
中文词间词和词内词预视加工的差异:词间阴影的作用*
2019-09-13 07:34关宜韫宋悉妮郑玉玮张颖靓
心理学报 2019年9期
关宜韫 宋悉妮 郑玉玮 张颖靓 崔 磊
(1山东师范大学心理学院, 济南 250358) (2济南大学教育与心理科学学院, 济南 250022)
1 问题提出
阅读是一个复杂的认知任务, 读者在进行阅读时眼睛的运动主要分为注视(fixation)和眼跳(saccade)。个体阅读时的信息主要是在注视时获得, 而眼跳的目的是使新信息落在视网膜的中央凹处(fovea), 即视觉中央的2°视野范围。在中央凹周围, 即视觉中央的2°~5°左右的区域是副中央凹(parafovea), 这一区域的视敏度显著下降。因此, 在阅读中读者必须移动眼睛将新的阅读内容呈现在中央凹视觉区内(Rayner, 1998, 2009)。有大量的研究显示, 读者不仅能从中央凹区域获取信息, 还能通过预视加工从副中央凹区域获得一定的信息, 从而加快读者的阅读, 这种效应称为预视效应(preview benefit) (Rayner, 1998)。
预视加工对读者的阅读效率具有很大的影响, 大量的研究表明, 当预视词被掩蔽而无法得到预视加工时, 阅读效率会大大降低(Perea, Teiero, & Winskel, 2015; Pollatsek & Rayner, 1982)。因此, 眼动控制研究领域中的两大模型对阅读过程中的预视加工进行了详细的描述和预测。串行模型认为, 注意是按序列分布的, 即注意一次只能聚焦在一个词上, 只有在当前注视词加工完成之后, 注意才能转移到下一个词上, 并开始对下一个词进行加工(Rayner, White, Kambe, Miller, & Liversedge, 2003); 而并行模型认为, 注意在空间上是平行分布的, 可以对视觉区域内的所有词同时进行加工(Engbert, Nuthmann, Richter, & Kliegl, 2005)。两种眼动控制模型对预视加工的解释和预测成为当前视觉认知加工领域争论的热点问题。
1.1 词间词与词内词的预视加工
研究者考察预视加工时, 通常采用边界范式(Rayner, 1975), 即在注视词和预视词之间有一条隐含的边界, 在眼睛越过边界之前, 目标词位置呈现的是预视词; 一旦眼睛越过边界, 预视词立刻被目标词所取代。目前已有的关于预视加工的研究, 隐含的边界均是设立在词与词之间, 即预视位置的词和当前注视的词属于不同的词(词间词, between words)。研究者发现, 英文词间词的预视效应大约是30~50 ms (Rayner, 2009)。但是, 近期研究者发现, 隐含边界的位置会影响预视效应的大小。Hyönä, Bertram和Pollatsek (2004)首次将隐含的边界设置在词内, 即预视词和注视词同属于一个复合词(词内词, within words)。实验结果显示, 当边界位于复合词词内时, 读者能够获得80 ms的预视效应。研究者认为, 词内词的预视效应大于词间词可能是由两个原因导致的:首先, 词内词的两个词素之间没有空格, 因此, 与词间词相比, 预视词距离注视点更近, 从而导致产生了更大的预视效应; 其次, 对于词内词, 隐含边界前后的两个词素同属于一个语言单元(复合词), 而词间词位于边界前后的两个词分属于两个语言单元, 从而导致词内词产生了更大的预视效应。
为了检验Hyönä等人(2004)的第一个假设, 即空格对预视加工的影响, Juhasz, Pollatsek, Hyönä, Drieghe和Rayner (2009)选取了有空格的复合词和没有空格的复合词(例如basketball vs. tennis ball), 这两类复合词的两个词素均同属于一个语言单元。结果显示, 无空格复合词的预视效应显著地大于有空格复合词的预视效应, 因此, 该研究验证了第一个假设, 说明空格使读者的注视点距离预视词更远, 从而导致词间词的预视效应小于词内词。为了检验Hyönä等(2004)的第二个假设, Juhasz等人(2009)控制注视词与预视词的距离相同, 通过操纵位于隐含边界前后的两个词是否同属于一个语言单元, 考察语言单元对预视加工的影响。他们选取了有空格的复合词与短语作为目标词(例如tennis ball vs. filtby ball)。结果显示, 复合词的预视效应(31 ms)与短语的预视效应(20 ms)之间尽管存在差异, 但是没有达到统计检验的显著性, 该结果不符合Hyönä等的第二个假设。但是作者认为并不能由此否认语言单元对预视加工可能存在的影响, 短语的两个词虽然不属于同一个语言单元, 但因为形容词对名词的句法预期性高, 所以读者倾向于把形容词-名词短语错作为一个语言单元, 因而造成词间词(短语)和词内词(复合词)的预视效应没有差异。因此, 关于词间词和词内词预视加工之间的差异尚需要更多的研究来探讨, 以形成清晰的解释。
由于英文词与词之间存在空格, 因此, 研究者为了控制注视词和预视词的距离相同, 只能选择在词间词和词内词都存在空格的情况下, 对两类词语的预视加工进行考察, 却不能在排除空格影响的条件下对两类词语的预视加工进行探讨。而汉字作为表意文字, 每个汉字都是由一系列笔画按照某种方式组合而成的, 每个汉字所占用的宽度相同, 一个字可以单独成词, 也可以和其他汉字合并成词。在中文文本中, 字是基本的组成单元, 词与词之间没有明确的边界信息, 因此可以在排除空格影响的条件下, 探讨语言单元对预视加工的影响。Cui等人(2013)采用边界范式, 首次在中文中探究语言单元对预视加工的影响。该研究比较了中文文本阅读中单纯词、复合词、短语的预视效应。单纯词虽然由两个字组成, 但是只有一个词素, 两个字无法分离成词(例如“玫瑰”); 复合词是由两个字组成的词, 并且两个字也可以独立成词(例如“灯塔”); 短语也是由两个字组成的, 两个字均独立成词, 无法组成一个词(例如“斜塔”)。