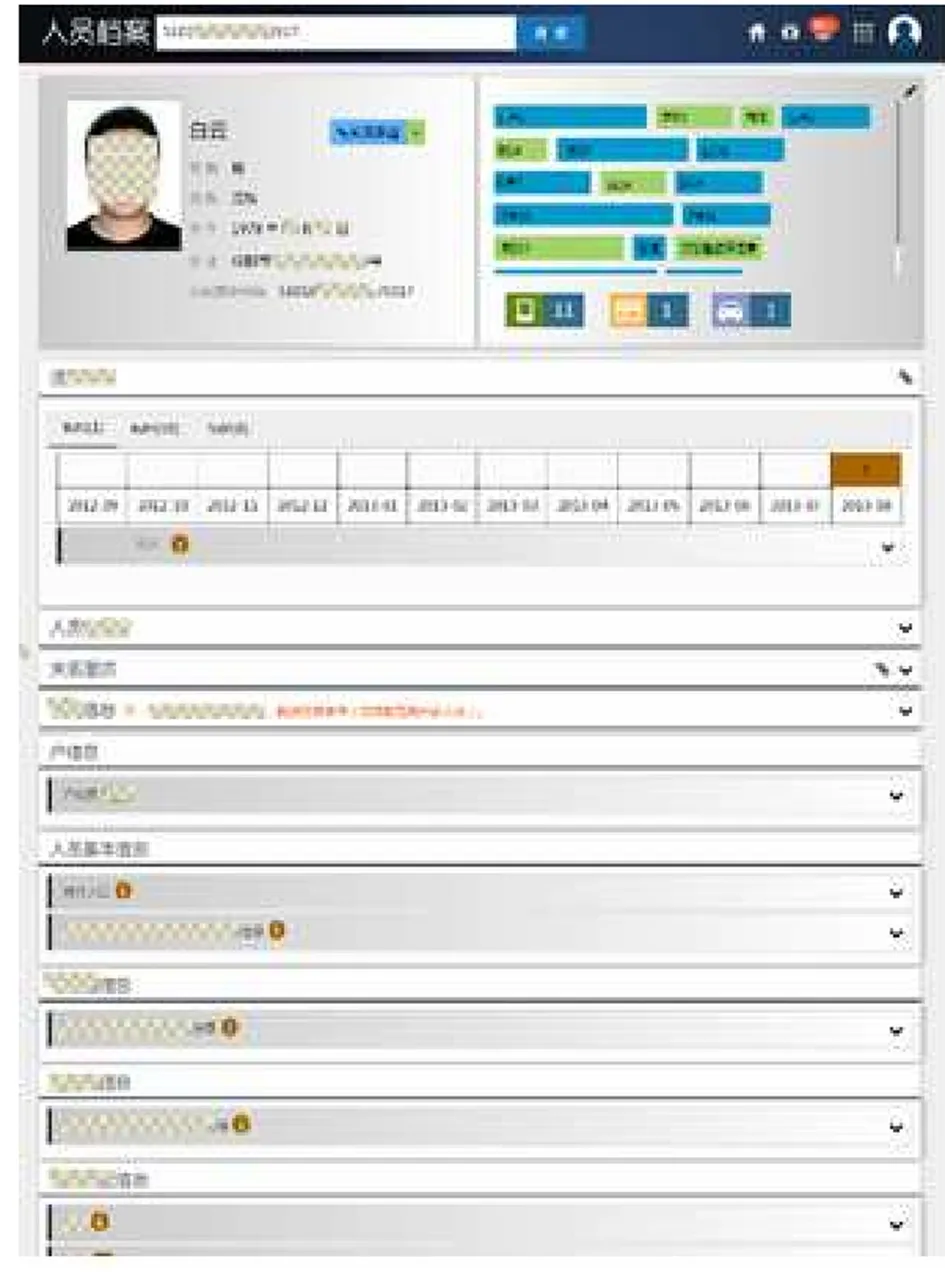
图2 数据集中展现图例
二是关系分析功能极大增强。以前关系分析功能只适用于几类关系的简单分析,且效率较差,如3级关系分析约需5分钟以上,超过4级分析经常失败。使用PUODM后可分析关系种类达到数十种,六级关系计算耗时可控制在1分钟以内。图3是关系分析的图例。
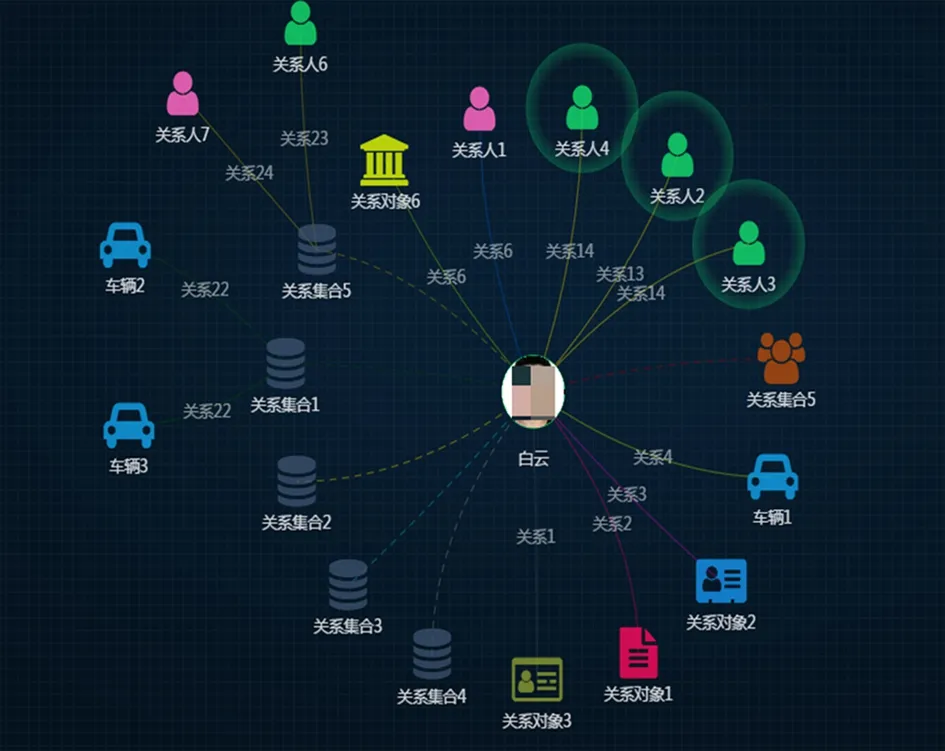
图3 关系分析图例
三是预测预警功能得到强化。由于PUODM将各类对象统一描述,因此在开展预测预警时数据使用变得更加简单,且性能更好,使得预测预警功能变得可行。
4 结束语
本文基于公安机关在大数据应用中的研究,提出了一种基于知识图谱的警用统一对象描述模型,用于对多源、异构、自治、高维、低质的数据进行数据治理和知识表示,解决警用大数据应用中异构数据使用繁琐、效率不高等问题。实际应用表明,由于警用大数据主要面向现实社会,且数据具有较为明显的行业特性,本文提出PUODM能够较好地满足公安机关的应用需求。
下一步工作重点一是PUODM知识推理机制研究。由于社会关系的复杂性,导致PUODM的关系传递时的可信度变化也非常复杂。现阶段主要依靠规则方式确定传递时可信度的变化,一般用于具有极高可信度的关系的传递,对可信度不高的关系传递则引入大量的人工研判。通过机器学习动态自主计算关系传递时可信度的变化,既可以减轻民警的工作压力,更可以自行丰富PUODM的关系,发掘更多的隐含线索。二是相似度计算算法优化。受限于数据类型、关系可信度等限制,现在相似度计算算法还比较简单,使用场景限制比较严格。如何创新警用大数据中的相似度计算算法也非常必要。
猜你喜欢
中国工作犬业(2022年10期)2022-12-06
北京航空航天大学学报(2022年8期)2022-08-31
现代世界警察(2022年8期)2022-08-19
中国工作犬业(2022年4期)2022-04-28
少先队活动(2020年12期)2021-01-14
水上消防(2020年2期)2020-07-24
Traditional Medicine Research(2020年1期)2020-01-15
科学导报(2019年71期)2019-12-16
新城乡(2018年6期)2018-07-09
环球时报(2017-08-01)2017-08-01
