
基于改进SSD的舰船目标精细化检测方法
2019-09-13 08:44周红丽
导航定位与授时 2019年5期
梁 杰,李 磊,2,周红丽
(1.北京机电工程研究所,北京 100074; 2.复杂系统控制与智能协同技术重点实验室,北京 100074)
0 引言
海面和港口作为交通枢纽以及重要经济区域,在军事和民用领域具有重要的地位,而舰船作为海上交通运输以及装备的主要载体,对其进行有效的定位和分类在沿海监管和防御等领域具有重要意义[1]。因此,在复杂环境和弱保障条件下,有必要提高对港口、海面舰船等概略、混杂目标选择性精确识别的能力[2],要求不仅能够准确定位舰船位置,给出其朝向信息,还能完成细粒度分类,实现舰船的类型识别和军民识别。
针对舰船目标的检测方法,主要可以分为两类。一类是基于人工特征提取加特征分类器的传统目标检测方法,它利用一些手工设计的图像特征或特征点来表征每一类物体的特点,并将图像由矩阵信息转化成对应的特征向量;然后利用训练好的特征分类器(如支持向量机(Support Vector Machine, SVM))对特征向量进行分类判别,同时通过滑动窗口的方法找到与目标特征最相似的位置从而完成目标定位[3]。例如,文献[4]提到了一种基于灰度统计特性的舰船检测方法,该方法以灰度值作为特征,通过人为设定的阈值来区分背景和目标,仅适用于海面较为平静且水体灰度较低的情况,对海面噪声较敏感,识别虚景率较高。针对上述不足,文献[5]提出了一种基于自适应阈值分割的舰船检测方法,该方法的阈值可由算法根据图像特征进行调节,但仅在舰船与背景对比度明显时效果较好。阈值法的特征较为单一,并不能有效地表征目标特点,适用的情况较少。为此,文献[6]提出了基于邻域分析的海洋遥感图像舰船检测方法;文献[7]提出了基于结构纹理分解的海面舰船检测方法,但算法检测效率低,当图像受到云雾干扰且背景复杂时,检测误差较大。综上,传统舰船目标检测方法的特征提取方式对人员经验的依赖性较强,仅能完成良好气象条件下场景内目标简单类型的判定,难以实现多类型的细粒度识别,无法快速生成情报以满足使用要求。
随着机器学习的不断发展以及硬件水平的不断提高,另一类基于深度学习的目标检测方法被广泛的研究和应用。深度学习通过逐层卷积的方式可提取到高层且抽象的语义特征信息,可挖掘隐藏在目标内部的特性,具有更好的目标表征能力。其按照检测的步骤可分为两大类:1)双步(Two-stage)检测算法,该类方法将目标检测问题划分为2个阶段,首先使用选择性搜索算法或者区域提取网络(Region Proposal Network,RPN)方法等提取出一系列候选区域,之后对每个区域重采像素或特征,并在此基础上进行目标分类和矩形框位置调整,典型代表为:Faster R-CNN[8];2)单步(One-stage)检测算法,该类算法不需要区域候选,由原始图像直接产生物体的类别概率和回归位置坐标值,典型代表为:YOLO[9]和SSD[10]。