
基于抽象API调用序列的Android恶意软件检测方法
2019-09-13 03:39崔艳鹏胡建伟
计算机应用与软件 2019年9期
崔艳鹏 颜 波 胡建伟
(西安电子科技大学网络与信息安全学院 陕西 西安 710071)
0 引 言
Android平台是目前世界上使用最多的智能平台,占据了全球85%的市场份额。迄今为止,Google市场有超过650亿次的下载量,比App Store高出2倍[1]。同时,Android平台的流行也吸引了许多恶意攻击者们的兴趣,他们开发的恶意软件可以进行各种恶意甚至非法操作,比如:窃取用户隐私及敏感数据、远程执行代码、消耗用户资费等行为。这些恶意软件不仅危及用户数据安全,也威胁到Android系统安全。
根据独立安全机构AV-Test在2018年1月发表的报告[2],使用AhnLab、Alibaba、McAfee、Tencent、Kaspersky Lab等19个手机杀毒软件对2 766个己知Android恶意应用进行检测发现各大手机杀毒软件对于已知的恶意应用检测效果并不理想。
同时,由于当前主流的Android恶意软件检测方法都严重依赖API版本和恶意家族样例,随着时间推移,Android API版本的不断变化和软件保护措施的不断加强,这些检测方法变得越来越低效。
针对上述技术存在的问题,本文提出了一种基于抽象API调用序列的Android恶意软件检测方法。该方法采用静态行为特征提取方法,提取Android应用软件的API调用序列。然后,通过基于API包名、混淆名和自定义名的方法来抽象API调用序列。该方法能有效地识别Android系统原生API、Google API、混淆后的API以及开发者自定义的API,且不会对API版本产生依赖。最后,将抽象后的API调用序列作为分类特征来训练RandomForest分类器。实验结果表明,与一般使用API调用序列作为特征的判别方法相比,本文方法能更有效地检测未知应用软件的恶意性,且能适应API版本的变化,具有更好的容错性。
1 相关工作
目前,关于Android恶意软件检测的方法比较多,主要有基于动态检测和静态检测方法。但基于动态检测的方法在实验资源成本上会耗费过大,且代码覆盖率不全,导致相应特征提取不全,检测有效性降低,所以国内外学者们主要是研究静态检测方法。当前,基于静态检测的方法主要是从签名、权限和API这三大方面进行展开的。
基于签名的静态检测方法[3]是采用了模式匹配的思想。该方法极度依赖已知的恶意软件签名库,无法对未知的恶意软件进行检测。