结果显示, 仅在单纯词的预视加工过程中出现了显著的副中央凹-中央凹效应(P-O-F效应), 即预视加工的信息对当前的阅读产生了影响; 但是复合词和短语并未出现显著的P-O-F效应; 而且复合词和短语之间的预视效应也没有出现显著差异。该结果表明, 虽然构成单纯词和复合词的两个字同属于一个语言单元, 但是相对于复合词, 单纯词的首字对尾字的预期性更高, 因此导致了更大的预视加工; 而对于复合词和短语, 虽然复合词的两个词素同属于一个语言单元, 短语的两个词不属于一个语言单元, 但两者的预视加工也未出现差异。该结果与Juhasz等人(2009)的研究结果一致。Cui等人(2013)指出, 由于中文词语切分的不确定性(Hoosain, 1992), 导致很多读者无法对复合词和短语做出清楚的区分, 在事后的词切分评定中, 被试错将45%的短语认定为复合词, 因此导致复合词和短语的预视加工没有出现显著差异。所以, 本研究对词间词和词内词的词边界进行了更加清晰的界定, 以考察语言单元对预视加工的影响。
如前所述, 在英文的研究中, 虽然可以在有空格的情况下研究词间词和词内词对预视加工的影响, 但是不能完全排除空格的影响; 而在Cui等人(2013)的研究中, 读者并没有对复合词和短语的词边界做出很好的区分。为了更加清晰地考察语言单元对预视加工的影响, 本研究对词间词和词内词的词边界进行了更加清晰的界定, 通过操纵隐含的边界位于复合词的首字之前或者首字和尾字之间, 使目标字位于词间或者词内, 从而严格控制预视字与注视字是否属于一个语言单元。另外, 通过操纵目标字的预视类型为一致预视或者假字预视, 探讨词间词与词内词的预视效应是否存在差异。本研究预期, 在排除了词间和词内空格影响的条件下, 词内词的预视效应大于词间词的预视效应。
1.2 边界信息对词间词和词内词预视加工的影响
近年来, 关于中文预视加工以及中、英预视加工之间差异性的研究成为研究者关注的热点。与印欧语系已有的研究结果相类似, 研究者同样发现, 在中文文本阅读中, 预视加工对注视时间(when)和注视位置(where)均有重要的影响(Morris, Rayner, & Pollatsek, 1990; Perea & Acha, 2009; Yen, Radach, Tzeng, Hung, & Tsai, 2009)。当预视词是高频词的时候, 注视时间更短, 跳读率更高(Liu, Reichle, & Li, 2015; Rayner, Ashby, Pollatsek, & Reichle, 2004), 并且进入和跳出高频词的眼跳距离大于低频词(Hyönä, 1995; Liu, Reichle, & Li, 2016; Wei, Li, & Pollatsek, 2013)。但是研究者也发现, 预视加工的大小和深度在中文和印欧语系之间存在着巨大的差异。首先, 中文的预视效应更大。英文中的预视效应大约是30~50 ms (Rayner, 2009), 但是中文的预视效应可以达到60 ms以上(Cui et al., 2013; Yan, Richter, Shu, & Kliegl, 2009; Yang, Wang, Xu, & Rayer, 2009)。Vasilev和Angele (2017)通过元分析证实, 中文的预视效应在凝视时间上比拼音文字大约大了10 ms。其次, 中文预视加工获知信息的水平更高。在英文研究中, 大多数的研究均获得了正字法、语音的预视效应, 但是大多数研究并没有发现语义水平的预视效应(Dimigen, Kliegl, & Sommer, 2012; Rayner, Balota, & Pollatsek, 1986), 只有在一些特殊的情况下(比如首字母大写或者预期性较高的时候)才发现了语义水平的预视效应(Rayner, Schotter, & Drieghe, 2014; Schotter, Lee, Reiderman, & Rayner, 2015)。但是, 已有很多研究均发现在中文文本中存在较为稳定的语义预视效应。王穗苹、佟秀红、杨锦绵和冷英(2009)采用正常阅读的句子文本, 通过改变预视字从而形成语义连贯和语义违背两种句子条件。统计结果表明, 读者对目标词的注视时间在语义违背条件下要显著长于语义连贯条件, 表明读者可以获得语义预视效应。后来越来越多的研究支持了该研究结论(Li, Wang, Mo, & Kliegl, 2017; Yan et al., 2009; Yang et al., 2009)。
中文文本中更大更强的预视效应可能是由中文语言的独特性导致的。首先, 中文的视觉密度更加紧凑(例如, 住宿vs. accommodation), 因而导致读者在注视当前词时, 可以在视觉范围内对更多的词进行加工。其次, 中文的每个方块汉字均是一个独立的视觉单位, 不仅含有正字法、语音的信息, 而且很可能包含语义信息, 此外, 汉字的正字法和语义之间的关系比英文要更加紧密, 因此预视加工能够较早地获得语义信息, 从而语义水平的预视效应(Schotter, 2013; Schotter et al., 2015)。再次, Yen等(2009)认为, 中文更大的预视效应是由于中文文本缺少明确的词边界信息导致的。在中文文本中, 词与词之间没有明确的边界信息, 一个汉字可以独立成词, 也可以与其他汉字合并成词, 因此读者在加工当前注视的字(词)的同时可能需要对更多的字(词)进行预视加工, 以提前确定词边界的位置。根据Yen等人的观点, 中文文本中更大的预视效应是因为没有边界信息造成的, 那么在英文文本中, 如果减少词边界信息是否会增加预视效应呢?在中文文本中, 如果增加词边界信息是否会减小预视效应呢?研究者尚未得到一致的结论。