早期的One-stage算法经验证虽然速度较快,但精度较差,因而近几年该类算法采用多种优化策略来提高精度。例如YOLOv3[11]算法通过引入特征金字塔网络[12](Feature Pyramid Networks,FPN)实现了多尺度预测;RetinaNet[13]算法通过引入焦点损失(Focal loss)来优化损失函数;CornerNet[14]算法借鉴了关键点检测的思想来回归预测框角点。这些改进算法在精度上基本可以和Two-stage算法媲美。总之,两类算法各有所长,需根据实际应用的需求进行选取。例如,文献[15]提出了基于改进Faster R-CNN的舰船检测算法,其在RPN中引入K均值(K-Means)聚类来设置锚框(anchor)的尺寸,可提高舰船的定位精度;文献[16]采用标记分水岭分割算法对深度卷积神经网络(Deep Convolution Neural Network,DCNN)进行改进,可大大缩短对候选区域的检测时间,快速准确地识别红外舰船目标;文献[17]提出了一种基于改进RetinaNet的目标检测方法,融合MobileNet[18]架构进行网络加速,可提高检测速率。综上,深度学习的出现给以舰船为代表的时敏目标精确检测创造了技术条件。
虽然深度学习在目标检测方面较传统方法具有较好的性能表现,但仍有需要改进的地方。具体来说,舰船等时敏目标的长宽尺寸差别较大,且事先无法获知目标的位置和姿态信息;同时飞行器往往以倾斜视角捕获目标影像,在该视角下舰船的排列较为密集。因此,直接利用深度学习检测算法得到的矩形框结果会包含大量的背景冗余信息和重叠区域,无法满足对目标的精确定位和细粒度分类需求。为了解决舰船目标排列紧凑且方向不一时的识别错位问题,考虑工程应用中的实时性要求,本文选择在单步检测模型(Single Shot MultiBox Detector, SSD)的基础上,引入可变形卷积[19]、可变形池化模块、旋转矩形框机制和旋转的非极大值抑制模块,并借鉴MobileNet架构对网络加速,最终得到一种具有旋转不变性的舰船目标精细化检测方法。该方法具备对舰船目标的几何姿态信息较强的学习能力,可以有效预测目标的旋转角度并以旋转矩形框给出目标的位置,从而实现了多类军民舰船目标类型区分和朝向判定的功能,并利用自建数据库验证了所提算法在检测舰船目标时的准确性与实时性。
1 SSD通用目标检测模型
SSD是一种典型的深度学习单步检测类算法,其沿用直接回归的思想,预先按照一定方式划定默认框,通过建立预测框、默认框和标注框的关系来指导训练并进行检测。同时,SSD利用难例挖掘策略来平衡正负样本,增加多层特征图预测模块来提高小目标的识别精度,去掉锚框内重采样来提高速度,因而在整体性能上位居深度学习检测类算法的前列,具有可实时和准确度高这2个优点。