基于权限的静态检测方法[4-5]主要是从Android系统的权限安全机制着手,因为Android系统中组件间重要敏感的行为受权限限制。该方法通过从应用程序的Android Manifest文件中提取权限字段,建立了正常数据和恶意软件数据的所有权限数据库,最后利用机器学习算法对Android应用中的恶意软件进行分类和识别。该方法优点是简单并且很容易实现,缺点是容易出现误差,比如由于缺乏经验的开发者可能事先申请了某些权限,但其在编程中却没有用到被该权限作用的函数,因此准确率较低,且遗漏问题严重。
基于API调用的静态检测方法[6-7]主要是将Android应用程序的信息接口(API)作为突破口。Android应用软件中API的调用序列存在着大量的行为信息,通过分析API调用特征所得到的特征向量,再结合多种分类算法,可以对Android恶意软件进行检测。文献[8]提出了一种DroidAPIMiner分类器,该分类器从应用软件的字节码中提取API和其他参数,并且对API的使用频率进行统计,最后使用了不同的机器学习的方法处理了这些特征。文献[9]提出了权限和API特征结合的检测方法,主要通过将权限和高危的20种API结合起来作为一个特征集合。实验验证了该方法的准确率比将单一的权限或者API作为特征的准确率要高。但是文献中指出的20种高危API可能会被混淆后的名字代替,从而该方法会漏掉这一关键特征,检测效率也将有偏差。文献[10]提出了一种改进的多级签名检测方法,将签名和API结合起来,对方法和类的签名进行多级匹配。但是该方法依赖已知恶意软件家族,实验训练样本是已知的恶意软件,测试样本则是训练样本进行变种后,按照比例挑选出来的。同时,该方法检测精度也只有88%。文献[11]提取了多项特征数据,包括通过静态检测方法获取的权限、API调用信息和通过动态检测方法获取的日志文件作为总体特征。虽然他们的实验检测效率达到94%,且在准确性方面优于其他反病毒系统,但是检测模型的质量取决于良性样本集合和恶意样本集合。文献[12]提出了一种基于上下文信息的检测方法,该方法提取敏感API编程接口,并分析其行为的激活事件和条件因子,生成语境特征,该方法精确度达92.86%,但是文献中实验数据集太少,只有266个,实验数据具有特殊性。
基于静态检测的方法方便、快速、代码覆盖率高,但是必须考虑到两个问题:一方面,随着Android安全技术的不断提高,很多应用软件均被使用了混淆等保护技术,获取混淆后APK所包含的相关特征信息变得困难;另一方面,目前现有的Android恶意软件静态检测方法都无法适应API版本的更替,随着API版本的更改,检测效率会降低。因此,本文提出的检测方法是采用API包名、混淆名和自定义名来抽象API调用序列,使得抽象出来的序列不依赖API版本,同时又包含了混淆代码特征,具有更好的容错性。