有研究表明, 在英文无词间空格的条件下, 读者可以获得更大的预视效应。Drieghe, Fitzsimmons和Liversedge (2017)在英文文本中通过操纵前目标词的词频(高频和低频)和句子类型(有空格和无空格), 比较了有无空格文本之间预视效应的差异。实验结果显示, 当前目标词是高频词时, 无空格文本的预视效应显著地大于高频有空格、低频有空格、低频无空格的预视效应。他们认为, 当没有任何词边界信息以及前目标词的加工难度较低(高频词)的情况下, 读者更倾向于同时加工多个词, 以确定词边界的信息, 因此造成预视效应的增大; 而在有词边界信息的情况下, 读者会更加集中地加工当前注视的信息, 因此造成预视效应的减小。
但是也有研究者认为, 英文文本中的空格可以促进预视加工。Drieghe, Brysbaert和Desmet (2005)的研究表明, 在词N和词N+1之间增加一个空格会减少词N的阅读时间。Drieghe等人(2005, 2017)认为, 在词之间增加边界信息会减少词之间的边界掩盖(即词与词之间无明确的边界信息), 这将导致更快的词语识别。另外, Sheridan, Reichle和Reingold (2016)研究有词间空格的正常英文文本和边界由数字填充的无空格英文文本之间预视效应的差异, 结果显示, 在首次注视时间上, 有空格文本的预视效应要显著地大于无空格文本。他们认为, 空格一方面可以易化词切分过程, 帮助读者进行有效的眼跳定位; 另一方面, 增加空格会减少词之间的边界掩盖, 因此可以促进读者的预视加工。
Cui, Denis, Bai, Yan和Liversedge (2014)在中文文本中通过增加词间空格以考察对预视加工的影响。结果显示, 在单字词的条件下, 词间空格的预视效应比正常文本条件的预视效应大; 而在双字词条件下, 词间空格的预视效应和正常条件之间没有显著差异。他们认为, 增加词间空格可以为单字词提供词边界信息, 而且在文本中加入词间空格之后, 单字词的前后两侧均是空格, 因此在对该词进行加工时没有任何边界信息的掩盖; 但是对于双字词, 空格虽然也提供了词边界信息, 但是双字词的两个词素之间仍然存在着词边界掩盖, 每个词素只有一侧临近空格, 因此, 他们认为单字词在词间空格的条件下出现预视效应的增大, 是由于减小了词边界掩盖的作用, 而不是词边界信息的作用。
由上面的论述可知, 采用空格作为词边界信息对不同类型词语的预视加工进行考察的同时, 空格也对词之间的边界掩盖产生了不同的影响。因此, 本研究采用词间阴影作为词边界信息, 以考察词边界信息对预视加工的影响。采用词间阴影的方法可以在控制句子长度不变的条件下, 考察词边界信息对预视效应的影响(Bai, Yan, Liversedge, Zang, & Rayner, 2008), 同时该方法不会对不同类型词语的词边界掩盖产生不同的影响。此外, Rayner和Schotter (2014)的研究发现, 当文本中的预视词采用大写字母时, 预视效应显著地大于小写字母, 他们认为大写字母这一突出特征会增加读者的注意, 从而增大预视效应。因此, 本研究采用黄色阴影来标记边界信息, 从而将边界信息对预视加工产生影响的可能性最大化。
综上所述, 本研究通过操纵隐含的边界位于复合词的首词素之前或者首词素和尾词素之间, 从而控制目标字与边界前的字是否同属于一个语言单元, 以探讨词间词与词内词的预视效应是否存在差异。本研究预期词内词的预视效应大于词间词。另外, 本研究采用正常呈现、词间阴影和非词阴影文本, 以考察词边界信息对词间词和词内词预视加工的影响。本研究认为词边界信息对词间词预视效应的影响大于词内词, 因为读者在加工词间词时, 词间阴影所提供的词边界信息会易化读者的词切分过程, 因此会造成词间词在词间阴影条件下的预视效应大于正常呈现和非词阴影条件; 而读者在加工词内词时, 由于读者已经完成了对当前词的词切分, 因此词边界信息对词内词预视效应的影响较小。
2 研究方法
2.1 被试
被试为104名天津师范大学在校学生, 被试的裸视或矫正视力正常, 均不了解实验目的。母语为汉语, 无阅读障碍。实验结束后, 被试可以获得一份小礼品作为实验报酬。
2.2 实验仪器
本研究采用加拿大SR Research公司生产的Eyelink 2000眼动仪, 采样频率为1000 Hz, 记录被试右眼的数据。实验材料字体为宋体, 颜色为黑色, 呈现在白色屏幕上, 每个汉字在屏幕上的大小为2.1 cm × 2.1 cm。被试眼睛与屏幕之间的距离为60 cm, 每个汉字约为1°视角, 确保当被试注视目标字的前一个字时, 目标字位于预视加工的位置。
2.3 实验设计与材料
本研究采用三因素被试内设计, 自变量1为词语类型, 有两个水平:词间词和词内词; 自变量2为句子类型, 有三个水平:正常呈现、词间阴影和非词阴影; 自变量3为预视类型, 有两个水平:一致和不一致。
本研究采用了120对词间词和词内词, 如前所述, 词间词是指隐含的边界位于目标词的首词素之前, 即注视词和预视词属于不同的词; 而词内词是指隐含的边界位于目标词的两个词素之间, 即注视词和预视词属于同一个复合词, 所以本研究控制每组词间词(“纸盒”)的首词素和词内词(“稿纸”)的尾词素相同, 即隐含边界后的第一个字(预视字)相同。控制词内词和词间词的整词词频、笔画数差异不显著(ts<1.39)。同时为了避免目标字作为双字词的首词素和尾词素的位置频率会对研究结果产生影响, 研究者控制两者的位置频率差异不显著,t(119) = 0.84,p> 0.05。目标词的词汇属性统计详情见表1。不一致预视条件下的预视字是一个假字。假字是通过TrueType造字软件进行构建, 利用汉字的部件组合而成, 因此这些假字的构字特征跟真实汉字没有任何差别, 只是假字在汉语中并不存在, 也没有语音和语义。组词内词和词间词的句子结构完全相同, 也就是说句子中除了目标词存在差别之外, 句子的其他内容没有任何差异, 整个句子语义合理, 目标词和之前的字、以及之后的字均不能组合成词。实验句子最多包含17个汉字, 在电脑上一行呈现。目标字既不会呈现在句子开头前三个字, 也不会呈现在句子的结尾, 以避免句子阅读中特殊位置呈现的特殊效应对研究结果的干扰, 比如句末整合效应。本研究采用边界范式(Rayner, 1975), 在眼睛越过隐含的边界之前, 预视字位置呈现的是与目标字一致或者不一致的预视字, 一旦眼睛越过隐含的边界, 预视词就会变成目标字。实验材料和范式举例见图1。