基于SSD进行目标检测,常用方法是由ImageNet数据集预训练得到初始模型,利用自建数据集对模型进行若干次微调,进而达到良好的检测效果[20]。例如民用领域中行人检测、车辆检测和文字检测等常见任务,只需更改分类网络部分的类别输出就能得到较好的效果。但对于舰船目标检测而言,要求对目标进行高精度定位和细粒度分类,只采用上述微调的方式得到的结果无法满足精细化识别需求,需要对SSD算法在网络结构上进行重新设计和优化。
SSD算法主要由两大部分组成:1)基础特征提取网络(backbone);2)特征检测器(task head)。本文在此框架的基础上,针对基础网络、anchor机制、损失函数等重点组成部分进行优化改进,提出了基于改进SSD的舰船目标精细化检测算法。
2 基于改进SSD的舰船目标精细化检测算法
算法以VGG19模型作为基准网络,利用 MobileNet的思想对其进行加速,并引入可变形卷积和可变形池化,构造出新的卷积神经网络进行特征提取。同时,将旋转矩形框应用到目标检测器中,得到具有旋转不变性的舰船目标检测器,该检测器不仅可以输出目标的位置和大小信息,还能输出目标的角度信息。最后,本文设计了一种针对旋转矩形框的IoU计算方法来进行非极大抑制(Non-Maximum Suppression,NMS)筛选[21],并在原始SSD算法的损失函数上进行拓宽,加入了角度回归的损失来指导训练。
2.1 网络加速
考虑到backbone在引入可变形卷积和可变形池化后,会增加特征提取时的运算量、处理时间以及权重模型的参数,本文借鉴MobileNet的思想对 VGG19模型进行加速和压缩。MobileNet使用的是深度可分离卷积,其核心思想是把标准卷积操作分解成深度卷积(DConv)和逐点卷积(PConv)操作,DConv起到滤波作用,PConv起到通道转换作用,这样可减少卷积核的冗余表达,从而大幅降低网络参数量和计算量。
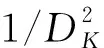
(1)
因此,本文将 VGG19中标准 3×3 卷积操作分为 3×3的DConv模块和 1×1 的PConv模块,每个卷积后仍连接归一化(Batch Normalization,BN)层和 ReLU激活函数来构建网络,整个架构如图 1 所示。
2.2 可变形卷积与池化原理
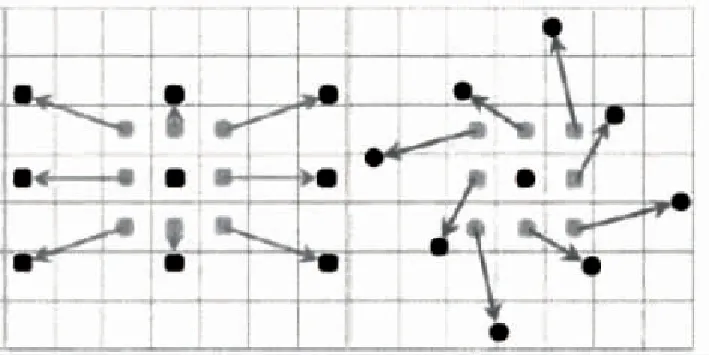
传统的卷积操作使用的是方块核,卷积窗口形状是固定的,本文算法引入了可变形卷积和可变形池化模块来增强基础网络对几何变换的建模能力,提高了输出特征对目标旋转变换的敏感性。2个模块的基本思想都是用带偏移的采样来代替原来的固定位置采样,增加的偏移量可以通过梯度反向传播进行端到端的学习。如图2和图3所示,可变形卷积核的大小和位置可以根据识别目标进行动态调整,不同位置的卷积核采样点会根据目标内容发生自适应的变化,从而适应舰船目标的几何形变。