2 基于抽象API调用序列的检测方法
基于抽象的API调用序列的Android恶意软件检测方法通过对提取出的API调用序列进行多层次的抽象描述,然后计算抽象API调用序列之间的转移概率作为分类特征,最后通过RandomForest算法来达到区分恶意软件的效果。实验的整体设计框架如图1所示。
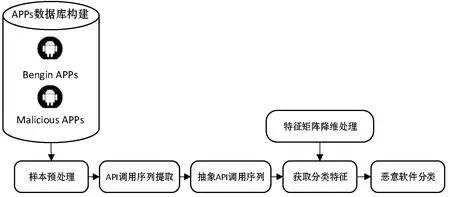
图1 实验设计框架图
2.1 样本预处理
为了使实验样本包含不同API版本,本文从各大应用市场下载各类别的不同版本的热门软件,良性应用软件集总共3 000个。其中:前1 500个API版本均在24~27之间,这些版本是目前市场上多数使用的API版本;后1 500个API版本均在16~23之间,这些版本是比较老的API版本,但依旧占据小部分市场。同时,上述良性应用软件集都是通过杀毒软件的过滤筛除后得到的。实验中的恶意应用软件集来自于VirusShare.com[13]中提供的2 000个恶意软件。
为了更好地训练分类器和获取更好的分类结果,本实验中训练样本集合与测试样本集合的比例为8∶2。表1给出了本实验数据的具体划分情况。

表1 实验训练集与测试集划分
2.2 API特征的分析与提取
Android 系统中的API是可以提供给Android应用软件开发者调用的系统接口。随着Android版本的不断更新,Android应用软件开发者不仅使用Android系统原生API,还包括Google API。这些API包含丰富的功能函数,其为上层应用软件提供框架支撑和行为实现。获取API调用序列的一种方法就是获取Android应用程序的函数调用关系图,通过对函数关系图的分析,获取API 调用序列。
图2为原始API的表达形式,其中包含的信息有:API所属的包名(java.lang.String)、函数名(getBytes)、函数返回值类型(bytes)。

图2 API示意图
2.2.1函数调用关系图的提取
对于Android应用软件的函数调用关系图的提取,本文使用了AndroidGuard工具。AndroidGuard可以进行程序流程图的生成,还能通过图形化的方式输出,让用户对程序有直观的了解。
为了更好地说明本文方法的不同之处,以一个真实的恶意软件样本作为运行实例。图3列出恶意样本malicious1.apk反编译后提取出来的类。图3中的代码片段表示本地保存的短信内容、电话等信息会上传到服务器。