表1 词间词和词内词的词汇属性统计
句子中的目标词即为设置成粗体的词内词(“稿纸”)和词间词(“纸盒”)。另外, 在正式实验中, 目标词并没有加粗。隐含边界的位置用竖线来标示(|), 对于词内词, 隐含的边界位于双字词的两词素之间, 对于词间词, 隐含的边界位于首字的左边。在眼睛越过隐含的边界之前, 预视位置上呈现的预视字是与目标字一致的字(“纸”)或者是与目标字不一致的假字(“”), 但当读者的眼睛越过隐含的边界时, 预视字则被目标字代替(“纸”)。
2.4 实验材料的评定
句子合理性评定。为确保句子的语义连贯, 并且词间词和词内词的语义连贯性之间没有差异, 因此进行了句子合理性评定。24名不参加正式实验的大学生参与评定, 采用5点量表进行评定, 其中一半被试的评定问卷里1代表非常不合理, 5代表非常合理; 而另外一半问卷1代表非常合理, 5代表非常不合理。除了120个实验句子外, 还加入了36个语义不合理的句子。统计结果显示, 词内词(M= 1.84,SD= 0.22)与词间词(M= 1.79,SD= 0.31)的句子合理性无显著差异(t< 1), 符合本研究的研究目的。
句子词切分评定。句子词切分评定要求两组各12名被试分别对词间词和词内词的句子进行词边界的切分, 里面包含了120个实验句子。要求被试仔细阅读句子, 然后用竖线对句子中的词语进行切分(Yan et al., 2010)。统计结果显示, 被试对词间词和词内词的边界进行切分的一致性分别为85.9%和87.2%, 差异不显著, 符合本研究的实验要求。
2.5 实验程序
被试进入实验室后, 主试首先向被试介绍指导语, 并回答被试的疑问, 以确保被试对实验程序理解正确。然后, 调整仪器并且进行三点校准。在每个句子或问题之前, 都会再进行一次漂移修正以保证记录精确性, 即屏幕的中央左侧位置会出现一个校准点, 只要被试的注视点和校准点重合时校准点才会消失, 下一屏内容呈现。在实验过程中, 如果被试的注视点发生漂移, 则随时重新进行校准。校准完毕后开始实验, 实验开始是练习部分, 包含6个句子和两个问题, 以帮助被试熟悉实验流程, 练习完毕后, 开始正式实验。阅读材料以逐句的方式呈现在屏幕中央, 被试的任务是以自己的速度认真阅读每一屏呈现的句子, 阅读完毕后按键, 然后进行下一个句子的阅读。被试每读完三个句子后, 根据所读句子的内容对一个问题进行判断。研究采用拉丁方设计, 以确保每名被试只阅读每个主题句子的一种条件。在实验结束后向被试询问是否注意到实验过程中有奇怪的现象, 个别被试汇报在实验过程中有个别句子的字有变化, 但是被试并不能清晰汇报该变化的内容。
每名被试共阅读156个句子:其中包括120个随机顺序呈现的实验句子, 30个填充句子, 6个练习实验的句子。整个实验大概持续35分钟, 其中包括5分钟的校准时间。
3 结果与分析
剔除4名回答问题正确率在75%以下的被试(Rayner, 1998), 另外剔除4名看到边界变化超过总体句子数量25%以上的被试, 实验共获得96名被试的有效眼动数据。数据分析时, 注视时间短于60 ms和长于600 ms的眼动数据均被删除。因此, 大约11.2%的数据被删除。
基于研究目的将报告以下眼动指标:首次注视时间(眼睛第一次阅读某个兴趣区内的首个注视点的注视时间)、凝视时间(从首次注视点开始到注视点首次离开当前兴趣区之间的持续时间)、回视路径时间(从某个兴趣区的第一次注视开始, 到注视点落在该兴趣区右侧的区域位置之间的所有注视点的持续时间的总和)、跳读率(第一遍阅读中兴趣区被跳读的概率) (闫国利 等, 2013)。以下F1均指以被试为随机误差的方差分析值, 而F2均指以项目为随机误差的方差分析值。
基于词语类型是由操纵目标字在词间词和词内词来实现的, 因此, 数据分析主要集中于目标字上, 本研究重点报告目标区域的眼动指标, 数据分析的兴趣区单位见图2所示(竖线表示边界所在的位置), 具体眼动数据见表2。
首次注视时间对于首次注视时间, 词语类型的主效应显著,0.30;F2(1, 113) = 28.56,p< 0.001,词内词的首次注视时间长于词间词。预视类型的主效应显著,不一致预视条件的首次注视时间显著长于一致预视条件。句子类型的主效应不显著,F1(2, 118) = 1.59,p> 0.1;F2(2, 226) = 2.25,p> 0.1, 正常呈现、词间阴影以及非词阴影的首次注视时间差异不显著。词语类型和句子类型的交互作用显著,F1(2, 188) = 5.75,p< 0.01,简单效应检验显示, 在非词阴影的条件下, 词内词(245 ms)和词间词(241 ms)的首次注视时间差异不显著, 但是在正常呈现和词间阴影的条件下, 词内词的首次注视时间显著长于词间词。词语类型和预视类型的交互作用显著,F1(1, 94) = 11.63,p< 0.01,词内词的预视效应(42 ms)显著大于词间词(24 ms)。其它条件下的交互作用均不显著(Fs< 2.25)。
凝视时间对于凝视时间, 词语类型的主效应显著,词内词的凝视时间长于词间词。预视类型的主效应显著,F1(1, 94) = 144.06,p< 0.001,= 405.04,p< 0.001,不一致预视条件的凝视时间显著长于一致预视条件。句子类型的主效应不显著,F1(2, 188) = 0.48,p> 0.1;F2(2, 226) = 0.76,p> 0.1, 正常呈现、词间阴影以及非词阴影的凝视时间差异不显著。词语类型和句子类型的交互作用显著,F1(2,简单效应检验显示, 在非词阴影的条件下, 词内词和词间词的凝视时间差异不显著, 但是在正常呈现和词间阴影的条件下, 词内词的凝视时间显著长于词间词。词语类型和预视类型的交互作用显著,F1(1, 94) = 15.06,p< 0.001,0.14;F2(1, 113) = 11.79,p< 0.01,0.09, 词内词的预视效应(60 ms)显著大于词间词(36 ms)。其它条件下的交互作用均不显著(Fs< 2.10)。