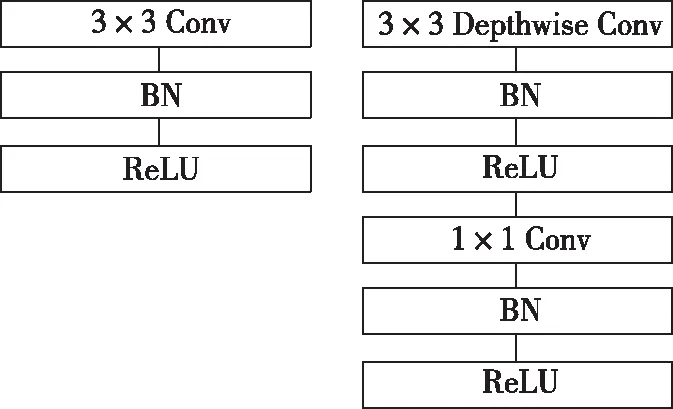
图1 可分离卷积结构图Fig.1 Separable convolution structure
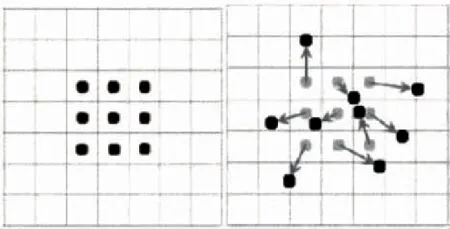
(a)传统的3×3方块卷积核 (b)加入偏移量后的卷积核1
(c)加入偏移量后的卷积核2 (d)加入偏移量后的卷积核3图2 方块卷积核与可变形卷积核Fig.2 Block convolution kernel and deformable convolution kernel
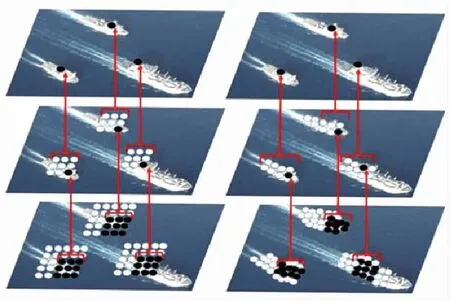
图3 方块卷积与可变形卷积实例对比(左图为传统方块卷积,特征采集时纳入无用的背景信息;右图为可变形卷积,有效避免了背景和干扰项的影响)Fig.3 Comparison of block convolution and deformable convolution (the left picture is the traditional block convolution, the use of background information is included in the feature collection; the right picture is the deformable convolution, effectively avoiding the influence of background and interference terms)
一般的卷积操作步骤为:1)使用一个规则网格R对输入特征图X进行采样;2)对每个采样点乘以权值W并求和。以一个3×3的卷积为例
R={(-1,-1),(-1,0),…,(0,1),(1,1)}
(2)
对于位置p0,传统的卷积输出为
(3)
在可变形卷积中,如方格变形偏移,只需加上其偏移向量Δpn
(4)
Δpn只影响X输入层像素的抽样,并不影响权重W,所以需要训练的参数有2组:W和Δpn,如图4所示。
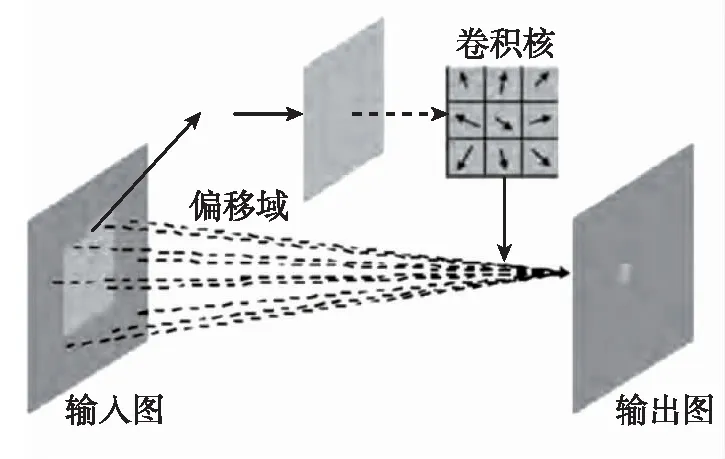
图4 可变形卷积网络结构Fig.4 Deformable convolution network structure
同样地,传统的池化为
(5)
要想成为可变形的池化,与可变形卷积类似,只需加上其偏移向量Δpij,即
(6)
网络结构如图5所示。
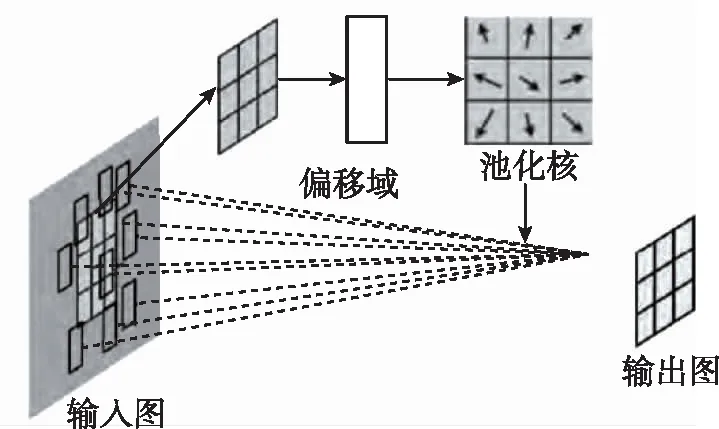
图5 可变形的池化网络结构Fig.5 Deformable pooled network structure
2.3 旋转anchor机制