图3 Malicious1.apk中zjSevice类的代码片段
这个恶意软件伪装成一个图片查看器的应用软件,但其中包含恶意行为:恶意记录短信内容、电话号码等敏感信息到本地并上传到某服务器上,导致隐私数据泄露。为了清晰地描述API的调用关系,本文只分析图3 uploadAllfiles函数,且忽略了对象初始化、返回类型和参数以及方法中隐式调用的调用关系。该函数的API调用关系如图4所示。
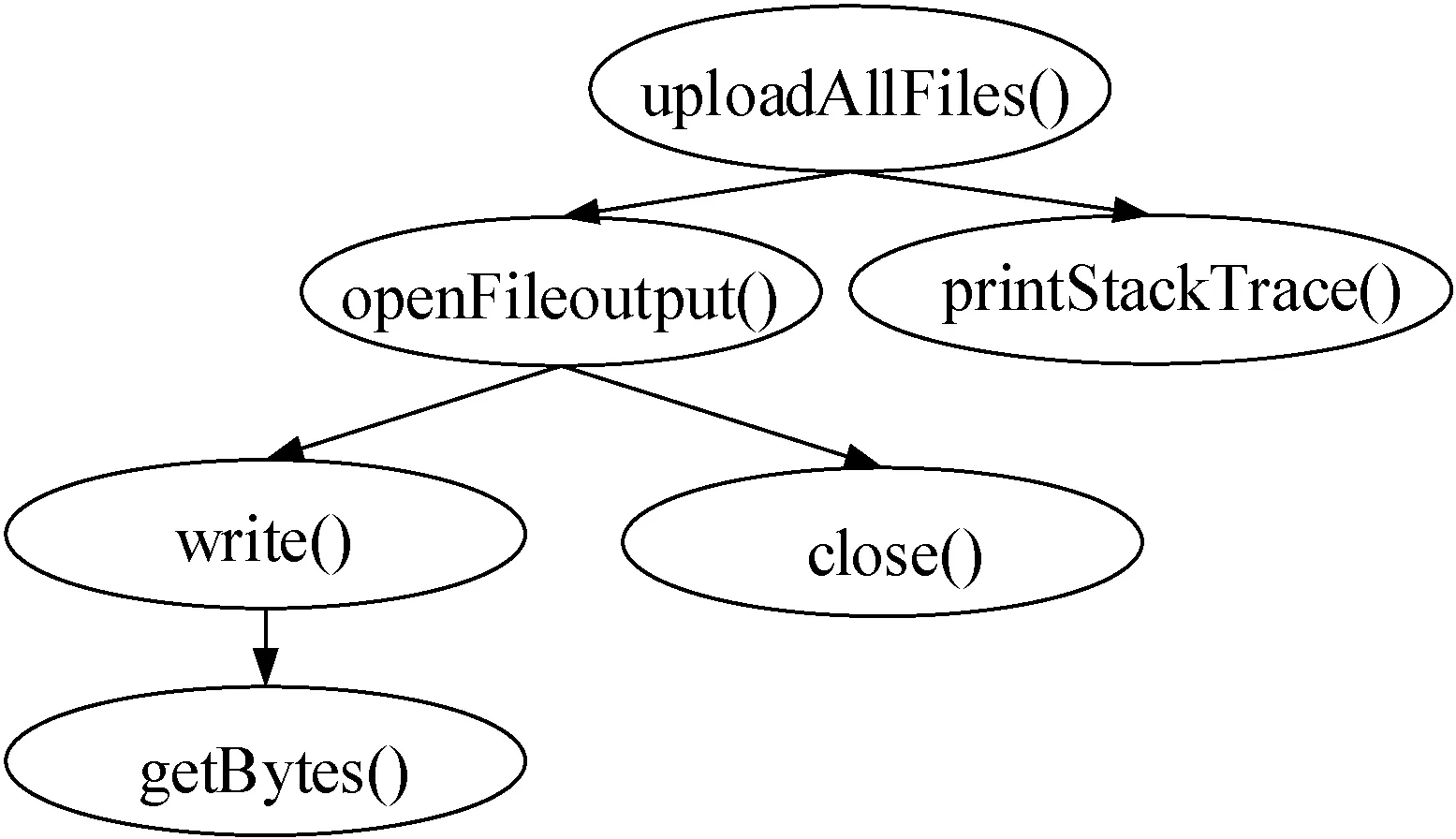
图4 uploadAllfiles函数的调用关系图
2.2.2API调用序列的提取
本文从获取到应用软件的函数调用关系中提取API调用的序列。该阶段的操作步骤为:标识函数调用关系图中的入口节点(即没有传入边的节点);枚举出每个入口节点可到达的路径。在此阶段确定的所有路径的集合L就是该函数的API调用序列。以图3中的uploadAllfiles函数的调用关系图为例,函数调用序列对如图5所示。
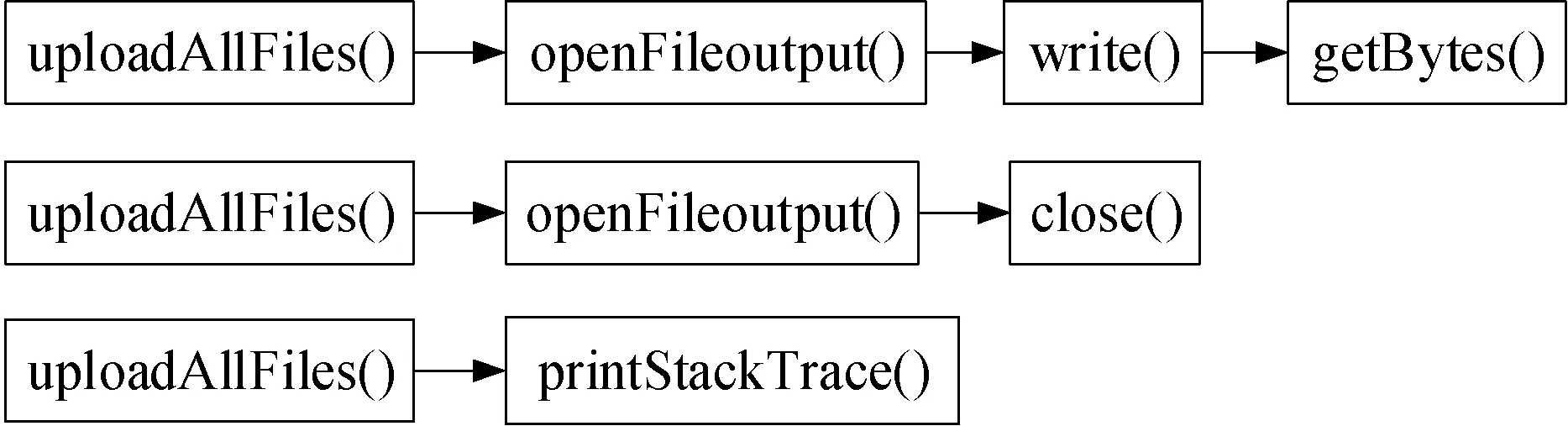
图5 uploadAllfiles函数的API调用序列对
2.2.3抽象API调用序列
不同的Android版本对应着不同的API版本,不同版本的Android API也存在不同,会根据新增的功能去增加或删改一些应用程序接口。因此,如何让提取API特征不依赖API版本成为一个亟待解决的问题。
本文方法通过抽象API的包名避免了检测的特征对于API版本的依赖。具体包括:对API官方网站给出的API进行包名抽象、对应用程序自定义的包名统一抽象为insensitive-defined、对被混淆后的包名统一抽象为obfuscated。根据Android API和Google API官方统计,API以包名进行分类共有9个,分别包括android、com.google、java、javax、org.xml、org.apache、junit、org.json和org.w3c.dom。由于org.w3c.dom家族下的API都为文档对象模型 (DOM)提供接口,junit类适用于开发者做单元测试的类,并且org.w3c.dom和junit都几乎不曾在实验样本集中出现过,所以剔除这两类。表2中给出了所有API抽象描述后的种类集合,总共8种。

表2 抽象API的集合