表2 被试在目标字上的眼动指标均值和标准差
回视路径时间对于回视路径时间, 词语类型的主效应显著,F1(1, 92) = 60.35,p< 0.001,= 0.40;F2(1, 113) = 42.23,p< 0.001,= 0.27, 词内词的回视路径时间长于词间词。预视类型的主效应显著,F1(1, 92) = 113.84,p< 0.001,= 0.55;F2(1, 113) = 275.34,p< 0.001,= 0.71, 不一致预视条件的回视路径时间显著长于一致预视条件。句子类型的主效应项目分析显著,F1(2, 184) = 2.06,p> 0.1;F2(2, 226) = 7.02,p< 0.01,= 0.06, 正常呈现(334 ms)和非词阴影(338 ms)的回视路径时间显著地长于词间阴影(318 ms)。词语类型和预视类型的交互作用显著,F1(1, 92) = 34.99,p< 0.001,= 0.28;F2(1, 113) = 27.61,p< 0.001,= 0.20, 词内词的预视效应(60 ms)显著大于词间词(36 ms)。句子类型和预视类型的交互作用显著,F1(2, 184) = 4.62,p< 0.05,= 0.05;F2(2, 226) = 3.62,p< 0.05,0.03, 词间阴影的预视效应(57 ms), 小于正常呈现条件(86 ms)和非词阴影条件(95 ms), 正常呈现条件的预视效应小于非词阴影。其它条件下的交互作用均不显著(Fs < 2.10)。
跳读率对于跳读率, 词语类型的主效应显著,F1(1, 95) = 28.36,p< 0.001,= 0.23;F2(1, 119) = 13.99,p< 0.001,= 0.11, 词内词的跳读率小于词间词。预视类型的主效应不显著,F1(1, 94) = 0.84,p> 0.1;F2(1, 113) = 0.99,p> 0.1, 不一致预视条件与一致预视条件的跳读率差异不显著。句子类型的主效应显著,F1(2, 190) = 3.96,p< 0.05,= 0.04;F2(2, 238) = 6.00,p< 0.01,0.05, 词间阴影和非词阴影的跳读率显著地大于正常呈现, 但是词间阴影和非词阴影的跳读率之间差异不显著。词语类型、句子类型和预视类型的交互作用项目分析显著,F1(2, 190) = 1.90,p >0.1;F2(2, 238) = 13.22,p< 0.05,= 0.03。其它条件下的交互作用均不显著(Fs< 2.10)。
由于三因素交互作用项目分析显著, 因此进行简单效应分析。
对于词内词, 预视类型和句子类型的主效应不显著(Fs< 1.8), 预视类型和句子类型的交互作用显著,F1(2, 190) = 3.55,p< 0.05,0.04;F2(2, 238) = 4.76,p< 0.01,= 0.04, 在正常呈现和非词阴影条件下, 一致预视和不一致预视的差异不显著, 而在词间阴影条件下, 一致预视的跳读率显著地大于不一致预视的跳读率; 对于词间词, 句子类型的主效应显著,F1(2, 190) = 3.37,p< 0.05,= 0.03;F2(2, 238) = 4.66,p= 0.01,0.04, 正常呈现和非词阴影的跳读率显著地小于词间阴影, 正常呈现和非词阴影的跳读率之间差异不显著, 预视类型的主效应与预视类型和句子类型的交互作用不显著(Fs< 1.9)。
对于正常呈现下, 词语类型的主效应被试分析显著,F1(1, 95) = 4.21,p< 0.05,= 0.04;F2(1, 119) = 2.48,p >0.1, 词内词的跳读率大于词间词的跳读率。预视类型的主效应以及词语类型和预视类型的交互作用不显著(Fs< 1.4)。对于词间阴影条件下, 词语类型的主效应显著,F1(1, 95) = 10.61,p< 0.01,= 0.10;F2(1, 119) = 8.22,p< 0.01,= 0.07, 词内词的跳读率大于词间词。预视类型的主效应被试分析边缘显著,F1(1, 95) = 3.54,p< 0.1,= 0.04;F2(1, 119) = 2.53,p> 0.1, 一致条件下的跳读率大于不一致条件。词语类型和预视类型的交互作用被试分析边缘显著、项目分析显著,F1(1, 95) = 3.70,p< 0.1,= 0.04;F2(1, 119) = 4.95,p< 0.05,= 0.04, 词内词在一致条件下的跳读率大于不一致条件, 但是在词间词的条件下, 一致预视和不一致预视条件的跳读率没有差异。对于非词阴影条件下, 词语类型的主效应被试分析显著,F1(1, 95) = 11.13,p< 0.01,= 0.11;F2(1, 119) = 5.36,p< 0.05,0.04, 词内词的跳读率大于词间词的跳读率。预视类型的主效应以及词语类型和预视类型的交互作用不显著(Fs< 1.0)。
另外, 因为实验操作的隐含边界位于词内词的两词素之间, 而位于词间词的两词素之前, 因此将词内词的尾字和词间词的整词作为预视加工的兴趣区进行比较。数据分析的兴趣区单位见图3所示(竖线表示边界所在的位置), 具体眼动数据见表3。
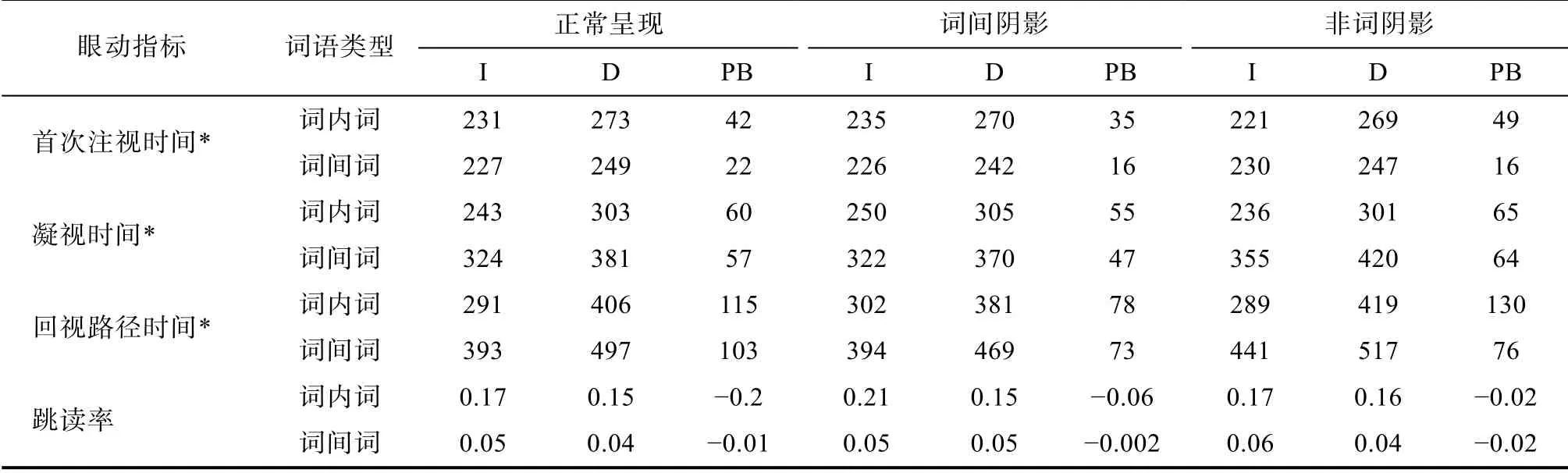
表3 被试在目标区域上的眼动指标均值和标准差