SSD目标检测方法采用标准的垂直矩形框对目标进行定位,对于舰船等带有角度信息的细长型目标则具有明显的局限性,主要体现在以下三点:1)垂直矩形框并不能显示出舰船目标的真实形状和长宽比;2)当目标旋转角度接近45°时,垂直矩形框会引入较多的背景信息,复杂场景下会提高误检率和虚检率;3)难以区分密集排列时的舰船目标,一个框可能包含多个目标,框与框之间重复部分较大。
针对上述3个问题,本文借鉴场景文字检测中旋转边框定位的思想[22],将原始的anchor改造为带有旋转的anchor,以倾斜角度来量化表示目标的倾斜程度,最终的检测框以(x,y,w,h,θ)给出。其中,θ定义为以矩形形心为起点、船头连线中心点为终点的向量与x轴的夹角,逆时针方向为正,取值为(-90,270],示意图如图6所示。表1比较了两种检测框对舰船目标的刻画效果,可见旋转矩形框更适用于反映目标的真实形状。
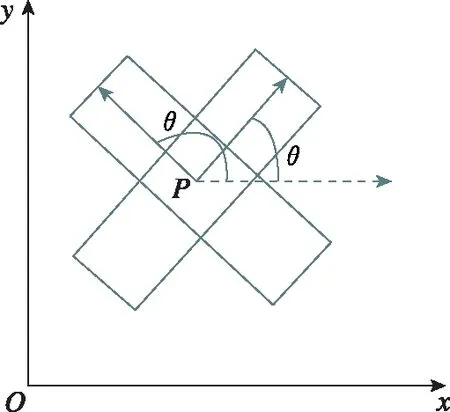
图6 目标旋转角度示意图Fig.6 Schematic diagram of the target rotation angle

表1 标准矩形框与旋转矩形框的比较
2.4 旋转的非极大值抑制
学术界通常使用IoU作为两框匹配策略的判定标准,对于垂直矩形框,2个框的交集和并集也是垂直矩形框,计算方法较为简单;但对于旋转矩形框,2个框的交集理论上是一个多边形(边数不多于8),计算方法较为复杂。本文采取一种简单的计算R-IoU(Related-IoU)的方法:1)以一个框A作为基准框,将另一个框B旋转与框A平行,得到框B′;2)以垂直矩形框的方法来计算框A和B′的IoU;3)将2)中所得的IoU乘上框A和B角度差的余弦,即为2个旋转框的R-IoU。R-IoU计算公式如下
(7)
由式(6)可以看出,计算R-IOU时引入了角度信息,2个框的有效角度相差在[0,180]范围内时,差值越大其余弦值越小,即R-IoU的值越小。在训练时利用R-IoU剔除与标注框(GroundTruth,GT)角度偏差大的默认框,在NMS时可以对R-IoU大(即角度偏差小)的重复框进行有效抑制。
2.5 损失函数
损失函数的设计对目标检测网络的训练至关重要,改进SSD算法的损失函数是在原有损失函数上进行拓宽,加入角度回归的损失,使得模型能够有效学习角度偏差。整个损失函数计算公式如式(8)所示。
(8)
其中,N为匹配到的旋转anchor个数,c是置信度向量,α为权值系数,默认为1。
该损失函数是位置损失和类型损失的加权和,Lconf是类型损失函数,LR-box是位置(回归)损失函数。位置损失函数具体如下
(9)
(10)
(11)
(12)
(13)
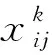