在Android软件开发中,自定义包名的命名规则采用反域名命名规则,全部使用小写字母。一级包名为com;二级包名为个人或公司名称,可以简写,三级包名根据应用进行命名;四级包名为模块名或层级名;根据实际情况也是可以用五级包名、六级包名。而在Android应用程序层中,混淆技术主要采用标识符混淆,它是对源程序中的包名、类名、方法名和变量名进行重命名,用无意义的标识符来替换,使得破解和分析更困难。通过标识符混淆后的包名多数以单一字符或定制的混淆字典中的字符串替换每级包名,这些单一字符和定制的混淆字典中的字符串的命名方式不会遵守反域名命名规则。因此根据上述特性,本文对应用程序自定义的包名和混淆后的包名识别算法步骤如下:
输入:API调用信息Sorigin,API官网抽象出的集合[APIabstract]=[android, com.google, java, javax, org.xml, org.apache]。
输出:抽象的API。
步骤一:以“.”切分Sorigin,得到一个包名组L。
步骤二:将包名组L中的元素与[APIabstract]逐个匹配,匹配成功,则输出匹配的元素,即为抽象API。
步骤三:如果步骤二匹配不成功,计算L中每个元素的长度,统计元素长度不超过3的元素数量count。
步骤四:判断count是否大于等于len(L)/2,是则输出匹配元素obfuscated,表示为混淆的包名;否则输出匹配元素insensitive-defined,表示为自定义包名。
继续以图5的API调用图为例,API抽象后结果如图6所示。
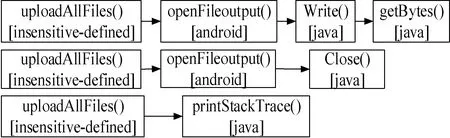
图6 抽象后的API调用序列
2.3 获取分类特征
为了更好体现API调用序列之间的关系,本文方法通过计算API两两之间的转移概率,获取转移矩阵作为分类特征。
API两两之间的转移概率P的计算公式如下:
(1)
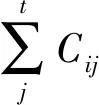
接着,根据上述2.2节分析可知,抽象API集合LAPI_abstract=[android, com.google, java, javax, org.xml, org.apache, obfuscated, insensitive-defined],则LAPI_abstract中API两两之间转换的状态有64(8×8)种,设一个64列的特征向量Vtranslate_count=[API]1×64来代表64种转化状态。其中Vtranslate_count分别代表的是LAPI_abstract集合中抽象API两两之间的转换概率矩阵。一个应用软件中所有函数的抽象API调用序列中的API之间转移概率的集合就组成了转移概率矩阵。具体算法流程如下:
输入:一个应用软件中n个函数的抽象API调用序列集;特征维度t=64。
输出:转移概率矩阵Tn×t。
步骤一:创建转移概率矩阵Tn×t,并将其元素都初始化为0。
步骤二:计算Ti×j的值。其中Ti×t(第i行向量)表示第i个函数的抽象API调用序列中API之间的转移概率向量,因此Ti×j表示第i个函数在Vtranslate_count的第j个指定的两个API之间转换概率。该概率通过式(1)计算可得。
步骤三:输出矩阵Tn×t。
2.4 分类算法
本文采用的分类算法为随机森林算法,主要是为了区分恶意软件和良性软件。
随机森林[14]是建立在决策树算法基础上的改进算法,用于分类与回归。该算法通过重复多次的有放回的方式从原始样本中随机抽取部分样本产生新的样本集合,每个样本集合后续都可以构建成一棵决策树,多棵决策树组建成随机森林。最终分类结果根据每棵分类子树投票统计结果而定。该算法的执行步骤[13]如下:
输入:n个训练样本集T[n],测试样本x,样本特征维度M。
输出:x所属的类别。
步骤一:对于原始训练样本集T[n],有放回的随机抽取N个训练样本。
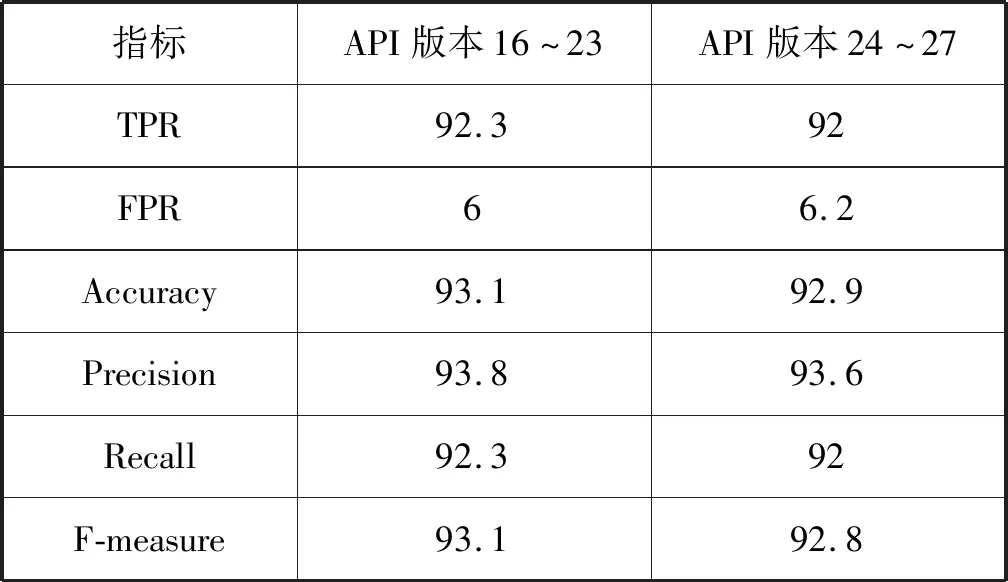
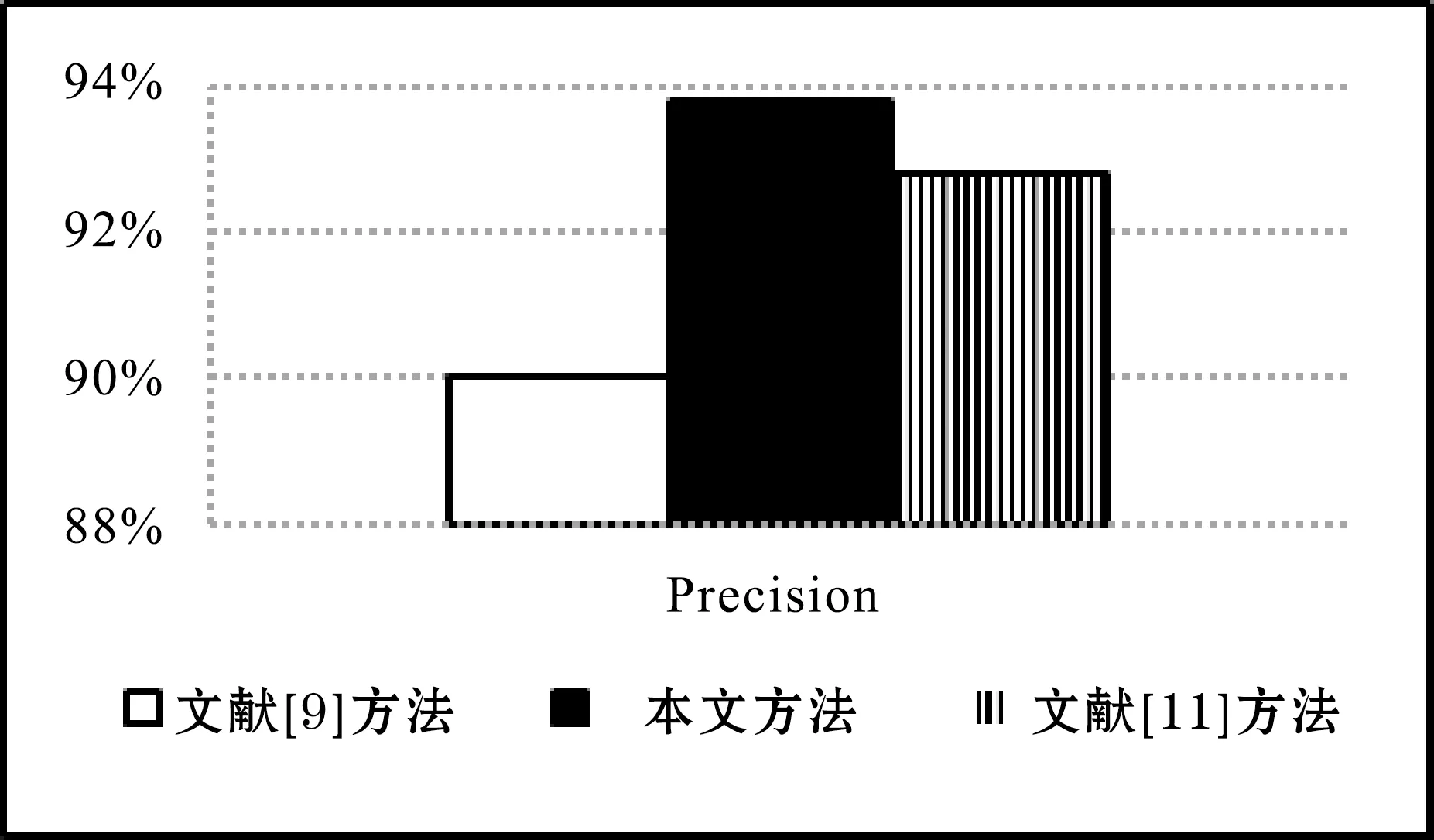
步骤二:随机地从M个特征中选取m个特征子集(m< 步骤三:将经过步骤二生长后的多棵树进行组建,构建成一个随机森林分类器。 步骤四:将测试样本x放入随机森林分类器中进行分类判别。 分类结果的好坏需要通过不同的指标来表现。本文主要以TPR、FPR、Accuracy、Precision、Recall和F-measure作为分类方法的评价标准。具体说明如下: TPR:表示非恶意样例被正确分类的比率。其公式如下: (2) 式中:TP表示非恶意样例被正确分类的个数;P表示非恶意样例的总个数。 FPR:表示恶意样例被错误分类的比率。其公式如下: (3) 式中:FP表示恶意样例被错误划分为正常样例的个数;N表示恶意样例的总个数。 Accuracy:表示准确率,即所有样本被正常分类的比率。其公式如下: (4) 式中:TN表示恶意样例被正常分类的个数。 Precision:表示精度,即非恶意样本正常分类的个数占所有被正常分类总样本个数的比率。其公式如下: (5) Recall:表示查全率,即表示非恶意样本被正常分类的个数占总正常样本的个数的比率。其公式如下: (6) F-measure:表示综合查全率,即平均上述的Precision和Recall指标后的综合评测标准。