首次注视时间对于首次注视时间, 词语类型的主效应显著,F1(1, 94) = 43.29,p< 0.001,0.32;F2(1, 117) = 28.05,p< 0.001,= 0.19, 词内词的首次注视时间长于词间词。预视类型的主效应显著,F1(1, 94) = 99.27,p< 0.001,0.51;F2(1, 117) = 193.64,p< 0.001,= 0.62, 不一致预视条件的首次注视时间显著长于一致预视条件。句子类型的主效应不显著,F1(2, 188) = 0.76,p> 0.1;F2(2, 234) = 1.34,p> 0.1, 正常呈现、词间阴影以及非词阴影的首次注视时间差异不显著。词语类型和句子类型的交互作用项目分析边缘显著,F1(2, 188) = 2.15,p> 0.1;F2(2, 234) = 2.67,p= 0.07,= 0.05, 简单效应检验显示, 在非词阴影的条件下, 词内词和词间词的首次注视时间差异不显著(差异为7 ms), 但是在正常呈现(差异为14 ms)和词间阴影(差异为18 ms)的条件下, 词内词的首次注视时间显著长于词间词。词语类型和预视类型的交互作用显著,F1(1, 94) = 28.82,p< 0.001,= 0.24;F2(1, 117) = 32.65,p< 0.001,= 0.22, 词内词的预视效应(42 ms)显著大于词间词(18 ms)。其它条件下的交互作用均不显著(Fs< 1.54)。
凝视时间对于凝视时间, 词语类型的主效应显著,F1(1, 94) = 274.12,p< 0.001,= 0.75;F2(1, 117) = 420.70,p< 0.001,= 0.78, 词内词的凝视时间短于词间词。预视类型的主效应显著,F1(1, 94) = 136.70,p< 0.001,= 0.59;F2(1, 117) = 262.47,p< 0.001,= 0.69, 不一致预视条件的凝视时间显著长于一致预视条件。句子类型的主效应显著,F1(2, 188) = 10.16,p<0.001,0.10;F2(2, 234)=15.76,p< 0.001,= 0.12, 正常呈现(313 ms)、词间阴影(312 ms)的凝视时间显著地短于非词阴影(329 ms)的凝视时间, 但是正常呈现与词间阴影的凝视时间之间差异不显著。词语类型和句子类型的交互作用显著,F1(2, 188) = 22.16,p< 0.001,0.19;F2(2, 234) = 23.61,p< 0.001,= 0.17, 简单效应检验显示, 在不同句子类型的条件下, 词内词的凝视时间都显著短于词间词的凝视时间, 但是在非词阴影条件下的差异最大(差异120 ms), 其次是正常呈现的条件(差异80 ms), 最后是词间阴影条件(差异70 ms)。其它条件下的交互作用均不显著(Fs< 1.74)。
回视路径时间对于回视路径时间, 词语类型的主效应显著,F1(1, 94) = 213.48,p< 0.001,0.69;F2(1, 117) = 201.41,p< 0.001,0.63, 词内词的回视路径时间短于词间词。预视类型的主效应显著,F1(1, 94) = 152.50,p< 0.001,0.62;F2(1, 117) = 311.66,p< 0.001,= 0.73, 不一致预视条件的回视路径时间显著长于一致预视条件。句子类型的主效应项目分析显著,F1(1, 94) = 10.97,p< 0.001,= 0.11;F2(1, 117) = 14.15,p< 0.001,0.11, 正常呈现(398 ms)、词间阴影(387 ms)的回视路径时间显著地短于非词阴影(419 ms)的回视路径时间, 但是正常呈现与词间阴影的回视路径时间之间差异不显著。词语类型和句子类型的交互作用被试分析显著, 项目分析边缘显著,F1(2, 188) = 3.54,p< 0.05,= 0.04;F2(2, 234) = 2.91,p= 0.06,0.02, 简单效应检验显示, 在不同句子类型的条件下, 词内词的回视路径时间都显著小于词间词的回视路径时间, 但是在非词阴影条件下的差异最大(差异126 ms), 其次是正常呈现的条件(差异98 ms), 最后是词间阴影条件(差异91 ms)。词语类型和预视类型的交互作用被试分析显著, 项目分析边缘显著,F1(1, 94) = 5.15,p< 0.05,= 0.05;F2(1, 117) = 3.80,p= 0.05,= 0.03, 词内词的预视效应(108 ms)显著大于词间词(85 ms)。句子类型和预视类型的交互作用被试分析边缘显著, 项目分析显著,F1(2, 188) = 2.86,p= 0.06,= 0.03;F2(2, 234) = 3.07,p< 0.05,= 0.03, 词间阴影的预视效应(75 ms)显著小于正常呈现条件(110 ms)和非词阴影最大(105 ms)。其它条件下的交互作用均不显著(Fs< 2.27)。
跳读率对于跳读率, 词语类型的主效应显著,F1(1, 95) = 187.45,p< 0.001,0.66;F2(1, 113) = 13.99,p< 0.001,= 0.11, 词内词的跳读率大于词间词。预视类型的主效应不显著,F1(1, 95) = 0.84,p> 0.1;F2(1, 119) = 0.99,p> 0.1, 不一致预视条件与一致预视条件的跳读率差异不显著。句子类型的主效应项目分析显著, 被试分析不显著,F1(2, 190) = 1.82,p> 0.1;F2(2, 238) = 6.00,p< 0.01,= 0.05, 词间阴影和非词阴影的跳读率大于正常呈现, 但是词间阴影和非词阴影的跳读率之间没有差异。词语类型、句子类型和预视类型的交互作用项目分析显著,F1(2, 190) = 2.07,p< 0.01,= 0.04;F2(2, 238) = 3.20,p< 0.05,= 0.03。其它条件下的交互作用均不显著(Fs< 2.08)。
由于三因素交互作用项目分析显著, 因此进行简单效应分析。