邵雍理论基础是“以物观物”说。“所谓‘以物观物’是对‘以我观物’而言的,即排除个人的感情,而去体察万物,从而达到所谓‘穷理’‘尽性’‘知命’。”[39]44陈献章主张自得,注重个体的参与,故其诗歌中包含着更多自我情感的投入。由此而言,庄昶诗歌更多倾向于继承邵雍的观物说。其《雪蓬为盛行之作》末句:“只有区区观物亭,半庭茂叔窗前草”[3]卷一,46即可视为对邵雍学说的回应,也是他作诗的一贯主张。这一主张也贯穿于他的题画之作,如《题通伯先生山水画》《钟钦理画牛》《题沈石田画鹅为文元作》《题菜》等。正是陈庄二人的提倡,才使得有明一代,学击壤派者“转相模仿”[31]卷一五三,3966。
类型损失函数是以softmax函数为主的多分类交叉熵函数,具体见式(14)和式(15)
(14)
(15)
2.6 具有旋转不变性的舰船目标检测器
综上所述,本文构建了一个针对舰船目标的新检测器。该检测器首先利用可变形卷积网络对图像进行特征提取,之后在多尺度上进行目标检测[12],每个尺度得到K×(1+5+classes)个通道的预测张量。这里的K指的是在每个特征图网格里prior R-box的个数,prior R-box指的是旋转anchor的真实选取。对于一个prior R-box,会产生(1+ classes)维的置信预测向量和5维位置预测向量。经过对预测张量的解码,检测器可以得到修正后的准确预测框,之后算法综合多个尺度上的检测结果进行NMS处理,可以筛去重复预测框。整个流程图见图7。
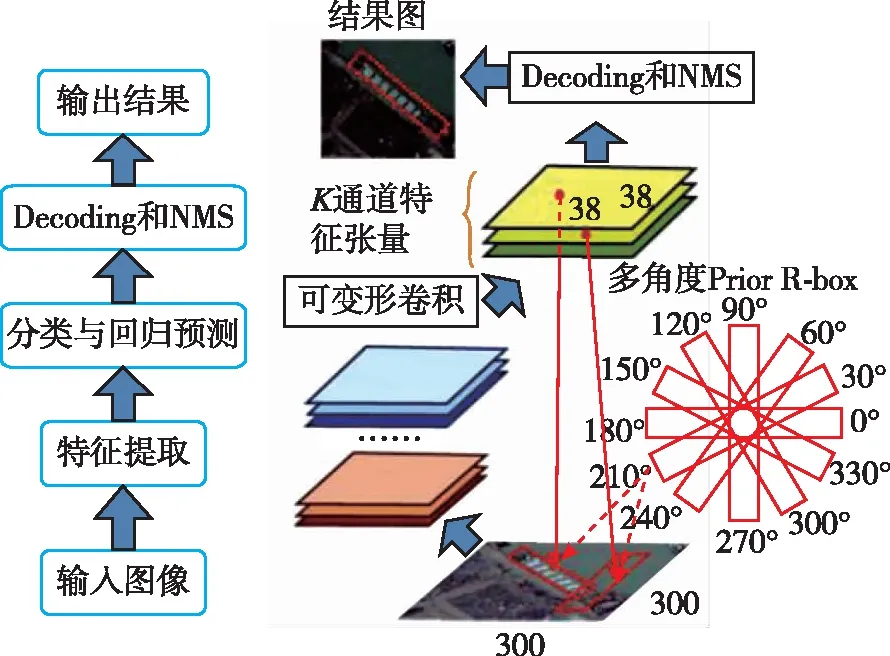
图7 改进SSD的检测流程图Fig.7 Flow chart of improved SSD detection
在改进的SSD舰船目标检测器中,多角度prior R-box与可变形卷积相辅相成。可变形卷积结构使得特征图含有目标的几何形状信息,在prior R-box滑动过程中减少了无效的背景信息对目标定位的干扰。同时,prior R-box在滑动到每个位置上时都会按30°遍历12个旋转角来拟合舰船的朝向信息,这样只需要确定几个长宽比的矩形框便可以覆盖所有目标形状,大大缓解了传统检测器因目标旋转而引起的先验框指数倍增长的问题。
3 仿真实验
本文通过设计实验验证了改进的SSD算法在舰船识别与分类中的有效性,并与其他主流的基于深度学习的目标检测算法进行了比较。经实验分析,本文所提出的算法在量化指标和检测精度方面均表现良好。
3.1 数据集介绍
由于网上并没有完全适合本文应用需求的开源舰船数据集,因此本文构建了一个具有一定规模的数据集。该数据集包括红外图像和可见光图像2个部分,具体类型分为8类:航母、驱逐舰、核潜艇、两栖攻击舰、渔船、货船、巡逻船、油罐船。
本数据库图像大小主要为640×512和320×256,包括红外图像15634张(含19352个实例),可见光图像3145张(含14873个实例),图像已通过开源工具完成标注,标签格式为:类别代号、旋转矩形中心点横坐标、中心点纵坐标、宽、高、旋转角。
3.2 实验条件配置