其公式如下: (7) 本节包含了对不同特征的分类性能的验证实验,具体包括以下两部分实验:(1) 基于抽象API调用序列特征的分类实验。(2) 本方法与市场已有的恶意软件检测方法的比较实验。 3.2.1基于抽象API调用序列特征的分类实验 实验结果对不同API版本的数据集上的准确率、召回率表现进行了详细地统计。从表3中可以看出,API版本在16~23的F-measure和API版本在24~27的F-measure都是93%。API版本在16~23和24~27的TPR、 FPR的差距都只控制在0.2%,表明本文方法能有效区分恶意样本且不受API版本的影响。 表3 不同API版本中RandomForest算法的各项指标 % 3.2.2与其他方法的对比实验 为了验证本文提出的基于抽象API调用序列的特征方法对于Android恶意软件的检测效果。将本文提出的检测方法与邵舒迪等[9]提出的基于权限和API特征结合方法,以及卢正军等[10]提出的基于上下文信息的Android恶意行为检测方法进行对比实验。实验结果如图7所示。 图7 本文方法与文献[9]和文献[11]方法对比结果 根据实验结果可以看出,本文方法的检测精度比文献[9]方法高出了3.8%,比文献[11]提出的方法检测率高出了1%。因此,基于抽象API调用序列的Android恶意软件检测方法效果远优于的文献[9]和文献[11]方法,且实验结果更加具有说服力。 根据目前Android系统存在的安全问题,本文在对Android应用软件的静态特征进行分析后,提出了一种基于抽象API调用序列的Android应用软件检测方法,来判别某个软件是否为恶意软件。本文对3 000款正常软件和2 000款恶意软件进行了仿真实验,结果验证了本文提出的方法的准确性和高效性。 该方法依旧还有提升的空间,可以结合动态方法提取恶意软件运行时的行为进行分析,同样也可以从运行时API调用的角度出发考虑,将动态和静态分析获取到的API调用序列融合在一起,或许可以达到更好的检测效果。3 实验结果与分析
3.1 方法评测标准
3.2 实验结果
4 结 语
猜你喜欢
计算机系统应用(2019年3期)2019-03-11
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
数学学习与研究(2017年3期)2017-03-09
少儿科学周刊·少年版(2015年3期)2015-07-07
中国信息化·学术版(2013年1期)2013-05-28
西南学林(2011年0期)2011-11-12