对于词内词, 预视类型和句子类型的交互作用显著,F1(2, 190) = 3.50,p< 0.05,= 0.04;F2(2, 238) = 4.76,p< 0.01,= 0.04, 在正常呈现和非词阴影条件下, 一致预视和不一致预视的差异不显著, 而在词间阴影条件下, 一致预视的跳读率显著地大于不一致预视的跳读率。句子类型的主效应与预视类型的主效应不显著(Fs< 1.7)。对于词间词, 句子类型的主效应项目分析显著,F1(2, 190) = 0.89,p> 0.1;F2(2, 238) = 4.66,p= 0.01,0.04, 正常呈现和非词阴影的跳读率的小于词间阴影, 正常呈现和非词阴影的跳读率之间差异不显著, 预视类型的主效应与预视类型和句子类型的交互作用不显著(Fs< 1.7)。
对于正常呈现下, 词语类型的主效应被试分析显著,F1(1, 95) = 83.54,p< 0.001,= 0.47;F2(1, 119) = 2.48,p >0.1, 词内词的跳读率大于词间词的跳读率。预视类型的主效应以及词语类型和预视类型的交互作用不显著(Fs< 1.4)。对于词间阴影条件下, 词语类型的主效应显著,F1(1, 95) = 59.35,p< 0.001,= 0.39;F2(1, 119) = 8.22,p< 0.01,= 0.07, 词内词的跳读率大于词间词。预视类型的主效应被试分析边缘显著,F1(1, 95) = 8.39,p< 0.01,0.08;F2(1, 119) = 2.53,p> 0.1, 一致条件下的跳读率大于不一致条件。词语类型和预视类型的交互作用显著,F1(1, 95) = 4.92,p< 0.05,= 0.05;F2(1, 119) = 4.95,p< 0.05,= 0.04, 词内词在一致条件下的跳读率大于不一致条件, 但是在词间词的条件下, 一致预视和不一致预视条件的跳读率没有差异。
对于非词阴影条件下, 词语类型的主效应被试分析显著,F1(1, 95) = 98.48,p< 0.001,= 0.51;F2(1, 119) = 5.36,p< 0.05,0.04, 词内词的跳读率大于词间词的跳读率。预视类型的主效应以及词语类型和预视类型的交互作用不显著(Fs< 1.7)。
4 讨论
本研究采用眼动轨迹记录法, 通过操纵隐含的边界位于复合词的首词素之前或者首词素和尾词素之间, 从而严格控制目标字与边界前的字是否同属于一个语言单元, 以此探讨词间词与词内词的预视加工是否存在差异。同时, 为了考察中文文本中词边界信息对预视加工的影响, 本研究在句子中加入了词边界信息——词间阴影, 从而对词边界信息的作用机制以及对预视加工的影响进行探讨, 为中文和印欧语系预视效应的差异性提供可能性的解释, 并且为中文文本阅读中的词切分和动态加工过程提供解释说明, 从而为眼动控制模型的构建提供新的视角和实证基础。
本研究的结果显示, 当以目标字为兴趣区时, 在首次注视时间、凝视时间和跳读率上均发现词间阴影、正常呈现和非词阴影之间的差异不显著, 该结果和Bai等(2008)的研究结果一致。一方面可能是因为词间阴影所标示的词边界信息对读者的阅读加工并没有作用; 另一方面, 正如Bai等人所言, 读者每天阅读的文本都是非边界文本, 词间阴影的句子是读者所不熟悉的, 但是读者并没有出现阅读的障碍, 反而表现出跟熟悉的正常文本相同的阅读时间, 这表明词边界信息可能存在促进作用。同时本研究在回视路径时间上发现词间阴影的阅读时间显著地短于正常文本, 因此推测词间阴影的促进作用还是存在的, 这尚需进一步研究的证实。
当以词内词的目标字和词间词的整词为兴趣区进行数据分析时, 在凝视时间和回视路径时间上发现, 正常文本和词间阴影的阅读时间显著地短于非词阴影, 该结果和Bai等(2008)的结果一致, 说明词在中文阅读加工中的作用。除此之外, 因为词间阴影所标示的词边界信息在早期指标上(首次注视时间、凝视时间)并没有出现促进作用, 而仅在晚期指标(回视路径时间)上出现了促进作用, 该结果在一定程度上说明词边界信息对阅读的促进作用不是发生在早期阶段, 而是发生在晚期阶段(Bai et al., 2008)。研究词切分发生的时间对于理解中文的阅读方式具有重要的作用, 但是对于其发生作用的时间进程还需要进一步的研究。
其次, 在首次注视时间、凝视时间以及回视路径时间上均发现了词内词的预视效应大于词间词的预视效应, 即当预视位置的目标字与当前注视的字属于一个语言单元时的预视效应要大于不同语言单元, 从而证实了Hyönä等(2004)的假设, 词语的语言属性会影响预视效应的加工, 即当边界前后的两个词素同属于一个语言单元时预视效应会更大。该结果与以往研究词内和词间的预视效应的结果不同(Cui et al., 2013; Juhasz et al., 2009), 但诚如作者在文中所言, 词性的预期性以及词切分的不确定性也是影响结果的重要因素。本研究严格控制目标字与边界前的字是否同属于一个语言单元, 结果显示, 词内的预视效应大于词间的预视效应, 该结果表明语言单元确实是影响词内词的预视效应大于词间词预视效应的重要因素。
该结果也说明中文读者可以根据目标字所在的位置灵活地进行词切分。Zang等人(2016)研究了前目标字经常作为双字词的首字或者经常作为单字词是否会影响目标字的预视加工。结果显示, 前目标字更多地作为首字出现时的预视效应要大于更多的作为单字的预视效应, 说明读者能够根据目标字的位置频率来调节预视加工。本研究则是通过操纵隐含的边界位于首词素和尾词素之间或者复合词的首词素之前, 使目标字位于词内或者词间, 结果表明, 当目标字是双字词的尾字时, 预视效应更大, 说明中文读者能够根据目标字所在的位置快速地对该字所具有的语言属性进行判断, 从而对预视加工产生不同的影响。