算法的训练和验证均基于Caffe框架,训练阶段GPU选择NVIDIA GeForce TitanX,采用动量项(momentum)为 0.9的异步随机梯度下降,权值的初始学习率为0.001,衰减系数设为0.0005,最大迭代次数为500000,在300000和350000次时分别降低10%的学习率。为提高算法的鲁棒性,对原始图像进行如下增广处理:增加高斯与椒盐噪声,均值、高斯滤波,反色,左右上下翻转,亮度对比度变换等操作。
3.3 实验评价指标
在计算机视觉领域中,根据任务不同,其评测指标也各不相同。本文结合其他任务中的评价方法,采用识别概率、识别精度和识别速度进行评价,具体含义如下:
1)识别概率:
设DT为识别到的目标位置信息,GT为真实目标位置信息。在类别标签预测一致的情况下,根据DT与GT的IoU结果来判断其是否识别正确,如果IoU大于阈值(这里取0.5),则识别正确,反之为识别错误。IoU计算方式见式(7)。将识别正确的框个数除以GT总数量得到识别概率。
2)识别精度:
设DC为识别的目标中心位置信息,GC为真实目标中心位置信息。按上述方法判断识别到的情况,根据DC与GC在图像上的像素距离来计算识别精度。识别精度的计算如下
(16)
3)识别速度:
本文利用学术界常用的FPS来表征识别速度。FPS指的是每秒中识别图像的数量,即帧/s。它是识别时间的倒数,其值越大说明1s内识别的图像越多,算法运行速度越快,反之则越慢。
3.4 实验结果及分析
实验将预测层输出的舰船目标类型数改为训练集对应的类型数量,利用自建的舰船数据库进行了3组训练:1)将可见光样本的4/5作为训练集,1/5作为测试集,验证模型的同源有效性;2)将全部可见光样本作为训练集,红外图像作为测试集,验证模型的异源迁移性;3)将整个数据集(即两种源域混合)的4/5作为训练集,1/5作为测试集,验证模型的多源融合性。由于实用时多为红外探测体制,本节将数据集中的可见光图像都进行灰度化处理,以使样本接近红外图像。
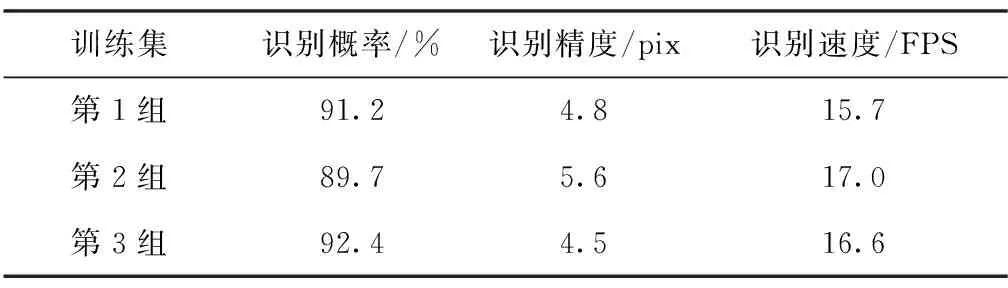
训练完成后,将得到的权值模型在对应测试集上进行批量测试,检测框的概率阈值设为0.5。这里选取改进SSD算法的部分检测效果图,如图8和图9所示,并按照3.2节的评价指标对实验结果进行了统计,见表2。结果表明:改进SSD算法能够对多模态下水面和港口不同姿态的舰船进行有效检测,能够对多个类型进行区分,并适应于多种场景,具有一定的泛化能力和较强的鲁棒性。测试时间在TitanX约55ms一帧,在TX2上约200ms一帧,满足工程应用的实时性要求。
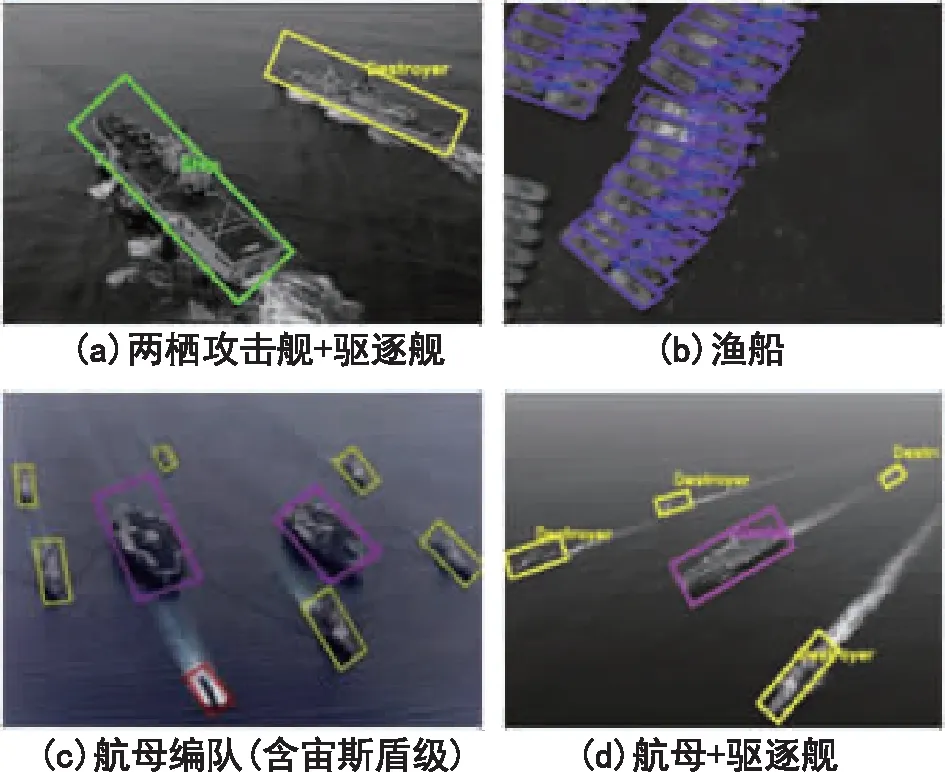
图8 可见光图像检测结果图Fig.8 Visible image detection results