再次, 在首次注视时间、凝视时间以及跳读率上均发现词间阴影的预视效应与正常呈现的预视效应没有差异。该结果和Cui等人(2014)的研究结果一致, 即, 无论是用空格还是阴影来标示边界信息, 均不会对复合词的预视加工产生影响。但是, Cui等人发现空格对单字词的预视加工起促进作用, 而在本研究中发现目标字在词间阴影条件下的预视效应和正常呈现的预视效应没有差异。研究者认为, 虽然词间阴影和词间空格具有共通性, 即它们均为读者提供了词边界信息, 但是两者的作用机制可能存在差异。由此表明, 在考察词边界信息的作用时, 需要厘清差异到底是由增加的词边界信息所导致的, 还是由采用的词边界标记方式所导致的, 这分属于不同的认知加工过程。另外, 词间阴影的预视效应与正常呈现的预视效应没有差异, 这也再一次说明词边界信息并不是中英文预视加工产生差异的根本原因, 需要研究者从更深层次的影响因素对不同语系的加工机制进行更深入和细致的分析和探讨。如前所述, 词间空格在提供词边界信息的同时, 减少甚至去除了词间的词边界掩盖, 所以, 两个研究结果之间的差异可能是因为词间空格条件减少了词边界掩盖造成的, 从而再次证实Cui等人对其研究结果的推测。同时, 该结果也表明词边界信息在早期并没有促进读者的预视加工, 说明中文读者的词切分是智能化的过程, 读者并不需要借助词间阴影所标示的词边界信息确定词的边界。Li, Rayner和Cave (2009)提出的词切分和词汇识别的模型认为, 读者在阅读时可以利用头脑中已有的词表征, 自动高效地对词进行切分。因而词间阴影对读者的预视加工并没有产生促进作用。这说明词边界信息并不是中英文预视加工产生差异的原因, 其加工机制仍需要研究者从更深层次的影响因素进行更深入和细致的分析和探讨。
本研究仅在回视路径时间上发现词间阴影的预视效应显著地小于正常呈现的预视效应。但是Drieghe等(2017)发现在首次注视时间和单一注视时间上, 并且只有在前目标词是高频词的时候, 无空格的预视效应大于有空格的预视效应, 而在前目标词是低频词时, 没有发现预视效应的差异。两个研究之所以出现差异可能是因为边界前词语的加工难度不同造成的。当边界前词语的加工难度较低时, 读者更可能在早期加工预视信息, 从而造成预视效应的增大。因此, 关于词切分和预视加工之间的关系仍需要进行更精细的分析, 从动态的视角, 对连续的词语进行动态的时程分析。
最后, 在首次注视时间、凝视时间以及回视路径时间上均没有发现词间阴影对词间词和词内词的预视加工产生差异。造成这一结果的原因可能是:第一, 词边界信息可能对词间的预视效应的影响要大于对词内的预视效应的影响, 因为读者在加工词间词的首字时, 词间阴影所提供的词边界信息会易化读者的词切分过程, 因此会造成词间阴影的预视效应大于正常呈现条件; 而对于词内词, 即双字词的尾词素, 读者在加工词内词的尾词素时, 已经完成了当前词的词切分, 因此可能会造成词间阴影的预视效应与正常呈现的预视效应差异较小。但是由于词间阴影在假字预视时为词内词提供了错误的词长信息(Cui et al., 2014), 即读者在预视加工时, 更可能将假字作为一个单字词, 因此可能造成在假字预视条件下阅读时间的增加, 从而造成了词内词在词间阴影条件下的预视效应和正常呈现的预视效应的差异增大。而在词间词的条件下, 即双字词的首词素, 假字所提供的词边界信息和阴影所提供的词边界信息是一致的, 因此在词间词的条件下, 假词对词间阴影所提供的词边界信息的影响较小。阴影提供的词边界的作用与假字提供的错误词长信息的作用大小相同时, 也会造成词间阴影对词间词和词内词的预视效应的差异不显著。
第二, 词切分和词汇识别可能是同时进行的。Li等人(2009)提出了一个词切分和词汇识别的模型, 该模型认为读者首先平行加工字的视觉特征, 然后传送到词的加工单元, 并激活相对应的词, 在词的识别单元, 相关的词相互竞争。通过多次循环, 词语识别单元中将会有一个唯一的词胜出。当某一个词胜出后, 词就被识别出来, 也就完成了词的切分。根据Li等人的观点, 目标字不论位于首词素或者尾词素, 都是同时被加工的, 并且当目标词被识别时, 词边界信息也被识别, 因此造成了边界信息对词间词和词内词的预视加工没有差异。再一次说明, 之前相关研究中关于中文预视效应比英文更大的原因是由于缺少词边界的解释有待于商榷, 需要更深层次理论的探讨。
综上所述, 在本研究中, 通过操纵隐含的边界位于复合词的首词素之前或者首词素和尾词素之间, 从而严格控制目标字与边界前的字是否属于一个语言单元。实验结果表明, 词内词的预视效应显著大于词间词的预视效应, 说明在排除文本空格影响的条件下, 语言属性会影响读者的预视加工。另外, 在中文文本中加入词边界信息——词间阴影, 考察词边界信息对预视加工的影响, 实验结果显示, 阴影所提供的词边界信息对词间词和词内词的预视加工均不存在显著影响, 该结果表明词切分和词汇识别可能是同时进行的, 该结果符合Li等人(2009)提出的词切分和词汇识别的模型。
5 结论
本研究得到如下结论:
(1)词内词的预视效应大于词间词的预视效应, 说明语言单元会影响读者的预视加工, 同时说明读者能够根据字所在的位置信息灵活地进行词切分以及预视加工。
(2)词间阴影对词间词和词内词的预视加工均没有显著影响, 该结果表明词切分和词汇识别可能是同时进行的, 该结果符合Li等人(2009)提出的词切分和词汇识别的模型。
猜你喜欢
故事作文·高年级(2022年2期)2022-02-24
纺织科学研究(2021年7期)2021-08-14
小天使·三年级语数英综合(2021年3期)2021-06-15
文苑(2020年11期)2020-11-19
现代装饰(2020年4期)2020-05-20
中国诗歌(2019年6期)2019-11-15
广东第二课堂·小学(2018年10期)2018-10-26
广东第二课堂·小学(2017年11期)2017-12-06
小猕猴智力画刊(2017年6期)2017-07-03
数学大王·中高年级(2016年4期)2016-05-14