图9 红外图像检测结果图Fig.9 Infrared image detection results
训练集识别概率/%识别精度/pix识别速度/FPS第1组91.24.815.7第2组89.75.617.0第3组92.44.516.6
对比表2的第1、2组统计结果可知,算法在同源训测数据的性能表现要优于异源,这说明由可见光样本训练出的网络模型虽然具有一定的异源迁移能力,但其性能表现仍不如在数据分布更接近的同源数据上。这一现象符合深度学习算法的原理,借鉴到工程应用时则需将训练样本尽可能地接近实际测试样本。对比第1、3组统计结果可知,算法在多源训测数据的性能表现要优于同源,这说明扩大数据量和提高样本多样性对提高算法性能有较大的帮助。借鉴到工程应用中,则是对于难获取的非合作舰船目标,尽可能地搜集类似的红外样本,与可见光仿真样本混合训练,有助于提高待打击目标的识别性能。
为证明本文算法的优越性,实验在相同配置条件下按照第3组训练方式做了改进SSD算法和其他通用深度学习检测算法的性能对比,如表3所示。
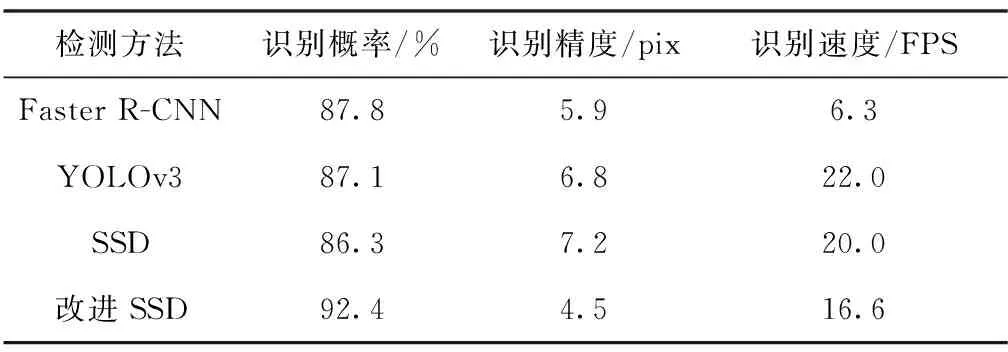
表3 不同检测模型的检测性能对比
由表3的统计结果可得,改进后的SSD算法较其他流行的深度学习算法在本文数据集上的性能表现最好,主要原因是其在SSD算法多尺度预测、默认框机制、难例挖掘等优势基础上加入了可变形卷积与池化操作、旋转框机制,并且对损失函数进行了优化。以上改进弥补了原始SSD算法较其他算法在精度上的不足,同时融合了MobileNet网络架构使算法基本维持了原有的识别时间。
4 结论
针对提高对海智能识别的使用需求,本文提出了一种端到端的舰船目标精细化检测方法。算法分析与实验表明:
1)算法通过引入可变形卷积与池化模块,对舰船目标的几何姿态信息具有较强的学习能力,可适应复杂海面和港口环境下的舰船目标检测;
2)算法通过引入旋转默认框机制,使得检测框包含了更少的背景信息并能够给出目标朝向信息,对不同姿态的海面舰船具有较强的鲁棒性,分类能力更高;
3)算法借鉴MobileNet的思想对网络进行优化,减少了冗余计算量,平衡了速度与精度,可满足算法实时性要求;
4)算法对于训练集外的新目标类型适应能力较弱,对于外形比较接近的不同目标或背景容易产生误检,对于弱小目标容易产生漏检,这些是有待进一步提高的方面。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
舰船科学技术(2022年10期)2022-06-17
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
舰船科学技术(2021年12期)2021-03-29
智慧少年·故事叮当(2020年10期)2020-11-06
中华诗词(2020年1期)2020-09-21
小学生作文(中高年级适用)(2018年5期)2018-06-11
